Meteor-feature-requests: Use MongoDB change notifications instead of oplog with MongoDB 3.6
MongoDB 3.6 will contain an official change notifications API. Using that to observe changes should be much better than current oplog approach. We should probably implement a third (besides oplog and polling) driver to use change notifications.
 mitar
mitar
All 65 comments
The changes API uses the aggregate pipeline[¹], so it might be possible to have reactive aggregate queries in publications? That would be a huge plus.
Just imagine being able to use $graphLookup[²] and have it update automagically!
 fermuch
on 9 Aug 2017
fermuch
on 9 Aug 2017
Are MDG even interested in this any more? Seems that Apollo has taken priority.
 niallobrien
on 28 Aug 2017
niallobrien
on 28 Aug 2017
@niallobrien Apollo and Meteor are separate projects with separate developers and there is no reason that Meteor wouldn't be interested in such a feature. That being said, our resources are not unlimited and help would be appreciated in looking into this.
 abernix
on 28 Aug 2017
abernix
on 28 Aug 2017
Does "resources are not unlimited" === "we will continue to have one developer staffed on the Meteor project"?
 msavin
on 28 Aug 2017
msavin
on 28 Aug 2017
@abernix I never mentioned Meteor, I specifically mentioned MDG and if I'm not mistaken, MDG develop both Meteor and Apollo...
niallobrien
on 28 Aug 2017
As most of the best additions for meteor were implemented first as packages, I think this feature would also be best implemented first as a package, and then, when it becomes stable enough, could be integrated to the meteor core (or not).
The meteor core needs to maintain stability and backwards compatibility (meaning this driver would only be added when mongo 3.6 is the minimum version supported by meteor, and all other older versions are deprecated).
As an example, the oplog watcher was first implemented as a package, by kadira I think. After some time, meteor adopted it. Before it, we had long-polling for everything.
When Meteor adopted this driver, backwards-compatibility was ensured (no need to change your code, but if you want to use it just add MONGO_OPLOG_URL to your env).
The same is happening right now with redis-oplog. It started as a proof-of-concept, then moved very quickly in 0.x versions, and now is stabilizing and mostly fixing corner-cases.
MongoDB 3.6 isn't even released yet (AFAIK), and there is already work being done to free meteor from mongodb for those who don't want to use it (after all, this was one of the most requested features since meteor was conceived). In a few releases more, mongo will be totally optional (and this is a good thing!), so creating a package for this new mongo API makes a lot of sense, or at least it does in my conception.
EDIT: I'm not affiliated with the MDG; everything I say here is based on my observations I've seen meteor had in the past.
fermuch
on 29 Aug 2017
meaning this driver would only be added when mongo 3.6 is the minimum version supported by meteor, and all other older versions are deprecated
Not true. Meteor already has support both for oplog and long polling. This would be just one extra approach and if Meteor is running on 3.6 it could be used, otherwise it could degrade to oplog.
mitar
on 29 Aug 2017
meaning this driver would only be added when mongo 3.6 is the minimum version supported by meteor, and all other older versions are deprecated
Not true. Meteor already has support both for oplog and long polling. This would be just one extra approach and if Meteor is running on 3.6 it could be used, otherwise it could degrade to oplog.
As far as I've seen, this approach would need you to write a query to the aggregation pipeline[¹], which is currently not supported by meteor (you need to access the raw collection to use it) and is not compatible with the oplog driver.
How would a backwards-compatible driver work?
I can imagine adding aggregation support to the long-polling driver, but I can't see how it would work with the oplog.
fermuch
on 29 Aug 2017
I think you are confusing things here. This is a completely new API which also supports using aggregation pipeline API as a way to select which notifications you care about. The point is that you do not have to "oplog observe" the "notification aggregation pipeline" to get notifications. You simply use MongoDB driver to say "hey, inform me of any notifications on this collection, and apply those aggregation pipeline operations on top of notification documents before that". So, in the same way as oplog driver currently connects to the MongoDB oplog, change notifications driver would connect to change notifications. The fact that the latter is using internally aggregation pipeline syntax does not matter.
So this is orthogonal question to a question of support of aggregation pipelines in Meteor.
mitar
on 29 Aug 2017
If there is one person who can pull this off while making it look trivial, it's @theodorDiaconu. He already has extensive knowledge of how LiveQuery works.
msavin
on 29 Aug 2017
Just a quick reminder to all here - we can't really even start to think about supporting Mongo 3.6 until https://github.com/meteor/meteor-feature-requests/issues/152 has been addressed. There's quite a bit of work involved in dropping Meteor's 32-bit support, but it has to happen before we can jump to Mongo >= 3.4. So while Mongo 3.6's change notifications API definitely looks interesting, and will likely be awesome with Meteor, there is still a lot of less exciting work that needs to be accomplished to get Meteor ready for newer Mongo versions.
 hwillson
on 5 Sep 2017
hwillson
on 5 Sep 2017
What do you folks think Meteor developers could expect if this functionality were integrated? It looks to like it can be a cleaner way to consume changes compared to oplog - we can observe specific events instead of all of them - but it looks like it would still have the same issue with overloading servers. Perhaps the redis-oplog is still the right way to go about this.
msavin
on 29 Sep 2017
@msavin As far as I understand, the overload comes from processing each and every message in the OPLOG, instead of only what's really needed. With the changes notifications, only messages for currently active subscriptions would be watched, so why would it be the same?
In my mind, this would happen:
- User A subscribes to
itemsInStockon Server B - Server B creates a changes consumer and watches for User A's updates, notifying her if an item is added/removed/updated.
