Mfem: Different results between parallel and serial runs
Hi all,
I'm hoping to get some advice with parallelizing my code. I'm working on a nonlinear magnetostatics problem, which I've verified in serial, but when attempting to run with multiple processes I run into trouble. My problem looks like Curl(mu^{-1}Curl A)=J, with the curl-curl term implemented in a NonLinearForm, and J as a ParGridFunction (computed based on @mlstowell's suggested method 2 from #1488). I use strongly imposed Dirichlet boundary conditions for A.
When using multiple processors, J is seemingly different from the serial case, and dependent upon the number of processors used. I created a MWE that constructs J based on the previously mentioned discussion and shows that the discrete norm of J varies with the number of processors. Visualizing the resulting grid function in glvis appears to show that the field differs near process boundaries (see attached screen shots).
I'm not convinced that this issue with J is the source of all my parallel problems, but I've confirmed that the result of NonlinearForm::Mult does not change with the number of processors, so J seemed like the next logical place to look.
Thanks as always,
Tucker
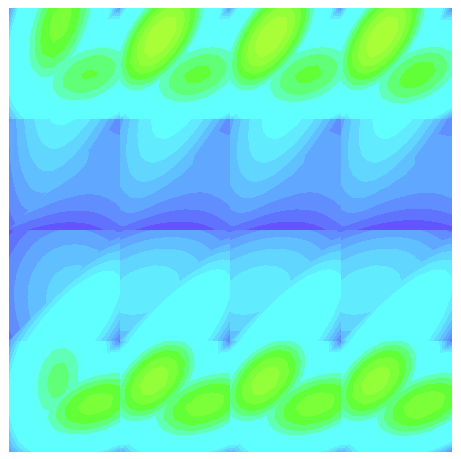
(one proc. top view)
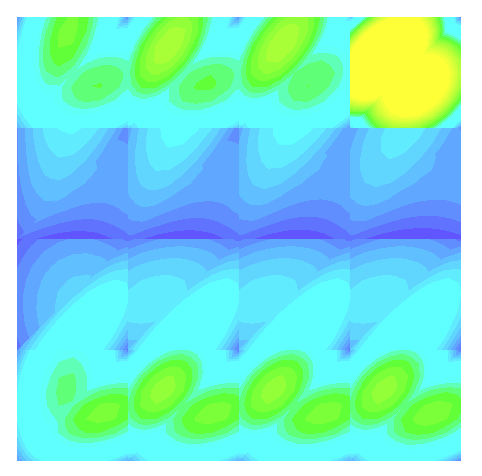
(two proc. top view)
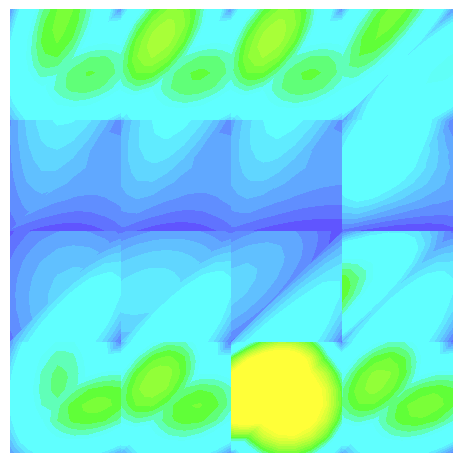
(four proc. top view)
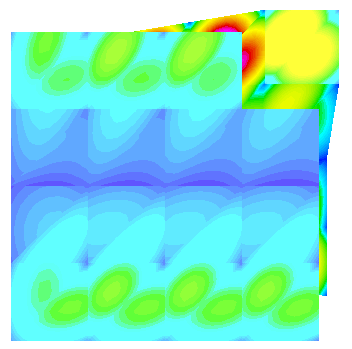
(two proc. exploded along process boundary)
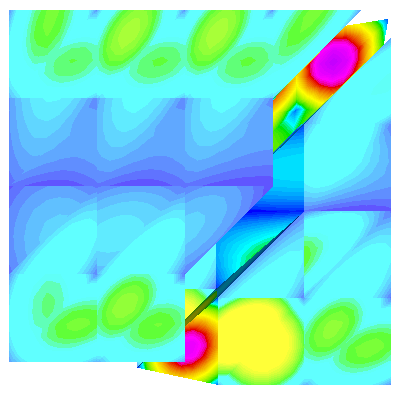
(four proc. exploded along process boundary)
MWE:
#include <iostream>
#include <fstream>
#include <mpi.h>
#include "mfem.hpp"
#include "pfem_extras.hpp"
using namespace mfem;
int main(int argc, char **argv)
{
MPI_Init(&argc, &argv);
int nranks, rank;
MPI_Comm comm = MPI_COMM_WORLD;
MPI_Comm_size(MPI_COMM_WORLD, &nranks);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
int order = 2;
int nedges = 4;
Mesh smesh(nedges, nedges, nedges,
Element::TETRAHEDRON, true /* gen. edges */,
1.0, 1.0, 1.0, true);
ParMesh mesh(comm, smesh);
mesh.ReorientTetMesh();
int dim = mesh.Dimension();
H1_FECollection h1_fec(order, dim, 1);
ND_FECollection nd_fec(order, dim, 1);
ParFiniteElementSpace h1_fes(&mesh, &h1_fec);
ParFiniteElementSpace nd_fes(&mesh, &nd_fec);
Array<int> ess_bdr(nd_fes.GetMesh()->bdr_attributes.Max());
ess_bdr = 1;
/// norm of regular grid function does not vary with proc. count
{
ParGridFunction u(&nd_fes);
VectorFunctionCoefficient current_coeff(dim, [](const Vector &x, Vector &J)
{
J = 0.0;
auto y = x(1) - 0.5;
J(2) = -6*y;
});
u.ProjectCoefficient(current_coeff);
auto *u_true = u.GetTrueDofs();
std::cout.precision(16);
