Littlefs: Automated release process is really confusing
The releases page lists v1.4 as released 27 days ago. Yet it contains commits made just 5 days ago. From what I understand, the CI build updates the release and the git tags whenever the build succeeds and the LFS version macro is not changed. If the LFS version macro is changed, the CI bot creates a new release. With this approach the latest released sources are a constantly moving target and when I report that "I have a problem with v1.4" absolutely no one will know which version is that, unless I know exactly when I downloaded the files or unless I want to compare all the files with each commit.
Therefore my proposal would be to change this scheme to something like this:
- for normal builds (from master branch) CI bot only publishes releases with "pre-release" checkbox selected, all of them are called like "v1.5-development" or something like this (however if you ask me this is not needed at all, you can download latest sources otherwise and the master branch should compile successfully at all times);
- CI bot never touches git tags;
- you manually add a tag whenever you want to release something;
- for builds out of tags CI bot publishes normal releases;
Let me know what you think, as I find the current scheme really confusing and only today I finally understood what is going on here.
 FreddieChopin
FreddieChopin
All 17 comments
Thanks for the feedback, I'd be happy to see how we can improve releases.
The main problem I have with marking releases as they come: Let's say littlefs is on v1.4, and someone finds a bug (maybe the filesystem deletes itself if the file name is in iambic pentameter). But that's ok because we can fix it. But then what do we do with the bug fix? Do we need to create a v1.5 for the bug fix? Or does only master contain bug fixes?
Another problem is: When do we actually make a release? If bug fixes just go on master, at what point do we go "ok, this is probably stable enough, lets make a release".
You are right that with the current system v1.4 is a moving target. But this is where git hashes come in, which already do a great job at uniquely identifying the code base, even outside of releases.
Maybe it would help to use the hash in the version name? So instead of v1.4 we label it v1.4.7e67f93? The bot could do this automatically, and that would give anyone a name for a fixed point in the history. Thoughts?
 geky
on 18 Jul 2018
geky
on 18 Jul 2018
The main problem I have with marking releases as they come: Let's say littlefs is on v1.4, and someone finds a bug (maybe the filesystem deletes itself if the file name is in iambic pentameter). But that's ok because we can fix it. But then what do we do with the bug fix? Do we need to create a v1.5 for the bug fix? Or does only master contain bug fixes?
There are many approaches. For example you may do it like this:
- assume that littlefs is already at v2.3, which is not compatible with v1.4, which is the last of v1.x series;
- implement the fix in master;
- create a "v1.4.x" branch;
- cherry-pick the fix to this branch;
- tag and release as v1.4.1;
Another problem is: When do we actually make a release? If bug fixes just go on master, at what point do we go "ok, this is probably stable enough, lets make a release".
This is a question which you must answer yourself (; But please note that I'm fine with the bot making the releases, as long as it does _NOT_ modify previous tags/releases, because this is confusing. So whenever you feel like bumping the version number (once a month, once a feature, whenever you like, ...) just do it, add the tag, and the bot will make the release. And also mark the master-releases as "pre-release" with some clear name like "vX.Y-development".
To reiterate - I'm fine with the automated process, just not fine with these 2 items:
- modifying already published releases;
- not-marking the latest automated release as "pre-release";
Mostly the first one, the second one I could live with, as this is just a visual distinction on github.
But this is where git hashes come in, which already do a great job at uniquely identifying the code base, even outside of releases.
Unless you just downloaded the .tar.gz or .zip file (from the "Releases"), where there's no git repo and no git hashes (;
Maybe it would help to use the hash in the version name? So instead of v1.4 we label it v1.4.7e67f93? The bot could do this automatically, and that would give anyone a name for a fixed point in the history. Thoughts?
Also an option, but in this case it should (IMHO) still be marked as pre-release, and you'd have to teach the bot to remove previous development releases (unless you really want to have hundreds of them by the end of the year (; ).
I'm just a believer that released source should be frozen. If a release is broken and was already published (longer than a few seconds), do not modify it. If it's really broken (for example some files are corrupt or whatever) - delete it from the website. If it has bugs - fine, every software has them, that's why you're still developing it instead of calling it "finished and complete". In any case just release the new version with next major/minor/patch number.
FreddieChopin
on 18 Jul 2018
Maybe it would help to use the hash in the version name? So instead of v1.4 we label it v1.4.7e67f93?
