Lightgbm: output model metadata when predicting
Hi folks,
Could be possible when predicting get the number of "samples used" in each tree?
I'm studying to use it as an input to another model in the stack
For example:
tree 1 - the leaf used 15 samples of 10k sub samples of 15k total samples (i don't know if subsample can be different from total samples)
tree 2 - 20 samples of 9k sub samples
...
total samples = [15/10000, 20/9000 ....] (an array of number of samples)
any idea?
 rspadim
rspadim
All 25 comments
sorry, could you describe it clearer? I didn't understand your issue.
What is the "samples used" in each tree? Did you mean multiple GBDT models?
 guolinke
on 29 Sep 2019
guolinke
on 29 Sep 2019
Hi @guolinke, for each tree we have some metadata about samples, i will post an image example here:
https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRcn7a7bHwhEuueUD0zxo17A-QYc4JmIK6bn4fJfze7pH3c9RSYvVJ3UNwyUA
I want the “samples =1”, 47 ,48 ... the “number of samples used at leaf” and the total samples used in the tree (train data length)
rspadim
on 29 Sep 2019
did you mean the number of samples per leaf?
you can get it from the trained GBDT model: https://github.com/microsoft/LightGBM/blob/e6505417eff10d1bae863d72d2a08469afc19e04/include/LightGBM/tree.h#L394
guolinke
on 30 Sep 2019
but how could i get it when executing predict?
for example:
output, leaf_samples_used = trained_model.predict(some_X_values, output_leaf_samples=True)
i want for each X row the predicted output + the number of samples/data length of each leaf/tree
rspadim
on 30 Sep 2019
you can use pred_leaf, and count the samples in each leaf index by yourself.
guolinke
on 30 Sep 2019
Ok i will test, i din’t know how to leave this issue “partially open” or ”waiting reply“
thanks @goulinke
rspadim
on 30 Sep 2019
The idea is get informatin from original train data, anyway i will test it
rspadim
on 30 Sep 2019
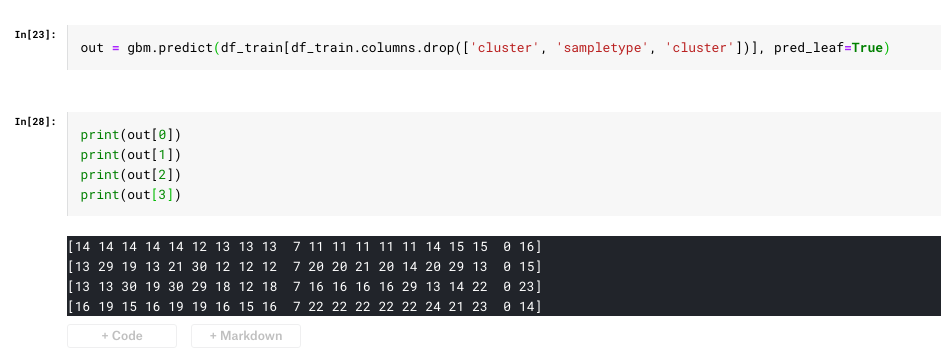
it output the sample, but i don't have access to total data size, to create a % of samples used, is it using all data from training set? can each tree have a subsample with less data?
rspadim
on 30 Sep 2019
the out[0] is the leaf index for the sample 0,
and out[i] is the leaf index of the sample i.
you can sample your need samples from out.
guolinke
on 1 Oct 2019
Ok I understood.
The doubt now is: out[0][0] is the number of samples at tree 0 at leaf used to predict sample 0. How many samples were used to train the tree 0?
rspadim
on 1 Oct 2019
all trees are using the all samples in the training of GBDT, except you set bagging.
guolinke
on 1 Oct 2019
Nice
1) The “first leaf” of a tree (i’m not considering predict function) have this information? (Number of samples when training)
2) in my example i have a tree with leaf with 0 samples, in this case the output is the model bias? I didn’t checked this before just curious about this
rspadim
on 1 Oct 2019
@rspadim
out[i][j] = k means the leaf index of the i-th sample on j-th tree is k.
for the number of samples in each leaf of each tree, you should count them by these indices by yourself.
