Machinelearningnotebooks: BUG: HyperDriveStep's allow_reuse param does not work.
I made a reproducible example in this branch of a fork of this repo. This is a big time suck for our team as the majority of our pipelines use HyperDriveStep and we always have downstream steps from HyperDrive.
https://github.com/swanderz/MachineLearningNotebooks/blob/hyperdrive_allow_reuse/how-to-use-azureml/machine-learning-pipelines/intro-to-pipelines/aml-pipelines-parameter-tuning-with-hyperdrive.ipynb
 swanderz
swanderz
All 28 comments
@swanderz I see that you are copying training_files to script_folder, at cell
"Copy the training files into the script folder" which would be changing the hash of the source_directory and preventing the reuse. Are you running that everytime?
 purnesh42H
on 21 Jan 2020
purnesh42H
on 21 Jan 2020
@purnesh42H thanks for jumping on to help out! The copy script magic was just part of the minimum viable reproducible example I used. Here's the steps to reproduce:
- Run the whole notebook through
pipeline = Pipeline(workspace=ws, steps=[best_run_step])
pipeline_run = exp.submit(pipeline)
pipeline_run.wait_for_completion()
- Submit the pipeline again, with the above cells, changing nothing else.
HyperDriveStepwill run again, ignoringallow_reuse.
I'm interested to see what you get on your side!
swanderz
on 21 Jan 2020
@swanderz for some of the services such as HD or AutoML, they possibly produce similar output with same config but not exactly same afaik.
I will confirm with HD team and let you know.
 sonnypark
on 21 Jan 2020
sonnypark
on 21 Jan 2020
actually regardless of HD produce same output or not allow_reuse needs to skip HD runs so that user can control it. Will check why it didn't work.
sonnypark
on 21 Jan 2020
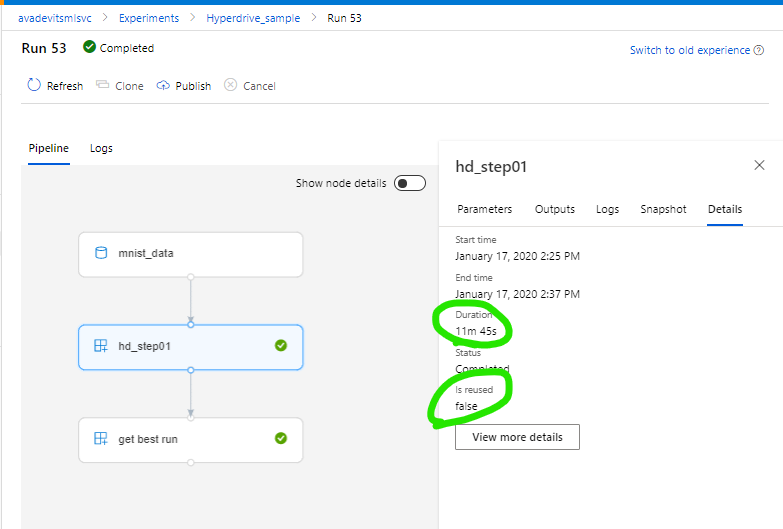
@sonnypark I appreciate you also helping me get answers. Can you please run the reprex and see what you get? When I do it, the stdout says something along the lines of hd_step01 will run and generate new outputs and I wait ~12 minutes for the step to complete, which its a lot longer than I would expect if the step is being reused.
swanderz
on 21 Jan 2020
Yes "hd_step01 will run and generate new outputs" is what we get when the step is not reused. Will try to repro.
sonnypark
on 21 Jan 2020
synced with @clmccart 95% chance this is related to #734.
swanderz
on 22 Jan 2020
734 is unrelated. In the case of hyperdrive, there is a change in hyperdrive config setting which is preventing the reuse
purnesh42H
on 23 Jan 2020
Any update on this?
 nemasobhani
on 7 Feb 2020
nemasobhani
on 7 Feb 2020
Fix has been checked in and will be available on the next release (which will be next week).
sonnypark
on 11 Feb 2020
@sonnypark good to hear. in the next release, will the changes in the experimental branch also be included? I'd like to have this issue and #771 fixed in the same release.
swanderz
on 11 Feb 2020
the experimental branch?
sonnypark
on 11 Feb 2020
I realized that Experimental release is the different name of Release cut.
Yes, the fix has been added to the latest release cut yesterday.
