Machinelearningnotebooks: Empty Hyperdrive Metrics JSON
SDK Versoin: 1.0.74
Subscription Id: ff2e23ae-7d7c-4cbd-99b8-116bb94dca6e
January 10 run
PipelineRun
run_#: 4779
run_id: 4ef59daf-966b-4a2c-ba8d-59ebb3bca9ae
HyperDriveStepRun
run_#: 4782
run_id: 6de7c91d-4bf0-4d37-9cf6-f8a93606f959
only interesting log is stdoutlogs.txt that shows the json is empty
[2020-01-10 19:28:14Z] Metrics for HyperDrive run:
[2020-01-10 19:28:14Z] {}
HyperDriveRun
run_id: ret-master_1578683796190236
run#: 4783
hyperdrive.txt
"<START>[2020-01-10T19:16:36.703641][API][INFO]Experiment created<END>\n""<START>[2020-01-10T19:16:38.661621][GENERATOR][INFO]Trying to sample '5' jobs from the hyperparameter space<END>\n""<START>[2020-01-10T19:16:38.896103][GENERATOR][INFO]Successfully sampled '5' jobs, they will soon be submitted to the execution target.<END>\n"<START>[2020-01-10T19:16:39.0908407Z][SCHEDULER][INFO]The execution environment is being prepared. Please be patient as it can take a few minutes.<END><START>[2020-01-10T19:17:09.7149502Z][SCHEDULER][INFO]Scheduling job, id='ret-master_1578683796190236_0'<END><START>[2020-01-10T19:17:09.7207223Z][SCHEDULER][INFO]Scheduling job, id='ret-master_1578683796190236_4'<END><START>[2020-01-10T19:17:09.7183463Z][SCHEDULER][INFO]Scheduling job, id='ret-master_1578683796190236_3'<END><START>[2020-01-10T19:17:09.7157185Z][SCHEDULER][INFO]The execution environment was successfully prepared.<END><START>[2020-01-10T19:17:09.7163945Z][SCHEDULER][INFO]Scheduling job, id='ret-master_1578683796190236_1'<END><START>[2020-01-10T19:17:09.7174296Z][SCHEDULER][INFO]Scheduling job, id='ret-master_1578683796190236_2'<END><START>[2020-01-10T19:17:10.3444937Z][SCHEDULER][INFO]Successfully scheduled a job. Id='ret-master_1578683796190236_1'<END><START>[2020-01-10T19:17:10.5486447Z][SCHEDULER][INFO]Successfully scheduled a job. Id='ret-master_1578683796190236_4'<END><START>[2020-01-10T19:17:10.6502366Z][SCHEDULER][INFO]Successfully scheduled a job. Id='ret-master_1578683796190236_0'<END><START>[2020-01-10T19:17:11.3638122Z][SCHEDULER][INFO]Successfully scheduled a job. Id='ret-master_1578683796190236_2'<END>"<START>[2020-01-10T19:17:13.856358][GENERATOR][INFO]Max number of jobs '5' reached for experiment.<END>\n""<START>[2020-01-10T19:17:16.061477][GENERATOR][INFO]All jobs generated.<END>\n"<START>[2020-01-10T19:17:43.6674261Z][SCHEDULER][INFO]Successfully scheduled a job. Id='ret-master_1578683796190236_3'<END>"<START>[2020-01-10T19:27:53.631839][CONTROLLER][INFO]Experiment was 'ExperimentStatus.RUNNING', is 'ExperimentStatus.FINISHED'.<END>\n"
Child StepRun example
run_id: ret-master_1578683796190236_4
run_#: 4788
all the interesting logs i could find
get_metrics step that consumes the hyperdrive json
run_id: bc19744a-0b32-4e53-8c46-6ddee4a20546
run_#: 4790
The line of the log "Empty Dataframe comes from printing the contents of pd.read_json()
df = (pd.read_json(args.input_dir, orient='index')
# convert columns to floats from single-item lists
.transform(lambda x: x.apply(lambda y: y[0]))
.reset_index()
.rename(columns={
"index": "run_id",
"geometric mean": "geometric_mean"})
.pipe(df2csv, args.output_dir, "hyperdrive_metrics.csv")
.pipe(df2csv, "./outputs", "hyperdrive_metrics.csv")
)
print(df.head())
70_driverlog.txt
Starting the daemon thread to refresh tokens in background for process with pid = 152
Entering Run History Context Manager.
