Marlin: [2.0.x, RFC] `disable_all_heaters()` should not have the side-effect of stopping the print timer.
I have uncovered a tricky problem. The symptom was that our printers (using an EXTENSIBLE_UI) had a "printer halted" screen that would work on MINTEMP when PRINTCOUNTER was disabled, but not show when PRINTCOUNTER was enabled (the board would reboot instead).
It turns out that the cause is that "safe_delay()" cannot be called by any code that is called directly or indirectly by "kill(PGM_P lcd_msg)", as this will hang the board. This happens even prior to the cli() -- so I suspect kill may be called from an ISR?
The reason PRINTCOUNTER was implicated was this call chain:
kill(PGM_P lcd_msg)callsthermalManager.disable_all_heaters();thermalManager.disable_all_heaters();callsprint_job_timer.stop();print_job_timer.stop(), when PRINTCOUNTER is enabled, callsPrintCounter::saveStats()- Since on the Due the emulated EEPROM gets wiped out each time you flash the firmware, I had added some extra code to saveStats() to backup that data to an external serial flash chip.
- That code I use to write to the serial flash chip can do several PAGE PROGRAMs on the serial flash, and rather than busy waiting for each to finish, I call "safe_delay".
While it was my modifications which introduced the fault, I think this uncovers two problems that came together cause the failure:
killis calling other code when interrupts are disabled, and that code cannot callsafe_delaydisable_all_heaters()currently has the non-obvious side effect of messing with the print timer -- and possibly writing to EEPROM -- and neither of these things are needed in a call tokill()
While it would be jolly if safe_delay would work inside the kill function, I believe in practice it would be difficult to arrange this. I would like to instead remove print_job_timer.stop() from disable_all_heaters(). Stopping the timer has nothing to do with disabling heaters, regardless of the validity of the code comment that says "If all heaters go down then for sure our print job has stopped". Having a function with more side effects than it advertises is bad programming practice and leads to hard to understand faults. There are only a handful of places in Marlin where disable_all_heaters() is called. Where it makes sense to stop the timer, that code can call print_job_timer.stop() directly.
If I were to make this change, then kill would not attempt to pause the print job timer. Which is of no consequence since the printer will be halted anyway.
Thoughts? Can I create a PR removing print_job_timer.stop() from disable_all_heaters() and instead call it where ever disable_all_heaters() happens to be called?
 marcio-ao
marcio-ao
All 70 comments
Ok, the above modifications get me closer (the error screen paints), but I still have some code for playing an error sound that relies on "millis()" and that code is causing the board to reboot. Any ideas on how I could get around that problem?
marcio-ao
on 18 Oct 2018
Have a look at safe_delay(). Call thermalManager.manage_heater(); every now and then, else the watchdog will bite you..
 AnHardt
on 18 Oct 2018
AnHardt
on 18 Oct 2018
@AnHardt: Actually, it is safe_delay which is biting me. If you call it from within kill, it will hang the board because safe_delay calls delay which won't work if interrupts are disabled. I suspect kill is itself being called from an ISR. Even if it isn't being called from an ISR, it calls "cli()" to suspend interrupts followed by anothre call to "disable_all_heaters()", which eventually is calling code that calls safe_delay. And that delay crashes because the timer ISR isn't running.
marcio-ao
on 19 Oct 2018
On ARM depending on the implementation but probably all of them, millis() requires the systick to be active to increment and that requires interrupts to be enabled.
 p3p
on 19 Oct 2018
p3p
on 19 Oct 2018
@marcio-ao : kill() is an emergency feature, with no return of death, and as such, it should be used where there is no other way to recover.
That is the reason of the cli(), and i do agree no call to delay() and/or safe_delay() should be done from within it.
Calling safe_delay() should be forbidden from kill(), as safe_delay() can call the idle() chain of functions.
Instead of using cli(), we could just disable stepper and termal interrupts, but it is also very complex to ensure the "delay()" keeps running.
I assume there is no kill() call from the isr() (you can add a trace() function to know the chain of calls that lead to the kill() fn being called
 ejtagle
on 19 Oct 2018
ejtagle
on 19 Oct 2018
@thinkyhead
While you are at it.
_delay_ms(600); // Wait a short time (allows messages to get out before shutting down.
cli(); // Stop interrupts
_delay_ms(250); //Wait to ensure all interrupts routines stopped
thermalManager.disable_all_heaters(); //turn off heaters again
#ifdef ACTION_ON_KILL
SERIAL_ECHOLNPGM("//action:" ACTION_ON_KILL);
#endif
#if HAS_POWER_SWITCH
move the ACTION_ON_KILL block above the cli() else it is not send when serial sending is interrupt based.
AnHardt
on 19 Oct 2018
You got it! fba4a58
 thinkyhead
on 19 Oct 2018
thinkyhead
on 19 Oct 2018
Calling safe_delay() should be forbidden from kill(), as safe_delay() can call the idle() chain of functions.
I still think this is a bad choice, because it puts a restriction on code that can be called from kill() that is hard to work around. For example, if the display driver code needs to do a delay, it may well be calling safe_delay. The requirement that safe_delay() not be used upon a kill() basically means that the display driver code must treat drawing the kill screen as a special case, which can be very difficult.
I like @thinkyhead's idea of having a global state flag that says "kill()" was called could solve this elegantly. safe_delay() could check that flag and not call any of the thermal functions if it was set. If needed, it could even implement the requested delay using NOPs, by calling delayMicroseconds() repeatedly, or whatever is needed to make sure it still works under whatever exceptional circumstances kill was called.
marcio-ao
on 19 Oct 2018
I assume there is no kill() call from the isr() (you can add a trace() function to know the chain of calls that lead to the kill() fn being called
@ejtagle: I am still finding that delay() is not working in the kill(), even after the recent modifications. I tried adding "trace()" to the code, but it is undefined. Is there something I need to do to enable it? Certainly having that trace feature would be extremely helpful.
marcio-ao
on 19 Oct 2018
I think the problem is that kill() must be getting called from an ISR, so the interrupts must be disabled even before the call to cli().
