Is the embed model working for sqlite? I seems to be getting errors trying to run lift
model User {
id String @default(cuid()) @id @unique
email String @unique
name String?
posts Post[]
provider embed {
id String
accessToken String
}
}
Error:
Error: Error in lift engine for rpc listMigrations:
thread 'main' panicked at 'loading the connector failed.: DataModelErrors { code: 1001, errors: ["Unexpected token. Expected one of: End of block (\"}\"), field declaration."] }', src/libcore/result.rs:997:5
 lecoqjacob
lecoqjacob
All 9 comments
I am also getting the same error with both sqlite and postgres.
 ansarizafar
on 1 Jul 2019
ansarizafar
on 1 Jul 2019
This is not yet implemented but will eventually be handled by leveraging a JSON column for SQL-based databases.
 schickling
on 3 Jul 2019
schickling
on 3 Jul 2019
is there a schedule when this feature will be implemented? @schickling
 ManAnRuck
on 6 Aug 2019
ManAnRuck
on 6 Aug 2019
Thanks everyone for raising and contributing to this issue. We would love to know more about your use cases. Would all of you be kind to share that as a comment on this issue and help us build this feature 🙌
 divyenduz
on 26 Sep 2019
divyenduz
on 26 Sep 2019
Hey @divyenduz , there appear to be 2 ways to approach embedded models that immediately come to mind for me and I wanted to see what people thought about them.
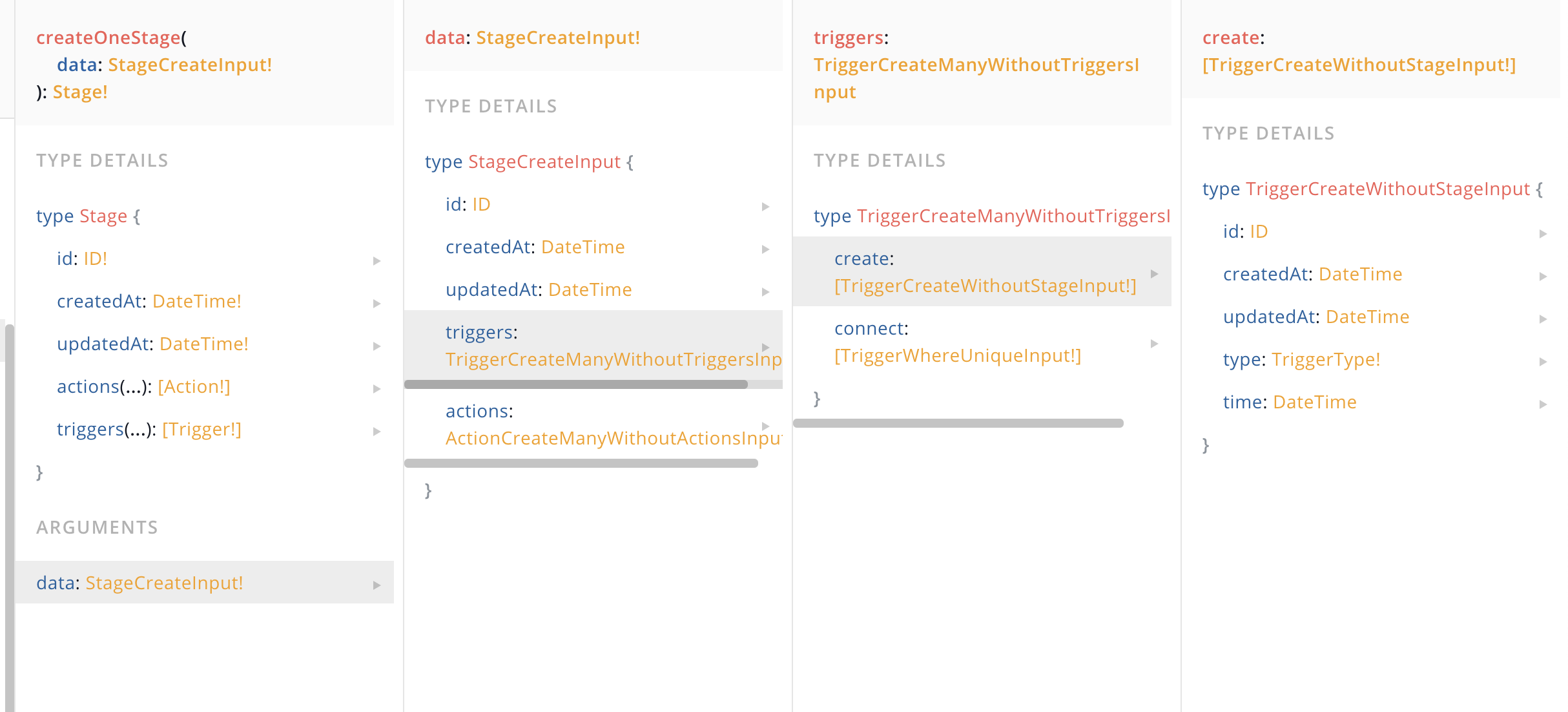
