Machinelearningnotebooks: Explain the purpose of providing a name for PipelineData
It is not clear from the documentation why PipelineData needs to have a name. Can it be blank? Does it need to be unique? The name seems to be used as part of blob storage path under azureml/[run_id]/. So I believe it is ok to use the same name for two independent runs but these are my speculations. It would be much more clear if the doc explained the significance of the name.
Document Details
⚠ Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.
- ID: 76780996-4443-4aff-18c0-65195afcab00
- Version Independent ID: 6032c190-bb76-7050-89fa-30476b36b43f
- Content: azureml.pipeline.core.PipelineData class - Azure Machine Learning Python
- Content Source: AzureML-Docset/stable/docs-ref-autogen/azureml-pipeline-core/azureml.pipeline.core.PipelineData.yml
- Service: machine-learning
- Sub-service: core
- GitHub Login: @j-martens
- Microsoft Alias: jmartens
 ryotatomioka
ryotatomioka
All 7 comments
@ryotatomioka as mentioned in the document, name represents the name of the PipelineData object, which can contain only letters, digits, and underscores. Name is required.
 GiftA-MSFT
on 22 May 2020
GiftA-MSFT
on 22 May 2020
Thank you @GiftA-MSFT but the document does not explain __WHY__ a user needs to specify a name.
If you can think from a user's perspective, is there __ANY__ benefit for a user in giving PipelineData a name?
What happens if a user gives the same name to more than one PipelineData objects?
ryotatomioka
on 24 May 2020
@ryotatomioka name is used as the output name in one step (unless 'output name' is provided) and as input of one or more subsequent steps.
GiftA-MSFT
on 26 May 2020
PipelineData names are used to identify the outputs of a step. After a pipeline run has completed, you can use the step name with an output name to access a particular output. The names should be unique within a single step in a pipeline.
For example:
Download Outputs
We can download the output of any step to our local machine using the SDK.
In [ ]:
# Retrieve the step runs by name 'train.py'
train_step = pipeline_run1.find_step_run('train.py')
if train_step:
train_step_obj = train_step[0] # since we have only one step by name 'train.py'
train_step_obj.get_output_data('processed_data1').download("./outputs") # download the output to current directory
 alexkalita
on 27 May 2020
alexkalita
on 27 May 2020
@alexkalita thanks for your input.
@ryotatomioka will now proceed to close this thread. Thanks.
GiftA-MSFT
on 27 May 2020
Thanks @alexkalita for pointing me to the example.
ryotatomioka
on 4 Jun 2020
@ryotatomioka totally understand where you are coming from. Managing the variable name that represents the PipelineData that also has its own name property can get confusing. I've had multi-hour "bugs" where it turned out that I was referencing the variable name instead of the name property.
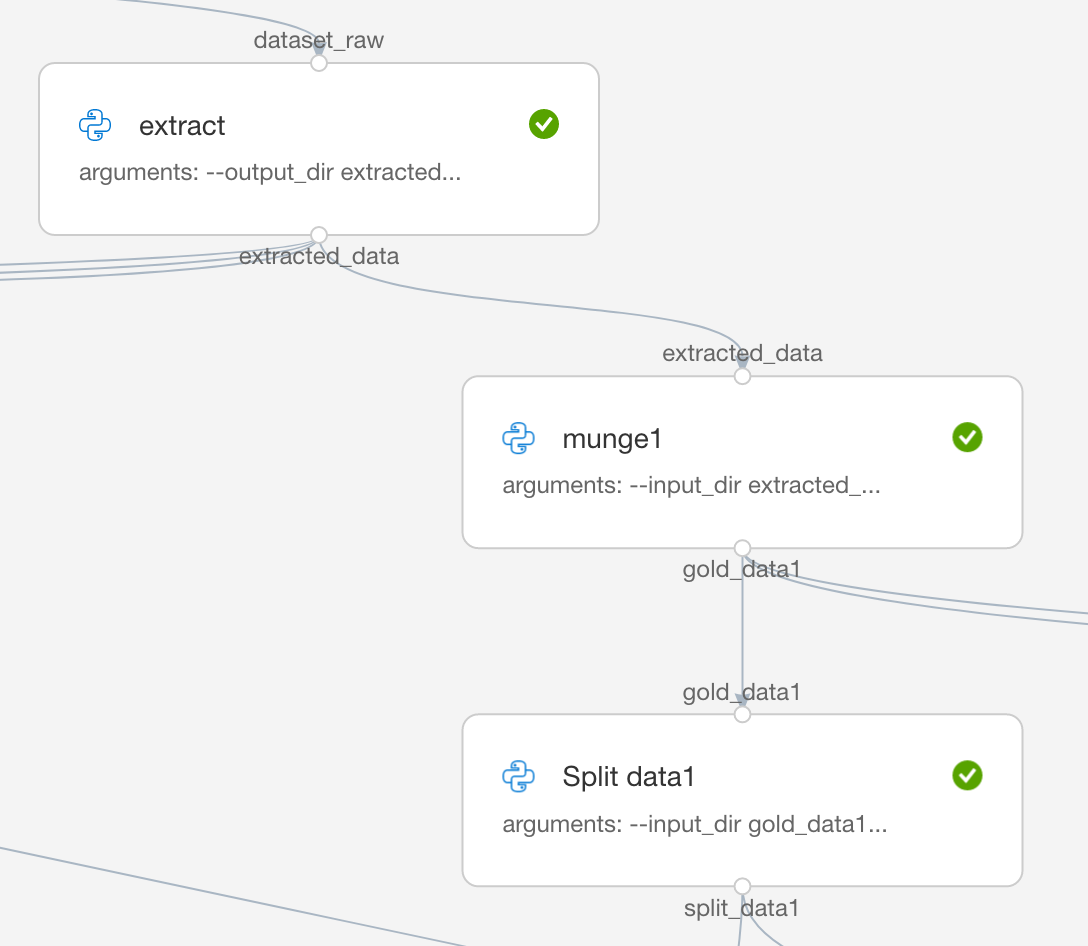
also FWIW that the name is what is displayed in the UI of the Pipeline DAG. In the image below, extracted_data and gold_data1 are the names of PipelineDatas in my pipeline.
 swanderz
on 9 Jun 2020
swanderz
on 9 Jun 2020
Related issues
 jarandaf
·
4Comments
jarandaf
·
4Comments
 nswitanek
·
4Comments
nswitanek
·
4Comments
 ahyerman
·
3Comments
swanderz
·
5Comments
ahyerman
·
3Comments
swanderz
·
5Comments
 BillmanH
·
5Comments
BillmanH
·
5Comments
Most helpful comment
PipelineData names are used to identify the outputs of a step. After a pipeline run has completed, you can use the step name with an output name to access a particular output. The names should be unique within a single step in a pipeline.
For example:
https://github.com/Azure/MachineLearningNotebooks/blob/master/how-to-use-azureml/machine-learning-pipelines/intro-to-pipelines/aml-pipelines-with-data-dependency-steps.ipynb