Lighthouse: SEO Evaluation Error - Robots.txt
Current build claims an SEO reduction / penalty for many pages listing robots.txt as marking pages blocked from indexing when this is not the case at all when pages are tested with multiple crawlers and with Google Search Console. Seems to be a bug in this build.
 strayangelfilms
strayangelfilms
All 10 comments
this message display on my website report "Search engines are unable to include your pages in search results if they don't have permission to crawl them."
 ashishdhade
on 18 May 2018
ashishdhade
on 18 May 2018
Do you have a URL for us to take a look at @strayangelfilms?
 patrickhulce
on 18 May 2018
patrickhulce
on 18 May 2018
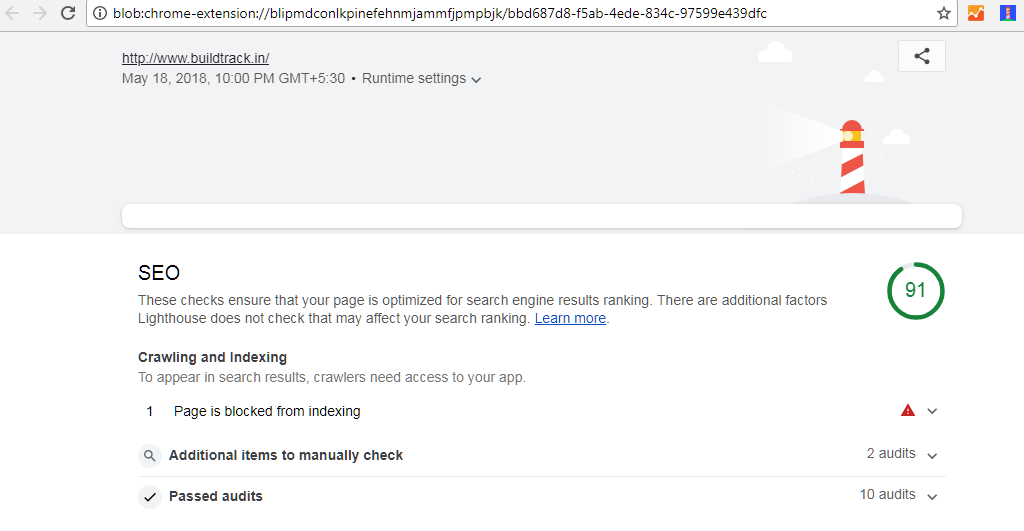
please check this http://www.buildtrack.in/
ashishdhade
on 18 May 2018
Thanks for sharing @ashishdhade!
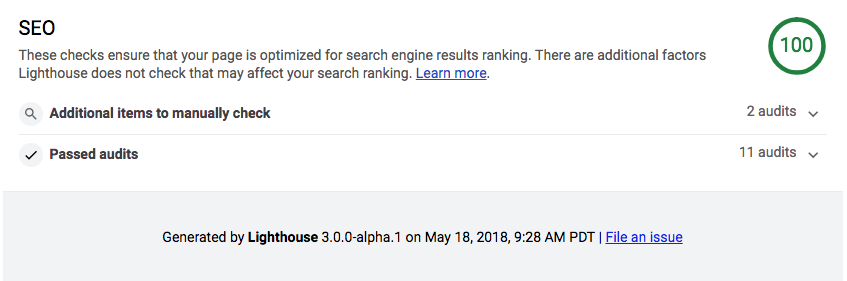
I'm seeing a 100 for SEO on that site
patrickhulce
on 18 May 2018
welcome @patrickhulce but please check this
ashishdhade
on 18 May 2018
Hello @patrickhulce
ashishdhade
on 18 May 2018
Try www.strayangel.com or www.lockebridge.com as two examples of sites with valid robot.txt that Lighthouse claims are being blocked but are not.
On May 18, 2018, at 9:22 AM, Patrick Hulce notifications@github.com wrote:
Do you have a URL for us to take a look at @strayangelfilms?
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub, or mute the thread.
strayangelfilms
on 18 May 2018
lockebridge is fine

for strayangel, LH is complaining about a meta tag explicitly saying noindex, not the robots.txt
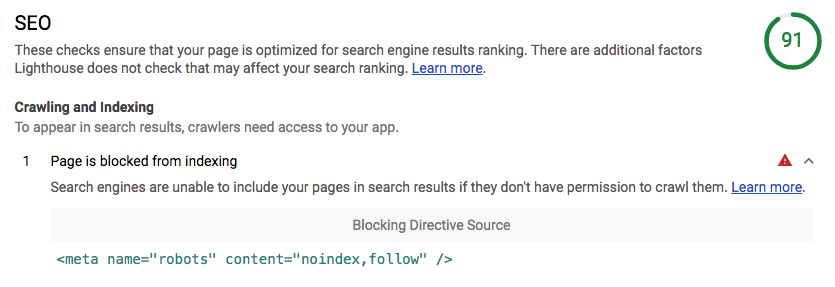
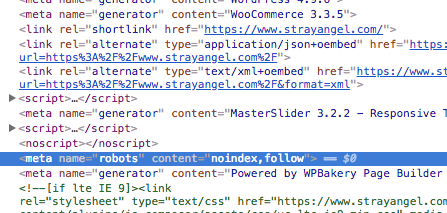
EDIT: the cached version that shows up in google is 4 days old and does not have the meta tag
patrickhulce
on 18 May 2018
Wow, you really saved my butt on this, there was a WooCommerce setting that was inadvertently telling the home page not to index! Very obscure and took 4 hours to track down. And here I am reporting bugs that aren’t bugs at all. Sorry!!! Thanks @patrickhulce !!!
strayangelfilms
on 19 May 2018
no prob, glad it worked out :)
patrickhulce
on 19 May 2018
Related issues
 muuvmuuv
·
3Comments
muuvmuuv
·
3Comments
 nl-igor
·
3Comments
nl-igor
·
3Comments
 Simply007
·
3Comments
Simply007
·
3Comments
 mjara74
·
3Comments
mjara74
·
3Comments
 codepodu
·
3Comments
codepodu
·
3Comments
Most helpful comment
lockebridge is fine

for strayangel, LH is complaining about a meta tag explicitly saying noindex, not the robots.txt

EDIT: the cached version that shows up in google is 4 days old and does not have the meta tag