Littlefs: LFS Corruption - Invalid Look Ahead Buffer (super block directory pointer and CTZ pointer conflict)
@geky,
This is more or less a Cry for Help. I have experienced my file system being reformatted due to -84 LFS_ERR_CORRUPT and I've been trying to understand what is going wrong for the last week.
Our file system is running on 511 blocks of size 4096. I have our block wear-leveling set to 500 and the CACHE_SIZE is 1024. Our max reads can be 1024 but our maximum program size is 256.
I'd like to start by learning a bit about the super block (This is not the piece that is causing the corruption on mount). I'll post 2 images for our block 0 and block 1. What I see is that block 0 has a revision of 0x0B but seems to be "corrupted". Block 1 has a revision of 0x0C and has all of the data that I would expect.
Do you know why block 0 looks the way it does?
Block 0 looks corrupted
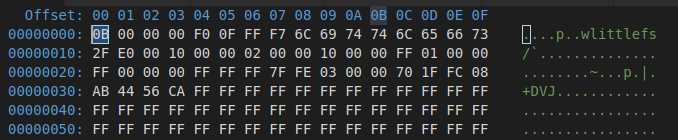
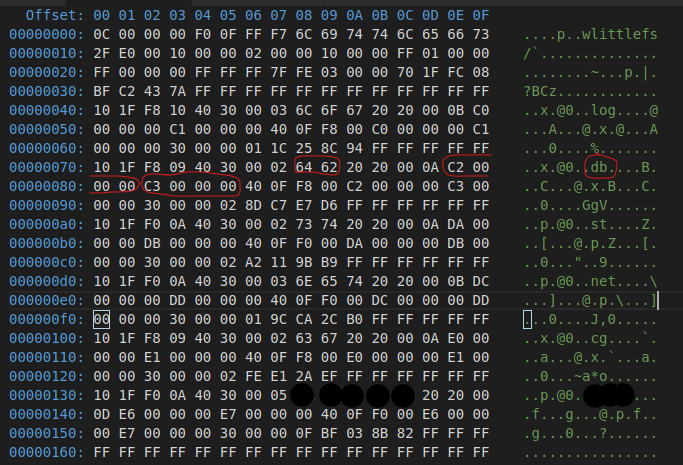
Block 1 seems to be what I'd expect. Circled red is the directory that failed to mount
Getting into the corruption piece
I can see that the superblock 1 said that directory "db" lives at 0xC2 / 0xC3. It turns out that when I look at those 2 blocks, I see the left overs of a CTZ file that is frequently written (I know that blocks are erased before being written to, therefore it is expected that a CTZ file would be littered through external flash). ~I are currently investigating whether or not the file system ever placed the CTZ file in blocks 0xC2/ 0xC3.~ Using debug.py I looked at the directory of the CTZ file in question and have confirmed that the last 2 valid points do indeed point to 0xC2 and 0xC3. Therefore the file system in its current state believe that the CTZ used to live at 0xC2 and currently lives at 0xC3 and the superblock believes that our db directory metadata pair lives at 0xC2 / 0xC3. Seeming to be more like an LFS issue...

HERE IS THE GOTCHA
After extracting the entirety of external flash I was able to find the db directory but it lived in blocks 0x7D/0x7E. The current revision of these blocks are 0x00004743 (18243d) and 0x00004742 (18242d). NEITHER of which are close to being divisble by 500. Therefor I had determined that the block wear-leveling was NOT the issue. Do you agree?
@geky, your time is greatly appreciated,
Thrasher
 thrasher8390
thrasher8390
All 14 comments
@geky, I just had a thought that maybe the lookahead buffer is getting corrupted. I'm going to start learning about how that works.
My assumption is currently that the buffer is populated with "free blocks" during the mount. Our lookahead buffer is 512 bits so it covers our entire flash chip. I suppose it is possible that some data could have been corrupted there which would then cause lfs to think that 0xC2 and 0xC3 are "free blocks".
thrasher8390
on 12 Mar 2020
@geky, I believe I found root cause.
The issue lives in lfs_alloc. During the initial traverse it is possible for the traverse to fail due to IO_ERRORS. Today, if the traverse fails the free.buffer is left in an invalid state but free.size has already been initialized. Therefore the next time that lfs_alloc is called, it will result in finding a "free block" even though the whole lookahead buffer is corrupted / invalid.
I was able to recreate this by simply adding a breakpoint to int err = lfs_fs_traverse(lfs, lfs_alloc_lookahead, lfs); and skipping the traverse call completely. This results in hitting the err condition which also results in the look_ahead_buffer being it's initialized value (all 0's). The next time the program tries to write the ctz file, lfs used a free block and overwrote other valid information.
The fix that I'm testing out now is setting free.i and free.size = 0 during the err condition.
thrasher8390
on 16 Mar 2020
@geky, can you make me a contributor?
thrasher8390
on 17 Mar 2020
Does your fix change anything in the absence of IO errors? I'm working with the fuzzer to try and discover problems. I'm not simulating any errors when writing to flash (or reading from it).
 pjsg
on 19 Mar 2020
pjsg
on 19 Mar 2020
Hi @thrasher8390, sorry for not seeing this until now. Currently catching up from the last two weeks. Glad you were able to find the source of the issue.
It looks like errors in traverse aren't well tested at the moment, I'll see if I can fix that.
@geky, can you make me a contributor?