AzureML SDK Experimental Release Candidate is 1.1.0a1.dev0
And #771 fix should be in the release too.
sonnypark
on 11 Feb 2020
@sonnypark @rastala @purnesh42H @sanpil @nemasobhani
remember this bug? it's back....
here's the reprex
here are the package versions I'm using.
azureml-automl-core 1.1.5.1
azureml-contrib-notebook 1.1.5.1
azureml-core 1.1.5.4
azureml-dataprep 1.3.2
azureml-dataprep-native 14.1.0
azureml-interpret 1.1.5
azureml-pipeline 1.1.5
azureml-pipeline-core 1.1.5
azureml-pipeline-steps 1.1.5
azureml-sdk 1.1.5
azureml-telemetry 1.1.5.3
azureml-train 1.1.5
azureml-train-automl-client 1.1.5.1
azureml-train-core 1.1.5
azureml-train-restclients-hyperdrive 1.1.5
azureml-widgets 1.1.5

swanderz
on 20 Mar 2020
@swanderz I can see 'finished' run on the link you posted with new step created without reusing. But I guess you already ran the same notebook before with no changes.
Any changes on your packages from the ones which was able to reuse?
Oh I found that you ran the same job twice in the same notebook!
sonnypark
on 21 Mar 2020
Yeah to prove the bug. I submit the run twice. In the 2nd PipelineRun, we should see that the HyperDriveStep is not re-run... but we don't.
I want to say that the bug does not happen in 1.1.0a1.dev0, but does happen in 1.1.5.1
swanderz
on 21 Mar 2020
looks strange to me. It looks the second step is reused:
Created step get best run [31c67e94][a9842d81-7995-43c1-bb55-df20aa92e1b0], (This step is eligible to reuse a previous run's output)
Created step hd_step01 [54aa5211][a10bf668-d90f-44a4-9524-8759d419aa95], (This step will run and generate new outputs)
@swanderz did you actually could see the second run took same amount of time to run the job?
sonnypark
on 21 Mar 2020
I was able to reuse running the published HyperDriveStep notebook. You can check the run was really reused in portal:

sonnypark
on 21 Mar 2020
@sonnypark I appreciate you helping out again. Are you 100% that you have the same environment as me? Can you run pip list | grep 'azureml' and share the results? It is very frustrating that I can't help you to reproduce the error on your end. In our workflows, HyperDriveStep is sporadically reused. @sanpil @yanrez what can I do to determine if a step will be re-used beyond the console stdout and the portal info?
All the PipelineRuns
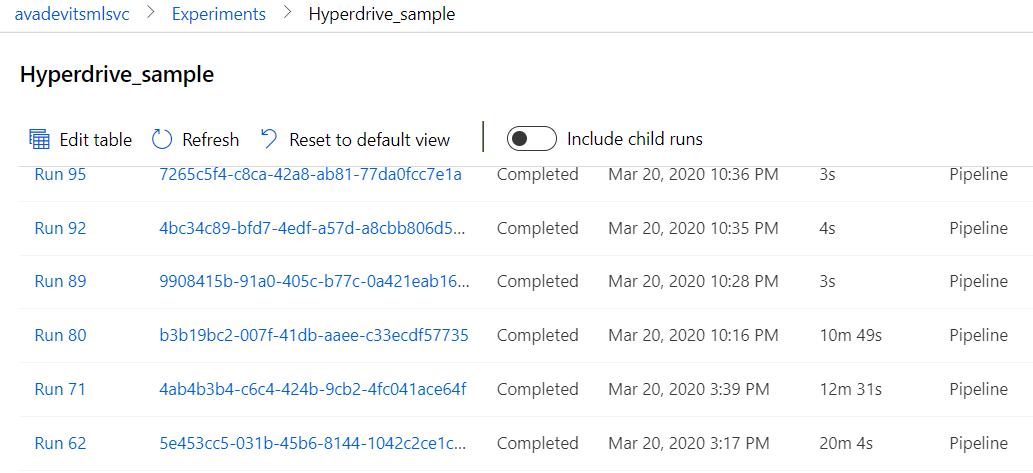
All HyperdriveStepRuns
Here's the StepRuns that corresponds to past 3 HyperDriveStep's that have run.

1st PipelineRun 62
this is the first time i ran the pipeline in two months.
