Marlin: [BUG] Layer shifting: Reports and solutions
Is anybody else seeing layer shifts on BugFix 2.0.0 ? I'm seeing one or two of them on long prints. I'm seeing them on the X-Axis (and mostly in the negative X direction).
I'm running an IDEX machine. So mostly, I'm asking if anybody is seeing layer shifts on non-IDEX machines.
Anybody???
UPDATE: I think we know this problem affects non-IDEX machines also. If you are seeing Layer Shifts, please update this thread and let us know what you are seeing.
 Roxy-3D
Roxy-3D
All 497 comments
I'll chime in quickly to confirm multiple idex machines, and rolling back to 1.1.9 problem vanishes. Working on matching settings and trying to reproduce elsewhere now.
 InsanityAutomation
on 12 Nov 2018
InsanityAutomation
on 12 Nov 2018
If you have S-Curve acceleration, try disabling it and check if you still get layer shifting (see https://github.com/MarlinFirmware/Marlin/issues/12398).
 nemphys
on 14 Nov 2018
nemphys
on 14 Nov 2018
If possible, please narrow down to a specific date where the problem starts to manifest. This can be done in LOG2(n) steps by following this procedure:
- Test October 1 and see if the problem exists.
- Yes? << Test September 1 and see if the problem exists.
- No? >> Test September 15 and see if the problem exists.
- Yes? << Test September 8 and see if the problem exists.
- Yes? << Test September 4 and see if the problem exists.
- No? >> Test September 6 and see if the problem exists.
In this manner the issue can be narrowed down to a specific date.
References: #9487, #9768, #11047, #11479, #11577, #11801, #11885, #12239, #12365
 thinkyhead
on 14 Nov 2018
thinkyhead
on 14 Nov 2018
Hello,
I have the same problem on a CoreXY with a MKS SBase motherboard.
I have done several tests in my case the deactivation of the S-curve acceleration does not change anything.
I will test with the code versions as you request tonight.
After having made many attempts to print the same G-code, the shift of the layers is not random. All the parts I have printed that all have the same offset (all the parts are identical).
 Christophe76350
on 14 Nov 2018
Christophe76350
on 14 Nov 2018
That is helpful information. I have so far not been able to reproduce the issue, so if it can be narrowed down to some specific change that will be very useful.
thinkyhead
on 14 Nov 2018
To keep some of the discord info here as well, first user reports of shifts came to me on October 20th. I'll have another machine here Friday to give me more opportunity to test, since it only occurs on long prints it'll be a bit slow going to track down.
InsanityAutomation
on 14 Nov 2018
To keep some of the discord info here as well, first user reports of shifts came to me on October 20th.
My experience is similar. Using a branch from September 21st... I am NOT seeing the failure.
UPDATE: I think I just saw a shift in both the X & Y axis with the September 21st code.... Damn!!!!
Roxy-3D
on 14 Nov 2018
Test with the version of October 29th last night same problem. I do a test with the version of October 15th tonight.
Christophe76350
on 15 Nov 2018
I flashed Oct 13th last night and am running things now.
InsanityAutomation
on 15 Nov 2018
version of October 15th same problem for me.
Christophe76350
on 15 Nov 2018
October 1st version no layer shift for me it's okay.
Christophe76350
on 15 Nov 2018
October 1st version no layer shift for me it's okay.
I'm not sure that is true! Would you mind doing another long print with it please? I'm pretty sure I saw a dual X & Y layer shift with the September 21st code.
Roxy-3D
on 15 Nov 2018
First photo firmware on October 1.
Second photo firmware dated October 15th.
The screws show the offset of the layers well.


Christophe76350
on 16 Nov 2018
Omg so much??? Good to know I have 1.1.9 bugfix for now
 Atatoth
on 16 Nov 2018
Atatoth
on 16 Nov 2018
So, sounds like some change between Oct 1-15 is affecting some (so next try Oct 8). And maybe something from around Sept 21 is affecting others (so next try Sept 25). I'll look at changes between Oct 1-15 and see if there are any suspect commits.
thinkyhead
on 16 Nov 2018
I did a test at the 7 cotobre (last committee of the day) no problem.
I'm trying again on October 15th I have a doubt about the firmware I flashed for the test on October 15th (sorry).
Do you want my configuration files? If it helps, I use the same ones for each compilation.
Edit : No problem with the code of October 15th (still sorry) so for the moment: October 15th ok / October 29th not ok. Next test with the October 21 version.
Edit 2 : October 21th it's ok
Christophe76350
on 16 Nov 2018
i'm losing steps with the latest 2.0.x too, i'll try to rollback to 1.1.6, which some people are reporting is working fine. I'm using a corexy with tmc2130
 italocjs
on 16 Nov 2018
italocjs
on 16 Nov 2018
What low level things are different between 2.0.0 and 1.1.6 ? It is probably not a stepper driver losing steps because of timing differences. The reason I say that is with IDEX machines in Duplication mode, both extruders are losing position at the same time (and the same amount).
It feels more like a set_directions() call is missing or getting out of phase with other things happening...
Roxy-3D
on 16 Nov 2018
I still had issues with Oct 13th here. Just flashed Sept 27th and I'm running again. I'm using the same 30hr gcode for every test. 2nd idex machine got delayed, didn't see it occur on the singlenozzle crx. Still more to go...
InsanityAutomation
on 17 Nov 2018
I still had issues with Oct 13th here. Just flashed Sept 27th and I'm running again. I'm using the same 30hr gcode for every test.
I'm using the exact same .GCode file. And on that print, I had a small X Axis shift after about 10 hours. And that is with the Sept. 21st code base (bugfix 2.0.0).
Roxy-3D
on 17 Nov 2018
If Sept 21 is bad, then try Sept 1 and see if it works. If it does, then try Sept 10, and so on… Too bad we can’t find a short print that consistently causes the issue to occur.
I will look at the set_direction behavior and see if anything obvious stands out.
thinkyhead
on 17 Nov 2018
I'm going all the way to the 1.1.9 release date of 2.0 since we don't see it in 1.1.9 but have yet to find a good 2.0 date. Just built aug3rd (3 days forward but the couple commits are minor and stop idex crashing was pulled from 1.1)
InsanityAutomation
on 18 Nov 2018
If Sept 21 is bad, then try Sept 1 and see if it works.
Actually.... I've gone a different path. I loaded up the current 1.1.9 and back ported a few things I need into it. I'm 8 hours into a print and so far, no problems... If the print finishes OK, I'll kick off another large print on it to confirm the problem is not on 1.1.9.
Roxy-3D
on 18 Nov 2018
I wish that would tell us about 2.0, but who knows where the problem lies? It might be associated with display update, serial communication, G-code parsing, or any number of things. But if you happen to port something into 1.1.9 that causes bad behavior, that would be a great find.
thinkyhead
on 18 Nov 2018
Fyi I'm using SD to eliminate serial errors and monitor from my PC while it's running.
InsanityAutomation
on 18 Nov 2018
@InsanityAutomation my screen and sd support are disabled, i'm printing trough octoprint. so i dont believe they are causing the problem. i
italocjs
on 18 Nov 2018
I wish that would tell us about 2.0, but who knows where the problem lies?
Mostly... I'm looking for a point in time without the problem. (and I do have some large prints I have to get done) But I'm starting to suspect the planner:: changes to merge lines to avoid stutter.
It would be good to have a 2.0.0 version that had planner:: stutter changes taken out of it.... I think there is a 50%-50% chance the problem goes away if we do that.
Roxy-3D
on 18 Nov 2018
After a lot of testing since my last message my layer shifts occur if I enable "Z_STEPPER_AUTO_ALIGN" during compilation.
Whether I use G34 or not in my G-code I have layer shifts.
If I compile the firmawre without the "Z_STEPPER_AUTO_ALIGN" my prints are correct without layer shift.
I think this is another problem than the one addressed in this post.
Christophe76350
on 18 Nov 2018
If I compile the firmware without the "Z_STEPPER_AUTO_ALIGN" my prints are correct without layer shift.
Several of us with layer shifts do not (and never have had) Z_STEPPER_AUTO_ALIGN enabled. I don't think this is the cause.
But I have more information. The long 1.1.9 print I did last night came out OK. I'm going to run another long print today and into the night with 1.1.9.
Roxy-3D
on 18 Nov 2018
That's why I think my problem is not necessarily the same as the one being sought here.
In all this in my case it has an influence on my layer shift. But the tests I did on different versions of the firmware certainly don't give any indication of your problems.
One thing is certain after having performed a tenth test for me the activation of Z_STEPPER_AUTO_ALIGN causes a layer shift for sure.
I'm not saying that this is not a different problem I'm just giving the results of my tests.
Christophe76350
on 18 Nov 2018
One thing is certain after having performed a tenth test for me the activation of Z_STEPPER_AUTO_ALIGN causes a layer shift for sure.
Thank You for the careful analysis!!!
Roxy-3D
on 18 Nov 2018
Thank You for the careful analysis!!!
I'm not here to fight. I thought the purpose of a beta was to debug all the bugs I see that I'm sorry to see that I wanted to make things progress by doing tests.
I didn't take into account the tests I did I must be crazy and the results I got are irrelevant after all. If my problems appear in others they will probably be like me crazy. After all, after counting the total number of prints I made to test the problem, 20 pieces whose result still depends on activating the same parameter or deactivating the parameter represents nothing.
I go back to smoothieware and am really disappointed with the way things are interpreted here so. If some people doesn't find a bug it's probably because it doesn't exist.
Christophe76350
on 18 Nov 2018
Thank You for the careful analysis!!!
I'm not here to fight. I thought the purpose of a beta was to debug all the bugs I see that I'm sorry to see that I wanted to make things progress by doing tests.
That comment was sincere! If somebody is willing to print 10 times to gather evidence, that counts as careful analysis!!!
In your prints.... Do you see the failure at the same place in the print? Or does it fail at random times? In the layer shifting I'm seeing, it happens at random times.
But I'm very sure it is not just a stepper motor that wasn't strong enough be cause some times it has both X & Y shifted. And @InsanityAutomation has seen the layer shift on an IDEX machine in Duplication mode. So it wasn't just one stepper that lost steps. It was two at the same time.
Roxy-3D
on 18 Nov 2018
Confirmed that it was the X axis shifting in duplication mode? Of course Y shift in duplication mode would have no special significance.
thinkyhead
on 18 Nov 2018
And @InsanityAutomation has seen the layer shift on an IDEX machine in Duplication mode. So it wasn't just one stepper that lost steps. It was two at the same time.
Confirmed that it was the X axis shifting in duplication mode? Of course Y shift in duplication mode would have no special significance.
That is what I remember. I'm sure he will jump in with confirmation soon. (At the time we were talking about multiple steppers losing position at the same time. That is why I think this is true.)
Roxy-3D
on 18 Nov 2018
Yes, it was x that shifted both parts in duplicate mode. I'll dig up the photos from the end user who first reported it later tonight.
InsanityAutomation
on 18 Nov 2018
@Christophe76350
you could try to increase stepper pulse width manually in Configuration_adv.h :
#define MINIMUM_STEPPER_PULSE 4
I had layer shifts with CoreXY, LPC1768 and DRV8825 that lead to "skewed" prints like in your picture
Issue #11047
 kAdonis
on 19 Nov 2018
kAdonis
on 19 Nov 2018
In your prints.... Do you see the failure at the same place in the print? Or does it fail at random times? In the layer shifting I'm seeing, it happens at random times.
The layer shifts are all the same with each impression. There is nothing random, I had a moment to question the mechanics but no problem on this side. I have a second mechanically identical one that works with a Rhumba motherboard and the no layer shift on the same Gcode with the firmware compiled with Z_STEPPER_AUTO_ALIGN enabled.
@Christophe76350
you could try to increase stepper pulse width manually in Configuration_adv.h :
#define MINIMUM_STEPPER_PULSE 4I had layer shifts with CoreXY, LPC1768 and DRV8825 that lead to "skewed" prints like in your picture
Issue #11047
I'm currently testing.
Christophe76350
on 19 Nov 2018
Issue #12491 could be related, but would mean this layer shifting is due to skipped steps.
A couple ideas:
- Test with unloaded steppers and see if they maintain position
- Slow down the stepper ISR (to ~1/4th the frequency). Keeping all curve computation the same while slowing down the step rate would reduce the chance for missed steps. But if it's a logic issue, the skew will still be apparent (unless it's a timing issue/interaction with another ISR).
 xenovacivus
on 20 Nov 2018
xenovacivus
on 20 Nov 2018
Don't give up trying to narrow down the specific day that the issue appeared. These threads tend to go on forever with speculations, when the best use of time would be to meticulously seek out the specific commit that introduced the problem.
thinkyhead
on 20 Nov 2018
I'm 30hrs in on the Aug 3rd snapshot with no issues. From there we can safely say the issue appeared in 2.0 later, and was not a result of the refactoring. I have another machine now validating Sept21st however if it's anything like the bugs fixed for 1.1.9 some machines never saw it and some couldn't get rid of it.... I honestly don't know how to ensure I hit the worst case scenario here to force a machine to skip steps, so if the machine has never skipped I don't know if it ever will....
InsanityAutomation
on 20 Nov 2018
Have we checked for a correlation between stepper driver types or motherboard?
 landodragon141
on 20 Nov 2018
landodragon141
on 20 Nov 2018
Fyi, brand new machine out of the box with factory firmware dated sept21st layer shifts on X using the same gcode I'm running on the other machine. Aug 3rd snapshot now has 38hrs with no shift.
InsanityAutomation
on 21 Nov 2018
Have we checked for a correlation between stepper driver types or motherboard?
I didnt noticed any issues using the latest firmware with the a4988, only with the tmc2130
italocjs
on 21 Nov 2018
Worth noting one machine is all stand-alone tmc2208 spreadcyle, the other is 4988 on both X and tmc standalone spreadcyle on y.
InsanityAutomation
on 21 Nov 2018
I have another machine now validating Sept21st however if it's anything like the bugs fixed for 1.1.9 some machines never saw it and some couldn't get rid of it....
I have also seen the layer shifts with a September 21st code base. Right now, I think we have two book ends. The problem seems to have been introduced somewhere between August 3rd and September 21st.
Roxy-3D
on 21 Nov 2018
I'm also have this nasty issue. D-bot CoreXY 1.7A steppers.
Few days ago changed RAMPS 1.4+mega2560 w marlin 1.1.8 for RURAMPS4D 1.3 + DUE.
TMC2130 SPI on X,Y,E . TMC2208 in standalone on Z. Homing with endstops. TMC2130 lib v 2.5.0. 800ma/16 steps in adv.cfg. Tried to set from 700ma to 1000ma without any result, switcing on/off hybrid mode didb't help as well. What left ? Try to disable stealthchop, S-curve, older TMC 2130 lib ?
Shifs occur at speeds over 50mm/s. Acceleration is set to 1000.
I'm kinda tired, almost every print is ruined. Wanted to increase printspeed, but did increase a hedache.
Could anybody post a link to Pre-August 2.0 build ?
 NKote
on 21 Nov 2018
NKote
on 21 Nov 2018
Not sure if my issues are related, but I experience extreme shifting with TMC2208:

Although I'm still dialling in the new configuration, this x-axis shift happened a few times already with the same print. It's a fairly simple bracket printed through octoprint. Est. print time was 1:35 and the . shift started right away but became really noticable around 5%. The x-axis eventually is so far off, the hot-end keeps banging on the x-min stop… This happened with manual mesh bed levelling, tonight I'll try again with turned levelling off. No problems at all with homing or manual movement via Gcode, printing via Cura through USB or Octoprint or setting a higher/lower current.
Machine: Ender-3
Board: Fysetc F6 v1.3
Drivers: TMC2208 drivers (Watterott, configured through software serial)
Power: 24v
X Stepper current: 700mA
Microsteps: 16
Mode: Stealthchop (hybrid mode off)
Marlin: 0946cbcdca99d833d1a4667d00daf112394107c0 (but this happened with older commits too)
 ErikFontanel
on 21 Nov 2018
ErikFontanel
on 21 Nov 2018
I've tryed some print and found that S-Curve acceleration and different TMC2130 libraries doesn't affect the shifting at all. decreasing speed to 50mm\s or switching to spreadcycle (hell, its noisy!!!) helps. And the drivers are really hot. 60 degrees at least, although they are fan-cooled. With RAMPS 1.4. it was OK even at 80mm\s.
NKote
on 21 Nov 2018
Looks like we're getting closer. Let's try Sept 1st next!
thinkyhead
on 22 Nov 2018
I have a print 25hrs in on a sept1st snapshot. No shifts yet.
InsanityAutomation
on 22 Nov 2018
Question not really related: i reverted back to the 1.1.9 marlin, and i'm setting things up. Which hybrid threshold is a good start value for a 1.7a 4kg stepper? i heard is best to keep spreadcycle for high speeds
italocjs
on 24 Nov 2018
I'm kinda tired, almost every print is ruined. Wanted to increase printspeed, but did increase a hedache. Could anybody post a link to Pre-August 2.0 build ?
Question not really related: i reverted back to the 1.1.9 marlin, and i'm setting things up.
I understand the frustration! But the early information points to September 1st being OK. Instead of scampering off to all kinds of different points in the code base, it would be very helpful if the people that need a solid base all re-group at BugFix 2.0.0 as of September 1st. That should give us several things. Most importantly, we will get more confirmation the problem wasn't in the code base prior to that point of time.
Here is a pointer to August 31st. (I don't know what time of day people's September 1st snap shot were taken. So this is one day before everybody's report of OK.)
https://github.com/MarlinFirmware/Marlin/tree/74a04aed552fa7f93ef42fe3e5e4f095dda4aac6
Roxy-3D
on 24 Nov 2018
Thanks a lot. Got insulting shift on 3h print with november build at 45mm\s.
But with one you sent me link to all went perfect at 50mm\s ! And drivers, as well as motors are defenitely cooler than with the november build.
NKote
on 25 Nov 2018
I'm also have this nasty issue. D-bot CoreXY 1.7A steppers.
Few days ago changed RAMPS 1.4+mega2560 w marlin 1.1.8 for RURAMPS4D 1.3 + DUE.
TMC2130 SPI on X,Y,E . TMC2208 in standalone on Z. Homing with endstops. TMC2130 lib v 2.5.0. 800ma/16 steps in adv.cfg. Tried to set from 700ma to 1000ma without any result, switcing on/off hybrid mode didb't help as well. What left ? Try to disable stealthchop, S-curve, older TMC 2130 lib ?
Shifs occur at speeds over 50mm/s. Acceleration is set to 1000.
I'm kinda tired, almost every print is ruined. Wanted to increase printspeed, but did increase a hedache.
Could anybody post a link to Pre-August 2.0 build ?
try using the 1.1.9 if possible, after changing to it, i'm not having any shifts, printing now at 80mm/s with mov speed of 100mm/s. using tmc2208 with full stealthchop
italocjs
on 25 Nov 2018
Just to update, over 100hrs running the sept1st snapshot here without a shift yet. A few more customer parts to get out and I'll bump up to Sept 15th.
InsanityAutomation
on 25 Nov 2018
Using a July download of the 2.0 firmware, changed from repetier. Has layer walking in the X and Y when printing with OctoPrint, same Gcode prints fine when printing from SD card. Just downloaded and configured a Nov version, downloaded 11-23. Still have the layer walking with OctoPrint
Hardware:
Due w/ RADDS shield, DRV8825
CoreXY
 kwalters3
on 27 Nov 2018
kwalters3
on 27 Nov 2018
A possibility??? https://github.com/MarlinFirmware/Marlin/issues/12540#issuecomment-442267831
Roxy-3D
on 28 Nov 2018
Given that the torture gcode were using is a massive amount of short jerky moves, it very much sounds like we're dealing with the same issue!
InsanityAutomation
on 28 Nov 2018
A possibility?
Strangeness in the acceleration handling could certainly be involved. I’ll look at it and review changes made in that region of the code over the past few months.
thinkyhead
on 28 Nov 2018
Fyi, I finally got a machine opened back up and now running the current snapshot but with junction deviation on instead of traditional jerk. If it is good with the torture test here, I'll turn junction deviation back off to confirm it's still present today. If no change, I'll go back to Sept 15th, before the planner overhaul for fwretract.
InsanityAutomation
on 30 Nov 2018
Fyi, current code base with junction deviation was notably slower than with traditional jerk, after a 47hr print finished (that took 36hrs before) it only had a single shift that was half the size of what they were previously. This was between 40 and 45hrs in. Again same gcode. I should start selling these lithos with a single shift here or there just to get material cost back lol
InsanityAutomation
on 2 Dec 2018
That's why I think my problem is not necessarily the same as the one being sought here.
In all this in my case it has an influence on my layer shift. But the tests I did on different versions of the firmware certainly don't give any indication of your problems.
One thing is certain after having performed a tenth test for me the activation of Z_STEPPER_AUTO_ALIGN causes a layer shift for sure.
I'm not saying that this is not a different problem I'm just giving the results of my tests.
@Christophe76350 Hey, I hope you keep testing. You have definitely found something and I can absolutely confirm that #11302 is also causing significant layer shifting for me. Been trying everything to pinpoint the cause until I saw your post and decided to comment out Z_STEPPER_AUTO_ALIGN.
Here are before and after images of some prints of the 20mm hollow calibration cube. The image on the left is w/o s-curve acceleration and adaptive step smoothing enabled, the right image is with those two featured turned on.
With Z_STEPPER_AUTO_ALIGN enabled:

With Z_STEPPER_AUTO_ALIGN commented out:

As you can see, with Z_STEPPER_AUTO_ALIGN commented out, there is a significant reduction in layer shifting (doesnt seem to be completely gone).
This was printed on a CoreXY machine running Nov 30 git of bugfix-2.0.0 on an LPC1768 (mks-sbase).
 gururise
on 3 Dec 2018
gururise
on 3 Dec 2018
I'm wondering if we should back out all planner and stepper motor changes going back to Sept. 1st. And then slowly, and carefully start adding things back in. And maybe not in the original merge order.
A strategy like that might help us figure out what is causing the trouble.
Roxy-3D
on 5 Dec 2018
There do appear to be quite a few combination of things having an impact here which is what's making it so difficult to pin down...
InsanityAutomation
on 5 Dec 2018
I believe the G34 issue I posted above is related to #11205
gururise
on 5 Dec 2018
I had a couple of layer shifts yesterday and today. Both were in the Y direction.

That one shifted 2.0 mm.
The next one shifted 19.2mm and later 22.9 mm.

I home to the Y MAX endstop so I deliberately ran the head into the Y MAX endstop to see what position it reported. The endstop message said 477.72. It should have been 436.0 so the Y positioning was off by 41.7 mm. The two shifts totalled 42.1 mm so we have a reasonable agreement in offsets.
After hitting the endstop I immediately did a M114 and it reported a Y of 600 with a Y count of 189666.
Next I did a G28 which gave me a Y of 436 with a count of 173102.
The difference between the two counts divided by my steps-per-mm give a distance of 41.72 mm.
Something definitely messed with the coordinate system.
The only recent changes I've made were to enable JUNCTION_DEVIATION , ADAPTIVE_STEP_SMOOTHING and LIN_ADVANCE. I do NOT have S curve acceleration nor Z_STEPPER_AUTO_ALIGN enabled.
I'll back those three changes out and restart the last print. The first shift happened at the 10-12 hour point so it'll be late Wednesday before I have confidence that the shift has gone away.
 Bob-the-Kuhn
on 5 Dec 2018
Bob-the-Kuhn
on 5 Dec 2018
The only recent changes I've made were to enable JUNCTION_DEVIATION ADAPTIVE_STEP_SMOOTHING and LIN_ADVANCE. I do NOT have S curve acceleration nor Z_STEPPER_AUTO_ALIGN enabled.
I have never had any of these enabled. And I have seen the layer shift problem on bugfix 2.0.0 in the past month.
Roxy-3D
on 5 Dec 2018
I take it the only alternative is to go back to one of the dates that Scott mentions and use that to print the problem object.
I'm going to go straight to 1 Sep. My home built has been driving me nuts & I don't have the time to narrow down the date where the problem started.
Bob-the-Kuhn
on 5 Dec 2018
Just commenting as an observer: It might be useful to track the git hash + config files for every observation, it might help chasing down other factors that might not immediately be obvious. A lot of testing has been done, it would be good to know on which hash exactly and what features were enabled / disabled? My 2 ct.
 swilkens
on 5 Dec 2018
swilkens
on 5 Dec 2018
I grabbed the 2018-09-01 Bugfix2.0 but still had a layer shift at about 8 hours into the print.
Are the dates in Scott's post 2017 or 2018?
Are these shifts only happening when Z changes or can they happen in the middle of a layer? My latest shift was less than the width of the wall so about 2/3 of the shift was over the plastic on the previous layer. Under a magnifying glass I couldn't find any Z discontinuities in the first layer of the shift.
Bob-the-Kuhn
on 6 Dec 2018
@Bob-the-Kuhn These are for 2018
landodragon141
on 6 Dec 2018
Just caught a layer shift before it went to the next layer.
In the lower left is the normal infill. Across the top is the shifted infill.

I think I'm running the Bugfix 2.0 code from the last commit on 1 SEP 2018. I went to history, scrolled/paged to the last commit on 1 SEP 2018, clicked on the "browse repository at this point" and then downloaded the ZIP. The configuration files are very different than the 3 DEC 2018 ones (the latest one I downloaded).
Bob-the-Kuhn
on 6 Dec 2018
I reprinted the shifted layer and can pinpoint exactly where the shift happened.
The infill was proceeding normally from lower right to lower left and then up the left side to the second small hole where it would stop and then resume at the yellow highlighted area and then proceed right to left..
The area outlined in green is where the problem started. It should have been printed before the area in yellow but was skipped entirely.
The area in yellow is the first of the shifted printing. It should be touching the large circle and stopping at the first straight line.