I don't believe you need any permissions to create a pull request. The "contributor" tag is just a tag GitHub awards to users who have had PRs accepted.
 geky
on 20 Mar 2020
geky
on 20 Mar 2020
@geky, I'll try to push again. I kept getting a "You don't have permissions to push to this repository"
remote: Permission to ARMmbed/littlefs.git denied to thrasher8390.
fatal: unable to access 'https://github.com/ARMmbed/littlefs.git/': The requested URL returned error: 403
I even tried to clone and push to a repo that I own and I was able to do that. For a moment I thought maybe the credentials were incorrect on my computer.
@pjsg, I'm not familiar with "The Fuzzer". If there are no IO errors then my change will NOT affect your code. This issue has only been replicated due to an IO error during traversal. Does this answer you question?
thrasher8390
on 24 Mar 2020
@thrasher8390 Yes -- that helps. Thank you.
The way that you do a pull request is to fork this repo into your own github account (use the fork button at the top of this page). Then you push your changes into your copy of the repo. Then you can do a pull request from your repo into this repo.
pjsg
on 24 Mar 2020
@pjsg, Really!?!? That seems so strange. Is that a specific setting for this repo? Why can't I just make a branch and this create a PR from my branch -> master?
Maybe I'm just a noob. Following this link now. -> https://akrabat.com/the-beginners-guide-to-contributing-to-a-github-project/
thrasher8390
on 24 Mar 2020
That is just the way that github works -- in this way you don't need to be
a contributor to the main repo (and typically only the original author is a
contributor). For example, if you look at
https://github.com/ARMmbed/littlefs/pull/397 you will see that this is a PR
where
roykuper13 https://github.com/roykuper13 wants to merge 1 commit into
ARMmbed:master https://github.com/ARMmbed/littlefs from roykuper13:
add-lto-flag https://github.com/roykuper13/littlefs/tree/add-lto-flag
Philip
On Tue, Mar 24, 2020 at 8:54 AM Derek Thrasher notifications@github.com
wrote:
@pjsg https://github.com/pjsg, Really!?!? That seems so strange. Is
that a specific setting for this repo? Why can't I just make a branch and
this create a PR from my branch -> master?—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/ARMmbed/littlefs/issues/394#issuecomment-603221280,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/AALQLTKXMZSL6RJTESMZA2DRJCUQFANCNFSM4LGN3AJQ
.
pjsg
on 24 Mar 2020
Thanks @pjsg, I had no idea!
I got the PR up! https://github.com/ARMmbed/littlefs/pull/401.
I also created a PR with contributing laws! (@pjsg)
https://github.com/ARMmbed/littlefs/pull/403
thrasher8390
on 24 Mar 2020
Ran into some hiccups getting a test in place: This is the first test case around truly "arbitrary" block device errors (as opposed to expected errors from wear). The bug was also a bit tricky to reproduce, not only do we need a block device error during scan but we also need normally-in-use blocks to be in the next lookahead scan.
Here's a test case the reproduces the bug. You can run the default tests locally with make test or the specific test case with make test_alloc#8:
https://github.com/ARMmbed/littlefs/commit/1c5bae6d30e8c78bb4a84b14ecf0319b27dd92fa
I pushed it up on this branch with your fix cherry-picked. It passed testing with the default tests, though I'm curious if CI will catch anything else. It has quite a few more configurations, though it takes ~1 hour to get through everything.
https://github.com/ARMmbed/littlefs/tree/test-revamp-lookahead-buffer-corruption
You can see the running CI from here:
https://github.com/ARMmbed/littlefs/branches
A quick note with GitHub, if you update a branch, any PRs based on that branch are automatically updated. So you could force-push ARMmbed:test-revamp-lookahead-buffer-corruption to thrasher8390:bugfix/thrasher8390/issue-394-lookahead-buffer-corruption if you wanted to update https://github.com/ARMmbed/littlefs/pull/401.
I'm going to want to bring in the fix and test at the same time, but am fairly use to compensating for contributor's different PR habits so don't worry if it all ends up in a mess as git often does.
Reviewing the PRs, thanks for those!
geky
on 25 Mar 2020
The way that you do a pull request is to fork this repo into your own github account
Oh, it's also worth noting that my use of littlefs's branches is a bit atypical. I could also have a personal fork of littlefs (geky/littlefs) that I develop on before creating PRs to the core repo (armmbed/littlefs). But I can't do that currently since armmbed/littlefs was original geky/littlefs before moving to the armmbed org. I could look into using a fork with a different name, but I don't want to accidentally break GitHub's redirects from the rename.
Hmm, an alternative model would be to hand out membership roles to developers so we could share a development branch. Unfortunately that would get complicated with littlefs being a part of armmbed, which is a larger organization.
geky
on 25 Mar 2020
I don't want to accidentally break GitHub's redirects from the rename.
And I may have just accidentally broken it...
geky
on 30 Mar 2020
Oh _wow_. Apparently if you overwrite a previously transferred repo (geky/littlefs) and then delete it, it will restore the previous redirect (geky/littlefs->armmbed/littlefs). I did not expect that to work.
geky
on 30 Mar 2020
Related issues
 PoppaChubby
·
6Comments
PoppaChubby
·
6Comments
 husigeza
·
9Comments
husigeza
·
9Comments
 FrederikTB
·
4Comments
FrederikTB
·
4Comments
 FreddyBZ
·
3Comments
FreddyBZ
·
3Comments
 zhabl
·
12Comments
zhabl
·
12Comments
Most helpful comment
Oh _wow_. Apparently if you overwrite a previously transferred repo (geky/littlefs) and then delete it, it will restore the previous redirect (geky/littlefs->armmbed/littlefs). I did not expect that to work.