Linguist: Fixing C/C++/Objective-C classifications
A fair fraction of the outstanding issues with Linguist mis-classifications are to do with C, C++, Objective-C and any other languages that use .m or .h as extension.
While it's possible we can see further improvements by increasing our samples for the Bayesian classifier I'm pretty convinced we need to craft a few reliable heuristics to shortcut the classifier.
We currently have the following in heuristics.rb but it's not being called.
def self.disambiguate_c(data, languages)
matches = []
matches << Language["Objective-C"] if data.include?("@interface")
matches << Language["C++"] if data.include?("#include <cstdint>")
matches
end
@DX-MON had a good go at this in #1036 but at the time we didn't have a good way to benchmark the effects of these changes. With the new benchmarks we are now in a good place to tackle this problem.
The current heuristic is deliberately limited in scope, that's because any heuristics we define should be accurate, simple to understand and fast.
Basically I'm asking for some help with this. I'm more than happy to grab a bunch (1000s) of files to test any potential changes on. Questions for you all:
- How do we feel about #1036 - I'd love to see a case for
Cin thatdisambiguate_cmethod too if possible. - #1036 is matching on a bunch of keywords - are all of these necessary? Are we potentially sacrificing accuracy for completeness?
- Are there any good heuristics for pure C code?
 arfon
arfon
All 138 comments
@arfon The keywords have been carefully selected as being unique to the specific language they are detecting for - for example, you cannot use @ syntax outside of comments in C++ as this is a syntax violation, so we can use @protocol, for example, to help detect Obj-C as protocol is an invalid C and C++ keyword and @ syntax is invalid for both too
More testing would be a good way to verify that nobody is doing silly things in comments though, as I believe there is scope to include extra matching based on not being in comments to select out people using //! @class and such for documentation.
Also, looking specifically for std:: is a good benchmark for C++ as this syntax is unique to the STL.
 DX-MON
on 24 Oct 2014
DX-MON
on 24 Oct 2014
Thanks @DX-MON - I've made a new PR with all of your commits in here: #1627. I made the Objective-C matchers a little more strict in this commit as @end was matching lines like these in a valid C file (and therefore classifying the file as Objective-C).
More testing would be a good way to verify that nobody is doing silly things in comments though, as I believe there is scope to include extra matching based on not being in comments to select out people using
//! @classand such for documentation.
Yeah, excluding lines that begin with // might be a good idea.
arfon
on 24 Oct 2014
The other blocks of text to exclude if going after comments are lines enclosed in matching /* and */ pairs (hence the "and such").
I didn't know about \b so thank you for that :)
DX-MON
on 24 Oct 2014
i'm re-iterating my assessment from #332 :
imo the only halfways easy way to differentiate between C,C++,and Obj-C headers is by looking at the extensions of other files in the repo (i.e. context). if there are .m files and no .c files, the header is definitely obj-c, and if there are only .c files, it's cleary C. for C++, the possibilities are .C, .cpp, .cc, etc...
 rofl0r
on 1 Nov 2014
rofl0r
on 1 Nov 2014
@rofl0r Unfortunately the way Linguist's framework is set up makes such a comparison impossible. Also, for many instances of misclassification, the header files are in a completely separate folder to the source files, making such a comparison impractical too - Linguist would need to be able to correlate unrelated directories of files for this to be truely effective. also, .C for C++ code is not always true - it is the DOS style file extension for C code (MS-DOS only had upper-case file names and extensions after all).
DX-MON
on 1 Nov 2014
well, DOS-C is not really C anyway, as there is no single ANSI-C compliant compiler available which runs on DOS... and i would suspect this affects no more than 1 out of 1000 C repos, so the "DOS-C" niche is negligible.
rofl0r
on 1 Nov 2014
I didn't say DOS-C, I said DOS style file naming. All sane compilers I know of treat .C and .c the same, same as they treat .CPP and .cpp the same. FAT32's primary fall-back mode is DOS file names, same with NTFS. Because these file systems are case insensitive and do that, the tools have to tread ice the exact same way. An example of the problem is #1054 and the 2D_dos repository's code reads as complete valid ISO C.
Ignoring that for a sec, though, and getting fully back on topic, #1202 also asked about extension comparison to aid with .h file disambiguation and the answer is no different from then - sorry.
DX-MON
on 1 Nov 2014
I think that "typedef struct" is a pretty clear flag for C-only code.
 khoek
on 1 Nov 2014
khoek
on 1 Nov 2014
Hi @escortkeel I am intrigued as to how you figure this seeing as it is not invalid C++ or Obj-C syntax. It is also used in C++ syntax headers for C interoperability. If these headers contain classes and other non-C constructs then they should not be marked as C headers. This is why I specifically went after keywords in Obj-C and C++ that occur in only those languages in complete isolation.
DX-MON
on 1 Nov 2014
@DX-MON I haven't seen much C++ code with typedef structs personally. I totally agree about the interoperability stuff, though. Good point.
khoek
on 1 Nov 2014
I think first of all it's a good idea to make sure comments are never looked at! That should reduce some false positives, although I can't tell if it's actually a problem or not without statistics.
Nevertheless, a couple of other things to look out for are (I don't know Objective-C, so this would be C vs C++):
\<template\>-> C++#include\s*[<"][^.]*[>"]-> C++ (it's not illegal to#include <header_no_dot>in C, but I doubt anyone actually does it)std::-> C++ (as mentioned before)\<delete\s*[]-> C++- (header only)
\<extern "C"-> C (1) - (header only)
#ifdef\s*__cplusplus\>-> C (1)
(1) these cases show a C header that tries to be nice and be able to be included in a C++ project. With the check for __cplusplus, the header may be adding more C++ functionality also, but it is clear that the header is for a C project, even if it plays nice with (or even adds features for) C++.
 ShabbyX
on 3 Nov 2014
ShabbyX
on 3 Nov 2014
@ShabbyX I intentionally did not make assumptions based on kinds of includes because it is not illegal to specify arbitrary extensions to the preprocessor - only C++ specific STL includes are heuristically detected. extern "C" is actually also a C++-sim as is #ifdef __cplusplus - feeding the former to a C compiler results in errors and the latter clearly demarks C++ specific code. They could be added to the C++ heuristic though as that might help
DX-MON
on 3 Nov 2014
Ok, the extern "C" on itself (if not surrounded by #ifdef __cplusplus) is C++ only, but I would argue against #ifdef __cplusplus marking the file as C++.
It is true that #ifdef __cplusplus is adding C++ code, but a header that contains such a test is definitely not written for C++, but just supports it. If it was a header for a C++ project, it wouldn't need #ifdef __cplusplus. I believe only header files of C libraries have that test, just to play nice with C++. It would be unfair to call them C++ headers, since they really belong to a C project.
ShabbyX
on 3 Nov 2014
I've actually written several libraries which are internally C++ with externally a C API using that #ifdef trick - I do not think it is a reliable heuristic because it is for inter-language interoperability only.
DX-MON
on 3 Nov 2014
Due to the fact that C++/Obj-C intentionally use similar (or even compatible) headers, there is no way this issue can be decided for all cases. But I think the following one rule might be a starting point:
If a header works in C, mark it as C.
Since C is the progenitor of the other languages, I think it is reasonable to mark files as C when possible. The rule immediately suggests a way to find heuristics for the other languages: Parse a large sample of input files using C language rules, and record the errors that are produced when given C++/Obj-C code. The most common errors would be good candidates for a heuristic to detect what language a header is written in.