all args:
Namespace(exp_name='ret-master', input_file='/mnt/batch/tasks/shared/LS_root/jobs/avadevitsmlsvc/azureml/bc19744a-0b32-4e53-8c46-6ddee4a20546/mounts/attrition_pipeline_blob/azureml/6de7c91d-4bf0-4d37-9cf6-f8a93606f959/hyperdrive_json', output_dir='/mnt/batch/tasks/shared/LS_root/jobs/avadevitsmlsvc/azureml/bc19744a-0b32-4e53-8c46-6ddee4a20546/mounts/attrition_pipeline_blob/azureml/bc19744a-0b32-4e53-8c46-6ddee4a20546/best_run_data')
cwd: /mnt/batch/tasks/shared/LS_root/jobs/avadevitsmlsvc/azureml/bc19744a-0b32-4e53-8c46-6ddee4a20546/mounts/workspaceblobstore/azureml/bc19744a-0b32-4e53-8c46-6ddee4a20546
dir of cwd ['train.py', 'azureml-setup', 'azureml_compute_logs', 'get_data.py', 'get_metrics.py', 'azureml-logs', '.ipynb_checkpoints', 'AZ_BATCHAI_STDOUTERR_DIR', 'logs', 'outputs']
input_dir_parent: /mnt/batch/tasks/shared/LS_root/jobs/avadevitsmlsvc/azureml/bc19744a-0b32-4e53-8c46-6ddee4a20546/mounts/attrition_pipeline_blob/azureml/6de7c91d-4bf0-4d37-9cf6-f8a93606f959
dir of input_dir_parent: ['hyperdrive_json']
input file: /mnt/batch/tasks/shared/LS_root/jobs/avadevitsmlsvc/azureml/bc19744a-0b32-4e53-8c46-6ddee4a20546/mounts/attrition_pipeline_blob/azureml/6de7c91d-4bf0-4d37-9cf6-f8a93606f959/hyperdrive_json
saving hyperdrive_metrics.csv to /mnt/batch/tasks/shared/LS_root/jobs/avadevitsmlsvc/azureml/bc19744a-0b32-4e53-8c46-6ddee4a20546/mounts/attrition_pipeline_blob/azureml/bc19744a-0b32-4e53-8c46-6ddee4a20546/best_run_data
saving hyperdrive_metrics.csv to ./outputs
Empty DataFrame
Columns: [run_id]
Index: []
The experiment failed. Finalizing run...
Cleaning up all outstanding Run operations, waiting 300.0 seconds
2 items cleaning up...
Cleanup took 0.0019447803497314453 seconds
Starting the daemon thread to refresh tokens in background for process with pid = 152
Traceback (most recent call last):
File "get_metrics.py", line 53, in <module>
bestrun = df.query('geometric_mean == geometric_mean.max()')
File "/azureml-envs/azureml_5aac805784c21ec6369a526dfab4280d/lib/python3.6/site-packages/pandas/core/frame.py", line 3199, in query
res = self.eval(expr, **kwargs)
File "/azureml-envs/azureml_5aac805784c21ec6369a526dfab4280d/lib/python3.6/site-packages/pandas/core/frame.py", line 3315, in eval
return _eval(expr, inplace=inplace, **kwargs)
File "/azureml-envs/azureml_5aac805784c21ec6369a526dfab4280d/lib/python3.6/site-packages/pandas/core/computation/eval.py", line 322, in eval
parsed_expr = Expr(expr, engine=engine, parser=parser, env=env, truediv=truediv)
File "/azureml-envs/azureml_5aac805784c21ec6369a526dfab4280d/lib/python3.6/site-packages/pandas/core/computation/expr.py", line 830, in __init__
self.terms = self.parse()
File "/azureml-envs/azureml_5aac805784c21ec6369a526dfab4280d/lib/python3.6/site-packages/pandas/core/computation/expr.py", line 847, in parse
return self._visitor.visit(self.expr)
