Mastodon: When Sidekiq (pull) queue is very high, some important tasks are to much delayed
There are sometimes days that the pull queue is extremely high. Right now it's over the 5 million. When I take some samples, they are for 99% remote deletions (ActivityPub::LowPriorityDeliveryWorker). I've set the number of Sidekiq threads to 1000, and that is normally high enough. The server doesn't have any problems with a high pull queue, cause all other queues are processed normal.
But some more important tasks than remote deletions (that also use the pull queue) are delayed to much, like:
backup archives:
- When someone requests a backup archive it can take days before they can download them. Users think that it's broken.
suspensions:
- When someone is locally suspended, the session is immediately locked like expected, but the deletion of user data takes also a very long time. This can cause confusion.
Suggestion
Maybe it's better to create a queue with an even lower priority for the remote toot deletions. So local low priorities have a higher priority than remote low priorities.
Specifications
v2.9.3
 joenepraat
joenepraat
All 24 comments
I'm all for a dedicated delete queue.
 shleeable
on 27 Aug 2019
shleeable
on 27 Aug 2019
Also the local deletions are delayed, cause it's in the same queue as the remote deletions. We absolutely need a local low priority queue, that is one priority higher than the remote deletions.
joenepraat
on 27 Aug 2019
Sorry to mention you @Gargron , but this is a real issue.
joenepraat
on 27 Aug 2019
If we can make authorized-fetch-mode on-by-default, we would no longer need to forward deletes (which is what the low-priority queue is responsible for in this issue) because the original instance would already know all inboxes that could have fetched a post.
 Gargron
on 27 Aug 2019
Gargron
on 27 Aug 2019
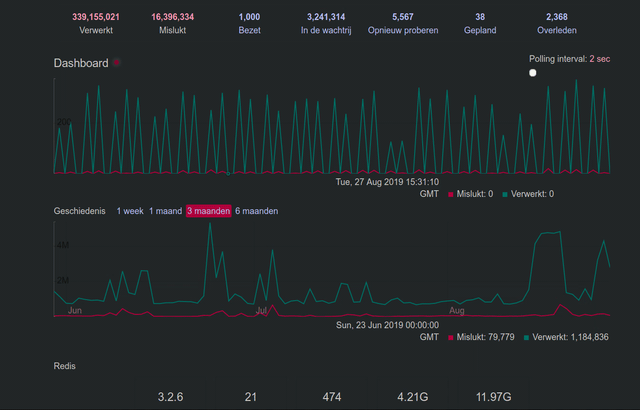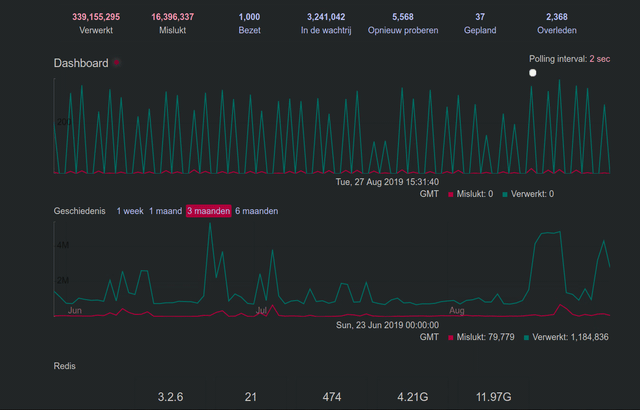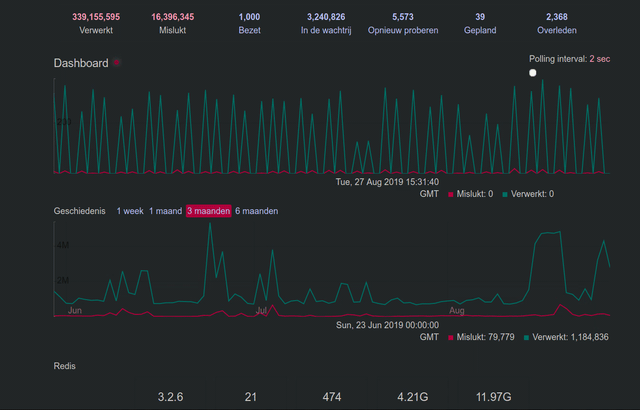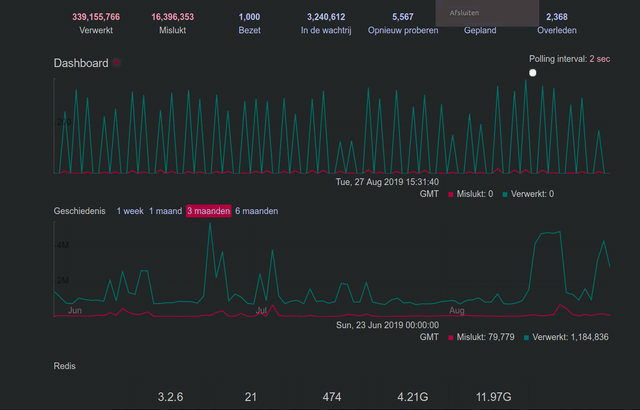
