Machinelearningnotebooks: AutoMLStep: pass training data via PipelineData object
Anyone have an example of AutoMLStep that takes input from a previous PipelineStep I've been working with this notebook and trying to generalize the get_data.py that gets created into a standalone PipelineStep.
How do I pass data to AutoMLStep via a PipelineData object without PythonScriptStep's arguments param?
Because arguments isn't a param of AutoMLStep, I've got some thoughts on how to hack this out
- create a
PipelineDataobject,split_data, withoutput_mode="upload"andoutput_path_on_compute='/tmp/azureml_runs' - make a
split_stepPythonScriptStepthat explicitly saves out anX.csvandy.csvto a thesplit_dataPipelineDataobject - in the
get_data.pyscript pass the full paths on the datastore tosplit_data's csv outputs - profit???
cc: @heatherbshapiro @sanpil @yanrez @akshay-0 @jpe316 @cody-dkdc
 swanderz
swanderz
All 20 comments
@swanderz: can you take a look at this: https://aka.ms/pl-nyctaxi-tutorial?
 sanpil
on 29 Jul 2019
sanpil
on 29 Jul 2019
@swanderz you are thinking in the right direction. However, you don't need to do these hacks as every input path is made available as environment variable. So if you provide your x and y input blobs as input to AutoMLStep, they will be made available as environment variables prefixed by AZUREML_DATAREFERENCE_, which you can retrieve in your get_data.py. Please go through the notebook mentioned by @sanpil and follow from Split the data into train and test sets section onwards for better understanding. You will see that all outputs of testTrainSplitStep are being provided as input to AutoML step as PipelineData.
 purnesh42H
on 29 Jul 2019
purnesh42H
on 29 Jul 2019
@purnesh42H ok good to know. I'm going to see if I can hack it out using the env variables.
Months ago we started with a get_data.py to pass things to AutoML. Then as our pipeline solidified, our get_data.py became our train-test-split PipelineStep, but we kept the same return a data dict object convention. Our method of passing to downstream steps was to pickle the data dict. and unpickle it in any downstream step. My takeaway is that this isn't the way the devs have envisioned things.
My gut tells me that it's a hacky workaround (at least from a consistency perspective) to ask users to employ environment variables to load data to an AutoMLStep, but in ALL OTHER Steps to use the the arguments parameter. In addition, the notebook I referenced yet another way to access data.
swanderz
on 30 Jul 2019
@purnesh42H assumption: "/part-00000" is what each of the csvs will be called in their respective PipelineData directories.
Alternative (and more simple take IMHO):
- Save the 4 outputs of train-test-split to the same PipelineData object with different filenames.
- in
get_data.pyload them all but based on their filenames...
Perhaps there's an advantage to isolated PipelineData objects I'm not seeing here, but even if it's better to have 4 of them, you could at least them be files not directories which obviates the need for "/part-00000" in the first place. right??