auto unorm = std::sqrt(InnerProduct(comm, *u_true, *u_true));
if (rank == 0)
std::cout << "norm u: " << unorm << "\n";
delete u_true;
}
/// assemble J in H(curl)
{
VectorFunctionCoefficient current_coeff(dim, [](const Vector &x, Vector &J)
{
J = 0.0;
auto y = x(1) - 0.5;
J(2) = -6*y;
});
/// get int rule (approach followed my MFEM Tesla Miniapp)
int irOrder = h1_fes.GetElementTransformation(0)->OrderW()
+ 2 * order;
int geom = h1_fes.GetFE(0)->GetGeomType();
const IntegrationRule *ir = &IntRules.Get(geom, irOrder);
/// Create a H(curl) mass matrix for integrating grid functions
BilinearFormIntegrator *h_curl_mass_integ = new VectorFEMassIntegrator;
h_curl_mass_integ->SetIntRule(ir);
ParBilinearForm h_curl_mass(&nd_fes);
h_curl_mass.AddDomainIntegrator(h_curl_mass_integ);
// assemble mass matrix
h_curl_mass.Assemble();
h_curl_mass.Finalize();
ParLinearForm J(&nd_fes);
J.AddDomainIntegrator(new VectorFEDomainLFIntegrator(current_coeff));
J.Assemble();
ParGridFunction j(&nd_fes);
j.ProjectCoefficient(current_coeff);
{
HypreParMatrix M;
Vector X, RHS;
Array<int> ess_tdof_list;
h_curl_mass.FormLinearSystem(ess_tdof_list, j, J, M, X, RHS);
if (rank == 0)
std::cout << "solving for J in H(curl)\n";
HypreBoomerAMG amg(M);
amg.SetPrintLevel(0);
HypreGMRES gmres(M);
gmres.SetTol(1e-12);
gmres.SetMaxIter(200);
gmres.SetPrintLevel(0);
gmres.SetPreconditioner(amg);
gmres.Mult(RHS, X);
h_curl_mass.RecoverFEMSolution(X, J, j);
}
h_curl_mass.Assemble();
h_curl_mass.Finalize();
/// compute the divergence free current source
auto div_free_proj = mfem::common::DivergenceFreeProjector(h1_fes, nd_fes,
irOrder, NULL, NULL, NULL);
// Compute the discretely divergence-free portion of j
ParGridFunction div_free_current_vec(&nd_fes);
div_free_current_vec = 0.0;
div_free_proj.Mult(j, div_free_current_vec);
ParGridFunction load(&nd_fes);
load = 0.0;
h_curl_mass.AddMult(div_free_current_vec, load);
auto *load_true = load.GetTrueDofs();
auto load_norm = std::sqrt(InnerProduct(comm, *load_true, *load_true));
if (rank == 0)
std::cout << "norm load: " << load_norm << "\n";
{
socketstream sout;
char vishost[] = "localhost";
int visport = 19916;
sout.open(vishost, visport);
sout << "parallel " << nranks << " " << rank << std::endl;
int good = sout.good(), all_good;
MPI_Allreduce(&good, &all_good, 1, MPI_INT, MPI_MIN, mesh.GetComm());
if (!all_good)
{
sout.close();
if (rank == 0)
{
std::cout << "Unable to connect to GLVis server at "
<< vishost << ':' << visport << std::endl;
std::cout << "GLVis visualization disabled.\n";
}
}
else
{
sout.precision(10);
sout << "solution\n" << mesh << load;
sout << "pause\n";
sout << std::flush;
if (rank == 0)
{
std::cout << "GLVis visualization paused."