File "/azureml-envs/azureml_5aac805784c21ec6369a526dfab4280d/lib/python3.6/site-packages/pandas/core/computation/expr.py", line 441, in visit
return visitor(node, **kwargs)
File "/azureml-envs/azureml_5aac805784c21ec6369a526dfab4280d/lib/python3.6/site-packages/pandas/core/computation/expr.py", line 447, in visit_Module
return self.visit(expr, **kwargs)
File "/azureml-envs/azureml_5aac805784c21ec6369a526dfab4280d/lib/python3.6/site-packages/pandas/core/computation/expr.py", line 441, in visit
return visitor(node, **kwargs)
File "/azureml-envs/azureml_5aac805784c21ec6369a526dfab4280d/lib/python3.6/site-packages/pandas/core/computation/expr.py", line 450, in visit_Expr
return self.visit(node.value, **kwargs)
File "/azureml-envs/azureml_5aac805784c21ec6369a526dfab4280d/lib/python3.6/site-packages/pandas/core/computation/expr.py", line 441, in visit
return visitor(node, **kwargs)
File "/azureml-envs/azureml_5aac805784c21ec6369a526dfab4280d/lib/python3.6/site-packages/pandas/core/computation/expr.py", line 747, in visit_Compare
return self.visit(binop)
File "/azureml-envs/azureml_5aac805784c21ec6369a526dfab4280d/lib/python3.6/site-packages/pandas/core/computation/expr.py", line 441, in visit
return visitor(node, **kwargs)
File "/azureml-envs/azureml_5aac805784c21ec6369a526dfab4280d/lib/python3.6/site-packages/pandas/core/computation/expr.py", line 563, in visit_BinOp
op, op_class, left, right = self._maybe_transform_eq_ne(node)
File "/azureml-envs/azureml_5aac805784c21ec6369a526dfab4280d/lib/python3.6/site-packages/pandas/core/computation/expr.py", line 482, in _maybe_transform_eq_ne
left = self.visit(node.left, side="left")
File "/azureml-envs/azureml_5aac805784c21ec6369a526dfab4280d/lib/python3.6/site-packages/pandas/core/computation/expr.py", line 441, in visit
return visitor(node, **kwargs)
File "/azureml-envs/azureml_5aac805784c21ec6369a526dfab4280d/lib/python3.6/site-packages/pandas/core/computation/expr.py", line 577, in visit_Name
return self.term_type(node.id, self.env, **kwargs)
File "/azureml-envs/azureml_5aac805784c21ec6369a526dfab4280d/lib/python3.6/site-packages/pandas/core/computation/ops.py", line 78, in __init__
self._value = self._resolve_name()
File "/azureml-envs/azureml_5aac805784c21ec6369a526dfab4280d/lib/python3.6/site-packages/pandas/core/computation/ops.py", line 95, in _resolve_name
res = self.env.resolve(self.local_name, is_local=self.is_local)
File "/azureml-envs/azureml_5aac805784c21ec6369a526dfab4280d/lib/python3.6/site-packages/pandas/core/computation/scope.py", line 201, in resolve
raise compu.ops.UndefinedVariableError(key, is_local)
pandas.core.computation.ops.UndefinedVariableError: name 'geometric_mean' is not defined
2020/01/10 19:29:56 mpirun version string: {
Intel(R) MPI Library for Linux* OS, Version 2018 Update 3 Build 20180411 (id: 18329)
Copyright 2003-2018 Intel Corporation.