swanderz
on 30 Jul 2019
@sanpil @purnesh42H help I'm going crazy.
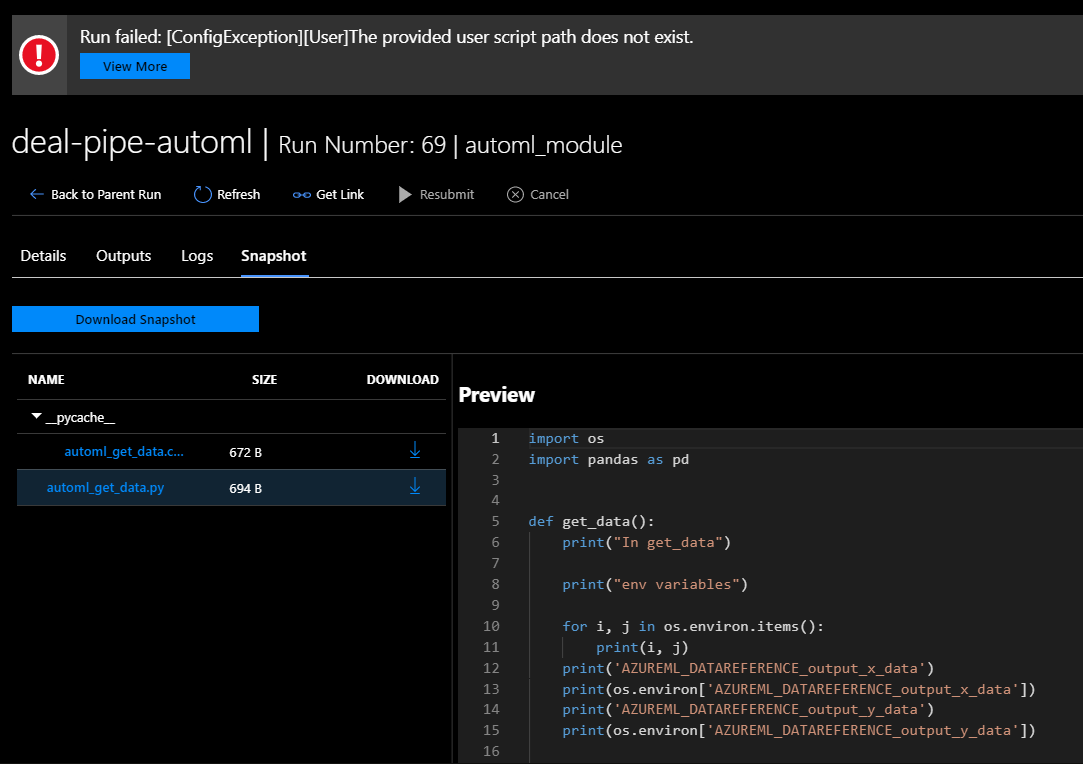
Is the data_script argument supposed to be the path to the file relative to the path parameter? Is it supposed to be a local path? I've been fiddling with it and getting error after error like this. What drives me crazy is that the automl_get_data.py is available in the "Snapshot" of the failed run. so it must exist. Right? Right?!?
Here's a code snippet:
automl_settings = {
"iteration_timeout_minutes": 5,
"iterations": 4,
"n_cross_validations": 5,
"validation_size": 0.2,
"primary_metric": 'AUC_weighted',
"preprocess": True,
"max_concurrent_iterations": 2,
"verbosity": 1
}
path_relative = os.path.join('.', 'compute','automl')
path_full = os.path.realpath(path_relative)
attempts = {'full paths': #Error occurred: [ConfigException][User]The provided user script path does not exist.
{'path':path_full,
'data_script':os.path.join(path_full,"automl_get_data.py")},
'full path relative data_script': #Error occurred: [ConfigException][User]The provided user script path does not exist.
{'path':path_relative,
'data_script':os.path.join(path_relative,"automl_get_data.py")
},
'full path immediate data_script': #ValueError: path not found .\automl_get_data.py
{'path':path_relative,
'data_script':os.path.join('.',"automl_get_data.py")
},
'full path direct data_script': #ValueError: path not found .\automl_get_data.py
{'path':path_relative,
'data_script':"automl_get_data.py"
},
'normed full paths': #Error occurred: [ConfigException][User]The provided user script path does not exist.
{'path':os.path.normpath(path_full),
'data_script':os.path.normpath(os.path.join(path_full,"automl_get_data.py"))
}
}
automl_config = AutoMLConfig(task = 'classification',
debug_log = 'automl_errors.log',
compute_target=compute_target,
run_configuration=aml_compute,
**attempts['full path direct data_script'],
**automl_settings
)
automl_step = AutoMLStep(
name='automl_module',
automl_config=automl_config,
inputs=[output_x_data, output_y_data],
outputs=[metrics_data, model_data],
allow_reuse=True)
Starting the setup....
WARNING - Received unrecognized parameter: time_column_name None
WARNING - Received unrecognized parameter: grain_column_names None
WARNING - Received unrecognized parameter: drop_column_names None
WARNING - Received unrecognized parameter: group None
WARNING - Received unrecognized parameter: target_lags None
WARNING - Received unrecognized parameter: target_rolling_window_size None
WARNING - Received unrecognized parameter: max_horizon None
WARNING - Received unrecognized parameter: country_or_region None
WARNING - Received unrecognized parameter: seasonality None
WARNING - Received unrecognized parameter: use_stl None
WARNING - Received unrecognized parameter: season_trend None
WARNING - Received unrecognized parameter: season None
The experiment failed. Finalizing run...
Logging experiment finalizing status in history service.
Cleaning up all outstanding Run operations, waiting 300.0 seconds
3 items cleaning up...