I would suggest following the semantic versioning rules (see https://semver.org/) and so this would be written as v1.4.0+7e67f93
 dpgeorge
on 19 Jul 2018
dpgeorge
on 19 Jul 2018
I would suggest following the semantic versioning rules (see https://semver.org/) and so this would be written as v1.4.0+7e67f93
Oh good to know, didn't know there was a semver rule for "build metadata". Although in this case the hash is completely replacing the patch number, so would it still make sense? Notating it as v1.4.7e67f93 also implies the "7e67f93" is not optional.
@dpgeorge do you generally agree with @FreddieChopin?
Sorry if my responses are slow, I _am_ interesting in seeing where this goes.
Unless you just downloaded the .tar.gz or .zip file (from the "Releases"), where there's no git repo and no git hashes (;
Though this would be fixed by using v1.4.7e67f93 as the name for releases.
you'd have to teach the bot to remove previous development releases (unless you really want to have hundreds of them by the end of the year (; ).
I was thinking the bot would remove the old release as soon as it makes the new one. So nothing would change with the current system except the hash would be included in the release name.
I'm just a believer that released source should be frozen. If a release is broken and was already published (longer than a few seconds), do not modify it. If it's really broken (for example some files are corrupt or whatever) - delete it from the website. If it has bugs - fine, every software has them, that's why you're still developing it instead of calling it "finished and complete". In any case just release the new version with next major/minor/patch number.
This holds true for commits, but I don't understand why it should hold true for versions. IMO the version marks a set of features, the patch number or hash both mark the specific version of the code base.
I could have the bot create a new patch number for each commit, but that seems redundant (and kinda annoying to program).
There are many approaches. For example you may do it like this:
- assume that littlefs is already at v2.3, which is not compatible with v1.4, which is the last of v1.x series;
- implement the fix in master;
- create a "v1.4.x" branch;
- cherry-pick the fix to this branch;
- tag and release as v1.4.1;
Correct me if I'm wrong, but isn't this the same as using a patch number instead of a hash? Other than pre-releases.
To reiterate - I'm fine with the automated process, just not fine with these 2 items:
- modifying already published releases;
I'm still not sure what is wrong with modifying releases. I get that it can be confusing, but it seems like a better alternative to creating many small patch releases. Am I missing another use case for immutable releases?
Oh, is it important to you guys that you get notifications for patch releases? Although if this happened every commit that would be annoying.
- not-marking the latest automated release as "pre-release";
I'm still not sure when to change a release from "pre-release" to "real release". My current approach is to change it when the next feature comes out, but this means the "real release" is always going to be the previous feature. And if no features get developed for a while, the most recent changes to the repo will be stuck in "pre-release" mode.
I could chose an arbitrary time, say I wait 1 month for a release, but would you be ok waiting a month to get a bug fix?
For more context, this may be a different problem than littlefs, but I'm also looking at applying this script to about 15 small driver repositories, which get updated rarely and don't have an owner or schedule to decide when changes have matured to be "release worthy".
geky
on 19 Jul 2018
Although in this case the hash is completely replacing the patch number, so would it still make sense?
I don't think so, since point 2 of semver https://semver.org/#spec-item-2 states that patch must be a non-negative integer that increases.
dpgeorge
on 19 Jul 2018
That's fair, although I think v1.4 is already invalid semver (no patch version). If we don't have a patch version do you think v1.4+7e67f93 would then be the best name to use?
geky
on 19 Jul 2018
@dpgeorge do you generally agree with @FreddieChopin?
Yes I do agree with their comments. It is confusing if a version tag like v1.4 is constantly moving.
My humble suggestion would be to fully adopt semver and then tag releases yourself when you feel it is time. For patch level changes that could be straightaway, or after a few days or a week to let it settle down. master (if not tagged) should always be considered unstable and broken, but users can use it if they want simply by taking the code at that point.
In MicroPython (note that we don't use semver) our version tags look something like v1.9.4-384-ga8736e5c3. That means that it's been 384 commits since version 1.9.4, and the git hash is given at the end to easily look up the commit. Anyone reporting a bug can report the version string and we instantly know where their build came from.
dpgeorge
on 19 Jul 2018
I had a nice post edited here, but I must have forgotten to send it... Damn...
Shorter version goes like this. People (including me) expect a release or a git tag to be frozen. I don't have a good explanation why is that, but it's just like that (; I've never come across a project which would do otherwise, that's why for the whole week since I approached littlefs I was super confused by the releases, until I finally understood what was going on. If you feel the need to have latest master packaged as a release, then the version with a git hash is definitely better than constantly updating git tags. However I think this is redundant, as if someone wants to or has to use master, then he/she can just clone the repo or download the snapshot from repo's main page. I'd still "release" the previous major/minor version as a regular release (for example the latest v1.4+x should be renamed to v1.4 when you first publish v1.5+y). If you want to have things packaged, just call it "nightly", "unstable", "testing", "development" or sth like this.
