Linkerd2: Fail immediately if the proxy has never communicated with the control plane
In the context of this message and the resulting thread: https://linkerd.slack.com/archives/C89RTCWJF/p1534295856000100
In case the Slack link is bad for any reason:
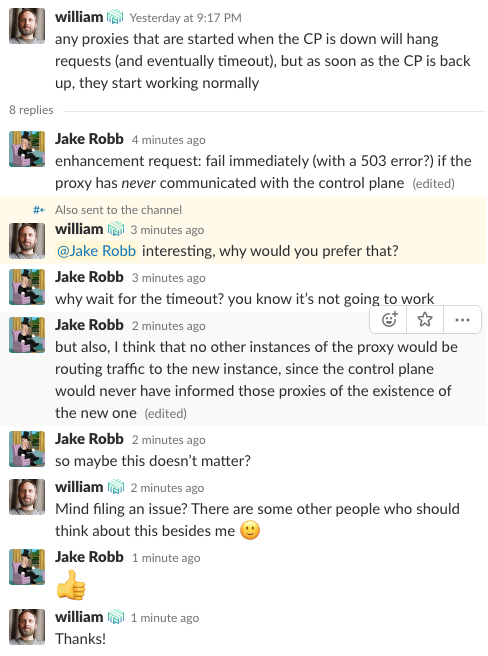
I _think_ that if a proxy is started when the control plane is down, then no other instances of the proxy would know it existed, and so perhaps they'd never send it any traffic -- unless the control plane has been down long enough for a proxy to die and a new one to be recreated that happens to have the same network address. That may be rare enough that this doesn't matter.
However, I think it would be best for the proxy to fail fast if there's no chance that it could respond successfully to a request, rather than to wait for any kind of timeout. The error should cause the caller to retry on another endpoint. Failing fast maximizes the chances that a successful response can be delivered within the retry budget.
Largely uninformed implementation suggestions below:
The proxy instance could maintain a simple flag indicating its readiness to serve requests, which would be set once the control plane has provided the proxy with routing information. If the flag is not set, the proxy would respond immediately to all requests with an error. I believe 503 is the correct choice here. (Bonus: perhaps, in the scenario of an extended loss of contact with the control plane, a proxy might also decide to unset the flag.)
Alternatively, the proxy instance could opt not to begin accepting inbound traffic at all (don't even listen on the port) until it is ready to serve requests. This would result in a "connection refused" error at the caller, which should fail similarly fast. I think I prefer the 503 option, since it could carry with it some context that makes troubleshooting the underlying cause more straightforward.
 jakerobb
jakerobb
All 20 comments
Related: #1307
 wmorgan
on 15 Aug 2018
wmorgan
on 15 Aug 2018
@jakerobb
I think that if a proxy is started when the control plane is down, then no other instances of the proxy would know it existed, and so perhaps they'd never send it any traffic
I don't believe that's the case. The proxies get service discovery information from the control plane's Destination service, which gets this information from the Kubernetes Endpoints and Services APIs. If a proxy starts while the control plane is down, when the control plane comes back up, the Kubernetes API should inform the Destination service of the existence of the endpoints behind that proxy.
 hawkw
on 16 Aug 2018
hawkw
on 16 Aug 2018
Sorry, to clarify, I meant that existing proxy instances would not know the new proxy existed _until the control plane came back up_. I’d expect everything to revert to normal after the CP is online.
jakerobb
on 16 Aug 2018
Oh, yes, that's correct. Sorry, I misunderstood your original post as saying that a proxy started when the control plane was down would become _permanently_ stuck.
It's also worth noting here, though, that the bind timeout only applies to the _outbound_ side of a proxy --- requests from the proxied service to the rest of the mesh. On the inbound side --- requests from other proxies, etc --- the proxy doesn't need any information from the control plane, and will happily serve requests regardless of the control plane's state.
hawkw
on 16 Aug 2018
Ah! Of course. And the proxied service would have no recourse, so the retry budget issue I mentioned isn’t a thing.
Given that, I think this is mostly moot and extremely low priority, but I still feel like returning a 503 immediately is more correct than allowing a timeout to expire. Thanks for talking it through. 🙂
jakerobb
on 16 Aug 2018
I'd vote for keeping this issue open. Our goal is to _never_ make a service worse when linkerd is installed.
