Maskrcnn-benchmark: Why FrozenBatchNorm2d in ResNet?
❓ Questions and Help
I have read the ResNet code and I don't understand why is FrozenBatchNorm2d used? should we let model to lean parameters when training on per batch?
 txytju
txytju
All 35 comments
The reason why we use FrozenBatchNorm2d instead of BatchNorm2d is that the sizes of the batches are very small, which makes the batch statistics very poor and degrades performance.
Plus, when using multiple GPUs, the batch statistics are not accumulated from multiple devices, so that only a single GPU compute the statistics.
When we have sync BatchNorm in PyTorch, we could start looking into having BatchNorm instead of a frozen version of it.
 fmassa
on 12 Dec 2018
fmassa
on 12 Dec 2018
So when will we have sync BatchNorm in PyTorch? I have read the paper "Rethinking ImageNet Pretrain" and it seems that sync BatchNorm is important to train a fater-rcnn from scratch.
txytju
on 12 Dec 2018
There is an open PR adding sync batch norm to pytorch in https://github.com/pytorch/pytorch/pull/14267
fmassa
on 12 Dec 2018
There's also sync batch norm available in apex if you need anything today: https://github.com/NVIDIA/apex
 jjsjann123
on 13 Dec 2018
jjsjann123
on 13 Dec 2018
Why this lib's implementation of FrozenBatchNorm2d has running_mean/var nevertheless pretrained models have only identical values to 0/1?
I mean, current FrozenBatchNorm2d might have some redundancy and seemingly it is same as below simplified impl (just affine trafo);
class FrozenBatchNorm2d(nn.Module):
def __init__(self, num_features):
super(FrozenBatchNorm2d, self).__init__()
self.num_features = num_features
self.register_buffer("weight", torch.ones(1, num_features, 1, 1))
self.register_buffer("bias", torch.zeros(1, num_features, 1, 1))
def forward(self, x):
return x * self.weight + self.bias
Is it in order to deal with future modifications or I overlooked something?
And one more question; if we want to use SyncBatchNorm, what only we need to do are replace BN modules and set broadcast_buffers=True in torch.nn.parallel.DirtributedDataParallel?
I tried training for COCO with configs/e2e_faster_rcnn_R_50_FPN_x1.yaml as is, and I changed above two things(using SyncBn from apex), but loss diverged in initial phases.
 lyakaap
on 13 Jan 2019
lyakaap
on 13 Jan 2019
@lyakaap the reason why we have this redundancy is to facilitate loading of torchvision models. Indeed, in our previous implementation we had exactly what you wrote, but loading pre-trained models from torchvision (which had running_mean, weight, etc) was not possible out of the box and we had to perform some net surgery.
In the end, it was just simpler to have this small redundancy in the function.
About your second question, I'd say that this is all that is needed in order to make it work, but I haven't tried it myself, so maybe you'll need to tune a few other parameters?
fmassa
on 14 Jan 2019
@fmassa Thank you for replying!
( Actually, memory consumption of that simplified version almost the same as current FrozenBN implementation :) )
lyakaap
on 14 Jan 2019
Yes, memory consumption is almost the same because I perform the multiplications / additions in the weight / running_mean, instead of directly in the x - running_mean + ... (which would also bring significant slowdowns)
fmassa
on 14 Jan 2019
@fmassa one more question on this topic: how are weight and bias of FrozenBatchNorm2d updated during training? They are buffers, not parameters, (so sgd does not update them), and I don't see any mechanism of updating them in the class implementation.
 dnnspark
on 17 Jan 2019
dnnspark
on 17 Jan 2019
@dnnspark they are not updated, they are kept fixed. That's the behavior of the Caffe2 implementation of Detectron, and we kept it the same here.
fmassa
on 17 Jan 2019
@fmassa But if the weight and bias are initialized with ones and zeros respectively and not being updated, isn't the result of forward() (i.e. w*x+b) always just identity? Then the FrozenBatchNorm2d is effectively doing nothing?
dnnspark
on 18 Jan 2019
@dnnspark if we start from scratch, then yes. But we load the weights from a pre-trained model, which have those fields saved and are not initialized as the identity.
fmassa
on 18 Jan 2019
@fmassa I got it. Thanks for replying!
dnnspark
on 19 Jan 2019
@fmassa ,hi,I look into the code, you mean ,in this FrozenBatchNorm2d, for the resnet50 based mask rcnn,if we load the pretrained backbone R-50.pkl, i see

the bias and weight of bn in the pretrained model are loaded.
my question are:
- here the bias and weight correspond to alpha and gamma in the following formula?
