Ml-agents: Training never succeeds, any advice?
Hi, I'm trying to train car driving agent but it never succeeds. 😢
In detail,
- Subject to go to a certain position
- Using CarController of Unity standard asset
- Input
- Rotation for the destination
- Distance for the destination
- Velocity
- Skidding or not
- Output
- Accel / Brake (-1 to 0 means break, 0 to 1 means accel)
- Steering
- Reward
- If the vector of forward is nearer than the vector of forward of the last frame to the vector for destination (Using Vector3.Dot), rewarded +0.15
- If the vector of velocity is nearer than the vector of velocity of the last frame to the vector for destination (Using Vector3.Dot), rewarded +0.35
- If the car is skidding, rewarded -0.2
I've tried,
- Very close distance to the destination
- Little far to the destination
- Rewarded only when reached the destination
- 1e6 steps
- 1e7 steps
- 128
hidden-units - 256
hidden-units - Other input and reward logic
but never worked. I don't know what's wrong.
Maybe car driving is too complicated to be solved by ml-agents though PFN shows the sample.
I'm new to ml-agent, so I don't know the best way to construct the environment, input and reward.
Can you suggest something? I really appreciate your help.
Thank you for reading.
 dora-gt
dora-gt
All 31 comments
Sorry for the rough explanation, but the code is too long to show here.
...and my english may be poor because I'm a Japanese😥
It seems that the agent often continues to rotate, I tried some logic to prevent it, but never worked.
My reward logic isn't aim to reward it...why...
Giving reward every frame is wrong?
Input isn't enough or format is wrong?
Training is not enough?
Hidden-units is not enough?
Any advice is welcome.
dora-gt
on 18 Oct 2017
Maybe you should focus on the rotation first.
A training with a straight line and a small penalty each frame so that the agent can learn stability and avoid unnecessary rotation.
The problem is that you still want your agent to keep a good exploration, so don't wait too much and keep the entropy high before adding more complex training to it.
 mplantady
on 18 Oct 2017
mplantady
on 18 Oct 2017
Thank you for your reply.
don't wait too much means, training without max step goes wrong sometimes?
Actually, the behavior suddenly changes after some training.
First, it moves randomly (I think this is good).
After some training, it goes backward continuously (I think this causes wrong training).
I'll try easy problem with short time. Thank you.
dora-gt
on 18 Oct 2017
Yeah, I prefer using a small Max Step (~ equal to 1 hour) with "Load Model = true".
This way you can adjust things without restarting always at the begining.
mplantady
on 18 Oct 2017
I noticed one more thing.
If the training process takes too long, the action value comes vainly large,
because CarController accepts only -1 to 1 for steering value while action value is like 500 (tooooo large).
Can we avoid this? parameter or training time...? 🤔
dora-gt
on 18 Oct 2017
Hi, of course you should clamp output value to -1 and 1.
Make sure all your states are between -1 and 1, too. If they are not, such as distance, you need to find a proper range of real distance to make the states input between-1 and 1.
 trulyspinach
on 18 Oct 2017
trulyspinach
on 18 Oct 2017
Hi, thank you for the reply.
Yes, I am clamping the value (actually, CarController does) and the values are normalized.
I'm trying very short training, but it doesn't work too... 😢
I don't think this environment is too hard for deep-learning, why...
dora-gt
on 19 Oct 2017
Could you please explain how you calculate the "Rotation for the destination" ?
Or is the car too hard to control ?
I don't think it should be a hard task for deep-learning, too.
trulyspinach
on 19 Oct 2017
Rotation is like:
Quaternion rotation = Quaternion.FromToRotation(forward, destination - carPosition);
The car is the default state of Unity standard asset, but may have too strong power.
dora-gt
on 19 Oct 2017
Hi,
I don't think your input have any problem. I haven't had any good idea about representing rotation yet, too. I am trying to train a soccer robot which is very likely to yours.
Seems like all example are using discrete action, which's "right" and "left" means go right and go left, but in our case, "right" and "left" mean turn right or turn left.
I am sorry for won't be able to help. But I will let you know if I find anything helpful.
Hope someone would help, too.
trulyspinach
on 19 Oct 2017
Do you use observation cameras ?
Is it submitted on your github fork, to take a look ?
mplantady
on 20 Oct 2017
@SPINACHCEO , thank you so much.
I'll inform you if I found something helpful for your soccer robot too.