(In the end, the above rule could even have additional value, showing compatible headers in a C++/Obj-C object.)
 ntessore
on 26 Nov 2014
ntessore
on 26 Nov 2014
Our repository was previously correctly classified but recent changes have definitely broken the C/C++ differentiation in our repository. I thought I'd fix just by using the .gitattributes file, but I wasn't able to get that to ever work (even in the linguist repo) so I don't know what I'm doing wrong.
If you are interested, about half of our C++ files are now showing up under C.
https://github.com/idaholab/moose
 permcody
on 9 Dec 2014
permcody
on 9 Dec 2014
That would be due to the following logic errors in the regex's in the heuristic that I noticed as a result of this.. @arfon please could you fix these in a new PR:
Line 45 of heuristics.rb:
/^\s*template\s*</.match(data) or /^[^@]class\s+\w+/.match(data) or /^[^@](private|public|protected):$/.match(data) or /std::.+$/.match(data))
needs changing to:
/^\s*template\s*</.match(data) or /^[:blank:]*try/.match(data) or /^[:blank:]*catch\s*\(/.match(data) or /^[:blank:]*(class|namespace)\s+\w+/.match(data) or
/^[:blank:]*(private|public|protected):$/.match(data) or /std::\w+/.match(data))
This adds checking for C++ try-catch and fixes the presence checks of @ in front of class, etc - they aren't needed because the regex already clamps to start-of-line - just junk excess white-space from the line and get on with it :).
DX-MON
on 9 Dec 2014
To chip in another repository where C is wrongly detected, https://github.com/lutoma/xelix has had wrong detections ever since it was created 4 years ago, and right now ~13%/2% are detected as C++/Obj-C respectively even though it doesn't have any. It's an osdev project though, so it might make use of weird patterns that may not occur in "normal" C.
 lutoma
on 10 Dec 2014
lutoma
on 10 Dec 2014
@lutoma I've taken a look and this seems to only be because the classifier is getting it wrong, not because of the heuristics. I would suggest making a few of those headers (longer ones for preference) samples for the Bayesian classifier.
DX-MON
on 10 Dec 2014
@DX-MON - does your earlier comment still hold? i.e. Does the regex still need fixing up?
arfon
on 10 Dec 2014
@arfon Yes, the regex fix should cover @permcody's problem. @lutoma's is down to the classifier screwing up.
DX-MON
on 10 Dec 2014
:+1: thanks for the clarification @DX-MON
arfon
on 10 Dec 2014
@DX-MON Ah, thanks for checking.
I don't know how exactly linguist works internally, but maybe it might also be worth a shot to try and figure out the language based on the other files in the repository. So if there's a .h file and the repository exclusively contains C, but no C++/Obj C files, it should probably be counted as C.
As for submitting samples for the Bayesian classifier, sure. What's the best way to go about that?
lutoma
on 10 Dec 2014
@lutoma The way you've done it is perfect :) any and all samples for the classifier help so don't worry it's a large number.
As for how Linguist works, it can and does only perform classification on a per-file basis, with the type that crops up most marking the repo as that type, weighted by lines of code.
DX-MON
on 10 Dec 2014
Looking at some headers classified as C, while they obviously shouldn't be, here are a couple more things to look out for:
- If a non-comment contains
::, it's definitely not C - If a function definition contains
&, it's definitely not C - If there is
using namespace, it's definitely not C
I understand that some of these checks are harder, and may require some basic parsing, but they may probably be worth it.
ShabbyX
on 11 Dec 2014
@ShabbyX using namespace is a good point. an optional "(using[:blank:])?" to the namespace check would suffice there. @arfon if you would be so kind.
Testing for & like that is not possible with just a regex, I don't think Linguist is not about to get the complexity of a C++ parser - and it's certainly not worth it for the bugs it'd introduce - and same for :: - but this is where more samples for the classifier helps. It can be trained to do this sort of work with good samples, and lots of them.
DX-MON
on 11 Dec 2014
From https://github.com/github/linguist/issues/2035 both of these files are being incorrectly identified as C++:
- https://github.com/Vedaad-Shakib/MPS/blob/master/include/que.h
- https://github.com/Vedaad-Shakib/MPS/blob/master/src/que/que.h
I haven't dug into why yet but wanted to report this.
We also have another new C/C++ issue here: https://github.com/github/linguist/issues/1993
arfon
on 25 Jan 2015
I have another example for a C header incorrectly classified as C++:
https://github.com/phillipberndt/pqiv/blob/469fe63df4b27463f8accf8a45ae515a17c202e7/pqiv.h
I didn't follow this issue so far, but noticed that there are only 30 C headers, 21 C++ headers, and 9 ObjC headers in the samples directory. Are those the only files used for training the classifier? If so, then while I agree that a Bayesian classifier probably won't reach 100% accuracy, that's IMHO still a pretty small sample to distinguish languages that are this similar. Did anyone ever _try_ to solve this by just throwing a couple of 100s (or 1000s) more header files at the learner?
 phillipberndt
on 11 Feb 2015
phillipberndt
on 11 Feb 2015
@phillipberndt Please open a pull request with that header. The // based comments are probably what are making the classifier think C++.
Throwing more samples at the classifier is exactly what needs to be done but the problem is that permission needs to be given for the files to be included in the classifier samples, and hence why a data mining operation has not been done to fill out the classifier's C, C++ and Obj-C directories.
DX-MON
on 11 Feb 2015
Here's a whole bunch of mostly C++ files misclassified as C:
https://github.com/search?utf8=%E2%9C%93&q=language%3Ac+namespace&type=Code&ref=searchresults
There are 8,016,195 matches although there are multiple matches per file.
I think a good heuristic would be to check if a file contains namespace, typename, static_cast or other fairly unique C++ keyword.
 vitaut
on 12 Feb 2015
vitaut
on 12 Feb 2015
Here are two C++ files incorrectly identified as C:
https://github.com/cppformat/cppformat/blob/74169e4b5deb805a03ebe7db0c90c3ea196edbb1/test/posix-test.h
https://github.com/cppformat/cppformat/blob/f2c9df8e9f1ecd824bb3fdb99a0761602c0be729/test/util.h
vitaut
on 12 Feb 2015
@DX-MON There is a list of public domain libraries at http://unlicense.org. I think you could find a couple of hundred files there that would not need permission, as far as I understand (IANAL).
ntessore
on 12 Feb 2015
@vitaut One interesting point with the github search results you mentioned is that it seems that most of the files have a .C extension which already means the file should be classified as C++.
ShabbyX
on 12 Feb 2015
@ShabbyX Yes, although GitHub shows only 1000 results so it's not clear what's going on in the rest.
vitaut
on 12 Feb 2015
Sorting in a different order shows some misclassified .h and even .c files (why are they putting C++ code in .c files?). There are correctly classified C cases too, but mostly because the search is not very specific.
vitaut
on 12 Feb 2015
@ShabbyX a ".C" file does not a C++ file make.. actually you shouldn't be using .C for C++ as it's the DOS form of a C file. likewise .H. Valid C++ implementation extensions, regardless of case, are .cc, .cpp, cxx. While .C is accepted by many compilers as C++, that behaviour is inconsistent with case insensitive file systems and DOS originating repositories.
DX-MON
on 13 Feb 2015
@DX-MON Well, according to Wikipedia, here's a list of C++ extensions:
.cc .cpp .cxx .C .c++ .h .hh .hpp .hxx .h++
Moreover, .C files are used for C++ code as can be seen from the search query I provided. So I think the detection should be based not on the file extension in this case, but on the file content.
vitaut
on 13 Feb 2015
@vitaut Your suggestions for typename and static_cast I like. We already do classifications on the std:: namespace as that is unique to C++, but in order to not accidentally match in comments, I did not write the heuristic to directly match the namespace keyword, only namespace std:: anchored to the start of a line.