@Gargron Thank you for replying. I don't know what 'authorized-fetch-mode' is and if it's possible to use it already, but anything that fixes this queue issue is welcome. See my little Sidekiq screencast for an example.
joenepraat
on 27 Aug 2019
@Gargron Sorry to bother you again, but I found another case why it's important to fix this ASAP:
When the pull queue is high, it's delaying the local deletions as well as said earlier. But that means that 'delete and re-draft' is at that moment completely broken. Yesterday I had a bunch of deleted drafts still hanging on the local timeline for hours.
joenepraat
on 28 Aug 2019
Sidekiq's queue extremely high again. I almost want to empty the queue. Any progress on this @Gargron ? You talked about authorized-fetch-mode on-by-default. Does that that mean it is already available?

joenepraat
on 16 Sep 2019
You talked about authorized-fetch-mode on-by-default. Does that that mean it is already available?
Authorized fetch mode is available, but it cannot become the default until 3.0 is released and installed on most servers. After that, delete forwarding can be disabled.
cc @ThibG @nightpool
Gargron
on 16 Sep 2019
@Gargron Thank you for your explanation. Can it be turned on manually? Or doesn't that solve anything on my side?
joenepraat
on 16 Sep 2019
You can comment out forward_for_reblogs! and forward_for_replies! lines from app/lib/activitypub/activity/delete.rb
Gargron
on 16 Sep 2019
@Gargron Thanks, but does that solve the high queue numbers you think? So delete & re-draft works normal again?
joenepraat
on 16 Sep 2019
These lines?
if @status.public_visibility? || @status.unlisted_visibility?
forward_for_reply <<<<<
forward_for_reblogs <<<<<
end
Yes
Gargron
on 16 Sep 2019
After 3.0.0 was released we had quite some time a reasonable low pull queue (mostly Chewy::Strategy::CustomSidekiq::Worker). Since yesterday though we had high numbers again. Mostly ActivityPub::LowPriorityDeliveryWorker.