}
2020/01/10 19:29:56 MPI publisher: intel ; version: 2018
January 9 Run
The above failure happening on January 10, run ids for success from the day before were:
PipelineRun
run_#: 4760
run_id: 9d8867b9-eb2f-489b-9a2b-802c330c4e00
HyperDriveStepRun
run_#: 4763
run_id: f05ed3ac-9251-4bfc-b48c-ef29080b9a66
only interesting log is stdoutlogs.txt that shows the json is NOT empty
[2020-01-09 19:06:01Z] Metrics for HyperDrive run:
[2020-01-09 19:06:01Z] {"ret-master_1578595655944344_0":{"Arguments":["Namespace(boosting_type='gbdt', colsample_bytree=0.4, input_dir='/mnt/batch/tasks/shared/LS_root/jobs/avadevitsmlsvc/azureml/ret-master_1578595655944344_0/mounts/attrition_pipeline_blob/azureml/83f98067-9e24-491c-8826-7f21d334d9b3/split_data', is_unbalance=True, learning_rate=0.09, max_bin=255, min_child_samples=120, model_name='Attrition', n_estimators=500, num_leaves=6, objective='binary', output_dir='c:\\\\\\\\temp\\\\output', subsample=0.5)"],"majority_obs":[62545],"minority obs":[2552],"precision":[0.027785521791655051],"recall":[0.57389635316698662],"f1":[0.05300478638539266],"geometric mean":[0.65668638867113249],"LIFT":[2.3002189381499725],"rate_diff":[3.7471597707991826]},"ret-master_1578595655944344_3":{"Arguments":["Namespace(boosting_type='gbdt', colsample_bytree=0.7, input_dir='/mnt/batch/tasks/shared/LS_root/jobs/avadevitsmlsvc/azureml/ret-master_1578595655944344_3/mounts/attrition_pipeline_blob/azureml/83f98067-9e24-491c-8826-7f21d334d9b3/split_data', is_unbalance=True, learning_rate=0.08, max_bin=255, min_child_samples=20, model_name='Attrition', n_estimators=500, num_leaves=17, objective='binary', output_dir='c:\\\\\\\\temp\\\\output', subsample=0.9)"],"majority_obs":[62545],"minority obs":[2552],"precision":[0.028118723499218925],"recall":[0.48368522072936659],"f1":[0.053147738057576714],"geometric mean":[0.61934277140264071],"LIFT":[2.313992704246679],"rate_diff":[3.0972674456733857]},"ret-master_1578595655944344_2":{"Arguments":["Namespace(boosting_type='gbdt', colsample_bytree=0.5, input_dir='/mnt/batch/tasks/shared/LS_root/jobs/avadevitsmlsvc/azureml/ret-master_1578595655944344_2/mounts/attrition_pipeline_blob/azureml/83f98067-9e24-491c-8826-7f21d334d9b3/split_data', is_unbalance=True, learning_rate=0.06, max_bin=255, min_child_samples=70, model_name='Attrition', n_estimators=500, num_leaves=40, objective='binary', output_dir='c:\\\\\\\\temp\\\\output', subsample=0.9)"],"majority_obs":[62545],"minority obs":[2552],"precision":[0.029686995805098419],"recall":[0.52975047984644918],"f1":[0.056223263393766557],"geometric mean":[0.64513785382908162],"LIFT":[2.3454255531193939],"rate_diff":[3.8511857677790942]},"ret-master_1578595655944344_4":{"Arguments":["Namespace(boosting_type='gbdt', colsample_bytree=1.0, input_dir='/mnt/batch/tasks/shared/LS_root/jobs/avadevitsmlsvc/azureml/ret-master_1578595655944344_4/mounts/attrition_pipeline_blob/azureml/83f98067-9e24-491c-8826-7f21d334d9b3/split_data', is_unbalance=True, learning_rate=0.07, max_bin=255, min_child_samples=70, model_name='Attrition', n_estimators=500, num_leaves=36, objective='binary', output_dir='c:\\\\\\\\temp\\\\output', subsample=0.7)"],"majority_obs":[62545],"minority obs":[2552],"precision":[0.028000918062887306],"recall":[0.46833013435700577],"f1":[0.052842447211694642],"geometric