So when User A disconnects or stops the subscription, the watcher for Server B on itemsInStock can be deleted.
fermuch
on 29 Sep 2017
@msavin
I've tried the redis-oplog, even thought I like it there was two bugs:
- Not considerting SimpleSchema options (I fixed)
- Some mutations, even thought processed in the server were not being pushed to the client.
So I still prefer to use a MongoDB-only solution.
The problem with overloading the server as far as I understand is:
- We have to read every single change.
- Every instance has to do the same
With the notifications API I think we can listen to changes for the things we care (Publications cursors) and it could be implemented in a way that only the server that needs it receives the changes (I think by default this would be the way to go).
To make it perfect, we could add a way to manipulate the notifications API when creating the cursor.
With these, we will have no overloading (more than what you need) and full control of reactivity, even disabling it (which will be great to still use publications but do not track changes in the documents nor update them).
 raphaelarias
on 3 Oct 2017
raphaelarias
on 3 Oct 2017
By the way, I would like to help in the efforts to bring the notifications API to Meteor.
raphaelarias
on 3 Oct 2017
@raphaelarias do you have a bug submitted for Some mutations, even thought processed in the server were not being pushed to the client. ?
Now let's go back to Notifications API:
https://dzone.com/articles/new-driver-features-for-mongodb-36#notification-api
It's a very nice API and it will solve SOME of the big problems (bandwidth
It still does not allow what RedisOplog can do:
- Ability to trigger reactive events without persisting data (like the example of when someone is typing in a message and you want to tell that to the other party)
- Ability to make mutations that should not trigger reactivity
- Merge incoming changes into a single message (When you have 100 subscribers on the same collection on the same instance, you will receive 100 change notifications)
In terms of scalability, using a middleware like Redis is the way to go.
 theodorDiaconu
on 4 Oct 2017
theodorDiaconu
on 4 Oct 2017
@theodorDiaconu Yes, but I haven't investigated further to help understand what happened, as I'm not using RedisOplog anymore.
The thing is, to use RedisOplog add another point of failure (another DB and another package that you may not be able to maintain), so if notifications API can replace it, I'm on board.
Ability to trigger reactive events without persisting data (like the example of when someone is typing in a message and you want to tell that to the other party)
It does not solve, and as far as I understand it may be difficult to change how meteor works to natively support it. But with less bandwidth and CPU usage this may be less of a problem, isn't it?Ability to make mutations that should not trigger reactivity
If, when implemented, we can pass options, or control the notifications API, logic dictates that we can deactivate reactivy.Merge incoming changes into a single message (When you have 100 subscribers on the same collection on the same instance, you will receive 100 change notifications)
Doesn't Meteor reuse subscriptions to optimise the pub/sub? If that's the case and we can apply (using notifications API) filters and mutations to it, done. So we may not receive 100 change notifications.
raphaelarias
on 4 Oct 2017
I just found the documentation - its being called "Change Streams"
@fermuch Nice - it looks like that can work:
Change streams provide a way to watch changes to documents in a collection.
However, I do wonder if this is intended to target a collection or individual groups of documents. If the latter, and it could power LiveQuery, I would probably use Meteor forever.
@raphaelarias I'm on the same boat in regards to vendor support. If Redis-Oplog were a commercial offering, I might have more faith in it, but looking at what happened with most of the third party things here, it seems like a risky bet.
@theodorDiaconu I also think Redis has a place in Meteor, in fact, much of Redis marketing demonstrates how good of a combination it is with MongoDB. However, I am not sold that RedisOplog would be as reliable as LiveQuery is today. (Reliable means many things here.)
Maybe the right solution is to have a Redis package that works independently to MongoDB, and integrates well with Meteor's pub/sub system.
msavin
on 4 Oct 2017
If Redis-Oplog were a commercial offering, I might have more faith in it, but looking at what happened with most of the third party things here, it seems like a risky bet.
I second that too. Especially that redisOplog is a big package. When something breaks in a small package (e.g. oauth packages) we can fix in no time. But this is a complex beast!
@theodorDiaconu we had discussed this in the past. I really think you should look into a commercial license for redisOplog (what's $99 / year for a production app!). Maybe a short survey on the Meteor forum to see who is interested in it could be a starting point.
PS: Sorry for hijacking this post
 ramezrafla
on 5 Oct 2017
ramezrafla
on 5 Oct 2017
I would probably pay.
On 5 Oct 2017, at 4:49 pm, Ramez Rafla <[email protected]notifications@github.com> wrote:
If Redis-Oplog were a commercial offering, I might have more faith in it, but looking at what happened with most of the third party things here, it seems like a risky bet.
I second that too. Especially that redisOplog is a big package. When something breaks in a small package (e.g. oauth packages) we can fix in no time. But this is a complex beast!
@theodorDiaconuhttps://github.com/theodordiaconu we had discussed this in the past. I really think you should look into a commercial license for redisOplog (what's $99 / year for a production app!). Maybe a short survey on the Meteor forum to see who is interested in it could be a starting point.
PS: Sorry for hijacking this post
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHubhttps://github.com/meteor/meteor-feature-requests/issues/158#issuecomment-334365717, or mute the threadhttps://github.com/notifications/unsubscribe-auth/AExrJn0ro3oQn01Kr8u3s38Uq6WESphlks5spG3ggaJpZM4Ohy_i.
raphaelarias
on 5 Oct 2017
I guess adding an option where Meteor "ignores" changes within the database is really needed when the Mongo API gets added to the core. In our example case we've removed about 100k chat messages per day to clean our database. This killed our Meteor app with enabled oplog. We've moved to redis-oplog and can now control which updates are processed by Meteor and which not.
 dnish
on 5 Oct 2017
dnish
on 5 Oct 2017
Thanks @ramezrafla and @msavin for the ideas. Don't worry I won't let RedisOplog die. Will start investing time again in it and Grapher.