Bob-the-Kuhn
on 7 Dec 2018
It would be great if we can get some gcode that causes the shift... That would make it fairly straight forward to debug and find the flaw.
Roxy-3D
on 7 Dec 2018
My initial reaction is that re-running same gcode may or may not reproduce the shift because I've had different shifts on one object and on another object one pass and one shift but … I'm pretty sure I changed bugfix dates/snapshots and probably re-sliced between the two runs.
I've started a (hopefully) 26 hour build using the 31 AUG snapshot. I'd really like to have that succeed before I start doing 6 hour prints trying to reproduce the issue.
Is there a know good date?
Bob-the-Kuhn
on 7 Dec 2018
Is there a know good date?
I thought Sept. 1st was good. But your test up above is calling that into question.
Roxy-3D
on 7 Dec 2018
Here's the gcode from the problem area in the shifted layer:
; missing area starts in next 5-15 lines
G1 X 80.917 Y 146.889 E 30.43964
G1 X 81.627 Y 146.740 E 30.46808
G1 X 78.332 Y 150.035 E 30.65089
G1 X 78.893 Y 150.035 E 30.67290
G1 X 82.336 Y 146.592 E 30.86395
G1 X 83.045 Y 146.443 E 30.89239
G1 X 79.454 Y 150.035 E 31.09167
G1 X 80.015 Y 150.035 E 31.11368
G1 X 83.755 Y 146.295 E 31.32121
G1 X 84.464 Y 146.147 E 31.34965
G1 X 80.576 Y 150.035 E 31.56541
G1 X 81.137 Y 150.035 E 31.58742
G1 X 85.183 Y 145.989 E 31.81192
G1 X 86.317 Y 145.416 E 31.86180
G1 X 81.698 Y 150.035 E 32.11813
G1 X 82.259 Y 150.035 E 32.14014
G1 X 87.451 Y 144.842 E 32.42829
G1 X 88.586 Y 144.269 E 32.47816
G1 X 82.820 Y 150.035 E 32.79813
G1 X 83.381 Y 150.035 E 32.82014
G1 X 89.720 Y 143.695 E 33.17193
G1 X 90.200 Y 143.453 E 33.19303
G1 X 90.233 Y 143.743 E 33.20451
G1 X 83.942 Y 150.035 E 33.55363
G1 X 84.503 Y 150.035 E 33.57564
G1 X 90.290 Y 144.247 E 33.89681
G1 X 90.347 Y 144.751 E 33.91670
G1 X 85.064 Y 150.035 E 34.20991
G1 X 85.625 Y 150.034 E 34.23194
G1 X 90.421 Y 145.238 E 34.49808
G1 X 90.579 Y 145.641 E 34.51506
G1 X 86.186 Y 150.034 E 34.75887
G1 X 86.747 Y 150.034 E 34.78088
G1 X 90.738 Y 146.043 E 35.00235
G1 X 90.971 Y 146.371 E 35.01813
G1 X 87.308 Y 150.034 E 35.22143
G1 X 87.868 Y 150.035 E 35.24342
G1 X 91.210 Y 146.693 E 35.42885
G1 X 91.320 Y 146.842 E 35.43611
G1 X 91.488 Y 146.976 E 35.44455
G1 X 88.429 Y 150.035 E 35.61429
G1 X 88.990 Y 150.035 E 35.63630
G1 X 91.800 Y 147.225 E 35.79224
G1 X 92.123 Y 147.463 E 35.80798
G1 X 89.551 Y 150.035 E 35.95069
G1 X 90.112 Y 150.035 E 35.97270
G1 X 92.513 Y 147.633 E 36.10596
G1 X 92.904 Y 147.804 E 36.12268
G1 X 90.673 Y 150.035 E 36.24651
G1 X 91.234 Y 150.035 E 36.26852
G1 X 93.379 Y 147.889 E 36.38758
G1 X 93.867 Y 147.963 E 36.40694
G1 X 91.795 Y 150.035 E 36.52195
G1 X 92.356 Y 150.035 E 36.54396
G1 X 94.488 Y 147.902 E 36.66230
G1 X 94.863 Y 147.860 E 36.67709
G1 X 95.240 Y 147.712 E 36.69300
G1 X 92.917 Y 150.035 E 36.82193
; start of shifted section
M106 S89.25
G1 E 34.82193 F 2400.00000
G92 E 0
G1 X 93.166 Y 118.933 F 2100.000
G1 E 2.00000 F 2400.00000
M106 S255
G1 F 300
G1 X 92.690 Y 119.409 E 2.02641
G1 X 92.878 Y 119.782 E 2.04280
G1 X 93.724 Y 118.936 E 2.08972
G1 X 94.282 Y 118.939 E 2.11162
G1 X 93.067 Y 120.154 E 2.17906
G1 X 93.255 Y 120.527 E 2.19544
G1 X 94.987 Y 118.795 E 2.29155
G1 X 95.366 Y 118.696 E 2.30690
G1 X 96.021 Y 118.322 E 2.33652
G1 X 93.443 Y 120.900 E 2.47956
G1 X 93.632 Y 121.272 E 2.49
These are lines 1827-1904 in the attached file.
Bob-the-Kuhn
on 7 Dec 2018
The green area is not missing. It's on top of the circles near by.
What's that structure in about the mid of the green area? Is that debris on top of the previous layers infill? Could the nozzle have been caught by that?
 AnHardt
on 7 Dec 2018
AnHardt
on 7 Dec 2018
I'll flash the Sept 1st snapshot back tonight and start another 50hr torture test. See if maybe I just didn't run enough there.
InsanityAutomation
on 7 Dec 2018
I can confirm that I have also have been seeing the layer shifts.
I have not printed in quite a while as I was upgrading my printer to new electronics.
Rearm + TMC2130 drivers. I thought the drivers were at fault and might be something with the re-arm implementation.
It would be good to know what hardware + drivers each person is using (perhaps make a table on the 1st post), and utilize that as a reference. Perhaps we notice a pattern....
 psavva
on 7 Dec 2018
psavva
on 7 Dec 2018
@AnHardt is correct - the "missing" is actually over the circular area.
The layer being printed is the first solid layer. The infill is the 3D Honeycomb frm the Slic3r slicer. The main structure in the middle of the green area is a partial honeycomb. In the picture it looks like there may be some residue from the shifted layer on top of it. I don't remember seeing any residue when looking at the actual part. When looking at the actual part I didn't notice any residie. I expect it's just the way the last infill layer is reflecting light. Other areas of uncovered infill have the same color.
I'm running a Due with A4988 drivers. and 23HS41-1804S steppers. My machine is basically a CNC machine with a 3D print head currently mounted to it. Big, strong & SLOWWWWW.
Bob-the-Kuhn
on 7 Dec 2018
@AnHardt is correct - the "missing" is actually over the circular area.
The layer being printed is the first solid layer. The infill is the 3D Honeycomb frm the Slic3r slicer. The main structure in the middle of the green area is a partial honeycomb.
@Bob-the-Kuhn Does this mean you are no longer convinced the Sept. 1st snap shot is bad? A number of us did long prints with Sept 1st and did not see a problem.
Roxy-3D
on 9 Dec 2018
I definitely had a layer shift with the 1 SEP snapshot. It's just that my "missing" assessment was wrong. The plastic is just in a location I didn't notice.
I currently doing a print of 60 copies of the layer that had a shift. I'm at 45 without a big shift. There was a small shift towards +X by 2 mm about layer 20 and then a shift back at about layer 30.
Lots of possibilities as to why I'm seeing shifts, Could be that I'm occasionally loosing steps.
I did complete a 313 layer 34 hour build this morning using the last commit on 31 AUG 2018. There was somw waviness in the walls but nothing big enough to put calipers on.
I've ordered some rotary encoders. If I can figure out how to use them then I'll be able to better judge the reliability of my hardware.
Bob-the-Kuhn
on 9 Dec 2018
I was getting quite significant layer shift with the latest 2.x, I tried to revert back to 49e107c (the last commit on the 1st of September) but I'm getting the same issue. It solved it by disabled junction deviation (I still need to try to reenable scurve). But this looks to be just a workaround and might just hide the issue, as @Roxy-3D says that problem shows even with this disabled (https://github.com/MarlinFirmware/Marlin/issues/12403#issuecomment-444517607)
- Print with Junction Deviation and Scurve enabled
- Print with Junction Deviation enabled and scurve disabled
- Print with Junction Deviation and Scurve disabled
What's interesting is that the layer shift at the same layer for the first two cubes (and I think a third one from yesterday but I don't have it around to check)

 simon-jouet
on 9 Dec 2018
simon-jouet
on 9 Dec 2018
I'm getting more and more of the opinion we need to back out all Planner and Stepper Motor changes from Sept. 1st to the current time. Verify that is 'clean'. And then very slowly, carefully, and with full testing add the changes back in one at a time.
Does anybody have the skill set and inclination to create a branch like that? If so, we can probably get the community to spread out the work of adding in each subsequent change and help test the different versions.
Roxy-3D
on 20 Dec 2018
I've been seeing a few shifts lately too. I pritnted these today and all 4 are shifted in the same way. Interestingly in the area where simplify3d slows down from between 5-20mm/s.


The other one I printed at the begining of the month and had tried scaling the object. In the slicer it looked normal but then suddenly a whole section was shifted out. Both of these are long prints (first one is .1), second is large on sBase with DRV8825 drivers. I was running with 3us pulses, maybe now I'll increase to 4. I last pulled commits 25 days ago around "fix skew correction".
 forkoz
on 25 Dec 2018
forkoz
on 25 Dec 2018
I also have witnessed layer shifts with bugfix 2.0 on a Anet A8 with a MKS GEN L board with TMC2130's on all motors. Last print had a layer shift in Y axis of approx 1mm at approx the 22nd layer. Then no other anymore. Params were 600ma current on x,y,z,e with 16 microsteps, 10 jerk for x and y, default acceleration set to 400, max to 2000,2000,... Interpolation was ON and drivers are configured for stealthchop and SPI. I'm now going back to 750ma and see if it improves. In any case, the Y motor does get 80°C hot after an hour of printing while X remains at +- 50°C. Strangely enough, with the Anet A8 board, they never reached 45°C, even not after multiple hours of printing.
 DavidThijs
on 29 Dec 2018
DavidThijs
on 29 Dec 2018
After multiple prints without problems, today I suddenly experienced tlayer shifting. As always with 3d printing things can go wrong so I restarted the print. I was suprised to see that the second print had the exact same layer shifting. After looking at the gcode in Cura I could not see strange things and started googling.
Quite quickly I found this topic about the layer shifting bug.
Because nothing much changed about my printer I started thinking what I changed in the slicing software. I rememberd that I turned on acceleration and jerk control (to be honest I think it was only acceleration control) so turned them both off, sliced and restarted the print. This time it printed without any layer shifts.
I use a RAMPS board with a november Marlin 2.0bugfix and Octoprint.
I've used a caliper to measure where the layershift starts and it's around 3mm this should be around layer 15 (0,2mm layer hight)
I also included both files. I hope this is helpful.
Pitan_Body_v1.1.gcode.zip
Pitan_Body_v1.1(no jerk and acc ctrl).gcode.zip
 jvdbrg
on 2 Jan 2019
jvdbrg
on 2 Jan 2019
@jvdbrg have you tried this with a current 2.0.x as well? I recall a change was made around november to the planner which affected the printer behavior when using Cura's acceleration / jerk control feature (https://github.com/MarlinFirmware/Marlin/issues/12364)
It would be interesting to see if you still experience the shift with current 2.0.x
swilkens
on 11 Jan 2019
I also have witnessed layer shifts with bugfix 2.0 on a Anet A8 with a MKS GEN L board with TMC2130's on all motors. Last print had a layer shift in Y axis of approx 1mm at approx the 22nd layer. Then no other anymore. Params were 600ma current on x,y,z,e with 16 microsteps, 10 jerk for x and y, default acceleration set to 400, max to 2000,2000,... Interpolation was ON and drivers are configured for stealthchop and SPI. I'm now going back to 750ma and see if it improves. In any case, the Y motor does get 80°C hot after an hour of printing while X remains at +- 50°C. Strangely enough, with the Anet A8 board, they never reached 45°C, even not after multiple hours of printing.
Update 17/01/2019
Replaced default steppers to 2.0A ones with low inductance. Increased current to 1000mA on x and y. The TMC2130 drivers are cooled with a lot of airflow over the heatsink. Steppers are now only a bit warm approx 35°C. Cura sliced object shows again layer shifts around the 27th and 35th layer. Then no shifts anymore. So I still believe it's firmware or slicer command related and not a hardware issue.



DavidThijs
on 17 Jan 2019
Fails_12-15hrs_in.rar.zip
Attached fails about 10-12 hours in when printing from OctoPrint. If I turn the X/Y stepper current voltage to 1.8V (from 1.2V as stock on the Trex3) and print from SD, then I can get failures within a few hours. This is IDEX, and X layer shifts affects both extruders. The layer that the shifts occur appears to be random. 7 tries at this print before I decided to just do it at 50% scale, which worked fine. It was approximately 9 hours.
 BigE2
on 17 Jan 2019
BigE2
on 17 Jan 2019
Hi @simon-jouet,
I also had layer shifting problems on my HyperCube Evolution CoreXY printer.
As you are printing on a CoreXY with junction deviation enabled, your problem is probably caused by the bug #12851 that I fixed recently.
Mine now runs very fast and smoothly with travel speeds of 300mm/s and travel acceleration of 4500mm/s² and infill print speed of 200mm/s without layer shifts so far.
 HackingGulliver
on 18 Jan 2019
HackingGulliver
on 18 Jan 2019
I have large shifts, too on my CoreXY. I think it was fine after you fixed that bug, but after I compiled and flashed today, every print fails. The printer makes a loud "whump" noise and shifts 1-2 cm. This happens at random layers. Might be completely unrelated to the issue you found.
I lowered the acceleration from 4000 to 1000 and the speed to 100 without any difference. Drivers are TMC2130 running at 900mA 30V. I disabled StealthChop through the new menu item on the lcd and lowered the hybrid threshold to 1. No difference, only a bit louder.
I think it mostly shifts to the lower right.
 hamster65
on 19 Jan 2019
hamster65
on 19 Jan 2019
@hamster65
Yes, that loud "whump" noise is why I investigated the movement behavior of my printer. When the tool head takes a sharp corner, we expect it to slow down and then accelerate again. Therefor I tested the motion with several zig-zag travel moves at high speeds. It turned out that the tool head did not decelerate in some cases (i.e. certain angles) and caused too much load on the steppers which resulted in lost steps.
Here are my tests for my print bed of 30x30cm² that all run fine and smooth now. You will see that the angle between segments gets wider with every script. Maybe you will want to increase travel acceleration, junction deviation and speed in several test runs and see if and when your printer fails.
M204 T4500 ; Travel acceleration
M205 J0.07 ; Junction deviation
G1 Z20 F300
G1 X150 Y20 F24000
G1 X140 Y30
G1 X160 Y40
G1 X140 Y50
G1 X160 Y60
G1 X140 Y70
G1 X160 Y80
G1 X140 Y90
G1 X160 Y100
G1 X140 Y110
G1 X160 Y120
G1 X140 Y130
G1 X160 Y140
G1 X140 Y150
G1 X160 Y160
G1 X140 Y170
G1 X160 Y180
G1 X140 Y190
G1 X160 Y200
G1 X140 Y210
G1 X160 Y220
G1 X140 Y230
G1 X160 Y240
M204 T4500 ; Travel acceleration
M205 J0.07 ; Junction deviation
G1 Z20 F300
G1 X150 Y20 F24000
G1 X140 Y40
G1 X160 Y60
G1 X140 Y80
G1 X160 Y100
G1 X140 Y120
G1 X160 Y140
G1 X140 Y160
G1 X160 Y180
G1 X140 Y200
G1 X160 Y220
G1 X140 Y240
G1 X160 Y260
M204 T4500 ; Travel acceleration
M205 J0.07 ; Junction deviation
G1 Z20 F300
G1 X150 Y20 F24000
G1 X140 Y50
G1 X160 Y80
G1 X140 Y110
G1 X160 Y140
G1 X140 Y170
G1 X160 Y200
G1 X140 Y230
G1 X160 Y260
G1 X140 Y280
M204 T4500 ; Travel acceleration
M205 J0.07 ; Junction deviation
G1 Z20 F300
G1 X150 Y20 F24000
G1 X140 Y40
G1 X160 Y80
G1 X140 Y120
G1 X160 Y160
G1 X140 Y200
G1 X160 Y240
G1 X140 Y280
M204 T4500 ; Travel acceleration
M205 J0.07 ; Junction deviation
G1 Z20 F300
G1 X150 Y20 F24000
G1 X140 Y140
G1 X160 Y280
My TMC2130s are running at 950mA at 24V. However, after some month without issues, I had to increase the step pulse width to 1µs as the extruder motor suddenly stopped turning. (I'm using a 32 bit board (MKS SBASE 1.3) that may be too fast and hence generates too small pulses) .
Stealth chop is no option for me too as it fails miserably at fast travel moves.
S-curve acceleration and adaptive step smoothing are enabled.
My layer shifts mostly happend at the same layer of a print and there were several "whumps" during prints.
HackingGulliver
on 20 Jan 2019
@swilkens I'm currently in the proces of setting up the new firmware. When it is installes, I will try to print the item and get back on this item.
jvdbrg
on 20 Jan 2019
Todays tests was the right 46mm spaced x-carriage holder that can be found on: https://www.thingiverse.com/thing:1428253
6 out of 6 samples had layer shift on every print. No bigger shifts than 2mm. 4 of them have x axis shift, 1 of them has both and 1 of them has shifts on Y axis.
Layer shifts occured very early in the print and seem to be repeatable. I rotated the print object 90° to make the y-axis work harder on some of the samples, still the X is favored for layer changes. Since I use the stock Anet A8 extruder, weight will be the major concern.
I then installed the latest Bugfix 2.0 with the latest TMC library (0.3 I think). Now I have an option in the menu that allows me to turn stealthchop off for x and y. They run in spreadcycle now.
Result, no layer shifts so far (layer 162, 2Hrs of print)...
I have given op on stealthchop, it just doesn't work with my printer. Maybe it does work better with a higher voltage !
DavidThijs
on 3 Feb 2019
I have large shifts, too on my CoreXY. I think it was fine after you fixed that bug, but after I compiled and flashed today, every print fails. The printer makes a loud "whump" noise and shifts 1-2 cm. This happens at random layers. Might be completely unrelated to the issue you found.
I lowered the acceleration from 4000 to 1000 and the speed to 100 without any difference. Drivers are TMC2130 running at 900mA 30V. I disabled StealthChop through the new menu item on the lcd and lowered the hybrid threshold to 1. No difference, only a bit louder.
I think it mostly shifts to the lower right.
I did some testing today with CoreXY/MKS Sbase setup, I've build my unit so that X-stepper has longer cable. Seems that balancing the longer cable would need higher current setting
define DIGIPOT_I2C_MOTOR_CURRENTS { 1.8, 1.6, 1.6, 1.4, 1.4 }
I haven't tested with the big model but small one gives promising result. Equal currents 1.6+1.6 and 1.8+1.8 gave layer shift but 1.8+1.6 seem to work.
 J-PN
on 3 Feb 2019
J-PN
on 3 Feb 2019
I made some progress on this issue tonight. I'm not convinced this is really a Marlin issue. I think it might be a cheap heatsink and cheap thermal adhesive problem.
Edit: I did turn up the current from 1.3A (stock) to 1.8A to force the temperature to rise a little faster. I had noticed that the higher current settings tended to have more layer shifts. These drivers, if properly designed and properly cooled, should be able to handle 1.8A with no problem. Obviously here there is a serious design problem, but these are identical to the drivers that I purchased on Amazon a while back as well.
See these two videos
https://youtu.be/SP_xGC-Hjo4
BigE2
on 7 Feb 2019
The CoreXY layer accuracy with SBase board is far from reasonable :-( With the Smoothware I had no better luck. 8-bit board with Marlin 1.1.9 is just great.
I started to wonder if 32uSteps has something to do. I switch the jumper next to heat-sink to 16uS and reduced the Marlin FW steps 160->80. For some reason the steppers move 2x distance ??? How to set MKS Sbase to the 16 microstep mode?
J-PN
on 11 Feb 2019
@J-PN did you remember to reload the default settings and store them in eeprom using M502 and M500?
 gloomyandy
on 11 Feb 2019
gloomyandy
on 11 Feb 2019
I re-flashed the FW with the new values.
J-PN
on 11 Feb 2019
That is not enough, the values are stored in eeprom and will override the default settings. You need to reload the (new) firmware defaults and store them in eeprom.
gloomyandy
on 11 Feb 2019
Also could you explain what you mean by "The CoreXY layer accuracy with SBase board is far from reasonable"? What is wrong with it? It would also probably help if you provide details of your 8 bit and 32bit systems in particular what drivers are you using, what voltage, what microstepping etc.
gloomyandy
on 11 Feb 2019
@J-PN There is still a known issue with CoreXY and 32Bit Hardware #11047
Find this line in Configuration_adv.h
//#define MINIMUM_STEPPER_PULSE 2
and change to
#define MINIMUM_STEPPER_PULSE 4
kAdonis
on 11 Feb 2019
I must say, I didn't do the 'Initiate Eeprom' after the reflashing the FW.
With the example currents 1.2 the print drift very heavy towards back right corner (Tronxy X5S)
In the picture top result: original Metzi board (A4899)
The next ones with MKS SBase with onboard drivers DRV8825 (heat sinks are cool, X&Y motors slightly warm, extruder bit more warmer)

In the picture middle result: DIGIPOT_I2C_MOTOR_CURRENTS { 1.8, 1.6, 1.6, 1.4, 1.4 }
In the picture bottom result: DIGIPOT_I2C_MOTOR_CURRENTS { 1.6, 1.4, 1.4, 1.4, 1.4 }
I've noticed that the X motor needs higher current setting (longer cable).
You can see that even before the actual layer-shift the layers are uneven, micro-stepping holding issue?
J-PN
on 11 Feb 2019
You will almost certainly need the change to MINIMUM_STEPPER_PULSE mentioned above (I certainly do on my SBase). I would try that before going any further. You will also need to do the M502 M500 after making pretty much any config change.
gloomyandy
on 11 Feb 2019
The reason for using current driven motors instead of voltage driven is so
that the cable length doesn't matter. The reason the x stepper needs more
current is definitely not due to the longer cable. There's something else
going on there.
On Mon, Feb 11, 2019, 12:26 PM J-PN <[email protected] wrote:
I must say, I didn't do the 'Initiate Eeprom' after the reflashing the FW.
With the example currents 1.2 the print drift very heavy towards back
right corner (Tronxy X5S)In the picture top result: original Metzi board (A4899)
The next ones with MKS SBase with onboard drivers DRV8825 (heat sinks are
cool, X&Y motors slightly warm, extruder bit more warmer)X5S190127.zip
https://github.com/MarlinFirmware/Marlin/files/2852909/X5S190127.zip
[image: _20190211_220933]
https://user-images.githubusercontent.com/46862137/52590967-59786c80-2e4b-11e9-8188-07100b536d0a.JPGIn the picture middle result: DIGIPOT_I2C_MOTOR_CURRENTS { 1.8, 1.6, 1.6,
1.4, 1.4 }
In the picture bottom result: DIGIPOT_I2C_MOTOR_CURRENTS { 1.6, 1.4, 1.4,
1.4, 1.4 }I've noticed that the X motor needs higher current setting (longer cable).
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
https://github.com/MarlinFirmware/Marlin/issues/12403#issuecomment-462481222,
or mute the thread
https://github.com/notifications/unsubscribe-auth/AbmHXrmkf9pUMEUhuPkRmXtLCDK7mC0Aks5vMdIFgaJpZM4YY1Jm
.
BigE2
on 11 Feb 2019
current driven motors instead of voltage driven is so that the cable length doesn't matter
Yes, I agree the current driven system should compensate the cable+motor inductance.
need the change to MINIMUM_STEPPER_PULSE
I've tested with 'MINIMUM_STEPPER_PULSE 2' and without and haven't noticed any difference.
The same with MAXIMUM_STEPPER_RATE 250000 & MINIMUM_STEPPER_DIR_DELAY 650
J-PN
on 12 Feb 2019
MINIMUM_STEPPER_PULSE 2 is the default setting for DRV8825 drivers, so there is no difference
Try MINIMUM_STEPPER_PULSE 4 or at least 3
kAdonis
on 12 Feb 2019
Hi, yes I put the MINIMUM_STEPPER_PULSE 4 and MINIMUM_STEPPER_DIR_DELAY 1000 just in case. With those the quality is OK.
I wonder if the SBASE example Configuration_adv.h should be update on the build
X5S_19Feb19.zip
J-PN
on 19 Feb 2019
Just as an update... Enabling spreadcycle instead of stealthchop for x & y solved my issues. No layer shifts anymore in the last 1.5 kg of filament printed ; and most prints are parts for the AM8 BLV mod, so a good variation of curves, straight lines, short accelerations, bridges etc...
I also enabled linear_advance but not s-curves as my 8bit 2560 might not be able to calculate all of that.
DavidThijs
on 23 Feb 2019
the error of the layers shift is present in 1.1.x and 2.0bugfix in 1.1.7 there are no layer shift errors.
The error appears during large displacements. 2 test cubes diagonally into the edges of the print field. 1 cube anywhere in the field runs without shifts.
 demson
on 10 Mar 2019
demson
on 10 Mar 2019
The error appears during large displacements. 2 test cubes diagonally into the edges of the print field. 1 cube anywhere in the field runs without shifts.
Wow! This is very helpful information if it can be duplicated! I do not have a printer available. But I would be very appreciative if some people can do this type of print and see if they can duplicate @demson 's results!
Roxy-3D
on 10 Mar 2019
Yes, the result was repeated on different files. The error does not depend on the MINIMUM_STEPPER_DIR_DELAY MINIMUM_STEPPER_PULSE options, tried more than necessary, turned off the multistep but this does not help. The executable file with the cubes attached. https://yadi.sk/d/YWIW-rJScjTgSg
The size of the print field is large, but I think that if you just put 2 cubes on the diagonal of the field, the result will be the same.
demson
on 10 Mar 2019
The error appears during large displacements. 2 test cubes diagonally into the edges of the print field. 1 cube anywhere in the field runs without shifts.
Wow! This is very helpful information if it can be duplicated! I do not have a printer available. But I would be very appreciative if some people can do this type of print and see if they can duplicate @demson 's results!
In the opposite. Without the configs this statement is worthless.
If the acceleration is low and the max-speed of the skipping axle is that high, it gets to top speed only on long moves (or never) - it's a simple configuration error - with too high top speed.
AnHardt
on 10 Mar 2019
the configuration file did not change from firmware 1.1.7 to firmware 1.1.x and 2.0.x and 7 was not missed by steps with the same values of speed, acceleration, jog
demson
on 10 Mar 2019
Junction deviation for example is not configurable in 1.1.7. This could result in a higher cornering/stat/stop - speed of a long move - what will increase the reachable top speed of the move by the same amount.
AnHardt
on 11 Mar 2019
the error of the layers shift is present in 1.1.x and 2.0bugfix in 1.1.7 there are no layer shift errors.
The error appears during large displacements. 2 test cubes diagonally into the edges of the print field. 1 cube anywhere in the field runs without shifts.
I had issues with missing steps, too. 1) on my 3 printers and 2) on my openpnp driven by marlin on radds.
The problem for 1) was that Slic3r since some version added gcode to control the acceleration, speed, etc and I didn't know about that change. The defaults were too high and I had missing steps on the y-axis with the heavy prusa style bed. I changed the values in slic3r and the problem went away.
But for 2) I still saw some missing steps on X and Y - PnP machines have to run fast, so I needed to go into the limits. I observed missing steps if I had the DEFAULT_RETRACT_ACCELERATION, DEFAULT_ACCELERATION and DEFAULT_TRAVEL_ACCELERATION set to something very high because I wanted to limit the acceleration per axis with DEFAULT_MAX_ACCELERATION.
this does not work, but would be preferred as it allows for fast movements on E which is rotating the pick and place machine's nozzle:
#DEFAULT_RETRACT_ACCELERATION 20000
#DEFAULT_ACCELERATION 20000
#DEFAULT_TRAVEL_ACCELERATION 20000
#define DEFAULT_MAX_ACCELERATION { 2500, 2500, 5000, 20000 }
this does work but is slow due to the very limited acceleration on Z and E:
#DEFAULT_RETRACT_ACCELERATION 2500
#DEFAULT_ACCELERATION 2500
#DEFAULT_TRAVEL_ACCELERATION 2500
#define DEFAULT_MAX_ACCELERATION { 2500, 2500, 5000, 20000 }
With the settings below I have no step loss in X and Y but a slow machine. With the upper settings I have missing steps in acceleration phase in X and Y direction although the acceleration should be the same... Maybe there is a glitch/bug in the acceleration limitation?
 mgrl
on 11 Mar 2019
mgrl
on 11 Mar 2019
@Roxy-3D i have done 4 prints of the same 36 hour print and have not seen any issue
no blobs, etc and no layer shift
are there any stl i could have a go at that will provoke this?
 boelle
on 13 Mar 2019
boelle
on 13 Mar 2019
@boelle do you have any 400mm base machines?
InsanityAutomation
on 13 Mar 2019
i'm building one, at very slow speed as i do not have a bottom less pit full of cash
it will be 500x500x500 or damm close to that, Z is verified to be a little over 500, but i still have to buy extruder and the build plate itself
boelle
on 13 Mar 2019
I have a gcode file sliced explicitly to torture the planner that has been very reliable in triggering layer shifts, but most of my machines are 400x400 so it's centered there. It will fit on a 300x300 barely in the back right edge. I can send a link for it if you'd like, just adjust fan and hotend temp as needed, and set a bed temp before starting.
InsanityAutomation
on 13 Mar 2019
I think it will be enough just to count the pulses, if at the point 0 0 after printing there will be a number of pulses other than zero, this will mean a shift.
demson
on 14 Mar 2019
@InsanityAutomation Can we twist your arm to locate the part at about (100mm,100mm) and slice it there? That might enable people with smaller machines to give it a try and help us understand the problem.
Roxy-3D
on 14 Mar 2019
i have printed a 200mm tall gear shaped object, takes 36 hours sliced with slic3rpe as if the printer was a mk2.5
gcode is 84MB :-/
boelle
on 14 Mar 2019
@InsanityAutomation Can we twist your arm to locate the part at about (100mm,100mm) and slice it there? That might enable people with smaller machines to give it a try and help us understand the problem.
Ill go over the parameters I used again and see what I can put together probably Sat. Should be able to make something a bit smaller.
InsanityAutomation
on 14 Mar 2019
thinking of it...
since you most likely will reslice this would it make more sense to place it in the 0,0 corner?
then no matter how big or small a bed people have they can just use G92 to get it to print in the center
just my simple thought, might not work
boelle
on 14 Mar 2019
since you most likely will reslice this would it make more sense to place it in the 0,0 corner?
Also... Do we have people with Delta's seeing the issue? If so, slicing close to the (0,0) corner might let them use the file....
Roxy-3D
on 14 Mar 2019
Has anyone tried uncommenting the
//#define TMC_DEBUG
in configuration_adv.h?
Right now I don't believe we know if the layer shift is coming from the
software, or if the stepper driver itself is messing up.
However, the M122 command may generate TOO much info.
We probably also need to uncomment //#define MONITOR_DRIVER_STATUS
The MONITOR_DRIVER_STATUS would also stop the print on overheat. I found
that with my stock TMC2208 boards, the chip itself was running at very high
temperatures (over 100C) while the heat sink was still around 30C. I
scraped off the enamel on the board under the heat sinks and then adhered
them with arctic silver thermal adhesive. With this mod, I had layer shifts
reduced significantly and the highest recorded temperature on the chip was
about 50C. (Still had layer shifts, though, on at least one design that
included long straight moves).
-Steve
BigE2
on 14 Mar 2019
the configuration file did not change from firmware 1.1.7 to firmware 1.1.x and 2.0.x and 7 was not missed by steps with the same values of speed, acceleration, jog
Yes, but the way the Planner schedules the acceleration ramps and max speed has been affected. It would be very helpful for you to reduce the max feed rate and accelerations (by maybe 15% or 20%) and see if your scenario still causes the problem... Knowing what happens would be helpful!!!
Roxy-3D
on 14 Mar 2019
i got the torture test ready, but it will take arround 50 hours and take about 180g of filament
and since i'm adding to my core xy build i need the working printer free to print parts. So not sure when but it will prob happen either at end of weekend or during the week.
i would not mind sharing the gcode if @InsanityAutomation can give his blessings, i just wonder what is the best way to share since its 139MB, google drive maybe?
all i did with his code is adding my own start code and then i used G92 to "trick the printer to print in center of my mk42 bed where the model org. was centered on a 300x300 bed
also retracts are changed from 3mm to 0.8mm since i have a direct drive
boelle
on 14 Mar 2019
i would not mind sharing the gcode if @InsanityAutomation can give his blessings, i just wonder what is the best way to share since its 139MB, google drive maybe?
You should be able .ZIP it up and attach it to a post here....
Roxy-3D
on 14 Mar 2019
bummer 10mb limit and its ~47MB zipped
will upload to google drive and post a share link instead :-/
boelle
on 14 Mar 2019
I'll do a smaller one to post here. That one is fine, but setup for a big machine. My web server won't have an issue hosting it directly either.
InsanityAutomation
on 14 Mar 2019
oki doke :-D
boelle
on 14 Mar 2019
speed limits were due to the feed rate, visually did not pull out at maximum speed. when I commented out multistep it seems to me the speed dropped even lower. For this reason, I think it is unlikely that hardware will skip steps. Accelerations and runs were lowered. At a decrease of jog (jog=5 >> jog=1), displacements occurred a little slower. In my test file, the shifted axis was X, Y axis shifted much less.
demson
on 15 Mar 2019
hello,
In my selfmade machine (cartesian + ramps 1.4 + 1 motor X a4988+ 1 motor Y TB6600 + 2 motors Z 2 a4988, Z_DUAL_STEPPER_DRIVERS + bugfix-1.1.x_20180731) i have a almost "constant" layer shift in Y-axis.
I see that the movements within a layer are ok but there is a the problem with changing layer movement:
G0 Fxx Xxx Yxx
G0 Xxx Yxx Zxx
do you know if in Marlin i can set something for having this G0 X Y Z as G0 X Y + G0 Z (avoid losing steps)? or it would be rather in the slicer configuration?
jerk Y 0.0mm/seg accel Y 300mm/seg*seg feddrate Y 20mm/seg, gcode ok in gcode viewer.
heavy bed, and no printing without shift in layers. YZ_skew_factor smooths but don't fix.
without S_CURVE_ACCELERATION
without JUNCTION_DEVIATION
first two layers and last two layers with more shift.
 ZocoPDF
on 18 Mar 2019
ZocoPDF
on 18 Mar 2019
hello,
after a lot of 10mm cube tests in bugfix-1.1.x, changing 1 parameter each time, the problem of constant shift layer has disappeared flashing Marlin 1.1.8 in ramps 1.4. Without any change in hardware configuration.
I've copied/pasted parameters form Marlin bugfix-1.1.x in M 1.1.8.
It's not a enclosed solution, but it works.