DX-MON
on 13 Feb 2015
@vitaut I cannot disagree about file content for detection, point I was making is that there were a large number of repos being incorrectly marked as C++ because of case sensitivity - .C for C++ is inherently broken in too many ways. Modifying languages.yml to include .C in both the C and C++ sections should do the trick to pass such files through the heuristic and classifier systems.
Also, if you look closely at your wiki link you will notice that .C is only valid as C++ on Unix/Linux machines. Case in point, Visual Studio ignores .C as C++ as do all other windows C++ compilers.
DX-MON
on 13 Feb 2015
@DX-MON Sure. Including .C both in C and C++ sections sounds reasonable.
vitaut
on 13 Feb 2015
To chip in on this again, I just quickly ran
find ~/code -name "*.c" -exec cp {} samples/C/ \;
find samples/C/ -execdir sh -c "if ! isutf8 -q {}; then rm -v {}; fi" \;
which copied all C files from my code directory to the samples folder and pruned those that had invalid UTF-8 in them (surprisingly many, which made the tokenizer throw exceptions).
This added some ~31000 C sample files to the classifier (and increased the runtime of bundle exec rake samples to about 7 minutes for me, so there's that).
With the additional samples, the C++ misdetections decreased from 3.3% to 1.11%, so I guess throwing even more files at the problem should make it accurate enough to pull the C++ percentage below the display threshold for GitHub.
If wanted, I could probably collect a few 10k C files from various projects in the public domain (and maybe under non-copyleft open source licenses), but I would like some input from GitHub first if that works for you legally. Also, I'm not sure if storing all that in a git repository makes sense, since at that point we're basically storing huge "binary" blobs that will probably never be edited again.
lutoma
on 25 Feb 2015
I like it, the same would be good to have done with some representative C++ code too as that should drop the error rate even further.
You make a fine point about having so many files in repository as essentially a binary blob kind of deal. I wonder what GitHub staff or @arfon @bkeepers have to say on the matter. This weekend I plan to put together a patch set for introducing .C and .H back into the mix as an extension that must go through the detection machinery too.
DX-MON
on 25 Feb 2015
This added some ~31000 C sample files to the classifier (and increased the runtime of bundle exec rake samples to about 7 minutes for me, so there's that).
With the additional samples, the C++ misdetections decreased from 3.3% to 1.11%, so I guess throwing even more files at the problem should make it accurate enough to pull the C++ percentage below the display threshold for GitHub.
Thanks for doing this @lutoma but I don't think this is a good way forward. Currently the classifier does some pretty weird stuff including weighting the results by the _number of samples_ :open_mouth:. This basically means that your 'improved' results here could very well be because of the vastly increased sample set for C rather than an actual improvement in the performance/fidelity of the classifier.
At this point I would rather see us continue to focus on heuristics as a way forward for this issue and problematic repos (with for example lots of small files) people to make use of the various Linguist overrides available to them.
arfon
on 25 Feb 2015
Currently the classifier does some pretty weird stuff including weighting the results by the number of samples
Wouldn't it be a good idea to remove that weight? It doesn't make much sense for the current sample set either.
phillipberndt
on 25 Feb 2015
Wouldn't it be a good idea to remove that weight? It doesn't make much sense for the current sample set either.
In theory yes but that's potentially a huge change for us and so I don't think it's something we could do quickly.
We're honeslty looking at re-writing the classifier from scratch at this point.
arfon
on 25 Feb 2015
It would be great if C++ headers without extensions (like these) could be marked correctly. linguist also affects syntax highlighting, right?
 benwaffle
on 18 Mar 2015
benwaffle
on 18 Mar 2015
It's interesting to note that those files start with // -*- C++ -*- which
is actually a very easy and definitive way of detecting the file type. I'm
not familiar with the syntax, but I guess that's for emacs? There is also a
syntax for vim which linguist could use to detect the language as stated by
the author.
On Wed, Mar 18, 2015 at 6:43 PM, benwaffle [email protected] wrote:
It would be great if C++ headers without extensions (like these
https://github.com/llvm-mirror/libcxx/tree/master/include) could be
marked correctly. linguist also affects syntax highlighting, right?—
Reply to this email directly or view it on GitHub
https://github.com/github/linguist/issues/1626#issuecomment-83083058.
ShabbyX
on 18 Mar 2015
It's interesting to note that those files start with
// -*- C++ -*-which is actually a very easy and definitive way of detecting the file type.
Yep, and Linguist should recognise these: https://github.com/github/linguist/blob/master/lib/linguist/strategy/modeline.rb ... I'll do some digging to see why it's not working.
arfon
on 18 Mar 2015
@ShabbyX - looks like the Emacs modeline isn't working for C++ - this Pull Request will fix your issue: https://github.com/github/linguist/pull/2233
arfon
on 18 Mar 2015
What should i do to suppress detecting my header files as C++ code?
https://github.com/plasmLC/libvk
Thanks!
 plasmLC
on 28 May 2015
plasmLC
on 28 May 2015
Problem has solved by including #include
plasmLC
on 28 May 2015
I have four very simple C headers which are being misidentified as C++:
https://github.com/Tarsnap/spiped/search?l=cpp
I can't see anything in them which would explain the misidentification. Feel free to include these files as test cases if they are useful.
 cperciva
on 7 Jun 2015
cperciva
on 7 Jun 2015
I have four very simple C headers which are being misidentified as C++:
https://github.com/Tarsnap/spiped/search?l=cpp
I've re-indexed the source and it's now just a single file: https://github.com/Tarsnap/spiped/blob/3a457211c4d0bfee2861f684e82856ab4bca9e89/libcperciva/util/insecure_memzero.h
It's not the heurisic that's failing here, rather it's just the classifier getting the wrong answer.
arfon
on 5 Aug 2015
@arfon Is there any way the classifier could be taught to consider the rest of a repository when classifying files? The Tarsnap/spiped repository has 78 files which have been correctly identified as C, and this one header file which the classifier is confused about... if the classifier could say "this file could be either C or C++, but everything else is C so this is probably the same" that might solve a lot of the cases when a small number of files in a repo get misclassified.
cperciva
on 5 Aug 2015
I'm afraid that would be a very big change - Linguist works on a per-file basis.
We built the override functionality for exactly this sort of situation.
arfon
on 5 Aug 2015
Hey, I just committed some changes to my repo and two header files appear as C++ headers, even though they're not:
https://github.com/tehcyx/circ/blob/25a9ba58ff75e3c827831943354a1f93b909b937/src/include/channel.h
Maybe that helps solving the problem.
 tehcyx
on 18 Sep 2015
tehcyx
on 18 Sep 2015
I'm new to Github but found it puzzling that it claimed for several headers in my project (https://github.com/raynebc/editor-on-fire) to contain C++. Seems this is a long standing problem.
 raynebc
on 20 Sep 2015
raynebc
on 20 Sep 2015
By using C-style comments only I got some of the header files to be classified as C, but I don't know what to do about this last one, that appears twice. It's a very small project. https://github.com/skewerr/cmddisplay
 skewerr
on 3 Oct 2015
skewerr
on 3 Oct 2015
@skewerr You can use Linguist overrides.
 pchaigno
on 3 Oct 2015
pchaigno
on 3 Oct 2015
@pchaigno Thanks, man. Didn't know about that.
skewerr
on 3 Oct 2015
Hello, I was surprised to see my latest C project (https://github.com/Zankoku-Okuno/libpredictmatic) classified as mostly C++ today. It seems the heuristics aren't the problem (admittedly, I've only looked at ~20 lines of the linguist code), so I understand the classifier must be at fault? Oddly, it classifies macro-util.h as C++ (despite only being three very plain macros), but classifies size_t-portable.h as C (despite being only an include and a "C++-style" comment).