1) From the graphQL api perspective, embedded models will appear just like normal models. For example below, if I have the model stage that will have an embedded model trigger if I am using nexus and want to add embedded triggers to that stage, I'd have to go through the create type when I'm writing my graphQL requests, just as if trigger was an entirely separate model. The pro here is that the syntax is kept the same, the con is that it's more verbose and potentially misleading with the connect since these are embedded and there isn't a clear way to reference existing embedded models in a different record.
2) An alternative would be simply having the input to that field be the entire structure that you'd want to write. This means that the embedded model would take a json object that matches all the types of the model and you'd just write it when you create or update the parent model.
Here's an example where I have a field variables that is a json structure that have nested objects and an array of objects. That means I bypass the create vs connect types on the input side- which kind of makes sense because as I mention above, I'm not even sure what connect would mean in this context when creating the action.
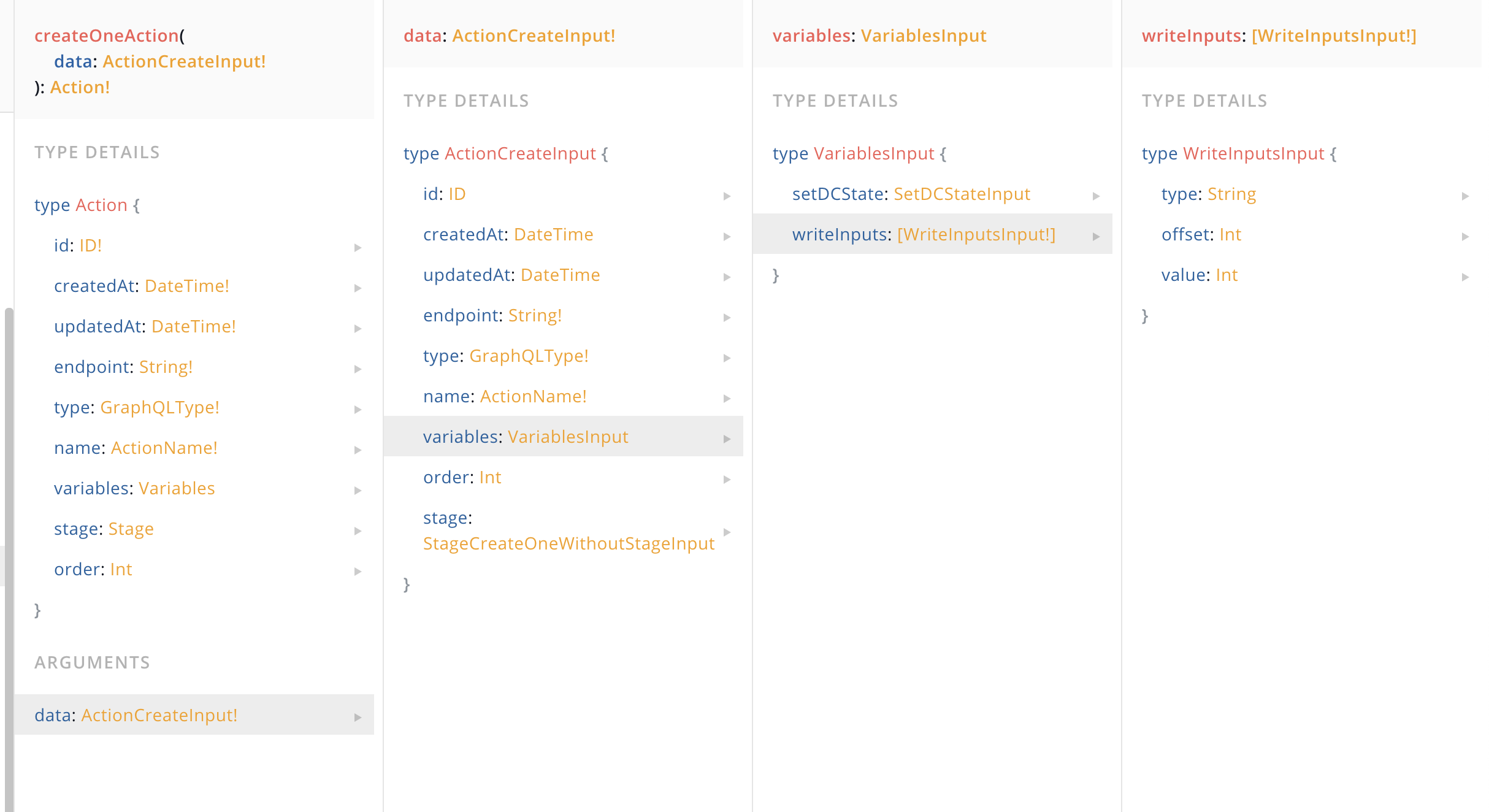
The downside to this approach, is that if I ever update variables I need to first fetch the current variables json object, mutate it and then write the entire thing back. There isn't an obvious way to selectively update just a single nested record from what I can tell. I actually have this working as a hack for a prisma 2 server I'm working on and in my case, the prisma primitive is a string and then I just jsonify/stringify the json objects as they come in and are fetched on the fly.