Here is a wild idea, would there be any way to re-enable interrupts at the start of kill()? Obviously doing this is not recommended from within an ISR, but neither is entering an infinite loop, which is exactly what kill() does. So my idea is the following:
- At the start of
kill()check a global flag to see ifkillwas already called, if so, return (this avoids re-enteringkill()from another ISR) - Set the global flag to indicate that
killis in progress. - Enable interrupts
- Call the UI to redraw the kill screen
- Disable interrupts
- Proceed to call the remainder of the shutoff code,
minkill()in @thinkyhead's latest commit.
marcio-ao
on 19 Oct 2018
So this is pretty weird, even when I try the following code, it only prints ">>>>delay" and then reboots the board:
/**
* Kill all activity and lock the machine.
* After this the machine will need to be reset.
*/
void kill(PGM_P const lcd_msg/*=NULL*/) {
#if ENABLED(EXTENSIBLE_UI)
static bool kill_called = false;
if(kill_called) return;
kill_called = true;
#endif
SERIAL_ERROR_START();
SERIAL_ERRORLNPGM(MSG_ERR_KILLED);
thermalManager.disable_all_heaters();
disable_all_steppers();
#if ENABLED(EXTENSIBLE_UI)
interrupts();
SERIAL_ECHOLNPGM("About to call millis()");
uint32_t start = millis();
SERIAL_ECHOLNPGM(">>>>delay");
#undef delay
delay(10);
SERIAL_ECHOLNPGM("<<<<delay");
SERIAL_ECHOLNPAIR("Elapsed time: ", millis() - start);
SERIAL_ECHOLNPGM(">>>>UI::onPrinterKilled");
UI::onPrinterKilled(lcd_msg ? lcd_msg : PSTR(MSG_KILLED));
SERIAL_ECHOLNPGM("<<<<UI::onPrinterKilled");
while(1) watchdog_reset();
#elif ENABLED(ULTRA_LCD)
kill_screen(lcd_msg ? lcd_msg : PSTR(MSG_KILLED));
#else
UNUSED(lcd_msg);
#endif
#ifdef ACTION_ON_KILL
SERIAL_ECHOLNPGM("//action:" ACTION_ON_KILL);
#endif
minkill();
}
This is the output I get:
echo:Active Extruder: 1
echo:Unknown command: "G26 "
echo:Unknown command: "G21 "
Error:MINTEMP triggered, system stopped! Heater_ID: bed
Error:Printer halted. kill() called!
About to call millis()
>>>>delay
So at least on the Due, it does not seem to be possible to re-enable interrupts inside an ISR. This seems odd. Perhaps something else causes the timer to lock up?
Incidentally, the code as written in minkill cannot possibly work on Due. This is because in HAL_DUE "_delay_ms" simply calls "delay":
void _delay_ms(const int delay_ms) {
// Todo: port for Due?
delay(delay_ms);
}
@marcio-ao : The function to call to get a traceback is defined in
HAL\shared\traceback\traceback.h : traceback();
And you need the serial port to be working, as it uses it to dump the information
Yes, inside an ISR on DUE you cannot reenable ints. That is the way ARM with the NVIC controller works. Global interrupts are not disabled. What is disabled is all interrupts that have lower (and the same if configured to) priority than the currently executing ISR.
The board reset is probably resetting because of the watchdog. The watchdog is ticked in the termalManager when the ADC conversion is done.
ejtagle
on 19 Oct 2018
@marcio-ao : Enable USE_WATCHDOG and WATCHDOG_RESET_MANUAL and you will get a traceback when the watchdog kicks in.
If you want a "nice" traceback, add the following flags to your gcc compile line
-funwind-tables -mpoke-function-name
And you will get a proper traceback with function names included
ejtagle
on 19 Oct 2018
The problem with the kill() and the question is "how safe is the state of Marlin when this function is called?"
If the answer is "the firmware is in a sane state, i can trust turning off heaters, aborting gcode execution, motion execution, etc", then, maybe kill() should not be implemented the way it is implemented right now - And a KILLED state would make much more sense.
But, for memory corruption, unsafe execution, etc, etc, kill() should just kill it. And i know the main problem is how to inform the user, because when there is memory corruption, you cannot trust anything.
For example, Windows has dedicated code to be able to display the "Blue screen of death".. That is the only way to make sure the message is seen
ejtagle
on 19 Oct 2018
Yes, inside an ISR on DUE you cannot reenable ints.
That's what I was beginning to suspect. I was trying to call HAL_timer_enable_interrupt and NVIC_EnableIRQ functions all to no avail. It's good to know for sure that what I am trying to do is impossible on the DUE so I won't waste more time trying to get this approach to work!
So, the situation is that in Marlin kill() can be called from an ISR, and on DUE, there is absolutely no way to make delay() or millis() to work from within that ISR. This makes it hard to implement certain things in a GUI. It also means the board will always reboot right now because the HAL_DUE defines _delay_ms() as delay(), and there is a _delay_ms(250) the kill routine.
This does explain a lot. Thank you for clarifying.
marcio-ao
on 19 Oct 2018
What is disabled is all interrupts that have lower (and the same if configured to) priority than the currently executing ISR.
Would it be possible to have the Arduino timer routines be a higher priority than the ISRs that can call kill()?
marcio-ao
on 19 Oct 2018
Yes, it is possible. I seem to recall delay() uses the SysTick timer (all ARM based boards use it)
The other choice would be to busy_wait instead of using delay()
ejtagle
on 19 Oct 2018
We basically have a situation right now where is any code in the kill() routine calls the seemingly harmless routines delay() or safe_delay(), the kill() function hangs mid-execution and you potentially burn down someone's house. I would argue that for safety, the timer routines should be higher priority than the temperature control ISR (which can call kill()), but lower than the stepper ISR (which presumably doesn't). With such a priority change in place, I think everything would work.
marcio-ao
on 19 Oct 2018
The other choice would be to busy_wait instead of using delay()
Yes, but this means that the UI code has to know when to busy_wait or when to safe_delay(). It also means millis() cannot be used for timekeeping. I currently rely on that in some sound playing functions (which can run asyncronously) and it would be rather tricky to rewrite it all to use delay.
marcio-ao
on 19 Oct 2018
Depending on the need of SPI communications, you´d probably need also to switch priorities.
But i am not sure if your proposed change would make sense.