An alternative solution to this is that we can fall back to forwarding tcp streams (i.e. through kubeproxy) until the control plane is live. This will eventually need some policy control, but as a default option we should do no harm.
_Edit_: Sorry, I think I may have misread the conversation:
Is the issue that outbound requests from new instances fail while the Controller is down? If so, the issue should stay open.
If the issue is that new instances do not receive inbound requests until the Controller is running, I agree this is best addressed through HA.
 olix0r
on 16 Aug 2018
olix0r
on 16 Aug 2018
An alternative solution to this is that we can fall back to forwarding tcp streams (i.e. through kubeproxy) until the control plane is live. This will eventually need some policy control, but as a default option we should do no harm.
That would disable TLS so it would only be a solution until TLS is the default. When TLS is the default then "do no harm" means we couldn't do it.
 briansmith
on 16 Aug 2018
briansmith
on 16 Aug 2018
The proxy instance could maintain a simple flag indicating its readiness to serve requests, which would be set once the control plane has provided the proxy with routing information.
If we're going to do something like this, this sounds like it should be part of the implementation of a readiness/liveness probe. Then Kubernetes won't direct traffic to this pod until it is ready, and we don't have to fail any requests, and Kubernetes won't de-schedule another pod that's part of (the previous version of) the deployment until it is ready.
I'm not sure it makes sense to treat a controller-proxy partition that occurs during proxy startup differently that occurs later, so I don't think "if the proxy has never communicated with the control plane" is the right condition. I think "if the proxy hasn't communicated with the control plane recently enough" is a better condition that subsumes that. And again, this seems like something that belongs as part of a liveness probe.
briansmith
on 17 Aug 2018
Brian, I don’t agree.
As @hawkw said, this only affects outbound traffic from the proxied service. So there’s nothing a liveness/readiness probe could do to prevent the service from attempting to reach out. (Not that such a probe wouldn’t provide other benefits!)
I had the same thought about “recently enough,” but if the proxy has routing information that came from the control plane, there is no amount of time that could pass after which it becomes reasonable to presume that said routing info is stale. In a stable cluster, routing info could be good for months at a time. If you have data about the location of a potential service endpoint, what harm is there in attempting to contact it?
jakerobb
on 17 Aug 2018
@jakerobb
this only affects outbound traffic from the proxied service
As @briansmith pointed out in https://github.com/linkerd/linkerd2/issues/1465#issuecomment-413672245, this isn't _entirely_ correct --- a proxy started when the control plane is down* won't have received its TLS cert, and therefore won't be able to accept TLS connections. In a mesh where TLS is mandatory rather than optional, a proxy that can't accept TLS connections is essentially unable to serve any requests.
*N.B. that in this case, I'm taking "the control plane is down" to mean that the _whole_ control plane, including the CA, is down; not just the Destination service.
hawkw
on 17 Aug 2018
This issue has been automatically marked as stale because it has not had recent activity. It will be closed in 14 days if no further activity occurs. Thank you for your contributions.
![stale[bot] picture](https://avatars3.githubusercontent.com/in/1724?v=4&s=40) stale[bot]
on 22 Nov 2018
stale[bot]
on 22 Nov 2018
I believe this feature request is still worth implementing.
jakerobb
on 26 Nov 2018
I'm a little confused on the specifics of this issue. Why is it appropriate for the proxy to fail requests? To my way of thinking, if the proxy fails to communicate with the control plane, the proxy should just forward the requests to the original destination, probably after some small timeout for controlplane communication.
olix0r
on 26 Nov 2018
It’s appropriate when the alternative is a timeout, as described by William in the original Slack conversation. Better to fail fast when you have sufficient knowledge to know that the communication will not succeed.
I could see forwarding to the original destination as another viable option, until tls=mandatory becomes a thing. In that scenario, the proxy should never excuse itself from the conversation, so to speak.
jakerobb
on 29 Dec 2018
Hello, I was pointed here from #2088 and would like to express my opinion on this. I am sorry if this does not hit the actual issue idea.