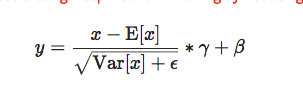
- why the running var and running mean are not loaded and used?
many thks
 alexwq100
on 25 Feb 2019
alexwq100
on 25 Feb 2019
@alexwq100 about your questions:
1 - yes, weight and bias correspond to gamma and beta in the equation
2 - because the pre-trained weights from Caffe2 have performed some pre-processing already, and have merged the running mean and the running var inside the gamma and beta
fmassa
on 25 Feb 2019
@alexwq100 about your questions:
1 - yes, weight and bias correspond to gamma and beta in the equation
2 - because the pre-trained weights from Caffe2 have performed some pre-processing already, and have merged the running mean and the running var inside the gamma and beta
@fmassa thanks for your quick reply!!!
for the second answer, could you explain it in more detain? how did you merge the running mean and the running var inside the gamma and beta?~~~
alexwq100
on 26 Feb 2019
@alexwq100 I didn't do it in this codebase, it was done in Detectron.
And merging he running mean / std inside gamma and beta is jus a matter of rewriting the equation, so that you have y = x * gamma_2 + beta_2
fmassa
on 26 Feb 2019
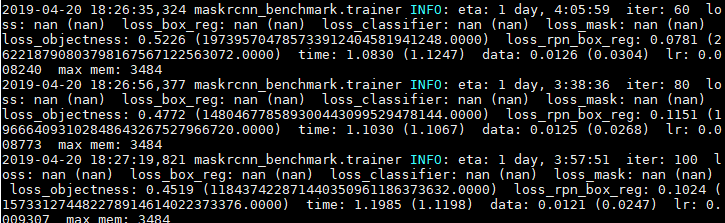
@fmassa @jjsjann123 when i use sync bn from apex instead of frozen bn, the loss is "nan", how can i fix it.
 RainHxj
on 20 Apr 2019
RainHxj
on 20 Apr 2019
Which sync bn were you using? (did you install apex with --cuda_ext?)
I need more information about your setup to help.
Are you running fp16 or fp32?
What's the configuration? what's the group size? Have you tried to debug whether the nan is produced by your sync bn layer?
Optimally I would like to have a minimum repro to debug this.
jjsjann123
on 20 Apr 2019
thanks for you reply.
l install apex like this
i am running fp32
batch_size = 16, batch_per_gpu = 2, gpu_num =8
i just change the bn layer, so the nan is produced because of using sync bn.
At the same time, when i use torch.nn.BatchNorm2d instead of frozen bn, i also get error.
RainHxj
on 20 Apr 2019
Looks like you are doing the right thing here.
When you say torch.nn.BatchNorm2d still gives you error, is it the same nan in loss that we are talking about?
Note that it is mathematically different when you switch from frozenBatchNorm to SyncBatchNorm, as now you are relying on run-time stats from the incoming mini-batch for normalization.
I would suggest you take a look at input/output from you SyncBatchNorm layer to see if it is the SyncBatchNorm that's introducing nans. If you get a mini-repro with a SyncBatchNorm layer that generates nan I could kick in and check what's wrong with the kernels.
jjsjann123
on 21 Apr 2019
Looks like you are doing the right thing here.
When you say torch.nn.BatchNorm2d still gives you error, is it the same
nanin loss that we are talking about?
Note that it is mathematically different when you switch fromfrozenBatchNormtoSyncBatchNorm, as now you are relying on run-time stats from the incoming mini-batch for normalization.I would suggest you take a look at input/output from you
SyncBatchNormlayer to see if it is theSyncBatchNormthat's introducingnans. If you get a mini-repro with aSyncBatchNormlayer that generates nan I could kick in and check what's wrong with the kernels.
We met the exactly same problem both on FPN or RetinaNet when I used SyncBatchNorm. sync_batchnorm and optimized_sync_batchnorm can both lead to this problem. If you train an RetinaNet, you'll see that the AP will start dropping fastly from nearly 45k iters. We tested it on 1080ti cuda9 and 2080ti cuda10, pytorch 1.0.1 DDP and apex DDP, pytorch nightly syncbn and apex syncbn, even on different codebases, we still met this strange problem. Maybe you can try syncbn in maskrcnn-benchmark, it seems quite easy to reproduce it. If we just simply replace syncbn to torch.nn.BatchNorm2d, we'll get a resonable AP (a little bit lower than frozenBatchNorm), so we blame the problem on syncbn.