@mplantady , Hi, I don't use observation cameras and my repository doesn't contain my code actually, I'm using private repo. because it contains some proprietary code.
I'll try to make it public.
dora-gt
on 20 Oct 2017
dev branch has some difference, some parameters differ. I should use it maybe. 🤔
dora-gt
on 20 Oct 2017
Finally!!! 😍
I got positive result while I can't verbalize the way well...but the following is my opinion.
- Rotation logic may not be wrong
- It worked finally
- Using action value as steering angle and acceleration may not be wrong
- It worked finally
- Training long time doesn't mean always good
- It causes overfitting sometimes
- Agent max step helps sometimes
- We have to watch the process(cumulative reward, episode length, learning rate) carefully
- Training time and learning rate are related and very sensitive, have to be set very carefully
- Rewarding every step isn't good for my environment
- I fixed it to reward (+1.0) it only when the car reaches the destination
- Though rewarding negatively every step (-0.00006, should be optimized depending on the environment)
- Fixed to set cumulative reward 0.0-1.0 during the session (untill
done = true)
- I don't know this is good or not
Summarizing it... the training process is very very very difficult, we have to optimize every value carefully.
It has to be more accurate, I have to keep improving it.
dora-gt
on 20 Oct 2017
@dora-gt That's great! Congratulations !
Is this happen after you adjust some hyperparameters ? My soccer bot still acts like an idiot.😔
Could you please suggest me something ?
trulyspinach
on 20 Oct 2017
Maybe...reward logic (rewarding only when the car reaches the destination) and preventing from overfitting (minimum agent max step, minimum overall max step) were important but I'm not sure...
Can I try your environment? or just look your code?
dora-gt
on 20 Oct 2017
of course, hold on a while I will send it to you :)
trulyspinach
on 20 Oct 2017
Archive.zip
The zip contains my environment and the training script I using(with a progress bar).
Just put the Robot Ball folder into you ml-agent Unity3D project.
You can change the size of agent to a bigger value in SoccerGround.cs to make it easier to train at start.
Thanks for you time :)
Hope your can make it works. 😁
trulyspinach
on 20 Oct 2017
Hi @dora-gt,
So glad you were able to get something working! I'd love to see a video of it, once it is ready.
I put together a short document this morning walking through the hyperparameters available in PPO, to give a little more structure to the process of tuning that often needs to happen: https://github.com/Unity-Technologies/ml-agents/blob/master/docs/best-practices-ppo.md Hopefully it can be helpful to you and others in the future. @SPINACHCEO It may be useful to you as well.
 awjuliani
on 20 Oct 2017
awjuliani
on 20 Oct 2017
@SPINACHCEO Thank you, I'll look into later.
@awjuliani Thank you for the document, that will help many people ☺️
I'll tune again reading the document.
and... here is the movie that my agent acts though it is not accurate enough, showing something close to the desired behaviour.
I'm trying to apply this to more long distance now, and make it more accurate (go directly).
dora-gt
on 21 Oct 2017
@awjuliani , I read the document and I would like more explanation on the following.
EpsilonandNumber of Epochs
- I could not understand what these are for
- Could you explain a little more?
ValueofValue EstimateandValue Lossmeansreward?
I'm sorry I'm poor at ML. Could you explain more about it?
dora-gt
on 21 Oct 2017
@awjuliani Hi, thanks very much for the documentation. They're really helpful.
@dora-gt
I have some knowledges in ML so in my understanding ->
- Number of Epochs, epochs mean how many time should the model process a dataset. In our current context, it means how many gradient descent step should perform when the model collect enough experience(
buffer_size). By performing more step the agent learning more from a single set of experience.
- Epsilon, I think it means the rate of accepting new policies. Policy in RL basically mean a mapping between state and action: determine what action shall I take in a certain state.
trulyspinach
on 21 Oct 2017
Very cool video @dora-gt! One thing you might want to try is to use a curriculum where the goal is moved progressively further away as the agents gets better.
Thanks @SPINACHCEO for the answers. Epsilon is particular to Proximal Policy Optimization (see here: https://arxiv.org/abs/1707.06347) and controls the extent to which the policy after a gradient update should be allowed to differ from the policy before that update. By keeping this within a small range, we can prevent updates from accidentally breaking our policies.