What i´d do is
-Add a flag to signal the KILLED state (in the kill() function)
-Check that flag in safe_delay(). If set, then busy wait and also clear the watchdog to perform the requested delay. You can use the DELAY_NS with 1000 as a way to perform 1ms delays busy-waiting
-Do not count on SPI facilities or USART facilities.
ejtagle
on 19 Oct 2018
Although I understand the need to output some form of information on kill, the function is (should be) designed for "oh god somethings gone horribly wrong we are all going to die" situations, get everything shutdown and stop the mcu as soon as possible. safe delay or anything that calls (complex branching) functions should be severely limited. There may be a need for another kill function that is less critical that you can use when the machine isn't possible on fire, or crushing my hand because its gone mental.
I'm curious what priority Due has the Systick as, on LPC176x it only increments millis so I set it as priority 0 allowing all other interrupts to use millis.
p3p
on 19 Oct 2018
@p3p Probably is it also set to 0 (the highest priority) . It is not being configured on the Arduino runtime...
ejtagle
on 19 Oct 2018
@ejtagle: With your safe_delay workaround, there is still the millis() problem to contend with.
I am a beginner on the DUE platform, so I'll let it up to you and the other Marlin folks to think it through whether changing priorities would be feasible option. My only observation is that since safe_delay() and millis() work in normal execution, it would be extremely helpful if they would also work when the printer was killed, otherwise you end up with code that works in one situation and not another.
"oh god somethings gone horribly wrong were all going to die" situations.
Generally kill() is called after a runaway temp situation, which means the kill() gets called a certain number of seconds after the temperature fails to raise. So it doesn't seem like kill() needs to respond immediately, it is far worse if it fails to respond at all (because some code called delay() by mistake, for example). Which is why I think not having those timers running is actually a safety risk.
marcio-ao
on 19 Oct 2018
I will have to disagree with that, it should be as instantaneous as we can, and most definitely not be running user interface / communication code, if the kill is not actually critical all the UI updates should be performed before it is called, as the caller knows it doesn't really matter.
but that's all just my opinion.
p3p
on 19 Oct 2018
@p3p I agree with you. kill() was intended to be as instantaneous as possible, for emergency stops.
@marcio-ao : Can you wrap your calls to millis() in a, let´s say safe_millis() call ?
Maybe there is a way to get the time... The SysTick timer is still running, so it should be possible, if interrupts are disabled, to manually update the counter...
ejtagle
on 19 Oct 2018
I'll write for you a replacement to millis() that should only be called when killed and will work with ints disabled (assuming you poll the millis() function at least every 1 second)
ejtagle
on 19 Oct 2018
I agree with you. kill() was intended to be as instantaneous as possible, for emergency stops.
It seems like notifying the user somehow, even playing some sound to alert them of the situation if they are not in the room, seems like an important thing.
I'll write for you a replacement to millis() that should only be called when killed and will work with ints disabled (assuming you poll the millis() function at least every 1 second)
Sure. We could add that function to the EXTENSIBLE_UI and call it safe_millis or something. However, I am still of the opinion that the best solution is simply to allow timers to run.
For what it is worth, this UI code I am having problems with is nothing new and I haven't changed it in months. I know it was working perfectly earlier versions of bugfix-2.0.x, so I really feel like a recent change (perhaps in the last few weeks), that introduced this problem. I'll see if I can find an earlier commit where everything works as expected.
marcio-ao
on 19 Oct 2018
This "replacement" will only work for ARM cpus, but should work when ISRs are completely disabled.
uint32_t safe_millis() {
/* If not killed, just call the old Arduino code */
if (!killed) {
return millis();
}
static uint32_t currTimeHI = 0; /* Current time */
/* Machine was killed, reinit SysTick so we are able to compute time without ISRs */
if (currTimeHI == 0) {
/* Get the last time the Arduino time computed (from CMSIS) and convert it to SysTicks*/
currTimeHI = (uint32_t)((GetTickCount() * (uint64_t)(F_CPU/8000)) >> 24);
/* Reinit the SysTick timer to maximize its period */
SysTick->LOAD = SysTick_LOAD_RELOAD_Msk; /* get the full range for the systick timer */
SysTick->VAL = 0; /* Load the SysTick Counter Value */
SysTick->CTRL = /* MCLK/8 as source */
/* No interrupts */
SysTick_CTRL_ENABLE_Msk; /* Enable SysTick Timer */
}
/* Check if there was a timer overflow from the last read */
if (SysTick->CTRL & SysTick_CTRL_COUNTFLAG_Msk) {
/* There was. This means (SysTick_LOAD_RELOAD_Msk * 1000 * 8)/F_CPU milliseconds
have elapsed */
currTimeHI++;
}
/* Calculate current time in milliseconds */
uint32_t currTimeLO = SysTick_LOAD_RELOAD_Msk - SysTick->VAL; // (in MCLK/8)
uint64_t currTime = ((uint64_t)currTimeLO) | (((uint64_t)currTimeHI) << 24);
/* The count of milliseconds is */
return (uint32_t)(currTime / (F_CPU/8000));
}
(untested, but according to datasheet, it makes sense)
ejtagle
on 19 Oct 2018
Let's itemize all the functions that call kill:
manage_inactivitysave_job_recovery_infomonitor_tmc_driverG29_with_retryget_serial_commandsGcodeSuite::M112validate_homing_moveCardReader::openFile_temp_error(PID_autotune,manage_heater)min/max_temp_error<-Temperature::readings_ready<-Temperature::isrTemperature::analog2temp<-Temperature::isr
The only ISR now calling the main kill function is the Temperature::isr. The functions called by that ISR could avoid calling kill by setting flags which tell loop() to call kill instead (with the appropriate message).
thinkyhead
on 19 Oct 2018
@marcio-ao : We should have 2 different functions:
Maybe one of them should be called abort() and the othe shutdown()
abort() should be used for graceful stopping of the machine, with chances of restarting.
shutdown() when an inmediate shutdown of the machine, with no delay is required.
It depends on the problem being handled the one to use. The heater problems require shutdown(). That feature was introduced because there are people with very powerful heatbeds, and if it takes too long to shutdown, the printer could catch fire and burn your house !