FreddieChopin
on 19 Jul 2018
Yes I do agree with their comments. It is confusing if a version tag like v1.4 is constantly moving.
Good to know, I wanted to make sure I was in the minority. Though I have heard others comment that the current process is confusing.
I'm convinced now the release process does need to change, though I still need to work out the details.
Here's what I'm thinking:
- Every commit that lands on master bot gives it an incrementing patch release and tag
- If the commit contains a new feature, we bump the minor version, bot gives it an incrementing minor release and tag
So tags are not modified, but there is also no waiting-for-release period. Also, when someone goes to the releases page they would see the more recent patch releases.
Thinking about this model, master isn't a development branch but actually the release branch. I'm thinking this will work well for littlefs and smaller repos because there's not really a settling period after most features and most of the development work occurs on branches and PRs. If I'm wrong and littlefs grows to where this isn't true, we can always switch to manual releases in the future.
Thoughts?
geky
on 19 Jul 2018
sounds ok for me (;
FreddieChopin
on 19 Jul 2018
master (if not tagged) should always be considered unstable and broken, but users can use it if they want simply by taking the code at that point.
if someone wants to or has to use master, then he/she can just clone the repo or download the snapshot from repo's main page.
With small repos, my assumption is that master is more likely be stable than previous releases. Simply because master contains the most bug fixes and small repos have lower feature-churn.
It sounds like most of the reasons for not having master attached to a release are to create the settle period for features.
Automatically creating releases for master may end up not working for littlefs, but I would like to give it a try. The script would be a big help with managing a lot of small repos if it works well, though littlefs may not fall into this category.
geky
on 19 Jul 2018
It sounds like most of the reasons for not having master attached to a release are to create the settle period for features.
If you ask me, my main concern is modification of released sources and git tags. Wherever the release actually came from (master, special branch, outer space, ...) does not matter much. For my own projects I do releases from master (however I do it manually and not so frequently (; ). I know projects who do this from special branches. I guess doing it out from master is less work, especially when master is considered to be compilable and working correctly (thanks to CI and proper process).
FreddieChopin
on 19 Jul 2018
Every commit that lands on master bot gives it an incrementing patch release and tag
... master isn't a development branch but actually the release branch.
Yes that sounds good. So PRs and branches are checked thoroughly before merging to master.
dpgeorge
on 20 Jul 2018
I have a prototype working over here to mess around with:
https://github.com/geky/littlefs-test-repo/releases
I'm going to test it a bit more then create a PR.
The only different thing is that the release notes get cut-and-pasted into the most recent version of a minor release. I've tested URLs and tags and it doesn't seem to mess with the immutability of the versions.
Also I thought about adding branches for v1.5 and v1 (major and minor branches). But I couldn't think of a good reason for having them.
geky
on 25 Jul 2018
Also I thought about adding branches for v1.5 and v1 (major and minor branches). But I couldn't think of a good reason for having them.
No need to add them now. If such branch ever becomes needed, you can do it then in no time (;
The only different thing is that the release notes get cut-and-pasted into the most recent version of a minor release.
I think it would be better if they would be copy&pasted or just generated from scratch. This way the text of previous releases also stays unchanged. Personally I see no reason to alter the text of previous releases, so that's why I'm mentioning it.