Cleanup took 0.0011196136474609375 seconds
Traceback (most recent call last):
File "setup.py", line 742, in <module>
result = setup_run()
File "setup.py", line 736, in setup_run
num_iterations=num_iterations
File "/azureml-envs/azureml_868df23b3dd8a34671c1a6ebc15551fc/lib/python3.6/site-packages/azureml/train/automl/_remote_script.py", line 551, in setup_wrapper
logger=logger
File "/azureml-envs/azureml_868df23b3dd8a34671c1a6ebc15551fc/lib/python3.6/site-packages/azureml/train/automl/_remote_script.py", line 235, in _prepare_data
user_module = _load_user_script(script_path, logger)
File "/azureml-envs/azureml_868df23b3dd8a34671c1a6ebc15551fc/lib/python3.6/site-packages/azureml/train/automl/utilities.py", line 102, in _load_user_script
raise ConfigException('The provided user script path does not exist.')
automl.client.core.common.exceptions.ConfigException: The provided user script path does not exist.
logs/azureml/executionlogs.txt
It's crazy because I can see the path that's passed... what's going on?
"path":"c:\\Users\\anders.swanson\\Documents\\deal\\compute\\automl",
"data_script":"c:\\Users\\anders.swanson\\Documents\\deal\\compute\\automl\\automl_get_data.py"
[2019-07-31 19:44:35Z] Parsed interface. Will be submitting job to AutoML
[2019-07-31 19:44:35Z] AutoML settings={"name":"deal-pipe-automl","subscription_id":"ff2e23ae-7d7c-4cbd-99b8-116bb94dca6e","resource_group":"RG-ITSMLTeam-Dev","workspace_name":"avadevitsmlsvc","path":"c:\\Users\\anders.swanson\\Documents\\deal\\compute\\automl","iterations":4,"data_script":"c:\\Users\\anders.swanson\\Documents\\deal\\compute\\automl\\automl_get_data.py","primary_metric":"AUC_weighted","task_type":"classification","compute_target":"deal-pipe-automl","spark_context":null,"validation_size":0.2,"n_cross_validations":5,"y_min":null,"y_max":null,"num_classes":null,"preprocess":true,"lag_length":0,"max_cores_per_iteration":1,"max_concurrent_iterations":2,"iteration_timeout_minutes":5,"mem_in_mb":null,"enforce_time_on_windows":true,"experiment_timeout_minutes":null,"experiment_exit_score":null,"blacklist_models":null,"whitelist_models":null,"auto_blacklist":true,"exclude_nan_labels":true,"verbosity":1,"debug_log":"automl_errors.log","debug_flag":null,"enable_ensembling":true,"ensemble_iterations":4,"model_explainability":false,"enable_tf":false,"enable_cache":true,"enable_subsampling":false,"subsample_seed":null,"cost_mode":0,"is_timeseries":false,"metric_operation":"maximize","time_column_name":null,"grain_column_names":null,"drop_column_names":null,"group":null,"target_lags":null,"target_rolling_window_size":null,"max_horizon":null,"country_or_region":null,"seasonality":null,"use_stl":null,"season_trend":null,"season":null}
[2019-07-31 19:44:35Z] Finished initializing
[2019-07-31 19:44:35Z] Set up run properties for Automl
[2019-07-31 19:44:35Z] Automl CreateRunDTO {"RunId":"3cb258b4-dd21-49a9-a0e7-06d1c448e62f","ParentRunId":null,"Status":null,"StartTimeUtc":null,"EndTimeUtc":null,"HeartbeatEnabled":false,"Options":null,"CancelUri":null,"Name":null,"DataContainerId":null,"Description":null,"Hidden":null,"RunType":null,"Properties":{"num_iterations":"4","training_type":"TrainFull","acquisition_function":"EI","metrics":"accuracy","primary_metric":"AUC_weighted","train_split":"0.2","MaxTimeSeconds":"300","acquisition_parameter":"0","num_cross_validation":"5","target":"deal-pipe-automl","RawAMLSettingsString":"{'name':'deal-pipe-automl','subscription_id':'ff2e23ae-7d7c-4cbd-99b8-116bb94dca6e','resource_group':'RG-ITSMLTeam-Dev','workspace_name':'avadevitsmlsvc','path':'c:\\\\Users\\\\anders.swanson\\\\Documents\\\\deal\\\\compute\\\\automl','iterations':4,'data_script':'c:\\\\Users\\\\anders.swanson\\\\Documents\\\\deal\\\\compute\\\\automl\\\\automl_get_data.py','primary_metric':'AUC_weighted','task_type':'classification','compute_target':'deal-pipe-automl','spark_context':None,'validation_size':0.2,'n_cross_validations':5,'y_min':None,'y_max':None,'num_classes':None