guolinke
on 1 Oct 2019
i got the tree info:
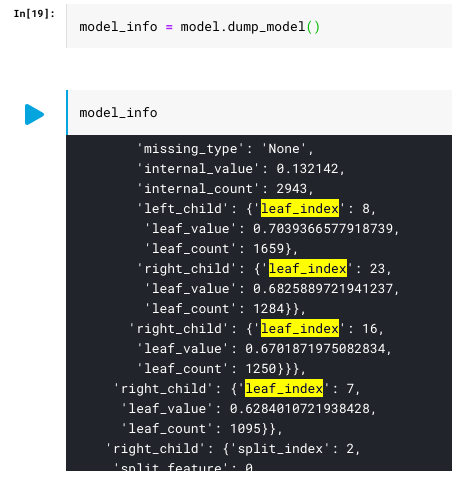
should i walk the tree and enumerate the leafs? or there's other method to easily output all leafs structure?
rspadim
on 1 Oct 2019
maybe i'm doing something wrong...
i did this:
def get_sub_leafs(leafs, child):
if type(child) is not dict:
return
if 'leaf_index' in child.keys():
leafs[child['leaf_index']] = child
if('left_child' in child.keys()):
get_sub_leafs(leafs, child['left_child'])
if('right_child' in child.keys()):
get_sub_leafs(leafs, child['right_child'])
def get_leafs(tree_info):
if type(tree_info) is not list:
return []
ret = []
for i in range(len(tree_info)):
tree = tree_info[i]
if 'tree_structure' not in tree.keys():
ret.append([])
continue
leafs = {}
get_sub_leafs(leafs, tree['tree_structure'])
ret.append(leafs)
return ret
def leaf_samples(pred_leaf_output, leafs):
ret = []
for i in range(len(pred_leaf_output)):
sample = []
for l in range(len(pred_leaf_output[i])):
leaf = pred_leaf_output[i][l]
# print(i,l,leaf)
sample.append(leafs[i][leaf]['leaf_count'])
ret.append(sample)
return ret
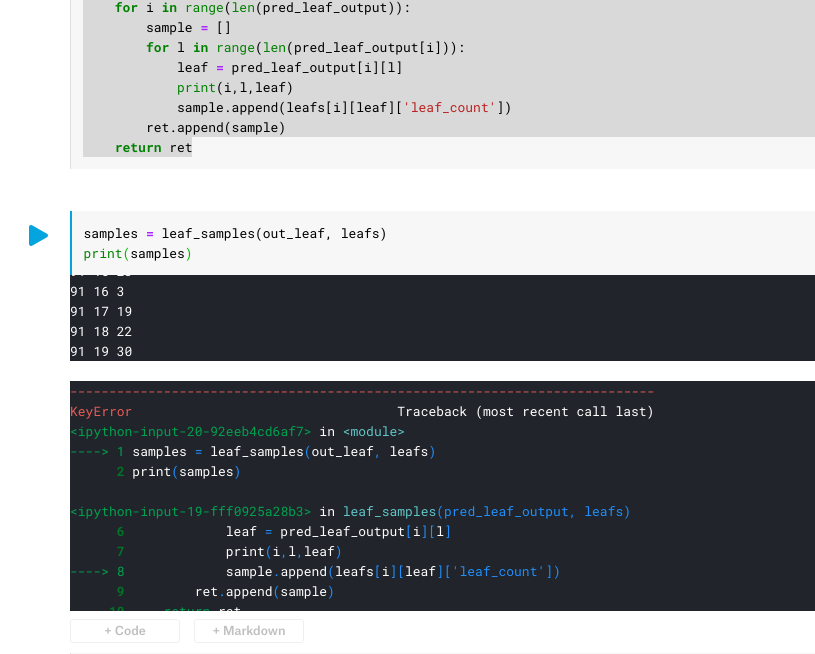
checking the model output, the leaf_index: 30, doesn't exists at model dump
the sample is=91, tree=19, leaf index=30
from model dump:
print(model_info['tree_info'][91])
{'tree_index': 91, 'num_leaves': 29, 'num_cat': 0, 'shrinkage': 0.1, 'tree_structure': {'split_index': 0, 'split_feature': 3, 'split_gain': 0.37031400203704834, 'threshold': 0.28011239035087726, 'decision_type': '<=', 'default_left': True, 'missing_type': 'None', 'internal_value': 0, 'internal_count': 80000, 'left_child': {'split_index': 2, 'split_feature': 2, 'split_gain': 0.37882599234580994, 'threshold': 0.012133480554533187, 'decision_type': '<=', 'default_left': True, 'missing_type': 'None', 'internal_value': 6.6345e-05, 'internal_count': 79924, 'left_child': {'split_index': 15, 'split_feature': 7, 'split_gain': 0.42527198791503906, 'threshold': 7.952119376772665, 'decision_type': '<=', 'default_left': True, 'missing_type': 'None', 'internal_value': 0.0064674, 'internal_count': 8287, 'left_child': {'split_index': 16, 'split_feature': 0, 'split_gain': 0.5021479725837708, 'threshold': 0.18156757166691948, 'decision_type': '<=', 'default_left': True, 'missing_type': 'None', 'internal_value': 0.00719231, 'internal_count': 8203, 'left_child': {'split_index': 20, 'split_feature': 11, 'split_gain': 0.837020993232727, 'threshold': 0.2571629870130723, 'decision_type': '<=', 'default_left': True, 'missing_type': 'None', 'internal_value': 0.00274671, 'internal_count': 6201, 'left_child': {'split_index': 21, 'split_feature': 1, 'split_gain': 0.813372015953064, 'threshold': 0.9739680142503099, 'decision_type': '<=', 'default_left': True, 'missing_type': 'None', 'internal_value': -0.118957, 'internal_count': 56, 'left_child': {'leaf_index': 0, 'leaf_value': -0.001834329550690723, 'leaf_count': 33}, 'right_child': {'leaf_index': 22, 'leaf_value': -0.026331601972165317, 'leaf_count': 23}}, 'right_child': {'split_index': 22, 'split_feature': 3, 'split_gain': 0.7716929912567139, 'threshold': 0.05531775377497678, 'decision_type': '<=', 'default_left': True, 'missing_type': 