@raphaelarias
The thing is, to use RedisOplog add another point of failure (another DB and another package that you may not be able to maintain), so if notifications API can replace it, I'm on board.
There are certain key concepts here:
- Redis Oplog is fully BC so adding it/removing it is done via a simple configuration
- As you scale you cannot avoid splitting in your app in microservices and using different type of databases that satisfy different needs: Searching, Big Data Analytics. Hence, adding "point of failures". RedisOplog was never intended for 100-200 online users.
theodorDiaconu
on 5 Oct 2017
+1 for paid package - especially if that can pave the way for more features like performance monitoring and so on
@theodorDiaconu can you please clarify what you mean with "RedisOplog was never intended for 100-200 online users"
msavin
on 5 Oct 2017
@msavin I guess he means that this package was not made for "small apps", because they won't need it. I would also love to pay for it if it gets maintained. This really saved one of our chat applications which generates revenue, so it would be fair to "pay you back".
dnish
on 5 Oct 2017
@theodorDiaconu maybe create an open collective: http://opencollective.com/ And then companies can be backers.
mitar
on 5 Oct 2017
I'd be willing to help brand it, build a site, etc. Check out this branding idea :D
https://forums.meteor.com/t/meteor-scaling-redis-oplog-status-prod-ready/30855/263
I actually started some work on it but didn't want to be too pushy 😄
I know you want to keep it open source, but you can do paid open source with really lenient licensing. "The package is yours forever, but if you use it you have to send money to X." I believe that is much healthier for both sides.
You can take a look at BotPress as one example. They are open source but if you go above X operations or whatever you are expected to pay for it.
msavin
on 5 Oct 2017
BUT - to bring it back to the original discussion, maybe the right solution is to use Redis for simple things that need to be really fast - like indicating that someone is typing during a chat - and using MongoDB + Change Streams for the rest.
I've noticed that MongoDB doesn't always write reliably - or it may take a while - so using Change Streams feels more reliable. If I understand correctly, RedisOplog assumes that the write happened right away, and I could see that causing some discrepancies, especially in collaborative apps.
msavin
on 5 Oct 2017
@msavin it is not intended for small apps, you won't benefit too much from it's performance.
@mitar I will do that, create a roadmap, and get a bit of budget.
Ok guys, I will start this project to bring redis-oplog to it's deserved form, @msavin I've sent you an email with my Skype id, so we can brainstorm a bit the "branding" part.
I think there can be a way to use ChangeStreams and RedisOplog together. I'll be waiting for their driver to mature to even begin thinking about such merge.
On topic:
Their driver needs to be very smart to do the "merging" of streams. So that if you have 100 listeners for a change (with diff fields) on a collection, to receive only one message with all the info you need from the db, instead of 100.
Oplog is doing this in the sense that tailing the oplog is done via one channel.
theodorDiaconu
on 6 Oct 2017
@theodorDiaconu I agree. But the way it is right now I cannot trust the app and run my SaaS on it. It's a very sensitive, important and intricate area to leave a package run by itself without any kind of ongoing development and/or support.
We don't use very advanced things regarding pub/sub, and still, it was not a drop-in replacement, as I pointed out before.
In any way. I would use a paid version, but I think we should use Change Streams API as much as possible, to keep it simple. And then more advanced features or complements we use Redis.
So, if you can merge both, awesome. To do that Meteor needs to have a first-class (ideally) support for notifications API, otherwise it will have to hack it's way into it.
TL;DR: I would love a fully-supported redis-oplog and an awesome, open and flexible Change Streams API for Mongo. That's why I would like to help to bring this to life.
raphaelarias
on 8 Oct 2017
Change Streams would bring absolute performance to our scaling problem, one use case:
Given a publication for collection "users" that contains some filters, limit and optionally skip options.
In order to make sure that the image on the client is the correct one we have to listen to all updates inserts and removes on "users" collection. Given the scenario that "users" collection changes a lot, the watcher from Redis is still going to be bombarded. (Let's call this a FLS query)
Now, given Change Streams, and watching a FLS query at DB level, the only changes that come to the callback are the ones for that cursor only. Which solves a very important problem that even RedisOplog doesn't currently solve completely. It requires additional use of channels and namespaces, which works great, but ChangeStreams would solve it better.
Why RedisOplog and ChangeStreams are two different beasts ?
With RedisOplog, changes are sent out to Redis. With ChangeStreams, there's no need to send changes anywhere. This is why the two, can't be properly merged together.
RedisOplog Advantages
- Redis is a beast in what it does, it's very performant, with ChangeStreams, the CPU of the database will increase by a lot. But the DB can scale, so this is not a decisive factor.
- Synthetic Mutations (emulate changes that aren't saved in the database)
- "Silent" Mutations (that do not trigger reactivity)
ChangeStreams Advantages
- Reactivity at the database level means one less point of failure
- Solves the problem of FLS queries
- Easy to implement, given the changes processor is handled at Mongo level. Less prone to errors
- Faster reactivity since you don't need an additional system to talk changes.
Conclusion
RedisOplog is a temporary solution until ChangeStreams comes to the mongodb node driver. The story behind it was noble, I've invested a lot of time in it, we managed to solve an important issue of Meteor, but the sad(or happy) reality is that once Notifications API comes to life, that is it, that is the way to go. It's the same thing they did with Blaze, it is a beautiful engine, it solves elegantly lots of problems, but React won, I am agnostic.