,'preprocess':True,'lag_length':0,'max_cores_per_iteration':1,'max_concurrent_iterations':2,'iteration_timeout_minutes':5,'mem_in_mb':None,'enforce_time_on_windows':True,'experiment_timeout_minutes':None,'experiment_exit_score':None,'blacklist_models':None,'whitelist_models':None,'auto_blacklist':True,'exclude_nan_labels':True,'verbosity':1,'debug_log':'automl_errors.log','debug_flag':None,'enable_ensembling':True,'ensemble_iterations':4,'model_explainability':False,'enable_tf':False,'enable_cache':True,'enable_subsampling':False,'subsample_seed':None,'cost_mode':0,'is_timeseries':False,'metric_operation':'maximize','time_column_name':None,'grain_column_names':None,'drop_column_names':None,'group':None,'target_lags':None,'target_rolling_window_size':None,'max_horizon':None,'country_or_region':None,'seasonality':None,'use_stl':None,'season_trend':None,'season':None}","AMLSettingsJsonString":"{\"name\":\"deal-pipe-automl\",\"subscription_id\":\"ff2e23ae-7d7c-4cbd-99b8-116bb94dca6e\",\"resource_group\":\"RG-ITSMLTeam-Dev\",\"workspace_name\":\"avadevitsmlsvc\",\"path\":\"c:\\\\Users\\\\anders.swanson\\\\Documents\\\\deal\\\\compute\\\\automl\",\"iterations\":4,\"data_script\":\"c:\\\\Users\\\\anders.swanson\\\\Documents\\\\deal\\\\compute\\\\automl\\\\automl_get_data.py\",\"primary_metric\":\"AUC_weighted\",\"task_type\":\"classification\",\"compute_target\":\"deal-pipe-automl\",\"spark_context\":null,\"validation_size\":0.2,\"n_cross_validations\":5,\"y_min\":null,\"y_max\":null,\"num_classes\":null,\"preprocess\":true,\"lag_length\":0,\"max_cores_per_iteration\":1,\"max_concurrent_iterations\":2,\"iteration_timeout_minutes\":5,\"mem_in_mb\":null,\"enforce_time_on_windows\":true,\"experiment_timeout_minutes\":null,\"experiment_exit_score\":null,\"blacklist_models\":null,\"whitelist_models\":null,\"auto_blacklist\":true,\"exclude_nan_labels\":true,\"verbosity\":1,\"debug_log\":\"automl_errors.log\",\"debug_flag\":null,\"enable_ensembling\":true,\"ensemble_iterations\":4,\"model_explainability\":false,\"enable_tf\":false,\"enable_cache\":true,\"enable_subsampling\":false,\"subsample_seed\":null,\"cost_mode\":0,\"is_timeseries\":false,\"metric_operation\":\"maximize\",\"time_column_name\":null,\"grain_column_names\":null,\"drop_column_names\":null,\"group\":null,\"target_lags\":null,\"target_rolling_window_size\":null,\"max_horizon\":null,\"country_or_region\":null,\"seasonality\":null,\"use_stl\":null,\"season_trend\":null,\"season\":null}","DataPrepJsonString":null,"EnableSubsampling":"False","runTemplate":"AutoML"},"ScriptName":null,"Target":"deal-pipe-automl","Tags":{},"RunDefinition":null}
[2019-07-31 19:44:36Z] Start Run in Jasmine Service
[2019-07-31 19:44:36Z] RunId:[3cb258b4-dd21-49a9-a0e7-06d1c448e62f] ParentRunId:[3cb4b7f8-f775-4f68-b239-5f4c3ce65119] ComputeTarget:[AmlCompute]
[2019-07-31 19:44:41Z] Job is running, job runstatus is Starting
[2019-07-31 19:44:45Z] Job is running, job runstatus is Preparing
[2019-07-31 19:44:53Z] Job is running, job runstatus is Preparing
[2019-07-31 19:45:09Z] Job failed, job RunId is 3cb258b4-dd21-49a9-a0e7-06d1c448e62f. Error: {"Error":{"Code":"User","Message":"[ConfigException][User]The provided user script path does not exist.","Target":null,"Details":[],"InnerError":null,"DebugInfo":{"Type":null,"Message":null,"StackTrace":null,"InnerException":null,"Data":null,"ErrorResponse":null}},"Correlation":null}
@purnesh42H assumption:
"/part-00000"is what each of the csvs will be called in their respective PipelineData directories.
Alternative (and more simple take IMHO):1. Save the 4 outputs of train-test-split to the same PipelineData object with different filenames. 2. in `get_data.py` load them all but based on their filenames...Perhaps there's an advantage to isolated
PipelineDataobjects I'm not seeing here, but even if it's better to have 4 of them, you could at least them be files not directories which obviates the need for"/part-00000"in the first place. right??
