Required information
We have been running applications in LXD/LXCs environment in prod for quite sometime. The design what we follow is , no swap, and don't over-commit memory.
Our system level graph shows that 40-60% used memory. And almost rest all are cached memory. Now as we run applications and load increases, the OOM killer invokes and kills the JVMs.
I have done some sysctl changes restrict the dirty cache and buffered memory:
vm.dirty_background_ratio : 1
vm.dirty_ratio : 1
vm.dirty_expire_centisecs : 200
vm.dirty_writeback_centisecs : 200
vm.swappiness : 5
vm.max_map_count : 262144
I even tried to tune /sys/fs/cgroup/memory/lxc/memory.kmem.limit_in_bytes but unfortunately its not allowing to edit or change the files.
Can you please suggest if we are going wrong anywhere? Is there any lxc tunable where I can restrict kernel memory in an lxc container.
How we can make applications on LXC more stable?
- Distribution: Ubuntu 16.04
- Distribution version:
- The output of "lxc info" or if that fails:
Name: BXXXXXXXXXX
Remote: unix:/var/lib/lxd/unix.socket
Architecture: x86_64
Created: 2017/02/01 15:09 UTC
Status: Running
Type: persistent
Profiles: default
Pid: 167841
Ips:
eth0: inet 10.1.90.39 BXXXXXXXXXXXX
eth0: inet6 fe80::216:3eff:fe3f:8742 BXXXXXXXXXXXX
lo: inet 127.0.0.1
lo: inet6 ::1
Resources:
Processes: 389
Disk usage:
root: 1.43GB
CPU usage:
CPU usage (in seconds): 8473
Memory usage:
Memory (current): 2.22GB
Memory (peak): 3.32GB
Network usage:
eth0:
Bytes received: 2.79GB
Bytes sent: 149.77MB
Packets received: 971927
Packets sent: 641436
lo:
Bytes received: 2.82MB
Bytes sent: 2.82MB
Packets received: 15200
Packets sent: 15200
driver: lxc
driver_version: 2.0.5
kernel: Linux
kernel_architecture: x86_64
kernel_version: 4.4.0-64-generic
server: lxd
server_pid: 5313
server_version: 2.9.3
storage: zfs
storage_version: 0.6.5.6-0ubuntu15
 siteshbehera
siteshbehera
All 12 comments
We'd at least need "lxc config show --expanded CONTAINER" and the full OOM trace from the kernel when it triggers.
You may want to upgrade to LXD 2.13 as 2.9.3 is outdated and there has been a couple of tweaks to the memory limit handling in 2.13 (not that it seems likely to be related to your problem).
One thing to keep an eye on as a common cause of confusing OOMs is tmpfs usage as this isn't reported as regular process memory but still very much counts towards the cgroup's total memory quota.
 stgraber
on 22 May 2017
stgraber
on 22 May 2017
@stgraber , please find the kernel log attached. Please find the details container o/p below:
architecture: x86_64
config:
boot.autostart: "1"
image.architecture: x86_64
image.description: Ubuntu 16.04 LTS server (20160907.1)
image.os: ubuntu
image.release: xenial
limits.cpu: "2"
limits.memory: 2GB
limits.memory.enforce: hard
limits.memory.swap: "false"
volatile.base_image: fa74d975ce690695daefa927f5d26d77898caaca736c0b33b2d6eef9c1c5e3a1
volatile.eth0.hwaddr: 00:16:3e:23:d2:9b
volatile.idmap.base: "0"
volatile.idmap.next: '[{"Isuid":true,"Isgid":false,"Hostid":100000,"Nsid":0,"Maprange":65536},{"Isuid":false,"Isgid":true,"Hostid":100000,"Nsid":0,"Maprange":65536}]'
volatile.last_state.idmap: '[{"Isuid":true,"Isgid":false,"Hostid":100000,"Nsid":0,"Maprange":65536},{"Isuid":false,"Isgid":true,"Hostid":100000,"Nsid":0,"Maprange":65536}]'
volatile.last_state.power: RUNNING
devices:
eth0:
host_name: BXXXXXXXXXX
name: eth0
nictype: bridged
parent: br0
type: nic
root:
path: /
pool: lxd
size: 2GB
type: disk
shared_log_1:
path: /LogBackups
source: /LogBackups/bdXXXX-haproxy/BXXXXXXXXXX/LogBackups
type: disk
ephemeral: false
profiles:
- default
Here are some of my doubts:
1) I was going through this link. If my understanding is true, the container memory is choked with buffered cache and hence cgroup in hypervisor will call for a OOM killer to flush out or make more space for kernel to keep page cache.
2) Can we somehow call make kernel call "sync" so instead of calling OOM killer it can call sync and flush out cache?