Even an extra second of delay could make the difference here...
ejtagle
on 19 Oct 2018
…as we now do for M112 in manage_heater…
#if ENABLED(EMERGENCY_PARSER)
if (emergency_parser.killed_by_M112) kill();
#endif
Can I also suggest that someone reorders things in the kill code so that it performs all of the safety critical things first (ideally doing the ones that are either most dangerous or possibly least likely to fail first), before calling any output code or playing a tune. That way if one of those "extra" functions hangs up the important work will have been completed already. So for instance calling the serial output function first seems like a bad idea.
 gloomyandy
on 19 Oct 2018
gloomyandy
on 19 Oct 2018
BTW, the updating of the UI should be done AFTER everything is turned off. There is an obvious example here.. Assume you are powering your heatbed thru a relay from a controllable power supply.
If the relay contacts melt together, then the printer should shutdown() turning off the main power supply
ejtagle
on 19 Oct 2018
performs all of the safety critical things first
Sure, although there's no reason to expect the machine to be in a meltdown just because kill() was called. The MCU, serial connection, etc. will all still be functioning under conditions like a min/maxtemp.
or playing a tune
We don't play any beeps at this time.
thinkyhead
on 19 Oct 2018
That feature was introduced because there are people with very powerful heatbeds, and if it takes too long to shutdown, the printer could catch fire and burn your house !
I was just going to reply to this, but @gloomyandy made the statement I was about to make. It sounds like the reason kill() is deadlocking the entire printer is that there is some lack of confidence in whether Marlin can successfully shutdown the heaters. This seems a bit worrisome, but if that is the concern, it seems like the recovery should be as follows:
- Shut off all heaters (or try to!)
- Set a flag to kill() the printer in idle and to disable resetting the watchdog timer.
- Idle loop displays the UI to the user
- And finally shuts off all heaters again (just in case) and suspends interrupts (just in case).
- If all else fails, the watchdog timer will kill the printer.
There is absolutely no reason to doubt that step 1 is sufficient to safeguard from accidents, but in case there are doubts, step 4 and 5 will take care of the issue.
marcio-ao
on 19 Oct 2018
the reason kill() is deadlocking the entire printer is that there is some lack of confidence in whether Marlin can successfully shutdown the heaters.
The reason for kill() is to lock the machine in a state where reset is required, for whatever reason.
thinkyhead
on 19 Oct 2018
and to disable resetting the watchdog timer.
Once the loop() is suspended the watchdog timer never gets reset.
This is why kill() itself resets the watchdog timer in an infinite loop.
thinkyhead
on 19 Oct 2018
The reason for kill() is to lock the machine in a state where reset is required, for whatever reason.
I didn't mean to offend anyone by mentioning there seemed to be a lack of confidence whether Marlin could shut off the heaters. But prior to your last commit, the code looked like this:
void kill(PGM_P lcd_msg) {
SERIAL_ERROR_START();
SERIAL_ERRORLNPGM(MSG_ERR_KILLED);
thermalManager.disable_all_heaters();
disable_all_steppers();
#if ENABLED(EXTENSIBLE_UI)
...
#endif
_delay_ms(600); // Wait a short time (allows messages to get out before shutting down.
cli(); // Stop interrupts
_delay_ms(250); //Wait to ensure all interrupts routines stopped
thermalManager.disable_all_heaters(); //turn off heaters again
...
while (1) {
#if ENABLED(USE_WATCHDOG)
watchdog_reset();
#endif
} // Wait for reset
}
The fact that thermalManager.disable_all_heaters() was done twice suggests there was some fear it wouldn't work the first time, or that some other ISR would turn the heaters on again.
Once the loop() is suspended the watchdog timer never gets reset.
Not true. If any code calls safe_delay, the watchdog timer gets reset. I am suggesting that safe_delay check whether the kill flag is set, and if it is, it will skip resetting the watchdog timer and calling manage_heaters, and basically just act as a regular delay. At some point, the idle function will check the kill flag and at this point it completes step 4 and halts the printer.
marcio-ao
on 19 Oct 2018
Serial comms may be working, but on some platforms it can block (USB serial port on Due and until a recent PR from @p3p on LPC1768) which creates the chance turning things off will be delayed.
gloomyandy
on 19 Oct 2018
Just my 2 cents:
-kill() is also called for endstops. And geared motors can also destroy a printer
-heatbed/hotend ... all of them require inmediate shutdown
-yes, there is obviously a lack of trust on Marlin being able to properly shutdown those elements. But from a security standpoint, it is justified in the sense that, for example, a corrupted pointer or corrupted stack can cause Marlin to be unable to shutdown those elements if trusting on the normal execution flow. That is why i do support the idea of @p3p to do all of these without any interrupts running, because otherwise you are adding an extra chance that elements will not be turned off.
-And, no, you can´t trust the watchdog to turn off motors/heaters. Watchdog does warranty CORE reset, but not peripheral resets - And once it is reset, the bootloader gains control and the bootloader DOES NOT turn off anything!...
ejtagle
on 19 Oct 2018
@ejtagle: This is turning out to be a much harder problem than I had ever thought it would be! I apologize to everyone for opening up this can of worms!
I'm going to go experiment with the millis() code you provided. Thank you for doing that.
marcio-ao
on 19 Oct 2018
@marcio-ao : Basically, once kill is called, you can´t count on anything to be in a "sane" state. Even SPI or USART could be screwed up.
What i´d do in your case is a very simple routine to just display a full screen image telling about the kill, and asking the user to turn off the printer....
ejtagle
on 19 Oct 2018
And, if you want to see the bootloader problem (please, don´t!!) , try to reprogram the Arduino while it is heating ... You will notice the heater remains turned on while programming...
_Please don´t do it, it is very dangerous!_ 👍
ejtagle
on 19 Oct 2018
The more I think about it the less I like trying to perform any sort of output from the kill function especially if that function can be called from an isr. If you are using USB serial output (on LPC1768 and probably any other chip with built in USB) then with interrupts turned off there is no way you are going to see the output, plus there is a chance that the buffers will get full and the output will block.
I don't like having special code in something as basic as delay/millis to handle this special case, for one it makes that code more complex and two the special case code will not get used very often so there is a good chance of a bug that does not get uncovered until the one time someone needs it to work.