It occurs to me that it's very easy to write polyglot C/C++, and is often done intentionally, but I assume this would confuse linguist. Not knowing how far linguist's tendrils go, I wonder if adding a C/C++ language be a viable solution? Actually, for all I know, that might annoy people more by labelling a lot of C code as C/C++.
Perhaps the real question is: which language should be preferred when linguist can't tell, given that either choice will annoy some number of people? Has that been discussed somewhere else alread?
 Zankoku-Okuno
on 30 Dec 2015
Zankoku-Okuno
on 30 Dec 2015
If it's a C/C++ language source file with no C++ features (no classes, no use of C++ keywords like "new" or "delete"), I'd argue it's most appropriate to just call it C. At the very least, us programmers should be allowed to manually designate the language in use for a file when it's classified incorrectly.
raynebc
on 30 Dec 2015
The following .h header file is incorrectly reported as a C header, although it contains #include <cstddef>.
 mariosal
on 20 Mar 2016
mariosal
on 20 Mar 2016
@mariosal Well, ok.. that's actually quite reasonable of Linguist seeing that's the only C++-like statement in an otherwise pure C preprocessor containing file. It's also 100% valid C (the extension doesn't matter in an include statement, C++ just took advantage of that by default in the STL). I also don't see a way to program a performant and robust regex that could filter on that.
You know that the file is C++ by intent (even if mostly C by form), so use the aforementioned override functionality to set it right in your repository.
DX-MON
on 20 Mar 2016
So it might be worth noting that I have a C header which, once it received a block comment containing a couple of cases of the word "class", was classified as C++ (note that I've since pushed a .gitattributes setting all *.h files to C).
File causing problem: NelsonCrosby/ncedit/lapi/class.h
Commit after which problem occurred: Fix some styling and expand some comments
 nelsonxb
on 5 Sep 2016
nelsonxb
on 5 Sep 2016
Could something like the following be added into whatever heuristics are being used:
Say a given repo has a file, foobar.h. Factor in whether there is a file named foobar.c or foobar.cpp.
One of my repos here : https://github.com/AndyGrant/Ethereal/tree/master/src
Has two files, transposition.c and transposition.h. Transposition.c is correctly identified as a C-source file, but the headed is identified as a C++ header.
I'm not familiar with the code, or with Ruby, otherwise I would submit a pull request for it.
 AndyGrant
on 11 Sep 2016
AndyGrant
on 11 Sep 2016
Say a given repo has a file, foobar.h. Factor in whether there is a file named foobar.c or foobar.cpp.
I think what you're suggesting here is that Linguist takes into account the classification of other files in a repository when returning the classification for each file. While I agree this would be a good idea, unfortunately Linguist currently works on a per-file basis so this would be a major change to the current design.
arfon
on 12 Sep 2016
Say a given repo has a file, foobar.h. Factor in whether there is a file named foobar.c or foobar.cpp.
I think what you're suggesting here is that Linguist takes into account the classification of other files in a repository when returning the classification for each file. While I agree this would be a good idea, unfortunately Linguist currently works on a per-file basis so this would be a major change to the current design.
arfon
on 12 Sep 2016
What is the order in which Linguist determines the file types?
If Linguist works in the following way, there may be another route:
Give Linguist a repo. Create a list of each file. Go though one by one
and determine the file type.
If this is the case, we could determine the file type of .h files last.
Then, while looking at other files, say, foo.c/foo.cpp, we can note whether
or not there is a #include "foo.h". Perhaps by setting some value in some
global structure (not sure how the project is setup, or how ruby works).
And then, use that information.
On Sun, Sep 11, 2016 at 10:49 PM, Arfon Smith [email protected]
wrote:
Say a given repo has a file, foobar.h. Factor in whether there is a file
named foobar.c or foobar.cpp.I think what you're suggesting here is that Linguist takes into account
the classification of other files in a repository when returning the
classification for each file. While I agree this would be a good idea,
unfortunately Linguist currently works on a per-file basis so this would be
a major change to the current design.—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
https://github.com/github/linguist/issues/1626#issuecomment-246231888,
or mute the thread
https://github.com/notifications/unsubscribe-auth/ALDT8piA9No7OmhieRd2c54OpYm8Wn6Gks5qpL3FgaJpZM4CyGjn
.
AndyGrant
on 12 Sep 2016
What is the order in which Linguist determines the file types?
There are a bunch of strategies we use, you can see the list (and order of them) here: https://github.com/github/linguist/blob/master/lib/linguist.rb#L60-L66
If this is the case, we could determine the file type of .h files last. Then, while looking at other files, say, foo.c/foo.cpp, we can note whether or not there is a #include "foo.h". Perhaps by setting some value in some global structure (not sure how the project is setup, or how ruby works). And then, use that information.
Certainly something like that _could_ be possible but I have to say, I'm somewhat skeptical of the performance of such an approach. Another possible approach would be to develop a far more sophisticated classifier than the current naive Bayes approach we use. For example, the file paths/directory structure together (and the classification of other files) could all be factored into the classification of a file rather than the current approach which basically just looks at the syntax of the files.
Please don't take my responses as being too dismissive. We're always looking for ways to improve Linguist but the project is pretty much in maintenance mode and this sort of modification would be a major change in the functionality of the library.
arfon
on 12 Sep 2016
When Linguist is preparing to determine the file type of a given file, what does it know?
Does Linguist only have the filename / file contents?
Does Linguist also have the full file path?
If Linguist has all of those things, why can't we do something like the following in the heuristic for .h files.
# ... Failed to match Objective-C syntax
# ... Failed to match C++ syntax
if fileExists(filePath + fileName.stripExtension() + ".c")
Header is for a C file
else if fileExists(filePath + fileName.stripExtension() + ".cpp")
Header is for a C++ file
You say
Linguist currently works on a per-file basis
But Linguist must be aware of where the file came from?
AndyGrant
on 12 Sep 2016
Does Linguist only have the filename / file contents?
Does Linguist also have the full file path?
You can see the heuristics class here: https://github.com/github/linguist/blob/master/lib/linguist/heuristics.rb
I believe theblob passed in here knows it's path yes. Something along the lines you suggest could work. Feel free to take a crack at stubbing out this idea and opening an early PR. We'd be happy to take a look.
arfon
on 12 Sep 2016
60% of my repo is misclassified as as C when it's all C++, even with obvious stuff such as #include <iostream>. https://github.com/lloda/ra-ra/search?l=C I think using .C instead of .c should also be an indicator.
 lloda
on 1 Nov 2016
lloda
on 1 Nov 2016
Just to let know, all of the so-called Objective-C in the Linux kernel repo is actually plain C headers.
For instance this is classified as Objective-C: arch/m32r/include/uapi/asm/sigcontext.h
 AlexanderAmelkin
on 2 Nov 2016
AlexanderAmelkin
on 2 Nov 2016
If a header file (.h) use the scope resolution operator ( :: ), the file should marked as C++, not C since C does not have that operator.
C++ allow to use the scope resolution operator even for globals, so something like this in .h file should be recognized as C++:
struct myType;
void some_global_function( myType v );
extern myType some_evil_extern_global_thing;
...
int main()
{
::some_global_function( some_evil_extern_global_thing );
return 0;
}
I have some header files in my private repositories marked as C while they are only C++ "parsable" since the use the scope resolution operator. Not a big issue after all...