@raphaelarias @msavin @ramezrafla
At this stage, investing in marketing is futile. If someone needs to scale fast, I can offer Premium Support to them and make sure the system is bug free and working flawlessly, until NotificationsAPI gets implemented.
theodorDiaconu
on 9 Oct 2017
Agreed, thanks @theodorDiaconu for taking leadership with Redis-oplog. We need to keep innovating and that's how we keep progressing. Some technology sticks, some doesn't, but the experience, reputation, and pedigree remain.
Disclaimer: haven't yet looked at changeStreams, taking at face value
ramezrafla
on 9 Oct 2017
According to this comment change streams has been implemented in 3.5.x release (just few days ago). I've been playing with 3.6.0-rc0 and it works really nice! I'm thinking of creating PoC replacement for oplog driver and comparing peformance of these two once I find some time.
 mpowaga
on 13 Oct 2017
mpowaga
on 13 Oct 2017
Awesome. We can soon start testing the new Change Streams API. Just as a reminder, for a wider release, there is still this issue to be closed: #152
raphaelarias
on 16 Oct 2017
I've started to work on a Change Stream observe driver prototype last week but it turned out to be more challenging than the announcement blog post [1] suggested. :sweat_smile: There isn't much official documentation yet but the API specification [2], the talk "Using Change Streams to Keep Up with Your Data" [3], and the code of the Node.js driver [4] are good starting points if you want to learn more about Change Streams.
Here's what I found out:
Change Streams cannot be used to watch cursors. Think of them more as an API that is similar to the oplog but with some additional features, such as filtering changes using queries. Unfortunately, they don't provide the same real-time capabilities as RethinkDB or Firebase. I think that an implementation of Meteor's observe driver using Change Streams would be very similar to RedisOplog, with similar limitations.
Let's take a look at some examples that show why using Change Streams with Meteor is not that simple:
Query by _id
If documents are queried by _id (or multiple _ids with $in), Change Streams can be used very efficiently because they can filter out all changes to other documents. For example, the query
Documents.find('<_id>');
would initiate the following Change Stream in the observe driver:
collection.watch([{
$match: { 'documentKey._id': '<_id>' }
}]);
By listening to all changes to the matched document, the server will only get notified if this document is updated or removed and can send the updates along to its connected clients.
Query by Arbitrary Fields
Unfortunately, querying by arbitrary fields (and perhaps using skip and limit) makes tracking changes a lot more complicated (that's what @theodorDiaconu describes as FLS queries in https://github.com/meteor/meteor-feature-requests/issues/158#issuecomment-335084684). For example, the query
Documents.find({ someField: '<some value>' });
requires that the observe driver maintains a set of matched document _ids. Otherwise, it couldn't notify its clients if a new document joins the set (as a result of an update) or leaves the set (as a result of a remove or an update). Just using one Change Stream as in the first example doesn't work here because the observe driver would miss important updates. For example, if a client wants to display a list of all tasks that aren't done yet, it would query todos documents like this:
Todos.find({ done: false });
The associated Change Stream would filter out documents whose done field isn't false:
Todos.watch([{
$match: { 'fullDocument.done': false }
}]);
However, if the done field of one of the matched documents is changed to true, the server will never be notified of that change because the document doesn't match anymore! A trivial solution for this problem would be to just watch all changes, including the inverse of the query, but that wouldn't be an improvement over the current oplog tailing approach.
Change Stream Use Cases
The key difference between these two cases is the immutability of the queried field. Since _ids never change, documents cannot enter or leave the set of matched documents when they are updated. Matching on changing fields is not a use case that Change Streams were designed for (if the application wants to maintain state about the documents, which is the case for Meteor). [3, 18:45]
It's possible to match on unchanging fields other than _id (e.g., an authorId of a blog post document). However, it depends on the application if a field is immutable or not, so Meteor cannot assume immutablility for fields other than _id.
Performance
There are also some performance-related things to keep in mind:
- Using the database instead of the server to check if relevant fields of a document have changed can impact the performance of other database operations. The goal for MongoDB is to support 1000 simultaneous Change Streams per
mongodprocess without impacting performance. [3, 7:40 and 29:13] - Documents that are matched by more than one Change Stream are sent to the server multiple times, which could increase traffic between the database and the server if overlap between Change Streams isn't kept as small as possible (for example, by reusing them for identical queries).
References
[1] [Blog: New Driver Features for MongoDB 3.6](https://dzone.com/articles/new-driver-features-for-mongodb-36#notification-api)
[2] [Change Streams API specification](https://github.com/mongodb/specifications/blob/master/source/change-streams.rst)
[3] [Video: Using Change Streams to Keep Up with Your Data](https://explore.mongodb.com/mongodb-local-san-francisco/using-change-streams-to-keep-up-with-your-data)
[4] [3.0.0 branch of node-mongodb-native](https://github.com/mongodb/node-mongodb-native/tree/3.0.0)
 klaussner
on 25 Oct 2017
klaussner
on 25 Oct 2017
The key difference between these two cases is the immutability of the queried field. Since _ids never change, documents cannot enter or leave the set of matched documents when they are updated. Matching on changing fields is not a use case that Change Streams were designed for. [3, 18:45]
This statement right here just brought the life back to RedisOplog.
They never specified this in their docs. Oh well, time to announce the resurrection.
@msavin @ramezrafla @raphaelarias it seems that the mission hasn't ended yet.
theodorDiaconu
on 25 Oct 2017
So basically the Change Stream API only return events pertaining to the subset of the document that satisfies the match condition and if a document field change that invalidate the match criteria (mutable query field) then no event will be generated. Is that correct?