Here is another guy who met the same problem. #686
 wjfwzzc
on 21 Apr 2019
wjfwzzc
on 21 Apr 2019
Looks like you are doing the right thing here.
When you say torch.nn.BatchNorm2d still gives you error, is it the samenanin loss that we are talking about?
Note that it is mathematically different when you switch fromfrozenBatchNormtoSyncBatchNorm, as now you are relying on run-time stats from the incoming mini-batch for normalization.
I would suggest you take a look at input/output from youSyncBatchNormlayer to see if it is theSyncBatchNormthat's introducingnans. If you get a mini-repro with aSyncBatchNormlayer that generates nan I could kick in and check what's wrong with the kernels.We met the exactly same problem both on FPN or RetinaNet when I used
SyncBatchNorm.sync_batchnormandoptimized_sync_batchnormcan both lead to this problem. If you train an RetinaNet, you'll see that the AP will start dropping fastly from nearly 45k iters. We tested it on 1080ti cuda9 and 2080ti cuda10, pytorch 1.0.1 DDP and apex DDP, pytorch nightly syncbn and apex syncbn, even on different codebases, we still met this strange problem. Maybe you can try syncbn inmaskrcnn-benchmark, it seems quite easy to reproduce it. If we just simply replace syncbn totorch.nn.BatchNorm2d, we'll get a resonable AP (a little bit lower thanfrozenBatchNorm), so we blame the problem on syncbn.Here is another guy who met the same problem. #686
Agree with you. @wjfwzzc
Similar Observations occur in my experiments.
And I found that it would got a reasonable AP after setting track_running_status = False in test time.(i.e. use the statistics in each batch, instead of the running mean and var.)
It seems that there might be something wrong in the syncbn, especially the part of running mean and var.
@jjsjann123
Do you have some ideas about this issue?
 zhangliliang
on 26 Apr 2019
zhangliliang
on 26 Apr 2019
Sorry for the delayed response. Got occupied for the past couple weeks.
@wjfwzzc were you observing similar issue as what @zhangliliang was describing? So training & loss looks fine, it's only validation (running stats) that's causing the issue?
We have two group BN implementation in apex even relying on different synchronization mechanism and we have it working as expected. I have spent time helping people debugging issues related to sync BN before and it's usually somewhere else in the model that causing the issue.
The problem described here sounds more like a model issue. (BN does the right thing, but the model just don't converge at this global batch size). But I agree that AP goes to 0 sounds very strange.
What is the use case here? If we are strong scaling trying to improve performance here, maybe we have the option to use torch.nn.BatchNormXd to establish a baseline here first?
@zhangliliang have you checked the running_stats in the BN layer? Are you using multi-group in your sync BN layer, if so, how are you reducing running_stats between processes?
running mean / var are just weighted average from unbiased mean/var calculated at training time, not likely something going wrong there. How are you enabling sync BN in your code? Can you share a link to your code base?
jjsjann123
on 1 May 2019
@dnnspark if we start from scratch, then yes. But we load the weights from a pre-trained model, which have those fields saved and are not initialized as the identity.
@fmassa
if I would like to train with some very different datasets than COCO, I'll have to replace this fixed BN with a standard BN, right? What's your suggestion? Thanks
 eepaul
on 2 May 2019
eepaul
on 2 May 2019
Sorry for the delayed response. Got occupied for the past couple weeks.
@wjfwzzc were you observing similar issue as what @zhangliliang was describing? So training & loss looks fine, it's only validation (running stats) that's causing the issue?
We have two group BN implementation in apex even relying on different synchronization mechanism and we have it working as expected. I have spent time helping people debugging issues related to sync BN before and it's usually somewhere else in the model that causing the issue.The problem described here sounds more like a model issue. (BN does the right thing, but the model just don't converge at this global batch size). But I agree that AP goes to 0 sounds very strange.
What is the use case here? If we are strong scaling trying to improve performance here, maybe we have the option to usetorch.nn.BatchNormXdto establish a baseline here first?@zhangliliang have you checked the running_stats in the BN layer? Are you using multi-group in your sync BN layer, if so, how are you reducing running_stats between processes?
running mean / var are just weighted average from unbiased mean/var calculated at training time, not likely something going wrong there. How are you enabling sync BN in your code? Can you share a link to your code base?