Hope this help to better recognise C from C++ headers.
 alessiot89
on 4 Dec 2016
alessiot89
on 4 Dec 2016
@lloda Unfortunately you have to remember that some of C's roots are in case-insensitive times (DOS), and so there are projects on GitHub that are pure C that use .C rather than .c (because of the way such OSes work) - so that is no indicator that you're writing C++.
Also, if you had your using's on seperate lines, then Linguist is able to use those as a solid C++ indicator. This can probably be improved though to take a using as being up to the first ';' and running with that.
DX-MON
on 22 Dec 2016
@DX-MON C's roots are most definitely not in DOS! C's roots are in Unix, whose and whose derivatives' file systems are normally case-sensitive. In modern days, it's only windows that's case-insensitive, and microsoft's compiler (cl.exe) has abysmal support for C; they are stuck in C89 and they don't even fully conform to that. There would be hardly anyone writing C code on windows, let alone use .C instead of .c.
That said, there is no reason why anyone couldn't use .C for C files in a case-sensitive file system as Unix (because everything non-windows is Unix) doesn't care about file extensions. Still, it could be a good tie-breaker; if Linguist can't make up its mind, it could call it C++ if the extension is .C.
ShabbyX
on 22 Dec 2016
In modern days, it's only windows that's case-insensitive
Incorrect. macOS is a case-insensitive filesystem as well, despite being derived from BSD.
 Alhadis
on 22 Dec 2016
Alhadis
on 22 Dec 2016
@DX-MON An indicator doesn't need to be 100% certain to be useful, but I see your point. On the other hand my code is no corner case, it's very obviously C++ and not C. There are many other indicators that are being missed. I just wanted to report this as a bug, it's not important enough for me to work around it.
lloda
on 22 Dec 2016
@ShabbyX Actually, if you re-read what I wrote more carefully.. I did not claim that all of C's roots are in DOS.. I said SOME. Also, cl.exe supports C99 as of VS2015, and some of C11. However, it is not a reliable indicator either way, so cannot be used for Linguist's rather binary way of determining membership of one language or another pre-Bayer filter.
@lloda Within Linguist, pre-Bayer filtering, it's either-or.. you either can use an indicator because it really has to be due to only appearing in.. or you can't because sometimes you'd get it wrong (better for the Bayer filter to deal with then). This is all about improving correctness.. not for some, but for all. Linguist used to treat .C as only being C++, which is clearly wrong. This is even documented above in this thread.
DX-MON
on 22 Dec 2016
Any updates? I'm still having this problem.
 moon-chilled
on 25 Feb 2017
moon-chilled
on 25 Feb 2017
Yes, still not fixed. Please work on this.
 davidgarland
on 1 Mar 2017
davidgarland
on 1 Mar 2017
 zhaozg
on 18 Apr 2017
zhaozg
on 18 Apr 2017
The Exercism C language track has one, single, .h file that is incorrectly classified as C++.
https://github.com/exercism/c/blob/6b49325e4b2b132f72501c071b542735fd5e1968/exercises/triangle/src/example.h
The only difference I can see between this an any other .h file in the repository is the lack of a blank line between the header guard and the include for stdbool.h. Is there something I can change in the file to correct this mis-classification, or should I open a PR to add it to the C samples?
 wolf99
on 2 Nov 2017
wolf99
on 2 Nov 2017
Noticed that a regex exists for C++ but not for C. Can I add one for c stl library includes like #include <stdlib.h>?
Might look like
CRegex = /^\s*#\s*include <(stdint.h|string.h|stdio.h|stdarg.h>/
 jweinst1
on 7 Feb 2018
jweinst1
on 7 Feb 2018
That's problematic because c++ code could still include those headers. How about a behaviour that's present only in c, like type function(void)? Regex could be something like:
CRegex = /^(char|short|int|long|bunch|of|other|types)*\w\s*\w\s*\(\s*void\s*\)
@Elronnd , good idea, ill keep thinking of more C-specifc ways to rule them out.
jweinst1
on 8 Feb 2018
I have a repository https://github.com/salda/file_scraper, it's C++ with C, but it's marked as 70% Objective-C :(
 salda
on 20 Feb 2018
salda
on 20 Feb 2018
@salda you, like many others, are hitting the problem due to misidentified .h files. https://github.com/salda/file_scraper/blob/master/myhtml/charef_resource.h is the file primarily responsible for the heeeawg proportions as it's 459k. Its size is also why it doesn't appear when you click the language bar. For the moment a manual over ride is your best bet.
 lildude
on 20 Feb 2018
lildude
on 20 Feb 2018
@lildude Thanks, I just wanted to add my record here, nothing more.
But when it's not possible to split C-languages between C, C++ and Objective-C , then why it's not just marked as 1 common C-based parent language?
Or why not offer the user to choose what child/specialization of that parent language is that instead of incorrect assumption?
salda
on 20 Feb 2018
@lildude Thanks, I just wanted to add my record here, nothing more.
:+1:
But when it's not possible to split C-languages between C, C++ abd Objective-C , then why it's not just marked as 1 common C-based parent language?
Because there isn't one 😉 People will definitely argue that these languages are all different and shouldn't be grouped together - people are already quite touchy about the misclassification due to the languages being so similar when it comes to the header files that it's often incredibly hard to distinguish them apart.
Or why not offer the user to choose what child/specialization of that parent language is that instead of incorrect assumption?
We do in a way, with the Linguist overrides. GitHub.com doesn't have this functionality directly within it, and isn't likely to get it anytime soon, so it needs to be manually applied via Linguist overrides.
lildude
on 20 Feb 2018
But when it's not possible to split C-languages between C, C++ and Objective-C , then why it's not just marked as 1 common C-based parent language?
Because there isn't one 😉 People will definitely argue that these languages are all different and shouldn't be grouped together - people are already quite touchy about the misclassification due to the languages being so similar when it comes to the header files that it's often incredibly hard to distinguish them apart.
But there is simple counterargument that the headers can't be distinguished with current system, so it would make sense to have C, C++ and Objective-C in C-family language and make people touchy instead of classifying the languages incorrectly and make them angry/annoyed that they chose GitHub and then they see, how buggy it is.
salda
on 20 Feb 2018
But there is simple counterargument that the headers can't be distinguished with current system, so it would make sense to have C, C++ and Objective-C in C-family language
💡 Oooo, now that's given me an idea.
@Alhadis @pchaigno how about introducing a new "C-family Headers" (or similarly worded) language and using that the classify all .h files that smell slightly C-like?
Our biggest problem is almost always the blasted header files and at least this way we get a lot closer than we probably ever will with the current heuristic approaches like the one currently being implemented in https://github.com/github/linguist/pull/4025
lildude
on 20 Feb 2018
Possibly, but that risks introducing a new family of complaints:
- "
C-family headeris not a language." - "My repository is no longer marked as 100% C!"
:disappointed: Moreover, it'd impact one's ability to search for .h files by language, as it'd no longer be possible to search for .h in C++, and whatnot...
Alhadis
on 20 Feb 2018
Ah yes. 😞
lildude
on 20 Feb 2018
The only "good" solution I can think of is one that's outside Linguist's current abilities: "ambiguous"-type languages can have their classifications deferred until Linguist's finished classifying the rest of their repository, and then using the weighted averages of any confirmed C/C++/Objective-C files to determine how the "ambiguous" files picked up earlier should be determined.
