Minikube: Creating a StatefulSet with a PVC template fails with "PVC is not bound"
BUG REPORT
Minikube version: v0.21.0 (but seen since 0.17.0 I believe, that's when I started using minikube)
Environment:
- OS: macOS Sierra (10.12.5)
- VM Driver: xhyve
- ISO version: v0.23.0
What happened:
When creating a StatefulSet that includes a PersistenVolumeClaim template, the pods fail to start with the message:
PersistentVolumeClaim is not bound: "rabbitmq-data-pvc-tpl-bug-2"
See screenshots:
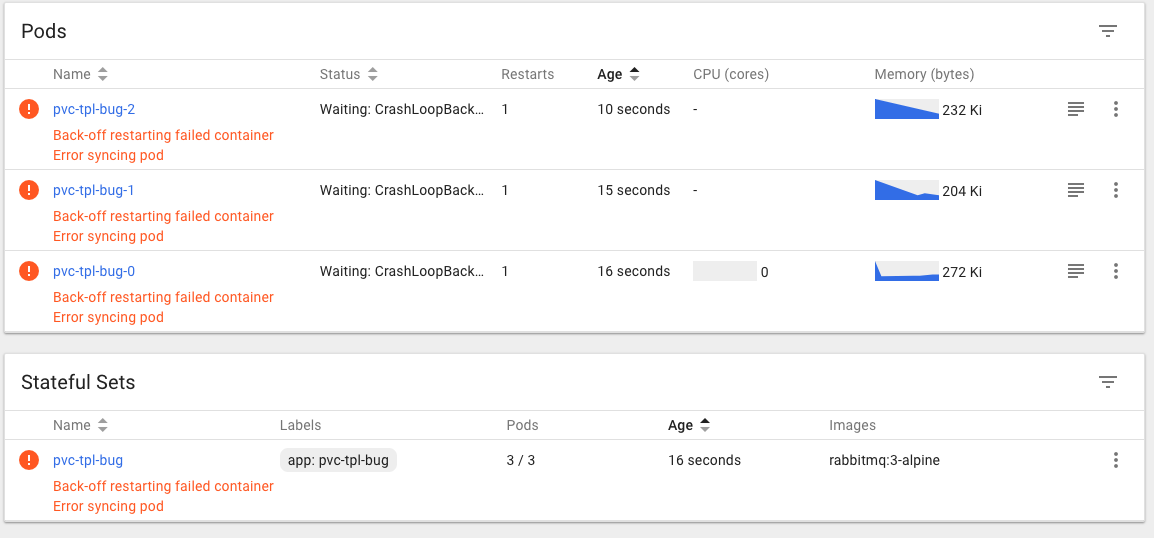

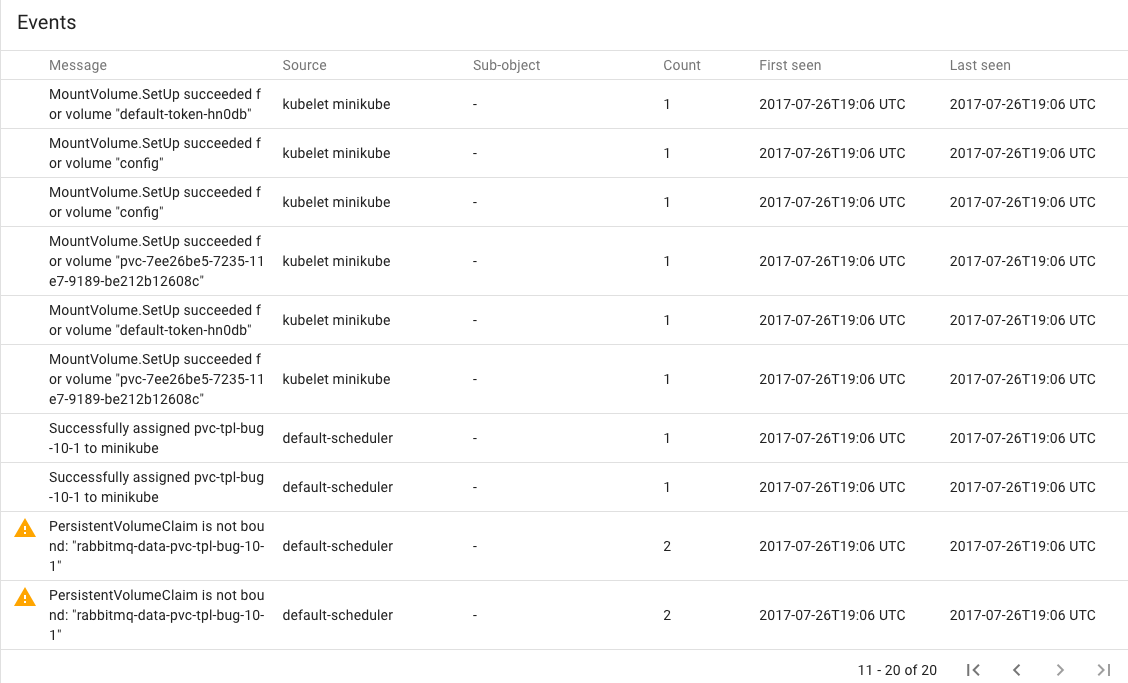
What you expected to happen:
The pods should start without issue
How to reproduce it (as minimally and precisely as possible):
OK. So I tried really cooking it down to a minimal set, as far as I can see, this is a combination of:
- Whether we are using a volume with a configmap alongside (remove it and it works)
- The number of replicas (1 works, 3 doesn't, not sure about 2 there was some noise during testing)
- The image used (tried with
google/pause, which worked, so disk access may be a factor)
So sorry if the repro is a little large. Mind you, the rabbitmq startup itself might fail now, because I have killed the config.
---
apiVersion: v1
kind: ConfigMap
metadata:
name: pvc-tpl-bug-00
labels: {app: pvc-tpl-bug-00}
data:
rabbitmq.config: |
some-data
---
apiVersion: v1
kind: Service
metadata:
name: pvc-tpl-bug-00
labels: {app: pvc-tpl-bug-00}
spec:
selector:
app: pvc-tpl-bug-00
ports:
- name: some-port
port: 5671
---
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: pvc-tpl-bug-00
labels: {app: pvc-tpl-bug-00}
spec:
replicas: 3
serviceName: pvc-tpl-bug-00
template:
metadata:
name: pvc-tpl-bug-00
labels:
app: pvc-tpl-bug-00
spec:
containers:
- name: pvc-tpl-bug-00
image: rabbitmq:3-alpine
imagePullPolicy:
ports:
- name: some-port
containerPort: 5671
volumeMounts:
- name: rabbitmq-data
mountPath: /var/lib/rabbitmq
- name: config
mountPath: /etc/rabbitmq
volumes:
- name: config
configMap:
name: pvc-tpl-bug-00
items:
- key: rabbitmq.config
path: rabbitmq.config
volumeClaimTemplates:
- metadata:
name: rabbitmq-data
labels: {app: pvc-tpl-bug-00}
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: "1Mi"
Anything else do we need to know:
When running the spec multiple times, make sure to increase the number in the name, for some reason I got entirely different errors when I just deleted everything and re-ran.
 andsens
andsens
All 7 comments
Any updates on how to deal with this issue?
 hayesgm
on 5 Nov 2017
hayesgm
on 5 Nov 2017
Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/lifecycle stale
 fejta-bot
on 7 Feb 2018
fejta-bot
on 7 Feb 2018
Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/lifecycle stale
fejta-bot
on 17 May 2018
Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/lifecycle stale
fejta-bot
on 26 Aug 2018
Stale issues rot after 30d of inactivity.
Mark the issue as fresh with /remove-lifecycle rotten.
Rotten issues close after an additional 30d of inactivity.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/lifecycle rotten
fejta-bot
on 25 Sep 2018
Rotten issues close after 30d of inactivity.
Reopen the issue with /reopen.
Mark the issue as fresh with /remove-lifecycle rotten.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/close
fejta-bot
on 25 Oct 2018
@fejta-bot: Closing this issue.
In response to this:
Rotten issues close after 30d of inactivity.
Reopen the issue with/reopen.
Mark the issue as fresh with/remove-lifecycle rotten.Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/close
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
 k8s-ci-robot
on 25 Oct 2018
k8s-ci-robot
on 25 Oct 2018
Related issues
 xmnlab
·
3Comments
xmnlab
·
3Comments
 StasPerekrestov
·
3Comments
StasPerekrestov
·
3Comments
 wudongyin
·
3Comments
wudongyin
·
3Comments
 olalonde
·
3Comments
olalonde
·
3Comments
 Starefossen
·
3Comments
Starefossen
·
3Comments
Most helpful comment
Any updates on how to deal with this issue?