<< " Press space (in the GLVis window) to resume it.\n";
}
}
}
delete load_true;
}
MPI_Finalize();
return 0;
}
 tuckerbabcock
tuckerbabcock
All 4 comments
Hi, @tuckerbabcock ,
There are two issues here.
First, using the inner product in this way produces nonintuitive results. It is not surprising that a 2nd order Nedelec field would have different discrete norms on a mesh with triangular faces. The reason is that the orientation of the faces is determined by the order in which the elements are processed and when the processor layout changes this order changes. This matters because the Nedelec degrees of freedom for the interior of a triangular face are determined by projecting a vector function onto a pair of tangent vectors which act as basis vectors for the tetrahedron. In reference space these tangent vectors are orthogonal but they are not orthogonal in physical space (this is unique to tetrahedra and wedges). So, the code is projecting your current_coeff onto different non-orthogonal basis vectors and therefore producing degrees of freedom with quite different values. For example, the basis vectors for a particular face could be (1,0) and (0,1) in serial but (-1/sqrt(2), 1/sqrt(2)) and (-1,0) in parallel. If we use u.ComputeL2Error(zero_coeff) (where zero_coeff returns the vector (0,0,0)) we should see that this norm does not change considerably.
The second issue is also a subtle one. You are visualizing a ParGridFunction called load but this is not in fact a grid function. The way it's computed, by multiplying a ParGridFunction by a ParBilinearForm, it is actually a ParLinearForm. Such objects cannot be visualized in this manner. ParGridFunction objects contain all of the degrees of freedom for all local elements. In parallel this means that ParGridFunction objects contain duplicated entries along processor boundaries. These duplicates allow MFEM to interpolate field values within all local elements without needed to communicate with neighboring processors. On the other hand ParLinearForm objects do not contain duplicated information they contain partial information along processor boundaries. The reason for this is that degrees of freedom which are shared between processors correspond to finite element basis functions which are non-zero in elements on both sides of the processor boundary. ParBilinearForms and ParLinearForms contain integrals of finite element basis functions but in parallel they can only compute those integrals within the local elements. This means that the entries contained in ParBilinearForm and ParLinearForm objects are incomplete because they have not been summed with their counterparts on neighboring processors. So, when your program computes h_curl_mass.AddMult(div_free_current_vec, load); it is only computing the local portion of this product. To compute the full product you need to sum contributions from neighboring processors using ParLinearForm::ParallelAssemble().
This failure to sum contributions from neighboring processors explains why your GLVis output looks odd. If we treat a ParLinearForm as a ParGridFunction and pass it to GLVis this summation never takes place. GLVis assumes that the local ParGridFunction contains everything it needs to interpolate the field values so it just ignores the values from neighboring processors and build an interpolation using the incomplete data. In serial there is no incomplete data because all of the integrals could be completed locally.
To avoid such problems I've tried to maintain the habit of using ParGridFunction and ParLinearForm objects in their proper roles whenever possible rather than using Vector objects. The fact that MFEM allows the use of Vector objects for so many operations where ParGridFunction or ParLinearForm objects are more proper can easily lead to tricky problems like this and may be at the root of the problem in your main application.
Best wishes,
Mark
 mlstowell
on 1 Dec 2020
mlstowell
on 1 Dec 2020
Hi @mlstowell, thanks for taking the time to look at this and reply to me. I'm interpreting your first point to be that while the norm of the load vector does appear to change, it's because I'm taking a discrete norm instead of an integrated norm? And if I used an integrated norm the results would be more similar?
For the second point, I take it that it would be more appropriate to change the definition and use of load from
ParGridFunction load(&nd_fes);
load = 0.0;
h_curl_mass.AddMult(div_free_current_vec, load);
to
ParLinearForm load(&nd_fes);
load = 0.0;
h_curl_mass.AddMult(div_free_current_vec, load);
If that is the case, I was thinking it would be beneficial to others if in the Tesla miniapp jd_ was a ParLinearForm instead of a ParGridFunction, but after taking a look at it just now it seems more consistent to pass GridFunctions to the FormLinearSystem functions, and those functions handle the parallel cases, so perhaps a change there is not necessary.