ZocoPDF
on 21 Mar 2019
I just want to add my 2 cents... I had the same issues with layer shifting with s-curve acceleration and jerk enabled as seen in #12398. Even though my jerk settings were very very conservative. I think the issue may actually be cpu bottleneck even on 32 bit. Moving to junction deviation (which I still don't understand how to tune correctly...) seems to have solved the problem. Will report back once more testing is completed. A good test part is a stl file with circles, like this one.
 pinchies
on 23 Mar 2019
pinchies
on 23 Mar 2019
I'm actually still suffering layer shifts with junction deviation as well... still investigating.
pinchies
on 26 Mar 2019
hello,
after some tries, i've found that my problem of constant layer shift was in the TB660 driver on Y axis. It wasn't working properly.
I have changed it and then i got good printings.
Using Marlin bugfix-2.0.x 2019 03 26 "e3ab547"
without junction deviation, without s-curve, jerking X and Y 0.1

ZocoPDF
on 31 Mar 2019
Can you enable all of them and see if layer shifts come back? This would help narrow down the issue to a specific feature
psavva
on 31 Mar 2019
I will try.
One thing that i don't understand is that, with the broken TB6600 on Y axis, in marlin 1.1.8 the problem of constant shift layer looked almost solved ( some noise between layers) but with bugfix-1.1.x and bugfix-2.0.x there was a uniform shift layer. Photo above left.
ZocoPDF
on 2 Apr 2019

Do you consider the attached print to be due to this issue ? I'm starting to get this bad print after moving from Marlin 1.1.8 to Marlin 2. It doesn't happen every time, but I'm totally able to replice the shown issue with Slic3r Prusa Edition and the benchy. Simplify 3D doesn't exibit this issue.
 guestisp
on 5 Apr 2019
guestisp
on 5 Apr 2019
Hello....
Anybody have .gcode files to test this problem ?
 robbycandra
on 15 Apr 2019
robbycandra
on 15 Apr 2019
Anybody???
@robbycandra Just start a printer going on something that is going to take 12 hours to print. I think there is a fair chance you will see a small layer shift some where in the print.
Roxy-3D
on 25 Apr 2019
@Roxy-3D , because it takes hours to print. It is better if someone can share the GCODE files. Hopefully it can be tested using 20x20x20 cm workarea.
robbycandra
on 25 Apr 2019
Here's the problematic section of a file that would shift every time for me in different places.
short shift test.gcode.zip
Mirror: Download shift test
pinchies
on 25 Apr 2019
@pinchies , i will try your gcode.
I use my printer almost everyday but never found any layer shift problem.

robbycandra
on 25 Apr 2019

@pinchies , I have print it and found no layer shifting.
But if the printer frame is not rigid, its difficult to print your gcode.
robbycandra
on 26 Apr 2019
That's good to hear, thanks for testing, but I still have some questions:
- did you you have S_CURVE_ACCELERATION enabled?
- did you have JUNCTION_DEVIATION enabled? What value?
pinchies
on 26 Apr 2019
I'm also facing the loosing steps problem, my guess is that my drivers(TMC2130) overheat.
I found the if you have more than 4 warnings the current will be decreased by 50mA(default value), but for this to happen you must have active TMC_DEBUG and MONITOR_DRIVER_STATUS
#if ENABLED(MONITOR_DRIVER_STATUS)
#define CURRENT_STEP_DOWN 50 // [mA]
#define REPORT_CURRENT_CHANGE
#define STOP_ON_ERROR
#endif
I checked with the M122 command and seems to be OTPW true on Y axis(the one skipping steps).
I'm also on the latest 1.1.9 bugfix.
The problem appeared when trying to print a model that has rectilinear infill instead of honeycomb. I think that all the straigth lines are causing a problem.
UPDATE: Layer shift while writing this, doesn't seem that the OTPW is the problem, I set the current to 900(just to see if OTPW is the culprit). Below are my driver status, I just had a layer shift on Y axis, and Y doesnt have a warning.
Recv: X Y Z E0
Recv: Enabled true true true true
Recv: Set current 900 900 850 900
Recv: RMS current 887 887 826 887
Recv: MAX current 1251 1251 1165 1251
Recv: Run current 28/31 28/31 26/31 28/31
Recv: Hold current 14/31 14/31 13/31 14/31
Recv: CS actual 28/31 28/31 26/31 28/31
Recv: PWM scale 78 99 39 79
Recv: vsense 1=.18 1=.18 1=.18 1=.18
Recv: stealthChop true true true true
Recv: msteps 16 16 16 16
Recv: tstep 447 175 65535 5107
Recv: pwm
Recv: threshold 10 10 1 8
Recv: [mm/s] 993.25 993.25 1976.56 1022.87
Recv: OT prewarn false false false false
Recv: OT prewarn has
Recv: been triggered false false true false
Recv: off time 5 5 5 5
Recv: blank time 24 24 24 24
Recv: hysteresis
Recv: -end 2 2 2 2
Recv: -start 3 3 3 3
Recv: Stallguard thrs 8 8 0 0
Recv: DRVSTATUS X Y Z E0
Recv: stallguard
Recv: sg_result 0 0 0 0
Recv: fsactive
Recv: stst
Recv: olb
Recv: ola
Recv: s2gb
Recv: s2ga
Recv: otpw
Recv: ot
Recv: Driver registers: X = 0x00:1C:00:00
Recv: Y = 0x00:1C:00:00
Recv: Z = 0x00:1A:00:00
Recv: E0 = 0x00:1C:00:00
 alex26aly
on 26 Apr 2019
alex26aly
on 26 Apr 2019
@pinchies , When testing your gcode.... Yes and Yes... using default value.
robbycandra
on 26 Apr 2019
Hi same thing here with A4988.
The problem is manifested on big accelerations. (As for bridges)
The problem is present since all the versions> = 1.1.9
No S_CURVE_ACCELERATION.
No JUNCTION_DEVIATION.
 murdock62
on 27 Apr 2019
murdock62
on 27 Apr 2019
I had layer shifting with TMC2130 as well, version used was like 3 weeks ago - sorry can't remember the exact date. Downloaded version today, and all seems to work fine. tmc2130 library downgraded to 2.0.1 (no idea if this really did help)
 iz3man
on 27 Apr 2019
iz3man
on 27 Apr 2019
Hey there! I had layer shifts pretty early in April of 2018 and reported them here: https://github.com/MarlinFirmware/Marlin/issues/10446#issuecomment-467527351 It was never solved, but several people had those issues. - I just used an older Marlin version since then.
I think I finally nailed it down now and fixed it.
Set K Factor of Lin_Adv to 0 in the firmware, since I have it in my GCode. - Before I had the factory setting of 0.22 (I think so) in my Firmware AND a K factor in my GCode.
I tried fashing the release, the bugfix and always had the layershifts when using both K factors. Now the bugfix runs fine without shifts.
So maybe you want to try that out
 viperchannel
on 27 Apr 2019
viperchannel
on 27 Apr 2019
@viperchannel, do you have the gcode files? I you still have.. please share it here.
robbycandra
on 27 Apr 2019
@robbycandra
Sure. I had the shifts at around 10mm height in the Y axis. 3 times in a row in the same spot. About 1mm above the deck. I checked the file with the octoprint Gcode viewer and it looks fine in there.
After setting the K factor to 0 in the config, the same Gcode printed without issues.
(Using TMC2208 drivers, RAMPS Board, octoprint newest release version, Marlin latest bugfix with Lin_adv)
Been printing for a year now with that config with a older (I think dec 2017) build of marlin with no issues and not a single shift. So it is 100% not a hardware issue.
viperchannel
on 27 Apr 2019
@viperchannel do you have a pic about the layer shift on benchy? I've posted above my benchy where i get something similiar to a shift (i think it's related to a slow down, when slicer slow down speed, i Always get these strange layers similiar to a shift. Happens with all slicers)
guestisp
on 27 Apr 2019
@viperchannel , thanks... will try tommorrow
robbycandra
on 27 Apr 2019
@guestisp Sure. One is printed with 1.19 and one with 1.19 bugfix. Both a fresh config, manually edited and just adjusted the basic stuff like bedsize, boardtype, endstop settings etc. Nothing fancy. I ripped one of the boats apart on the pic to check the layer adhesion, thats why it is lower than the other. That has nothing to do with the shift itself. But if you look closely, you can see that the shift is at or almost at the same position. But the shift distance itself differs. I have another one that has an eaven bigger shift as the ones from the pic at the same spot.
@robbycandra thanks, be aware, it is pretty high temp (ASA filament) so don't try printing it with PLA without adjusting the temp

Print looks bad, but this was my first time using that filament, so I still need to find the right settings. But the shift is pretty obvious.
viperchannel
on 27 Apr 2019
@viperchannel looks quite different from mine...
guestisp
on 27 Apr 2019
hello,
after a lot of 10mm cube tests in bugfix-1.1.x, changing 1 parameter each time, the problem of constant shift layer has disappeared flashing Marlin 1.1.8 in ramps 1.4. Without any change in hardware configuration.
I've copied/pasted parameters form Marlin bugfix-1.1.x in M 1.1.8.
It's not a enclosed solution, but it works.
I had this problem too.
It was solved reducing acceleration.
The high speed was causing vibration and step loss.
Actually I'm using this values:
#define DEFAULT_ACCELERATION 1000 // X, Y, Z and E acceleration for printing moves
#define DEFAULT_RETRACT_ACCELERATION 2000 // E acceleration for retracts
#define DEFAULT_TRAVEL_ACCELERATION 1000 // X, Y, Z acceleration for travel (non printing) moves
 FernandoGarcia
on 28 Apr 2019
FernandoGarcia
on 28 Apr 2019
@viperchannel , I have print your g code and found no layer shift

Using latest bugfix2.0 . LIN_ADV, S_CURVE, JD all enabled.
robbycandra
on 29 Apr 2019
Thabks for testing it. I also sucessfully printed the file without shifts after setting K value to 0and only use the k value from the gcode. I am 99%sure that my shifts were caused by using a k factor both in the gcode and the firmware and maybe that caused some buffer overload or something after a certain printing time. I had about 30h of printing since i changed tgat without a single shift
viperchannel
on 29 Apr 2019
Hi @viperchannel , I test your GCode using default K value (0.22),
I dont think its because the K value.
robbycandra
on 29 Apr 2019
By reducing the jerk by 50% the fault disappears.
However an impression of 1:15 take 5 minutes more ...
murdock62
on 29 Apr 2019
That is so strange. The K factor is the only thing I changed. I had that shift in all prints, no matter if release or bugfix version. Once i printed lla the stuff i need, i will chnage the k factor back in the FW and try it again to see if the shift returns
viperchannel
on 29 Apr 2019
I test your GCode using default K value (0.22)
Very little OT: is there any test to see if K value is correct, othe than the calibration pattern made automatically by the firmware ? I don't see differences in printed lines, so i'm looking at something better
guestisp
on 29 Apr 2019
There is a difference in the lines, but be sure to set the correct pattern for your firmware in the pattern generator, and have lin adv activated in the formware of course. otherwhise you wont see a difference. There is version 1.0 for 1.18 firmware and 1.5 for 1.19 firmware. I personally think it is way easier to see the difference with the new 1.5 version.
viperchannel
on 29 Apr 2019
I'm using the 1.5 version but lines are too thin and numbers printed on the right most of the time doesn't stick to the bed, that's why i'm asking for a different test.
guestisp
on 29 Apr 2019
Note:
I use default value for acceleration, JD, E-Jerk.
But i use this
#define MIN_STEPS_PER_SEGMENT 6
#define MINIMUM_STEPPER_PULSE 5
I change this because i think the default value is too low.
The quality of driver in the market is not as good as original polulu driver.
robbycandra
on 29 Apr 2019
@guestisp , try to reduce speed to 50% at first layer manually.
This gcode is not easy to print.
robbycandra
on 29 Apr 2019
@guestisp , try to reduce speed to 50% at first layer manually.
I was talking about the Linear advance calibration, not about this gcode. End OT.
guestisp
on 29 Apr 2019
@robbycandra I printed with default setting and got the shifts and with acceleration set to 1500- The same. But after reflashing without the K I also tried both and had no more shifts. What board are you using and what drivers? I have a ramps with dual Z setup and 2208 drivers on all axis and a A4988 on the extruder.
@guestisp you have to fix bed leveling first and bed adhesion before playing around with LinAdv. Otherwhise you will have a very hard time to see the difference of the lines. I will print one for you and show you how it should look and how easy you can see the difference in the lines
viperchannel
on 29 Apr 2019
@viperchannel I can see "differences" in lines but they are very small. I don't know which line choose as they are very similiar. What I don't see properly are the numbers printed on the right. Bed level is OK, as i'm able to print "standard" prints properly and I'm using the original bltouch + UBL
guestisp
on 29 Apr 2019
This can happen if you are a tiny bit too low. I am just heating up and will show you the result. We can also mail if this gets too OT for here. ping me at viperchannel @ hotmail . com
viperchannel
on 29 Apr 2019
@viperchannel , I use MKS GEN L 1.0. Using 5 pcs A4988. Dual Z setup.
Default Max Acceleration 3000, 3000, 100, 10000 at first print. and 3000 3000 100 4000 at second print.
Default Accell all set at 1500
Your gcode use too much retraction i think.
Have you try this ?
#define MIN_STEPS_PER_SEGMENT 6
#define MINIMUM_STEPPER_PULSE 5
BTW, if we look at this issue #12365, we can see that @anycubic also have layer shift at same location with @viperchannel .
robbycandra
on 29 Apr 2019
@robbycandra no, I haven't yet tried it, but I will later.
I have a ton of retraction, I know that. But thats just for that kind of filament while using a bowden extruder. My ABS and PLA settings are way lower.
Maybe it has something to do beacuse of the driver combination. I read that alot of users that had shifts in my initial thread were also using TMC drivers. Good find with issue #12365 !
viperchannel
on 29 Apr 2019
Regarding my #12365 switching to Re-arm seemed to solve the issue (maybe be-linear is to heavy for a Delta and 8 bit? Don't know). Also TMC2130 + 24v to VMOT sorted little "random" shifts, hope it helps
 Anycubic
on 29 Apr 2019
Anycubic
on 29 Apr 2019
@viperchannel, check this out #13819.
@Roxy-3D , maybe the problem is in the min stepper pulse combined with Lin Adv + TMC
robbycandra
on 30 Apr 2019
Hi ,
Just to add to the list of people having the issue on 32 bits cpu. Alfawise boards with bugfix 2.0.x from 14/04/19. As of today we have about 10 testers that trie many things. Those printers do use a4988 basic stepper drivers.
U30 has a smaller bed than u20 and this helps.
On u20 increasing current in the steppers seems to reduce the occurrence of the issue.
The faster the print the more we have layer shifts.
Increasing again vref allows to go faster.
It looks like to avoid loosing steps we have to increase current while we are not at the limits of the machine
I will place a digital oscilloscope on step cell pin with infinite rémanence as a logical explanation could be that the Steps are getting too quick for the stepper to move ahead, and only by increasing current we somehow overcome this. I will post the findings here in 12 hours with a screen capture.
 hobiseven
on 30 Apr 2019
hobiseven
on 30 Apr 2019
@Roxy-3D I opened https://github.com/MarlinFirmware/Marlin/pull/13819
I have the exact same problem!
 chrisqwertz
on 30 Apr 2019
chrisqwertz
on 30 Apr 2019
@hobiseven If necessary I also have a scope as well as a logic analyzer. If necessary I can take the time to hook up both an measure as well.
chrisqwertz
on 30 Apr 2019
@chrisqwertz , @hobiseven, i think you can solve this problem.
robbycandra
on 30 Apr 2019
@chrisqwertz
What I would look for is a bad timing management for pulses / clocks, possibly at direction switch time. At least this is what I am thinking of. As I explained above, increasing the intensity in the steppers, boosting VREFs, pushes the bug to higher speeds. And increasing the Vref simply allows the steppers to react faster.
This is why, what I think is going on, is that at some point in time, pulses are too fast, beyond the machine setup defined in Config.h. and then, of course, the stepper misses steps, and take a bit of time to recover.
As a first measure, I would trigger on step clk rising edge, and place the digital oscilloscope on infinite remanence so we will see all clock cycles on the screen, specifically the ones shorter than what they are supposed to be.... Then we will check after that, what we discover... Stay tuned for screen captures tonight...
hobiseven
on 30 Apr 2019
@robbycandra I think that :
define MIN_STEPS_PER_SEGMENT 6
define MINIMUM_STEPPER_PULSE 5
is just a band aid helping to overcome the issue, but not really addressing it. If I am correct, and that the clock pulses are sometimes miss calculated, then it would help to get a decent width pulse...
Let's see tonight on the hardware.
hobiseven
on 30 Apr 2019
I will start with a 50mm/sec Gcode, in which I will also set all travels to 50mm/s MAX.
My configuration files for Marlin are attached.
With such config, we have 80 steps per mm in X and Y, with 16 microsteps per steps > we should not have more than 64K step clocks per second , and anything faster then that should not happen. We should not see any clock cycle below 15.6µS...
Please let me know if my reasonning is OK. I am assuming step cycles are evenly spread, and that I really wonder wether Marlin can do that... Let's see
hobiseven
on 30 Apr 2019
50mm/sec * 80step/mm = 4.000step/sec. Its 250usec
Max Print Speed using A4988 is around 35.000 step/sec.
robbycandra
on 30 Apr 2019
Yes, but what about the microsteps... They are seen as regular steps from the microcontroler, don't they?
Hence my 4K * 16 = 64K
hobiseven
on 30 Apr 2019
4K is already micro step
200 step / rotation * 16 microstep / step
-------------------------------------------- = 80 microstep / mm
20 teeth / rotation * 2mm / teeth
robbycandra
on 30 Apr 2019
Ok!
hobiseven
on 30 Apr 2019
@chrisqwertz : I did connect my stepper clock to a tektronix oscilloscope, with instavue feature : You trigger a trace, and it remains on the screen , as long as you want, and you accumulate traces. I did set infinite time. I trigger on the rising edge of the stepper clock. I did set the clock to 6µs in Marlin . This works well, but it seems that I do not only have clean clock signals. I also have nasty super short pulses, like 2 clock cycles at 72Mhz, which is my STM32 clock. This is then ringing like hell in the stepper clock wire. Please note I had to solder tiny wires on the board to connect my scope, so the huge ringing may come from that, but this is really looking strange, as this happens maybe once every minute or two. I am attaching the gcode I used to generate this. This is a ducati bike m48 nut, printed at 150mm/s, with transits @ 170. I also attach the pictures of the very strange super fast glitch I have on the clock line. Again on,y once every minute or so.
Can you, or any other hardware guy using Marlin, hook a digital scope, and check if you have that sort of short pulse? I do not know if this is the root cause of layer shift, but this looks super bad on a clock line.
CFFFP_ecrou_ducati_75011395A.zip
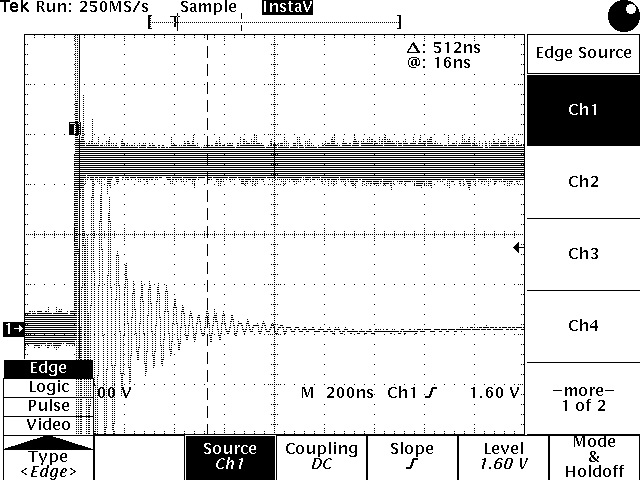
@thinkyhead , this is an easy thing to check...
hobiseven
on 1 May 2019
@hobiseven , is there any connection between your finding above with @chrisqwertz finding below...
robbycandra
on 1 May 2019
Don't give up trying to narrow down the specific day that the issue appeared. These threads tend to go on forever with speculations, when the best use of time would be to meticulously seek out the specific commit that introduced the problem.
I agree, but I had no layer shifts anymore since I switched from stealthchop to spreadcycle mode ; but it is well possible that when I drive up the speed, layer shifts are coming back but at a higher speed. So I can't rule this out yet.
DavidThijs
on 1 May 2019
@DavidThijs
We experience kind of a similar issue > Increasing Vref on steppers is "erasing" the issue, pushing it to higher speeds. Please do NOT rule this out, as we clearly see the issue created, although not the root cause. To help software developpers, and NOT speculate about anything, I am trying to narrow down the screen capture to something meaningfull.
@chrisqwertz
Apparently, you have a much quieter setup than mine. I did shorten all probe wires to the probe itself, no additional wires, and it is cleaner, but not perfect.
I would try this to help SW people :
1 - trig on the glitch itself, which is something like 30ns wide glitch condition, and get a wide enough pretrig and post trig window to include other stepper clocks , so we get an idea when this glitch occurs compared to other clocks. My image above is missleading as i trig simply on the rising edge of the signal, so all clocks and glitch are aligned, but they may not be at all.
2 - possibly include one other signal, like the direction signal from the same stepper. This could also help to understand whether or not this is linked to a direction change.
This glitch is hard to catch. In my last print, using the Gcode above ( Ducati nut) It did happen 3 times over 90 minutes.
@robbycandra
I will look in this .
We are using as far as I know Lin_advance disabled, and our pulses are set now to 6µs. Although this looks a bit similar.
hobiseven
on 1 May 2019
@hobiseven Does your cleaned up version still have all of that ringing on it, or is it just a very short pulse? Because it seems to me that there is something very odd about that glitch as shown in the capture. I've been trying to figure out how I could create something like that from the firmware and I really don't see how you can get the ringing like that on a pin that is driven directly high or low. I assume your test point is not after any resistors or anything and that the line is being driven directly from the processor? Also is there anything odd about the pin that you are monitoring (it is not open collector or anything?). Assuming there is nothing odd with the pin and test point the only way I can see how you can get that sort of ringing is for the pin to no longer be an output pin at that point. Maybe it has been switched to input or some other special feature of the pin has kicked in?
I'm more of a software guy than a hardware engineer though (but I have been working with hardware for a long time) so perhaps someone with more hardware experience can correct me and explain what sequence of events can create this sort of glitch. It would also be good to see a similar trace for another processor (like the LPC176x series) as that might indicate if this is a general issue or perhaps just something that only happens with the SRM32.
gloomyandy
on 1 May 2019
@gloomyandy as I said a bunch of that ringing comes from the wire wrap 5 inch wire I had to use and the ground pickup not ideal. The new snapshot I made , with a better connection, is showing a lot less reflections and this is to be expected. Remember that a 100mhz signal is nothing easy to measure. Still the waveform I get is not perfect. I will post this later on. My probes are 500mhz rated and I checked calibration - nothing I could improve. What is really not good is that even with a high trigger point the oscilloscope is capturing it. The logic gate that is connected to this wire will also. So this means possibly an additional step. I will now check if I can plug an hp logic analyser to catch a wider snapshot.
Remember that a clock signal has to be perfectly clean . No way around this .
hobiseven
on 1 May 2019
And of course I encourage any hardware person with good equipment to measure this. I will check in the lab if my guys have a better scope. Mine is a 744 tektronix that has not seen any service for 20 years....
hobiseven
on 1 May 2019
See my better pictures. I will check tommorow if I can get a better scope...
hobiseven
on 1 May 2019
Hmm you latest captures seem to be showing similar ringing on the "normal" signals as well as on the short one, the earlier ones did not seem to show that. At least that is my interpretation of those traces, is that correct?
Can you see how long the pulse actually lasts? That length may help pin down what part of the code is generating it. It looks very short can we estimate how many instructions are between the on and off? I assume that the pulse length is larger than the minimum pulse that an STM32 can actually create? If not we may need look at other possible sources than the code simply creating a short pulse.
gloomyandy
on 1 May 2019
@gloomandy
I will try to really get a better scope for that. I will borrow that Thursday evening and indeed try to measure that . But looking at what we see this is about 2 clk cycles @72... as I said before we need to locate the pulse in time compared to othe events . Do you have any suggestion? On my board I have a couple of free pins where I can drive signals . ( already rerouting y stepper pins to free header pins is a bit of a challenge as I need to moove the y bed by hand during homing. Maybe I can disable also y end stop...)
hobiseven
on 1 May 2019
Would it make your testing any easier to modify the gcode to remove the home(and perhaps other "startup" operations)? Would using M111 to set dry run mode (no extruder operations, so no need to heat things up). I suppose doing this may also mean the glitch no longer happens, but that in itself would tell us something.
2clk cycles seems like a very short pulse to be generated via software intentionally. Is it even possible with the STM32?
Is it possible to configure your scope to trigger on a pulse of a particular duration (I know it is not with my now rather old TDS220!)? If not can you set up a logic analyser to do that (I vaguely recall wrestling a HP logic analyser to do that many years ago, so sure these days you can?)? If so we could pretty easily just drive another pin at say the start and end of the stepper routine and that would show us if the glitch is being generated during that code. If more pins are available we can use a combination to sub-divide things. It is all pretty tedious but by moving the pin setting we should be able to narrow it down, so long as the glitch is repeatable (and it sounds like it is).
gloomyandy
on 1 May 2019
@gloomyandy
I have access to a regular hp la, as well as a better scope.
Please send me the file in which you think I need to toggle a pin, and place comments with “hobi” where you want me to turn on and off the external pin. Good idea.
For the dry run, I was not thinking about it. I want to have the motherboard and the screen to run the test. Not the full printer. Easy to tweak adc inputs to have 200/60. Let me give it a try! I want to eradicate that bug as it renders useless the alfawise port I just did...
hobiseven
on 1 May 2019
And One more thing : all testers report a very harsh direction switch on y leading the belt to jump teeth. I will monitor y direction too
hobiseven
on 1 May 2019
Sounds good. I would start by setting a pin here:
https://github.com/MarlinFirmware/Marlin/blob/bugfix-2.0.x/Marlin/src/module/stepper.cpp#L1404
and clearing it here:
https://github.com/MarlinFirmware/Marlin/blob/bugfix-2.0.x/Marlin/src/module/stepper.cpp#L1524
Which I think covers all of the pulse generation (assuming you do not have linear advance enabled). Hopefully we can then narrow it down, or rethink if the results show the glitch outside of this window.
Good luck!
gloomyandy
on 1 May 2019
@gloomyandy
Logic analyser HP16900/16911A probe card hooked. I so far did not manage to trigger on the small glitch yet... Will be a hard one to catch.
However, one thing seems strange to me. I have seen directions changes, where the stepper goes from + 10mm/s to -20mm/s, and obviously, there was no deceleration/acceleration. I will recheck, and take a snapshot to be sure, but my question to you is : Is this a possible behavior? Is there a minimal limit for speed changes at which the acceleration will not be done, ie going from -X mm/s to +X mm/s with no acceleration , just the direction pin change?
hobiseven
on 2 May 2019
I'm pretty sure what you are seeing is the jerk setting coming into effect. But a jerk of 30mm/s sounds rather high. There have been other questions raised about jerk before now (search the issues for it). Also do you have junction deviation enabled? That will also impact what happens in this situation.
gloomyandy
on 3 May 2019
@gloomyandy
I will tonight build more complex trigger scenarios, as indeed this looked high to me. I will attach a print.
I will also try to catch the clock spike too. I actually saw -20mm/s then going to +10mm/s for 15 clocks, and back to -20mm/s .
I will definitely try to have a hardcopy of this, to be sure I am not making any mistake here.
Basically, my small U30 has no layer shift issues, but it feels rough when printing. Like sometimes someone would hit the frame with a small hammer. And for me, this is not good. All U20 people having the same code do have layer shifts. We have the same intensity in the steppers, but U20 has a plater with a greater inertia, a bit more than twice the inertia. Same motherboard.
Junction deviation enabled? No it is disabled.
//#define JUNCTION_DEVIATION
My jerk parameters :
if DISABLED(JUNCTION_DEVIATION)
#define DEFAULT_XJERK 20.0
#define DEFAULT_YJERK 20.0
#define DEFAULT_ZJERK 0.4
endif
hobiseven
on 3 May 2019
You might want to lower those jerk values (I used to run mine at 10 before I switched to using junction deviation). I'm not really familiar with that code but I wonder if 20 is supposed to include going from +20 to then up to -10? I really don't know. Did it go to zero at all?
gloomyandy
on 3 May 2019
most printers seem to use 10.0 or 15.0, only a few at 20.0... we should try that... too
 tpruvot
on 3 May 2019
tpruvot
on 3 May 2019
Can someone try changing extruder acceleration during printing to reproduce the following fault? On my machine that lead to irreversible stuttering back and forth of the extruder.
I did a lot of testing the last few days and as of now, I cannot successfully print any part with my setup (Ramps, Re-Arm, TMC2208)
chrisqwertz
on 3 May 2019
@gloomyandy
I finally manage to isolate why I feel the printer is behaving roughly.
My printer settings are unchanged, I print at 150mm/s, and travels at 170mm, and I always felt the printer was behaving roughly. I did isolate one of this rough movement, and I attach the logic analyser traces :
Waveform 1 > Y mooves with clock pulses 120µs apart > 80 step per units . That is 104 mm/s.
Waveform 2 > Y stops for 16.25ms without any deceleration
Waveform 3 > Y restarts with clocks pulses 120µs apart.
This is really brutal, and we have that on X also. Z I cannot tell, and neither on the extruder, but probably it is there too.
I will try to locate the piece of Gcode doing that. This is apparently one of the curves in my Gcode. I would ideally isolate that piece of code doing this, as this would allow Marlin team to debug.
With such erratic steps, no wonder we are loosing some steps, don't you think?
Waveform-1.pdf
Waveform-2.pdf
Waveform-3.pdf
hobiseven
on 3 May 2019
@chrisqwertz you might also want to look at the waveforms I just attached..
hobiseven
on 3 May 2019
@chrisqwertz you are not providing much for anyone to try and reproduce your issue. What do you mean by "irreversible stuttering back and forth of the extruder"? What sort of acceleration do you have set for the extruder initially and how much are you changing it by? How are you changing the acceleration (through gcode or some other way?). What sort of speed are you printing at? Are you running linear advance?
gloomyandy
on 4 May 2019
@hobiseven Hmm that is a pretty high print speed. If it is a complex curve I wonder if you are just running out of movements or something? Do you ever see any sign of this issue at lower speeds? Are you printing from the SD card? Does increasing the BLOCK_BUFFER_SIZE make any difference? Identifying the gcode that triggers the problem would probably help.
I'm rapidly getting out of my depth here. @thinkyhead @ejtagle do you have any suggestions for how to identify the possible cause of this pause?
gloomyandy
on 4 May 2019
@gloomyandy
150mm/s is still ok with this printer. It has an stm32f103 @ 72mhz. We see all huge issues with u20 at lower speeds due to much higher bed inertia. But I did not try that gcode on my machine at lower speeds. I will check. I do print from the sdcard. Block buffer size... I will change it. I wonder if it is linked to the gcode itself, or if any other task is interrupting the pulse process... that should not be but who knows.
Anyway I will reduce gcode size as much as possible. The bottom part geometry is circular, nothing really complex.
hobiseven
on 4 May 2019
@gloomyandy
On top of trying to isolate the part of gcode doing that, I will also probe at the same time x step clk as well as x dir. if x is alive when y is muted that is not an other part of the program beside stepper or planner creating the issue.
hobiseven
on 4 May 2019
@hobiseven Circular motion can be a problem as it is usually emulated by a large number of very short moves, this can cause the stepper to become starved if they can not be fed into the planner fast enough.
Yes it would be good to see if the other drives also stop at this point. If they do it could be some other activity disabling interrupts or something, rather than any sort of starvation problem. It might also be worth setting a pin at the start of the stepper interrupt routine and clearing it at the end and monitoring that pin as well.
gloomyandy
on 4 May 2019
@gloomyandy
More information from this morning. I re-did the test with probes placed on both X and Y, and both steppers stop at the same time. we have a similar gap of 16.5ms. X travelling at 442µs per step, and Y ay 221µs per step.
I did that test with a small gcode which is only a 55mm diameter thin tube, with 0.4mm wall thickness. I did remove all the printer specific stuff, to keep only a 10mm tall tube. All printed virtually at 170mm/s.
The gcode is indeed a succession of tiny straight segments.
I will now enable the pin, and try to see whether or not the stepper isr probe pin , ( the probe signals as per your post, pin getting high when entering the ISR, and set to 0 when exiting ) is toggling or not.
I have 3 other possible pins to probe ISRs. Just tell me where to place them in the code.
Finally, is BLOCK_BUFFER_SIZE parameter the internal buffer size for the Gcode???
All this is one issue, that definitely affects our printers, but I am not yet sure this is the layer shifting issue... Let's see. Waiting for your inputs where to look at now!
hobiseven
on 4 May 2019
@gloomyandy
Attached the simple Gcode,
Bed remains at 20 degrees... we do not care. But to virtually print, I had to heat the nozzle.
hobiseven
on 4 May 2019
@gloomyandy
BLOCK_BUFFER_SIZE set to 64 does not makes any change. Still a gap of 16.25ms .
I am now trying to check the ISR. Standby for this.
hobiseven
on 4 May 2019
@hobiseven Does reducing the print speed have any impact on this? I'm struggling to know what to suggest now to be honest. My understanding is that even if the planner can't keep up you should not really get a big speed jump.
gloomyandy
on 4 May 2019
@jmz52
Is this something you experienced also on your mks robin? As we have the same cpu core you may!
hobiseven
on 4 May 2019
@hobiseven I experienced layer shifts with the ZET6 too, on the JGAurora A5S / A1 board when running marlin, while it was fine with the OEM firmware. Even when printing slow with very conservative acceleration / jerk settings. I have an oscilloscope too, but not sure what testing I can do that would be useful.
pinchies
on 4 May 2019
@pinchies @jmz52 @gloomyandy
By commenting out all the lcd tft code it seems that this problem goes away.
Jmz, as we have the same code you really may get same problems , right??
We are testing prints up to almost 200 mm/s on a few machines right now.
EDIT : NO, the problem DOES not go away. With a proper trigger on the logic analyser, I can say that any speed improvement on the LCD using DMA for FSMC STM32 interface did not change anything. We get 60 clock gaps.
If we disable all the display code before compilation, and run with octoprint, we still get clock gaps, but only 5 or 6 instead of 60. Those clock gaps are exactly the same length as before, 16.25ms. This may or may not result in a layer shift due to mechanical issues, but definitely, the problem remains.
hobiseven
on 4 May 2019
We use octoprint and the printer is headless.
hobiseven
on 4 May 2019
@hobiseven OK so I'm confused what code have you commented out? Did you have a display before? What kind?
gloomyandy
on 4 May 2019
The display these printers (MKS Robin, JGAurora A5S/A1, Alfawise U20/U30 // Longer3D LK1/LK2) use is a TFT colour LCD 320x240, with a neat trick by @jmz52 to 2x upscale and display the normal 128x64 marlin graphic LCD display on the colour TFT.
See: https://github.com/jmz52/Marlin/commit/813a4ea107f3b09b85a29e4446755fe276eba6f4
pinchies
on 4 May 2019
I do not use MKS Robin myself as it does not have enough FAN controls for my printer.
I am using 'black' STM32F407VE dev board with LV8729 drivers for XYZ and A4988 for extruder.
All missed steps problems I had were caused by mechanical imperfections and were resolved on mechanical level.
I had one report about missed steps problem on MKS Robin with LV8729 drivers 1/128 microsteps settings at 200mm/s speed. That particular problem was caused by LV8729 drivers pushed over their limit.
Printer had 800 steps/mm (16 tooth GT2 pulley). LV8729 can handle 1300.000 pulses per second meaning max speed for that printer was 162,5mm/s.
 jmz52
on 4 May 2019
jmz52
on 4 May 2019
@pinchies @hobiseven
There is an alternative code for MKS Robin LCD screens that uses DMA to send data to via FSMC.
Please note that code does not honor the u8g dev/comm functions style and uses custom implementation of 16-bit ESC sequences.
Key feature of this approach is that MCU can run interrupt handler's code while DMA is sending data to LCD controller.
If disabling lcd tft code solves problem with missed step I can suggest to give 'DMA version' a try,
u8g_dev_tft_320x240_upscale_from_128x64.cpp
u8g_com_stm32duino_fsmc.cpp
jmz52
on 4 May 2019
@jmz52
Thank you for your reply.
Indeed I noticed that the touch screen calibration code uses the dma . We will definitely look into this.
T
Commenting out the screen management code really greatly reduces the issue, although it seems not all issues are going away...
hobiseven
on 4 May 2019
@gloomyandy thank you for the help. The lcd is indeed a 320x240 lcd which is displaying a 2x zoomed dogm 128x64 image. We have indeed additional transfers to be done between dogm buffer and the full frame buffer, and then to the screen . For the last one dma will definitely help
@pinches we are starting to include the dma , as well as optimizing the tft lcd code. When printing we do not really need the lcd to show a lot! Do you also have a touch lcd?
hobiseven
on 4 May 2019
Yes, ours is a touch panel too. I got it working with some minor tweaks and calibration to the XPT2046 POC by @jmz52: https://github.com/pinchies/Marlin
pinchies
on 4 May 2019
@pinchies
Same here. However the git from jmz is using dma while the marlin main git does not. I built the first version based on jmz dma , we fixed a lot of issues then mooved to the marlin bugfix branch with newer 5.3.0 libs and no Dma. I will have to profile this. Did you used the 2 methods? Any benefit from dma? Bedside this it seems a lot of time is spent somewhere else in dogm. Do you have any hint?
Edit : as said above, DMA did not change anything to the issue.
This means that the problem is something else. I work on probing the stepper ISR to at least verify that this gets executed during the stepper clock gap. That will give us a first indication.
hobiseven
on 4 May 2019
Dear friends, is the firmware stable now?
Are the problems marked on this image considered layer shifting?