'None', 'internal_value': 0.00385581, 'internal_count': 6145, 'left_child': {'leaf_index': 21, 'leaf_value': 0.00021826397540176498, 'leaf_count': 6011}, 'right_child': {'leaf_index': 23, 'leaf_value': 0.00789112667340278, 'leaf_count': 134}}}, 'right_child': {'split_index': 17, 'split_feature': 2, 'split_gain': 1.233199954032898, 'threshold': 0.01032778725824801, 'decision_type': '<=', 'default_left': True, 'missing_type': 'None', 'internal_value': 0.0209621, 'internal_count': 2002, 'left_child': {'split_index': 18, 'split_feature': 10, 'split_gain': 2.243410110473633, 'threshold': 0.500356821922273, 'decision_type': '<=', 'default_left': True, 'missing_type': 'None', 'internal_value': -0.00622574, 'internal_count': 910, 'left_child': {'leaf_index': 17, 'leaf_value': 0.0031762346052802734, 'leaf_count': 574}, 'right_child': {'leaf_index': 19, 'leaf_value': -0.007112204077042234, 'leaf_count': 336}}, 'right_child': {'split_index': 19, 'split_feature': 9, 'split_gain': 0.9244379997253418, 'threshold': 0.38616044927221177, 'decision_type': '<=', 'default_left': True, 'missing_type': 'None', 'internal_value': 0.0436187, 'internal_count': 1092, 'left_child': {'leaf_index': 18, 'leaf_value': 0.005976045099091417, 'leaf_count': 835}, 'right_child': {'leaf_index': 20, 'leaf_value': -0.0008826310980207435, 'leaf_count': 257}}}}, 'right_child': {'split_index': 23, 'split_feature': 0, 'split_gain': 0.4760499894618988, 'threshold': 0.19532388848396504, 'decision_type': '<=', 'default_left': True, 'missing_type': 'None', 'internal_value': -0.0643242, 'internal_count': 84, 'left_child': {'split_index': 27, 'split_feature': 3, 'split_gain': 0.18526700139045715, 'threshold': 0.011922530206112296, 'decision_type': '<=', 'default_left': True, 'missing_type': 'None', 'internal_value': -0.0125121, 'internal_count': 57, 'left_child': {'leaf_index': 16, 'leaf_value': 0.0032687900241996563, 'leaf_count': 35}, 'right_child': {'leaf_index': 28, 'leaf_value': -0.008442120747217402, 'leaf_count': 22}}, 'right_child': {'leaf_index': 24, 'leaf_value': -0.017370522288277884, 'leaf_count': 27}}}, 'right_child': {'split_index': 3, 'split_feature': 6, 'split_gain': 1.1605900526046753, 'threshold': 6.458729519970906, 'decision_type': '<=', 'default_left': True, 'missing_type': 'None', 'internal_value': -0.000674132, 'internal_count': 71637, 'left_child': {'split_index': 4, 'split_feature': 5, 'split_gain': 3.2690699100494385, 'threshold': 6.906754528147679, 'decision_type': '<=', 'default_left': True, 'missing_type': 'None', 'internal_value': -0.0367872, 'internal_count': 879, 'left_child': {'split_index': 5, 'split_feature': 2, 'split_gain': 1.7535699605941772, 'threshold': 0.9847638355825183, 'decision_type': '<=', 'default_left': True, 'missing_type': 'None', 'internal_value': 0.0175496, 'internal_count': 490, 'left_child': {'split_index': 6, 'split_feature': 9, 'split_gain': 1.158959984779358, 'threshold': 0.14765311307309037, 'decision_type': '<=', 'default_left': True, 'missing_type': 'None', 'internal_value': 0.0302083, 'internal_count': 469, 'left_child': {'leaf_index': 3, 'leaf_value': 0.009705686127672163, 'leaf_count': 167}, 'right_child': {'leaf_index': 7, 