Example:
"{\"@context\":[\"https://www.w3.org/ns/activitystreams\",{\"ostatus\":\"http://ostatus.org#\",\"atomUri\":\"ostatus:atomUri\"}],\"id\":\"https://mastodon.technology/users/xxxxxxx/statuses/yyyyyyyyyyyyyyyyyyy#delete\",\"type\":\"Delete\",\"actor\":\"https://mastodon.technology/users/xxxxxxx\",\"to\":[\"https://www.w3.org/ns/activitystreams#Public\"],\"object\":{\"id\":\"https://mastodon.technology/users/xxxxxxx/statuses/yyyyyyyyyyyyyyyyyyy\",\"type\":\"Tombstone\",\"atomUri\":\"https://mastodon.technology/users/xxxxxxx/statuses/yyyyyyyyyyyyyyyyyyy\"},\"signature\":{\"type\":\"RsaSignature2017\",\"creator\":\"https://mastodon.technology/users/xxxxxxx#main-key\",\"created\":\"2019-10-26T09:58:14Z\",\"signatureValue\":\"X0f0Es/zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz+zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz+zzzzzzz/zzzzzzzz+zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz/zzzzzzzzzzzzzzzzzzzzzzzzzzzz/zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz/zzzzzzzz+zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz==\"}}", 191680, "https://social.hatthieves.es/inbox"
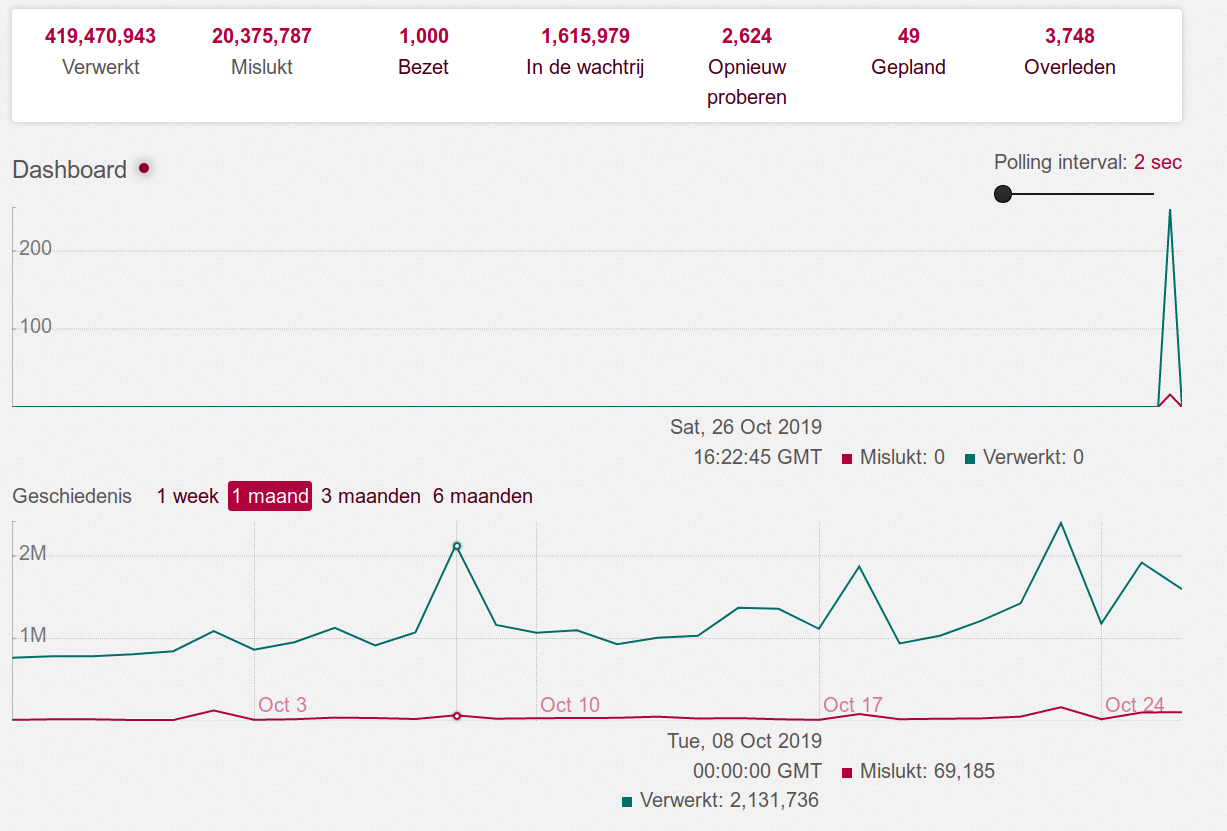
joenepraat
on 26 Oct 2019
@Gargron The pull queue is now much to high. See the rest of the recent comments in this issue. What to do about this on short terms and long terms?
