Machinelearningnotebooks: model.fit(X_train, y_train) in AutoML model yields different predictions than expected.
TLDR: Any idea what the difference between the AutoML model .fit and the conventional modle.fit and why they might be different? Can this kind of analysis be done in AutoML?
I was working on some model validation of AutoML and was using a function to test model resiliency of a previously trained model in AutoML. And I found that I got wildly different results when using model.predict(x_test) as opposed to using first model.fit(X_train, y_train) and then model.predict(x_test)
So using model.predict(x_test) with the model just as it is when you download it from the source.
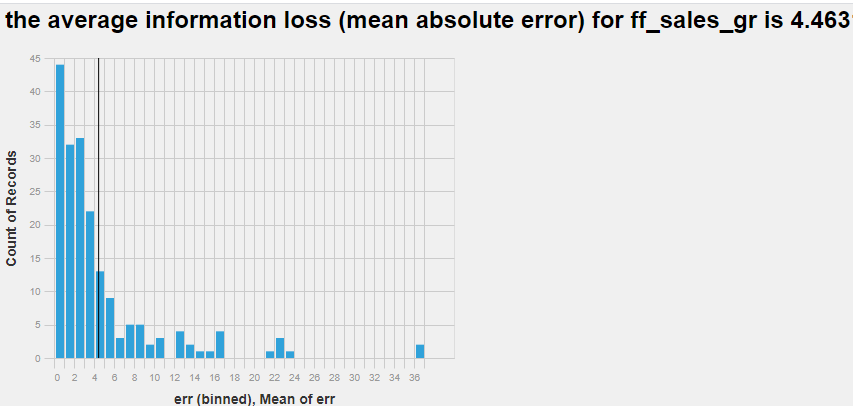
However if you "refit" it after downloading it with the same dataset. Meaning that you first model.fit(X_train, y_train) and then model.predict(x_test).

This is using the same data as was originally used to train the model.
If you do this with sklearn library using a local model this works fine:
def linear_split_and_test(i, testing_size=0.2):
random_state = i
X_train, X_test, y_train, y_test = train_test_split(
df[feature_cols], df[target], test_size=testing_size, random_state=random_state
)
reg = LinearRegression().fit(X_train, y_train)
pred = reg.predict(X_test)
loss = abs(pred - y_test)
return loss.mean()
model_iterations = pd.DataFrame(
[linear_split_and_test(i) for i in range(300)], columns=["loss"]
)
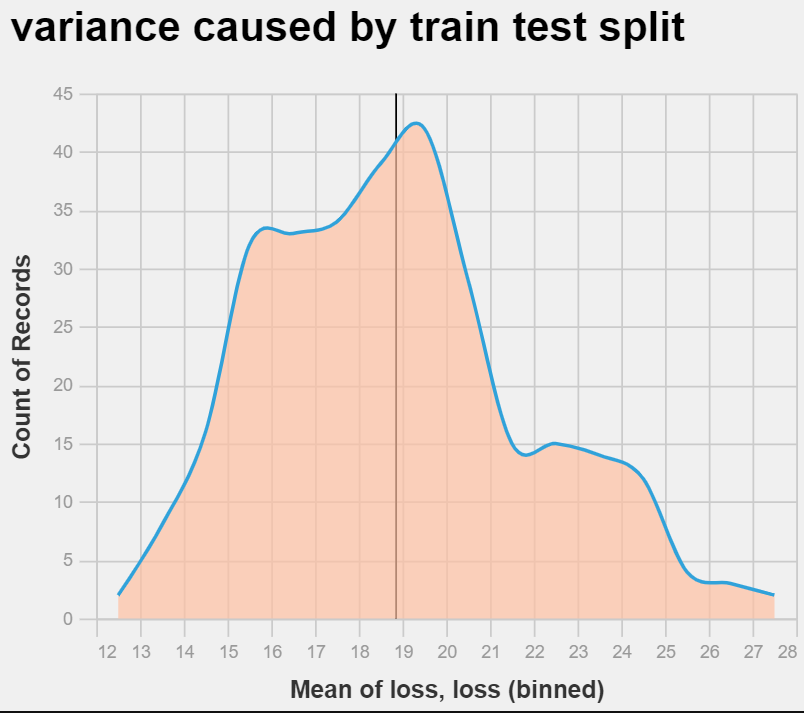
This is used to demonstrate the extent to which random sampling affects the output model. However the way it works in AutoML doesn't seem to work. The AutoML model .fit must work in some other way because it wildly skews the predicted results.
Any idea what the difference between the AutoML model .fit and the conventional modle.fit and why they might be different? Can this kind of analysis be done in AutoML?
 BillmanH
BillmanH
All 6 comments
@BillmanH Thanks for the feedback. We are investigating the issue and will update you shortly.
 ram-msft
on 17 Apr 2020
ram-msft
on 17 Apr 2020
@rtanase can you pls take a look at this one?
 swatig007
on 31 Aug 2020
swatig007
on 31 Aug 2020
@BillmanH , was this experiment particular to 1 particular AutoML model, or was it happening for multiple ones? I'm trying to understand whether there is some implementation specific issue, because in general the models that we train use the same .fit() API calls you were doing after training.
Were there any sample weights provided during training?
What kind of validation mechanism was used for AutoML training? (CV / Train Validation split)
Also tagging @anupsms for awareness.
 rtanase
on 1 Sep 2020
rtanase
on 1 Sep 2020
Yea It'll take me some time to repro an example that I can show you. At some point I'll recreate this with the iris dataset so that you can review.
- no sample weights that I'm aware of, unless automl applied them.
- the train test split was the standard sklearn function.
It's been a while since I've looked into this so I'm not even sure it's still valid in the latest sdk.
BillmanH
on 1 Sep 2020
I'm going to close this out as I did this in an older version of the SDK. If I repro the issue in a new version I'll repost the issue.
BillmanH
on 1 Sep 2020
@BillmanH if you have class imbalance in your dataset, AutoML will apply weights to lower the impact of imbalance. Is the current dataset imbalanced? The above charts suggest that AutoML's trained model (without refitting) is giving better accuracy. That has me think that one possible reason could be data imbalance in this data. When you fit it outside without class imbalance treatment that will likely give different results.
Also other possible reasons such as CV as mentioned by @rtanase will need to be examined.
 anupsms
on 1 Sep 2020
anupsms
on 1 Sep 2020
Related issues
 tkawchak
·
5Comments
tkawchak
·
5Comments
 jarandaf
·
4Comments
BillmanH
·
5Comments
jarandaf
·
4Comments
BillmanH
·
5Comments
 vineetgarhewal
·
3Comments
vineetgarhewal
·
3Comments
 AakanchJoshi
·
4Comments
AakanchJoshi
·
4Comments