Ml-agents: Unable train even simplest model
Hi, guys.
I am trying to train a simple model, with 10 states(continuous) and 10 actions(discrete) and so far unsuccessful. States consist from unique numbers from 0 to 9 in random order. Action should be state index where number 7 is located. Debug log example (numbers are divided by 10):
Agent found 7 under index 8 in List: 0.2,0.5,0.3,0.9,0,0.6,0.4,0.8,0.7,0.1
Full source link https://pastebin.com/mXRrunKw . Hyperparams are default, AgentStep implementation below. What am i doing wrong?
public override List<float> CollectState()
{
List<float> state = new List<float>(currentState);
return state;
}
public override void AgentStep(float[] act)
{
int action = (int)act[0];
string actionDesc = "";
if (action < 0 || action > currentState.Count)
{
throw new UnityAgentsException("invalid action: " + action);
}
if (currentState[action] > 0.69 && currentState[action] < 0.71)
{
actionDesc = "Agent found 7 under index " + action + " in List: " + string.Join(",", currentState.ToArray());
reward = 1;
done = true;
}
else
{
actionDesc = " Agent did not found 7 with action " + action + " in List: " + string.Join(",", currentState.ToArray()) + ", debug: " + string.Join(",",act);
reward = -0.1f;
}
Debug.Log(actionDesc);
}
 surferau
surferau
All 12 comments
When you say it is unsuccessful, do you mean it never finds the correct position or that it never become better at it ?
Even by luck it should at least find it sometime.
 mplantady
on 30 Oct 2017
mplantady
on 30 Oct 2017
It finds it by luck, but it never become able find it consistently. Here is Tensorboard screenshot:
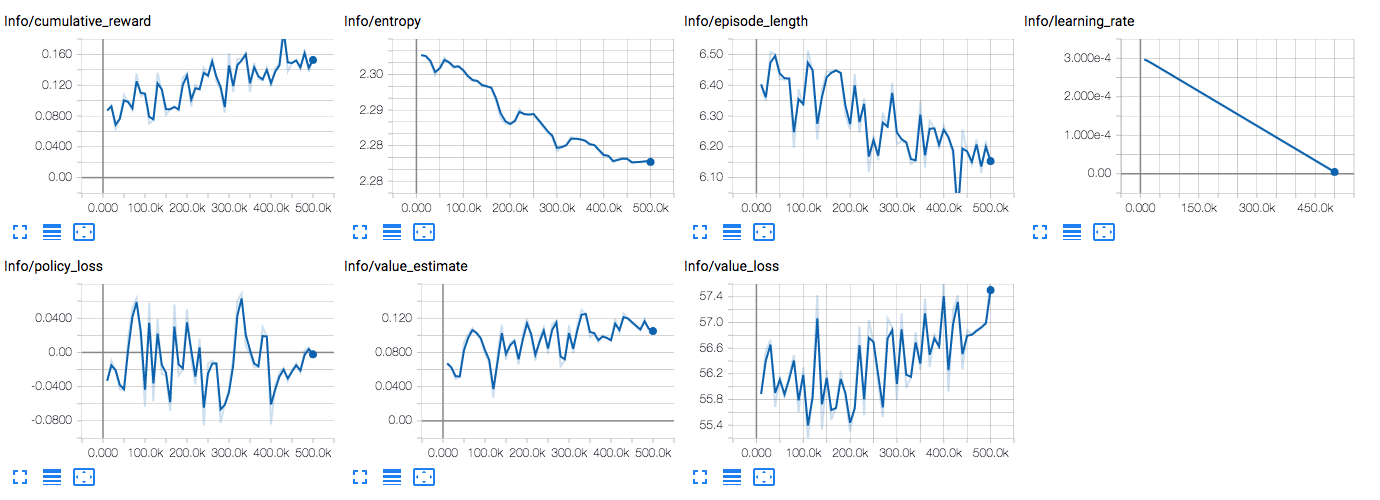
Maybe it needs more training like 10s of millions iterations but i think for such simple model it should not be like this.
surferau
on 30 Oct 2017
Hi @surferau,
While this may sound strange, It actually looks like your training process is going well! The reward is increasing, and the value estimate is as well. I believe the issue is that you are only training for 500,000 steps, which likely isn't enough to fully learn the task. I would recommend training for at least two million, and examining the results.