Yes, you could do that
purnesh42H
on 1 Aug 2019
@sanpil @purnesh42H help I'm going crazy.
Is the
data_scriptargument supposed to be the path to the file relative to thepathparameter? Is it supposed to be a local path? I've been fiddling with it and getting error after error like this. What drives me crazy is that theautoml_get_data.pyis available in the "Snapshot" of the failed run. so it must exist. Right? Right?!?
Here's a code snippet:automl_settings = { "iteration_timeout_minutes": 5, "iterations": 4, "n_cross_validations": 5, "validation_size": 0.2, "primary_metric": 'AUC_weighted', "preprocess": True, "max_concurrent_iterations": 2, "verbosity": 1 } path_relative = os.path.join('.', 'compute','automl') path_full = os.path.realpath(path_relative) attempts = {'full paths': #Error occurred: [ConfigException][User]The provided user script path does not exist. {'path':path_full, 'data_script':os.path.join(path_full,"automl_get_data.py")}, 'full path relative data_script': #Error occurred: [ConfigException][User]The provided user script path does not exist. {'path':path_relative, 'data_script':os.path.join(path_relative,"automl_get_data.py") }, 'full path immediate data_script': #ValueError: path not found .\automl_get_data.py {'path':path_relative, 'data_script':os.path.join('.',"automl_get_data.py") }, 'full path direct data_script': #ValueError: path not found .\automl_get_data.py {'path':path_relative, 'data_script':"automl_get_data.py" }, 'normed full paths': #Error occurred: [ConfigException][User]The provided user script path does not exist. {'path':os.path.normpath(path_full), 'data_script':os.path.normpath(os.path.join(path_full,"automl_get_data.py")) } } automl_config = AutoMLConfig(task = 'classification', debug_log = 'automl_errors.log', compute_target=compute_target, run_configuration=aml_compute, **attempts['full path direct data_script'], **automl_settings ) automl_step = AutoMLStep( name='automl_module', automl_config=automl_config, inputs=[output_x_data, output_y_data], outputs=[metrics_data, model_data], allow_reuse=True)Starting the setup.... WARNING - Received unrecognized parameter: time_column_name None WARNING - Received unrecognized parameter: grain_column_names None WARNING - Received unrecognized parameter: drop_column_names None WARNING - Received unrecognized parameter: group None WARNING - Received unrecognized parameter: target_lags None WARNING - Received unrecognized parameter: target_rolling_window_size None WARNING - Received unrecognized parameter: max_horizon None WARNING - Received unrecognized parameter: country_or_region None WARNING - Received unrecognized parameter: seasonality None WARNING - Received unrecognized parameter: use_stl None WARNING - Received unrecognized parameter: season_trend None WARNING - Received unrecognized parameter: season None The experiment failed. Finalizing run... Logging experiment finalizing status in history service. Cleaning up all outstanding Run operations, waiting 300.0 seconds 3 items cleaning up... Cleanup took 0.0011196136474609375 seconds Traceback (most recent call last): File "setup.py", line 742, in <module> result = setup_run() File "setup.py", line 736, in setup_run num_iterations=num_iterations File "/azureml-envs/azureml_868df23b3dd8a34671c1a6ebc15551fc/lib/python3.6/site-packages/azureml/train/automl/_remote_script.py", line 551, in setup_wrapper logger=logger File "/azureml-envs/azureml_868df23b3dd8a34671c1a6ebc15551fc/lib/python3.6/site-packages/azureml/train/automl/_remote_script.py", line 235, in _prepare_data user_module = _load_user_script(script_path, logger) File "/azureml-envs/azureml_868df23b3dd8a34671c1a6ebc15551fc/lib/python3.6/site-packages/azureml/train/automl/utilities.py", line 102, in _load_user_script raise ConfigException('The provided user script path does not exist.') automl.client.core.common.exceptions.ConfigException: The provided user script path does not exist.
logs/azureml/executionlogs.txtIt's crazy because I can see the path that's passed... what's going on?