Assuming the API returns an event when a document no longer meet the match condition, then would that solve this limitation? or are there any other major imitation that you've observed?
 aogaili
on 25 Oct 2017
aogaili
on 25 Oct 2017
Change Streams are just watching oplog and return matching entries. Perhaps biggest performance gain is thanks to fullDocument option which can reduce mongo lookups.
Another limitation is that Change Streams can be used only when mongo server is running with --enableMajorityReadConcern option which requires WiredTiger storage.
mpowaga
on 25 Oct 2017
The goal for MongoDB is to support 1000 simultaneous Change Streams per mongod process without impacting performance.
Hm, this is also a pretty low limit, wouldn't people agree?
Assuming the API returns an event when a document no longer meet the match condition
I think we should report this upstream.
Thank you @klaussner for looking into this!
mitar
on 25 Oct 2017
mitar
on 25 Oct 2017
The goal for MongoDB is to support 1000 simultaneous Change Streams per mongod process without impacting performance.
Documents that are matched by more than one Change Stream are sent to the server multiple times, which could increase traffic between the database and the server if overlap between watchers isn't kept as small as possible (for example, by reusing watchers for identical queries).
Looks like in some cases oplog tailing would be more performant than Change Streams.
mpowaga
on 25 Oct 2017
Maybe we need to forget about making all the things realtime like with oplog, and instead focus on creating a solution that aligns with MongoDB Change Streams and/or Redis?
For example, with Meteor today, subscribing to just one document in a collection is most efficient - and maybe we should move on from "massive" subscriptions.
msavin
on 25 Oct 2017
@mpowaga We are getting rid of the need for the startup option of --enableMajorityReadConcern in MongoDB 3.6 by making readConcern:Majority always available on every mongod.
 atcabral
on 26 Oct 2017
atcabral
on 26 Oct 2017
To continue on the previous comment, my understanding is that:
- subscribing to just one document is way more efficient than subscribing to multiple documents
- getting multiple documents over a method is way faster than using a subscription.
If I were building a Meteor app today, I would probably use methods for big data sets and subscriptions to get one document at a time, for what I would call a reactive object. If we were to agree that this is the right approach, perhaps we should focus on creating a "LiveObject" package instead of replacing LiveQuery.
LiveObject can be powered by Redis (which supports persistent storage) or (I think) with MongoDB and ChangeStreams. It would essentially be one document stored in MongoDB or a JSON object stored in Redis. It can also used with Tracker to "trigger" a method call to reload static data when needed.
In the end, we can have:
- LiveQuery (via oplog)
- LiveObject (via redis or mongo)
- Static data (via methods)
As for scaling oplog, I'm not sure how reasonable it is. RethinkDB tried to make a real time database but it looks like it had limitations, and it looks like MDG abandoned it completely.
I think oplog tailing will always be great for small-medium custom apps, and maybe that's all it needs to be. Or perhaps, we should try to implement a scalable LiveObject solution before trying something far more complicated.
If there's interest, I can do my part by creating a page and spec for it.
Edit: Maybe a better name is LiveDocument, and it could be implemented on subscriptions that use findOne instead of find.
msavin
on 27 Oct 2017
RethinkDB tried to make a real time database but it looks like it had limitations, and it looks like MDG abandoned it completely.
Perhaps it's time to re-open the discussion RE: RethinkDB?
 s-devaney
on 29 Oct 2017
s-devaney
on 29 Oct 2017
@s-devaney I think that thing is on life support. Last I checked, it had a lot of issues, but I could be wrong. MongoDB and Redis look very healthy in comparison.
I just opened up a discussion focusing on the limited use case of Change Streams. It would be great to get everyone's opinion in there:
https://forums.meteor.com/t/implementing-livedocument-as-an-alternative-to-livequery-discussion/40152/1
msavin
on 29 Oct 2017
Interesting quote from MDG:
“Including id in queries can also help improve scaling when using oplog tailing. In general, running queries on id will be faster and have more predictable performance. If it is possible to rework your schema so that _ids are used more extensively, especially on hot collections, you may able to get orders of magnitude improvement in performance.”
Change Streams and Meteor are an amazing fit. Subscribing by _id is the most efficient way to use Pub/Sub, and it's exactly what Change Streams supports.
msavin
on 31 Oct 2017
@msavin In my experience, it's often impossible to restructure a schema (or app) so that it allows all documents to be queried by _id. To take advantage of database-level filtering with Change Streams, all queries (for a specific collection) in a container would have to use the _id field. As soon as you observe one non-_id query, the container must receive all changes* to all documents (no improvement compared to oplog tailing). Given that querying by _id is already quite fast with oplog tailing, I think that Change Streams wouldn't bring a significant performance or scalability improvement for the "query by _id" use case.
*It's possible to filter out irrelevant fields using an aggregation pipeline, so the amount of data sent per update could be reduced. However, there's a tradeoff to be made between less data sent per update and less duplication of updates.
klaussner
on 1 Nov 2017
@klaussner for queries that cannot be fulfilled by _id only, Method's could and probably should be used instead.
With that said, Change Streams would bring several benefits here:
- Ability to focus on specific collections instead of whole database
- Ability to focus in on specific fields instead of all the fields
- Ability to notify server of events not related to pub/sub
All in all, it would reduce number of events coming in from database, which might be the most important thing. Additionally, it paves the way to make things even more efficient, i.e. if we were to create Meteor microservices for specific publications.
msavin
on 1 Nov 2017
@msavin I believe it would be better to always retrieve data form the server via Pub/Sub, instead of Methods. We do use methods for non-reactive things, but the official way it is still Pub/Sub and it's more organised that way, don't you think?