Value in particular refers to the expected future discounted reward at the current state for an agent. It roughly translates to "how well the agent thinks it is doing." This should on average increase over time, to reflect the fact that the agent receives more reward. Value loss is how far off the agent's estimates are to reality. Hope that helps.
awjuliani
on 21 Oct 2017
@SPINACHCEO , I checked your project. It looks so difficult 😅 because
- Agent has to go to goal with ball or kick the ball to the goal
- Agent has to control ball
- Agent has to avoid from being on walls
Maybe this is very difficult one of machine learning projects.
Here is my opinion.
cos of the agent to ballmay confuse agent because it doesn't mean rotation- It may help giving velocity of ball
- It may help giving goal's position or rotation to the goal.
- Using camera may help because the wall changes behaviour of agent and ball
- but I haven't used camera so far
Good luck! and thank you for the explanation on my question.
I could understand number of epochs and epsilon.
dora-gt
on 22 Oct 2017
@awjuliani , thank you for the explanation. I could understand.
I translated the document into Japanese, because there are very few documents on ml-agents in Japanese.
PPO で学習させる際のベストプラクティス
dora-gt
on 22 Oct 2017
@dora-gt Thanks for the advices. I found that Quaternion.FromToRotation is really useful representing rotation. I successfully trained my agent to hold the ball, and trying to train it to score the goal now.
I wish I could use camera but I don't know why I can't. It always threw some exception. I already post another issue but seems like no one is facing the same problem. :(
trulyspinach
on 23 Oct 2017
@SPINACHCEO Great to hear that you could successfully train the agent and sorry to hear about camera... I don't use camera so I don't know much about it, but I found that tuning hyper parameters is really important. Here is the before and the after.
- Before tuning
- Not stable...
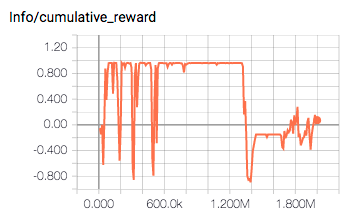
- After tuning
- Stable!
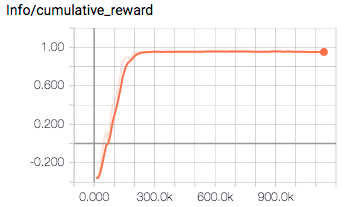
What I tuned was...
--hidden-units=128--epsilon=0.1--learning-rate=1e-5
I don't know which is the best part of the improvement 😅 but the document helped a lot, thank you @awjuliani
dora-gt
on 23 Oct 2017
It's getting better! 😍
dora-gt
on 23 Oct 2017
I got something to improve training process, so close this issue for the moment.
Thank you very much guys.
Conclusion:
- Input value (state) is very important
- Should include only something meaningful to output
- Should not include something confusing
- Rewarding logic is very important
- Can't train from rewardless process
- Should implement curriculum training process
- Optimizing hyper parameters is important
- Depending on what you want to train, and the result summary
dora-gt
on 25 Oct 2017
Hi @dora-gt,
So glad you were able to get something working! I'd love to see a video of it, once it is ready.
I put together a short document this morning walking through the hyperparameters available in PPO, to give a little more structure to the process of tuning that often needs to happen: https://github.com/Unity-Technologies/ml-agents/blob/master/docs/best-practices-ppo.md Hopefully it can be helpful to you and others in the future. @SPINACHCEO It may be useful to you as well.
Hey can someone help me. the link is not working.. and I really need a document to explain more about the hyperparameters in PPO.
 ust007
on 30 Nov 2018
ust007
on 30 Nov 2018
This thread has been automatically locked since there has not been any recent activity after it was closed. Please open a new issue for related bugs.
![lock[bot] picture](https://avatars1.githubusercontent.com/in/6672?v=4&s=40) lock[bot]
on 3 Jan 2020
lock[bot]
on 3 Jan 2020
Related issues
 sunrui19941128
·
33Comments
sunrui19941128
·
33Comments
 KilianSillero
·
29Comments
KilianSillero
·
29Comments
 drArthur
·
20Comments
drArthur
·
20Comments
 karthikveeramani
·
31Comments
karthikveeramani
·
31Comments
 m-ronchi
·
22Comments
m-ronchi
·
22Comments
Most helpful comment
Finally!!! 😍
I got positive result while I can't verbalize the way well...but the following is my opinion.
done = true)Summarizing it... the training process is very very very difficult, we have to optimize every value carefully.
It has to be more accurate, I have to keep improving it.