Failing fast is clearly better than timing out and having proper readiness checks would be even better, so the affected Pods never get traffic, if they won't work.
Nevertheless, IMO it would be better to have a fallback if the control plane is down. Otherwise it would make the Linkerd control plane a critical cluster component and I think every additional mission critical component is one too much. One could argue that this is unlikely to happen, since only new Pods are affected, if the control plane is down and since the controller has multiple replicas in HA mode.
However, the odds change when someone has potentially short-lived instances (eg AWS Spot Instances), a Horizontal Pod Autoscaler and a Cluster Autoscaler. A proper readiness probe and a Pod Disruption Budget would protect new Pod from receiving traffic and causing bad requests, but it would also halt all automatic cluster operations (ie scaling, restarting, replacing) until the control plane is back up.
Then there is still the argument, that one can start the controller in HA mode (ie having multiple replicas), but it is still a software and any piece of software might fail any time for unexpected reasons. Since all replicas are using the same version, they are prone to the same bugs. Also configuration issues could increase the risk of a failure, like a bad timing of a Image Registry downtime, missing Pod Disruption Budget, a too low Pod Priority class and a sudden traffic increase.
I know these examples a kind of artificial and it could also happend to other components like DNS and the Kubernes control plane, but my actual point is that any software can fail, so having less critical dependencies between them is better.
This comment got a bit longer as expected. Sorry for that.
 svenwltr
on 18 Jan 2019
svenwltr
on 18 Jan 2019
A legitimate point of view, for sure.
In my case, linkerd2 will be providing a required function (TLS encryption); without it, we MUST NOT allow the communication to occur, as a matter of corporate policy.
As I said in an earlier comment, I think the behavior I’m asking for might only be reasonable in the tls=mandatory scenario.
jakerobb
on 18 Jan 2019
This issue has been automatically marked as stale because it has not had recent activity. It will be closed in 14 days if no further activity occurs. Thank you for your contributions.
stale[bot]
on 18 Apr 2019
This happens now, right @olix0r ?
 grampelberg
on 18 Apr 2019
grampelberg
on 18 Apr 2019
@grampelberg Now, when Identity is not disabled, the proxy only indicates readiness when it has been able to communicate with the identity service.
olix0r
on 18 Apr 2019
Sounds good to me.
/close
jakerobb
on 16 Jul 2019
Related issues
 franziskagoltz
·
3Comments
franziskagoltz
·
3Comments
 manimaul
·
3Comments
briansmith
·
4Comments
manimaul
·
3Comments
briansmith
·
4Comments
 skalinets
·
3Comments
skalinets
·
3Comments
 zaharidichev
·
4Comments
zaharidichev
·
4Comments
Most helpful comment
Hello, I was pointed here from #2088 and would like to express my opinion on this. I am sorry if this does not hit the actual issue idea.
Failing fast is clearly better than timing out and having proper readiness checks would be even better, so the affected Pods never get traffic, if they won't work.
Nevertheless, IMO it would be better to have a fallback if the control plane is down. Otherwise it would make the Linkerd control plane a critical cluster component and I think every additional mission critical component is one too much. One could argue that this is unlikely to happen, since only new Pods are affected, if the control plane is down and since the controller has multiple replicas in HA mode.
However, the odds change when someone has potentially short-lived instances (eg AWS Spot Instances), a Horizontal Pod Autoscaler and a Cluster Autoscaler. A proper readiness probe and a Pod Disruption Budget would protect new Pod from receiving traffic and causing bad requests, but it would also halt all automatic cluster operations (ie scaling, restarting, replacing) until the control plane is back up.
Then there is still the argument, that one can start the controller in HA mode (ie having multiple replicas), but it is still a software and any piece of software might fail any time for unexpected reasons. Since all replicas are using the same version, they are prone to the same bugs. Also configuration issues could increase the risk of a failure, like a bad timing of a Image Registry downtime, missing Pod Disruption Budget, a too low Pod Priority class and a sudden traffic increase.
I know these examples a kind of artificial and it could also happend to other components like DNS and the Kubernes control plane, but my actual point is that any software can fail, so having less critical dependencies between them is better.
This comment got a bit longer as expected. Sorry for that.