Mastodon: RTL support for post contents in profile pages and individual posts view
This is very similar to #186 which was fixed two months ago. Right now, RTL text works perfectly well in the tootdeck (compose form textarea and statuses).
However, toots displayed in profile pages and individual post views are still LTR-directioned. Compare this post (not mine) in the time line and in the user's page:
[in the stream, displayed correctly]:

[in the user's page, displayed incorrectly]:

Not only the three-dots are misplaced, but also, since there is an English word inside the Hebrew text, the order of words in the sentence is completely messed up. This can all be fixed by smartly setting { direction: rtl } in the CSS the same way it was done in that commit.
- [x] I searched or browsed the repo’s other issues to ensure this is not a duplicate.
 mabkenar
mabkenar
All 34 comments
@mabkenar thanks for opening the issue! Especially a well-researched one, it helps. Would you be available to open a pull request with a fix? No pressure!
 ashfurrow
on 23 Apr 2017
ashfurrow
on 23 Apr 2017
@ashfurrow Thank you for the nice words! You're welcome!
I am not a fluent web developer, and given my limited time, I'm afraid I cannot do this anytime soon! I would however gladly help with testing and other non-technical issues regarding this bug.
mabkenar
on 24 Apr 2017
@mabkenar we appreciate it – keep opening issues as you find bugs. Thanks!
ashfurrow
on 24 Apr 2017
Hmm, took a look into this and it seems like (at least on current master) this work okay _if_ the characters are RTL _only_:

Some RTL and some LTR characters works sometimes, depending on the ratio:


So I'm not entirely sure where to go with this one. The code does check for RTL and use RTL if the characters are at least 30% of the post. Maybe that ratio should be changed? What do you think @mabkenar ?
ashfurrow
on 24 Apr 2017
Interesting. I just made a test account and wrote a Hebrew post and then a Persian post. Here. Hebrew is set RTL, but Persian is set LTR.
Output:

Source:

I don't know what is happening here. Looks like something is being set per language, and it is done differently for Hebrew than for Arabic.
mabkenar
on 24 Apr 2017
BTW, how can I check the version of Mastodon deployed on a certain instance? I don't know which version is mastodon.xyz running, for example.
mabkenar
on 24 Apr 2017
Very strange, thanks for the info.
It's not current possible to check what version of Mastodon an instance is running, but a recent merge adds this info, so debugging will get easier soon!
ashfurrow
on 24 Apr 2017
I'm famous!
 eladhen
on 24 Apr 2017
eladhen
on 24 Apr 2017
It looks like Persian isn't included in the list of RTL languages, which is probably causing the problem.
So it sounds like there are two aspects to the issue here:
- Review the ratio of required RTL characters (currently 30%, I'm thinking 70% might be better?)
- Add Persian to the list of RTL languages.
Does that sound right? Would anyone be available to open a pull request?
ashfurrow
on 24 Apr 2017
The 30% ratio is relatively okay - it works well on twitter and other websites that use their implementation. It's very rare to have a sentence that is >70% English that you'd still want to align to the right. This is not a problem imo.
If the required ratio for right-alignment is 70% RTL characters, a lot of Hebrew sentences that combine a tiny bit of English in the middle will be aligned to the left and thus unreadable. Especially if it's a short sentence. It's much more common to have a bit of English in a short Hebrew sentence than a bit of Hebrew in a short English sentence.
So to paraphrase more clearly: aligning the message to the right if it has >30% Hebrew is correct. Requiring it to be 70% Hebrew to be aligned to the right is wrong.
Regarding Persian: Persian uses the arabic script, and `\p{Persian}' doesn't seem to exist in this list here: http://www.regular-expressions.info/unicode.html - so I think it's a different issue.
However, Mastodon's implementation of RTL seems to have three main issues:
- The main one in this issue - it doesn't apply on profile pages. This should be easy to fix, the code was probably just never applied to that view.
The fact that it doesn't apply to Persian/Arabic for some reason, even though these do work with the twitter implementation this part of the code is based upon. Further investigation is required.
Unlike the twitter implementation, Mastodon counts mentions and URLs when calculating the ratio and deciding how to align the text - this is wrong because a URL is often much longer than the rest of the post, especially if it's URL-Encoded unicode, such as links to the Hebrew wikipedia, or a post that contains 4 images and one sentence (the image URLs appear to be counted).
 elad661
on 24 Apr 2017
elad661
on 24 Apr 2017
Great researching @elad661 – thank you. I agree with the ratio comments you made, I think I was a little sleepy when I suggested that (changing from 30% RTL vs 70% LTR – they're the same ratio 😆).
The reason the profile and status page differ is because one is rendered from Rails and the other from React. I agree, more investigation is required. Whatever logic is used on both should be consistent.
Very good catch about URLs!
ashfurrow
on 25 Apr 2017
Something weird and inconsistent is going on with this implementation in any case, see this example from my feed: both toots contain mostly Hebrew (the only English bits are username mentions), yet one is left-aligned and the other is right aligned, with no clear indication why.