Best regards.
 Alissonverd
on 7 May 2019
Alissonverd
on 7 May 2019
This is not what I call a layer shift, which is the whole thing shifted typically by one millimeter up to centimeter!
hobiseven
on 7 May 2019
Looks more like to some bad extrusion. Which slicer do you use?
guestisp
on 7 May 2019
@guestisp I'm using Cura 3.6.0, it's a good slicer? or maybe a filament quality problem
Alissonverd
on 8 May 2019
That actually looks like a z axis wobble to me. It seems to repeat.
On Tue, May 7, 2019 at 3:09 PM Alissonverd notifications@github.com wrote:
@guestisp https://github.com/guestisp I'm using Cura 3.6.0, it's a good
slicer? or maybe a filament quality problem—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
https://github.com/MarlinFirmware/Marlin/issues/12403#issuecomment-490273013,
or mute the thread
https://github.com/notifications/unsubscribe-auth/AG4YOXUIFJHCEAGGTI4B2ULPUH4YRANCNFSM4GDDKJTA
.
BigE2
on 8 May 2019
@gloomyandy
We are progressing a little bit.
I placed a flag/toggling pin in Marlin main loop, and I attach the waveform I found. it goes to 1 then 0 per each main loop. Each 16ms, the main loop is a little bit longer than most of the time. This is clearly visible on the waveform. It appears that this exactly matches the clock gap we have. 16ms. So one process happening at that occurence in the main code is maybe not filling a buffer or something of that flavor.
I will dig more, and try to identify which part of code takes more time.
I try to probe also inside the step ISR , using a write(step_pin, high) then same with low, but this does not work for some reason. I need to add a delay(1) after the write command to see a pin toggling on the logic analyser. Any idea? I suspect a setting in the HAL but did not found it yet.
Please note, that we disables the SDcard sdsupport and sdio_support also here. I kept the LCD code in, as it makes the bug 10 times more visible. without LCD code 6 clock gaps, with LCD code, 60 gaps.
hobiseven
on 8 May 2019
16ms could be the number of ADC-over samples times temperature-IRQ (~1ms) - where the temp IRQ has somewhat more to do.
AnHardt
on 8 May 2019
@AnHardt Just to be sure I get it right . Are you saying the temperature is probed by ISR every 1ms, but a specific temperature related process is taking place every 16 occurences?
hobiseven
on 8 May 2019
Sorry i miscalculated.
Every 1ms one of the ADC-channels is started/read out. When 16 raw values are sampled from one channel a new temperature is looked up (or calculated). So the produced period should be 1ms * 16 * channels - not 16ms.
Sorry.
AnHardt
on 8 May 2019
Interesting. Personally I would still be looking to see if any code ever leaves interrupts disabled for more than a short period of time. It ought to be possible to modify the disable code to make a not of when it was disabled and check the time in the enable. Anything over say 1mS is very bad. I'd also be tempted to check for a call to disable when interrupts are already disabled, bot are probably an indication that something is wrong.
Actually you could even turn a pin on in the interrupt disable routine and off in the enable and monitor it with your LA.
gloomyandy
on 8 May 2019
One more thing : it is the below code generating the waveform , i will redo one level below, in advance_command_queue...
WRITE(LA_TRIG, HIGH);
// delayMicroseconds(500);
advance_command_queue();
WRITE(LA_TRIG, LOW);
hobiseven
on 8 May 2019
@gloomyandy
I will definitely probe the interrupts as soon as I understand why the ST32 pins are not toggling without a delay command... For tonight, i drilled down a bit in the code, and I got down to gcode.gpp
// Parse the next command in the queue
WRITE(LA_TRIG, HIGH);
delayMicroseconds(500);
parser.parse(current_command);
process_parsed_command();
WRITE(LA_TRIG, LOW);
delayMicroseconds(500);
hobiseven
on 8 May 2019
I have continued my investigations, and it is not obvious this is a parser issue unfortunately. I still cannot manage to get output pins to toggle during an ISR either temp or stepper .
However, I discovered that using this :
define JUNCTION_DEVIATION
if ENABLED(JUNCTION_DEVIATION)
#define JUNCTION_DEVIATION_MM 0.03 // (mm) Distance from real junction edge
endif
Is actually reducing the problem occurence by a factor of 10 to 20. Rather than getting 60 discontinuities on my test Gcode, attached, I only get 3 to 6. And before, I could even get double discontinuities, I only saw single, 16ms discontinuities.
Only that setting made such a change. I will look where this setting is changing things, but I assume this is in the planner, correct?
The bug is still there, but appears way less frequently. Still 16ms with no stepper clocks.
Question : Does anybody knows why a command like WRITE(PIN_TEST, (volatile boolean) 1); does not work in the ISR processes???? I cannot get the pins to toogle.
hobiseven
on 9 May 2019
I have continued my investigations, and it is not obvious this is a parser issue unfortunately. I still cannot manage to get output pins to toggle during an ISR either temp or stepper .
However, I discovered that using this :define JUNCTION_DEVIATION
if ENABLED(JUNCTION_DEVIATION)
define JUNCTION_DEVIATION_MM 0.03 // (mm) Distance from real junction edge
endif
Is actually reducing the problem occurence by a factor of 10 to 20. Rather than getting 60 discontinuities on my test Gcode, attached, I only get 3 to 6. And before, I could even get double discontinuities, I only saw single, 16ms discontinuities.
Only that setting made such a change. I will look where this setting is changing things, but I assume this is in the planner, correct?
The bug is still there, but appears way less frequently. Still 16ms with no stepper clocks.
Question : Does anybody knows why a command like WRITE(PIN_TEST, (volatile boolean) 1); does not work in the ISR processes???? I cannot get the pins to toogle.
This echo's our discovery way back in the beginning that enabling JD drastically reduced the occurrences. This was part of the logic on it being moved from config_adv to config and jerk being labeled classic jerk. Now you have data showing the difference in pulses instead of just my observed decreased likelihood of shifting!
InsanityAutomation
on 9 May 2019
Does anybody knows why a command like WRITE(PIN_TEST, (volatile boolean) 1); does not work in the ISR processes
There is no reason it shouldn't on Marlins side, stepper pins are always toggled from an ISR, and I often use an extra pin at the start and end of ISRs to test timing.
 p3p
on 9 May 2019
p3p
on 9 May 2019
Is the pin configured to be an output pit with SET_OUTPUT()?
 ManuelMcLure
on 9 May 2019
ManuelMcLure
on 9 May 2019
I know that but there might be something either in the compiler or somewhere!! My logic analyser says the truth!
Are you doing that using stm32,and platformio/vscode??
hobiseven
on 9 May 2019
I use pinmode (output)...
hobiseven
on 9 May 2019
Is there any architecture documentation about the sw as a whole??
hobiseven
on 9 May 2019
I think pinMode() is Arduino-style which may not work with WRITE() which is FastIO style. SET_OUTPUT() is the FastIO function to declare a pin as output. But I'm not certain - I'm sure someone more knowledgeable will chime in if I'm mistaken.
ManuelMcLure
on 9 May 2019
Ok I try this immediately! If i can time the it’s that may help.
hobiseven
on 9 May 2019
Are you doing that using stm32,and platformio/vscode??
No only AVR and LPC, pinMode() should be okay, all the STM HAL implementations apart from STM32F1 use that for SET_OUTPUT anyway..
I know that but
I was just answering the question directly, if you are getting stepper signals WRITE is working from an ISR so .. the problem had to be somewhere else, pin configuration or conflict (being reinitialised somewhere else in Marlin after you set it as output)
p3p
on 9 May 2019
No only AVR and LPC, pinMode() should be okay, all the STM HAL implementations apart from STM32F1 use that for SET_OUTPUT anyway..
LPC uses gpio_set_output() for SET_OUTPUT() - the only reference to pinMode() in the LPC HAL is in _PULLUP()/_PULLDOWN() and the unused SET_MODE() macro.
ManuelMcLure
on 9 May 2019
LPC uses gpio_set_output() for SET_OUTPUT()
I know but he is using an stm platform so I only mentioned those, if pinMode was used it would make no difference functionally, although it would be slower. unless there is something odd about the stm32 Arduino framework.
p3p
on 9 May 2019
I will change the pin. It is so frustrating to not be able to do a simple basic probing like that!
hobiseven
on 9 May 2019
I tried again to probe the ISR code but no luck. I can place write(pin,(volatile bool)1); in the parser code, and it works, but not in the stepper code still. And indeed, I confirm this is a STM32.
@JMZ52 do you have any idea why it would fail on some pins? Could there be an incompatibility of some pins? I used PC14 and PE5. I know it is not directly a question about the thread, but it would help me. I removed -O3 compiler flag..
hobiseven
on 9 May 2019
Does M43 (PINS_DEBUGGING) say anything special about those pins? Although the fact that it works from the parser seems to imply that it isn't a basic problem with the pin...
ManuelMcLure
on 10 May 2019
All, I found my - really stupid - mistake on the pin probing. I was a bit lazy and place a probe behind a debouncer / RC.
So, I will redo probing tonight, and I will printout step, temp ISR, as well as parsing process. And If needed I can also put additional pins to probe.
Can some of you precisely point out in the temperature ISR where to probe, and put a pin on / off?
I already got this for stepper IST from @gloomyandy .
hobiseven
on 10 May 2019
After correcting my beginner's mistake, here we are : No stepper ISR during the glitch. See the pict.
I will now check what happens in dryrun mode, with no heat.... I think I need to remove the heat command from Gcode, and place an M111 S8, correct?
If you want zoomed images around anywhere I can do, at ot below CPU clock cycle.
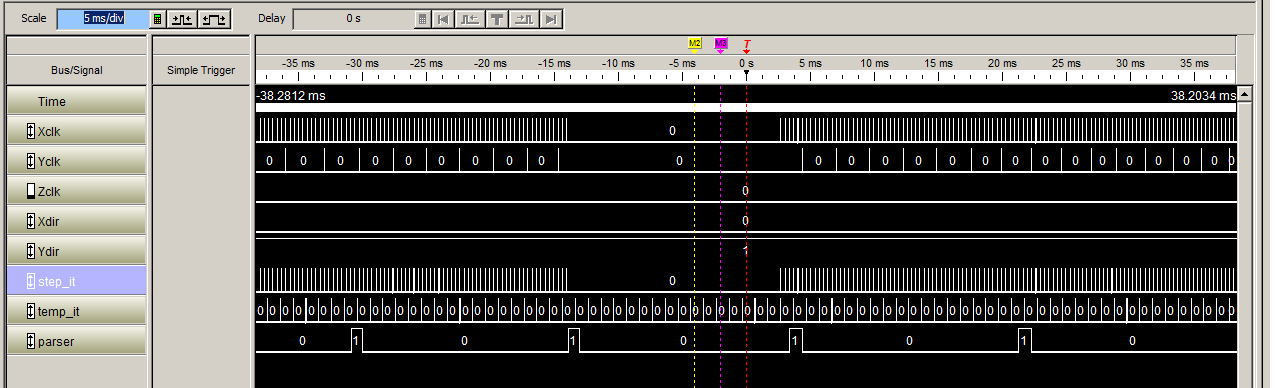
hobiseven
on 10 May 2019
I also checked if there was a lack of blocks : No.
See attached code, and picture that goes with it :
void Stepper::stepper_pulse_phase_isr() {
WRITE(STEP_IT, (volatile bool) 1);
// If we must abort the current block, do so!
if (abort_current_block) {
abort_current_block = false;
if (current_block) {
axis_did_move = 0;
current_block = NULL;
planner.discard_current_block();
}
}
if( !current_block){
WRITE(NOBLOCK, (volatile bool) 1);
WRITE(NOBLOCK, (volatile bool) 0); }
// If there is no current block, do nothing
if (!current_block) return;
hobiseven
on 10 May 2019
And to be complete, here is the code for the parser signal in gcode.cpp
// Parse the next command in the queue
WRITE(PARSER_FLAG,(volatile bool) 1);
parser.parse(current_command);
process_parsed_command();
WRITE (PARSER_FLAG,(volatile bool) 0);
}
hobiseven
on 10 May 2019
I did try to run a dry run, not too sure about the Gcode, but there is no change. No heating, but the temperature isr still runs. No change, bug is still there. 60 stepper pulse holes in average.
hobiseven
on 10 May 2019
After placing some flags at IT disable points for the stepper, the one which is right before stepper IT are disapearing, is in planner.cpp, line 2144. at each clock gap, this is where the CPU goes.
hobiseven
on 11 May 2019
https://github.com/MarlinFirmware/Marlin/blob/bugfix-2.0.x/Marlin/src/module/planner.cpp#L2057-L2065 in current git
tpruvot
on 11 May 2019
I rechecked all the interrupt disable / enable I could, and specifically for the enable, I would not find any that is matching the ISR resume.... the only reason interrupts could not happen, might be that they are not requested..
I checked and placed a probe signal in case within the stepper isr, value next_isr_ticks would become larger than 4K. This is not it either.Typically above 2000 with my Gcode at the "bug" location, but not above 4000, hence this is not a wrong "next_ist_ticks" calculation.
Last thing I can think off is a possible timer stopped by something else. I will check that now.
hobiseven
on 11 May 2019
Has a fix been found, I updated to marlin 2.0 so I can run mmu2, I've been getting consistent layer skips in the negative y direction, which I know is not a mechanical issue, as I have dual y axis steppers with tmc 2208 in stand alone mode.
Tried adjusting pront speed, feed rate, acceralting and jerk values to no avail
Ended up reducing jerk from 30 to 10
And acc from 3000 to 1500 to 800
 0lympu5
on 11 May 2019
0lympu5
on 11 May 2019
One more observation : CPU Freq = 72Mhz, step timer prescaler = 18, Step timer frq = 4mhz. .25µs per tick.
16 bit timer roll over > 65536 * .25µs > 16.3ms... and this is the length of the "bug" . Do we miss an interupt???
hobiseven
on 11 May 2019
@0lympu5 So far, no, we did not found. This is definitely not a mechanical issue. What CPU are your running? what freq?
hobiseven
on 11 May 2019
@hobiseven it's a ramps 1.4 with a arduino mega 2560 chip set I believe
0lympu5
on 11 May 2019
@0lympus5 this is a very different cpu .... can t really compare
hobiseven
on 11 May 2019
Ah okay, sorry for that, do you know of any fixes I can try or another forum page I could look at
0lympu5
on 11 May 2019
@0lympu5 - Please check you have a cooling fan over your TMC drivers, they run hot. Also look into tuning the stepper driver voltage. Too high or too low vref can both cause layer shift issues.
pinchies
on 11 May 2019
@pinchies this issue is not specific to a platform and people reported issues with various ones (including AVR).
Most people including myself see their layer-shift issues vanish when :
- downgrading to marlin 1.x
- enabling Junction Deviation (seems like the reason was found by hobiseven a few comments above).
- enabling spreadcycle on X/Y when using TMC drivers (totally fixed the problem for me, but noisier).
- double-checking hardware / configuration issues (mostly max accelerations and travel speeds iirc).
Hence the issue title : "reportS and solutionS".
 Moyster
on 11 May 2019
Moyster
on 11 May 2019
Please check the usernames - I was just replying to 0lympu5 specific situation, they mentioned they use ramps with TMC2208. From what I have been able to gather, there appears to be several possible bugs in here, I'm definitely trying to keep up :) - I'm specifically interested in STM32 Marlin 2.0 bugs in particular though, as that's the platform I'm suffering layer shifts on.
pinchies
on 11 May 2019
@pinchies
Indeed what I see is on an stm32f1 platform and I do not pretend this is the sole issue, but it is a real audible issue on our stm32. We tried increasing vref, as well as junction deviation but this is just a band aid and does not cure the issue. I try right now to understand possible limit cases in the isr routine. This is generic code but the timers and latencies are more platform dependent... more tomorrow
hobiseven
on 11 May 2019
Yeah only reason I ask is I'm sure it's a software issue as it was fine till changing to 2.0
0lympu5
on 11 May 2019
Tomorrow i will change my logic analyser setup, and I will use the FSMC LCD parallel interface to read out variables values right at the stepper ISR exit. I have a strong suspicion on the timer reload value. I should be able to make a short list of a few values, if all is fine. I should be able to get 16 bit data at 1mhz. I will have to use a short LCD cable, as the probes will add significant capacitance. Let's see tomorrow!
hobiseven
on 11 May 2019
@hobiseven If you can give me your test setup and your code changes, I can use my logic analyzer do verify your findings on an lpc1768 platform (Re-Arm Board)
chrisqwertz
on 11 May 2019
No problem I will let you know what I find and how I test it. I hope it will be meaningfully tomorrow evening!
hobiseven
on 11 May 2019
This is checked on an STM32F103VE. It might be related to ST chip, or to ARM core. This is unknown right now. Or it can be a HAL issue.
These are my latest findings, which are not what I expected to find! Would have been too easy.
I now have a hardware debug setup, with the motherboard extracted from the printer, connected to a spare LCD screen, so I can see what goes on. I replaced the long LCD cable by 2 really short ones, and inserted in the middle 2 FFC cable to DIP40, and soldered some pins on that, so I can plug LA probes to any of the wires. That LCD interface has a 16bit multiplexed adress / data bus. See the picture.
I adapted the stress test gcode, which is a huge washer 120mm diameter, with a hole of 40mm in the middle to run on this setup. Dry run, no homing, and no temperature monitoring. We "print" cold. I also made all the plastic prints circular shapes to increase as much as possible the number of G1 short mooves. This runs in real, as well as disconnected. Origin is lower left corner, and print is centered in the middle of the 225x225 bed. Gcode attached below.
I did place at the end of the stepper ISR 2 additional lines in the code, one to toggle the step_isr pin probe to 0, so I can detect when we are about to exit the ISR and re-enable interrupts, and a second line, which is writing the next reload value in the timer on the LCD interface, so we are ready for the next interrupt, to be generated approximately 120µs later.
Code :
// Now 'next_isr_ticks' contains the period to the next Stepper ISR - And we are
// sure that the time has not arrived yet - Warrantied by the scheduler
// Set the next ISR to fire at the proper time
HAL_timer_set_compare(STEP_TIMER_NUM, hal_timer_t(next_isr_ticks));
// Don't forget to finally reenable interrupts
WRITE(STEP_IT, (volatile bool) 0);
LCD_IO_WriteData (next_isr_ticks);
ENABLE_ISRS();
}
And I unfortunately have to report that the reload value on the last 2 interrupt before the stepper clock gap is the same as the one that was loaded right at the gap. In my case I get :
- red marker at -14.2373ms, reload 0x1DC
- yellow marker at -14.1164ms, reload 0x01DC > gap with red = 120.8 µs
- green marker at -13.9954ms, reload 0x1DC > Gap with yellow = 121 µs
- purple marker at 2.5086ms, reload 0x1DC.... > Gap with green = 16.504 ms
Our stepper timer is running @ 4Mhz, 0.25µs per tick. This is given by the 18 preloader ratio. CPU @ 72Mhz. The TImer has a 16bit counter in this CPU.
One full 16 bit iteration = 65356 * 0.25µs = 16,384 ms, and if we add the requested delay,
We have 16.384 + 0.121 = 16.505 ms, which is what we find as a gap.
Conclusion > The ISR calculations and timer reloads are correct. next_isr_ticks is well calculated.
The timer should be reloaded / is reloaded with the correct value, but it is like this is not taken in account , and we have a complete 16 bit cycle plus the requested delay.
We have to dig in the STM32F1 HAL to understand what goes on here.