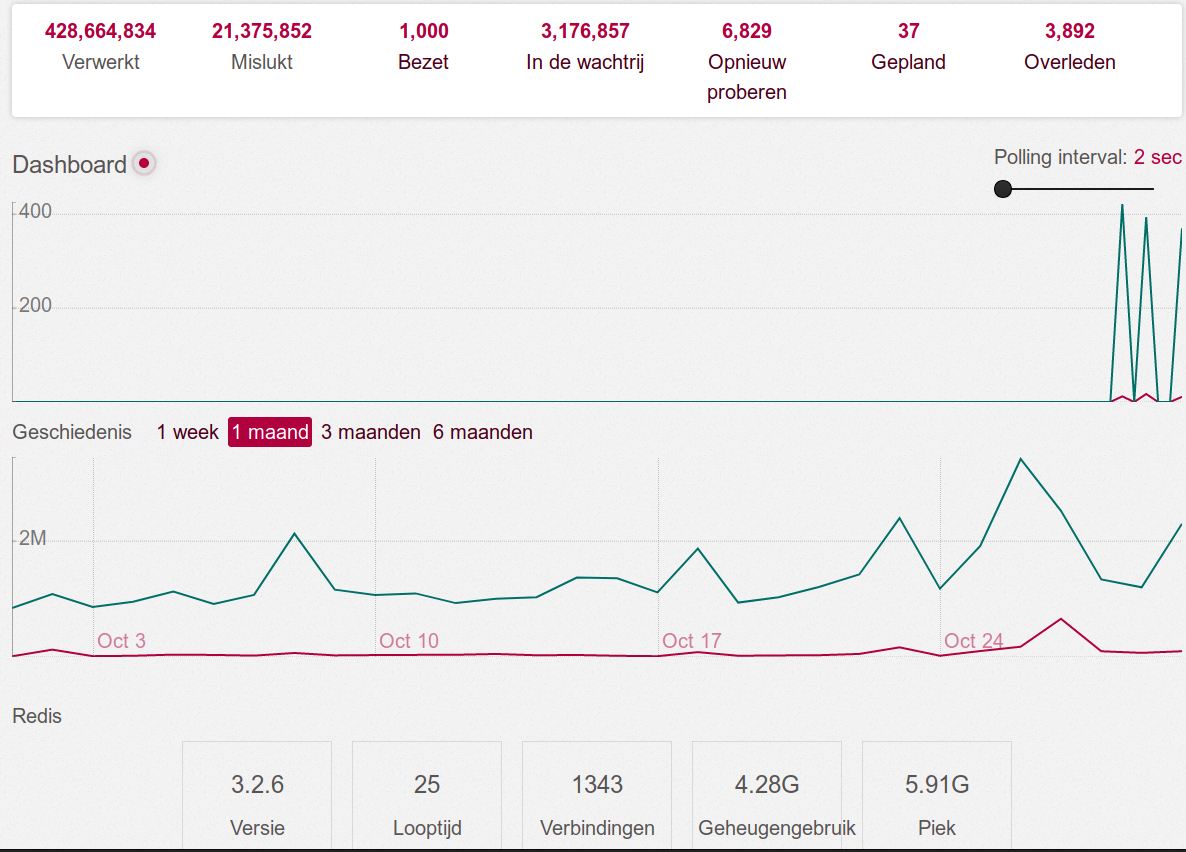
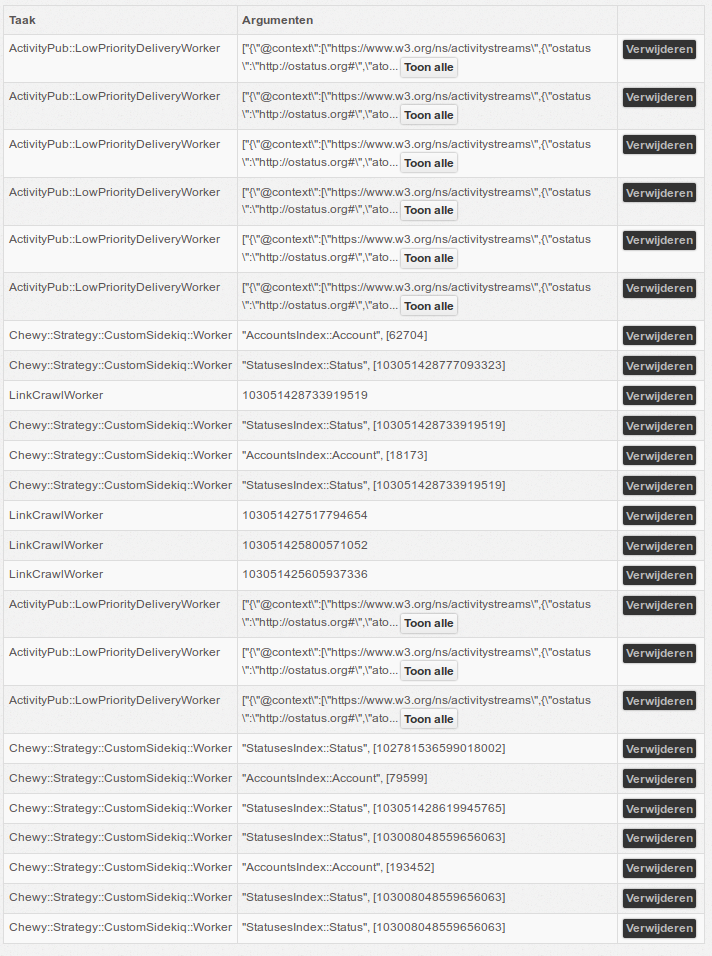
joenepraat
on 30 Oct 2019
This is getting ridiculous.
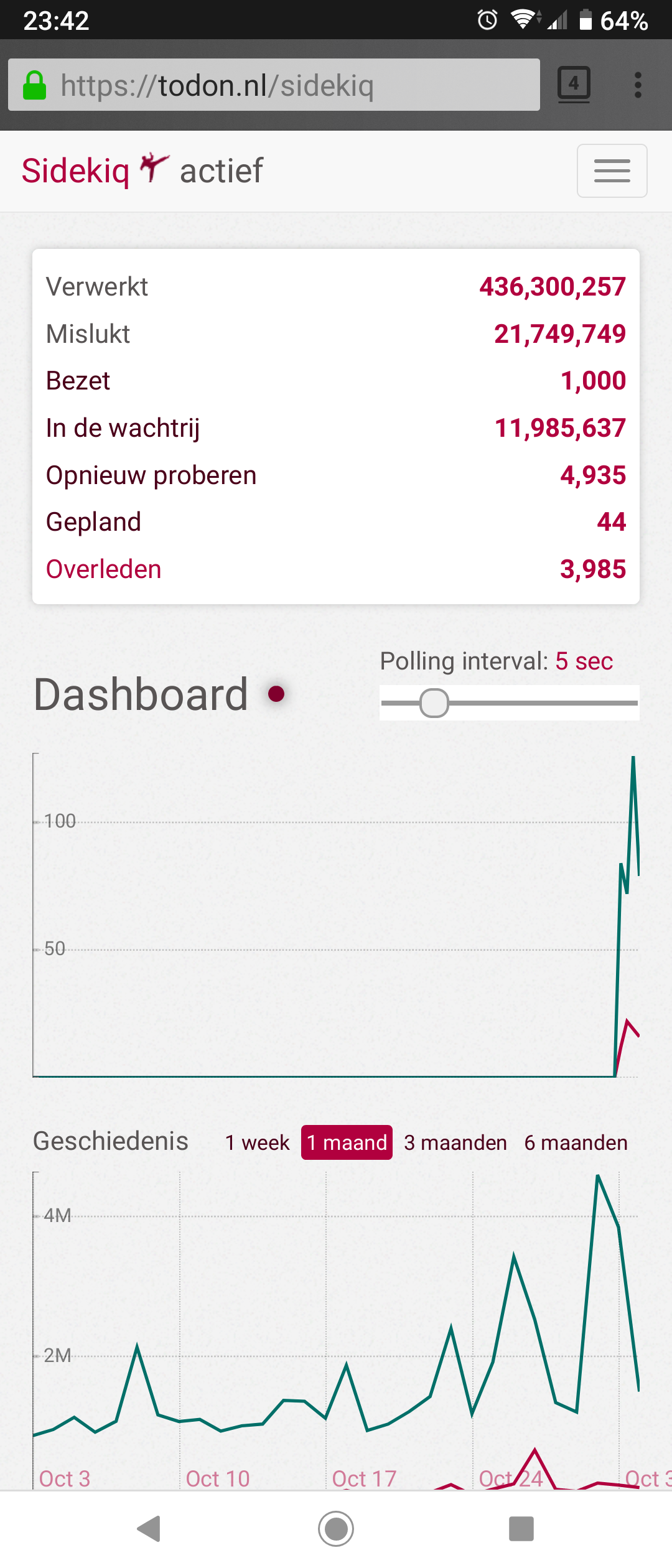
joenepraat
on 1 Nov 2019
@jeroenpraat there's no one size fits all solution to queue congestion. figure out what is getting backed up, why (a slow external service? a lot of jobs enqueued by one person?) and address it by taking jobs out of the queue.
What's the breakdown of jobs in your queue? What's the histogram of worker classes?
 nightpool
on 2 Nov 2019
nightpool
on 2 Nov 2019
@nightpool There are millions of pull jobs. How to see what is causing it? There is no way in Sidekiq to filter jobs or to make rapports.
joenepraat
on 2 Nov 2019
@jeroenpraat https://github.com/mperham/sidekiq/wiki/API
nightpool
on 2 Nov 2019