'leaf_value': -0.0006757681012085782, 'leaf_count': 302}}, 'right_child': {'leaf_index': 6, 'leaf_value': -0.026515952639636544, 'leaf_count': 21}}, 'right_child': {'split_index': 11, 'split_feature': 4, 'split_gain': 0.6049360036849976, 'threshold': 7.223092500459664, 'decision_type': '<=', 'default_left': True, 'missing_type': 'None', 'internal_value': -0.105232, 'internal_count': 389, 'left_child': {'split_index': 12, 'split_feature': 10, 'split_gain': 0.6287130117416382, 'threshold': 0.7882377992279866, 'decision_type': '<=', 'default_left': True, 'missing_type': 'None', 'internal_value': -0.0840663, 'internal_count': 302, 'left_child': {'leaf_index': 5, 'leaf_value': -0.010031780547921984, 'leaf_count': 268}, 'right_child': {'leaf_index': 13, 'leaf_value': 0.0044034229344962275, 'leaf_count': 34}}, 'right_child': {'split_index': 25, 'split_feature': 3, 'split_gain': 0.3017579913139343, 'threshold': 0.012326685660018995, 'decision_type': '<=', 'default_left': True, 'missing_type': 'None', 'internal_value': -0.178704, 'internal_count': 87, 'left_child': {'leaf_index': 12, 'leaf_value': -0.014235441428461363, 'leaf_count': 63}, 'right_child': {'leaf_index': 26, 'leaf_value': -0.02741233603058693, 'leaf_count': 24}}}}, 'right_child': {'split_index': 7, 'split_feature': 10, 'split_gain': 1.0139299631118774, 'threshold': 0.3561216412419172, 'decision_type': '<=', 'default_left': True, 'missing_type': 'None', 'internal_value': -0.000225512, 'internal_count': 70758, 'left_child': {'split_index': 13, 'split_feature': 11, 'split_gain': 0.6041600108146667, 'threshold': 0.4328192536070275, 'decision_type': '<=', 'default_left': True, 'missing_type': 'None', 'internal_value': -0.0456502, 'internal_count': 488, 'left_child': {'split_index': 24, 'split_feature': 2, 'split_gain': 0.3462580144405365, 'threshold': 0.5672950071037143, 'decision_type': '<=', 'default_left': True, 'missing_type': 'None', 'internal_value': -0.00697562, 'internal_count': 221, 'left_child': {'leaf_index': 4, 'leaf_value': -0.002837940782527453, 'leaf_count': 171}, 'right_child': {'leaf_index': 25, 'leaf_value': 0.006622533943504096, 'leaf_count': 50}}, 'right_child': {'split_index': 14, 'split_feature': 2, 'split_gain': 0.6965410113334656, 'threshold': 0.09549816707894973, 'decision_type': '<=', 'default_left': True, 'missing_type': 'None', 'internal_value': -0.0776617, 'internal_count': 267, 'left_child': {'leaf_index': 14, 'leaf_value': -0.001371845854345548, 'leaf_count': 104}, 'right_child': {'leaf_index': 15, 'leaf_value': -0.01184598701788924, 'leaf_count': 163}}}, 'right_child': {'split_index': 8, 'split_feature': 7, 'split_gain': 0.6192629933357239, 'threshold': 6.301189389855213, 'decision_type': '<=', 'default_left': True, 'missing_type': 'None', 'internal_value': 8.99458e-05, 'internal_count': 70270, 'left_child': {'split_index': 10, 'split_feature': 6, 'split_gain': 0.9836350083351135, 'threshold': 7.432817600849191, 'decision_type': '<=', 'default_left': True, 'missing_type': 'None', 'internal_value': 0.0085283, 'internal_count': 7739, 'left_child': {'leaf_index': 8, 'leaf_value': 0.001848188888246156, 'leaf_count': 4349}, 'right_child': {'leaf_index': 11, 'leaf_value': -0.0004241071411989574, 