mean":[0.61161981016375477],"LIFT":[2.1956635318704283],"rate_diff":[2.8925503595012976]},"ret-master_1578595655944344_1":{"Arguments":["Namespace(boosting_type='gbdt', colsample_bytree=1.0, input_dir='/mnt/batch/tasks/shared/LS_root/jobs/avadevitsmlsvc/azureml/ret-master_1578595655944344_1/mounts/attrition_pipeline_blob/azureml/83f98067-9e24-491c-8826-7f21d334d9b3/split_data', is_unbalance=True, learning_rate=0.07, max_bin=255, min_child_samples=145, model_name='Attrition', n_estimators=500, num_leaves=17, objective='binary', output_dir='c:\\\\\\\\temp\\\\output', subsample=0.4)"],"majority_obs":[62545],"minority obs":[2552],"precision":[0.028938581402408174],"recall":[0.54894433781190022],"f1":[0.054978854286812762],"geometric mean":[0.65097607224790521],"LIFT":[2.4527424161276588],"rate_diff":[3.5686661491029645]}}
HyperDriveRun
run_id: ret-master_1578595655944344
run#: 4764
hyperdrive.txt
"<START>[2020-01-09T18:47:36.426297][API][INFO]Experiment created<END>\n"<START>[2020-01-09T18:47:37.6436910Z][SCHEDULER][INFO]The execution environment is being prepared. Please be patient as it can take a few minutes.<END>"<START>[2020-01-09T18:47:40.964050][GENERATOR][INFO]Trying to sample '5' jobs from the hyperparameter space<END>\n""<START>[2020-01-09T18:47:41.105792][GENERATOR][INFO]Successfully sampled '5' jobs, they will soon be submitted to the execution target.<END>\n"<START>[2020-01-09T18:48:08.2232082Z][SCHEDULER][INFO]Scheduling job, id='ret-master_1578595655944344_0'<END><START>[2020-01-09T18:48:08.2228187Z][SCHEDULER][INFO]The execution environment was successfully prepared.<END><START>[2020-01-09T18:48:08.2254794Z][SCHEDULER][INFO]Scheduling job, id='ret-master_1578595655944344_2'<END><START>[2020-01-09T18:48:08.2274792Z][SCHEDULER][INFO]Scheduling job, id='ret-master_1578595655944344_4'<END><START>[2020-01-09T18:48:08.2244292Z][SCHEDULER][INFO]Scheduling job, id='ret-master_1578595655944344_1'<END><START>[2020-01-09T18:48:08.2263754Z][SCHEDULER][INFO]Scheduling job, id='ret-master_1578595655944344_3'<END><START>[2020-01-09T18:48:09.4057991Z][SCHEDULER][INFO]Successfully scheduled a job. Id='ret-master_1578595655944344_0'<END><START>[2020-01-09T18:48:09.5525239Z][SCHEDULER][INFO]Successfully scheduled a job. Id='ret-master_1578595655944344_3'<END><START>[2020-01-09T18:48:09.7140716Z][SCHEDULER][INFO]Successfully scheduled a job. Id='ret-master_1578595655944344_2'<END><START>[2020-01-09T18:48:10.3537908Z][SCHEDULER][INFO]Successfully scheduled a job. Id='ret-master_1578595655944344_4'<END><START>[2020-01-09T18:48:10.6752889Z][SCHEDULER][INFO]Successfully scheduled a job. Id='ret-master_1578595655944344_1'<END>"<START>[2020-01-09T18:48:13.488363][GENERATOR][INFO]Max number of jobs '5' reached for experiment.<END>\n""<START>[2020-01-09T18:48:13.613230][GENERATOR][INFO]All jobs generated.<END>\n""<START>[2020-01-09T19:06:00.579356][CONTROLLER][INFO]Experiment was 'ExperimentStatus.RUNNING', is 'ExperimentStatus.FINISHED'.<END>\n"
Child StepRun example
run_id: ret-master_1578595655944344_0
run_#: 4766
nothing unusual to report
get_metrics step that consumes the hyperdrive json
run_id:
run_#: 4766
nothing unusual to report
Theory
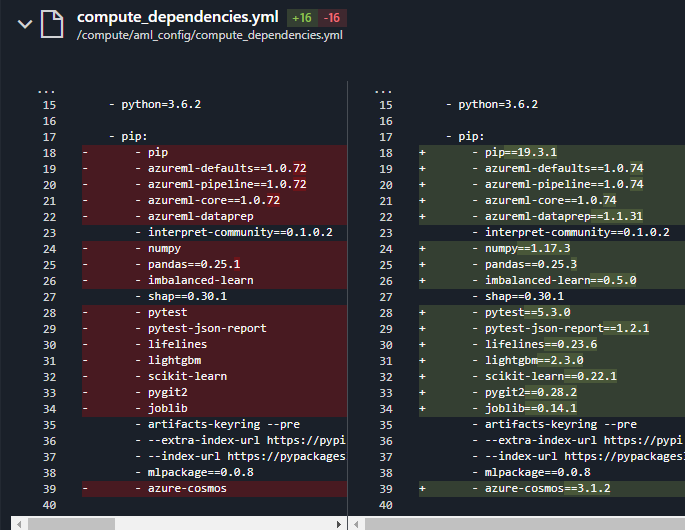
Literally the only thing that changed in the pipeline is the conda env spec. We upgraded from 1.0.72 to 1.0.74... though I believe that @alieus experienced the same issues with 1.0.72...