For instance, assume a repository has C++ code in one half of their repo, with Objective-C being abundant in the other half. The proximity of C++ files in a nearby parent/subdirectory could tell us "this .h file should be a C++ file (does that make sense?)
Alhadis
on 20 Feb 2018
does that make sense?
Yup.
lildude
on 20 Feb 2018
How about marking them as C in the first place if they qualify and don't assume it's C++ or Obj-C? Does that make sense? Or do people with C++ projects complain the other way and say oh no, now my project is not 100% C++ anymore? I also like @Alhadis' comment to check for the surrounding files.
Or even better yet, include the makefile, cmake in the consideration. Compiler flags can already give away what language it is.
tehcyx
on 20 Feb 2018
Or even better yet, include the makefile, cmake in the consideration. Compiler flags can already give away what language it is.
Assuming the project's build pipeline wasn't too tangled and inside-out, yeah...
Objective-C should, like, stop existing, really. So should C++. Only C is real.
Alhadis
on 20 Feb 2018
From my point of view, marking headers (or even non-header files) as C is correct, if they don't contain any code proven to be C++ or Objective-C and it can/should be done like that.
But the problem is that currently my included headers in C are marked as Objective-C even there is no sign of Objective-C in them.
Also the calculation of the percentage is strange, because included header containing one long constant can be used as a 50% of the repository even if other files contain all of the functional code.
So in the end if GitHub didn't mark my repository language anyhow and let me select the language, the result would be superior to current situation.
salda
on 20 Feb 2018
I must add that the situation is way more bugged.
In my repository https://github.com/salda/file_scraper, I click on the coloured line with languages and then select Objective-C (69.7%) and I see only 1 small file marked as Objective-C, myhtml/mynamespace_resource.h, so how can this file make 69.7% of the repository?
salda
on 20 Feb 2018
@salda one idea is in your header,
#pragma once
Could be added to the cpp regex used as a heuristic in linguist. Currently, the cpp regex catches more fundamental header features for c++, but not newer features like pragma
CPlusPlusRegex = Regexp.union(
/^\s*#\s*include <(cstdint|string|vector|map|list|array|bitset|queue|stack|forward_list|unordered_map|unordered_set|(i|o|io)stream)>/,
/^\s*template\s*</,
/^[ \t]*try/,
/^[ \t]*catch\s*\(/,
/^[ \t]*(class|(using[ \t]+)?namespace)\s+\w+/,
/^[ \t]*(private|public|protected):$/,
/std::\w+/)
I must add that the situation is way more bugged.
In my repository https://github.com/salda/file_scraper, I click on the coloured line with languages and then select Objective-C (69.7%) and I see only 1 small file marked as Objective-C, myhtml/mynamespace_resource.h, so how can this file make 69.7% of the repository?
@salda Everything is explained in the README and earlier by me but to summarise for your context...
- Linguist measures the language breakdown by bytes of code
- As I pointed out earlier, https://github.com/salda/file_scraper/blob/master/myhtml/charef_resource.h is by far the largest file in your repo at 459kb
- The total size of code in your repo is ~662.25kb, making this file alone 69.3% of the total code in your repo
- Add to that the one file you can see at 2.71kb, you get ~69.7% which if what is being reported
- As this file is over 384kb, it exceeds the search indexing thresholds (referenced in the troubleshooting section of the README) and thus won't appear in the search results when you click the language
lildude
on 20 Feb 2018
@lildude aha, yes, I am retarded
I have checked the language files for the 1st time (didn’t understant the point before).
salda
on 20 Feb 2018
@jweinst1 pragma is not a C++ feature.. It's a C preprocessor feature.
Furthermore, #pragma once is valid in C headers too. That's why that was never included in the C++ regex.
Just to add insult to injury though, pragmas are compiler-specific extensions - the "once" extension is supported by many but not all compilers, so cannot be relied on anyway in portable code. See http://en.cppreference.com/w/cpp/preprocessor/impl for further reference.
DX-MON
on 21 Feb 2018
For some reason this is classified as C++ https://github.com/dotnet/corefx/blob/30148bf4a56ea5dc934893f8b87367ff221014a6/src/Native/Unix/System.Security.Cryptography.Native/pal_evp_pkey.h, although the code is pure C. Could that be because of // comments?
 ghost
on 29 Jun 2018
ghost
on 29 Jun 2018
Could that be because of // comments?
Probably not. It’s probably because the file is quite small and doesn’t appear to have anything that makes it uniquely C and the classifier has determined it to be C++ based on how closely it matches the samples we’ve got. This is an unfortunately common problem with the C-family header files, especially small files.
There are a few PRs open to improve this, but they’ve gone a bit stagnant. In the meantime, an override is the only option.
lildude
on 29 Jun 2018
@lildude, I'd say that a '.h' or '.c' extension is a way more reliable hint to use when unsure than some samples or file size. If it looks like a duck, and quacks like a duck, it is probably a duck, not a C++. ;)
AlexanderAmelkin
on 2 Jul 2018
@lildude, I'd say that a '.h' or '.c' extension is a way more reliable hint to use when unsure than some samples or file size. If it looks like a duck, and quacks like a duck, it is probably a duck, not a C++. ;)
We already use the extension as an early quack check 😄 https://github.com/github/linguist/blob/5db20d64a2db4339e88ed729954eb8e849092e41/lib/linguist.rb#L59-L67
... and this works perfectly for the .c files as it's only associated with _one_ language.
The problem is .h files are used by multiple C-family languages and this is where the challenge lies - differentiating between each of these languages when there's often very little, if any, language-specific differentiator within the file.
lildude
on 2 Jul 2018
If it looks like a duck, and quacks like a duck, it is probably a duck, not a C++. ;)
I think that's the way to go for .h files. Having most pure C headers classified as C, even if they are part of a C++ project, is not something that unexpected. I would argue that it is actually the best behaviour. Having valid C headers arbitrarily classified as C or C++, apparently more often C++, is really unexpected.
Which of the open PR for C/C++ disambiguation would you say is closer to an acceptable fix? I found a few of them, but I have no idea where to start:
https://github.com/github/linguist/pull/3585
https://github.com/github/linguist/issues/1626
https://github.com/github/linguist/pull/4025
 smola
on 9 Jul 2018
smola
on 9 Jul 2018
@smola #4025 is near-ready, only missing a test case. I'll close it if it isn't updated in a week or will try to add it myself.
3585 is on me; I had completely forgot about it. I still need to run some benchmark, but other than that, it should be possible to merge it soon (unless the number are all wrong).
Once those pull requests are merged, I think we should look for other ways to address the remaining issues with the .h extension, if any. We try to make the users' experience as smooth as possible, and for this reason, we follow usage and not specifications (or even, sometimes, logic). By all accounts, a large number of users still have .h C++ files so I don't think we should just consider all .h files C. Other approaches are possible, though at the cost of a large changes in how we process files in Linguist. We can look into these once the heuristic rules have been improved.
pchaigno
on 9 Jul 2018
In https://github.com/katesalazar/amara/search?l=markdown I see 164 src/ docs marked as C and 7 src/ docs marked as Objective-C. But I think they are all C.
I paste you several permalinks in case they are of any use for this issue.
- https://github.com/katesalazar/amara/blob/0521c6a95450f5698cce53b22dd05adb173f7a43/src/rtg/rtg_operation_tests.h
- https://github.com/katesalazar/amara/blob/0521c6a95450f5698cce53b22dd05adb173f7a43/src/stt/stt_identifier_subnode.h
- https://github.com/katesalazar/amara/blob/0521c6a95450f5698cce53b22dd05adb173f7a43/src/stt/stt_integer_literal_subnode.h
- https://github.com/katesalazar/amara/blob/0521c6a95450f5698cce53b22dd05adb173f7a43/src/stt/stt_natural_subnode.h
- https://github.com/katesalazar/amara/blob/0521c6a95450f5698cce53b22dd05adb173f7a43/src/stt/stt_operation_subnode.h
- https://github.com/katesalazar/amara/blob/0521c6a95450f5698cce53b22dd05adb173f7a43/src/stt/stt_rational_subnode.h
- https://github.com/katesalazar/amara/blob/4d8634cb333f241a84100444a0192e214ab1a047/src/stt/stt_string_literal_subnode.h
These permalink docs that were reported as Objective-C, but I think they are C.
ghost
on 18 Oct 2018
I had some .h files in several of my repositories that were being classified as Objective-C/C++, so I added an override (*.h linguist-language=C), which works for the colored "language bar", however I did recently notice that search results still treat them as though they were Objective-C/C++.
For example, Sagiri/pluck is (correctly) shown as 82.4% C and 17.6% Assembly, which means 0% C++. But when you search the repository with language:c++, you still get a few C header files.
I didn't see any mention of a discrepancy between the "language bar" and search results, so I figured it was worth mentioning.
 Zeturic
on 7 Dec 2018
Zeturic
on 7 Dec 2018
Here are some C header files incorrectly classified as Objective-C.
https://github.com/gavinkflam/st/blob/master/config.h
https://github.com/gavinkflam/hid-apple-plugboard-git-dkms-kestrel/blob/master/config.h
https://github.com/gavinkflam/dwm/blob/master/config.h
https://github.com/gavinkflam/hid-apple-plugboard-git-dkms/blob/master/config.h
https://github.com/gavinkflam/hid-apple-plugboard/blob/2819dc99695d5a0559de121cfdbe2697814dfa5d/config.h
 gavinkflam
on 23 Feb 2019
gavinkflam
on 23 Feb 2019
Here are some more Objective-C false positives
https://github.com/mmontag/chip-player-js/search?l=objective-c
 mmontag
on 28 Feb 2019
mmontag
on 28 Feb 2019
Hi. I also have a very strong amount of Objective-C false positives in my repo.
https://github.com/jpcima/midiplay
It doesn't actually contain any, this source only has C++.
 jpcima
on 7 May 2019
jpcima
on 7 May 2019
Hi. I also have a very strong amount of Objective-C false positives in my repo.
https://github.com/jpcima/midiplay
It doesn't actually contain any, this source only has C++.
It seems your color bar can be fixed. Sadly, currently only the color bar, it seems. Be sure to read and understand https://github.com/github/linguist/issues/1626#issuecomment-445269204.
ghost
on 7 May 2019
@jpcima your high Objective-C total is due to one very large file (920kb): https://github.com/jpcima/midiplay/blob/master/sources/data/ins_names_data.h.
As it is over 320kb, it is also not showing in the search results when you click the language bar and then Objective-C due to the search code limitations referenced and linked to in https://github.com/github/linguist#my-repository-is-detected-as-the-wrong-language
Like most of the other cases mentioned in this issue, I don't think this is a situation where Linguist is going to be able to reliably detect the correct language in future because the file in question is a header file with an extension that is common across all the C-family languages and has very little variation in tokens, probably with none that are unique to C++.
To solve your issue, you'll need to implement an override - either by forcing the language, or excluding the file (ie marking as vendored or generated).
lildude
on 7 May 2019
Thanks for explanations and taking some time to examine @katesalazar @lildude.
It makes sense. I will implement necessary measures on my side.
jpcima
on 7 May 2019
I will implement necessary measures on my side.
I missed the important link https://github.com/cathugger/mkp224o/pull/14. Cheers!
ghost
on 7 May 2019
Probably not. It’s probably because the file is quite small and doesn’t appear to have anything that makes it uniquely C and the classifier has determined it to be C++ based on how closely it matches the samples we’ve got. This is an unfortunately common problem with the C-family header files, especially small files.
I don't understand why you do this "sample checking" to decide between C and C++. This will hardly give 100% correct results, given that the source code can be very similar, and in some cases valid in both languages.
I believe that a simpler approach would fix the majority of cases:
1 - Check if the file has structures/keywords that can only be used in C++. If yes, then it's C++.
2 - If, however, the file doesn't have any C++ specific code, decide between C and C++ by checking the amount of .c and .cpp files in the same folder/same project.
For mixed C/C++ projects, the user would always have the possibility to edit the .gitattributes file. But I believe these are the small minority of cases.
This is just a suggestion. I have C and C++ projects in github since 2014, and the language detection was always wrong in all my projects, even though 95% of them were C or C++ only (not mixed).
Thanks!
 felipeek
on 12 Jun 2019
felipeek
on 12 Jun 2019
I believe that a simpler approach would fix the majority of cases:
1 - Check if the file has structures/keywords that can only be used in C++. If yes, then it's C++.
2 - If, however, the file doesn't have any C++ specific code, decide between C and C++ by checking the amount of .c and .cpp files in the same folder/same project.
@felipeek That's what we're already doing. We have heuristics to identify C++-specific syntax, which takes precedence over the sample-based (Bayesian) classifier. If a heuristic is matched, then samples aren't even considered.
If you believe you can improve our current C++/C heuristics, we'd welcome a pull-request.
Alhadis
on 12 Jun 2019
false-positive obj-c not even a single close construct
https://github.com/moe123/macadam/search?l=Objective-C
false-positive c++
https://github.com/moe123/macadam/search?l=C%2B%2B
There are only few headers you could reasonably tag c++;
indeed, the two only matching your heuristics stricto sensu:
https://github.com/moe123/macadam/blob/master/macadam/details/mc_target.h
https://github.com/moe123/macadam/blob/master/macadam/mcmath.h
Hence your model has other issues.
Question: can we force re-indexing properly by hand?
 moe123
on 21 Nov 2019
moe123
on 21 Nov 2019
_Generic is a C only keyword, that could be used to detect C from C++ or Objective-C/++
and template could be used to detect C++ headers with the C header extension instead of assuming .h = C.
 MarcusJohnson91
on 19 Jun 2020
MarcusJohnson91
on 19 Jun 2020
I have no .cpp files in my project,
None of my code matches the heuristic patterns for cpp,
I have a .gitattributes with *.h linguist-language=C,
and yet still github thinks some of my headers are cpp
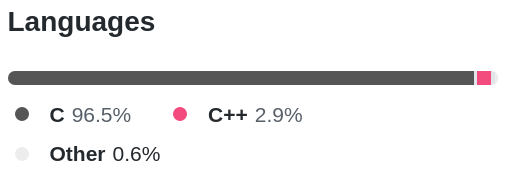
https://github.com/zeta-lang/czeta/search?l=c%2B%2B
 noxabellus
on 29 Jun 2020
noxabellus
on 29 Jun 2020
Have you added *.h linguist-detectable=true to your gitattributes file?
It does the same for my C only project as well, tho at least it surpresses it from showing up in the bar on the project page.
https://github.com/MarcusJohnson91/FoundationIO/search?l=c%2B%2B
MarcusJohnson91
on 29 Jun 2020
It seems that it takes a while for the language statistics bar to update once you have added the .gitattributes file (fwiw, I dont have linguist-detectable, just linguist-language=C) as now, roughly an hour after pushing the change, my bar is displaying correctly
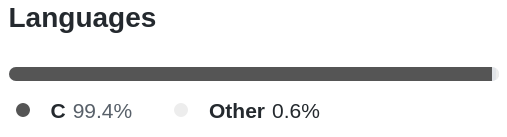
The files that are recognized by default as c++ still show up as such in the project search, though.
noxabellus
on 29 Jun 2020
@noxabellus yours is not so bad ;LOL; https://github.com/moe123/macadam/search?l=c ; c++ I could understand the dilemma; obj-c very not; linguist is just a front-end patch nothing else. The core problem is the github indexation model which is polluted.
moe123
on 29 Jun 2020
IMO #import ought to be removed as a pattern for Objective-C. Although it began as an ObjC feature, it is implemented for C/C++ by clang and GCC, and (differently) for C++ by Microsoft. Detecting #import as objc is a significant source of misclassification for my headers.
 drewcrawford
on 26 Jul 2020
drewcrawford
on 26 Jul 2020
Until an advanced fix is complete and well tested (which might not even be mathematically possible), why not just skip headers for projects with non-header files? The ratio between languages will be mostly the same from having mostly one header per implementation file.
 Dawoodoz
on 22 Nov 2020
Dawoodoz
on 22 Nov 2020
I found one of the C header files in my project was being misidentified as Objective-C, so thought I'd investigate. I first started deleting lines until I had a minimal reproduction case. Here is what I came up with (stored as test.h, in case filename is relevant):
struct V {
int capacity;
};
As written, this identifies as Objective-C, but if I change the name of capacity to anything else, it identifies as C. I went back to my original file, and saw the same behaviour: a struct with a member named "capacity" causes the file to be identified as Objective-C, and renaming it to anything else gives C.
I understand this is an impossible decision to make automatically, as Objective-C is a superset of C, but imo there should be a higher threshold for marking a file as Objective-C than the naming of one struct member.
Edit: Not to imply that such detection is intended behaviour; I don't see the word capacity mentioned in any of the heuristics linked to from this thread.
 tombsar
on 2 Dec 2020
tombsar
on 2 Dec 2020
capacity is a term that ObjC developers are perhaps more likely to use culturally, and you see this sort of naming in the example files in this repo. Of course there’s no reason any language can’t use the word “capacity” to name something.
The longer I think about this example, the more convinced I am that this problem requires a text classification (e.g. neural network) approach. Regex classification works when you have a keyword table in a language reference that is radically different, but between C/++/ObjC they have substantially similar keywords, and a lot of the facts you “learn” with simple systems is wrong facts like “capacity is an ObjC keyword”
In reality it’s context-sensitive (does it occur within an objc selector?). That question itself involves a bunch of other language rules, which you can try to regex with lookarounds but I suspect it’s a losing battle. This is I think why behavior for this language combination is poor, you just can’t get a good result from tools that distinguish very different languages, for languages that are this similar.
Understanding the context requires an embedding of the language grammar, that is whether we are naming a field right now (as in @tombsar ’s example) or an ObjC method, a field in an ObjC object, property, or something else. An NN would learn such an embedding as a matter of course, and would understand that while we may be using ObjC-friendly names it remembers that the context is a struct. Another benefit is you could maintain more easily by people submitting their mis classified code and just retraining the model, no code changes required.
Unfortunately I know nothing about good ruby NN implementations, how portable they are etc. I just suspect that without one, we won’t be able to tell examples like this apart very thoroughly.
drewcrawford
on 3 Dec 2020
As written, this identifies as Objective-C, but if I change the name of
capacityto anything else, it identifies as C. I went back to my original file, and saw the same behaviour: a struct with a member named "capacity" causes the file to be identified as Objective-C, and renaming it to anything else gives C.
It should be based on keywords.
#import or @ Objective-C
template or class C++
_Generic, _Bool, _Complex C.
MarcusJohnson91
on 3 Dec 2020
capacity is a term that ObjC developers are perhaps more likely to use culturally, and you see this sort of naming in the example files in this repo.
I guessed it would be something like that. Note that "capacity" is a standard container member in the C++ STL, so a larger range of sample code might pick up that commonality.
It should be based on keywords.
#importor@Objective-C
templateorclassC++
_Generic,_Bool,_ComplexC.
I think what I'm seeing is that some of my files have none of those keywords, so a heuristic is being used to classify instead, leading to the surprising results.
My preference would be that such files (ones that don't match any of the language-specific keywords or constructs) are classified as C, since that is the lowest common denominator between the three languages, but I understand why you might not want that as a solution.
A properly-trained RNN classifier is probably the way to go if you want best-possible results, but I likewise don't know anything about the Ruby ecosystem to know what to suggest there.
tombsar
on 3 Dec 2020
Shouldn't linguist just look if the majority of the code is C? If the majority of the code is C, the 'Objective-C' file should be marked as C, and vice-versa.
For projects that use both C and C++, see what is used in the directory and assume that.
 ItzSwirlz
on 11 Dec 2020
ItzSwirlz
on 11 Dec 2020
Shouldn't linguist just look if the majority of the code is C? If the majority of the code is C, the 'Objective-C' file should be marked as C, and vice-versa.
For projects that use both C and C++, see what is used in the directory and assume that.
Totally agree. This is what I suggested in this thread some time ago. I think linguist should define a threshold - let's say 80% - and when it detects that 80% or more of the files that are inside the project/directory are identified as C, for example, it should just assume the others are C as well.
This would obviously do not solve the issue, since somebody could, theoretically, have half of the files C++ and the other files C inside his project/folder. However, I think this would solve 99% of the cases, so in my opinion it is totally worth doing
felipeek
on 12 Dec 2020
struct V { int capacity; };
Interestingly, this minimal reproduction is the same number of SLOC as my production sample for this case: https://github.com/Starwort/NEA/blob/master/solver_c/memory.h - I don't want to repeatedly push changes to my repository and I don't want to install the numerous dependencies for running linguist myself, so I haven't been able to minimise it, but I don't see why it would identify as C++
memory.h
#include "types.h"
Board* allocate_board();
void free_board(Board* board);
 Starwort
on 6 Jan 2021
Starwort
on 6 Jan 2021
What if we added a dedicated strategy for C-like header files? This is such a commonly reported problem, it must comprise at least 80% of complaints about misclassified files.
I envision the strategy to behave like this:
- For every
.hfile, check for a file with a matching path (sans file extension), ending in.c,.cpp,.cc(etc) - Assert that only one such definition file exists (I assume authors don't have
foo.hin a directory withfoo.candfoo.cpp) - Defer analysis of the
.hfile until its counterpart has been evaluated - Assert that the counterpart's language is one of C, C++, or Objective-C.
- Use the language of the corresponding definition file as the language of the
.hfile
If one of these steps is unsuccessful, fall through to the usual behaviour of heuristics, followed by Bayesian classification.
Would this be a feasible approach, or am I being naïve here?
Alhadis
on 6 Jan 2021
Related issues
 TimothyGu
·
5Comments
arfon
·
6Comments
TimothyGu
·
5Comments
arfon
·
6Comments
 oldmud0
·
6Comments
oldmud0
·
6Comments
 siscia
·
6Comments
siscia
·
6Comments
 RafaelPAndrade
·
4Comments
RafaelPAndrade
·
4Comments
Most helpful comment
I had some
.hfiles in several of my repositories that were being classified as Objective-C/C++, so I added an override (*.h linguist-language=C), which works for the colored "language bar", however I did recently notice that search results still treat them as though they were Objective-C/C++.For example, Sagiri/pluck is (correctly) shown as 82.4% C and 17.6% Assembly, which means 0% C++. But when you search the repository with
language:c++, you still get a few C header files.I didn't see any mention of a discrepancy between the "language bar" and search results, so I figured it was worth mentioning.