As suggested above I think that perhaps we should add a method into the LCD interface that does not use delay etc. and that uses the simplest possible code to display a shutdown message (bitmap display on graphics devices, simple text on character LCDs), on devices with no display perhaps the same method can flash an LED or just do nothing. Even better if we can use that same code to display the startup splash screen so that it gets tested frequently.
gloomyandy
on 19 Oct 2018
@ejtagle: You're a genius! The safe_millis() code works perfectly! Check out this video:
https://devel.alephobjects.com/lulzbot/video/Color_LCD_Prototype_Demo/HeatingFailed.MOV
Thank you so much!
PS: It still reboots in the end, but that it because minkill() calls _delay_ms(), which in the HAL_DUE is just delay(). I bet if I implement _delay_ms() in terms of safe_millis() it will work.
marcio-ao
on 19 Oct 2018
@ejtagle: Basically, once kill is called, you can´t count on anything to be in a "sane" state. Even SPI or USART could be screwed up.
Why is this so? AFAIK, Marlin only calls kill() when it detects an unexpected value in an otherwise ordinary operation, like a mintemp, which is simply a temp reading out of the expected range. None of this has anything to do with memory corruption and is simply an invalid temperature reading. Unless we were using memory with parity bits, I really don't even know how Marlin would be able to detect memory corruption and attempt to recover from it. It seems like the assumption that kill() will get called when things are really FUBAR in memory is unrealistic.
marcio-ao
on 19 Oct 2018
@marcio-ao Marlin does not detect memory corruption, except by its symptoms. Granted. But as kill() could be called from nearly anywere of the codebase, yes, it can´t realiably count on anything to be working (as @gloomyandy and @p3p point out)
It has already happened that bad configurations cause trouble, for example, misconfiguring the active logic level that controls heaters, or incorrectly wiring motors...
Even logical errors on the firmware can cause trouble. The best approach is always to perform the safest possible turn off. Displaying text to the user is a "desirable" feature, just to let them know the cause, but not mandatory: For example, instead of doing that, we could just store in the EEPROM a flag with the cause of the kill, and on the next boot, display that cause to the user
ejtagle
on 19 Oct 2018
@marcio-ao , @thinkyhead ... minkill() should not be calling _ms_delay() .. It should be done using DELAY_US() ... As that macro does not depend on interrupts being enabled
Something along the lines
_ms_delay(650);
Should be replaced by:
for (int i=0; i<650; ++i) DELAY_US(1000);
Well one problem is that you have no idea how or when kill will be called in the future, so making assumptions is probably not a good idea and minimising the things that are needed to work for kill to be able to function is probably a good thing.
If kill can be called from an isr then there is a chance that things are not in a safe state to be reused. So for instance the LCD may have been in mid update with data being sent to it by software or hardware SPI, there is a good chance that if you try and write something else to the LCD then things will fail. There may be a way to reset the LCD and SPI etc. before you try and use it to display the emergency message, but you probably can't just use it.
@ejtagle I like the flag idea, but what if eeprom is not available? Is there anyway to use a RAM location and have it survive a reset? The bootloader tends to get in the way of things I think. For instance the LPC1768 does not handle Watchdog errors very well as by default it just restarts without displaying the reason for the restart.
gloomyandy
on 19 Oct 2018
The more I think about it the less I like trying to perform any sort of output from the kill function especially if that function can be called from an isr. If you are using USB serial output (on LPC1768 and probably any other chip with built in USB) then with interrupts turned off there is no way you are going to see the output, plus there is a chance that the buffers will get full and the output will block.
I don't like having special code in something as basic as delay/millis to handle this special case, for one it makes that code more complex and two the special case code will not get used very often so there is a good chance of a bug that does not get uncovered until the one time someone needs it to work.
As suggested above I think that perhaps we should add a method into the LCD interface that does not use delay etc. and that uses the simplest possible code to display a shutdown message (bitmap display on graphics devices, simple text on character LCDs), on devices with no display perhaps the same method can flash an LED or just do nothing. Even better if we can use that same code to display the startup splash screen so that it gets tested frequently.
@marcio-ao : Perhaps renaming to UI::delay() and UI:;millis() to signal they are intended to be used by the extensive UI only
ejtagle
on 19 Oct 2018
Well one problem is that you have no idea how or when kill will be called in the future, so making assumptions is probably not a good idea and minimising the things that are needed to work for kill to be able to function is probably a good thing.
If kill can be called from an isr then there is a chance that things are not in a safe state to be reused. So for instance the LCD may have been in mid update with data being sent to it by software or hardware SPI, there is a good chance that if you try and write something else to the LCD then things will fail. There may be a way to reset the LCD and SPI etc. before you try and use it to display the emergency message, but you probably can't just use it.
@ejtagle I like the flag idea, but what if eeprom is not available? Is there anyway to use a RAM location and have it survive a reset? The bootloader tends to get in the way of things I think. For instance the LPC1768 does not handle Watchdog errors very well as by default it just restarts without displaying the reason for the restart.
@gloomyandy : Most bootloaders do not erase internal RAM. not clear it to 0. Using an absolute address could work, if chosen wisely - And some processors have an RTC with non volatile SRAM that can be used for exactly this purpose!
(But if the power is turned off, and there is no backup battery, then there is no hope)
ejtagle
on 19 Oct 2018
So for instance the LCD may have been in mid update with data being sent to it by software or hardware SPI, there is a good chance that if you try and write something else to the LCD then things will fail.
I still agree with your earlier point that important things should be moved prior to the UI code running, to avoid the danger that it will cause a lockup. Under most circumstances, however, writing data to a display which isn't ready won't block the system, it simply will further corrupt the display or do nothing. There are only a few places in my UI code where I actually poll a busy flag and wait for the display to be ready. In that case, it would be smart to have a timeout, so having a functional millis() is important.
I like the flag idea, but what if eeprom is not available? Is there anyway to use a RAM location and have it survive a reset?
Not to be facetious, but I hear a lot of complicated things being proposed in order to keep kill() from having to do complicated things :)
marcio-ao
on 19 Oct 2018
I wasn't suggesting that the display will block, but rather answering your question about the state of the hardware and why you can't rely on the system when kill is called. Sure if you just call display functions most of the time they will work, but sometimes they won't. So long as you have got the printer into a safe state before you call things that you know may not work, maybe that is good enough?