'leaf_count': 3390}}, 'right_child': {'split_index': 9, 'split_feature': 6, 'split_gain': 1.1857099533081055, 'threshold': 6.96638171139069, 'decision_type': '<=', 'default_left': True, 'missing_type': 'None', 'internal_value': -0.000954407, 'internal_count': 62531, 'left_child': {'leaf_index': 9, 'leaf_value': -0.0034753251319082296, 'leaf_count': 1021}, 'right_child': {'leaf_index': 10, 'leaf_value': -3.9338225566242505e-05, 'leaf_count': 61510}}}}}}, 'right_child': {'split_index': 1, 'split_feature': 6, 'split_gain': 0.899740993976593, 'threshold': 7.800211429504976, 'decision_type': '<=', 'default_left': True, 'missing_type': 'None', 'internal_value': -0.0697705, 'internal_count': 76, 'left_child': {'leaf_index': 1, 'leaf_value': -0.019397264922207055, 'leaf_count': 33}, 'right_child': {'split_index': 26, 'split_feature': 4, 'split_gain': 0.23882700502872467, 'threshold': 8.177268044866095, 'decision_type': '<=', 'default_left': True, 'missing_type': 'None', 'internal_value': 0.0255475, 'internal_count': 43, 'left_child': {'leaf_index': 2, 'leaf_value': 0.009504335168141712, 'leaf_count': 23}, 'right_child': {'leaf_index': 27, 'leaf_value': -0.0054372740653343505, 'leaf_count': 20}}}}}
print(leafs[31])
{0: {'leaf_index': 0, 'leaf_value': 0.009762649535827462, 'leaf_count': 122}, 29: {'leaf_index': 29, 'leaf_value': -0.013846047478978352, 'leaf_count': 93}, 27: {'leaf_index': 27, 'leaf_value': -0.0173753812567765, 'leaf_count': 251}, 21: {'leaf_index': 21, 'leaf_value': 0.0008709151264456015, 'leaf_count': 1199}, 24: {'leaf_index': 24, 'leaf_value': -0.006885982553677898, 'leaf_count': 2081}, 23: {'leaf_index': 23, 'leaf_value': 0.0016059135602401, 'leaf_count': 3578}, 22: {'leaf_index': 22, 'leaf_value': -0.010276423748379034, 'leaf_count': 183}, 25: {'leaf_index': 25, 'leaf_value': 0.005689893848585681, 'leaf_count': 2081}, 11: {'leaf_index': 11, 'leaf_value': -0.010325861321599987, 'leaf_count': 732}, 26: {'leaf_index': 26, 'leaf_value': -0.0017955757727865333, 'leaf_count': 1323}, 20: {'leaf_index': 20, 'leaf_value': -0.013766754918170655, 'leaf_count': 833}, 12: {'leaf_index': 12, 'leaf_value': -0.027914699030419196, 'leaf_count': 75}, 13: {'leaf_index': 13, 'leaf_value': 7.406045877918877e-05, 'leaf_count': 2598}, 1: {'leaf_index': 1, 'leaf_value': -0.021399474504737143, 'leaf_count': 176}, 15: {'leaf_index': 15, 'leaf_value': 0.0031584091338895818, 'leaf_count': 442}, 28: {'leaf_index': 28, 'leaf_value': -0.022917549021076414, 'leaf_count': 52}, 14: {'leaf_index': 14, 'leaf_value': 0.002561596790227553, 'leaf_count': 3453}, 30: {'leaf_index': 30, 'leaf_value': 0.007183236291191282, 'leaf_count': 2105}, 2: {'leaf_index': 2, 'leaf_value': -0.02459001061242535, 'leaf_count': 97}, 9: {'leaf_index': 9, 'leaf_value': 0.0025377422957305017, 'leaf_count': 18411}, 19: {'leaf_index': 19, 'leaf_value': -0.004778496542606137, 'leaf_count': 1342}, 17: {'leaf_index': 17, 'leaf_value': -0.002647468640075182, 'leaf_count': 8836}, 18: {'leaf_index': 18, 'leaf_value': 0.002434694480521371, 'leaf_count': 7558}, 3: {'leaf_index': 3, 'leaf_value': -0.00041535103581648183, 'leaf_count': 5147}, 16: {'leaf_index': 16, 'leaf_value': 0.003951455048737675, 