 awjuliani
on 30 Oct 2017
awjuliani
on 30 Oct 2017
After 2M steps which took 40 minutes the tensorboard graphs look like this
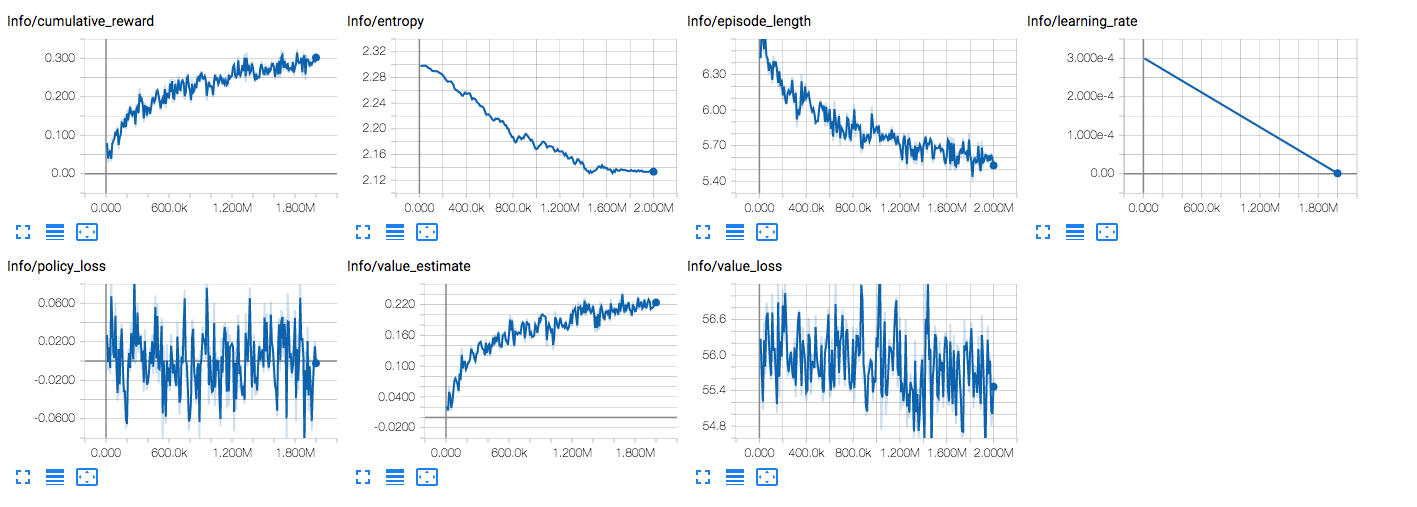
while it made some progress but as you can see it significantly slowed down in the end. I think the most important param here is episode_length since it should be "1" when model is able to consistently predict. Therefore the question is PPO supposed to work like this or there is an issue either with my c# code or python code? I was not able to train GridWorld example with gridsize=4 as well, it just never converge.
surferau
on 30 Oct 2017
If anyone is interested update:
changing lookup number from 7 to 100 (states look like 0,1,2,3,4,5,6,100,8,9 instead of 0,1,2,3,4,5,6,7,8,9) made training process take about 5 minutes instead of never, meaning that relative difference between states is very important. Playing with time_horizon an num_epoch in this example showed that time_horizon does not influence anything (maybe because there is no connection between current state and previous state), but num_epoch does matter, the bigger the better but each step takes more real time to process, if num_epoch too low like 1-3 the training process might take very long time or never, but values over 5 did not show much difference in amount_steps_taking/real_time_seconds_pass . TensorBoard screenshot (indicator of successful training is episode length = 1) :