hobiseven
on 12 May 2019
Stress test Gcode with no homing, dryrun, + picture of the LA.
The LA trigger condition is : clkx+clky+clkz = 0 for more than 14ms. ( I have also seen shorter clock gaps, but that is an other bug... ;-) )
And a simple check : Reload value of the counter is correct : 0x1DC = 476, and 476*0,25µs = 119µs > close to the 120.8 we measured.
 hobiseven
on 12 May 2019
hobiseven
on 12 May 2019
Nice work! Just been looking at the code for the stepper ISR. Could you add some code that will toggle an I/O line if the following condition is ever triggered:
if (!--max_loops) next_isr_ticks = min_ticks;
it is this line here: https://github.com/MarlinFirmware/Marlin/blob/bugfix-2.0.x/Marlin/src/module/stepper.cpp#L1368
Seems to me that this could possibly be causing the problem you are seeing if you have a large number of very short moves.
gloomyandy
on 12 May 2019
@gloomyandy
Will do, and will give you the result,
but with @tpruvot we just identified a change in the STM32F1 HAL header files, specifically about the timer update. We will revert to the old code...
hobiseven
on 13 May 2019
yep, unfortunately, adding pause/update/resume in HAL_timer_set_compare didnt help. same shocks...
but its nice to know that happens even without motors connected...
tpruvot
on 13 May 2019
Indeed will be good to check if this is related to that cpu type stm32f103vet6 or if it is present on other stm32 cpu types or on othe m3 arm. And I dare to mention cpu clones... @tpruvot you will let us know if we have the same on skr... stm32f103c...
I have for tonight debug session
1- read back timer after update to check the value and demonstrate we have this bug
2- possible fix in mind should that really be our issue
hobiseven
on 13 May 2019
I had another "idea/intuition" this night... Could some "clock domain" reconfigure affect the timer clocks ?
tpruvot
on 13 May 2019
Please check the code I pointed you at. If that code is ever used. Then you will only have a very short period of time (less than 1uS) to update the timer counter and exit the ISR, if you fail to do this then you will have to wait for the timer to wrap around (exactly as you are seeing). At least that is my interpretation of that code!
gloomyandy
on 13 May 2019
Yep, will do tonight! Not an easy one to nail down! The other track we have is that we update the register too late. Will let you know what I see.
So that is 3 items to check tonight!
hobiseven
on 13 May 2019
Hi printers...
Well, this is really a tough one.
I checked the piece of code : if (!--max_loops) next_isr_ticks = min_ticks;
And we never have that condition...
I also checked the variables values that we send to the counter reload, and they are also correct, actually, usually the same one as one interrupt before, of just different by one or 2 units. I read back the value we wrote, and it is normal, ie same as the one we wrote.
I checked the overall interrupt time, and they are the same.
I checked the the counter is incrementing since the beginning of the interrupt ( actually the event is slightly before), and we usually have a value of 0x2D when we write the compare value in the compare register, typically with 0x0400, so the counter is not above the compare value.
I checked that there was no temperature interrupt during the stepper interrupt, and no.
I also placed during the temperature ISR a stepper read counter, and I can indeed see the stepper timer increasing until roll over.
It is exactly like if for some very obscure reason, rather than loading the compare register, we load the "shadow" register, and we get this taken in account at the next event, which is 0 crossing. The counter then continues to increase until it reaches the correct value, and all operations resume normally.
I do only see 2 things remaining :
1 - the counter compare register update procedure is not correct. I will try to get answers from friends at STM. MAybe we should stop the timers to reload the compare value. There was a change in the HAL back in september 2018, and we reverted the code to that... No change.
2 - for whatever reason, the chip I get on the board is a crap one ( but then all the 20 or so chips from beta testers are crap too)...
Practically, I am getting out of ideas about what to change now. We also reprogrammed the HAL to use different timer channel > No change.
Last thing I can try is buy an other model of STM32F103VET6 board , and load marlin on it, then check.
I would need to by a real ST board to be sure.
Last thing, but that would be a very last resort > Open the chip to see what it really is... I am really getting out of ideas.
Gosh... really frustrating. I can see everything almost going on in the device.
hobiseven
on 13 May 2019
Asking folks that know the STM chips well would be a good idea. It may also be worth checking to see if there are any errata for the chip, you often find that there can be subtle bugs like this hiding away.
gloomyandy
on 13 May 2019
Absolutely correct sir. I am crawling through those!
hobiseven
on 13 May 2019
Actually, just thought about an ugly, but possible fix
99.99% of the time, the direct/shadow (as ST calls it) compare register load works, but 0.01% of the time, the non direct register is used to reload at the next event ..
Why don't we use all the time the non direct register? maybe that can work. I will give it a try.
It would mean that we would have to store the decision flag to execute steps in a static variable, as this would be used on the next ISR. We would simply shift everything by 1 ISR cycle. That may have an impact on the internal buffer....
And of course, I will ask STM. There is nothing I could find in their errata, but their revision number is 15....
hobiseven
on 13 May 2019
Is it also happen to LPC1768 (ReARM) and Atmel SAM3X8E ARM (Arduino DUE) ?
robbycandra
on 14 May 2019
@robbycandra,
I found apparently a fix, which works on the analyzer but I have not tried in real yet. Too late
And there is a possibility that it is a simple config bit in timer.h from libmaple which is incorrectly set : ARPE . As far as I understood libmaple sets it by default to 1, and for direct timer register updates we want it set to 0.
In either case, we test live the workaround tomorrow and we check that bit in timer.h
Gosh.... I am tired!
hobiseven
on 14 May 2019
@hobiseven , I appreciate your effort. And i think we all waiting for you. But sleep and rest are important.
robbycandra
on 14 May 2019
fix can be found there :
https://github.com/hobiseven/Marlin_2.0.X_Beta_Alfawise_Ux0/commit/4019a15f9819b49dcc5e18a0630ce8e9a5c57145
tpruvot
on 14 May 2019
So, what we have here finally is a mismatch between the timer modes declared in the libmaple and the usage of the timer done in the stepper ISR.
at the end of the ISR, we intend to reload the compare register in the stepper timer with an immediate value, to be used fo the current count. Typically the stepper timer is at about 0x20 to 0x30 when reload occurs.
In libmaple, we have a timer declaration with apparently ARPE flag enabled> preload enabled ( shadow registers that immediately reload the compare counter at next timer event)
And this is not a correct combination.
either we have :
1 / ARPE flag enabled, we can only reload a register that will become the compare value after next IT is generated. That works and we have already 1-2 hours of print at 200mm/s with no layer shift. Please note that since we delay the count reload to next IT, we should also delay the step command / decision to next IT too.... But the error is tiny.
The correct command to reload at the end of the ISR is then :
HAL_timer_set_reload(STEP_TIMER_NUM, hal_timer_t(next_isr_ticks));
and the corresponding timer init sequence is HAL_timers_STM32F1.cpp
case STEP_TIMER_NUM:
timer_pause(STEP_TIMER_DEV);
timer_set_mode(STEP_TIMER_DEV, STEP_TIMER_CHAN, TIMER_OUTPUT_COMPARE); // counter
timer_set_count(STEP_TIMER_DEV, 0);
timer_set_prescaler(STEP_TIMER_DEV, (uint16_t)(STEPPER_TIMER_PRESCALE - 1));
timer_set_reload(STEP_TIMER_DEV, 0xFFFF);
timer_oc_set_mode(STEP_TIMER_DEV, STEP_TIMER_CHAN, TIMER_OC_MODE_FROZEN,
TIMER_OC_PE); // no output pin change, enable preload
timer_set_compare(STEP_TIMER_DEV, STEP_TIMER_CHAN, MIN(hal_timer_t(HAL_TIMER_TYPE_MAX), (STEPPER_TIMER_RATE / frequency)));
timer_attach_interrupt(STEP_TIMER_DEV, STEP_TIMER_CHAN, stepTC_Handler);
nvic_irq_set_priority(irq_num, STEP_TIMER_IRQ_PRIO);
timer_generate_update(STEP_TIMER_DEV);
timer_resume(STEP_TIMER_DEV);
break;
2/ not tested yet, and we hope it will work :
No arpe flag, and for that we need to change the stepper timer init in HAL_timers_STM32F1.cpp
case STEP_TIMER_NUM:
timer_pause(STEP_TIMER_DEV);
timer_set_mode(STEP_TIMER_DEV, STEP_TIMER_CHAN, TIMER_OUTPUT_COMPARE); // counter
timer_set_count(STEP_TIMER_DEV, 0);
timer_set_prescaler(STEP_TIMER_DEV, (uint16_t)(STEPPER_TIMER_PRESCALE - 1));
timer_set_reload(STEP_TIMER_DEV, 0xFFFF);
timer_oc_set_mode(STEP_TIMER_DEV, STEP_TIMER_CHAN, TIMER_OC_MODE_FROZEN,
TIMER_OC_NPE); // no output pin change, disable preload
timer_set_compare(STEP_TIMER_DEV, STEP_TIMER_CHAN, MIN(hal_timer_t(HAL_TIMER_TYPE_MAX), (STEPPER_TIMER_RATE / frequency)));
timer_attach_interrupt(STEP_TIMER_DEV, STEP_TIMER_CHAN, stepTC_Handler);
nvic_irq_set_priority(irq_num, STEP_TIMER_IRQ_PRIO);
timer_generate_update(STEP_TIMER_DEV);
timer_resume(STEP_TIMER_DEV);
break;
and we should be able to use the Marlin code as it is defined, and the command at the end of the ISR
HAL_timer_set_compare(STEP_TIMER_NUM, hal_timer_t(next_isr_ticks));
We will test this option 2 tonight. Beside this major bug, which may or may not be in other HALs, there are other bugs that we are going to look at....
You might want to check on other chips how your timers are initialized. direct reload, or indirect/preload
hobiseven
on 14 May 2019
the F4 may be also affected, but unsure https://github.com/rogerclarkmelbourne/Arduino_STM32/blob/master/STM32F4/cores/maple/boards.cpp#L174
tpruvot
on 14 May 2019
Well, looking at the code, I also see :
https://github.com/rogerclarkmelbourne/Arduino_STM32/blob/master/STM32F4/cores/maple/boards.cpp#L160
We have to understand whether the issue is a "bug" of the F1, or normal.
I hope my conclusions above are correct.
hobiseven
on 14 May 2019
Finally I retested the code disabling timer preload mechanism and we still have the bug. So , as presented in my post above option 1 ok and option 2 not ok. We have to get the timer to work with it’s preload register...
We will now focus on othe bugs , one recent which is that the head , right in the middle of a print mooves on x or y until the limit with no reason.... i will do that in an other thread!
hobiseven
on 14 May 2019
@pinches please try this in your stm32f103z which has a different package.
@chrisqwertz would be good to make a check in lpc libs and try to use the register in preload mode if it is not the case. I also have one French forum person that had jumps and I will try that change on his board .
hobiseven
on 15 May 2019
@hobiseven as far as I can tell there is no "preload mode" for the LPC176x devices. I had a quick look at the code (and the technical docs) yesterday and can't see any problem with how that device is handling the setting of the timer.
gloomyandy
on 15 May 2019
@gloomyandy
Ok so there might be an other issue..!
What I will do is then change the definition of the trigger , assuming that there might be shorter jumps. Rather than triggering on 14ms clock gaps I will look for much shorter ones. When the printer is printing is it safe to assume that head speed will never be lower than any of the jerk values? X y and z? If this is the case then the maximal clock gap should be defined by the slowest axis ie z.
Is this correct?
I will try to find other clock gaps....
hobiseven
on 15 May 2019
@hobiseven I think that is correct, but with linear advance enabled I'm really not sure what happens with the extruder.
The problem with missed steps is that there can be so many possible causes, so yes I'm sure there will be other issues. So for instance there is the very short pulse that was reported by @chrisqwertz and for which there is still not an actual fix for (other then specifying a miniumum pulse setting).
gloomyandy
on 15 May 2019
@gloomyandy
You talk about the really fast clock ie below 30ns...that one is still on my radar screen. As my LA is capable of 4Ghz sampling I can try to catch it.... but I just have regular probes. Let’s see. This cannot be generated by the cpu, that is too fast. Maybe this is simply the gpio value update... ok i have a look to that one, and also to the « z minimal speed » clock gap. I will leave linear advance disable for the time being.
hobiseven
on 15 May 2019
No I'm talking about the narrow pulse generated by linear advance. That one is certainly generated by the Marlin code, but all we have is a work around.
gloomyandy
on 15 May 2019
I found something interesting while comparing the STM32F1 HAL with the LPC1768.
In Marlin\src\HAL\HAL_LPC1768\HAL_timers.h
It looks like; we're missing break statements. Both timer interrupts are always en/disabled no matter which you want to select.
FORCE_INLINE static void HAL_timer_enable_interrupt(const uint8_t timer_num) {
switch (timer_num) {
case 0: NVIC_EnableIRQ(TIMER0_IRQn); // Enable interrupt handler
case 1: NVIC_EnableIRQ(TIMER1_IRQn); // Enable interrupt handler
}
}
FORCE_INLINE static void HAL_timer_disable_interrupt(const uint8_t timer_num) {
switch (timer_num) {
case 0: NVIC_DisableIRQ(TIMER0_IRQn); // Disable interrupt handler
case 1: NVIC_DisableIRQ(TIMER1_IRQn); // Disable interrupt handler
}
That is indeed interesting, appears to have been lost in the cleanup at some point.
p3p
on 15 May 2019
Not quite, The Temperature ISR runs on timer 1, so it was being disabled whenever the Stepper Interrupt was, but not the other way round. It was an interesting oversight but wouldn't have been causing any problem I can think of.
p3p
on 15 May 2019
All,
The bug we observed with STM32F103 is that while the stepper counter reached the compare value, for some reason, one interrupt over 1 milion is lost, resulting in the counter to wrap, and again hit the compare value 16.384ms later. We totally fixed the issue by not using the compare feature ( + ISR epilogue with the code reloading counter to 0), but using the counter autoreload to 0 . We disabled all buffers / preload functions.
So, for STM 32F1, we are fine.
If any of your ARM CPUs do use a compare/capture mecanism that triggers an interrupt, and you do not have an autoreload to zero mecanism like the STM chip, you can be subject to the same bug. This is an issue between the compare output, and NVIC interrupt controler. This depends of your ARM core revision also.
As I just provided samples of NXP LPC1778 to Marlin team, i will check with them once the board would be running, and try to probe for stepper clock gaps.
Bottom line, for STM32F10, issue closed.
And we have just submitted a PR. For thos who need the fix right now, please checl STM32F1_timer.h and .cpp files in my git : https://github.com/hobiseven/Marlin_2.0.X_Beta_Alfawise_Ux0/commit/83c9dbb1d3661bbda9d923ca0f8868c0c6fd4b99
hobiseven
on 24 May 2019
I've been getting good feedback from users on ZET6 after applying this patch.
pinchies
on 24 May 2019
@pinchies We updated the patch a few hours ago, and that last iteration is exactly doing what the initial code needs. So please make sure you load the last version...
hobiseven
on 24 May 2019
@chrisqwertz Currently there isnt a board around them yet! They were sent to the person developing a 12 stepper 6 hotend pcb around one.
InsanityAutomation
on 24 May 2019
Can I add you?
chrisqwertz
on 24 May 2019
To be sure, you joined the Marlin channel correct? https://discord.gg/qudwZS6
InsanityAutomation
on 24 May 2019
now i am
chrisqwertz
on 24 May 2019
Did you publish the fix in the latest release? I very recently got rearm and was swapping between Arduino and re arm to see if there was a mechanical error. Where can I get the fix?
 omercanvural
on 25 May 2019
omercanvural
on 25 May 2019
For those who need the fix right now, please check HAL_timers_STM32F1.h and HAL_timers_STM32F1.cpp files in my git : hobiseven/Marlin_2.0.X_Beta_Alfawise_Ux0@83c9dbb
will be published soon. PR made. obviously only for STM32F1!
hobiseven
on 25 May 2019
Afaik re-arm is LPC1778, right? I was hoping to test tomorrow. Is there a chance to get fixed files for it as well? If it is something hard just ignore me please, I can wait it to get master branch release. I don't wanna be pushy, just wanted to try it and provide some feedback if i can.
Thanks.
omercanvural
on 25 May 2019
Lpc1768
On Sat, May 25, 2019, 00:50 Ömer Can VURAL notifications@github.com wrote:
Afaik re-arm is LPC1778, right? I was hoping to test tomorrow. Is there a
chance to get fixed files for it as well? If it is something hard just
ignore me please, I can wait it to get master branch release. I don't wanna
be pushy, just wanted to try it and provide some feedback if i can.Thanks.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/MarlinFirmware/Marlin/issues/12403?email_source=notifications&email_token=ABCNNWVKEONJLIEOSJVELYTPXBWMPA5CNFSM4GDDKJTKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGODWGW2ZY#issuecomment-495807847,
or mute the thread
https://github.com/notifications/unsubscribe-auth/ABCNNWRUDLGZ5VJIQUBZNZDPXBWMPANCNFSM4GDDKJTA
.
chrisqwertz
on 25 May 2019
my fix will not do anything for you... it is specific STM. i have no idea about the potential, if any, issues on LPC
hobiseven
on 25 May 2019
Stock CR10S printer, working fine for 12+ months on stock firmware; updated to Marlin 2.0 bugfix, and layer shifts every print.... can confirm switching back to stock or th3d resolves problem, but keen to get Marlin 2.0 working :)