As to the flag suggestion, the problem is that as pointed out above, when you call kill you really can't rely on anything. So how do you get things into a known state? One way is to have special code like the delay example above, then add code into the LCD to reset things, then do the same for the serial I/O etc. But that is getting more and more complex (and hard to test since it will hardly ever be used). Or we can reset the entire system. Marlin already does this in the case of a watchdog timeout, so perhaps it makes sense to explore that option.
gloomyandy
on 19 Oct 2018
So long as you have got the printer into a safe state before you call things that you know may not work, maybe that is good enough?
@gloomyandy: This is going to be my game plan, even though I know it isn't perfect. I know I'll never get it past our usability folks to have the printer simply hang without putting something up on the screen.
for (int i=0; i<650; ++i) DELAY_US(1000);
@ejtagle: This works. Made a PR with it for @thinkyhead to merge.
Thank you for your help with the millis() stuff, I never would have figured that out on my own.
marcio-ao
on 19 Oct 2018
The millis() stuff will only work on ARM devices. On AVR a different solution is needed, but probably along the same idea (polling the timer0...)
ejtagle
on 19 Oct 2018
On AVR a different solution is needed, but probably along the same idea (polling the timer0...)
Well, we aren't planning on releasing a printer with a touch panel on AVR, so I guess that is a problem for another day...
marcio-ao
on 19 Oct 2018
I am suggesting that
safe_delaycheck whether the kill flag is set, and if it is, it will skip resetting the watchdog timer
Just to make it clear, we want/need to reset the watchdog timer. It's important.
If we were to add a kill_flag and set that instead of calling kill directly, then we can breathe easy that kill will not be called from the temperature ISR, and then we just have to deal with minkill being potentially called from the watchdog ISR (in which case minkill could test for the kill_flag being false).
But anyway, I'll check out your PR and see what we've got…
thinkyhead
on 20 Oct 2018
@thinkyhead : That is why i proposed the following change:
-Do NOT modify safe_delay
-Do NOT touch kill() / minkill()
-Let´s have a special UI::delay() and UI::millis() that contains the special logic of the kill flag, this function meant to be called by EXTENSIBLE_UI implementations only
So, if there is no extensible UI, no changes or extra overhead
And, if there is an EXTENSIBLE_UI, then the implementation has something to use if they need a delay of some sort. The implementators of EXTENSIBLE_UI should be warned that the onPrinterKilled() function will be called with ISRs disabled and no UART/SPI service can be called.
And, of course, onPrinterKilled() should be called by Marlin after disabling heaters and motors
ejtagle
on 20 Oct 2018
Marlin is still full of assumptions to run on an AVR. There a reset is the perfect way to set all pins to inputs with no pullups. Also the boards (like RAMPS) do assume this.
If these assumptions are not true for other processors we have to find other concepts for them.
Don't blame Marlin for that. It was designed with AVRs in mind.
Marlin is constantly changing. Sadly our innovations sometimes have unrealized gamchanging side effects. When the kill() code was written sending over the serial was never interrupt based, and USB not on the screens, so pushing a message seemed to be relatively save.
For a while the display output, in kill(), had a temporary sei(). Don't know why or when it vanished.
What we fear most is a permanently on, uncontrolled heater. That could happen due to a sensor error (MIN/MAX-IEMP_ERROR - cables broken or shorted) or a lost connection between heater and sensor (one of them not in the heater block ) what we try to detect with THERMAL_PROTECTION. For this cases, on AVR a reset or simply switching of the heater is adequate.
But the most dangerous thing is a defect MOSFET switching on the heater permanently. Here only a second switch can help. A working power supply switch with PS_DEFAULT_OFF and/or the suicide functionality are the last remaining rescue. (Or thermal fuses - hardware protection is always better than software.)
The machine may destroy itselves, but we really want to avoid a fire.
The machine may fail silently, but we really want to avoid a fire.
The usability team may be unsatisfied, as long the security team is.
A kill() should be a rare event! If that occurs we either have a hardware defect or a misconfigured system. The second is why we, the developers, do see kill() that often. A user should ideally never experience a kill() - except there is a hardware defect. (On our 5 production printers we haven't seen a kill for the last 3 years - on a highly customized 4 year old, never updated Marlin - they just work since we preventively replace the moving cables once a year. In average only one is constantly printing - but we occasionally have peaks where we wanted to have more of them - like today. )
AnHardt
on 20 Oct 2018
The second is why we, the developers, do see kill() that often.
Kills are common on our printers because we sell accessory toolheads. You will often get a MINTEMP error when you swap out toolheads with the printer powered on. In fact, when don't see a MINTEMP, we get concerned.
marcio-ao
on 22 Oct 2018
The implementators of EXTENSIBLE_UI should be warned that the onPrinterKilled() function will be called with ISRs disabled and no UART/SPI service can be called.
@ejtagle: Why the restriction on SPI? I am using SPI and there seems to be no problems (aside from perhaps the possibility that it wouldn't work if the ISR was triggered when another chip select was high. So far, this has not happened).
It's important to note that any external display is either going to be UART or SPI... there are no other alternatives (that I know of).
marcio-ao
on 22 Oct 2018
When the way to change the toolheads includes opening the sensor cables what causes the MINTEMP_ERROR what causes the kill, then changing the kill() is wrong.
In that case, opening the cables is not an error but a planned action. Than disabling the error for that time would be better than waiting for the error and changing the consequences.
AnHardt
on 22 Oct 2018
I'm quite sure we have I²C-displays.
AnHardt
on 22 Oct 2018
Let´s have a special UI::delay() and UI::millis() that contains the special logic of the kill flag, this function meant to be called by EXTENSIBLE_UI implementations only
@ejtagle: Please review my PR #12188 and let me know if this is what you have in mind. One possible alternative might be to move the implementation of the delay routine to the HAL_DUE, rather than having it in "ui_api.cpp"
marcio-ao
on 22 Oct 2018
Let´s have a special UI::delay() and UI::millis() that contains the special logic of the kill flag, this function meant to be called by EXTENSIBLE_UI implementations only
@ejtagle: Please review my PR #12188 and let me know if this is what you have in mind. One possible alternative might be to move the implementation of the delay routine to the HAL_DUE, rather than having it in "ui_api.cpp"
That was the idea. Maybe in the future, once the AVR case is completed, we could move it into shared
The implementators of EXTENSIBLE_UI should be warned that the onPrinterKilled() function will be called with ISRs disabled and no UART/SPI service can be called.
@ejtagle: Why the restriction on SPI? I am using SPI and there seems to be no problems (aside from perhaps the possibility that it wouldn't work if the ISR was triggered when another chip select was high. So far, this has not happened).
It's important to note that any external display is either going to be UART or SPI... there are no other alternatives (that I know of).
I'm quite sure we have I²C-displays.
The problem is that SPI/I2C/UART routines could depend on TX interrupts to be enabled. Right now, the only one that depends on that is the UART/(USB UART)
For example, on DUE it would be a BIG WIN to reimplement the hardware SPI using DMA and interrupts: We could speed up transfers quite a bit, specially for displays and SD cards.
I am right now toying with the idea of connecting a 320x240 tff that uses a ILI934x via SPI to the DUE (and ALSO to the AVR)... I have already written a microGUI framework that is more than suitable for that (30 bytes of SRAM consumption) ... and using DMA/ints can improve the throughput and pixel fill rates quite a bit!
So you get an idea of what it looks like...
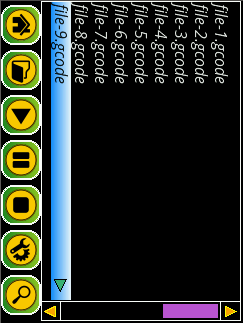
This is the file selection screen.
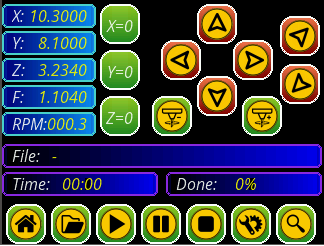
And this is the main screen (in this case is for a CNC i am working ATM)
The custom tft driver i wrote supports lines, circles, triangles, unfilled, solid-filled or gradient filled, png-like compressed (typically outperforms PNG) images with alpha channel that are decompressed in realtime, smoothed fonts.
The microGui supports the concept of buttons, checkboxes, radiobuttons, panels, labels, imagebuttons, etc, etc. It looks very nice.
There is no dynamic memory use, and the cost in flash is 60kbytes (including graphics) and 100 bytes of SRAM (or way less) to decompress images, as configuration is all stored in FLASH. So AVR is also able to run it.
DUE dma can be used to both solid fill and gradient fill areas in the background (but right now, without using it, it already works in realtime and you are unable to see the screen forming)
ejtagle
on 22 Oct 2018
@ejtagle: Very cool!
marcio-ao
on 22 Oct 2018
@marcio-ao This is still under development. Not all design decisions are taken yet. I want it to be easy to use, not depend on screen resolution and do some autolayout (all that is already done), and the configuration should all be stored in FLASH in tables, and not require to write code.
Right now i am thinking on how to write a more elaborate listbox, that instead of displaying text (as the one that is shown) is able to contain other controls as widgets... All that without consuming SRAM... I am thinking on how to implement that...
For example, the code that creates the filepicker (but not the toolbar below it) right now is:
Code Sample
#include "ui_filepicker.h"
#include "simplelist.h"
#include "panel.h"
#include "ui_fonts.h"
#include "ui_commands.h"
static const SimpleList::Cfg lItems = {
{
uicmdChooseFile, // ID
{{0, 0}, {320, 200}}, // Rect
Color::BLACK // Background color
},
fntOpenSansItalic16, // Font to use
true, // Has selection arrow
Color::WHITE, // border color
Color::WHITE, // Unselected text color
Color::DODGERBLUE, // Selected background 1
Color::ALICEBLUE, // Selected background 2
Color::BLACK, // Selected text
Color::ORANGE, // Scroll button color
Color::YELLOW, // Scroll button border color
Color::MEDIUMORCHID, // Thumb color
Color::MEDIUMSEAGREEN, // Selection arrow color
Color::BLACK, // Selection arrow border color
20 // Item height
};
static const Widget::Cfg* const gFilePickerChilds [] = {
&lItems
};
const Panel::Cfg pFilePickerPane = {
{
{
{{0, 0}, {320, 200}}, // Rect
Color::BLACK // Background color
},
gFilePickerChilds
}
};
I want it to be easy to use, not depend on screen resolution and do some autolayout (all that is already done)
In my UI, I made my stuff be resolution independent by using a grid based system and a couple macros, so hopefully all the adjustments for display resolution are all done at compile time and contribute nothing to code size. However, I don't have any auto-layout capabilities, so I need to manually write both landscape and portrait versions of each screen.
marcio-ao
on 22 Oct 2018
I am exploiting C++11 features and constexpr constructors, so i don`t need macros. Once it is done, i'll post it to github ... ;)
Coordinates in the current implementation can be relative to container, relative to previous widget, and expressed in pixels or in percentage of screen width.
For example, this is the action bar (buttons Folder, play, pause,, stop, configuration, view)
Code Sample
///////
#include "ui_commands.h"
#include "ui_commandbar.h"
#include "simplebutton.h"
#include "panel.h"
#define PROGMEM
#include "inspect-32.h"
#include "config-32.h"
#include "stop-32.h"
#include "pause-32.h"
#include "play-32.h"
#include "open-32.h"
#include "home-32.h"
static const SimpleButton::Cfg bHome = {
{
uicmdHome, // ID
{{4, 0}, {40, 40}}, // Rect
Color::BLACK // Background color
},
Color::WHITE, // Border color
Color::FORESTGREEN, // Face1 color
Color::YELLOWGREEN, // Face2 color
Color::MEDIUMORCHID, // Pressed Border color
Color::CRIMSON, // Pressed face1 color
Color::DARKRED, // Pressed face2 color
12U, // Corner Radius
home_bmp // Bitmap to display
};
static const SimpleButton::Cfg bOpen = {
{
uicmdOpen, // ID
{
{45, 0}, {40, 40},
Widget::ckRelPrev, Widget::ckRelPrev
}, // Rect
Color::BLACK // Background color
},
Color::WHITE, // Border color
Color::FORESTGREEN, // Face1 color
Color::YELLOWGREEN, // Face2 color
Color::MEDIUMORCHID, // Pressed Border color
Color::CRIMSON, // Pressed face1 color
Color::DARKRED, // Pressed face2 color
12U, // Corner Radius
open_bmp // Bitmap to display
};
static const SimpleButton::Cfg bPlay = {
{
uicmdPlay, // ID
{
{45, 0}, {40, 40},
Widget::ckRelPrev, Widget::ckRelPrev
}, // Rect
Color::BLACK // Background color
},
Color::WHITE, // Border color
Color::FORESTGREEN, // Face1 color
Color::YELLOWGREEN, // Face2 color
Color::MEDIUMORCHID, // Pressed Border color
Color::CRIMSON, // Pressed face1 color
Color::DARKRED, // Pressed face2 color
12U, // Corner Radius
play_bmp // Bitmap to display
};
static const SimpleButton::Cfg bPause = {
{
uicmdPause, // ID
{
{45, 0}, {40, 40},
Widget::ckRelPrev, Widget::ckRelPrev
}, // Rect
Color::BLACK // Background color
},
Color::WHITE, // Border color
Color::FORESTGREEN, // Face1 color
Color::YELLOWGREEN, // Face2 color
Color::MEDIUMORCHID, // Pressed Border color
Color::CRIMSON, // Pressed face1 color
Color::DARKRED, // Pressed face2 color
12U, // Corner Radius
pause_bmp // Bitmap to display
};
static const SimpleButton::Cfg bStop = {
{
uicmdStop, // ID
{
{45, 0}, {40, 40},
Widget::ckRelPrev, Widget::ckRelPrev
}, // Rect
Color::BLACK // Background color
},
Color::WHITE, // Border color
Color::FORESTGREEN, // Face1 color
Color::YELLOWGREEN, // Face2 color
Color::MEDIUMORCHID, // Pressed Border color
Color::CRIMSON, // Pressed face1 color
Color::DARKRED, // Pressed face2 color
12U, // Corner Radius
stop_bmp // Bitmap to display
};
static const SimpleButton::Cfg bConfig = {
{
uicmdConfig, // ID
{
{45, 0}, {40, 40},
Widget::ckRelPrev, Widget::ckRelPrev
}, // Rect
Color::BLACK // Background color
},
Color::WHITE, // Border color
Color::FORESTGREEN, // Face1 color
Color::YELLOWGREEN, // Face2 color
Color::MEDIUMORCHID, // Pressed Border color
Color::CRIMSON, // Pressed face1 color
Color::DARKRED, // Pressed face2 color
12U, // Corner Radius
config_bmp // Bitmap to display
};
static const SimpleButton::Cfg bInspect = {
{
uicmdInspect, // ID
{
{45, 0}, {40, 40},
Widget::ckRelPrev, Widget::ckRelPrev
}, // Rect
Color::BLACK // Background color
},
Color::WHITE, // Border color
Color::FORESTGREEN, // Face1 color
Color::YELLOWGREEN, // Face2 color
Color::MEDIUMORCHID, // Pressed Border color
Color::CRIMSON, // Pressed face1 color
Color::DARKRED, // Pressed face2 color
12U, // Corner Radius
inspect_bmp // Bitmap to display
};
static const Widget::Cfg* const gCmdBarChilds [] = {
&bHome,
&bOpen,
&bPlay,
&bPause,
&bStop,
&bConfig,
&bInspect
};
const Panel::Cfg pCmdBar = {
{
{
{{0, 200}, {320, 40}}, // Rect
Color::BLACK, // Background color
},
gCmdBarChilds
}
};
The first Button (bHome) is in coordinates relatives to the container (pCmdBar), and the next buttons are in coordinates relatives to the previous control (ckRelPrev = coordinate kind relative to previous). You can specify for both X and Y different modes.
ejtagle
on 22 Oct 2018
This issue has been automatically locked since there has not been any recent activity after it was closed. Please open a new issue for related bugs.
![github-actions[bot] picture](https://avatars2.githubusercontent.com/in/15368?v=4&s=40) github-actions[bot]
on 6 Aug 2020
github-actions[bot]
on 6 Aug 2020
Related issues
 StefanBruens
·
4Comments
StefanBruens
·
4Comments
 ShadowOfTheDamn
·
3Comments
ShadowOfTheDamn
·
3Comments
 heming3501
·
4Comments
heming3501
·
4Comments
 Tamonir
·
3Comments
Tamonir
·
3Comments
 Bobsta6
·
3Comments
Bobsta6
·
3Comments
Most helpful comment
Marlin is still full of assumptions to run on an AVR. There a reset is the perfect way to set all pins to inputs with no pullups. Also the boards (like RAMPS) do assume this.
If these assumptions are not true for other processors we have to find other concepts for them.
Don't blame Marlin for that. It was designed with AVRs in mind.
Marlin is constantly changing. Sadly our innovations sometimes have unrealized gamchanging side effects. When the kill() code was written sending over the serial was never interrupt based, and USB not on the screens, so pushing a message seemed to be relatively save.
For a while the display output, in kill(), had a temporary sei(). Don't know why or when it vanished.
What we fear most is a permanently on, uncontrolled heater. That could happen due to a sensor error (MIN/MAX-IEMP_ERROR - cables broken or shorted) or a lost connection between heater and sensor (one of them not in the heater block ) what we try to detect with THERMAL_PROTECTION. For this cases, on AVR a reset or simply switching of the heater is adequate.
But the most dangerous thing is a defect MOSFET switching on the heater permanently. Here only a second switch can help. A working power supply switch with PS_DEFAULT_OFF and/or the suicide functionality are the last remaining rescue. (Or thermal fuses - hardware protection is always better than software.)
The machine may destroy itselves, but we really want to avoid a fire.
The machine may fail silently, but we really want to avoid a fire.
The usability team may be unsatisfied, as long the security team is.
A kill() should be a rare event! If that occurs we either have a hardware defect or a misconfigured system. The second is why we, the developers, do see kill() that often. A user should ideally never experience a kill() - except there is a hardware defect. (On our 5 production printers we haven't seen a kill for the last 3 years - on a highly customized 4 year old, never updated Marlin - they just work since we preventively replace the moving cables once a year. In average only one is constantly printing - but we occasionally have peaks where we wanted to have more of them - like today. )