It's not always possible to query by _id, specially if new documents will be added. But in any case, we still have to handle non _id queries. Would a solution be: every time we do an Insert we validated if it would be part of a Pub's query and if yes, add it to the Pub? I tend to think that solution it's not scalable.
raphaelarias
on 3 Nov 2017
We can debate it for ages, most of it comes down to your engineering choices.
Speaking for myself, I would gladly adjust my approach to designing applications to leverage subscriptions by _id and Change Streams. It would give me better scale and performance at a lower cost - it's not bad when you get 3 out of 3.
msavin
on 3 Nov 2017
Looking at my apps, I think I have many lists of documents, which I currently use pub/sub for to get reactive updates to those documents. But I think I have two cases here: reactive updates to documents in the list, and reactive updates to the list itself. I think that it looks change notifications can improve the first case quite a lot, while the second case not (yet). But the second case might be able to be solved differently. For example, through polling. I would not mind in many cases if list itself is updated every minute, while I think having stale display of documents themselves might be more problematic.
So maybe we could split this into such two cases? I think this is similar to what @msavin was proposing above with LiveQuery and LiveDocument, but I would prefer LiveQuery and LiveDocumentSet. Both could be done through pub/sub.
In a way this is how today we do reactive/composite queries in pub/sub anyway. We observe related queries and then rerun if something changes.
mitar
on 6 Nov 2017
Hi @theodorDiaconu May be this is wrong place to ask about RedisOplog. I was looking into RedisOplog how it handles bulk write and could not find any reference/document. Any idea?
 praves77
on 7 Nov 2017
praves77
on 7 Nov 2017
@praves77 if you want bulk-write without sending reactivity events, you can pass the option {pushToRedis: false} or use the rawCollection() for it. If you want to understand how it works, read the "How it works" section
theodorDiaconu
on 7 Nov 2017
I like the idea of dividing query processing between Change Steams and the Meteor server(s) but instead of handling lists and their documents differently, we could also distinguish between changing and unchanging fields.
Idea
Change Streams can be used to match on any unchanging field (not just _id). If we pass hints to find (in the options object) about which fields won't change, we can use them to create Change Streams that prefilter document changes at the database. The changes that make it past this initial filtering stage are still processed as before on the Meteor server(s) but the observers have more information about the changed documents and they receive fewer changes.
The diagram below illustrates the data flow of a document update. When the update is processed by the database, the Change Stream filters it based on an unchanging field in the document. The observer that initiated the Change Stream does the rest of the processing, i.e., match on changing fields, apply skip and limit, etc., and sends the change to its clients.
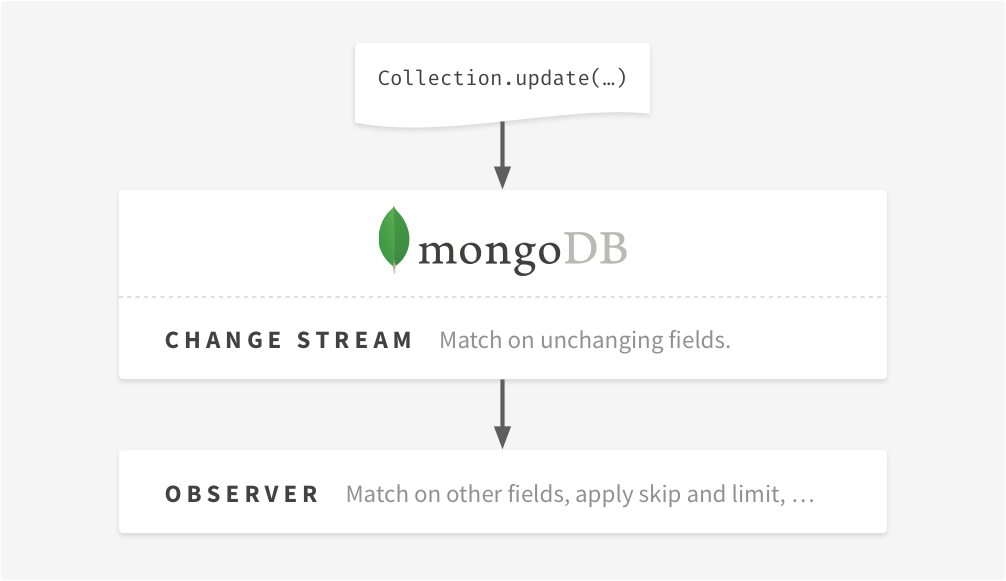
If this idea works (and if the schema contains unchanging fields suitable for filtering), it could partially solve the problem of inefficient "FLS" (field, limit, skip) queries because observers have more context about document changes, which means that they have to make fewer database queries.
Example
The following example shows the difference between oplog tailing and prefiltering with Change Streams. Let's assume we have a task list app that runs on three servers. Each task has a boolean done field, a description field, and belongs to a list via an unchanging listId field (in this example, tasks can't be moved to other lists). Each server has started some observers (labeled O1 through O6, see the diagrams below), which observe different queries:
- O3: done tasks in list
'x' - Other observers: done tasks in other lists
Query of O3:
Tasks.find({
listId: 'x',
done: true
}, {
fields: { done: 1, description: 1 }
});
Updates with Oplog Tailing
Assume that there is a task 'y' with done == false, which belongs to list 'x' (whose tasks are observed by O3). We change the done field of this task as follows:
Tasks.update('y', {
$set: { done: true }
});
With oplog tailing, each server receives that change and each observer asks the database if the changed task belongs to the list whose tasks it is observing. 🖥 🔥 The diagram below shows the data flow generated by this update. Only the green arrows represent relevant data flow, all other data flow causes unnecessary server load and/or network traffic.