FreddieChopin
on 25 Jul 2018
Hmmm,
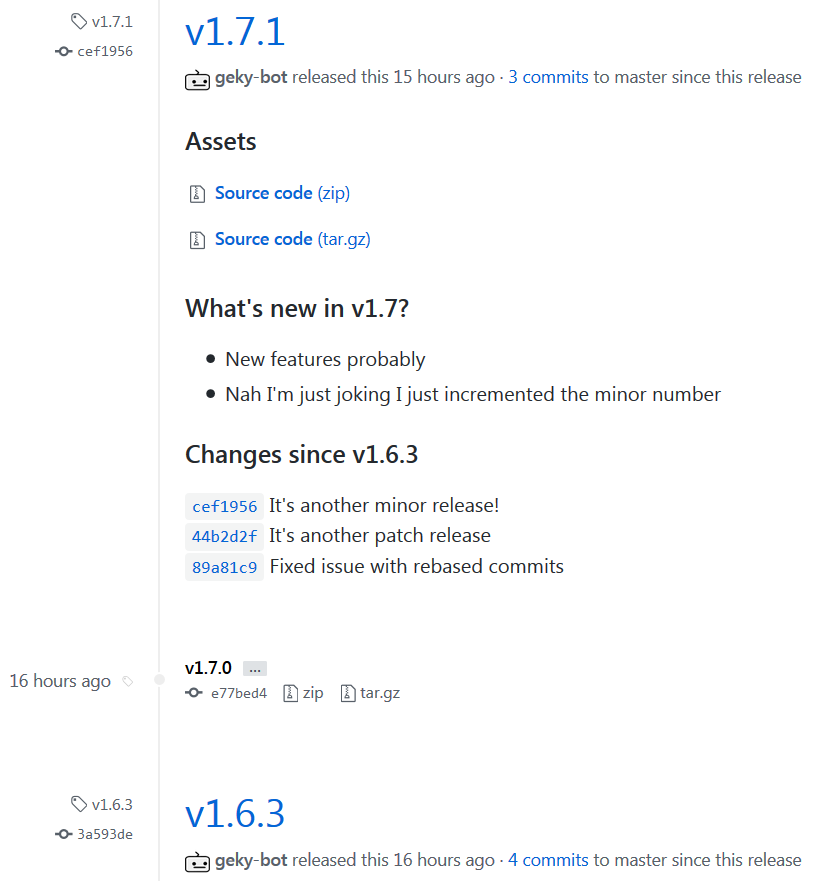
vs
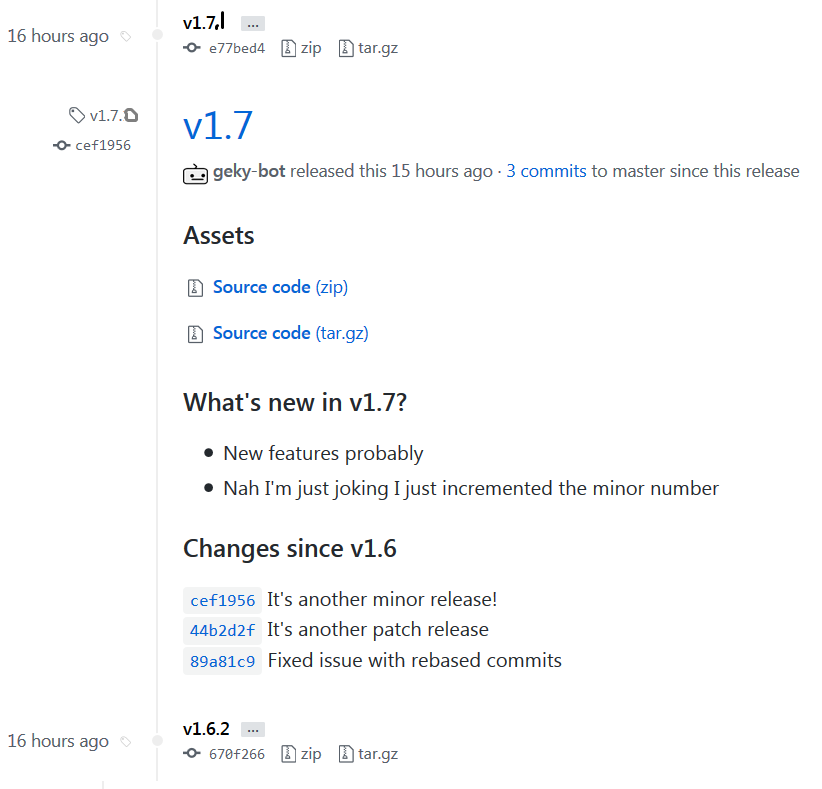
Looking at it a second time I'm thinking you're right and to just go with the second option.
geky
on 25 Jul 2018
Actually I just changed it to generate notes for every single release. Otherwise GitHub was starting to hide versions, which was a bit counterproductive.
Also created pr over here, should be ready to go: https://github.com/ARMmbed/littlefs/pull/81
geky
on 25 Jul 2018
Related issues
 zhabl
·
12Comments
zhabl
·
12Comments
 FrederikTB
·
4Comments
FrederikTB
·
4Comments
 e107steved
·
9Comments
e107steved
·
9Comments
 eastmoutain
·
6Comments
eastmoutain
·
6Comments
 iverdiver
·
5Comments
iverdiver
·
5Comments