"path":"c:\\Users\\anders.swanson\\Documents\\deal\\compute\\automl", "data_script":"c:\\Users\\anders.swanson\\Documents\\deal\\compute\\automl\\automl_get_data.py"[2019-07-31 19:44:35Z] Parsed interface. Will be submitting job to AutoML [2019-07-31 19:44:35Z] AutoML settings={"name":"deal-pipe-automl","subscription_id":"ff2e23ae-7d7c-4cbd-99b8-116bb94dca6e","resource_group":"RG-ITSMLTeam-Dev","workspace_name":"avadevitsmlsvc","path":"c:\\Users\\anders.swanson\\Documents\\deal\\compute\\automl","iterations":4,"data_script":"c:\\Users\\anders.swanson\\Documents\\deal\\compute\\automl\\automl_get_data.py","primary_metric":"AUC_weighted","task_type":"classification","compute_target":"deal-pipe-automl","spark_context":null,"validation_size":0.2,"n_cross_validations":5,"y_min":null,"y_max":null,"num_classes":null,"preprocess":true,"lag_length":0,"max_cores_per_iteration":1,"max_concurrent_iterations":2,"iteration_timeout_minutes":5,"mem_in_mb":null,"enforce_time_on_windows":true,"experiment_timeout_minutes":null,"experiment_exit_score":null,"blacklist_models":null,"whitelist_models":null,"auto_blacklist":true,"exclude_nan_labels":true,"verbosity":1,"debug_log":"automl_errors.log","debug_flag":null,"enable_ensembling":true,"ensemble_iterations":4,"model_explainability":false,"enable_tf":false,"enable_cache":true,"enable_subsampling":false,"subsample_seed":null,"cost_mode":0,"is_timeseries":false,"metric_operation":"maximize","time_column_name":null,"grain_column_names":null,"drop_column_names":null,"group":null,"target_lags":null,"target_rolling_window_size":null,"max_horizon":null,"country_or_region":null,"seasonality":null,"use_stl":null,"season_trend":null,"season":null} [2019-07-31 19:44:35Z] Finished initializing [2019-07-31 19:44:35Z] Set up run properties for Automl [2019-07-31 19:44:35Z] Automl CreateRunDTO {"RunId":"3cb258b4-dd21-49a9-a0e7-06d1c448e62f","ParentRunId":null,"Status":null,"StartTimeUtc":null,"EndTimeUtc":null,"HeartbeatEnabled":false,"Options":null,"CancelUri":null,"Name":null,"DataContainerId":null,"Description":null,"Hidden":null,"RunType":null,"Properties":{"num_iterations":"4","training_type":"TrainFull","acquisition_function":"EI","metrics":"accuracy","primary_metric":"AUC_weighted","train_split":"0.2","MaxTimeSeconds":"300","acquisition_parameter":"0","num_cross_validation":"5","target":"deal-pipe-automl","RawAMLSettingsString":"{'name':'deal-pipe-automl','subscription_id':'ff2e23ae-7d7c-4cbd-99b8-116bb94dca6e','resource_group':'RG-ITSMLTeam-Dev','workspace_name':'avadevitsmlsvc','path':'c:\\\\Users\\\\anders.swanson\\\\Documents\\\\deal\\\\compute\\\\automl','iterations':4,'data_script':'c:\\\\Users\\\\anders.swanson\\\\Documents\\\\deal\\\\compute\\\\automl\\\\automl_get_data.py','primary_metric':'AUC_weighted','task_type':'classification','compute_target':'deal-pipe-automl','spark_context':None,'validation_size':0.2,'n_cross_validations':5,'y_min':None,'y_max':None,'num_classes':None,'preprocess':True,'lag_length':0,'max_cores_per_iteration':1,'max_concurrent_iterations':2,'iteration_timeout_minutes':5,'mem_in_mb':None,'enforce_time_on_windows':True,'experiment_timeout_minutes':None,'experiment_exit_score':None,'blacklist_models':None,'whitelist_models':None,'auto_blacklist':True,'exclude_nan_labels':True,'verbosity':1,'debug_log':'automl_errors.log','debug_flag':None,'enable_ensembling':True,'ensemble_iterations':4,'model_explainability':False,'enable_tf':False,'enable_cache':True,'enable_subsampling':False,'subsample_seed':None,'cost_mode':0,'is_timeseries':False,'metric_operation':'maximize','time_column_name':None,'grain_column_names':None,'drop_column_names':None,'group':None,'target_lags':None,'target_rolling_window_size':None,'max_horizon':None,'country_or_region':None,'seasonality':None,'use_stl':None,'season_trend':None,'season':None}","AMLSettingsJsonString":"{\"name\":\"deal-pipe-automl\",\"subscription_id\":\"ff2e23ae-7d7c-4cbd-99b8-116bb94dca6e\",\"resource_group\":\"RG-ITSMLTeam-Dev\",\"workspace_name\":\"avadevitsmlsvc\",\"path\":\"c:\\\\Users\\\\anders.swanson\\\\Documents\\\\deal\\\\compute\\\\automl\",\"iterations\":4,\"data_script\":\"c:\\\\Users\\\\anders.swanson\\\\Documents\\\\deal\\\\compute\\\\automl\\\\automl_get_data.py\",\"primary_metric\":\"AUC_weighted\",\"task_type\":\"classification\",\"compute_target\":\"deal-pipe-automl\",\"spark_context\":null,\"validation_size\":0.2,\"n_cross_validations\":5,\"y_min\":null,\"y_max\":null,\"num_classes\":null,\"preprocess\":true,\"lag_length\":0,\"max_cores_per_iteration\":1,\"max_concurrent_iterations\":2,\"iteration_timeout_minutes\":5,\"mem_in_mb\":null,\"enforce_time_on_windows\":true,\"experiment_timeout_minutes\":null,\"experiment_exit_score\":null,\"blacklist_models\":null,\"whitelist_models\":null,\"auto_blacklist\":true,\"exclude_nan_labels\":true,\"verbosity\":1,\"debug_log\":\"automl_errors.log\",\"debug_flag\":null,\"enable_ensembling\":true,\"ensemble_iterations\":4,\"model_explainability\":false,\"enable_tf\":false,\"enable_cache\":true,\"enable_subsampling\":false,\"subsample_seed\":null,\"cost_mode\":0,\"is_timeseries\":false,\"metric_operation\":\"maximize\",\"time_column_name\":null,\"grain_column_names\":null,\"drop_column_names\":null,\"group\":null,\"target_lags\":null,\"target_rolling_window_size\":null,\"max_horizon\":null,\"country_or_region\":null,\"seasonality\":null,\"use_stl\":null,\"season_trend\":null,\"season\":null}","DataPrepJsonString":null,"EnableSubsampling":"False","runTemplate":"AutoML"},"ScriptName":null,"Target":"deal-pipe-automl","Tags":{},"RunDefinition":null} [2019-07-31 19:44:36Z] Start Run in Jasmine Service [2019-07-31 19:44:36Z] RunId:[3cb258b4-dd21-49a9-a0e7-06d1c448e62f] ParentRunId:[3cb4b7f8-f775-4f68-b239-5f4c3ce65119] ComputeTarget:[AmlCompute] [2019-07-31 19:44:41Z] Job is running, job runstatus is Starting [2019-07-31 19:44:45Z] Job is running, job runstatus is Preparing [2019-07-31 19:44:53Z] Job is running, job runstatus is Preparing [2019-07-31 19:45:09Z] Job failed, job RunId is 3cb258b4-dd21-49a9-a0e7-06d1c448e62f. Error: {"Error":{"Code":"User","Message":"[ConfigException][User]The provided user script path does not exist.","Target":null,"Details":[],"InnerError":null,"DebugInfo":{"Type":null,"Message":null,"StackTrace":null,"InnerException":null,"Data":null,"ErrorResponse":null}},"Correlation":null}
if your path="./automl", considering your pipeline creation code is ".", then data_script should be just "automl_get_date.py". If you still see such errors, please try with automl version 1.0.33. You can specify in the conda dependencies of run config like this pip_packages=['azureml-train-automl==1.0.33']
purnesh42H
on 1 Aug 2019
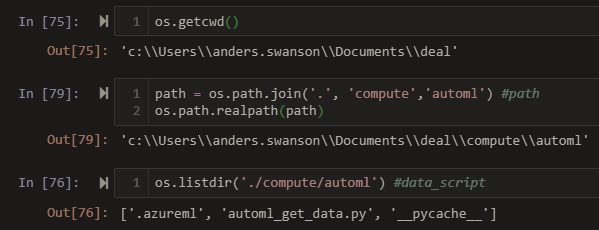
@purnesh42H you mean 1.0.53, the release from last week, right? not 1.0.33 from April 26? I'm currently using 1.0.53.
Your recommendation I had done captured in attempts['full path direct data_script']. But it still throws the same error
swanderz
on 1 Aug 2019
@purnesh42H you mean
1.0.53, the release from last week, right? not1.0.33from April 26? I'm currently using1.0.53.Your recommendation I had done captured in
attempts['full path direct data_script']. But it still throws the same error
No, please try with 1.0.33 as done here https://aka.ms/pl-nyctaxi-tutorial
purnesh42H
on 1 Aug 2019
@swanderz: please wait before you downgrade. Let me investigate the issue a bit more.
sanpil
on 1 Aug 2019
@swanderz can you please try like this
scripts_folder = "./scripts"
automl_config = AutoMLConfig(task = 'classification',
debug_log = 'automl_errors.log',
path = scripts_folder,
compute_target=compute_target,
run_configuration=conda_run_config,
data_script = scripts_folder + "/get_data.py",
**automl_settings)
I just checked this works with the latest version
purnesh42H
on 1 Aug 2019
@sanpil @purnesh42H I was really hoping that your suggestion was going to flag a bug that showed AutoMLStep wasn't compatible with os.path.join(), but I got the same error.