Happy to expand upon this implementation with nexus further if that is helpful, it works but is a little ugly at the moment because I have to extend all of the nexus input types to switch the native string type that I'm saving to the database to the input type of my embedded model.
 CaptainChemist
on 26 Sep 2019
CaptainChemist
on 26 Sep 2019
Is MongoDB and embedded type will supported, when the prisma2 released at Q1?
 GaborTorma
on 2 Jan 2020
GaborTorma
on 2 Jan 2020
@divyenduz Is there an ETA when this feature will be available?
ansarizafar
on 1 Feb 2020
any updates on @embed ? it has been removed from the documentation without any reason. i think @embed is important and should be available on all databases. In particular because we don't have cascade delete yet.
If we would have delete cascade, it would be less painful, because you could emulate embeds with another collection.
 macrozone
on 14 Jul 2020
macrozone
on 14 Jul 2020
Embedded types were supported in Mongo in Prisma 1. We don't currently support this.
 albertoperdomo
on 22 Oct 2020
albertoperdomo
on 22 Oct 2020
Related issues
 janpio
·
3Comments
janpio
·
3Comments
 julien1619
·
4Comments
julien1619
·
4Comments
 sameoldmadness
·
4Comments
sameoldmadness
·
4Comments
 timhall
·
3Comments
timhall
·
3Comments
 RafaelKr
·
3Comments
RafaelKr
·
3Comments
Most helpful comment
@divyenduz Is there an ETA when this feature will be available?