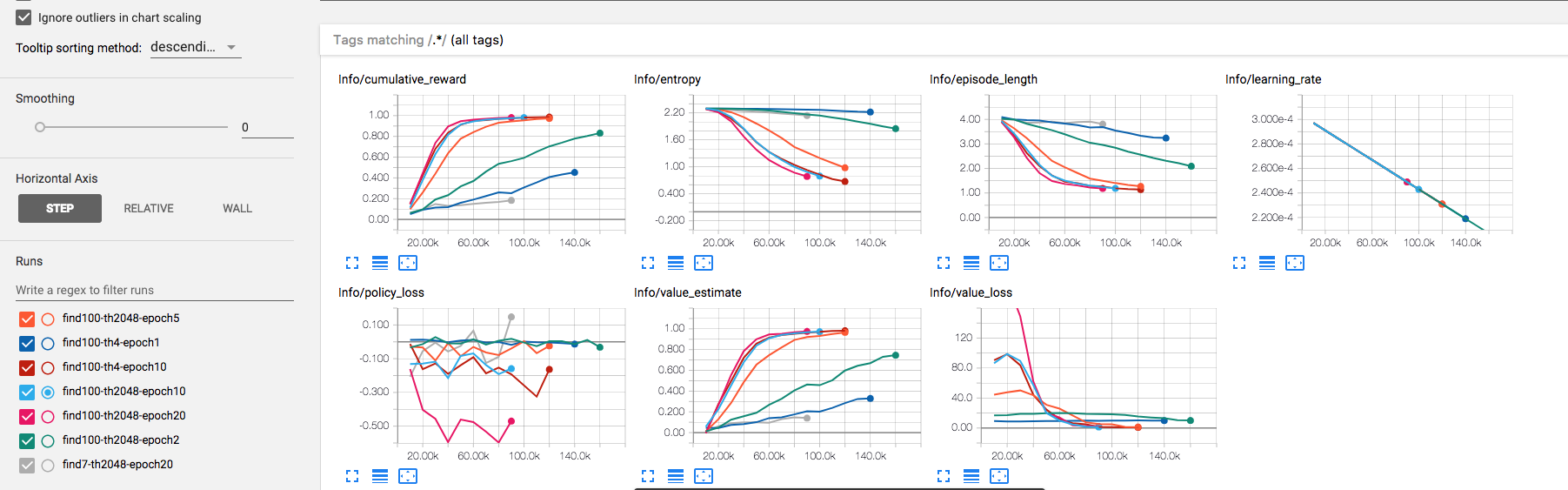
TLDR:
the bigger relative difference between states the easier for network to spot the difference, if relative difference is too low, network training time might be close to infinity. It is possible that current PPO implementation is not sensitive enough and needs more tuning.
surferau
on 31 Oct 2017
states look like 0,1,2,3,4,5,6,100,8,9
How about if you normalize your inputs?
 MarcoMeter
on 5 Nov 2017
MarcoMeter
on 5 Nov 2017
I tried it on the very first attempt (my 1st post: Agent found 7 under index 8 in List: 0.2,0.5,0.3,0.9,0,0.6,0.4,0.8,0.7,0.1)
So far i can say that model does not really care if there are normalized values or not. It did good in the example with states: 0,1,2,3,4,5,6,100,8,9 (it learned fast to find 100) and never learned(or maybe it would learn after calculation for several days) to find 0.7 with states 0.2,0.5,0.3,0.9,0,0.6,0.4,0.8,0.7,0.1 .
Then i tried teach model to find index(0 based) of requested number, example states:
0.2, 0.1, 0.3, 0.4, 0.7, 0.5, 0.6, 0.8, 0.9, 0, 0.7 <- the last number is what we look for
the question is: under what index 0.7 is located and correct answer is 4.
Source code: https://pastebin.com/SVbkuhH3
The model failed absolutely.
Tensorboard:
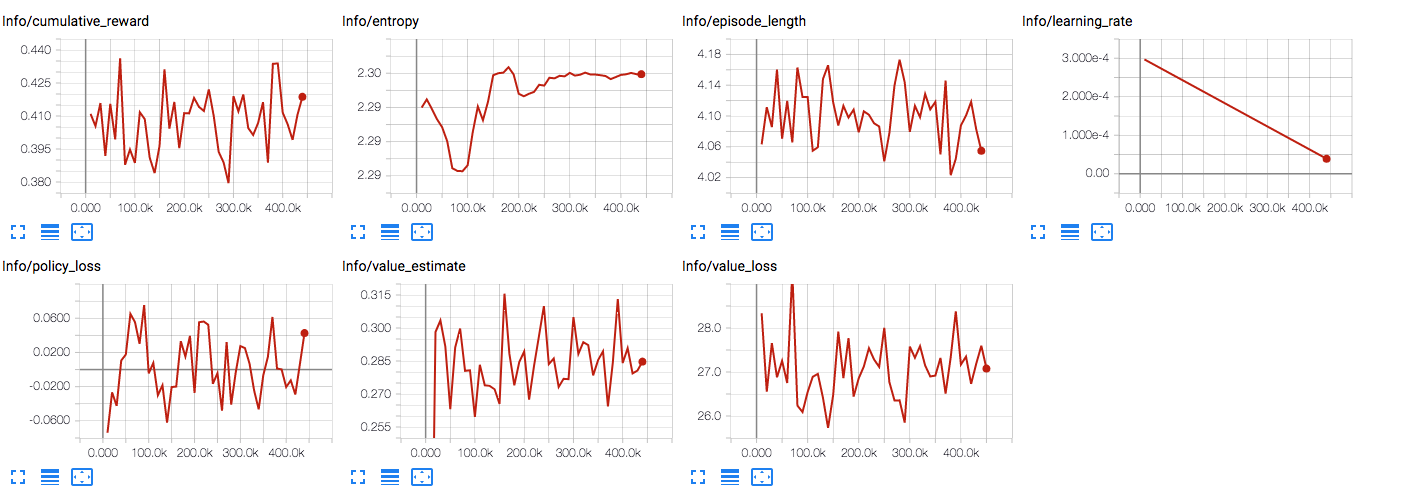
In contrast simple model with 1 relu input, 1 relu hidden layer and softmax output was trained in about 5 seconds to reach accuracy = 1.