Updates with Change Streams & Prefiltering
Since the listId field of a task never changes, we can modify the find call to give the observer a hint that it should create a Change Stream for it:
Tasks.find({
listId: 'x',
done: true
}, {
fields: { done: 1, description: 1 },
unchangingFields: ['listId']
});
If we run the update from the previous section with this implementation, only the server that observes tasks in list 'x' will be notified of the change! The Change Stream determines at the database which list the changed task belongs to (using fullDocument lookup) and sends the change only to server A, where it will be processed only by observer O3:

In this simple example, no unnecessary updates are sent to servers. However, more complex queries can still require servers to ask the database if a document satisfies all conditions. For example, if the query has conditions for more than one unchanging field (i.e., not just the done field in this case), the Change Stream doesn't provide enough context. Nevertheless, this should be far less of a problem since the Change Stream already filters out (potentially) lots of irrelevant changes.
Advantages
Prefiltering with Change Streams
- reduces the amount of updates sent to each server and its observers,
- doesn’t introduce new APIs,
- works similar to existing performance tuning options (
disableOplog,pollingIntervalMs, andpollingThrottleMs) and can easily be enabled if required, - allows Change Streams to be reused internally because they don't have to be query-specific.
Disadvantages
- The schema must have unchanging fields.
- To effectively reduce the number of changes arriving at each server, all queries should use the
unchangingFieldsoption, which could be problematic for third-party packages that publish data or create cursors and don't allow options to be passed tofind. - If the option isn't used by all queries, reducing overlap between Change Streams could be difficult.
klaussner
on 7 Nov 2017
I experimented with this a bit as well over the weekend. See example app here. I have not used Meteor for this experiment. My approach was to try few other directions:
- Connecting to MongoDB directly from the client. So server does not have to keep any state whatsoever.
- Use Change Stream to get notifications of changes.
I think I have found similar things reported above. It seems this can work well when making queries over read-only fields (I opened this as feature request in MongoDB).
But I worry a bit about 1000 stream per data node soft limit I have read about. So not sure how scalable is this if every query would have its own change stream. Maybe it would still be better if Meteor open only one stream per collection per node instance and process all notifications in JavaScript code, similar to how it is doing oplog now.
Also the fullDocument option in fact is not as nice as it looks. It simply makes a new query to resolve this. Which means that fullDocument value can be newer than the change.
So I am not sure how beneficial this would be to Meteor. It seems like a standard but pretty equivalent API to what we already have. So not sure what would be benefits.
BTW, I think I figured out a way to handle documents being removed from a match. You can open two change streams. One matching your query and one being a negation of your query. The latter you can project to only get _id out and nothing else. So then when a change appears in the second stream you know you have to remove it from the first. This is just me thinking, I have not tested this.
mitar
on 12 Mar 2018
On a side note, it looks like the documentation for ChangeStreams is finally live:
https://docs.mongodb.com/manual/reference/method/db.collection.watch/
msavin
on 13 Mar 2018
Copy-pasting my post from the forum:
It's possible that the concept of having 1000 Change Streams connections has been misunderstood.
Looking at the documentation, Change Streams supports $match, which means that you can specify multiple queries that would meet the requirement with-in one Change Stream. It looks to be as flexible as any MongoDB query.
It also looks like Change Steams support operationType, which lets you watch just about any operation, including insert, update, delete, etc.
I would assume that if someone wanted super scalability, it can be set up so that each server would watch only the documents it needs _id. One can also set up a second Change Stream to look for relevant inserts/removes/etc.
If correct, wouldn't this be more scalable than redis-oplog, as it can deliver updates updates specifically to the servers that require them? or does redis-oplog somehow know which servers need to updated with which data?
msavin
on 14 Mar 2018
BTW, I think I figured out a way to handle documents being removed from a match. You can open two change streams. One matching your query and one being a negation of your query. The latter you can project to only get
_idout and nothing else. So then when a change appears in the second stream you know you have to remove it from the first. This is just me thinking, I have not tested this.
This is the correct approach, but I've had issues doing this with both Meteor's standard oplog driver and change streams for a real-time trading system (small user base, but peaks of 1000's of messages a second). An actual snapshot of the document before and after a update is needed to reliably detect the negation. Unfortunately the oplog driver and change stream tend to coalesce rapid updates by the nature of how they work.
The only way I've been able to solve this is create a capped collection (kind of like Mongo's oplog) that journals the full document before doing an update on it. Since I have a separate process that converts systems binary messages into Mongo it was pretty easy to add functionality to query the collection before an update, journal it, and then do the update. This approach combined with a hack I did to allow the oplog driver to work with skip allows me to do a find on a large result set very fast while also detecting changes in the result set outside of the typical viewing scope of 25 - 100 documents (i.e. useful for stuff like tracking a total match count or detecting when to update an aggregation for a summary footer in a table).
IMO while Mongo's change stream has the potential to be a really cool feature, but I think it needs more functionality to be a revolutionary performance enhancing feature for Meteor. Right now it just seems like a cleaner and more refined version of looking at the oplog.
 mccrearyp
on 13 Sep 2018
mccrearyp
on 13 Sep 2018
Any updates on this? Seems like a key way to improve a major performance bottleneck with Meteor, but I don't see implementing MongoDB change streams in the Meteor roadmap.
 dandv
on 27 Sep 2020
dandv
on 27 Sep 2020
I know that @npvn has done some work around this.
What are your thoughts @npvn?
 StorytellerCZ
on 27 Sep 2020
StorytellerCZ
on 27 Sep 2020
Thanks @StorytellerCZ. I have been working with change streams a lot recently. I thought about the idea of having one stream opened for each Galaxy container to get all MongoDB updates, but it has one drawback: Each container has to process an inflow of all db changes, even those that no subscription client on that container is "interested" in.