'leaf_count': 5486}, 5: {'leaf_index': 5, 'leaf_value': -0.006352375919329612, 'leaf_count': 2777}, 10: {'leaf_index': 10, 'leaf_value': 0.001345508953114763, 'leaf_count': 1667}, 4: {'leaf_index': 4, 'leaf_value': -0.006847359113142332, 'leaf_count': 3106}, 7: {'leaf_index': 7, 'leaf_value': -0.04251719344372176, 'leaf_count': 106}, 6: {'leaf_index': 6, 'leaf_value': 0.003271148885369048, 'leaf_count': 1736}, 8: {'leaf_index': 8, 'leaf_value': -0.005115834456857492, 'leaf_count': 2354}}
if you need i can share the dataset/notebook
rspadim
on 1 Oct 2019
I don't know what you want to do from your code.
I think it should be leafs[l][leaf]
guolinke
on 2 Oct 2019
wow, sorry my typo, thanks, i will test
rspadim
on 2 Oct 2019
there's a "'internal_count': 80000", it's the train dataset right? if it's, i think we are done here with this issue
rspadim
on 2 Oct 2019
leaf_count is the number of training data falling to that leaf. internal_count is the number of training data passing through that non-leaf node.
guolinke
on 2 Oct 2019
uhm, for example... the training data have 100k rows, the sample to create the first tree have 80k, the 80k is the "non-leaf"? i'm at the top of tree model (not in a node/leaf) the first "internal_count" i can read at the json dictionary of model dump
rspadim
on 2 Oct 2019
sorry, I don't understand it..
the sum of leaf_count over all leaves, is 80k in your example.
and the internal_count = count_of_its_left_node + count_of_its_right_node, and the internal_count of the root node is 80k.
guolinke
on 2 Oct 2019
uhmmm, well i think it's ok
my doubt is more about something that i don't know how lgb handles, if a tree can be fit with 80k samples and the other one with 79k for example (in the same model), that's why i'm trying to find how many samples was used (in each tree)
rspadim
on 2 Oct 2019
all trees are using the same number of data (all training data if without bagging) in the one GBDT model.
Even with bagging, we will use the same number of data for each tree.
guolinke
on 2 Oct 2019
nice! :) i think we can close this iisue, thanks a lot guolinke, i used this code if someone else need:
def get_sub_leafs(leafs, child):
if type(child) is not dict:
return
if 'leaf_index' in child.keys():
leafs[child['leaf_index']] = child
if('left_child' in child.keys()):
get_sub_leafs(leafs, child['left_child'])
if('right_child' in child.keys()):
get_sub_leafs(leafs, child['right_child'])
def get_leafs(tree_info):
if type(tree_info) is not list:
return []
ret = []
for i in range(len(tree_info)):
tree = tree_info[i]
if 'tree_structure' not in tree.keys():
ret.append([])
continue
leafs = {}
get_sub_leafs(leafs, tree['tree_structure'])
ret.append(leafs)
return ret
def leaf_samples(pred_leaf_output, leafs):
ret = []
for i in range(len(pred_leaf_output)):
sample = []
for l in range(len(pred_leaf_output[i])):
leaf = pred_leaf_output[i][l]
sample.append(leafs[l][leaf]['leaf_count'])
ret.append(sample)
return ret
Related issues
 JoshuaC3
·
3Comments
JoshuaC3
·
3Comments
 jianqin123
·
3Comments
jianqin123
·
3Comments
 ahbon123
·
4Comments
ahbon123
·
4Comments
 John-Curcio
·
3Comments
John-Curcio
·
3Comments
 raphay3l
·
3Comments
raphay3l
·
3Comments