surferau
on 5 Nov 2017
Can I work on this?
 MhdTlb
on 9 Nov 2017
MhdTlb
on 9 Nov 2017
@surferau, @awjuliani, I was also facing a very long convergence time ( 36+ hours, 25+ million steps) for a simple 3x3 TicTacToe using ML Agents till I saw your post. I gave a higher value to the tiles which were vacant to be selected a little more than the others, (as per the post), Now it converges in 7-8 million steps, 6-7 hours. Check it out at https://github.com/menondj/RLearningUnity3D. So thank you!
Any feedback is also welcome.
 menondj
on 28 Feb 2018
menondj
on 28 Feb 2018
Re-visiting this thread ... any lingering questions or can we close this out? Also, worth adding that v0.3 of ML-Agents has launched with several new enhancements.
 mmattar
on 29 Mar 2018
mmattar
on 29 Mar 2018
Hi Folks,
Hopefully you have been able to resolve your problems. We are closing this due to inactivity, but if you need additional assistance, feel free to reopen the issue.
 eshvk
on 24 Apr 2018
eshvk
on 24 Apr 2018
I tried it on the very first attempt (my 1st post: Agent found 7 under index 8 in List: 0.2,0.5,0.3,0.9,0,0.6,0.4,0.8,0.7,0.1)
So far i can say that model does not really care if there are normalized values or not. It did good in the example with states: 0,1,2,3,4,5,6,100,8,9 (it learned fast to find 100) and never learned(or maybe it would learn after calculation for several days) to find 0.7 with states 0.2,0.5,0.3,0.9,0,0.6,0.4,0.8,0.7,0.1 .
Then i tried teach model to find index(0 based) of requested number, example states:
0.2, 0.1, 0.3, 0.4, 0.7, 0.5, 0.6, 0.8, 0.9, 0, 0.7 <- the last number is what we look for
the question is: under what index 0.7 is located and correct answer is 4.
Source code: https://pastebin.com/SVbkuhH3
The model failed absolutely.Tensorboard:
In contrast simple model with 1 relu input, 1 relu hidden layer and softmax output was trained in about 5 seconds to reach accuracy = 1.
Hi there,
I know it's a little bit irrelevant but How did you get this tensorflow board and plot those values ?
 khaledbnmohamed
on 24 May 2019
khaledbnmohamed
on 24 May 2019
Related issues
 mattinjersey
·
3Comments
mattinjersey
·
3Comments
 RavenLeeANU
·
4Comments
RavenLeeANU
·
4Comments
 Rodnyy
·
3Comments
Rodnyy
·
3Comments
 Procuste34
·
3Comments
Procuste34
·
3Comments
 DVonk
·
3Comments
DVonk
·
3Comments
Most helpful comment
If anyone is interested update:
changing lookup number from 7 to 100 (states look like 0,1,2,3,4,5,6,100,8,9 instead of 0,1,2,3,4,5,6,7,8,9) made training process take about 5 minutes instead of never, meaning that relative difference between states is very important. Playing with time_horizon an num_epoch in this example showed that time_horizon does not influence anything (maybe because there is no connection between current state and previous state), but num_epoch does matter, the bigger the better but each step takes more real time to process, if num_epoch too low like 1-3 the training process might take very long time or never, but values over 5 did not show much difference in amount_steps_taking/real_time_seconds_pass . TensorBoard screenshot (indicator of successful training is episode length = 1) :

TLDR:
the bigger relative difference between states the easier for network to spot the difference, if relative difference is too low, network training time might be close to infinity. It is possible that current PPO implementation is not sensitive enough and needs more tuning.