3) Looks like the cache at hypervisor is very high compared to cache available at container level. Hence container must do call sync once there is a memory crunch at container level rather than calling OOM killer.
4) As a workaround we have added the following setting :
lxc config set XXXXXXXXXX raw.lxc "lxc.cgroup.memory.kmem.limit_in_bytes = 1073741824"
I can verify that the limit has been set at hypervisor cgroup level. But doubt is by limiting kernel memory to 1G which of teh following scenerio will occur
a) OOM killer be invoked cgrp manager as kernel memory gets filled.
b) OS in container will freeze (chances are less as os is readonly)
c) sync syscall will be called by cgroup ?
We are closely monitoring the containers and will update what we see on ground level.
siteshbehera
on 24 May 2017
@siteshbehera did you upgrade to LXD 2.13?
We had this commit included in it: 33bb0bc674ab3c4c578454751dee42d9a2a8449a
My understanding is that having a soft limit set at 90% of the hard limit will help in exactly this case, by creating memory pressure that the kernel can handle ahead of the OOM killer running.
stgraber
on 24 May 2017
@stgraber :
We upgraded to LXD 2.13. Now the cache/buffer space seems to be more tamed.
We also applied raw.lxc: lxc.cgroup.memory.kmem.limit_in_bytes = 1073741824 to the container before upgrade .
Before upgrade :
BXXXXXXXXXX:
total used free shared buff/cache available
Mem: 8192 5491 366 3008 2334 366
Swap: 16383 350 16033
After Upgrading :
BXXXXXXXXXX:
total used free shared buff/cache available
Mem: 8192 4826 3196 2464 169 3196
Swap: 16383 333 16050
Can you please help in understanding how cgroups interact with kernel now? Does sync call gets invoked once 90% of container memory is used?
How do we set a soft limit set at 90% of the hard limit as mentioned by you earlier? Is there any config to set the soft limit?
siteshbehera
on 24 May 2017
LXD 2.13 will automatically set soft_limit_in_bytes to be 90% of limit_in_bytes if memory limits are set in hard mode. My understanding is that this creates some amount of memory pressure at the kernel level which will cause things like buffers to be flushed at that point rather than when hitting 100%.
cgroups are a kernel construct that userspace has relatively little control over. All LXD does is set those limits, then it's up to the kernel on how to enforce it. The behavior I describe above is what's been reported by some of our users and certainly appears to be the case on most Linux kernels. Choice of scheduler, use of hugepages, ... may all alter this behavior though, so it's hard to come up with one clear explanation.
kmem.limit_in_bytes is certainly an interesting one, though we've been unable to compute a sane value for it. It also doesn't help that older kernels have bugs which will cause the measured kernel memory to always go up and never be freeed, eventually causing an erroneous OOM to be triggered.
stgraber
on 24 May 2017
We have set kmem.limit_in_bytes assuming cache/buffered memory will be always under kernel memory space. Is this assumption true? Will there be any use case where any user process can write directly to cached memory? Will the cache memory can only be controlled by kernel or a user space process can control it?
siteshbehera
on 24 May 2017
I have honestly no idea whether the vfs cache would count as kernel memory. It would make finding reasonable kernel limits very difficult if it was.
You can't map cached memory to your program but you can certainly try to get the kernel to cache stuff for you by say opening and reading an entire blob of data.
The go to reference for the memory cgroup is: https://www.kernel.org/doc/Documentation/cgroup-v1/memory.txt
I'm closing this issue since as of LXD 2.13 (and LXD 2.0.10), it appears the soft memory limit we put on top of the hard memory limit is enough to get the kernel to free cached memory before the OOM triggers.
stgraber
on 25 May 2017
Thanks a lot clarification and help. Appreciate it.
siteshbehera
on 25 May 2017
Hi @stgraber,
I've just read your comment above:
It also doesn't help that older kernels have bugs which will cause the measured kernel memory to always go up and never be freeed, eventually causing an erroneous OOM to be triggered.
