Mask_rcnn: Trying crack detection : "Error No instance to display"
Hello Everyone,
I have been working recently on concrete crack detection or lets say crack detection but I have no success with it. I have gone through all mentioned examples and demos of Coco, balloon and nucleus dataset and tried them just to know whats happening. I have only one class for my project so I stick to balloon example and made a new model from scratch to training but while validating my model, prediction says No instances found although when I was trying inspect data copy and load my own dataset and model it was doing just fine But when i tried the Inpect_model file for my validation data I got no prediction.
I have changed the following prameters
class CrackConfig(Config):
"""Configuration for training on the toy dataset.
Derives from the base Config class and overrides some values.
"""
# Give the configuration a recognizable name
NAME = "crack"
# We use a GPU with 12GB memory, which can fit two images.
# Adjust down if you use a smaller GPU.
IMAGES_PER_GPU = 1
# Number of classes (including background)
NUM_CLASSES = 1 + 1 # Background + crack
# Number of training steps per epoch
STEPS_PER_EPOCH = 100
# Skip detections with < 90% confidence
DETECTION_MIN_CONFIDENCE = 0.6 # also tried for 0.9 at first
But most of the parameters like FPN, ROI in the config.py and model.py files were same.
The results gives me nothing at all. Can somebody points out to my problem what is the issue @waleedka ?
Do I have to make some changes because I thought its similar to balloon example with one class so i simply annotate my data of 82 training images and 19 val images and give it a run.
While checking the inspect data results I got following but while validating my model I got this result.
Inspecting the pre-process training data


Predictions Result of Model
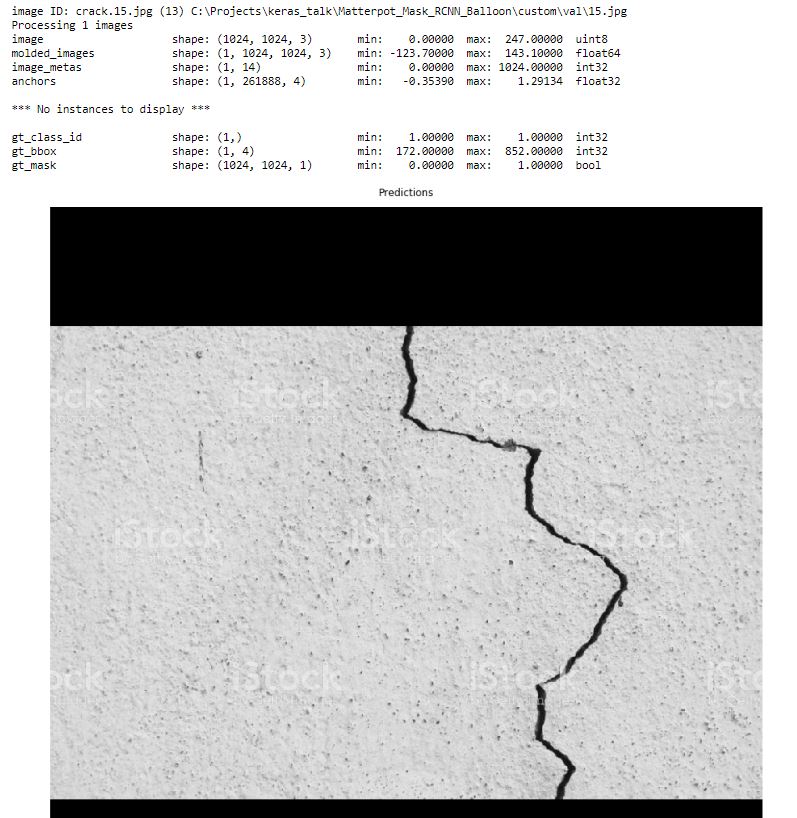
 rakehsaleem
rakehsaleem
All 15 comments
I am working on a similar topic, with small objects being detected by this Mask RCNN. Some strategies you may find helpful:
- Image Augmentation to increase the size of your dataset
- Training for more epochs
- Set validation steps to 10%-20% of your STEPS_PER_EPOCH -
For comparison, I have a dataset of about 150 images. I have used image augmentation to multiply that to over 1000 images. I have had good results with:
- BACKBONE = 'resnet50'
- STEPS_PER_EPOCH=300
- VALIDATION_STEPS=50
- LEARNING_RATE = 0.001
- IMAGE_RESIZE_MODE, IMAGE_MIN_DIM, IMAGE_MAX_DIM may need to be modified per your dataset's image dimensions.