@nightpool You expect me to use a raw API? I don't have access to my desktop now anyway, so doing this on a smartphone is impossible. Hopefully @Gargron has a better solution.
joenepraat
on 2 Nov 2019
Right know I see tons of delete jobs from @Gargron in the pull queue. Emptying the pull queue doesn't really help, cause new jobs arrive as crazy again
joenepraat
on 2 Nov 2019
I am experiencing the same on mstdn.jp right now. Any solutions? New delete requests are arriving like crazy.
 yisiliu
on 18 Jul 2020
yisiliu
on 18 Jul 2020
I am experiencing the same on mstdn.jp right now. Any solutions? New delete requests are arriving like
I am experiencing the same on mstdn.jp right now. Any solutions? New delete requests are arriving like crazy.
For me this is solved. I'd split the queues in 3 separate processes. But also, your instance is probably to full.
joenepraat
on 18 Jul 2020
I am experiencing the same on mstdn.jp right now. Any solutions? New delete requests are arriving like crazy.
For me this is solved. I'd split the queues in 3 separate processes. But also, your instance is probably to full.
Thanks for the reply! It was quite weird that the same request flooded our server and I couldn't find a way to stop it but flush the redis db. I tried to empty the pull queue but it couldn't stop the requesting from coming in. The redis memory usage went up to 35GB and I thought it was time to flush it. Has anyone seen such behaviors before, receiving the same delete request over and over again?
yisiliu
on 18 Jul 2020
Related issues
 psychicteeth
·
3Comments
psychicteeth
·
3Comments
 renatolond
·
3Comments
renatolond
·
3Comments
 almafeta
·
3Comments
almafeta
·
3Comments
 golbette
·
3Comments
golbette
·
3Comments
 ghost
·
3Comments
ghost
·
3Comments
Most helpful comment
I'm all for a dedicated delete queue.