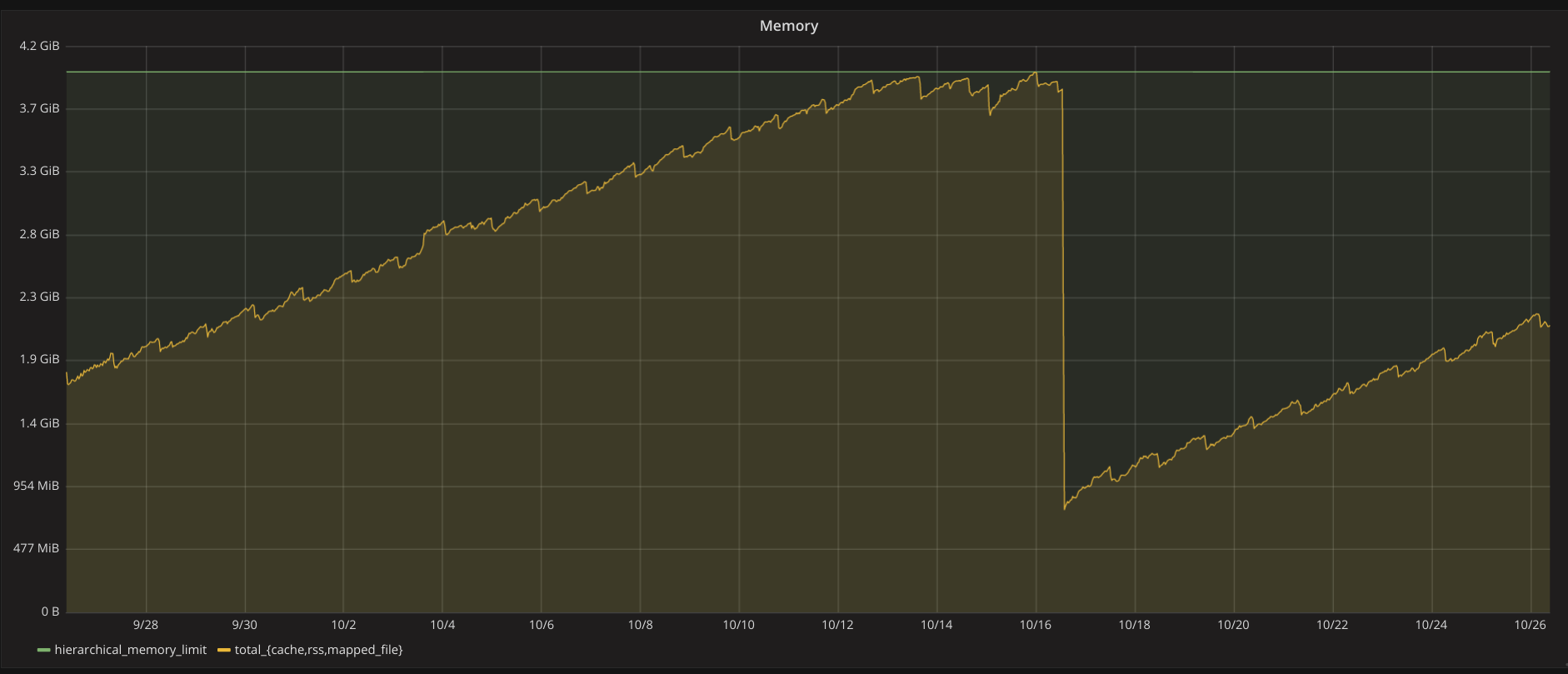
Could you point me to more information about this please? We're experiencing similar symptoms, but I'm struggling to find the root cause. You can see the effect on the attached graph of used memory; the drop in the middle is caused by a restart of the container, which is the only way to free the memory again.
I'm aware of this lxcfs issue, but the symptom I'm seeing are more like a slow memory leak.
We're running lxd 2.17, lxcfs 2.0.7, on kernel 4.11.0.
Any advice would be greatly appreciated!
 cronnelly
on 26 Oct 2017
cronnelly
on 26 Oct 2017
The kmem accounting issue was with much older kernels than what you're running, I'd expect a 4.11 kernel to be fine. That is, unless there is an actual kernel resource leakage somehow.
I don't really have much more details on this, other than it being mentioned rather repeatedly every time the memory cgroup came up in kernel discussions at various conferences.
stgraber
on 26 Oct 2017
Many thanks for your response, @stgraber.
My colleague @panfantastic finally got to the bottom if this. Quite simply, the default Ubuntu 16.04 container images are configured to write journald logs to a tmpfs mounted under /run/log/journal/. The default config rotates these files, but never actually sets a retention policy. So they just keep slowly
eating up available memory.
This is a quick fix, but we'll be looking to switch all containers to use on-disk logs:
echo "MaxRetentionSec=1week" >> /etc/systemd/journald.conf; systemctl restart systemd-journald.service
Oh, crap, completely forgot about that one. I do remember debugging this very problem with someone else some months ago...
stgraber
on 1 Nov 2017
Related issues
 tebanep
·
5Comments
tebanep
·
5Comments
 rrva
·
5Comments
rrva
·
5Comments
 kp3nguinz
·
5Comments
kp3nguinz
·
5Comments
 fwaggle
·
4Comments
fwaggle
·
4Comments
 jsnjack
·
3Comments
jsnjack
·
3Comments
Most helpful comment
Oh, crap, completely forgot about that one. I do remember debugging this very problem with someone else some months ago...