and:
model.train(dataset_train, dataset_val,
learning_rate=config.LEARNING_RATE / 10,
epochs=60,
layers='heads')
model.train(dataset_train, dataset_val,
learning_rate=config.LEARNING_RATE / 100,
epochs=90,
layers='heads')
model.train(dataset_train, dataset_val,
learning_rate=config.LEARNING_RATE / 100,
epochs=120,
layers="all")
 freezurbern
on 20 Mar 2019
freezurbern
on 20 Mar 2019
Hi @freezurbern -- I have a question on the following:
I have a dataset of about 150 images. I have used image augmentation to multiply that to over 1000 images.
I was wondering if using imgaug.augmenters adds on to the training data or just replaces them. Also, are the same augmentations applied in every epoch of the training?
 ectg
on 21 Mar 2019
ectg
on 21 Mar 2019
I was wondering if using imgaug.augmenters adds on to the training data or just replaces them. Also, are the same augmentations applied in every epoch of the training?
I am using imgaug before training to save the images to disk. This allows me to inspect them before training. I am using the same library as the on-the-fly use in the Mask R-CNN.
I augment the training data and add, not replace it. The original images are valuable for training and are included in the final training dataset. Please see some code below you may find helpful:
Augmenter[0] = iaa.meta.Noop() # No Operation, a way to pass non-augmented images to the dataset
Augmenter[1] = iaa.Sequential([
iaa.Fliplr(1)
])
Augmenter[2] = iaa.Sequential([
iaa.Flipud(1)
])
Augmenter[3] = iaa.Sequential([
iaa.Flipud(1),
iaa.Fliplr(1)
])
for augIDX, augType in enumerate(Augmenter):
print("\nPlease wait, running Augmenter: " + str(augIDX))
thisAugOut = list(Augmenter[augIDX].augment_batches(thisBatch, background=True))
Hey, thanks. So far I have been using the "on the fly" augmenter that is sent as a parameter to model.train(), and I think it replaces the images instead of adding to the existing training set. Not sure though.
If I augment the images beforehand(which is what I prefer), how do I ensure that the masks are augmented similarly?
ectg
on 21 Mar 2019
If I augment the images beforehand(which is what I prefer), how do I ensure that the masks are augmented similarly?
imgaug is capable of augmenting the masks as well. However, I do not use their mask support. My masks are binary PNGs, so I run the same augmentation on the training images and the training masks. After augmentation, I convert the mask PNGs to COCO JSON.
I don't know anything about using it, but here's the link to augmenting masks: https://imgaug.readthedocs.io/en/latest/source/examples_segmentation_maps.html
freezurbern
on 22 Mar 2019
Thank you @freezurbern for your such kind and valuable suggestions.
I have tried to improve the accuracy and got some results by changing the factor of confidence from 90% to 60% and i managed to get somehow the cracks.
Not sure, how well does the augmentation helps in masking but I'm finding difficulties in augmenting data. The other parameters you mentioned for epochs, rate, steps and others might lend me a helping hand in getting more stable and accurate model. I will try to regenerate new model and see if that works.
I wonder what annotation tool did u used. I previously tried Matlab Image labeler to generate binary mask values and make json files but the data was not somehow propely loaded although it was pixel wise annotation. And what detection were you trying to get ?
Thanks
-Rakeh
rakehsaleem
on 22 Mar 2019
@freezurbern
One importnt thing to ask Can we annotate multiple annotations in one images of same class. Like If I want to annotate more than 3 or 4 cracks in single image. would it be able to train the files or we have to stick with one annotation per class per image ? Anyone if tried kindly respond..
Thanks
-Rakeh
rakehsaleem
on 22 Mar 2019
@freezurbern Thanks! Will take a look.
@rakehsaleem, VIA is a nice and easy annotation tool, it is referenced here. Mask_RCNN-master\samples\balloon\balloon.py has some sample code for loading VIA masks exported as json.
ectg
on 22 Mar 2019
Not sure, how well does the augmentation helps in masking but I'm finding difficulties in augmenting data.
I wonder what annotation tool did u used.
My annotations are PNGs created in image editors like GIMP, Adobe Photoshop, etc. I'm still looking for ways to annotate for non-experts. Please see the images below of the annotation and the source image.
