Longhorn: how to recover from a node crash
I have the following setup:
- node1: all roles
- node2: all roles
- node3: etcd+control
I installed rancher and tested it with a statefulset and a deploymet + volume on node2. Rancher created volumes that where mounted on node2 and had replicas on node1.
After the the shutdown of node2, the deployments tried to recreate themself, but without success. Whenever I try to start a deployment with the volumes its stuck in containerCreating (without the volumes it works fine).
On the Nodes tab it shows node2 down:

on the Volume tab it shows the volumes as "Healthy":

In the volume view it shows all replicas running
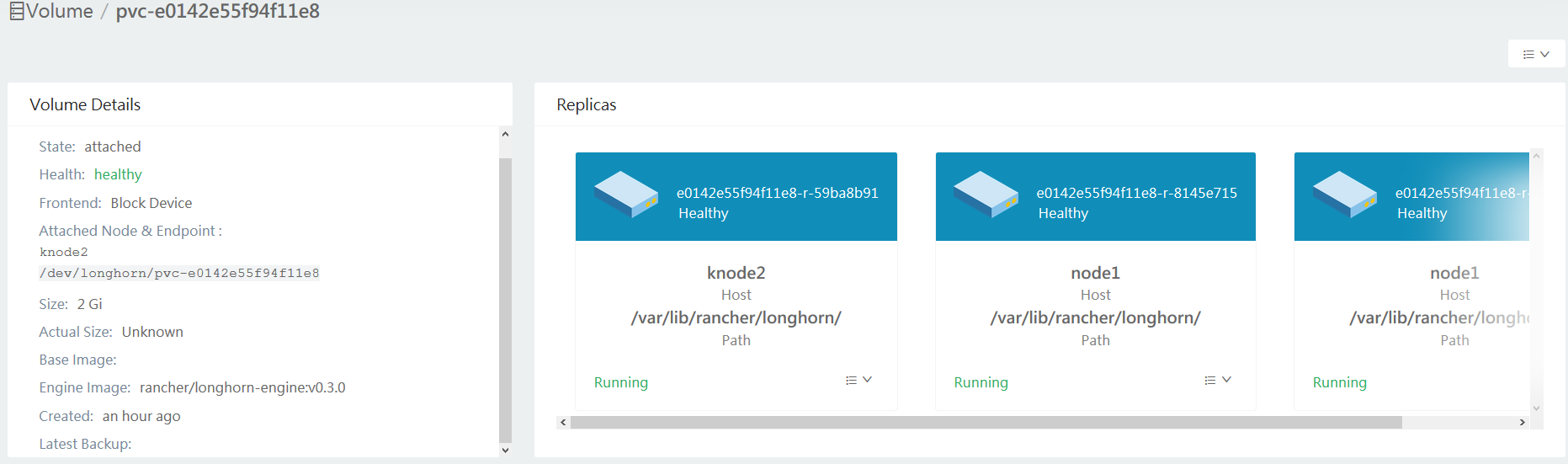
My question is: what is the expected behaviour and can i fix the volumes manually ?
 XzenTorXz
XzenTorXz
All 4 comments
also on the volume view it shows the error
Request failed with status code 502
from time to time, not sure if this is related.
XzenTorXz
on 6 Dec 2018
@XzenTorXz It's a bug. We aware of this as in https://github.com/rancher/longhorn/issues/199 and Kubernetes SIG Storage also aware of some unreliability of the workload migration with storage. We're working on fixing it, which will also involve some upstream Kubernetes work as well.
In the meantime, if you didn't hit the Kubernetes bug of https://github.com/rancher/longhorn/issues/199 , you can stop the workload and manually detach the volume. Restart the workload again should allow it to continue. If you hit the bug mentioned above, you would need to delete the csi-attacher-0 manually to allow statefulset to recreate, thus restore Kubernete's ability to attach the volume.
The error code you see is a symptom of what Kubernetes got wrong. The Kubernetes LB suppose to skip the node that's down, but it's still routing the request to the down node sometimes, thus you will see status code 502. We got some ideas on how to mitigate it, and it will be in the part of the fix for the issue.
 yasker
on 6 Dec 2018
yasker
on 6 Dec 2018
I had to delete node2 in kubernetes and all replicas of the volumes hosted on node2, then I could delete node2 in longhorn. And It reattached everything just fine.
XzenTorXz
on 7 Dec 2018
Fixed in https://github.com/rancher/longhorn-manager/commit/8f3b4bc89c5b2c914da3e32a6c19db930095115a.
Also, see https://github.com/rancher/longhorn/blob/v0.4/docs/node-failure.md for upcoming v0.4 releases.
yasker
on 5 Feb 2019
Related issues
 saidghamra
·
3Comments
saidghamra
·
3Comments
 lucernae
·
3Comments
yasker
·
7Comments
lucernae
·
3Comments
yasker
·
7Comments
 anouarchattouna
·
4Comments
anouarchattouna
·
4Comments
 excieve
·
4Comments
excieve
·
4Comments
Most helpful comment
@XzenTorXz It's a bug. We aware of this as in https://github.com/rancher/longhorn/issues/199 and Kubernetes SIG Storage also aware of some unreliability of the workload migration with storage. We're working on fixing it, which will also involve some upstream Kubernetes work as well.
In the meantime, if you didn't hit the Kubernetes bug of https://github.com/rancher/longhorn/issues/199 , you can stop the workload and manually detach the volume. Restart the workload again should allow it to continue. If you hit the bug mentioned above, you would need to delete the
csi-attacher-0manually to allow statefulset to recreate, thus restore Kubernete's ability to attach the volume.The error code you see is a symptom of what Kubernetes got wrong. The Kubernetes LB suppose to skip the node that's down, but it's still routing the request to the down node sometimes, thus you will see
status code 502. We got some ideas on how to mitigate it, and it will be in the part of the fix for the issue.