@sonnypark @alexkalita
 swanderz
swanderz
All 9 comments
the metrics upload from child run failed due to InternalServerError
assigning to Tom Wagner to take a look
 swatig007
on 24 Jan 2020
swatig007
on 24 Jan 2020
History had an issue communicating with a cache during the request to upload these metrics. We have updated the service to be more fault tolerant of these connection issues within the last week or so.
 thwagne
on 24 Jan 2020
thwagne
on 24 Jan 2020
closing @thwagne says this won't happen again.
swanderz
on 3 Mar 2020
@thwagne @swatig007
same thing just happened again. VERY frustrating. The individual runs are taking twice as long as well. Could this be related to the same connection issue as before?
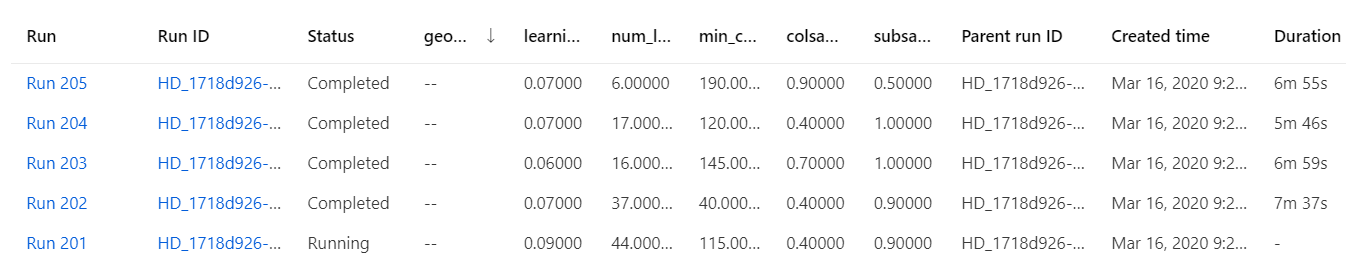
Region: West US II
Subscription ID:
PipelineRun: b375ca1c-66eb-4bb3-ba3b-35cceac398e6
HyperDriveStep: 2a769d94-a57e-4864-b7ff-0c6409d4deb8
HyperDriveRun: HD_e000cf88-840d-4d88-97ab-7e58bc8e5ec2
training run example: HD_e000cf88-840d-4d88-97ab-7e58bc8e5ec2_0
get metrics step: 18af5cd8-ddab-460c-acf1-4498c41d1955
 swanderz
on 17 Mar 2020
swanderz
on 17 Mar 2020
@jadhosn does your team use HyperDrive? If so, have you all seen this error before?
swanderz
on 17 Mar 2020
@swanderz we haven't used hyperdrive yet
 jadhosn
on 17 Mar 2020
jadhosn
on 17 Mar 2020
Run History team acknowledges as issue on their end. @andscho-msft is investigating
swatig007
on 17 Mar 2020
we normally see in the 70_driver_log.txt that cleanup takes 0-2 seconds. for this run, there's this line.
Cleanup took 480.1478006839752 seconds
swanderz
on 17 Mar 2020
Closing this issue, as I don't see it happening anymore...
swanderz
on 21 Mar 2020
Related issues
swanderz
·
5Comments
 chengyu-liu-cs
·
3Comments
chengyu-liu-cs
·
3Comments
 BillmanH
·
5Comments
BillmanH
·
5Comments
 nswitanek
·
4Comments
swanderz
·
5Comments
nswitanek
·
4Comments
swanderz
·
5Comments