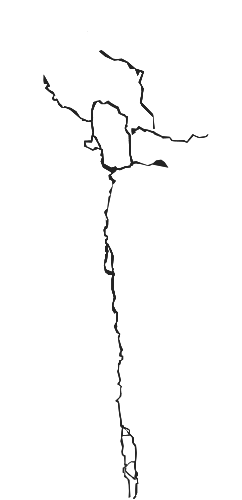

After creating these annotations as images, I convert them to the COCO JSON used in the Mask R-CNN with this repo based on this tutorial
One importnt thing to ask Can we annotate multiple annotations in one images of same class. Like If I want to annotate more than 3 or 4 cracks in single image. would it be able to train the files or we have to stick with one annotation per class per image ? Anyone if tried kindly respond..
YES! I have up to ten different cracks labelled in each image. These are labelled separately and seen as "different" instances to the Mask R-CNN.
@rakehsaleem, VIA is a nice and easy annotation tool, it is referenced here. Mask_RCNN-master\samples\balloon\balloon.py has some sample code for loading VIA masks exported as json.
Thanks for the links!
freezurbern
on 22 Mar 2019
Thanks for your suggestion. Can I see some referenced masked image to see how good is it performing..
Thank you.
rakehsaleem
on 22 Mar 2019
@freezurbern You have specified that you used resent50 backbone, did you downloaded the pretrained coco weights using resent50 architecture or used the same resenet101 weights?.
You have added three model.train commands one after another why?. Will improve the model accuracy.
 Niranjankumar-c
on 3 Apr 2019
Niranjankumar-c
on 3 Apr 2019
@Niranjankumar-c
You have specified that you used resent50 backbone, did you downloaded the pretrained coco weights using resent50 architecture or used the same resenet101 weights?
I used the Mask R-CNN utils.download_trained_weights(COCO_MODEL_PATH) function to download the pretrained weights from https://github.com/matterport/Mask_RCNN/releases/download/v2.0/mask_rcnn_coco.h5
Now that I think about it, I'm not sure whether the pretrained weights from matterport are resnet50 or resnet101.
You have added three model.train commands one after another why?. Will improve the model accuracy.
I used multiple training commands to train with a progressively smaller learning rate. I have since found this approach incorrect and should instead use decay in the optimizer.
freezurbern
on 9 May 2019
I am working on a similar project. How was your results though? USing VIA, you can annotate more than 1 object within same class in one picture. The VIA will distingusih them as 1, 2 ,3 ,4 .... Now, did you get a good loss results ?
 kimile599
on 28 Nov 2020
kimile599
on 28 Nov 2020
Hi @kimile599, thank you for your query here. So back then I was using for single-class object detection and if you have read some blogs or post, you know that the results are better for multi-class compared to a single class. Well, coming back to your original question, I was getting significant loss in terms of numbers for validation results (around 15-20%) but my prediction results were quite good with much better mask predictions. Also, you might have seen that the validation loss suffers from overfitting and this is something I still haven't solved out.
rakehsaleem
on 30 Nov 2020
Hi @kimile599, thank you for your query here. So back then I was using for single-class object detection and if you have read some blogs or post, you know that the results are better for multi-class compared to a single class. Well, coming back to your original question, I was getting significant loss in terms of numbers for validation results (around 15-20%) but my prediction results were quite good with much better mask predictions. Also, you might have seen that the validation loss suffers from overfitting and this is something I still haven't solved out.
Good to know that you got a decent prediction results. I am on a 4 class detection project. The loss is around 0.1. When i test my dataset, in a picture with many objects in 4 classes, only 1 class is masked and detected. I am not sure if you came cross the same situation. Thank you for your time.
kimile599
on 30 Nov 2020
Related issues
 wjdhuster2018
·
3Comments
wjdhuster2018
·
3Comments
 apptech-evan-huang
·
3Comments
apptech-evan-huang
·
3Comments
 simonhandsome
·
3Comments
simonhandsome
·
3Comments
 taewookim
·
4Comments
taewookim
·
4Comments
 ziyigogogo
·
3Comments
ziyigogogo
·
3Comments
Most helpful comment
I am working on a similar topic, with small objects being detected by this Mask RCNN. Some strategies you may find helpful:
For comparison, I have a dataset of about 150 images. I have used image augmentation to multiply that to over 1000 images. I have had good results with:
and: