Machinelearningnotebooks: AutoML hyperparameter selection
I'm finding some trouble finding a definitive answer about AutoML's hyperparameter selection.
It is mentioned across the documentation that AutoML selects the best pipeline (a combination of a modeling algorithm, a pre-processing technique and hyperparameters) to meet whatever constraints specified in the automl settings (primary metric, number of cross-validation folds etc.)
If we look at the different iterations (or runs) in an AutoML step:
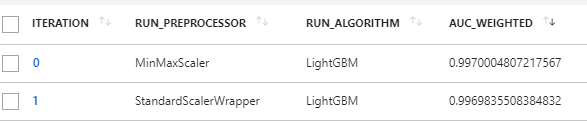
For example in iteration 0 above, for preprocessing MinMaxScaler and algorithm LightBGM:
AutoML will iterate through different hyperparameter options to return the best-fitted model by optimizing the specified primary metric (auc_weighted in this case).
_Question 1:_
We know that the hyperparameters are being selected to maximize auc_weighted in this example. What is the process of selecting the hyperparameters for each
_Question 2:_
We know that the hyperparameters are being selected to maximize auc_weighted in this example. So without re-running the AutoML step, if I select another model (model B) with the highest log_loss for example, the hyperparameters for model B will be inaccurate since they were optimized for a maximum auc_weighted?
_Question 3:_
I also went through the hyperparameter tunning process. Is that what AutoML is doing? Can we specify the search space sampling method for AutoML in that case?
@swanderz @purnesh42H
 jadhosn
jadhosn
All 9 comments
@justinormont @anupsms
 skasturi
on 14 Jan 2020
skasturi
on 14 Jan 2020
Question 1:
The hyperparameters choices come from two paths. Either they are pre-chosen and used in our collaborative filtering route, or are generated on the fly by more traditional hyperparameter optimization techniques.
For a validation dataset, if you don't provide the validation dataset, one will be created for you (in classification/regression) by either splitting a random subset of your training dataset in a Train/Validate mode, or by using a cross-validation mode on your training data. For time-series forecasting, the dataset is split on time to avoid data leakage which ensures that your validation data is always newer than your training data for a given split.
Question 2:
_I'm uncertain if I'm answering the right question, so feel free to correct my understanding of what you're asking._ If you select another model from a sweep, choosing based on a different metric, that model is likely reasonable, though less optimized than it could be. Many metric are well correlated so choosing one tends to co-optimize the other (but to a lesser extent); some other metric pairs can be at odds.
There are cases where you can actually do better choosing another metric for optimization than your final metric. For instance, if your business needs are best represented by accuracy but your dataset is very small, or has a highly skewed label distribution, accuracy can turn into a staircase where the metric moves only in large jumps. In those specific cases you may want to optimize a smoother metric like auc or log_loss then choose your final model on accuracy.
Question 3:
The hyperdrive service mentioned in the article is part of Azure AutoML. The hyperparameter optimization uses a mix of collaborative filtering and techniques listed in the article.
We don't expose the hyperprameter sampling methods. Creating an AutoML tool is always a balance of automating as much as possible for the user while allowing advanced users to have deeper control of the process.
 justinormont
on 14 Jan 2020
justinormont
on 14 Jan 2020
@justinormont Thank you for the answers above!
In the case of feeding in a validation set to AutoML, can I assume that the returned metrics and scores in general are on the test set?
In other words, is the returned primary metric for each model is the train or test metric?
jadhosn
on 23 Mar 2020
@jadhosn - The returned metric is currently based either on a Validation dataset or based on cross-validation. Metrics shouldn't be calculated on the train dataset and AutoML does not use the train dataset for calculating the metrics.
Note that when using AutoML we're currently talking about metrics based on validation dataset (either provided or internally split or using cross-validation).
A "test metric" would be using a third dataset (the "Test dataset") that currently AutoML does not support directly in AutoMLConfig class.
If you want to get metrics with a 'Test dataset' (a third dataset "not seen by the training process") you can do it manually in a notebook after getting the "best model" from AutoML.
In the future, we're planning for AutoML to also support a Test dataset, so you could provide the following as parameters to the AutoMLConfig class:
- Train Dataset
- Validation Dataset
- Test Dataset
Currently (as of March 2020) we just use 1 and 2 as parameters in AutoMLConfig (or just 1 and then we internally do split or cross-validation) as explained by Justin above.
Here's some info explaining differences between Validation dataset and Test dataset:
http://www.machinelearningtutorial.net/2017/04/01/training-set-vs-test-set-vs-validation-set-whats-the-deal/
 CESARDELATORRE
on 23 Mar 2020
CESARDELATORRE
on 23 Mar 2020
@CESARDELATORRE Thank you. As I'm using AutoML on a daily basis, some questions arise about the intended usage of some of the AutoML config attributes.
Any clarification/added detail on the args below can be really helpful as the documentation either lacks to mention the specific use or utilizes different terminology across different tutorials/docstring.
max_concurrent_iterations: Maximum number of iterations that would be executed in parallel on an amlcompute. This should be less than or equal to the number of _cores_ (?). If you run multiple experiments in parallel on a single amlcompute cluster or DSVM, the sum of the
max_concurrent_iterations values should be less than or equal to the maximum number of _nodes_ (?)
-> The confusion here is the distinction between cores and nodes. I can provision a cluster of 20 nodes, and each node can have 4 cores. Does that mean that the max_concurrent_iterations should be 20*4 = 80?
In that case, what would be the relation with max_cores_per_iteration?
Exit Criteria: Ref: I guess here it's more of a user question, but what is the sweet spot between letting AutoML run till _no further progress is made_ vs. limiting the
experiment_timeout(and maybe lose that awesome model that was meant to happen postexperiment_timeout)enable_early_stopping: Flag to enable early termination if the score is not improving in the _short term_ (what defines the short term? does that play well with no stopping criteria is given?)
FeaturizationConfig: As I understood online, this config only allows blocked_transformers but it doesn't cover how to disable the _non-advanced_ automated pre-processing (now with
preprocess=Trueis being deprecated). Does that mean that we cannot opt out of the _normalization and handling missing data_ pre-processing steps? Or How can I pick and choose automated pre-processing (not the advanced ones)?(Please note that trying Featurization="off" returns that the data contains categorical attributes that need treatment).
jadhosn
on 23 Mar 2020
Adding @rtanase so he can confirm.
Nodes and Cores:
If you have a dedicated cluster per experiment, you can set the number of 'max_concurrent_iterations' to the same number of max nodes in a cluster so there won't be queued trains.
If the cluster is shared between multiple concurrent experiments (parent runs), then that parameter is not very useful and won't offer predictability because of the multiple concurrent experiments that will cause queuing the runs, probably.
I think the "cores" mentioned in the doc abore is wrong and should say "nodes". Razvan, can you confirm?
'max_concurrent_iterations' is related to max number of parallel child runs within a single parent AutoML run.
However, 'max_cores_per_iteration' is only related to a single child run (single iteration). In that case it is right that is related to the cores on the compute target (that depends on the VM type you chose for your cluster).
Exit Criteria: Initially I wouldn't use 'experiment_timeout' but let AutoML to finish when converging by enabling 'enable_early_stopping'.
Use 'experiment_timeout' only if your time window for training must not be greater than some X time. Even in this case, the current time used won't be exactly that timeout but might be a bit more due to final ensembles and other time not currently included in the 'experiment timeout' (We're discussing this topic and it might change in the future because right now is not an exact timeout).
FeaturizationConfig: @rtanase Can you provide further info/confirmation here?
@jadhosn - I'd be interested if you can provide further info on the scenario that you cannot perform with the current config, what's the impact for your model and reasons on why you'd need to disable (opt out) the normalization and handling missing data pre-processing steps (not the advanced ones) and why that impacts your model.
We're in the process of making featurization more modular and decoupled, so making it more flexible is also a goal for upcoming releases.
CESARDELATORRE
on 23 Mar 2020
However, 'max_cores_per_iteration' is only related to a single child run (single iteration). In that case it is right that is related to the cores on the compute target (that depends on the VM type you chose for your cluster).
Does AutoML have subprocess built-in, where if I enable 4 cores to be used by a single iteration, the training step would leverage these cores as needed?
@jadhosn - I'd be interested if you can provide further info on the scenario that you cannot perform with the current config, what's the impact for your model and reasons on why you'd need to disable (opt out) the normalization and handling missing data pre-processing steps (not the advanced ones) and why that impacts your model.
@CESARDELATORRE For our application, we are potentially running north of 700 automl runs (parent runs), so understanding what's going on under the hood would help us better understand what to expect out of each automl parent-run, how many iterations to expect (which will factor into cost estimation), and would pave the way for easier outputs extraction in the future. The reasoning behind opting out of standard pre-processing is just to understand what can we/cannot control in the iterations, and more importantly save iterations towards
jadhosn
on 23 Mar 2020
@jadhosn - This is the current state:
• As of now, we only support a single job per VM/node in AML compute (which is how iterations get submitted to Amlcompute).
• At a later date we might change it, but its not something that will happen in the short term since the system contracts are designed to take a single job on a node of the cluster.
• Compute instances and DSVM can and will support multiple iterations per node. For compute instance number of max iterations is 2* number of of cores on the instance. I am not sure if there is any limitation on DSVM since it is not a managed resource.
CESARDELATORRE
on 24 Mar 2020
Thank you for your post. It looks as though this issue was resolved so we closed this thread. Should you have additional questions, please continue to post here and and we will gladly continue the discussion.
 v-strudm-msft
on 21 Apr 2020
v-strudm-msft
on 21 Apr 2020
Related issues
 wagenrace
·
3Comments
wagenrace
·
3Comments
 vineetgarhewal
·
3Comments
vineetgarhewal
·
3Comments
 tkawchak
·
5Comments
tkawchak
·
5Comments
 shankarpandala
·
3Comments
shankarpandala
·
3Comments
 chengyu-liu-cs
·
3Comments
chengyu-liu-cs
·
3Comments
Most helpful comment
@jadhosn - The returned metric is currently based either on a Validation dataset or based on cross-validation. Metrics shouldn't be calculated on the train dataset and AutoML does not use the train dataset for calculating the metrics.
Note that when using AutoML we're currently talking about metrics based on validation dataset (either provided or internally split or using cross-validation).
A "test metric" would be using a third dataset (the "Test dataset") that currently AutoML does not support directly in AutoMLConfig class.
If you want to get metrics with a 'Test dataset' (a third dataset "not seen by the training process") you can do it manually in a notebook after getting the "best model" from AutoML.
In the future, we're planning for AutoML to also support a Test dataset, so you could provide the following as parameters to the AutoMLConfig class:
Currently (as of March 2020) we just use 1 and 2 as parameters in AutoMLConfig (or just 1 and then we internally do split or cross-validation) as explained by Justin above.
Here's some info explaining differences between Validation dataset and Test dataset:
http://www.machinelearningtutorial.net/2017/04/01/training-set-vs-test-set-vs-validation-set-whats-the-deal/