 Zetrox2k
on 30 May 2019
Zetrox2k
on 30 May 2019
@Zetrox2k What are the Max Feed Rate, Acceleration and Jerk numbers you were using for the Marlin 2.0.0 code? What are those numbers in the stock firmware that does work?
Roxy-3D
on 30 May 2019
@Roxy-3D - Max Feedrates, acceleration, & jerk settings as follows. these are taken from the stock firmware.
define DEFAULT_MAX_FEEDRATE { 300, 300, 5, 25 }
define DEFAULT_MAX_ACCELERATION { 500, 500, 100, 5000 }
define DEFAULT_ACCELERATION 500
define DEFAULT_RETRACT_ACCELERATION 500
define DEFAULT_TRAVEL_ACCELERATION 1000
#define DEFAULT_XJERK 5.0
#define DEFAULT_YJERK 5.0
#define DEFAULT_ZJERK 0.4
define DEFAULT_EJERK 5.0
kmags on the discord server advised that i need to set my X Y Z E Jerk values to half theyre original value, so basically 2.5, 2.5, 0.2, 2.5?
Not sure if i halve the values on X Y Z & E, or just X Y Z
Zetrox2k
on 30 May 2019
@Zetrox2k What numbers did you use for the Marlin v2.0.0 build where you saw the layer shifts?
Both sets of numbers are important. And some of the numbers don't map 1 for 1. There was a bug fixed in the Planner where it wasn't respecting some number. That was fixed, but suddenly, old values that used to work have problems with the more correct and accurate Planner.
Roxy-3D
on 30 May 2019
@Roxy-3D Those are the values from both my stock firmware, and my Marlin 2.0 build. I copied them 1:1, figured that was the safest bet.
Zetrox2k
on 30 May 2019
@Roxy-3D Stock firmware i had no issues with stock firmware, but in 2.0 got layer shifts on every print.
Zetrox2k
on 30 May 2019
Playing with the acceleration and jerk is just a band aid. You are not tackling the real problem.
We now have here a community of happy 3Dprinter people enjoying smooth operation on stm32 alfawise boards with marlin 2.0.x bugfix after fixing the Hal .
I would recommend to hookup a cheap logic analyser on stepper clocks to verify wether or not you have clock gaps.
Does your machine always moove smoothly ? Just placing your hand on the frame will let you feel if you have clock gaps, that can be caused by many things.
hobiseven
on 30 May 2019
Just made a new printer and I moved from Arduino MEGA2560 to LPC1768 (SKR1.1) with TMC2130 drivers. First print with bugfix2.0 = layershifts every 10 layers or so. Print speeds were far from what the machine should be able to do. I'll dig up my salae clone to do some capture but I've no clue what signals should be worth checking. I presume dir/step are the ones. Do I also need to capture SPI signals ?
DavidThijs
on 15 Jun 2019
Had something similar. After switching from MKS gen L to SKR 1.3 I started to have layer shifts. I was able to reduce it significantly by add a fan for driver cooling (TMC2130). But still don't understand, because with the MKS gen L I didn't had to cool the drivers.
 jjansen85
on 16 Jun 2019
jjansen85
on 16 Jun 2019
@jjansen85 Did you run the same drivers with the same operating modes at the same current with your previous board? Did you run the same version of Marlin?
gloomyandy
on 16 Jun 2019
@jjansen85 Did you run the same drivers with the same operating modes at the same current with your previous board? Did you run the same version of Marlin?
Maybe you have a valid point. I just checked new and old config.
Previously I used 600 mA, now it is set at 650 mA. I should check if SKR gives issues with current set to 600 mA without extra cooling. Drivers and operating modes are the same. MKS was with marlin bugfix 2.0 from january '19, SKR with the version of somewhere in april.
jjansen85
on 16 Jun 2019
Am seeing strange random blocking noises on LPC1768 but no layer shifts, and am researching, when I found this issue here.
Have I understood correctly: For timers on STMF1 set up to interrupt on match, it is possible they might miss the interrupt and thus roll over and then match - the 16ms gap for stepping comes from that? So you fixed this by not using the compare feature.
It seems on an LPC1768 I don't have that option.
But I discovered the Repetitive Interrupt Timer and a System Tick Timer (in addition to the normal Timer0-3). Maybe the RTT does not miss interrupts? Has anyone any thoughts about using those for stepper interrupts (RIT) and for thermal control (STT)?
Edit: Please discard the last paragraph. The RIT won't cut it and the STT is too inflexible.
 BigIronGuru
on 16 Jun 2019
BigIronGuru
on 16 Jun 2019
As far as I know so far there is no indication that there is a problem with the way Marlin uses the timers on the LPC176x based systems. Do you have any evidence of a problem?
I seem to remember on the STMF1 there was a 16bit register involved which resulted in the 16mS gap when things went wrong, I have a feeling that on the LPC1768 if there was a similar bug then you would have to wait for a 32bit wrap around (which with the 1uS tick time that I think this timer uses, is a long time). But it has been a while since I've looked at this code so I may be wrong.
The RIT is in use for the software UART implementation. I have a feeling that the STT may already be in use to provide basic delays etc.
gloomyandy
on 16 Jun 2019
The LPC176x uses 32bit timers so if it has a roll over you will notice when the printer stalls for a few minutes, not a little hickup, as far as I'm aware there are never any delayed interrupts unless you push the board too hard, even then the steps are not missed but are out of time so may cause enough jerk that it is an issue.
Currently I would recommend keeping the steps/s below 400k, I keep mine below 80K as multistepping annoys me, high levels of microstepping are not worth it.
p3p
on 16 Jun 2019
I discovered the 32bits just now also. Time to learn more about my LPC1768, I can see.
@p3p Yes, I see what you are saying. Just began digging into this. Must be something else, then. Current steps/s is only 40k.
@gloomyandy Evidence? Only my ears right now.
The prints are ok, so it's not really a show stopper.
There is a "knocking" noise on X and on Y moves but not in the same places. Exercising single moves and gcode sequences (you know: back and forth repeatedly) over large and short distances does not show up any such symptoms (I tried really brutal stuff). But as soon as I print a more complex object, from SD or from octoprint, the knocking noises are discernable, mostly a while after a direction change but not every time (X or Y). Have not hooked up a scope or LA yet. What I can rule out (due to the movement tests) is knocking in the bearings anywhere or rattling somewhere. Single and repeated sequences are quiet and smooth.
Same gcode, same printer, same Marlin from PlatformIO but AVR 2560 8-Bit controller: Quiet, no knocking. That's the only thing I have right now to offer.
BigIronGuru
on 16 Jun 2019
@BigIronGuru This may be an odd suggestion but are you sure the noises you are getting are not from the extruder or perhaps related to extruder operation (retracts etc)? That will only be being used during prints obviously. Also do you have any bed levelling system active? I can't pin it down but I sometimes hear small bangs and linear moves are not as smooth as normal, I think it is because a linear move has been split into a series of smaller segments to allow for the different Z heights of the levelling grid and for some reason the moves do not run smoothly one into the other. Unfortunately it only seems to happen from time to time, usually only after I've printed a number of items without resetting the printer.
gloomyandy
on 16 Jun 2019
@gloomyandy
Not sure if I should stay on this thread - it's not a layer shift (but close, somehow).
Extruder disconnected. Yes, I am already that desperate.
I can't pin it down but I sometimes hear small bangs and linear moves are not as smooth as normal, I think it is because a linear move has been split into a series of smaller segments to allow for the different Z heights of the levelling grid and for some reason the moves do not run smoothly one into the other.
I will test unlevelled an air print 10cm high. Good idea.
for some reason the moves do not run smoothly one into the other. Yes. Now to find out what "some" reason is.
BigIronGuru
on 16 Jun 2019
As a side note here, a large number of Formbot Trex3 users have been reporting constant layer shift issues since launch. It shipped with a 2.0.x snapshot from Sept23rd. Published updates to turn on s curve acceleration and reduce motion settings went up to snapshots within the last 2mo. Issues persisted so I ported to pins file, thermistor table, mirror mode, and idex menus back to 1.1.9 with nearly identical config files (what existed in 1.1.9) and so far all users who have responded to that update (downgrade?) have reported the layer shifts have gone away. Its an Atmega2560 based idex 6 stepper machine. At this point im pretty confident something is up in the planner but havnt had time to hook up a logic analyzer long enough to find it.... Ill get there eventually... Day job has been to busy.
InsanityAutomation
on 16 Jun 2019
Folks
Please consider that after fixing the Hal for sym32f1 ( it is a walk around , as root cause is deep in the chip) we have 20+ happy marlin users using 1 month old marlin 2 code.
To find the issue I can propose to do the same as I did: print in debug mode a gcode having no discontinuities, like concentric circles . I made a huge washer like this 160mm diameter, 0.2mm thick. While printing that washer, you should never get all the stepper clock at 0 for a few ms. Plug a cheap logic analyser and try to identify what shocks are producing on your logic analyser..... my 0.02€...
hobiseven
on 16 Jun 2019
@hobiseven I agree and I'd love to have the time to dedicate to that approach. If somebody else doesn't beat me to it I may when the day job let's up a bit...
InsanityAutomation
on 17 Jun 2019
Forget my previous comment on shifts with lpc1768, my shifts on x axis were due to a loose pulley on the stepper. I'm feeling kind a stupid now.
DavidThijs
on 17 Jun 2019
I want to leave some positive feedback here.
I have a LPC1768 (Re-Arm) + RAMPS platform that has now 50hrs+ print time in the last 2 months without any major issues firmware wise. I try to flash the board with the latest commits at least once a week.
chrisqwertz
on 20 Jun 2019
Closing this thread since layer shifting is a symptom, not a specific bug. We'll continue to discuss layer-shifting on new bug reports that include that detail.
thinkyhead
on 21 Jun 2019
maybe unpin the issue also then?
boelle
on 22 Jun 2019
@boelle until gone I'd say keep it pinned for reference. Just because active discussion was intended to be moved doesn't mean we want it sliding away just yet.
InsanityAutomation
on 22 Jun 2019
i agree, but is there not a better and maybe open issue that we can pin instead? just a thought
i have seen many posts with the same issue, but never had the issue myself
boelle
on 22 Jun 2019
I've been fighting with layer shifts on both 1.1.9 and 2.0.x after upgrading from my Ender 3's default firmware. Default configuration except for enabling linear advance (which was my motivation for upgrading). They're always in the positive Y direction, roughly 1-3mm each. Stock hardware including board with A4988 steppers.
After digging through a lot of bug tracker entries, I came across this, which seems to work:
https://github.com/MarlinFirmware/Marlin/issues/12491#issuecomment-443464603
At first I was concerned that it only worked because the default JUNCTION_DEVIATION_MM of 0.02 was so small that it made printing really slow, but turning it up to 0.1 brought speed back up to roughly normal levels and did not bring back the layer shifts. So I suspect when junction deviation was added (or sometime after that) the "classic jerk" code was broken.
 richfelker
on 8 Aug 2019
richfelker
on 8 Aug 2019
At first I was concerned that it only worked because the default JUNCTION_DEVIATION_MM of 0.02 was so small that it made printing really slow, but turning it up to 0.1 brought speed back up to roughly normal levels and did not bring back the layer shifts. So I suspect when junction deviation was added (or sometime after that) the "classic jerk" code was broken.
This is a valuable clue!!! Thank You @richfelker !!!! One thing we could do is find a point in the branch history just before JUNCTION_DEVIATION was added... and see if that is immune to layer shifts. And the other thing we can do is look through all the JUNCTION_DEVIATION code with a fine tooth comb!
Roxy-3D
on 8 Aug 2019
It seems the underlying issue is known, but I'm not sure whether it's known that it causes such severe problems as layer shifts: https://github.com/MarlinFirmware/Marlin/issues/12540#issuecomment-442793326
richfelker
on 8 Aug 2019
@richfelker
What you say would imply a bug in marlin code , and therefore 32 bit cpus would have similar issues right? But we print just fine with stm32f1 and lpc1769.
Can you overclock your Avr ? In case of cpu speed limitations you would see an improvement.
hobiseven
on 8 Aug 2019
@hobiseven, see the linked comments on #12540. There's definitely a bug that causes wrong velocity changes under the conditions described; the mechanism of it is clearly explained. Whether that results in layer shifting (missed steps) may depend on other mechanical or software factors.
richfelker
on 8 Aug 2019
On the Trex3 IDEX machines, we did see layer shifts with classic jerk, in most cases within hours of starting a print with small jerky moves. We found enabling Junction deviation cut these down, but did not totally eliminate the problem. Enabling S curve as well got it down to 1 shift every 48 hrs or so. We had the same test print between Roxy, Tinymachines 3D, Formbot, and Myself for validation as well as distributed to some of the dozens of users is a group discussing the issue. In the end, the only resolution we had was to backport some of the advertised functionality and pin / thermistor definitions to the 1.1.x code base and the manufacturer is no longer shipping Marlin 2.0 on new machines. With the same configuration on 1.1.9 we have not seen any issues.
I have a logic analyzer sitting here and a spare board I plan to hook up for testing at some point. My belief is there is a race condition of some type. If this is caused by access to a 16 or 32 bit variable, it would explain why 8 bit avr is affected and the 32 bit platforms would likely not be as that would be a single instruction and no chance for interruption. I believe the above needs to be resolved, as classic jerk cannot be eliminated for the reasons described there, and that there is also a second issue somewhere.
What I can say with absolute certainty is that we have dozens of reports of users with layer shifts on the 2.0 code base with IDEX on 8 bit avr that was resolved by reverting to 1.1.x.
InsanityAutomation
on 8 Aug 2019
@InsanityAutomation, my layer shifts happened on both 1.1.9 and 2.0.x, so if yours go away or are reduced by reverting to 1.1.9, there's almost surely a different bug causing yours.
richfelker
on 8 Aug 2019
@InsanityAutomation, my layer shifts happened on both 1.1.9 and 2.0.x, so if yours go away or are reduced by reverting to 1.1.9, there's almost surely a different bug causing yours.
Yup, thats what leads me to a race condition where the specific combinations of timings make it appear, disappear, or change frequency. I have no doubt it still has something present way back then. With 1.1.9 we kept JD and SCurve on FWIW. The drastic change in frequency tells me we hit a second bug that may also be present on 1.1.9 just not showing itself with how things land currently.
InsanityAutomation
on 8 Aug 2019
@InsanityAutomation, the mechanism of the bug with classic jerk is described in https://github.com/MarlinFirmware/Marlin/issues/12540#issuecomment-442793326 and it's an error in the mathematical model, not a race condition. There may well be race conditions causing layer shifts under other conditions.
richfelker
on 8 Aug 2019
@InsanityAutomation, the mechanism of the bug with classic jerk is described in #12540 (comment) and it's an error in the mathematical model, not a race condition. There may well be race conditions causing layer shifts under other conditions.
Agreed, my intention was to state I believe the second bug is a race condition next to that.
InsanityAutomation
on 8 Aug 2019
I first noticed this a few prints after upgrading an Anet A8 board to 1.1.9.
I then tried everything with an MKS base 1.4 because of the lack of pots on the newer A8 board, and had the same issue with bugfix-2.0.x
Things I have tried:
CURA (known working config) & Slic3r (fresh config via wizard).
S_CURVE_ACCELERATION on/off
JUNCTION_DEVIATION on/off
Acceleration at 1000, 500 and jerk at 10, 5
Printing at 15mms, 30mm/s, 50mm/s, 60mm/s, 80mm/s (The slower speeds are generally worse)
Stealthchop on/off
Stepper driver pots all the way up, way down, and every 0.1v in between.
Blasting stepper drivers (at all voltages & with heat sinks) with fans
Testing and adjusting all the mechanics of the printer. It's smooth to the point where I can tap the x and y axes back and forth with a single finger tap in each direction. (Hiwin rails)
Belts tight and loose
3 different stepper models
Heated bed at 40/50/0
Printing via SD
Printing via repetier server, repetier host, and an MKS TFT32 (Everything else was checked without USB or the TFT32)
There are definitely plenty of other things I have tried so far that I am failing to recall. I will add them when I think of them.
What I am really struggling to work out is what antagonizing factor there could be that I haven't yet swapped out, which must exist or else everyone on 2.0.x would experience this. I think the only parts I haven't swapped out are the bed & heat block...
The issue snuck up on me while printing small basic models that didn't present with the issue, and as a result I have no idea what commit last worked (and playing whack-a-commit has not worked out).
As a result I am pretty desperate for a known safe commit (and, via that, a functioning printer) at this point.
Is there one?
 isycat
on 7 Sep 2019
isycat
on 7 Sep 2019
1.1.7 version is stable and works fine.
demson
on 7 Sep 2019
Going way back to 1.1.7 release made a big difference
isycat
on 9 Sep 2019
I'm using a v1.1.9 with my IDEX machine and it is stable.
This is the branch InsanityAutomation did.
https://github.com/InsanityAutomation/Marlin/tree/Trex3_1.1.9
Roxy-3D
on 9 Sep 2019
I'll try that as well, thanks.
(Diffing my old and new config has not brought up anything significant.)
isycat
on 10 Sep 2019
hi,
i have a layer shifting pb with mks sbase and marlin bugfix2.0, the same gcode with smoothieware , print well.
i put some picture and explanation in reprap forum https://reprap.org/forum/read.php?415,858787
do you think it's the same pb?
 Matou25
on 10 Sep 2019
Matou25
on 10 Sep 2019
This looks to be a different problem. The layer shift problem has very dramatic layer shifts. What you have posted looks more like acceleration is too high or speeds are too high, causing mechanical overshoot.
BigE2
on 10 Sep 2019
Most layer shift problems are mechanical in nature. The nozzle is being accelerated too fast or the nozzle catches when it moves over a curled edge. Some times it is a bearing or belt guide that binds a little bit and causes a shift. My guess is 80% or 90% of the layer shifts are mechanical in nature.
BUT... There is a layer shift problem in the v2.0.0 firmware.
Roxy-3D
on 10 Sep 2019
This looks to be a different problem. The layer shift problem has very dramatic layer shifts. What you have posted looks more like acceleration is too high or speeds are too high, causing mechanical overshoot.
thanks for your reply
i check acceleration parameter in marlin and smoothie and it's the same, gcode file is the same so speed is equal.
I try to print at 60% but it's the same result with marlin :-(
Matou25
on 12 Sep 2019
@Matou25 in the linked post you say your printer is a Kossel (delta). My understanding is that junction deviation does not work with deltas and you have to use the "classic jerk" which also does not work (has logic bugs that produce layer shifts). You might be able to get it to work, at the expense of really slow printing, by setting jerk to 0. I expect this will be painfully slow with any curves unless you have the feature (I forget its name) to recognize curves and convert them to arcs. It might also be possible to force junction deviation and just set a conservative value for it (to compensate for it working in cartesian space rather than motor coordinates).
Otherwise, you need to go back to a version before classic jerk was broken. It's known-broken back to 1.1.9. 1.1.7 might be good.
richfelker
on 12 Sep 2019
Most layer shift problems are mechanical in nature. The nozzle is being accelerated too fast or the nozzle catches when it moves over a curled edge. Some times it is a bearing or belt guide that binds a little bit and causes a shift. My guess is 80% or 90% of the layer shifts are mechanical in nature.
BUT... There is a layer shift problem in the v2.0.0 firmware.
thanks for your reply
i thinks it's not mechanics, because it's same gcode and i only change firmware.
Matou25
on 12 Sep 2019
@Matou25 in the linked post you say your printer is a Kossel (delta). My understanding is that junction deviation does not work with deltas and you have to use the "classic jerk" which also does not work (has logic bugs that produce layer shifts). You might be able to get it to work, at the expense of really slow printing, by setting jerk to 0. I expect this will be painfully slow with any curves unless you have the feature (I forget its name) to recognize curves and convert them to arcs. It might also be possible to force junction deviation and just set a conservative value for it (to compensate for it working in cartesian space rather than motor coordinates).
Otherwise, you need to go back to a version before classic jerk was broken. It's known-broken back to 1.1.9. 1.1.7 might be good.
thanks
you are right, Junction deviation is disable , jerh is at default 10
i think you talk about S-curve ? s-curve is disable i try to enable it but i receive a msg that it's not for delta when compiling
i will try to force junction deviation, do you have an idea how to do that ?
I have a 32bits board, it's possible to use 1.1.7 on it ? as i understand only marlin2.0 work with mks sbase 32bits board.
Matou25
on 12 Sep 2019
@Roxy-3D
You wrote : BUT... There is a layer shift problem in the v2.0.0 firmware.
Well, we have now a nice little community now using Marlin 2.0.0 on STM32F1, and we have no layer shift issues after fixing our HAL.
So there might be an issue on 2.0.0, but this is more platform related ( CPU speed / not fast enough, bug in the HAL), rather than in the Marlin code itself.... We have one issue remaining, where the head in middle of the print, goes on one side, and comes back then resume printing, but this does not affect the print. No more layer shifts.
hobiseven
on 12 Sep 2019
@Roxy-3D
You wrote : BUT... There is a layer shift problem in the v2.0.0 firmware.
Well, we have now a nice little community now using Marlin 2.0.0 on STM32F1, and we have no layer shift issues after fixing our HAL.
So there might be an issue on 2.0.0, but this is more platform related ( CPU speed / not fast enough, bug in the HAL), rather than in the Marlin code itself.... We have one issue remaining, where the head in middle of the print, goes on one side, and comes back then resume printing, but this does not affect the print. No more layer shifts.
I do firmly believe there are still shifts with certain configurations that exist. There are also still stepper shocks being recorded, though they may not always result in shifts.
InsanityAutomation
on 12 Sep 2019
The mechanism of the classic jerk bug is described in detail in https://github.com/MarlinFirmware/Marlin/issues/12540#issuecomment-442793326 which I linked above. It is an error in the mathematical model, not a problem with cpu speed or HAL stuff. I don't understand why some users seem to be unaffected; maybe something specific to the machine or other configuration prevents the buggy cases from being hit.
Also note that recent Cura has significantly lowered the default slicing resolution, preventing lots of tiny segments from being emitted but potentially (seems to be yes from my experience but I haven't 100% pinned this on Cura) causing tolerance errors in designs requiring high precision. It seems plausible that Cura users with the new low-resolution defaults might not be hitting certain jerk-related bugs in Marlin. I reverted to the high-resolution settings and never tested whether using the low-resolution ones works around the classic jerk problem. Either way, the high-res gcode is valid and Marlin should not break on it.
richfelker
on 12 Sep 2019
I would like to encourage people having layer shift issues with v2.0.0 to pull down the new code with this patch in it. I think it is very possible this Pull Request is going to fix the firmware based layer shifts some of us have been seeing.
Roxy-3D
on 20 Sep 2019
@Roxy-3D: Thanks. Am I correct that it shouldn't have any relation with the classic-jerk layer shifts? Or is it related to them too?
richfelker
on 20 Sep 2019
@Roxy-3D: Thanks. Am I correct that it shouldn't have any relation with the classic-jerk layer shifts? Or is it related to them too?
Right now I'll say test everything as it may have impact on every scenario. It was not explicitly related to jerk however it's an underlying function jerk may have used differently.
InsanityAutomation
on 20 Sep 2019
The timing of the step pulses relative to the direction change signal affects all scenarios. It is conceivable that the problem showed up for some people on quick back and forth movements of the extruder. It is possible that it showed up for other people after long fast moves across the bed for other users.
The bottom line is, the timing was too tight from a 'Setup & Hold' perspective in all of those scenarios. Probably there are other things entering the equation. Changing directions fast will cause a huge surge current on the power supply and it is possible the power supply voltage dropped .1 volt when that happened. That would affect the set up and hold time margin.
There are too many variables. The bottom line is the Setup & Hold times were not being met. So this Pull Request fixes that. Now the question is.... How many people with layer shift problems does this help? We don't know that answer. But we are eager to hear replies.
Roxy-3D
on 20 Sep 2019
I've got the SBase (DRV8825 drivers) working in CoreXY mode with parameters:
#define DIGIPOT_I2C_MOTOR_CURRENTS { 1.8, 1.8, 1.8, 0.9, 0.9 }
#define MINIMUM_STEPPER_POST_DIR_DELAY 750
#define MINIMUM_STEPPER_PRE_DIR_DELAY 750
#define MINIMUM_STEPPER_PULSE 5
I tried the latest build as of yesterday, and had MAJOR layer shifting. Only circles (chess piece with round bottom was really perfect, but then it started on sharp corners, and everything failed majorly.
Also a test piece just having sharp corners (150 x 10 rectangular bar for measure checks), is failing directly, while the circular movements are perfect.
This must be because of the sharp corners, i'm now compiling 2.x with JUNCTION_DEVIATION_MM set to 0.04 since the later iterations of Marlin 2.x have some good features like the SD-card not auto-loading on SKR1.3 and such, which is fixed in later iterations. I'll update this comment when I have done a test print, including pictures.
// EDIT //
Nevermind, I can't get the layer shifting to stop. I will have to go back to about 8/29 to make it work again without shifting.
// EDIT 2 //
Just cloned commit 38983fdfa9773faf7006ef392110aca01ad006d5 from 29 August 2019 at 08:19:07 CEST and it's running perfectly fine, sharp en straight print, exactly the same gcode. So from that point I cannot upgrade Marling anymore because it failed all my prints completely.
// EDIT 3 //
Images:
BEFORE EDIT 2

AFTER EDIT 2

 xoniq
on 22 Sep 2019
xoniq
on 22 Sep 2019
I would like to encourage people having layer shift issues with v2.0.0 to pull down the new code with this patch in it. I think it is very possible this Pull Request is going to fix the firmware based layer shifts some of us have been seeing.
15314
HI,
i test today and it's worse than before, see picture below.
it's always the same gcode file
i try to reduce speed for last attempt but it's even worse.