note that for hd_step01:
- duration is 9m 15s
- "Reuse" is "No"

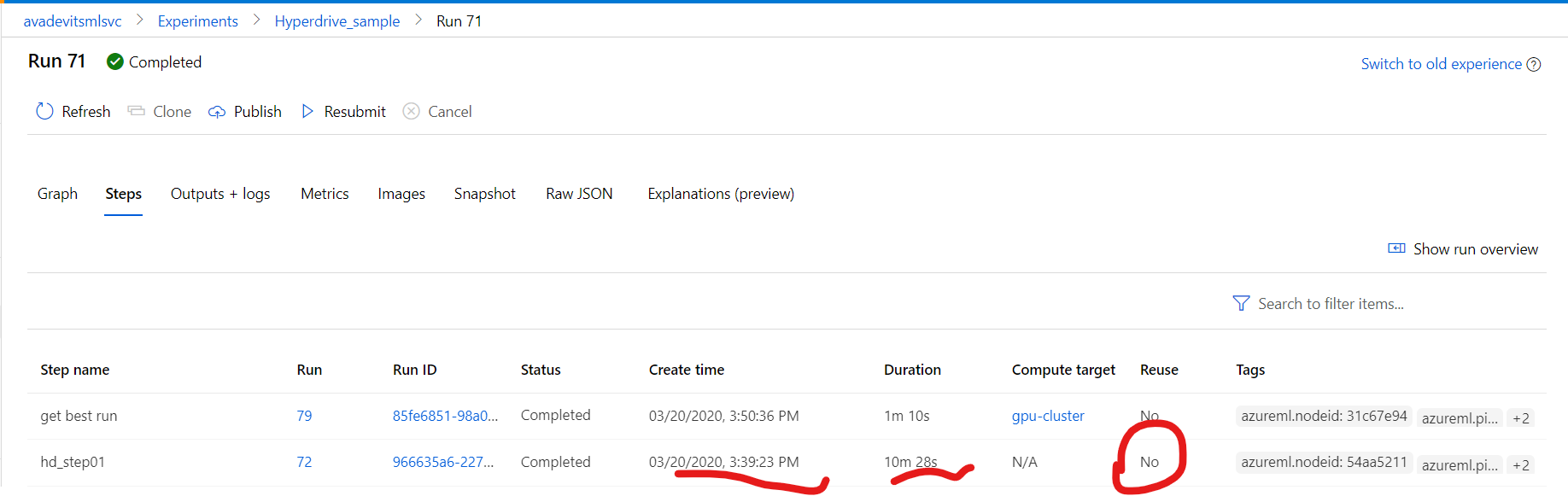
2nd PipelineRun 71
This is a run i submitted immediately after the first. I'm 97% sure I didn't change anything, just submitted again. Note:
- duration is 10m 28s
- "Reuse" is again "No"
3rd PipelineRun 80 (6 hours later)
I submitted this after seeing @sonnypark 's reply. Still didn't re-use... Strange. Note:
- duration is 8m 57s
- "Reuse" is again "No"

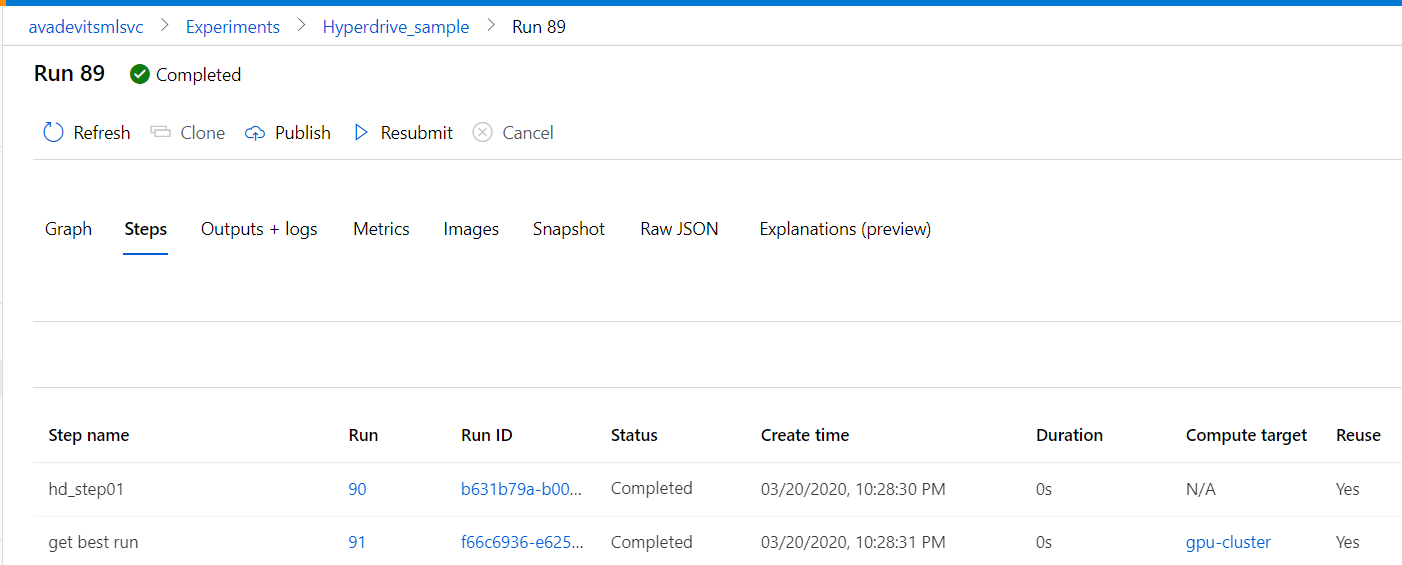
4th PipelineRun 89
Now it's working?? Note:
- duration is 0s
- "Reuse" is finally "Yes"
swanderz
on 23 Mar 2020
Considering you were able to reuse on the 4th run, I suspect either
- backend service ended up rerunning even with the same fingerprint for the module hash calculation or
- There were some unnoticed changed on 2/3rd run such as path or contents of files.