Please let me know if I'm interpreting your comments correctly, and if switching the load vector to a ParLinearForm would be an appropriate way to move forward.
Thanks for your help as always,
Tucker
tuckerbabcock
on 15 Dec 2020
:warning: This issue or PR has been automatically marked as stale because it has not had any activity in the last month. If no activity occurs in the next week, it will be automatically closed. Thank you for your contributions.
![stale[bot] picture](https://avatars.githubusercontent.com/in/1724?v=4&s=40) stale[bot]
on 15 Jan 2021
stale[bot]
on 15 Jan 2021
I'll close this for now since other things have come up and I haven't been able to look at this in a while, but I'll reopen if/when I need. Thank you for your help @mlstowell.
tuckerbabcock
on 21 Jan 2021
Related issues
 kolotinsky1998
·
4Comments
kolotinsky1998
·
4Comments
 samanseifi
·
4Comments
samanseifi
·
4Comments
 thorvath12
·
3Comments
thorvath12
·
3Comments
 brightzhang91
·
4Comments
brightzhang91
·
4Comments
 ztdepztdep
·
3Comments
ztdepztdep
·
3Comments
Most helpful comment
Hi, @tuckerbabcock ,
There are two issues here.
First, using the inner product in this way produces nonintuitive results. It is not surprising that a 2nd order Nedelec field would have different discrete norms on a mesh with triangular faces. The reason is that the orientation of the faces is determined by the order in which the elements are processed and when the processor layout changes this order changes. This matters because the Nedelec degrees of freedom for the interior of a triangular face are determined by projecting a vector function onto a pair of tangent vectors which act as basis vectors for the tetrahedron. In reference space these tangent vectors are orthogonal but they are not orthogonal in physical space (this is unique to tetrahedra and wedges). So, the code is projecting your
current_coeffonto different non-orthogonal basis vectors and therefore producing degrees of freedom with quite different values. For example, the basis vectors for a particular face could be (1,0) and (0,1) in serial but (-1/sqrt(2), 1/sqrt(2)) and (-1,0) in parallel. If we useu.ComputeL2Error(zero_coeff)(wherezero_coeffreturns the vector (0,0,0)) we should see that this norm does not change considerably.The second issue is also a subtle one. You are visualizing a
ParGridFunctioncalledloadbut this is not in fact a grid function. The way it's computed, by multiplying aParGridFunctionby aParBilinearForm, it is actually aParLinearForm. Such objects cannot be visualized in this manner.ParGridFunctionobjects contain all of the degrees of freedom for all local elements. In parallel this means thatParGridFunctionobjects contain duplicated entries along processor boundaries. These duplicates allow MFEM to interpolate field values within all local elements without needed to communicate with neighboring processors. On the other handParLinearFormobjects do not contain duplicated information they contain partial information along processor boundaries. The reason for this is that degrees of freedom which are shared between processors correspond to finite element basis functions which are non-zero in elements on both sides of the processor boundary.ParBilinearFormsandParLinearFormscontain integrals of finite element basis functions but in parallel they can only compute those integrals within the local elements. This means that the entries contained inParBilinearFormandParLinearFormobjects are incomplete because they have not been summed with their counterparts on neighboring processors. So, when your program computesh_curl_mass.AddMult(div_free_current_vec, load);it is only computing the local portion of this product. To compute the full product you need to sum contributions from neighboring processors usingParLinearForm::ParallelAssemble().This failure to sum contributions from neighboring processors explains why your GLVis output looks odd. If we treat a
ParLinearFormas aParGridFunctionand pass it to GLVis this summation never takes place. GLVis assumes that the localParGridFunctioncontains everything it needs to interpolate the field values so it just ignores the values from neighboring processors and build an interpolation using the incomplete data. In serial there is no incomplete data because all of the integrals could be completed locally.To avoid such problems I've tried to maintain the habit of using
ParGridFunctionandParLinearFormobjects in their proper roles whenever possible rather than usingVectorobjects. The fact that MFEM allows the use ofVectorobjects for so many operations whereParGridFunctionorParLinearFormobjects are more proper can easily lead to tricky problems like this and may be at the root of the problem in your main application.Best wishes,
Mark