Matou25
on 28 Sep 2019
It sounds like the culprit for current issues arrives at soon after 29 August 2019 at 08:19:07 CEST. We should narrow this down as close as possible to a single commit. I will look at that period of time and see if any changes stand out.
thinkyhead
on 30 Sep 2019
[Classic Jerk is] known-broken back to 1.1.9.
I don't know about that. But you may need to cut your Jerk values by 50% if you are coming from an earlier version of Marlin.
thinkyhead
on 30 Sep 2019
A lot of reports here are not mentioning what type of stepper drivers you've got. This is an important detail to mention, because the TMCStepper library also gets periodic updates. In future reports, please state whether you are using TMC drivers so we know to look at changes in the TMCStepper library. For example, recently there was a bug in the TMC2208Stepper component where the PWM on the TMC2208 was being incorrectly set.
thinkyhead
on 30 Sep 2019
Well, we have now a nice little community now using Marlin 2.0.0 on STM32F1, and we have no layer shift issues after fixing our HAL.
HALleluia?!
When there are SPI or Serial issues, that can surely affect trinamic drivers. And where there are Timer or other HAL issues, that can definitely affect stepping.
thinkyhead
on 30 Sep 2019
[Classic Jerk is] known-broken back to 1.1.9.
I don't know about that. But you may need to cut your Jerk values by 50% if you are coming from an earlier version of Marlin.
Again, see https://github.com/MarlinFirmware/Marlin/issues/12540#issuecomment-442793326 where the bug is described in detail and attributed to wrong logic/math.
richfelker
on 30 Sep 2019
I haven't tested the latest version yet but I have an input that i think might help narrowing things to look at.
I have tested same firmware version on same printer, same firmware settings, same Ramps 1.6, same gcode by just changing arduino mega to Re-arm. Result is that I only get layer shifts on re-arm.
I hope this would help.
Regards
omercanvural
on 30 Sep 2019
A lot of reports here are not mentioning what type of stepper drivers you've got. This is an important detail to mention, because the TMCStepper library also gets periodic updates. In future reports, please state whether you are using TMC drivers so we know to look at changes in the TMCStepper library. For example, recently there was a bug in the TMC2208Stepper component where the PWM on the TMC2208 was being incorrectly set.
HI,
i use mks sbase board with OnBoard DRV8825 tweak fast decay, i buy external board with TMC2130 but i don't test it for now.
My printer is a delta mini Kossel.
I don't know if it's related and/or if it can help, but during printing i can't use LCD full Graphic and encoder sometime work but after 2-3 minutes for 1 action
regards
Matou25
on 30 Sep 2019
Not every bad looking cube is caused by layer shifts.
https://github.com/MarlinFirmware/Marlin/issues/12540#issuecomment-442793326 describes a problem with a not ideal speed profile. But i don't see any reason to cause layer shifts, as long jerk, acc and speeds are set to correct values. In no parts of the graphs (above of that) the set values are exceeded. If any layer shift is caused by this effect, at least one of jerk or acc is set to high.
Better let's discuss how to find correct settings. That is not an easy task.
Finding the right jerk can't be done by simply moving back and forth with increasing jerk values until you see a fault. The lost steps during "acceleration" are, theoretically, got back during the negative "acceleration", when jerk has the same amount. It needs a staggered breaking, a slow return, multiple repetitions and verification at an hardware endstop.
AnHardt
on 30 Sep 2019
A note about short segments:
Let's assume a move along one axis, 100 steps long. With jerk 20steps/s this should start at 20steps/s, then accelerate to its commanded speed, travel with the commanded speed, brake again to 20steps/s and stop.
____
/ \
/ \
/ \
| |
|1234567890|
To simplify lets assume the commanded speed is much to high to reach it during the acceleration phase. We will have a change from accelerating to breaking in the middle of the move. Let's assume with the given acceleration we'd reach 70 steps/s.
/\
/ \
/ \
/ \
/ \
| |
|1234567890|
Now let's divide this single move into 10 moves, each 10 steps long. When jerk_speed is defined as "The maximum difference in speed between end of one move and start of the next" - we get
/\
| |
| |
/ \
| |
| |
/ \
| |
| |
/ \
| |
| |
/ \
| |
|1234567890|
a top speed of 150. If we further shrink the segments it's going worse. The time to calm down after the jerk gets shorter and shorter. The average acceleration goes to jerk_speed/step.
That can't work.
Do we have to define jerk-speed to be only applikable when starting from zero (stopping to zero) and changing direction (with half the value)?
AnHardt
on 30 Sep 2019
@AnHardt: See this text from the linked comment:
Interestingly, if the change in velocity is negative instead of positive, the drop in velocity doesn't happen (also seen in the graphs above - only increases in velocity results in a velocity limit).
At least that suggests to me that very wrong motion may happen in some cases.
Regarding your comments about very small segments, I share your concern there and have always been confused about how it was supposed to work. Presumably jerk should take into effect the current velocity relative to the nominal/max velocity for the segment ending (e.g. as a % of max) and enforce the limit in instantaneous change relative to the same % of the nominal/max velocity for the next segment, so that the absolute velocity fully follows the acceleration profile, but I suspect that's not how it works.
richfelker
on 30 Sep 2019
Without doubt the velocity graphs show unexpected behavior. Nerveless in relation to acc and jerk everything we see is "legal". No vertical line is longer than the configured jerk and none of the diagonal lines is steeper than the configured acceleration.
AnHardt
on 30 Sep 2019
I read the above as saying that the second move is performed at the wrong speed, i.e. never slowing down from the nominal speed of the previous move to the nominal speed of the next move. That's already sufficiently "wrong motion" to be concerned I think, even if it's not the direct/immediate cause of the layer shifting.
richfelker
on 1 Oct 2019
+1 with shifting layers on SKR 1.3 / TMC2208 (legacy) on Marlin 2.0...
I'm now putting my MKS Gen L v1 back as the drivers were working flawlessly on this board with previous Marlin.
 rnelias
on 2 Oct 2019
rnelias
on 2 Oct 2019
+1 with layer shifts on an SKR MINI v1.1 / TMC2208_STANDALONE with Marlin 2.0.x
I can do tests if required. Just let me know what to do....
 Lord-Quake
on 3 Oct 2019
Lord-Quake
on 3 Oct 2019
SKR Mini V1.1 has an STM32F103 in a small package. I wonder if you face the same IT bug as the one we have in the genuine STM32F103VE used on Longer boards. We had to change a small thing in the hal, as there is apparently a race condition in the interrupt controler, resulting in some interrupt being ignored / 1ppm. I would recommend to try this simple modification in the HAL.
hobiseven
on 3 Oct 2019
I'm afraid to ask. What does HAL mean?
Lord-Quake
on 3 Oct 2019
Ahhh. OK, Hardware abstraction layer. It is the piece of software that hides the processor specific implementation and makes all processor looking identical to the actual Marlin code.
hobiseven
on 3 Oct 2019
Thank you. Could you point me to the changes that I should try to make?
Lord-Quake
on 3 Oct 2019
In that file :
https://github.com/hobiseven/Marlin_2.0.X_Beta_Alfawise_Ux0/blob/master/Marlin/src/HAL/HAL_STM32F1/HAL_timers_STM32F1.cpp
switch (timer_num) {
case STEP_TIMER_NUM:
timer_pause(STEP_TIMER_DEV);
timer_set_mode(STEP_TIMER_DEV, STEP_TIMER_CHAN, TIMER_OUTPUT_COMPARE); // counter
timer_set_count(STEP_TIMER_DEV, 0);
timer_set_prescaler(STEP_TIMER_DEV, (uint16_t)(STEPPER_TIMER_PRESCALE - 1));
timer_set_reload(STEP_TIMER_DEV, 0xFFFF);
timer_oc_set_mode(STEP_TIMER_DEV, STEP_TIMER_CHAN, TIMER_OC_MODE_FROZEN, TIMER_OC_NO_PRELOAD); // no output pin change
timer_set_compare(STEP_TIMER_DEV, STEP_TIMER_CHAN, MIN(hal_timer_t(HAL_TIMER_TYPE_MAX), (STEPPER_TIMER_RATE / frequency)));
timer_no_ARR_preload_ARPE(STEP_TIMER_DEV); // Need to be sure no preload on ARR register
timer_attach_interrupt(STEP_TIMER_DEV, STEP_TIMER_CHAN, stepTC_Handler);
nvic_irq_set_priority(irq_num, STEP_TIMER_IRQ_PRIO);
timer_generate_update(STEP_TIMER_DEV);
timer_resume(STEP_TIMER_DEV);
break;
case TEMP_TIMER_NUM:
timer_pause(TEMP_TIMER_DEV);
timer_set_mode(TEMP_TIMER_DEV, TEMP_TIMER_CHAN, TIMER_OUTPUT_COMPARE);
timer_set_count(TEMP_TIMER_DEV, 0);
timer_set_prescaler(TEMP_TIMER_DEV, (uint16_t)(TEMP_TIMER_PRESCALE - 1));
timer_set_reload(TEMP_TIMER_DEV, 0xFFFF);
timer_set_compare(TEMP_TIMER_DEV, TEMP_TIMER_CHAN, MIN(hal_timer_t(HAL_TIMER_TYPE_MAX), ((F_CPU / TEMP_TIMER_PRESCALE) / frequency)));
timer_attach_interrupt(TEMP_TIMER_DEV, TEMP_TIMER_CHAN, tempTC_Handler);
nvic_irq_set_priority(irq_num, TEMP_TIMER_IRQ_PRIO);
timer_generate_update(TEMP_TIMER_DEV);
timer_resume(TEMP_TIMER_DEV);
break;
}
and in that file :
https://github.com/hobiseven/Marlin_2.0.X_Beta_Alfawise_Ux0/blob/master/Marlin/src/module/stepper.cpp
all is around the definition of HAL_timer_set_compare > We had to change that.
hobiseven
on 3 Oct 2019
Thanks again. I little over my head but I will look at it.
Lord-Quake
on 3 Oct 2019
Well, I will have to retract my comment.
After looking at everything I was able to determine that the layer shifting was caused by too low of vref settings. I've thoroughly tested everything and haven't had any shifts since I updated vref.
I also went back to standard printer settings for DEFAULT_AXIS_STEPS_PER_UNIT and then recalibrated the printer. With 1.1.9 I used two digits after comma e.g. 100.68. I have now set the values to only one digit after the comma e.g. 100.6.
Question: Are two digits also valid here or could this cause an issue with calculations?
Lord-Quake
on 5 Oct 2019
hi,
i test reduce jerk, acceleration but same pb.
So i decide to mount my news tmc2130 with external board
Now wall are straight no more layer shift. so my issue is more related to marlin's DRV8825 management.
thanks for your help and informations
Matou25
on 6 Oct 2019
Marlin will now use Junction Deviation by default unless this is overridden. That should help those with issues related to bad jerk calculations (if that is indeed a real problem).
thinkyhead
on 9 Oct 2019
Are two digits also valid here or could this cause an issue with calculations?
That should be fine.
thinkyhead
on 9 Oct 2019
After increasing to 5us it seems to print better. But today I have my display locked since 2nd layer!
Printed about 20mm then filament runout sensor unblock display for pause menu. ( buffer = 64 )
After resuming dispplay has locked again.
 karabas2011
on 9 Oct 2019
karabas2011
on 9 Oct 2019
@karabas2011
What value are you increasing to 5µs?
How is the display problem related to layer shifts?
AnHardt
on 9 Oct 2019
For what it's worth, I have input wheel and display glitches too; perhaps both these and layer shifts are related to insufficient cpu time and missed interrupts. (In particular, display often gets corrupted, especially on numeric input widgets, when spinning the input wheel fast, and some input events get lost or processed twice in menus).
richfelker
on 9 Oct 2019
@karabas2011
What value are you increasing to 5µs?
Step pulse for DRV8825
How is the display problem related to layer shifts?
It seems that both problems are linked.
The only thing I changed yesterday wat step pulse. Before I was able to navigate via menu during printing (after setting buffer 64) but with big layer shifting. Now shift significally reduced but suddenly display locked. I am continue experimenting.
karabas2011
on 9 Oct 2019
do we still have issues? or has it turned in to misunderstandings on how to do config? it's almost a year since @Roxy-3D opened this one
boelle
on 24 Oct 2019
No layer shifts seen anymore since I tensioned the pulleys. I'm running a mks gen L with tmc2130 in spi and one of the more recent builds of Bf2. 0
DavidThijs
on 24 Oct 2019
and i never seen any issues, using TMC2100 and DRV8825 for extruder
boelle
on 24 Oct 2019
I'm having issues with shifting. But tonight I backed up my firmware of Marlin, and tested with Klipper, and also here, layer shifting, in the first test print.
Mechanically it's not possible, motor pulleys are glued on, and round, new belts, no bad pulleys. In my Klipper test, it went wrong right away in a square test. With Marlin, I tried the same chess piece over and over, and it failed always on top, or on the moment it has to do spiral parts.
Since it's not mechanically possible, it might be the motors itself, I'm running the TMC2130 drivers with a current of 800 to 850, but I will crank these up to 950 or more, I gave motors which are capable of running more power, and these don't even get warm to touch.
Tomorrow I will test with a brand new commit of Marlin, with upped motor current, and then I will see what it does. It if keeps shifting, maybe I'll buy 2209 drivers.
xoniq
on 25 Oct 2019
do we still have issues? or has it turned in to misunderstandings on how to do config? it's almost a year since @Roxy-3D opened this one
Most layer shifts are mechanical in nature. These can be caused by trying to accelerate (or Jerk) the stepper motors too hard. Or it can be caused by loose belts or curled edges catching the nozzle on a printed part.
But some of the layer shifts appear to be caused by something in the Planner::. And in fact, that is part of the motivation for switching to the Junction Deviation model from Classic Jerk model.
We need to keep looking for the root cause of the problem.
Roxy-3D
on 2 Nov 2019
I'm having issues with shifting. But tonight I backed up my firmware of Marlin, and tested with Klipper, and also here, layer shifting, in the first test print.
Mechanically it's not possible, motor pulleys are glued on, and round, new belts, no bad pulleys. In my Klipper test, it went wrong right away in a square test. With Marlin, I tried the same chess piece over and over, and it failed always on top, or on the moment it has to do spiral parts.
Since it's not mechanically possible, it might be the motors itself, I'm running the TMC2130 drivers with a current of 800 to 850, but I will crank these up to 950 or more, I gave motors which are capable of running more power, and these don't even get warm to touch.
Tomorrow I will test with a brand new commit of Marlin, with upped motor current, and then I will see what it does. It if keeps shifting, maybe I'll buy 2209 drivers.
How did this go for you? Today layer shifting started happening again for me after updating to latest code and am wondering if upping the current has any positive effect on this.
 hapklaar
on 22 Nov 2019
hapklaar
on 22 Nov 2019
We have been going through the same type of issues and we also varied the stepper current. This is helping the steppers to continue to operate when you have an irregular train of steps. In our case, there was a 13ms gap in pulses and upping the current allowed the stepper to have enough instantaneous torque to overcome the step irregularity . This is a band aid, not a real fix.
In the end we realized that any time we had an irregularity in the pulses train, even if there was no layer shift , we could feel it in our hands while the head/ bed were moving. And we used a logic analyser to Find the root cause by placing probes on step clk as well as some spare io pins on the chip, that were controlled by io writes...
hobiseven
on 23 Nov 2019
@hobiseven Interesting... Do you have a theory as to what is causing these gaps in pulses and what can be done to 'fix' this?
hapklaar
on 23 Nov 2019
@hapklaar
Our issue was in the way the counters are used within the HAL for the stepper counters/timers reload. One interrupt was skipped, and the 16 bits counters had to make a full roll over to get the interrupt issued. This is specific to STM32F103V, and we slightly modified the code in the HAL to get this problem really resolved. This is now the current marlin repo.
The root cause for other chips might be different, but right now, we happily print. Code is spread WW for alfawise U30/U20, and it simply works fine.
TO really detect issues, we did made a simple 1 layer thick washer, large diameter, 180mm. We were able to get 30 "glitches" in the clocks for every part. We could feel the irregularity by simply putting our hands on the printer frame.
To start real deep investigations, you need to connect a logic analyzer on the stepper driver clock pins, and detect irregularity conditions.
In our case, once you start printing a 1 layer washer, the conditions was that the clocks should never stop for more than 5ms. Using such a trigger, we were able to precisely narrow down the piece of code generating troubles.
This may not apply to your case, but if you feel that there is a small shock in your printer frame when the layershift occurs, you may want to give a try to this.
Once you have identified the reall issue and get the right trigger with the logic analyser, then it is just a matter of putting additional outwrite on spare IOs in you code to see what happens.
We also had the possibility to dump in real time full register contents on IO pins, to see on the logic analyser the timer/ounter values. On our setup, we pushed the values to the LCD interface, as it is 16 bit wide.
On your setup, you will need to be using pins you have to do that. ...
hobiseven
on 23 Nov 2019
@hobiseven, I have been looking into the same thing, and never saw your comments on this issue (I was looking into it due to two different issues!).
Are you attempting to solve the issue at all, or just gathering information right now? I've posted a draft PR with one possible solution, if you are interested in trying it out. #16128. At this point I consider it an idea worth considering, but perhaps someone will suggest a better alternative.
 sjasonsmith
on 6 Dec 2019
sjasonsmith
on 6 Dec 2019
@sjasonsmith
I made extensive comments earlier about the STM32F1 issue we had, due to some very deep bug in the IT controller. Using the counters in a slightly different way ( ie, the "normal" way) solved the problem, and tpruvot made a PR, that is now included in the main branch.
I am just indicating to people that try to identify where the motor shocks , or layer shift are coming from, that they need an LA to successfully hunt those issues.
As of today, we experience NO layer shifts at all on STM32F1.
hobiseven
on 6 Dec 2019
@hobiseven Thanks for the quick reply! It looks like that was unrelated to what I have been investigating. I've been looking into issues with incorrect pulse durations, rather than missing interrupts like it appears you ran into. I've been reproducing issues on LPC1768 controllers. I presume STM controllers could be impacted as well, but it won't impact every configuration of hardware/software.
sjasonsmith
on 6 Dec 2019
stupid Q while trying to dust off the list
since this is now past a year ago have we figured out what is going wrong? ie can we draw any conclusions?
boelle
on 7 Dec 2019
PR #16128 has been merged into bugfix-2.0.x. This definitely fixed timing issues impacting 8825 drivers on 32-bit controllers, but probably fixes sporadic issues elsewhere as well.
It would be great for people to test the latest bugfix-2.0.x to see if issues remain. I recommend you remove any custom MINIMUM_STEPPER_PULSE or MAXIMUM_STEPPER_RATE to be sure you are testing the fix, and not working around issues in other ways.
sjasonsmith
on 20 Dec 2019
I just hit a layer shift again despite using junction deviation. Ender 3 (A4988's). Printing gears with lots of small motion-direction reversals. Is there a possibility PR #16128 might fix this? If so I'll pull master and give it a try.
richfelker
on 24 Dec 2019
I just hit a layer shift again despite using junction deviation. Ender 3 (A4988's). Printing gears with lots of small motion-direction reversals. Is there a possibility PR #16128 might fix this? If so I'll pull master and give it a try.
Was it a large layer shift? That PR is most likely to fix small random shifts, which would be seen more as surface roughness than a big shift. I would not expect it to fix issues on most 4988 AVR setups (such as a stock Ender 3), but it would be hard to know for sure without trying it.
sjasonsmith
on 24 Dec 2019
Nope, didn't help - just tried it and hit the exact same layer shift again. :-(
richfelker
on 24 Dec 2019
when the vref is to low it can result in layer shifting worth checking.
 Vertabreak
on 24 Dec 2019
Vertabreak
on 24 Dec 2019
One theory/question: does junction deviation use/honor per-axis (M201) acceleration limits in its computations, or does it ignore them and just use the M204 acceleration setting? Cura is emitting some ridiculously high (5000 mm/s²) travel acceleration settings that would be essentially ignored if M201 is honored. I was able to make the (otherwise repeatable) layer shift go away by dropping junction deviation from 0.08 to 0.05. I'll see if eliminating those M204 S5000s also makes it go away.
(Note: 0.08 is based on the formula for converting from classic jerk with jerk value of 25 that worked with stock Marlin 1.0 based firmware, and significantly lowering it makes prints a lot slower.)
richfelker
on 24 Dec 2019
I've re-run the print that failed twice in the exact same place with the M204 S5000 lines removed, and it got past the point without a layer shift. Reading the source in planner.cpp around lines 2200-2300, I don't see any way per-axis acceleration limits come into play, so I suspect my theory was correct that junction deviation is allowing extreme jerk based on a M204 acceleration setting that wouldn't be honored for pure acceleration purposes (due to the axis acceleration limits being the limiting constraint).
I'll follow up if I have any more problems with this changed, or if limiting that seems to fix it.
richfelker
on 24 Dec 2019
A separate thought regarding classic jerk: is it possible that there's a bad interaction between linear advanced and setting jerk dynamically with the M205 X.. Y.. command that could lead to layer shifts? I noticed that Cura has emitted that in my files. I have not been back to test with classic jerk for a while, but https://github.com/MarlinFirmware/Marlin/issues/15473 has me concerned that junction deviation is also broken...
richfelker
on 31 Dec 2019
Following up on the above, getting rid of M205 S5000 did not make layer shifts go away entirely; I hit another one on a different print today. I suspect my JD value of 0.08 might just be too high so I've lowred it to 0.05 again.
One thing I really dislike about junction deviation is that the right value for JD seems to be dependent on acceleration; it seems you would want higher values with low acceleration to mitigate the slowness of accelerating/decelerating from/to a near-stop, whereas with high acceleration you need low values to prevent extreme vibration. AIUI classic jerk was invariant with respect to acceleration.
richfelker
on 31 Dec 2019
OK, this is rather embarrassing but I think I should post it in case it's helpful to others with the same problem. I'm pretty sure all of my layer shift problems in this thread were ultimately exceeding the physical capabilities of the printer.
Due to multiple layers of bad behavior in Cura (particularly how it evaluates configuration files when invoked from command line), it's always been putting M205 X30 Y30 commands in my gcode for travel moves, and 30 is rather high jerk. Apparently the original firmware (either due to Creality's modifications, or just because that's how Marlin was back when they forked it?) did not honor these, either capping the jerk lower or ignoring it entirely, so they didn't break anything, but Marlin 1.9 and 2.0 are attempting to honor it, with bad results.
My JD value of 0.08 was based on the formula for choosing a value comparable to classic jerk, with jerk of 25, which is what I thought I'd been using but which doesn't seem to have been being honored either. Jerk of 20 yields JD=0.05 which seems to have worked.
Since confirming that I'm affected by #15473, even with low K, I've switched back to classic jerk with XY limits of 10 mm/s and have not seen any layer shifting problems. I can probably take it up higher, maybe to 20, and will experiment with that later.
TL;DR: If hitting this problem, check that new Marlin isn't honoring bogus jerk values in your gcode that old Marlin was limiting or ignoring.
richfelker
on 2 Jan 2020
I have been doing a lot of testing on this lately, and have come up with a theory. If I go with a ridiculously small JD value (0.005) I can get things to print with no layer shift - but produces poor results very slowly.
When we implemented junction deviation @hoffbaked added the special case arc velocity for small segments:
if (block->millimeters < 1) {
// Fast acos approximation, minus the error bar to be safe
const float junction_theta = (RADIANS(-40) * sq(junction_cos_theta) - RADIANS(50)) * junction_cos_theta + RADIANS(90) - 0.18f;
// If angle is greater than 135 degrees (octagon), find speed for approximate arc
if (junction_theta > RADIANS(135)) {
const float limit_sqr = block->millimeters / (RADIANS(180) - junction_theta) * junction_acceleration;
NOMORE(vmax_junction_sqr, limit_sqr);
}
}
Two 136 degree segments straight after one another produce a 272 (i.e. 88 degree) degree turn, but they are only limited by the arc velocity of a 2 * single 136 degree turns.
I think we need to extend the original to accumulate an arc vector something like this psuedo code:
if (block->millimeters < 1) {
//Add current vector to arc vector
}
else {
//clear arc vector
}
}
Then we can calculate either the junction deviation on on the arc (unit?) vector, or the actual arc velocity as per the current arc case. Each successive segment through an arc will get a slower max junction speed, which should produce the desired results.
I have also been thinking about how we work out what we should consider to be an arc segments instead of the arbitrary 1mm. I'm thinking about perhaps a segment which is too short to speed up from 0 to nominal speed and back to 0 within the machines acceleration constraints - but I am not convinced that this would provide us any more benefits than the above? perhaps allow a user to tune what is considered an arc segment.?
Thoughts? @thinkyhead @Sebastianv650 @hoffbaked? @ejtagle
 Squid116
on 9 Jan 2020
Squid116
on 9 Jan 2020
A brief look into my insanity here: https://github.com/Squid116/Marlin/blob/SKR/Marlin/src/module/planner.cpp#L2243
It is very rough - I'll do a bit of a tidy up over the weekend, I am running a test print now and it hasn't behaved weirdly or broken anything yet (25:00 in). This print (baby yoda) will typically induce a shift in the first 90 mins, so I'll know soon if it has helped.
Squid116
on 10 Jan 2020
Link to commit/diff here: https://github.com/Squid116/Marlin/commit/fc1e96d31fa1e6b0cfdfef4b12c871abaa6d5161
richfelker
on 10 Jan 2020
I wonder if this will affect the behavior of Linear Advance when printing curves, where it appears like Linear Advance isn't detecting that when printing a curve the velocity is constant but it seems to be trying to adjust LA for every segment instead of maintaining a constant extrusion velocity throughout the curve.
ManuelMcLure
on 10 Jan 2020
So test finished (well cancelled). There were two shfts - both much smaller than previously seen, but there none the less.
I definitely think the issue is that arcs (as oposed to true corners) are allowing the print to exceed the machine limits.
I have a few ideas on how I can tune what I have got, but maybe a different approach is needed?
- Increase the minimum arc segment from 1mm?
- Decrease it?
- Maybe end the arc accumulation if the actual junction deviation is less than the arc deviation (i.e. a real corner was observed inside an arc)
- dont use the arc calculation if the arc vector hasn't sufficently varied from the first vector in the arc calculation - this would be computationally expensive and I'm not sure it would work.
- If an arc calculation is used, then use the arc vector as prev_unit_vec
Squid116
on 11 Jan 2020
It seems like the idea of accumulating corners on small sections, and then calculating the deviation on that angle might work. On a small wavy line, it would have to reset when it curves the other way, or it could cancel out and read as a straightaway erroneously. And it doesn't make sense to accumulate over a long distance on say a really long arc of short segments. I'm not sure if just resetting periodically on accumulated length would give a good enough result. I don't have time at the moment, but I'll think it through more tomorrow.
On Jan 9, 2020, at 5:18 PM, Chris Rigter notifications@github.com wrote:
I have been doing a lot of testing on this lately, and have come up with a theory. If I go with a ridiculously small JD value (0.005) I can get things to print with no layer shift - but produces poor results very slowly.
When we implemented junction deviation @hoffbaked https://github.com/hoffbaked added the special case arc velocity for small segments:
if (block->millimeters < 1) { // Fast acos approximation, minus the error bar to be safe const float junction_theta = (RADIANS(-40) * sq(junction_cos_theta) - RADIANS(50)) * junction_cos_theta + RADIANS(90) - 0.18f; // If angle is greater than 135 degrees (octagon), find speed for approximate arc if (junction_theta > RADIANS(135)) { const float limit_sqr = block->millimeters / (RADIANS(180) - junction_theta) * junction_acceleration; NOMORE(vmax_junction_sqr, limit_sqr); } }Two 136 degree segments straight after one another produce a 272 (i.e. 88 degree) degree turn, but they are only limited by the arc velocity of a 2 * single 136 degree turns.
I think we need to extend the original to accumulate an arc vector something like this psuedo code:
if (block->millimeters < 1) { //Add current vector to arc vector } else { //clear arc vector } }Then we can calculate either the junction deviation on on the arc (unit?) vector, or the actual arc velocity as per the current arc case. Each successive segment through an arc will get a slower max junction speed, which should produce the desired results.
I have also been thinking about how we work out what we should consider to be an arc segments instead of the arbitrary 1mm. I'm thinking about perhaps a segment which is too short to speed up from 0 to nominal speed and back to 0 within the machines acceleration constraints - but I am not convinced that this would provide us any more benefits than the above? perhaps allow a user to tune what is considered an arc segment.?
Thoughts? @thinkyhead https://github.com/thinkyhead @Sebastianv650 https://github.com/Sebastianv650 @hoffbaked https://github.com/hoffbaked? @ejtagle https://github.com/ejtagle
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub https://github.com/MarlinFirmware/Marlin/issues/12403?email_source=notifications&email_token=AECMILMNCVCTLWT7PIBSV7LQ46PCHA5CNFSM4GDDKJTKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEIR7QEA#issuecomment-572782608, or unsubscribe https://github.com/notifications/unsubscribe-auth/AECMILO7ZK4JCJ4LINZ5NXDQ46PCHANCNFSM4GDDKJTA.
 hoffbaked
on 11 Jan 2020
hoffbaked
on 11 Jan 2020
My test last night confirmed that using an arc vector does improve results - it is just about honing in on what constitutes an arc.
My maths isn't good enough to know if there is an easy way to work this out, and my google-fu hasn't turned up anything.
I was thinking of checking the arc vector against the first segment of the arc if the angle between them reduces then the arc is over? It would be a load more calculations (essentially doing the JD calculations three times) but I feel it might be worth it?
Squid116
on 11 Jan 2020
I’m happy to see that a possible cause has been identified for this issue, as I have been running into this issue as of recently as well.
Random small layershifts, for which there are no reasons to assume a mechanical cause. This is happening on dozens of machines with people using different slicers, printspeeds, etc for me. What is most curious is that only some models seem to suffer from it, while others print just fine. In our case for instance a Benchy will trigger the shifts, but a calibration cube works fine.
Some examples:



Whereas something like this is no issue:

If it helps, in our case the issue only started with the Marlin 2 stable and the state of 2.0.x-dev shortly before then! Before then I used the Marlin 2.0.x-dev from earlier in December and also before that time, which did not manifest this issue (yet).
Later today I will be looking into trying to pin down the moment it started appearing.
 DrywFiltiarn
on 11 Jan 2020
DrywFiltiarn
on 11 Jan 2020
My test last night confirmed that using an arc vector does improve results - it is just about honing in on what constitutes an arc.
My maths isn't good enough to know if there is an easy way to work this out, and my google-fu hasn't turned up anything.
I was thinking of checking the arc vector against the first segment of the arc if the angle between them reduces then the arc is over? It would be a load more calculations (essentially doing the JD calculations three times) but I feel it might be worth it?
Maybe I’m thinking to simple, but couldn’t it be resolved by simply looking at the angles? Any arcing that is within N degrees of deviation is one case, and anything beyond that is another case? In my experience it specific angles and radius that triggers it, where other cases will work just fine, also seeing my photo’s in previous reply.
I feel that on Benchy the rounded yet sharp front of the bow as well the rounded, yet sharp corners of Benchy seem to be triggering the shifts occasionally (as a reference for out experience with shifting on Benchy, it was most common to happen in the area where the hull was printed, it was less common above that), also on the door model the rounded sharp corners of the stones seem to be the trigger to layer shifting. On the other model which I created to see if I could find a reason for the shifting, with the larger diameter arcs the issue does not occur.
So summarized it seems to be a relation between angle of change vs distance traveled, that results in the issue. Shorter, sharper angles means shifting, shallower longer direction changes cause no issues.
DrywFiltiarn
on 11 Jan 2020
Maybe I’m thinking to simple, but couldn’t it be resolved by simply looking at the angles? Any arcing that is within N degrees of deviation is one case, and anything beyond that is another case? In my experience it specific angles and radius that triggers it, where other cases will work just fine, also seeing my photo’s in previous reply.
The current junction deviation algorithm does this for angles (or what I have referred to as corners) - and it works pretty bloody well - for corners.
The problem I am describing here is that you have a short segment turning 10 degrees. As the machine processes each vector it basically goes yeah cool, 10 degrees, I can hurtle through that at full speed. Add 9 those in a row, and you have suddenly turned 90 degrees with nearly 0 deceleration.
What I am proposing is that we add all these small segments together into an arc then trigger a slow down based on this cumulative arc.
Squid116
on 11 Jan 2020
@hoffbaked what about using the arc centre of each successive three points, then we have two options:
- We can check to see if all arc centres in the arc are close to one another (problem: define a reasonable value of close) (problem two: how computationally expensive is it to check a group of point for closeness?
- Has the arc centre of the last three points crossed the cumulative arc vector compared to the previous result? This would cover your wavy line, and a longer arc (where the arc centres stays in the same spot but vector moves past the centrepoint).
Of course all this has the problem that we now need to store (at least 3) previous vectors individually, all the arc centres as well as the arc accumulation vector.
Squid116
on 11 Jan 2020
Maybe I’m thinking to simple, but couldn’t it be resolved by simply looking at the angles? Any arcing that is within N degrees of deviation is one case, and anything beyond that is another case? In my experience it specific angles and radius that triggers it, where other cases will work just fine, also seeing my photo’s in previous reply.
The current junction deviation algorithm does this for angles (or what I have referred to as corners) - and it works pretty bloody well - for corners.
The problem I am describing here is that you have a short segment turning 10 degrees. As the machine processes each vector it basically goes yeah cool, 10 degrees, I can hurtle through that at full speed. Add 9 those in a row, and you have suddenly turned 90 degrees with nearly 0 deceleration.
What I am proposing is that we add all these small segments together into an arc then trigger a slow down based on this cumulative arc.
Ah right, I haven’t had time yet to look into the exact code, so didn’t realize what I said was in fact already as it is currently implemented.
It would indeed as you say make sense to look forward N moves as accumulate those and use that as input.
DrywFiltiarn
on 11 Jan 2020
I have been looking further into it - and I think the klipper implementation of junction deviation is more complete:
https://github.com/KevinOConnor/klipper/blob/master/klippy/toolhead.py#L57
def calc_junction(self, prev_move):
if not self.is_kinematic_move or not prev_move.is_kinematic_move:
return
# Allow extruder to calculate its maximum junction
extruder_v2 = self.toolhead.extruder.calc_junction(prev_move, self)
# Find max velocity using "approximated centripetal velocity"
axes_r = self.axes_r
prev_axes_r = prev_move.axes_r
junction_cos_theta = -(axes_r[0] * prev_axes_r[0]
+ axes_r[1] * prev_axes_r[1]
+ axes_r[2] * prev_axes_r[2])
if junction_cos_theta > 0.999999:
return
junction_cos_theta = max(junction_cos_theta, -0.999999)
sin_theta_d2 = math.sqrt(0.5*(1.0-junction_cos_theta))
R = (self.toolhead.junction_deviation * sin_theta_d2
/ (1. - sin_theta_d2))
tan_theta_d2 = sin_theta_d2 / math.sqrt(0.5*(1.0+junction_cos_theta))
move_centripetal_v2 = .5 * self.move_d * tan_theta_d2 * self.accel
prev_move_centripetal_v2 = (.5 * prev_move.move_d * tan_theta_d2
* prev_move.accel)
self.max_start_v2 = min(
R * self.accel, R * prev_move.accel,
move_centripetal_v2, prev_move_centripetal_v2,
extruder_v2, self.max_cruise_v2, prev_move.max_cruise_v2,
prev_move.max_start_v2 + prev_move.delta_v2)
Notably the things that it checks that marlin doesn't:
- R * self.accel (this is our current vmax_junction_sqr)
- R * prev_move.accel (easily calculated if we store the previous acceleration)
- move_centripetal_v2 (easily calculated)
- prev_move_centripetal_v2 (would be easily calculated by saving a few extra details from the previous block)
- extruder_v2 (Maybe not needed or catered for elsewhere?)
- self.max_cruise_v2 (block->nominal_speed_sqr)
- prev_move.max_cruise_v2 (previous_nominal_speed_sqr)
- prev_move.max_start_v2 + prev_move.delta_v2 (maximum speed that the previous block could achieve - maybe not needed?)
Notably my machine runs very well on klipper with acceleration values much higher than I can achieve in marlin - and I don't see any layer shifts - could these extra limits be the difference? I'm not home at the moment but I will get stuck into working on this tonight to see if I get somewhere.
Squid116
on 15 Jan 2020
I have crudely implemented Klipper's calculations as above. Printed a test cube and it looked good, so now onto my torture test - baby yoda - this same file was printing under klipper and I have over a month worth of failures under marlin so hopefully this makes the difference!
Only printed the first layer so far, but everything feels smoother there is some wavyness around where the brim and the support raft intersect - they were nearly shaking the maching apart using the unmodified code, now if felt smooth. Can't wait to see how this little guy looks in the morning and report back.
Code is here if you are interested: https://github.com/Squid116/Marlin/commit/6837ed51514fb5550db65163f2a82b977ca6816d
I have an SKR 1.3 and a big slow machine so don't need to be too careful about optimisation when doing a proof of concept. So I havent made any considerations to optimisation yet - my plan was to get it working then work from there.
edit: 1:22 into the print and I'm going to leave it for a bit - but looking very promising at the moment, not often I get this far with no shift (although it isn't unheard of)!
Squid116
on 15 Jan 2020