Then, as a hail mary, I thought to rename the file to get_data.py from automl_get_data.py looks like that did the trick... _sigh_
swanderz
on 2 Aug 2019
@j-martens can we please add something to the AutoMLStep data_script parameter that says the script must be named get_data.py or it won't work?
https://docs.microsoft.com/en-us/python/api/azureml-train-automl/azureml.train.automl.automlstep?view=azure-ml-py
swanderz
on 2 Aug 2019
@swanderz - yes, I will open a side task internally to track this. It will go out in the next SDK doc push or the subsequent one. Thanks for tagging me. :-)
 j-martens
on 2 Aug 2019
j-martens
on 2 Aug 2019
@vmagelo - can you tackle this one sooner than later please? :-)
j-martens
on 2 Aug 2019
Ok.
 vmagelo
on 2 Aug 2019
vmagelo
on 2 Aug 2019
These edits went live. Thanks for your report. :-)
j-martens
on 6 Sep 2019
My gut tells me that it's a hacky workaround (at least from a consistency perspective) to ask users to employ environment variables to load data to an
AutoMLStep, but in ALL OTHER Steps to use theargumentsparameter. In addition, the notebook I referenced yet another way to access data.
Going back to this, is there any other way to access a PipelineData object coming from a previous script run step into an AutoML step, other than using the literal name of the environment variable?
Here's an example of the current suggested solution to access PipelineData or DataReferences in an AutoML step:
myDataReference = DataReference(ds, data_reference_name = 'automul_input', path_on_datastore = 'Originations')
trainWithAutomlStep = AutoMLStep(
name='AutoML_Classification',
automl_config=automl_config,
inputs=[myDataReference], #<--
allow_reuse=True)
def get_data():
print(os.environ['AZUREML_DATAREFERENCE_automul_input'])
X_train = pd.read_csv(os.environ['AZUREML_DATAREFERENCE_automul_input'] + "/X_train.csv", header=0)
y_train = pd.read_csv(os.environ['AZUREML_DATAREFERENCE_automul_input'] + "/y_train.csv", header=0)
return { "X" : X_train.values, "y" : y_train.values.flatten() }
The problem in the snippets above is that even though a data reference named automl_input was passed to the AutoML step, we cannot see where it is parsed in the get_data.py script (which means most probably the wrapper around the script parses it out). The main concern here is that the name of the environment variable is hardcoded inside my get_data script, which also needs to match the DataReference name I assigned which requires extra handling and manual checks.
My question is the following: Is there a way I can control and check the value of the DataReference being passed, that way I can check if it's a valid path? or even parse out the path in the environment variable vs. leaving it hardcoded in the script?
@j-martens @purnesh42H
 jadhosn
on 26 Sep 2019
jadhosn
on 26 Sep 2019
Is there a way I can control and check the value of the DataReference being passed, that way I can check if it's a valid path?
@jadhosn, totally agree that it is hacky, and that AutoMLStep() could work better, and I'm 97% certain that @sanpil and team are working on it. My current workaround (here's a quick excerpt) is to use PipelineData objects and print the env vars inside of get_data.py before calling them.
However, I wonder if there's a way to pass an in-memory string to the inputs arg. I'm doubtful @MayMSFT can you think of any other workaround?
swanderz
on 26 Sep 2019
@jadhosn the output paths of steps are not deterministic completely. It get's mounted at runtime and exposed as environment variable i.e. if you choose your mode to be "mount". Hence, you can't control/see that outside of step. On the other hand, the name of the environment variable is deterministic as it follows a format "AZUREML_DATAREFERNCE_
purnesh42H
on 26 Sep 2019
Related issues
swanderz
·
5Comments
 tylercmsft
·
4Comments
tylercmsft
·
4Comments
 ahyerman
·
3Comments
ahyerman
·
3Comments
 vineetgarhewal
·
3Comments
vineetgarhewal
·
3Comments
 jarandaf
·
4Comments
jarandaf
·
4Comments