I have been experimenting with the idea of having a separate Node.js server that listens to all db changes (via a change stream) and delivers these events to the appropriate containers via a namespace system (similar to the one used inside redis-oplog). I'm going to test it in production soon and if everything goes well it will be open-sourced.
I think for such a solution to be widely adopted by the community there're a lot of things to improve:
- Automatic namespacing that can achieve per-document focus level: In other words, the system should only dispatch changes related to the documents that a container's subscription clients are "interested" in, _and nothing else_. And ideally this should be achieved automatically rather than having to manually setup custom namespaces.
- Not introducing a new point of failure: By introducing a separate Node.js server, extra devops need to be handled to keep it up and running - definitely not ideal.
The best solution should be having a "change streams driver" running on each Galaxy container that listens to only the db changes related to that particular container. But there're certain challenges in this approach:
- In order to listen to only the relevant db changes, each container needs to specific an aggregation pipeline for its change stream to filter out relevant data. We can construct this pipeline using the information from all of the
SessionCollectionViewstored on each container. However with such a pipeline we can only retrieveupdateanddeleteevents for the currently subscribed documents, and won't be able to acknowledge newlyinserted documents. - Even though the performance of MongoDB change streams is very good (MongoDB support team confirmed with me that "a few thousand change streams could be opened to a node with minimal performance impact"), having one stream per container means there's no infinite scalability.
I will continue to invest time into finding the best solution.
 npvn
on 28 Sep 2020
npvn
on 28 Sep 2020
Thanks @npvn for your detailed update
If we are going to introduce another point of failure, might as well use Redis with redis-oplog (we created our own fork here which is designed for scalability). Redis was designed for this use case. I was hoping to retire this package once change streams are mature ... unlikely to happen soon if I understood correctly.
We could look into integrating oplogtoredis which would allow external db updates as well and add another level of scalability.
ramezrafla
on 28 Sep 2020
@dandv I think https://jira.mongodb.org/browse/SERVER-33827 is needed for this to be really useful.
mitar
on 29 Sep 2020
Thanks @ramezrafla, your fork looks very interesting. I'll definitely dive into it to have more insights. Would be great if we have a diff with the original redis-oplog codebase, but this summary works too 👍
npvn
on 30 Sep 2020
@npvn
The code changed so much, diff-ing would return every single line
Let me know how your tests go. I am thinking of implementing support for oplogtoredis soon.
ramezrafla
on 1 Oct 2020
Related issues
 ch-lukas
·
5Comments
ch-lukas
·
5Comments
 stolinski
·
3Comments
stolinski
·
3Comments
 vladejs
·
6Comments
msavin
·
3Comments
vladejs
·
6Comments
msavin
·
3Comments
 glasser
·
5Comments
glasser
·
5Comments
Most helpful comment
I like the idea of dividing query processing between Change Steams and the Meteor server(s) but instead of handling lists and their documents differently, we could also distinguish between changing and unchanging fields.
Idea
Change Streams can be used to match on any unchanging field (not just
_id). If we pass hints tofind(in theoptionsobject) about which fields won't change, we can use them to create Change Streams that prefilter document changes at the database. The changes that make it past this initial filtering stage are still processed as before on the Meteor server(s) but the observers have more information about the changed documents and they receive fewer changes.The diagram below illustrates the data flow of a document update. When the update is processed by the database, the Change Stream filters it based on an unchanging field in the document. The observer that initiated the Change Stream does the rest of the processing, i.e., match on changing fields, apply skip and limit, etc., and sends the change to its clients.
If this idea works (and if the schema contains unchanging fields suitable for filtering), it could partially solve the problem of inefficient "FLS" (field, limit, skip) queries because observers have more context about document changes, which means that they have to make fewer database queries.
Example
The following example shows the difference between oplog tailing and prefiltering with Change Streams. Let's assume we have a task list app that runs on three servers. Each task has a boolean
donefield, adescriptionfield, and belongs to a list via an unchanginglistIdfield (in this example, tasks can't be moved to other lists). Each server has started some observers (labeled O1 through O6, see the diagrams below), which observe different queries:'x'Query of O3:
Updates with Oplog Tailing
Assume that there is a task
'y'withdone == false, which belongs to list'x'(whose tasks are observed by O3). We change thedonefield of this task as follows:With oplog tailing, each server receives that change and each observer asks the database if the changed task belongs to the list whose tasks it is observing. 🖥 🔥 The diagram below shows the data flow generated by this update. Only the green arrows represent relevant data flow, all other data flow causes unnecessary server load and/or network traffic.
Updates with Change Streams & Prefiltering
Since the
listIdfield of a task never changes, we can modify thefindcall to give the observer a hint that it should create a Change Stream for it:If we run the update from the previous section with this implementation, only the server that observes tasks in list
'x'will be notified of the change! The Change Stream determines at the database which list the changed task belongs to (usingfullDocumentlookup) and sends the change only to server A, where it will be processed only by observer O3:In this simple example, no unnecessary updates are sent to servers. However, more complex queries can still require servers to ask the database if a document satisfies all conditions. For example, if the query has conditions for more than one unchanging field (i.e., not just the
donefield in this case), the Change Stream doesn't provide enough context. Nevertheless, this should be far less of a problem since the Change Stream already filters out (potentially) lots of irrelevant changes.Advantages
Prefiltering with Change Streams
disableOplog,pollingIntervalMs, andpollingThrottleMs) and can easily be enabled if required,Disadvantages
unchangingFieldsoption, which could be problematic for third-party packages that publish data or create cursors and don't allow options to be passed tofind.