Yes we observed the similar issue as @zhangliliang described. Just like what I said above, we can ensure that everything goes well using torch.nn.BatchNormXd, and both SyncBN versions lead to the very same issue. We also tried to replace them by our own syncbn implementation and it seems work well.
wjfwzzc
on 5 May 2019
Any chance you can share your code/model so I can take a quick look?
Otherwise, I can follow this (but it's gonna take me longer to get to that):
Maybe you can try syncbn in maskrcnn-benchmark, it seems quite easy to reproduce it.
jjsjann123
on 6 May 2019
@jjsjann123
I might found out something for the wired results by using SyncBatchNorm on this codebase.
The devil might lie in line 15 of maskrcnn_benchmark/solver/build.py. That it set the decay factor in all the bias in the model as 0, which means that the decay factor of bias in SyncBatchNorm also be 0. Thus the bias might become larger and larger after serveral iterations (e.g. 5w iterations) and the network becomes unstable.
After I change the decay factor for bias to 1, this training becomes much more stable and currently the AP becomes normal. Nevertheless, I need some times to do more experiments to check out whether this codebase would get some gains via SyncBatchNorm, compared to forzenbn.
@wjfwzzc
I am also curious about your implemenation of syncbn, whether the bias in your implementaion is not named as bias but other word. If not, there might be other devil exists.
zhangliliang
on 6 May 2019
@wjfwzzc mentioned that torch.nn.BatchNorm2d worked fine for them (at least reasonable AP), which also uses bias, so it should be affected by the decay factor here as well.
@zhangliliang I can give you a side branch where I rename bias in SyncBatchNorm to something else if you think it would be helpful.
Should be very easy to swap the bias used here: https://github.com/NVIDIA/apex/blob/master/apex/parallel/optimized_sync_batchnorm.py#L84
jjsjann123
on 6 May 2019
@wjfwzzc mentioned that
torch.nn.BatchNorm2dworked fine for them (at least reasonable AP), which also usesbias, so it should be affected by the decay factor here as well.@zhangliliang I can give you a side branch where I rename
biasin SyncBatchNorm to something else if you think it would be helpful.
Should be very easy to swap thebiasused here: https://github.com/NVIDIA/apex/blob/master/apex/parallel/optimized_sync_batchnorm.py#L84
after setting the decay in SyncBatchNorm from pytorch-nightly 1.0, currently I got reasonable gains (~1 AP gains in res50-fpn faster-rcnn, batch 16, scheduler 2x). In my experiments the BatchNorm2d with bias decay set to 0 (i.e. batch=2) drop ~3 AP compared to the baseline.
I might cleanup the codes to do more experiments.
zhangliliang
on 7 May 2019
Thanks for the investigation. Would appreciate it if you could keep us posted with updates.
Also feel free to reach out if you need support to rename bias
jjsjann123
on 8 May 2019
hi @zhangliliang
thanks for ur findings, i will try it to see it can get a reasonable result.
 zimenglan-sysu-512
on 10 May 2019
zimenglan-sysu-512
on 10 May 2019
Hi @zhangliliang ,
After changing the decay factor for bias to 1, the training is stable. But I get a lower performance than frozenBatchNorm. Do you add the decay for bias in the sync-bn layers not in the other layers? Could you provide the value of decay factor you used? I tried decay factor = 1e-4, which still results in NaN. I think the value of decay factor is also important.
 sunke123
on 13 May 2019
sunke123
on 13 May 2019
any update recently?
zimenglan-sysu-512
on 9 Jul 2019
Can someone explain what FrozenBatchNorm2d do exactly?
 dishank-b
on 2 Jun 2020
dishank-b
on 2 Jun 2020
Related issues
 KuribohG
·
3Comments
KuribohG
·
3Comments
 YuShen1116
·
4Comments
YuShen1116
·
4Comments
 Jinksi
·
3Comments
Jinksi
·
3Comments
 SkeletonOne
·
3Comments
SkeletonOne
·
3Comments
 Nacho114
·
4Comments
Nacho114
·
4Comments
Most helpful comment
The reason why we use
FrozenBatchNorm2dinstead ofBatchNorm2dis that the sizes of the batches are very small, which makes the batch statistics very poor and degrades performance.Plus, when using multiple GPUs, the batch statistics are not accumulated from multiple devices, so that only a single GPU compute the statistics.
When we have sync BatchNorm in PyTorch, we could start looking into having
BatchNorminstead of a frozen version of it.