I can take a look at the backend side to see any possible reasons for such. Is there any possibility on your side for such changes you didn't noticed?
sonnypark
on 23 Mar 2020
@sonnypark to my knowledge, nothing changed. Though this could an example of me fundamentally misunderstanding how allow_reuse works and what's entailed. One idea is that I made a Git commit on a file that has nothing to do with the step... would that trigger a new run?
What would help me to debug is:
- a list of every factor that goes into whether the step will be re-used, and
- a way for me to do the module hashing locally so I can tell what verify if the step will be reused or not before I submit my two hour pipelines.
swanderz
on 23 Mar 2020
I think git commit can be a potential change can lead to different fingerprint in that any changes on the source_directory might result in different fingerprint. Since you were able to reuse on 4th run I don't think it is python package related.
Afaik, any changes on source_dir including file content changes, path, file name can result in different fingerprint.
sonnypark
on 23 Mar 2020
I need help manually verifying:
- are the shapshots/hashes unique from run to run?
- if so, what is causing the snapshots/hashes to be different? I can't think of anything that's different.
swanderz
on 23 Mar 2020
Working with Sonny, we're narrowed things down to the following testable hypotheses.
Does allow_reuse work for HyperdriveStep if:
- I re-submit the exact same pipeline object, after the first
PipelineRuncompletes? - Re-create the pipeline object with line below, then submit again?
pipeline = Pipeline(workspace=ws, steps=[best_run_step]) - restart my kernel then re-run the notebook?
To test these hypotheses:
- clone my fork of MachineLearningNotebooks (I've directly committed the necessary scripts and data)
- Ensure the data is in default datastore with the
'mnist'prefix (if not follow the original version of the notebook to do so.) - Ensure you environment matches
- add your own
config.json - Run the entire notebook (Run->"Run All Cells") to test hypotheses 1&2.
- Kernel->Restart Kernel and Run All Cells to test hypothesis 3.
i've updated the reproducible example to ensure that within the notebook no changes are being made to the scripts nor the underlying data.
Again, here's my environment for reference:
azureml-automl-core 1.1.5.1
azureml-contrib-notebook 1.1.5.1
azureml-core 1.1.5.4
azureml-dataprep 1.3.2
azureml-dataprep-native 14.1.0
azureml-interpret 1.1.5
azureml-pipeline 1.1.5
azureml-pipeline-core 1.1.5
azureml-pipeline-steps 1.1.5
azureml-sdk 1.1.5
azureml-telemetry 1.1.5.3
azureml-train 1.1.5
azureml-train-automl-client 1.1.5.1
azureml-train-core 1.1.5
azureml-train-restclients-hyperdrive 1.1.5
azureml-widgets 1.1.5
We had a sync up for the issue. I mentioned 3 things I found:
- source_directory should not be current directory if notebook is used in the same directory to avoid the change in the source_directory
- HDstep uses snapshotId as part of HDConfig which is part of reuse hash calculation.
- It turns out snapshot creation has limit on its cache so that even same path provided without any changes results in different snapshotId.
In summary, combination of 2 and 3 above, sometimes HDStep is reused sometimes not depends on creation of snapshot from other steps.
So obvious fix on HDStep side is removing snapshotId from the hash calcuation so that reuse doesn't depends on snapshot creation. Since HDStep already checking the contents of the source_dir any changes on source_dir would still be part of reuse hash calculation.
Bug has been created to change it.
https://msdata.visualstudio.com/vienna/_queries/edit/674431/?triage=true
sonnypark
on 25 Mar 2020
bug referenced has been resloved
 DebFro
on 17 Apr 2020
DebFro
on 17 Apr 2020
@sanpil @sonnypark after some testing, I'm 97% sure the bug is fixed! Thanks for your hard work.
swanderz
on 20 Apr 2020
Thanks. I am worried about that 3% :)
 sanpil
on 20 Apr 2020
sanpil
on 20 Apr 2020
Related issues
 vineetgarhewal
·
3Comments
vineetgarhewal
·
3Comments
 tkawchak
·
5Comments
tkawchak
·
5Comments
 nswitanek
·
4Comments
nswitanek
·
4Comments
 wagenrace
·
3Comments
wagenrace
·
3Comments
 BillmanH
·
5Comments
BillmanH
·
5Comments
Most helpful comment
Yes "hd_step01 will run and generate new outputs" is what we get when the step is not reused. Will try to repro.