Not quite the triumphant result I was hoping for, but there is hope. The first shift looks like a genuine collision from the support curling up - the second is more of a mystery.
Squid116
on 15 Jan 2020
I was having layer shifting issues with my modified ender 3 and an mks sbase board. This solution seemed to have solved my issues:
https://github.com/MarlinFirmware/Marlin/issues/12677#issuecomment-449399385
Not sure if this might help here as well?
 aeschrud
on 15 Jan 2020
aeschrud
on 15 Jan 2020
I was having layer shifting issues with my modified ender 3 and an mks sbase board. This solution seemed to have solved my issues:
#12677 (comment)
Not sure if this might help here as well?
The fix for that issue addressed what I would call “micro shifting” due to random missed steps in every direction. The result was prints with rough or wavy sides. Not like the large shifts still seen here.
A large shift like these would likely require either mechanical interference, or something causing the drivers to shut down temporarily. Maybe an overheating scenario could cause this?
sjasonsmith
on 16 Jan 2020
@sjasonsmith no OT prewarn on the drivers - so I think we can rule that out.
I had gone back to basics in order to make sure I am dealing with one issue at a time, I will try tonight with my code and enabling some of these features (square wave stepping, adaptive step smoothing, S_CURVE_ACCELERATION etc). I have no doubt that the klipper code has improved things (in the unmodified code I'd often see 20+ shifts in the print), now I'll see if I can get everything playing nice together.
Squid116
on 16 Jan 2020
I just sat down to check things before I went to bed - and I heard it happen and managed to stop within the same layer. Looking at the misaligned infill I can pretty easily see the exact gcode that caused this skip. There was nothing remarkable about the move, there was no collision it does go 180 degrees with only a bunch of small segments in beteween.
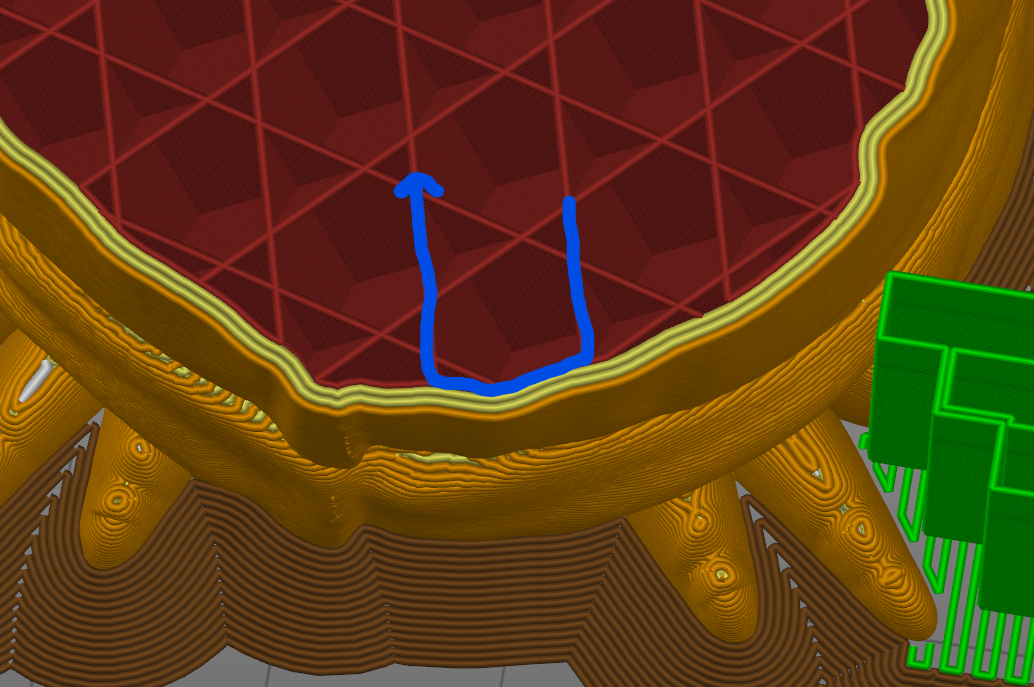
Of course this doesn't solve the problem, but hopefully I can isolate this gcode and run it through the planner with some logging to if there are any strange results.
edit: this is the gcode where the shift occured:
G1 X221.537 Y235.969 E22.87409
G1 X221.291 Y235.988 E22.87949
G1 X220.844 Y235.971 E22.88930
G1 X231.970 Y194.448 E23.83120
G1 X231.561 Y194.279 E23.84089
G1 X231.278 Y194.188 E23.84741
G1 X230.227 Y193.607 E23.87373
G1 X229.413 Y193.056 E23.89527
G1 X229.014 Y192.826 E23.90535
G1 X228.388 Y192.581 E23.92008
G1 X227.779 Y192.521 E23.93349
G1 X225.903 Y192.502 E23.97459
G1 X214.570 Y234.799 E24.93402
G1 X214.216 Y234.717 E24.94199
G1 X213.426 Y234.668 E24.95932
G1 X212.592 Y234.720 E24.97764
G1 X221.291 Y235.988 E22.87949
G1 X220.844 Y235.971 E22.88930
G1 X231.970 Y194.448 E23.83120
G1 X231.561 Y194.279 E23.84089
G1 X231.278 Y194.188 E23.84741
G1 X230.227 Y193.607 E23.87373
G1 X229.413 Y193.056 E23.89527
G1 X229.014 Y192.826 E23.90535
G1 X228.388 Y192.581 E23.92008
G1 X227.779 Y192.521 E23.93349
G1 X225.903 Y192.502 E23.97459
G1 X214.570 Y234.799 E24.93402 ;it tries to take this corner (~102 degrees) at 10.48mm/s
G1 X214.216 Y234.717 E24.94199
G1 X213.426 Y234.668 E24.95932
G1 X212.592 Y234.720 E24.97764
That corner it is trying to take at 10.48mm/s where y is approximately 0 at the start.
I worked my JD value of 0.013 (yes matching the default - but calculated from different values) as (0.455/500) where 5 is my "classic jerk" and 500 is my printing velocity. Somehow we are allowing it to take this corner at nearly 2 times the "classic jerk" value I know my machine can handle.
Edit: it tries to take that corner at the square root of 10.48 or 3.23mm/sec which is sensible.
Squid116
on 16 Jan 2020
All these layer shifting issues seem to be closed in favor of this one, so posting this here.
I get much smaller layer shifts than pictured in this thread, but this is what I have been trying to fix...


I have a Monoprice Select Mini v1 that I "upgraded" to an SKR 1.3 and TMC2209 drivers, and Marlin 2.
This is an existing printer that I swapped the control board out of. The printer frame and steppers printed fine with the original control board.
What I've tried:
- bugfix-2.0.x branch
- acceleration is down to 400 (which is what the original control board was using)
- printed slow (first layer is 20mm/s, rest 50mm/s. Even the first layers shift noticeably. these are the same speeds I was using on my old board)
- Did a Junction Deviation calibration print and picked an appropriate value.
- Tried moving the current for the X and Y stepper around a bit (tried 450, 550, 650, 750)
- re-lubricated linear bearings and rods, incase I got some gunk on them while fiddling around swapping the control board
- re-tensioned the X and Y belts (actually replaced the tensioning mechanism for both axes)
- Tried with and without stealthChop enabled
- Tried with and without Interpolation enabled
- Tried with and without Linear Advance enabled
- Tried with and without S-Curve Acceleration
I thought it might have been related to fast/long travels (120mm/s) missing steps perhaps, but I did a print that was narrow pillars at opposite corners of the bed so it had to do the longest travel possible, and it didn't make it any more or less "wavey".
Based on discussion in #12677 I'll try to mess with MINIMUM_STEPPER_PULSE, MINIMUM_STEPPER_POST_DIR_DELAY, MINIMUM_STEPPER_PRE_DIR_DELAY next but haven't had time.
Here is the M503 and M122 of one of my attempts:
https://gist.github.com/rally25rs/bcde16222a4a08508d567ad3fa47d96e
My config:
https://github.com/rally25rs/Marlin/blob/jeff-mp-mini/Marlin/Configuration.h
https://github.com/rally25rs/Marlin/blob/jeff-mp-mini/Marlin/Configuration_adv.h
_update_
It looks like MINIMUM_STEPPER_PULSE and/or MINIMUM_STEPPER_PRE/POST_DIR_DELAY fixed my layer shift issues. Not sure if those default values just aren't good for TMC2209s, or if it's also dependent on the steppers.
 rally25rs
on 17 Feb 2020
rally25rs
on 17 Feb 2020
@rally25rs can you share the values you used? I am also running skr 1.3 with 2209s. I'll see if your values help me.
Currently I am just running slow (40mm/s max speed) and avoiding the shifts, but I know I can go faster!
Squid116
on 19 Feb 2020
@Squid116 I had shifting issues with the original/default values of:
#define MINIMUM_STEPPER_POST_DIR_DELAY 20
#define MINIMUM_STEPPER_PRE_DIR_DELAY 20
#define MINIMUM_STEPPER_PULSE 2
I am now using:
#define MINIMUM_STEPPER_POST_DIR_DELAY 650
#define MINIMUM_STEPPER_PRE_DIR_DELAY 650
#define MINIMUM_STEPPER_PULSE 4
and no longer having issues. It's printing nice and vertical now.
I haven't had time to start dialing those values back toward the default to see how fast I can push it before the shifting happens. Have had too many other projects to finish this week 😆
I also currently have:
- junction deviation: on
- s-curve accel: off
- stealth chop: off
Again, I want to try re-enabling s-curve and stealthchop to see if they cause any issues, but just haven't had time to run more test prints.
Edit:
I turned s-cure accel back ON and I'm down to
#define MINIMUM_STEPPER_POST_DIR_DELAY 200
#define MINIMUM_STEPPER_PRE_DIR_DELAY 200
on the delays, and it's still printing without shifted layers. As I run prints I keep backing down the delays. (I'll update this post as I find a minimum that works well for me anyway. maybe it'll help someone down the road)
rally25rs
on 19 Feb 2020
I had one layer shift again a couple days ago even after I thought I'd fixed it (by using correct jerk setting). Would increasing the MINIMUM_STEPPER_* values be worth trying for A4988s? What kind of impact on performance should I expect from increasing them?
richfelker
on 19 Feb 2020
@rally25rs Were you able to further tune the parameters? I happen to be having the same issue and have a RAMPS board on a modified MPSM v3. Would love to learn if you were able to 1) verify if you have the resolution to the layer shifting and 2) what values you settled on?
 sidhant
on 19 Mar 2020
sidhant
on 19 Mar 2020
@sidhant I haven't found a minimum value that prevents the issue, mostly because I really don't feel like recompiling and flashing my firmware between every print, but I'm currently at
#define MINIMUM_STEPPER_POST_DIR_DELAY 200
#define MINIMUM_STEPPER_PRE_DIR_DELAY 200
#define MINIMUM_STEPPER_PULSE 4
- junction deviation: on
- s-curve accel: on
- stealth chop: off
and not having any issues (probably a dozen prints at those settings)
Jumping from a delay of 650 to 200 didn't feel hugely significant to print time (i didn't track print times between same models but just watching the printer) so I haven't been too worried about dialing it back further.
rally25rs
on 20 Mar 2020
Thanks @rally25rs!
To share back with the community, I have been extensively testing the layer shifting issue and seems like the culprit is StealthChop.
I am running a modified MP Select Mini V3 with RAMPS 1.4, running MARLIN 2.0.5.1 with TMC2130 drivers. After trying many different combinations of settings I can confirm that StealthChop guarantees layer shifting in my prints, while keeping it off with no other configuration changes has caused no layer shifting in the many prints I have done since. With StealthChop off, the printer is not as quiet however still pretty muted compared to stock drivers.
In pursuit of trying to narrow down layer shifting, I came across this excellent discussion where another user concludes that StealthChop and in particular the microPlyer feature is not ideal for 3D printing where missed steps are disastrous. An _engineer from TMC confirmed that in the scenario posted by that user, StealthChop can indeed miss steps_.
You can find the thread here: https://forum.raise3d.com/viewtopic.php?t=6013
In the datasheet for TMC2100 it is stated: "Attention: microPlyer only works perfectly with a stable STEP frequency". Well, a 3D printer has nothing but an unstable step frequency! It accelerates and brakes and changes motor direction all the time, just think of a rectilinear infill pattern, usually created at quite high speed.
One will notice that the recommendation is to use TMC2130 that allows StealthChop to be ON, but microPlyer to be OFF. I tried this by turning off the interpolation and confirming that the CHOPCONF registers are appropriately configured, however it resulted in a lot more layer shifting on my prints.
I decided to cut my losses and stick to StealthChop being entirely off. I am using the following settings that also work for @rally25rs.
#define MINIMUM_STEPPER_POST_DIR_DELAY 200
#define MINIMUM_STEPPER_PRE_DIR_DELAY 200
#define MINIMUM_STEPPER_PULSE 4
- junction deviation: on
- s-curve accel: on
- stealth chop: off
Also note that I have been printing at 60mm/sec (on a printer that's rated at 50-70 mm/sec) and have never slowed it down. Of note is also the fact that OT_PREWARN have never been triggered, so contrary to common cause that the drivers are over heating, that is not the case with my prints as I have heat sinks and aggressive active cooling.
sidhant
on 20 Mar 2020
@sidhant
To share back with the community, I have been extensively testing the layer shifting issue and seems like the culprit is StealthChop.
I'm inclined to agree that StealthChop may the culprit as well (atleast partially). I've been trying to tune out the layer shift in my prints pretty extensively and they are definitely more prevalent when using StealthChop. I think there may be something else going on though, yesterday, I actually printed a small planter for my daughters succulent with StealthChop on and it completed the print flawlessly. The settings for that were
Archim 2 Board
TMC 2130 all axis
March 15th Bugfix 2.0.x
//#define MINIMUM_STEPPER_POST_DIR_DELAY 650
//#define MINIMUM_STEPPER_PRE_DIR_DELAY 650
define MINIMUM_STEPPER_PULSE 2
define MAXIMUM_STEPPER_RATE 400000
//#define SQUARE_WAVE_STEPPING
Now, I tried printing a pauldron for a mandalorian cosplay with the same settings and in the first 50mm of the print it shifted 4 times at random intervals in the y axis . It' was only after I turned off StealthChop in the LCD that the rest of the print completed without any issues.
Fast forward to this morning.....
I started printing the accompanying pauldron with the same settings (StealthChop OFF) and it shifted hard on the Y axis for 3 consecutive layers. I'm not too sure about the stability of the TMC2130s with 32 Bit Marlin at the moment.
Edit- And it just did it again on the same print, different iteration. About 1 cm up it shifted hard in the Y axis again about 1cm to the rear of the bed.
 AFprinter
on 21 Mar 2020
AFprinter
on 21 Mar 2020
@AFprinter Yes, you are right. I do not think I can for certain claim StealthChop is THE underlying reason, however turning it off has greatly narrowed down the layer shifting issue for me. I was also finally able to further tune my motor currents. I do hold my hypothesis that there is something funky going on with TMC drivers.
A better test would be to go back to stock drivers DRV8825 and see what happens.
EDIT: I have also been seeing that folks have much better success using the next generation StealthChop, aka, StealthChop2 that is present on the TMC 22XX series chip such as the TMC2208 or TMC2209. I might try that next instead of wasting my time debugging.
sidhant
on 21 Mar 2020
For those actively testing with this, you may try adding DISABLE_MULTI_STEPPING to your configs. It may make no difference, but it will be interesting to know whether that is a factor in the shifting you observe.
sjasonsmith
on 21 Mar 2020
For those actively testing with this, you may try adding
DISABLE_MULTI_STEPPINGto your configs. It may make no difference, but it will be interesting to know whether that is a factor in the shifting you observe.
Where should this be added?
AFprinter
on 22 Mar 2020
Where should this be added?
You can just add to either config file.
#define DISABLE_MULTI_STEPPING
sjasonsmith
on 22 Mar 2020
IIRC StealthChop does not have missed step detection, so if you acceleration or driver current/vref settings aren't optimal, you will get random missed step issues.
I initially had to disable it for my Z axes or else it was missing ~20% of its steps. After that I also found that I still had the default marlin acceleration of 100, where it should have been down to around 20 or 30 for a lead screw setup.
I've since left StealthChop off for all my axis. My printer is in my basement so the increased noise isn't a factor, and it's still way quieter than the stock drivers.
rally25rs
on 23 Mar 2020
IIRC StealthChop does not have missed step detection, so if you acceleration or driver current/vref settings aren't optimal, you will get random missed step issues.
None of the drivers commonly used in 3D printers have missed step detection. As in, they are not closed loop systems. Issue of in general missed steps is not limited to TMC drivers or StealthChop. If we misconfigure the current or accelerate beyond mechanical limits, or the carriage hits an obstacle, etc., the stepper will miss a step and the firmware has no way of knowing. Adding some kind of linear or rotary encoder (like cheap ink printers do) will resolve it.
sidhant
on 23 Mar 2020
So after trying a couple different values for the aforementioned delays and stepper pulse rates and whatnot, I've arrived at a setting that seems to work (in spreadcycle at least). I have everything in their default values except I have square wave stepping ON. Stealchop is off and causes (at least on my machine) random lock ups where the heaters stay on creating a very unsafe situation. I've walked in and the model was completely burned and deformed around the hotend.
AFprinter
on 23 Mar 2020
Earlier on, I was printing petg with a Marlin BF2.0 nightly build #5 which I recompiled yesterday. I'm running an BigtreeTech SKR1.1 (LPC1768) with TMC2130 on all axis. I tend to run stealthchop on x and y axis to keep the noise down.
X and Y Axis are running on MGN12 rails and sliders, so quite frictionless (BLV mod)
With the default acceleration values of Marlin (3000), I had again skipped steps on the Y axis although I'm running a beefy 2.8A 48Ncm 0.9°/step motor with approx 900mA current and 16 microsteps. The TMC2130 has a big heatsink glued on it (10x the size of a stock one) and is forced cooled. So I can rule out overheating and skipped steps due to this.
Only after putting the Y axis acceleration back to 2000, it was working fine. I'm now going to reduce the microsteps to 8 as I don't need that precision with a 0.9° motor.
I also have s-curve and junction deviation active.
DavidThijs
on 26 Mar 2020
I just wanted to mention: During probing with G29, sometimes accelerations come with a "thumb" noise, and sometimes they don't. I experimented with lower currents while homing and probing but that led to stalls, not during (sensorless) homing but only while probing. Board is MKS_SGEN_L, TMC2130, bugfix branch.
hamster65
on 26 Mar 2020
I noticed a layer shift on my Ender 3, Marlin 2.0.5.3, the board is SKR E3 DIP, TMC 2208 UART. If ADAPTIVE_STEP_SMOOTHING is enable

.
I printed the same code, the left cube is ADAPTIVE_STEP_SMOOTHING off, the right cube is on.
 Viking117
on 2 Apr 2020
Viking117
on 2 Apr 2020
TLDR: EMI was messing with uart communications on tmc2208 and making the drivers freak out.
I got an btt SKR E3 dip v1.1 board with 2208 drivers running in uart. i got random layer shitfting and firmware setting changes seemed to work randomly. Initially it looked like driver overheating and skipping steps momentarily but no they were not overheating.

Eventually i tried using the drivers in standalone mode and it worked just fine.
So i realized that my issue might be EM interference on the uart lines from the step down converter i have next to the drivers.

I have not tested it out further because i want to get back to printing, but to me it does seem like EMI is messing with the tmc drivers for short periods somewhat similar to an overheat
 FyiIAmASpy
on 4 Apr 2020
FyiIAmASpy
on 4 Apr 2020
TLDR: EMI was messing with uart communications on tmc2208 and making the drivers freak out.
.
.
.
I have not tested it out further because i want to get back to printing, but to me it does seem like EMI is messing with the tmc drivers for short periods somewhat similar to an overheat
EMI can also be caused by heating the bed or extruder. On my SKR E3 dip v1.1 board, when the bed is warming up, the usb stops working.
Viking117
on 4 Apr 2020
TLDR: EMI was messing with uart communications on tmc2208 and making the drivers freak out.
.
.
.
I have not tested it out further because i want to get back to printing, but to me it does seem like EMI is messing with the tmc drivers for short periods somewhat similar to an overheatEMI can also be caused by heating the bed or extruder. On my SKR E3 dip v1.1 board, when the bed is warming up, the usb stops working.
That sounds like a poorly designed board or a missing ground connection to the shield.
sidhant
on 4 Apr 2020
An update from me:
I downgraded my board to a ramps, running the TMC 2209s in standalone, and was still getting layer shifts. So that ruled out the skr 1.3. the problem seemed to be occurring more and more frequently, so it appeared to be something degrading.
So I checked my mechanicals again, and I had one failing bearing. I didn't notice it last time I checked so it must have got worse since then, which matches the increase in frequency I have observed - replaced all bearings on that axis (y) and have printed for 60+ hours with no sign of the issue.
Squid116
on 5 Apr 2020
I also noticed that during nozzle cleaning (the nozzle moves back and forth over a brush) some movements are smooth while others produce a "knocking" noise. Same as during probing moves. Feels like it omnits the acceleration phase.. It appears to happen randomly. Repeating the same move may produce the noise, or it may run smoothly.
hamster65
on 5 Apr 2020
An update from me:
I downgraded my board to a ramps, running the TMC 2209s in standalone, and was still getting layer shifts. So that ruled out the skr 1.3. the problem seemed to be occurring more and more frequently, so it appeared to be something degrading.
So I checked my mechanicals again, and I had one failing bearing. I didn't notice it last time I checked so it must have got worse since then, which matches the increase in frequency I have observed - replaced all bearings on that axis (y) and have printed for 60+ hours with no sign of the issue.
Just out of curiosity, did you uncomment "monitor_driver_status"? I just noticed that I had that on and Martin was reducing my current down to a point where i was missing steps and I'm 99% sure that's what's causing my layer shifts. After turning off "monitor_driver_status" and selling my current a touch higher I haven't had any layer shifts.
I'll fire off a few more prints to see if that's actually the culprit.
AFprinter
on 11 Apr 2020
I just finished hooking an SKR ver1.3 board to my Tronxy X3A printer. The Z steppers are in parallel. I am using 2130 stepper drivers. I am running Marlin 2.0.X The board is controlled by OCTOPI running on a PI B+. Vref pots are at the factory setting. Any attempt to run stealthchop at print speeds higher than 20 mm/sec results in extreme layer shift. Increasing current in software does not seem to help. Hybrid threshold seems to be ignored. With stealthchop off all is well. I will test with monitor_driver_status commented and see if the situation improves.
At worst I will just leave stealthchop off.
 bill-orange
on 23 Apr 2020
bill-orange
on 23 Apr 2020
@bill-orange I have stopped investigating this for now, but my suspicion is that none of the cheap board manufacturers are implementing the TMC steppers correctly. There is a lot more to it than just plopping it in as a replacement (counter to what TMC claims). Looking through the datasheet it seemed that managing EMI, grounding, proper filtering and noise management is crucial. In addition, when using StealthChop, the current requirements and the torque trade-offs are unique compared to the legacy A4988. To give you an example, if you look at any appropriately designed printer for robust use (think Ultimaker, Zortrax etc.), they all have proper ferrite beads, sufficiently powered PSUs and well designed circuit boards (such as sectioned ground pours to manage EMI).
sidhant
on 23 Apr 2020
FYI - a lot of my layer shifting and quality problems went away when I reduced my travel speed to the same as the print speed.
Bob-the-Kuhn
on 24 Apr 2020
I had Y layer shifting happening on a 2.5 hr print. 15mm high part.
First print was 2 shifts at about 1/3 and then again ~7/8. Being I had the printer in a box over the last year, I thought something mechanical was going on. Checked everything and it all looks good.
I was running 2.0.5.3 release I downloaded about a week ago now.
So, I upgraded to the 2.0.x-bugfix on the 5th and started the same print. This time, the same shift on Y only once at about 13/16 of the way done.
I have noticed a few other issues....those are other topics.
I am going to slow down the max_accel and see if that helps.
 Tannoo
on 8 May 2020
Tannoo
on 8 May 2020
I experienced layer shifts again on my Ender 3 that had firmware rev 9c021158e5 last night, printing https://www.thingiverse.com/thing:2318105. I'm trying again with latest. Using LA, classic jerk, no scurve. With both the old and new firmware build, the circles are all printing with rapid oscillation between fast and slow motion, also visible in the extruder gear rapidly twitching back and forth (due to LA adjusting for the speed). But so far the new has not produced a layer shift (midway through the print now, but past the point of the first shift from last night's).
I suspect there was a hard bug causing the shifts (https://github.com/MarlinFirmware/Marlin/pull/16128 seems to have been merged before the version I was using, though, and I thought it had already fixed the problem I was experiencing in the past) as well as bad motion behavior making it more likely to be hit, with the former resolved and the latter still present.
One other data point: menu UI is now fully responsive during printing. Before it would randomly stutter or miss input, like a load or interrupt timing problem.
richfelker
on 25 May 2020
Nope, it's shifted again now. F...
richfelker
on 25 May 2020
I am getting some layer shifting on my prints but it shifts back and forth on the X axis mainly. See attached pic. I am not sure if its the same issue as this bug but I have done so much testing and ruled alot of things and now I am thinking its the firmware so I just started testing that. I also noticed that this happens mainly at higher heights (greater than 100mm) and gets more pronounced the higher it gets.
Did anyone try anything that worked?

 X7JAY7X
on 3 Jun 2020
X7JAY7X
on 3 Jun 2020
Did anyone try anything that worked?
Have you tried the various things people have mentioned above int his thread?
sidhant
on 3 Jun 2020
Hi folks .
One simple question: do we have a survey on the ones having layer shift and the cpu type they use??
hobiseven
on 3 Jun 2020
Did anyone try anything that worked?
Have you tried the various things people have mentioned above int his thread?
I have tried the following:
Test #1
- Disabled classic jerk, enabled Junction deviation
Result: No difference. Still layer shifting.
Test #2
- Changed MINIMUM_STEPPER_DIR_DELAY to 200 and MINIMUM_STEPPER_PULSE to 4
Result: No difference. Still layer shifting.
Test #3
- Disabled HYBRID_THRESHOLD, STEALTHCHOP_XY, STEALTHCHOP_Z
Result: No difference. Still layer shifting.
There are alot of posts in this thread but I think I tried everything that worked for others. If not, let me know.
What should I try next?
X7JAY7X
on 5 Jun 2020
This issue is stale because it has been open 30 days with no activity. Remove stale label / comment or this will be closed in 5 days.
![github-actions[bot] picture](https://avatars2.githubusercontent.com/in/15368?v=4&s=40) github-actions[bot]
on 6 Jul 2020
github-actions[bot]
on 6 Jul 2020
Pinging this because it probably should not be auto-closed.
richfelker
on 6 Jul 2020
Pinging this because it probably should not be auto-closed.
I personally think this should be closed, and new issues reported for more specific failures. This has encompassed so many issues over such a long period of time that it is really no longer clear what it contains (unless people feel like reading all 460+ replies).
sjasonsmith
on 6 Jul 2020
Fair enough.
richfelker
on 6 Jul 2020
This issue has been automatically locked since there has not been any recent activity after it was closed. Please open a new issue for related bugs.
github-actions[bot]
on 4 Sep 2020
Discussion currently being continued at: https://github.com/MarlinFirmware/Marlin/issues/19151
Roxy-3D
on 17 Sep 2020
Related issues
 Matts-Hub
·
3Comments
Matts-Hub
·
3Comments
 manianac
·
4Comments
manianac
·
4Comments
 jerryerry
·
4Comments
jerryerry
·
4Comments
 Anion-anion
·
3Comments
Anion-anion
·
3Comments
 Glod76
·
3Comments
Glod76
·
3Comments
Most helpful comment
OK, this is rather embarrassing but I think I should post it in case it's helpful to others with the same problem. I'm pretty sure all of my layer shift problems in this thread were ultimately exceeding the physical capabilities of the printer.
Due to multiple layers of bad behavior in Cura (particularly how it evaluates configuration files when invoked from command line), it's always been putting
M205 X30 Y30commands in my gcode for travel moves, and 30 is rather high jerk. Apparently the original firmware (either due to Creality's modifications, or just because that's how Marlin was back when they forked it?) did not honor these, either capping the jerk lower or ignoring it entirely, so they didn't break anything, but Marlin 1.9 and 2.0 are attempting to honor it, with bad results.My JD value of 0.08 was based on the formula for choosing a value comparable to classic jerk, with jerk of 25, which is what I thought I'd been using but which doesn't seem to have been being honored either. Jerk of 20 yields JD=0.05 which seems to have worked.
Since confirming that I'm affected by #15473, even with low K, I've switched back to classic jerk with XY limits of 10 mm/s and have not seen any layer shifting problems. I can probably take it up higher, maybe to 20, and will experiment with that later.
TL;DR: If hitting this problem, check that new Marlin isn't honoring bogus jerk values in your gcode that old Marlin was limiting or ignoring.