Without reading the code (and knowing the internals of mastodon), my hunch is that one of these was rendered server-side on page load, and the other was rendered dynamically via javascript because it came later.
Any toot that I post that has a mention has this problem. Is it possible that when counting a mention, the javascript implementation counts the length of the HTML tags that make the mention link towards the total count of LTR characters or something like that?
elad661
on 25 Apr 2017
It's very possible, that's a good hunch; I'll try to look into it (unless someone beats me to it).
ashfurrow
on 25 Apr 2017
also, look at the mention tags in this screenshot and see the @ sign is all over the place in the one that is right-aligned. Mentions should probably be contained in another with direction: ltr when grouped together like this.
elad661
on 25 Apr 2017
Let's see how this works with the RTL patch that was merged yesterday.
mabkenar
on 25 Apr 2017
@mabkenar
From reading the patch I can say it's probably unrelated, it's about making the interface right-aligned when the UI language is an RTL language, but this issue is independent of the UI language or alignment and talks about RTL in post content.
Even if that patch somehow magically fixes the problem when the UI language is set to Arabic (it probably doesn't, since the problem is a logic problem not a CSS problem), it will have no affect when the UI is set to English, and a lot of us want to read RTL posts properly even when using an English UI.
elad661
on 25 Apr 2017
@elad661 I think you are right on this.
Regarding the problem with misplaced "@" signs that you posted here:

I think it could be solved by injecting some Unicode isolation characters. I can't figure out the details ATM, but the best manual about it that I have found is this W3 article: How to use Unicode controls for bidi text.
Now that I think about it, why not we assign directionalities to each paragraph instead of the entire post? Use case: it is likely that I quote an English paragraph in a toot and add a short commentary, in Persian, above it. I expect my commentary to be RTL and the quoted English paragraph to be LTR. This is how GNOME's gedit does it, albeit only based on the first strong character in each paragraph:

Is it possible to break the toot into paragraphs and set the direction for each paragraph separately?
mabkenar
on 25 Apr 2017
We can use unicode-bidi: embed together with direction: ltr on the mentions, that's easier than control characters...
But then there's another problem that the order of the mentions is LTR (the person the message is addressed to, which should be the first, is the leftmost one). This can be confusing because even though mentions use English characters, a person whose native language is an RTL one will read it from right to left... at least that's how I think people are going to read it, more feedback is required.
There's a CSS solution for this too: use unicode-bidi: isolate (instead of embed) on all the mentions, but first we need to decide which order makes more sense. If you reply to an RTL toot with two people CC'd to it, which username should appear rightmost: the person you're replying to, or the 2nd person CC'd in the original toot?
Regarding paragraphs: that would be really useful in my opinion, but it will require more complicated changes. Right now a toot is one paragraph (one
) and every newline is a <br>. It'll need to change so newlines create another <p> and I'm not sure if that might have unwanted side effects.
gedit (or rather GTK, which is the toolkit that gedit uses) doesn't do it per paragraph, it does it per line of text (it doesn't have the concept of paragraph, it has lines, and the lines are wraped to fit the size of the screen). If we do copy this behaviour, we should definitely do it per paragraph and not per line. (also, I think their behaviour of doing it according to the "first strong character" is not great, and what we have in Mastodon at the moment is definitely better)
elad661
on 25 Apr 2017
Solving the issue with the mentions seems pretty hairy. Maybe it makes most sense to automatically separate the mentions as a paragraph before the rest of the toot iff the (first paragraph of the )rest of the toot is RTL? (I do this manually sometimes and find it reads more comfortably when tooting in Hebrew.)
 msappir
on 25 Apr 2017
msappir
on 25 Apr 2017
@elad661
a person whose native language is an RTL one will read it from right to left... at least that's how I think people are going to read it, more feedback is required.
If the post is rendered RTL then I read it from right to left, like you.
There's a CSS solution for this too: use unicode-bidi: isolate (instead of embed)
And it seems use of embeddings are discouraged in Unicode 6.3+, in favor of isolates, so it makes sense to use isolates
which username should appear rightmost: the person you're replying to, or the 2nd person CC'd in the original toot?
I think the person you're replying to should appear rightmost.
doing it according to the "first strong character" is not great, and what we have in Mastodon at the moment is definitely better
I agree. We should stick with the 30% (or so) percent rule.
we should definitely do it per paragraph and not per line
Why do you think that? IMO, a <br> (or two consecutive <br>s, if you like) effectively starts a new paragraph and can be used to "divide" the toot in directionally-independent parts.
mabkenar
on 25 Apr 2017
@msappir
to automatically separate the mentions as a paragraph before the rest of the toot
Maybe not. Users may want to play with the position of the mention in their reply text (e.g., Nice joke, @dude). The mention may not always come at the beginning of their reply toot.
mabkenar
on 25 Apr 2017
I was referring only to the situation where the mention comes first. The other cases are basically the same as the case you started this thread with, LTR words embedded in RTL text...
msappir
on 25 Apr 2017
I think @msappir 's suggestion adds a lot of complexity for very little gain, so using isolates is the way to go.
Regarding paragraphs (@mabkenar 's suggestion): I think two newslines to start a paragraph makes more sense, because the vertical space between two paragraph vs. between to lines is usually different (paragraph have little more vertical spacing), but I don't have any serious objection for doing it after one newline. It's just a question of how much complexity it adds. If it's not too complex to implement then I'm in favor of this idea.
elad661
on 25 Apr 2017
Bug still present in Mastodon 1.3.1 (post link):

mabkenar
on 28 Apr 2017
This is very strange, but it seems that only very short posts are correctly formatted as RTL. See below:

Long posts have an explicit direction: ltr in their <div> element. Short posts have explicit rtl.
mabkenar
on 28 Apr 2017
I think this may be related. I see app/views/stream_entries/_{detailed,simple}_status.html.haml calling rtl? but too often getting ltr. the parameter it sends is status.content which is expected to be a simple text string...
another mixed example:
https://tooot.im/@LavaandFireworks/331208
 seefood
on 8 May 2017
seefood
on 8 May 2017
I solved this in PR #3047 but I can't get @Gargron to like the solution. He prefers we trust the language detection algo, but I tested it and it's even less reliable than what we have now.
Anyone wants to weigh in so we can get this PR merged before 1.4?
seefood
on 27 May 2017
Thank you @seefood for the great work. I really appreciate your efforts to fix RTL issues in Mastodon. I see where each of you and @Gargron are coming from.
- I think setting the direction at publication time is technically the better (i.e. more efficient) solution than to finding the direction at render-time.
- I don't care how the direction is detected (via language detection, or by counting characters) as long as the algorithm works reliably.
Now, I haven't tested the new language detection library yet. Do you know anywhere its accuracy is documented?
mabkenar
on 3 Jun 2017
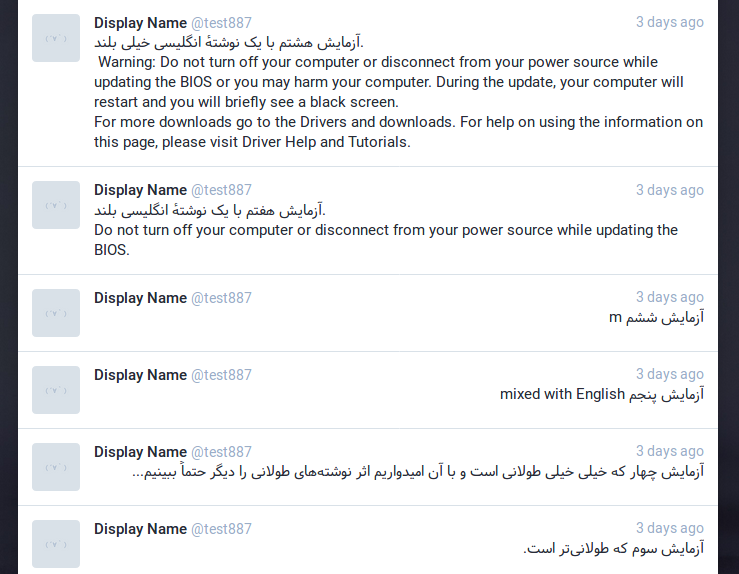
I just tested the language detection to see if Persian is detected correctly. This is the profile I checked it in: https://glitch.social/@test887
By looking at the source of the page linked above (e.g. by pressing Ctrl+U in Firefox) one can easily check the lang= attribute for every toot.
Except from one toot (which contains only two Persian words and a long English paragraph, and is strangely detected as lang='sd'), all other toots are detected either as Persian or English.
Problem is, a toot with 392 characters (excluding spaces) that contains exactly one Persian character (and the rest is English text) is detected as Persian (lang='fa'). So the 30% rule is completely out of effect.
mabkenar
on 7 Jun 2017
I really think the simple 30% rule is much more useful than trying to guess the language of the post. I just don't see how "guessing the language of the post" even makes sense for multilingual post, and any native speaker of an RTL language can testify that people sometimes use English words or even entire sentences inside a post that still need to be read as RTL.
elad661
on 7 Jun 2017
Well, I had a patch that few helped promote, so I removed it. just send a better PR and good luck.
 ira-lb
on 8 Jun 2017
ira-lb
on 8 Jun 2017
@elad661 That's why it is 30% rule, and not 50%.
mabkenar
on 11 Jun 2017
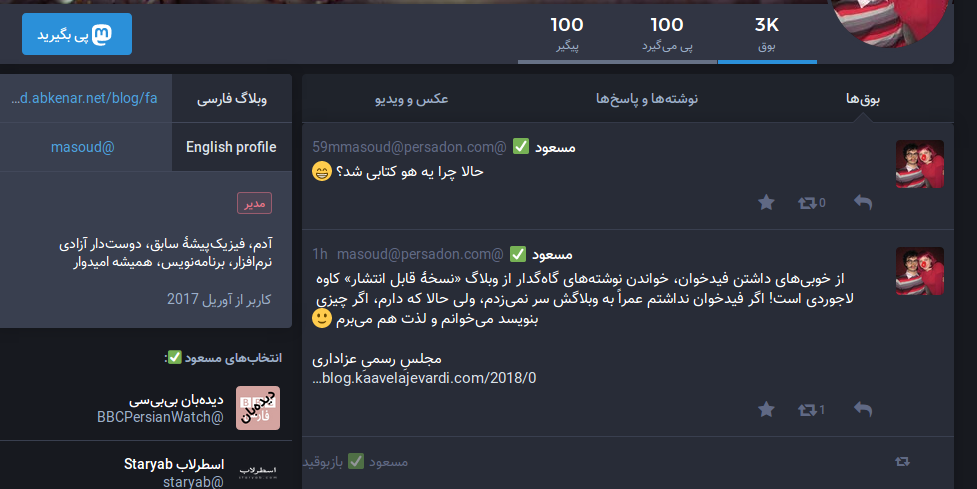
Well, the problem seems to be solved by @Gargron's own commit, where he acknowledged @seefood's previous efforts. Look at the same page now, and the directions are done right.
I know that setting directionalities based on the detected language may not be the most straightforward solution, but it works in most of the cases, and that's really good enough.
mabkenar
on 11 Jun 2017
Related issues
 KellerFuchs
·
3Comments
KellerFuchs
·
3Comments
 thomaskuntzz
·
3Comments
thomaskuntzz
·
3Comments
 phryk
·
3Comments
phryk
·
3Comments
 cumbiame
·
3Comments
cumbiame
·
3Comments
 marrus-sh
·
3Comments
marrus-sh
·
3Comments
Most helpful comment
This bug is back with the new public pages introduced in Mastodon 2.5. The previous fix on 2017-07-10 is here. Screenshot below from here: