Leela-zero: Version 0.10 released - Next steps
Version 0.10 is released now. If no major bugs surface in the next few days the server will start enforcing this version.
There is this 1500+ post issue where most plans for the future were posted in the past. It's become rather problematic to read, especially on mobile, and mixed with a lot of theories (most not backed with any data or experiments 😉) so I'll post my plans and thoughts for the near future in this issue.
It looks like we're slowly reaching the maximum what 64x5 is capable of. I will let this run until about 2/3 of the training window is from the same network without improvement, and then drop the learning rate. I expect that's the last time we can do that and (maybe!) see some improvement.
I have been training a 128x6 network starting from the bug-fixed data (i.e. starting around eebb910d) and gradually moving it up to present day. Once 64x5 has completely stalled, I will see if I can get the 128x6 to beat it. If that works out, we can just continue from there and effectively skip the first 6500 Elo and see how much higher we can get (and perhaps do the same with even bigger networks) from continuing the current run.
If that kind of bootstrapping turns out not to work, I'd be interested in doing a new run. My ideas for that right now:
Somewhere between 128x6 and 128x10 sized network. 128x10 would be 8 times slower, but there is a ~2x speed improvement that we could expect to have merged in by then, and the total running time would be around half a year maybe? "Short" enough that people are probably mostly going to stick around. Hopefully also "big" enough that we can see pro level play.
Immediately use new networks for self play (i.e. according to the latest AZ paper). We see very strong strength see-sawing right now. It is possible that using the new network immediately lets the learning figure out why some of those are bad and thus produce faster improvement. It's also possible that this procedure produces no or very slow improvement for our unsynchronized distributed set up and this run ends up being a total failure. But I think we should try to find this out, in the interest of answering the question in case anyone ever tries a "full" 256x20 run on BOINC or an improved version of this project.
Small revision of weights format. There is a redundant bias layer (convolution output before BN) that needs to go, and I want to add a shift layer after the BatchNorm layers. The latter hasn't been generally shown to provide improvements (and I never found any in Go either), but it is computationally almost free and makes the design more generic, so we might as well include it. (Note that scale layers are completely redundant in the AGZ architecture so no point in adding those)
There's been a demonstration that instead of stopping at 1600 playouts per move, it may be more computationally efficient to stop at 2200 "visits" per move. So we should do that.
Thanks to all who have contributed computation power and code contributions to the project so far. We've validated that the AlphaGo approach is reproducible in a distributed setting - even if only on smaller scale - and made a dan player appear out of thin air.
Some personal words:
I have been very, very happy with the quality and extent of code contributions so far. It seems that many of you have found the codebase approachable enough to make major enhancements, or use it as a base for further learning or other experiments about Go or machine learning. I could not have hoped for a more positive outcome in that regard. My initial estimate was that 10-50 people would run the client, maybe one person would submit build fixes, and that would be it. Clearly, I was off by an order of magnitude, and I'm spending much more time than foreseen on doing things like reviewing pull requests etc. So please have some patience in that regard - I will keep trying to do those thoroughly.
For the people who have a lot of ideas and like to argue: convincing, actionable data (or even better, code that can be tested for effectiveness) will make my opinion flip-flop like the best/worst politician, whereas arguing with words only is likely to be as fun and effective as slamming your head against a wall repeatedly.
Miscellaneous:
I am very interested in any ideas or contributions that make me more redundant for this project. I have some ideas of my own that I want to test. My wife would also like to see me again!
The training and server portions run fully automatically now for the most part (cough @roy7), although some other things like uploading training data have been proven problematic to automate, so that won't be live for the foreseeable future either.
There's been a lot of concern about bad actors, vandalism, broken clients, etc, but so far the learning seems to be simply robust against this. There is now some ability to start filtering bad training data, but it remains tricky to make this solid and not give too much false positives. I'd advise only worrying when there are actual problems.
 gcp
gcp
All 732 comments
How does the 128x6 network training work? If we keep the same training pipeline as 64x5, it needs testing self-plays. Would the self-plays be done by some contributing clients, or would you do all of them yourself?
 RavnaBergsndot
on 7 Jan 2018
RavnaBergsndot
on 7 Jan 2018
"Once 64x5 has completely stalled, I will see if I can get the 128x6 to beat it."
Does it beat it now? :)
 ssj-gz
on 7 Jan 2018
ssj-gz
on 7 Jan 2018
@gcp Thanks!
 marcocalignano
on 7 Jan 2018
marcocalignano
on 7 Jan 2018
Would the self-plays be done by some contributing clients, or would you do all of them yourself?
I can upload the networks and schedule tests for them, same as it happens for the regular networks. The clients won't really notice, they'll just run a bit slower :-)
gcp
on 7 Jan 2018
@gcp thanks.
 john45678
on 7 Jan 2018
john45678
on 7 Jan 2018
Thank you for running this project, it's been a delight to follow and contribute wherever possible!
About the increase in network size: Is there any good way to test in which cases increasing number of filters helps more, and where the Deepmind approach "Stack more layers" is better? In other words, is there a significant possibility that something like 64x10 might reach similar strength as 128x6? Is there any way other than training supervised nets to find out?
 jkiliani
on 7 Jan 2018
jkiliani
on 7 Jan 2018
GCP and everyone involved, thank you very much for all your efforts! This project has been truly fascinating to follow it, both as a Go player as well as a developer. Looking forward to further experiments.
 fishcu
on 7 Jan 2018
fishcu
on 7 Jan 2018
Thks for the computer only version im generating games in 17 minutes instead of 5 hours XD, what a massive improvement!
 Matuiss2
on 7 Jan 2018
Matuiss2
on 7 Jan 2018
Thank you for running and managing this wonderful project :)
 grolich
on 7 Jan 2018
grolich
on 7 Jan 2018
Plans sound good. Just to be clear, with the 128x6. network are you moving up by the intevals of the 65x5 “best” networks using the 250k game window that those networs were trained upon? Also are you using a set number of steps? I guess this should work but other approaches are likely to work better.
Also, this will not really tell us if the difference in strength is due to the size of the networks or the differences in how they are trained.
 evanroberts85
on 7 Jan 2018
evanroberts85
on 7 Jan 2018
Is there any good way to test in which cases increasing number of filters helps more, and where the Deepmind approach "Stack more layers" is better?
Isn't Deepmind's approach stacking both more filters and more layers? AGZ has 256 filters.
RavnaBergsndot
on 7 Jan 2018
About the increase in network size: Is there any good way to test in which cases increasing number of filters helps more, and where the Deepmind approach "Stack more layers" is better? In other words, is there a significant possibility that something like 64x10 might reach similar strength as 128x6? Is there any way other than training supervised nets to find out?
I believe that in general stacking deeper is more attractive for the same (theoretical!) computational effort. You leave more opportunity to develop "higher level" features (or not, when not needed, especially in a resnet where inputs are forwarded!), or possibility for features to spread out their influence spatially. Deeper stacks are harder to train, but ResNets and BN appear to be pretty good at dealing with that.
But in terms of computational efficiency, a larger amount of filters tends to behave better, especially on big GPUs, because that part of the computation goes in parallel. The layers need to be processed serially.
"In theory" 128 filters are 4 times slower than 64 filters, but in practice, the difference is going to be much smaller.
gcp
on 7 Jan 2018
Isn't Deepmind's approach stacking both more filters and more layers? AGZ has 256 filters.
They did 256x20 and 256x40. They did not do 384x20, for example.
gcp
on 7 Jan 2018
Just to be clear, with the 128x6. network are you moving up by the intevals of the 65x5 “best” networks using the 250k game window that those networs were trained upon? I guess this should work but other approaches are likely to work better.
No, I started with a huge window and have been narrowing it to 250k.
gcp
on 7 Jan 2018
Thanks for the fantastic work! I'm interested in knowing how results for 2200 visits bit were obtained. Also, has anyone trained a supervised network with different depths and filters?
 barrtgt
on 7 Jan 2018
barrtgt
on 7 Jan 2018
I'm interested in knowing how results for 2200 visits bit were obtained
See the discussion in #546. There's still some work ongoing in this area, and further testing, but it looks promising. The idea is not to spend too much effort in lines that are very forced anyway.
gcp
on 7 Jan 2018
First I would like to thank @gcp and all contributors for this awesome project and efforts. Now we can prepare for the next run, and here are things I would like to clarify or discuss:
- AGZ uses rectifier nonlinearity, while we are currently using ReLU if I am not terribly wrong. For the new network, it could be desirable to change the activation from ReLU to a nonlinear one, but unfortunately the AGZ paper lacks details about this. What would be our choice? There are many options like LeakyReLU, CReLU, or ELU.
- For the training window, I still do not see any advantage we gain from including data from too weak networks. In addition to the training window by number of games, how about filtering out games based on rating also (like 300 or any reasonable value)?
- I am still dubious if the AZ approach is reproducible for us, when the computational resource is fluctuating. A milder approach would be to accept-if-not-too-bad one, and to prioritize networks with more training steps. Is it reasonable enough?
- For networks with more filters, #523 must be merged somehow. What should be done to accomplish this as fast as possible?
- This question probably cannot be answered without any experiment, but I always have been thinking that 8-moves history for the ko detection is too much, though more feature planes will lead to a stronger AI somehow practically. Can we consider reducing the input dimension from current 8x2+2 to a smaller one, like 4x2+2?
 isty2e
on 7 Jan 2018
isty2e
on 7 Jan 2018
A milder approach would be to accept-if-not-too-bad one, and to prioritize networks with more training steps. Is it reasonable enough?
But the goal of AZ is to eliminate evaluation matches. If you need to know "not-too-bad", you need evaluation matches and you could as well go full AGZ. (This is pretty much the opposite argument of what we used to reject switching to the AZ method this run)
Also, shouldn't we try to reproduce AZ exactly because "we're not sure if it is reproducible"? If we change all kind of things and then fail (or succeed), we still do not know if it is because we changed a bunch of stuff or because it's an inherently bad method.
Anyway, before we start with a new larger network. How viable would it be to do one or a few runs with a smaller network, but with some variables adapted. For example we could use the current games and train a 3x32 network, and then run 500k games. After that run a 3x32 network from scratch and run 1m games to see the result. (And would these results carry over to larger networks?)
Another experiment i like to see would be to try different window sizes. We could use the current 5x64 network for that. Just go back 1m games, and train the then best network with a 100k or 500k window (or possibly 2 runs with each window size), and then run 500k games or so.
We're at 43k games/day now, so experiments like that would take ~2 weeks, but might give valuable data on our next run that might take several months. using a 3x32 network could probably 4 fold our game output and only take a couple days to get meaningful result.
 Dorus
on 7 Jan 2018
Dorus
on 7 Jan 2018
AGZ uses rectifier nonlinearity, while we are currently using ReLU if I am not terribly wrong. For the new network, it could be desirable to change the activation from ReLU to a nonlinear one, but unfortunately the AGZ paper lacks details about this. What would be our choice? There are many options like LeakyReLU, CReLU, or ELU.
BN dramatically reduces, if not totally eliminates the assumed advantages of other fancy activations over ReLU. This is why all those huge CNNs(Res-101, 1201, etc) prefer trying all kinds of different structures and filter/layer combinations rather than exploiting the seemingly low-hanging fruits of better activation functions. They are not low-hanging fruits because they only offer advantages in some non-general cases and controlled environments.
By the way ReLU is a nonlinear function, and two layers of ReLU could theoretically approximate all continuous functions, just like tanh and sigmoid.
This question probably cannot be answered without any experiment, but I always have been thinking that 8-moves history for the ko detection is too much, though more feature planes will lead to a stronger AI somehow practically. Can we consider reducing the input dimension from current 8x2+2 to a smaller one, like 4x2+2?
4x2+2 can't detect triple-ko.
RavnaBergsndot
on 7 Jan 2018
>
I started [the 128x6 network] with a huge window and have been narrowing it.
You could repeat the same process but with a 64x5 network like the current
one, to see how much of the gain (if there is a gain) comes from the
increase in network size and what effect just changing the training had.
evanroberts85
on 7 Jan 2018
@Dorus It is true that there is no evaluation in AZ, but I am not sure if it is the purpose. In fact, the motivation for changes from AGZ to AZ is unclear in the paper.
@RavnaBergsndot That is theoretically true to an extent, but in practice it affects the performance more or less, usually depending on the nature of the dataset. A simple example would be this. After all, this project aims to be a faithful replication of AGZ, so why not? Also AFAIK a triple ko consist of 6 moves so 3x2+2 will do, and we are not adopting superko rules, so is it any meaningful to detect a triple ko after all?
isty2e
on 7 Jan 2018
A consistent training procedure with no added variables would be nice to compare different configurations. I think the 5x64 has quite a bit more potential, but was ham-stringed by a rough start. I like the idea of the AZ method of using the latest network. I vote to do a small scale AZ approach first.
barrtgt
on 7 Jan 2018
That is theoretically true to an extent, but in practice it affects the performance more or less, usually depending on the nature of the dataset. A simple example would be this. After all, this project aims to be a faithful replication of AGZ, so why not? Also AFAIK a triple ko consist of 6 moves so 3x2+2 will do, and we are not adopting superko rules, so is it any meaningful to detect a triple ko after all?
Most of the experiments in that paper were done without BN. BN enforces most input points falling into the most interesting part of the ReLU domain, therefore reduces the need of non-zero value outputs when the input is negative. We need more recent experiments.
I'm also not convinced that AGZ's "rectifier nonlinearity" means "rectifier plus nonlinearity on its negative domain" instead of just ReLU itself.
3x2+2 won't do, because that "x2" part is for the same turn. "These planes are concatenated together to give input features st = [Xt, Yt, Xt−1, Yt−1, ..., Xt−7, Yt−7, C]." Therefore for 6 moves, we need at least 6x2+2.
RavnaBergsndot
on 8 Jan 2018
I feel the need for a more general discussion, more beginner friendly and less specifically about
leela. Please have a look at https://www.game-ai-forum.org/viewforum.php?f=21
 ddyer0
on 8 Jan 2018
ddyer0
on 8 Jan 2018
@RavnaBergsndot Well but the batch normalization was there in CIFAR-100 benchmark. And if the shift variable is somehow set inappropriately during training, the batchnorm layer can shift the input to the negative region of ReLU ("dying ReLU"), so that is the idea behind all the modified rectifier units. I can hardly imagine any case referring to ReLU by the "rectifier nonlinearity", because you know, ReLU is a rectifier linear unit.
And you are right about the input features, though I still do not see why we need to detect triple ko at the first place.
isty2e
on 8 Jan 2018
though I still do not see why we need to detect triple ko at the first place.
Triple kos matter in rule systems without superkos.
Actually, they change the result of the game.
With superko, they would just make a move illegal.
Without it, they form a (really interesting in a game, I might add) situation where, if neither player is willing to give way, the game cannot end and is declared a draw (actually a "no result", but in situations where no return-matches are played, it's effectively the same).
Not including enough information for triple-ko detection in the NN would make the network unable to tell the difference between a situation where a move would end the game without a win or a loss, and one that will.
So even if we aren't interested in superko, it's still a bare minimum to be able to detect triple ko.
That being said, It might help a lot in superko detection as well, since gapped repetitions are exceedingly rare in actual play, perhaps sufficiently so that the "damage" of not recognizing these cases without search might not be felt.
However, the important thing was to demonstrate why triple ko detection is needed even if we do not use superko.
grolich
on 8 Jan 2018
Why 128 filters? 24 blocks * 64 filters should be consuming same time as 6 * 128, I wonder how blocks/filters affect strength...
Maybe we can train a 24 * 64 network and a 6 * 128 network, to compare with them?
 ayssia
on 8 Jan 2018
ayssia
on 8 Jan 2018
64 filters, 24 blocks will almost certainly use more time than 128 filters, 6 blocks. @gcp explained earlier that increasing the number of filters allows more parallelization and is thus usually much less than quadratic in computation time on a GPU. Layers have to be evaluated serially on the other hand.
jkiliani
on 8 Jan 2018
I'm also not convinced that AGZ's "rectifier nonlinearity" means "rectifier plus nonlinearity on its negative domain" instead of just ReLU itself...I can hardly imagine any case referring to ReLU by the "rectifier nonlinearity", because you know, ReLU is a rectifier linear unit.
I'm 99.9% sure that "rectifier nonlinearity" exactly means ReLU. ReLU is a non-linear unit constructed from a rectifier and a linear unit. A rectified linear unit is a rectifier non-linearity.
As was already pointed out, the advantages of "more advanced" activation units disappear when there are BN layers involved, which is why everyone including DeepMind just uses BN+ReLU.
gcp
on 8 Jan 2018
2) In addition to the training window by number of games, how about filtering out games based on rating also (like 300 or any reasonable value)?
It's important to make sure the window has enough data or you will get catastrophic over-fitting, especially for the value heads. You can test this yourself. This can't be guaranteed if you introduce a rating cutoff so it's a bad idea.
gcp
on 8 Jan 2018
You could repeat the same process but with a 64x5 network like the current one, to see how much of the gain (if there is a gain) comes from the increase in network size and what effect just changing the training had.
Be my guest and be sure to let us know the result.
gcp
on 8 Jan 2018
While it is true that BN mitigates the dying ReLU problem a lot (and especially considering we are using ResNet) and therefore BN+ReLU practically works very well, it is not completely true that the architecture is completely free from the problem. Of course, if there is no problem with the current LZ nets, the change is unlikely to be made anyways.
For the training window, overfitting can be of course potentially problematic, but the counter-argument that it can be bad to learn from bad policies and results of weaker games also makes sense, and we don't really know if overfitting is severe after all, so both are not well supported by data, I would say. So what kind of experiment is good enough here? Training with a smaller window is fine, but doing that for several generations with self-plays from that trained network is nearly impossible for an individual. So if we restrict the experiment to be done for a single generation, how can we measure the strength? Self-play ratings are not necessarily applicable to non-LZ players. Is the match between networks trained with narrower and wider windows meaningful enough?
isty2e
on 8 Jan 2018
@gcp "Once 64x5 has completely stalled, I will see if I can get the 128x6 to beat it."
IMHO 128x6 doesn't even need to beat 64x5. Suppose you find out that 128x6 is about 300, 500, 700, or even 1000 elos lower than 64x5. It still means the former can play reasonably. Then, we can just adopt it and improve it by training on its own self-play games. It would still be much better than starting from the scratch.
 ashinpan
on 8 Jan 2018
ashinpan
on 8 Jan 2018
@gcp When you decide that we should move to 128x6, you can pitch it against at least 3 best networks (latest but about 1000 elos apart). Then we can decide the exact elo of the initial 128x6, which should be our starting point.
ashinpan
on 8 Jan 2018
Why put that burden on gcp? Dont be lazy and just run it yourself @ashinpan :)
Or just wait for one of our other enthusiasts to do so, i'm 100% sure somebody will.
Dorus
on 8 Jan 2018
IMHO 128x6 doesn't even need to beat 64x5.
If it can't from a similar training set, then what's the point of moving to 128x6 - with the same training set?
gcp
on 8 Jan 2018
@Dorus We haven't reached the complete stall yet, and it is @gcp who must decide that we actually have. Besides, he just can send out matches to do such a test; he doesn't need to do anything.
ashinpan
on 8 Jan 2018
@gcp Have you read my comment to the end?
ashinpan
on 8 Jan 2018
If 128x6 trained by supervised learning can't beat 64x5 trained to saturation by reinforcement learning, that mainly implies that the supervised learning can't absorb all the knowledge from games it didn't play itself. It certainly doesn't mean that such a net wouldn't beat 64x5 in short order once trained by reinforcement learning itself.
jkiliani
on 8 Jan 2018
@jkiliani I agree with you.
ashinpan
on 8 Jan 2018
I found leelaz has a tendency to forget learnd knowledge. Though current weight 65e94e52 much stronger than before on midgame, earlier 40b94cfe seems playing better on endgame. Since 58da6176 beat 40b94cfe by midgame, the endgame playing of leelaz improved so slowly. If we train a network based on previous network like AlphaZero, could it work? Or any better way to solve it?
 fffasttime
on 8 Jan 2018
fffasttime
on 8 Jan 2018
@fffasttime I think if your observation is correct, it simply means there is still considerable improvement potential in 64x5. What will likely happen is that eventually the learning process won't produce stronger networks anymore at 0.001 learning rate, but that with reduced rate, the networks will reach slightly higher mid game strength than now combined with higher endgame strength than 40b94cfe. We'll see what happens, but this run definitely doesn't seem to be quite over yet.
jkiliani
on 8 Jan 2018
The reason behind self-forgetting is highly likely due to network capability or learning rate. As suggested in the OP, we can try lowering the learning rate, and if it still stalls we might safely conclude that this is close to the limit of the current architecture.
isty2e
on 8 Jan 2018
@fffasttime It is well-known that Alphago also makes quirky endgame moves, probably owing to the same cause here. Perhaps this is the motivation for Alphazero adopting the method of training on the last network.
ashinpan
on 8 Jan 2018
Maybe we should reconsider the resigning... it's possible we'd get better results letting all games play to the end, maybe with just 400 playouts after one of the players falls below the resignation threshold.
In either case, reinforcement learning so far appears to be remarkably robust in that it fixes its own weaknesses even with the presence of bad data. I doubt the problem will persist.
jkiliani
on 8 Jan 2018
A new network could understand that one move is bad, but does not yet know that an alternative is even worse, because it has not been played much before in training games. This reminds me of the phrase "A little knowledge is a dangerous thing". In this case training with the new network despite its new weakness may be beneficial.
That said training with a network which scores only <30% will mean that then following network will need to score 70+% just to get back to where we were, assuming Elo ratings work cumulatively (which they do not). I can not see this leading to faster overall progress given how badly the average network does.
I am optimistic about the 128x6 network myself. I will try to get training running on my laptop tonight to do some tests but without a good GPU I am not sure if I can get reasonable results fast enough.
evanroberts85
on 8 Jan 2018
@gcp (Sorry, I just noticed your edited comment) "If it can't from a similar training set, then what's the point of moving to 128x6 - with the same training set?" I never said that it should be the same training set. We can start training on the new self-playing games of 128x6. (If I am not wrong, this was how AG Master was born)
ashinpan
on 8 Jan 2018
I never said that it should be the same training set.
But I am saying that it should. If training 128x6 on the training data that is beyond saturating 64x5 does not produce an improvement, then this implies that data is sub-optimal for that network. And we should reset rather than use data we known is not optimal (and get risk getting stuck in a lower optimum).
If 128x6 trained by supervised learning can't beat 64x5 trained to saturation by reinforcement learning, that mainly implies that the supervised learning can't absorb all the knowledge from games it didn't play itself. It certainly doesn't mean that such a net wouldn't beat 64x5 in short order once trained by reinforcement learning itself.
Exactly. My point is that if 128x6 cannot (somehow) use the training data from the 64x5 well enough, we should get new data, and not try recover a half-crippled net.
gcp
on 8 Jan 2018
A 4th point for a new run would be to extend the training data format to include the resign analysis. Shouldn't forget about that either.
gcp
on 8 Jan 2018
If I am not wrong, this was how AG Master was born
...and we get back to the open question, that if AG Master with 256x20 was better than AGZ with 256x20 (this can be inferred from the graphs in the papers), why did DeepMind do AGZ 256x40, and not AG Master 256x40.
gcp
on 8 Jan 2018
...and we get back to the open question, that if AG Master with 256x20 was better than AGZ with 256x20 (this can be inferred from the graphs in the appers), why did DeepMind do AGZ 256x40, and not AG Master 256x40.
My best guess is that "Go program trained without human knowledge" sells better in a paper than "Even more awesome Go program than our last awesome Go program". They had to make their point without human input data for that, even though the reason for AGZ 40 blocks being stronger than AG Master may very well be simply in the number of blocks, not the Zero approach. They also shifted goal posts in the latest Alphazero paper, by making their reference Go program there AGZ 20 blocks instead of 40 blocks.
jkiliani
on 8 Jan 2018
@gcp Let us think in this way:
1) AG Lee trained on human and self-play games
2) AG Master trained only on self-play games but initiated with a network (AG Lee) carrying human bias
3) AG Zero trained on self-play games from scratch.
It is obviously not the objective of Deepmind to make the best possible Go playing bot, but to let machines go where no human has gone. Then, even if AG Zero is inferior to AG Master at 256x20 level, they must still push AG Zero.
In our case, our initial 128x6 network would be admittedly of supervised learning; but its supervisor is another network (64x5), not human.
ashinpan
on 8 Jan 2018
@gcp "But I am saying that it should. If training 128x6 on the training data that is beyond saturating 64x5 does not produce an improvement, then this implies that data is sub-optimal for that network. And we should reset rather than use data we known is not optimal (and get risk getting stuck in a lower optimum)." I agree if by resetting you mean "reset the data", i.e., to train on self-playing games only. But I cannot see why we should start again with a network of zero elo, which makes completely random moves.
ashinpan
on 8 Jan 2018
Maybe we should have more patience, I think that 64x5 present can reach 7500 self-estimate elo rating before 4000,000 games played. But if we want to get much obvious improvement, IMHO, I don' think a little change(in this case is from 64×5 to 128×6) can reach a obvious upper limitation.
 Tsun-hung
on 8 Jan 2018
Tsun-hung
on 8 Jan 2018
A change in neural network structure is unfortunately never "little", since it means we cannot continue training from the previous best network, but have to transfer the knowledge encoded in those self-play games into a larger neural network.
At present, the big question about this procedure is whether or not doing so limits the achievable strength of the larger network by self-play, i.e. "cripples" it, and this is not easy to test. Failing to achieve a 128x6 network by supervised learning from 64x5 self-play data that is stronger than the latest 64x5 network does not prove that the network is crippled, and successfully training such a 128x6 network also does not prove it is not crippled.
IMHO the only way to test this would be to continue until 64x5 has plateaued, then take an arbitrary 64x5 (supervised) network, and see whether or not self-play reinforcement will take this network to the same plateau as achieved by starting from Zero.
Of course it may well be a good idea to restart anyway, to cleanly implement a better training format, possibly training procedure (AlphaZero), and code changes such as visit count. However, it would be very valuable to know whether the bootstrapping procedure works in theory without long-term damage to the network, since eventually even the second run (128x10?) would stall out.
jkiliani
on 8 Jan 2018
@jkiliani TX for your interpretation, I wonder whether it makes sense to train a 128x6 network with latest 500k games ptoduced by 64×5 network? Come up with anothet deal, is it worth trying a 64×10 network?
Tsun-hung
on 8 Jan 2018
I have to admit that without the hardware to run training experiments myself, anything I tell you about how specifically to do it would be pure speculation. My feeling is @gcp will succeed in training a 128x6 net stronger than the best 64x5 if he uses an annealing schedule and samples the network often enough, but other people who tried it themselves are better qualified to answer this.
jkiliani
on 8 Jan 2018
I do not understand why we should reset the training. I understand that if a bigger network is trained with the same sample of the smaller, will take more time and will reach a point that is not optimum for its search space. But at worst it just need more sample and more training to reach the level of the smaller not need to trow away all the sample we add till now.
marcocalignano
on 8 Jan 2018
@gcp are you planning on moving to AlphaZero-like (no eval) NN training steps AND change other issues such as lack of symmetry-reflrection usage etc. ?
Because I was rereading the paper, listing all the different random or noisy behaviors there would be in match evaluations in AlphaZero (had they been used) - and... I found none...
Since eval matches in AGZ had no temperature, no noise, no randomness, no regularization for the net, and the network had no usage of symmetry reflections - there seem to be no random or noisy factors at all...
How would an evaluation match even work? with no rollouts, and no other random factors, then each UCT with the same NN would deterministically always choose the same move 1, and respond with the same move 2 to the other network's move 1.
Aren't there only 2 games possible?
What are the other random factors I am missing? or is that the reason to remove the eval? (it doesn't do anything if there are only 2 games possible...)
grolich
on 8 Jan 2018
lack of symmetry-reflrection usage
God no, this is very useful for go.
But you have an excellent point about the inability to do match games in their setup.
gcp
on 8 Jan 2018
@jkiliani "At present, the big question about this procedure is whether or not doing so limits the achievable strength of the larger network by self-play, i.e. "cripples" it, and this is not easy to test."
If we can infer anything from the history of AG Lee and AG Master, it seems to be that:
(1) The quirks of older networks may remain very long, even forever. AG Lee has quirky endgame moves, and AG Master also has this characteristic.
(2) But the blind spot of AG Lee, the one that allowed Lee Sedol to win one game against it, was remedied by training on pure self-play games (so said David Silver in an interview).
So, I think we don't need to worry a lot for having to bootstrap from a supervised bigger network.
ashinpan
on 8 Jan 2018
(1) that quirk is just MCTS not caring about big or small losses, only about certain or uncertain losses. This has nothing to do with the NN.
Dorus
on 8 Jan 2018
But at worst it just need more sample and more training to reach the level of the smaller not need to trow away all the sample we add till now.
Maybe, maybe not. I think there's an argument that due to the forced exploration and randomness, it will indeed eventually "fill in" any holes it might have.
A nice example is a network trained from 9 dan pro games: it will be even worse at ladders than our current 64x5. But the policy priors from the pro games will be very much against situations where a ladder can start. So you need the randomness to "end up" in a ladder so it can discover about them.
But it's not so clear at this point if this is overall faster or not than being tabula rasa.
gcp
on 8 Jan 2018
God no, this is very useful for go.
That was probably because they insisted in "no domain knowledge" other than basic game rules. Btw, i wonder how much stronger a net can become if you included some domain knowledge like working ladder moves. The original AG also had planes for liberties etc, i do not think those planes are all that useful, but a plane for ladders* and captures could be very useful considering the weaknesses the current network has.
The current network makes many mistakes with: Self atari. Long diagonal ladders. Second line atari's that result in a capture on the first line next (this is a type of ladder.) Captures of large groups with 1 eye and no other liberties.
On the subject of capturing large groups: Possibly the network is trained to learn certain moves are invalid. But wouldn't it be better to not train it on invalid moves? Any output for invalid moves is zero'd out anyway, so the network could just produce garbage here, it wont make any difference to the end result. This might make it easier for the network to learn about valid captures.
*) Ladders are all captures that happen with a seri of atari's on a group with 2 liberties, decreasing them to 1 each time until eventually the group is captured.
Dorus
on 8 Jan 2018
@Dorus "(1) that quirk is just MCTS not caring about big or small losses, only about certain or uncertain losses. This has nothing to do with the NN."
Then, it is even better. We won't have anything to worry about.
ashinpan
on 8 Jan 2018
Pardon the silly question, but rather than starting over with a new network architecture, why wouldn't you use the output of the current network as additional inputs to a new one?
ddyer0
on 8 Jan 2018
@gcp are you tempted to adopt AlphaZero's approach of having randomness on all game and not just for the opening?
evanroberts85
on 8 Jan 2018
Is the 0.10.1 any better than 0.10?
 Marcin1960
on 8 Jan 2018
Marcin1960
on 8 Jan 2018
@gcp Thanks for all the hard work, and a big thank you to all the code contributors in general! Having this project be open-source is a tremendous help for people like me who like to tinker with things and see what they can do with them. To be honest, all the speed improvements that have been done on this implementation make it more and more easy to just go test something locally, and that's awesome :)
 Alderi-Tokori
on 9 Jan 2018
Alderi-Tokori
on 9 Jan 2018
Does it make sense to train specifically for end game situation? For example, the program can select some already played games and start from 150 steps on, the objective is to find a variant of the network that can maximize the area at the end. I think this is a much smaller problem and it should be solved very well with the current network. And once our network learned good end-game play, then the improvement will be focused on the mid-game and openings. Would this be more efficient?
 pheasant75
on 9 Jan 2018
pheasant75
on 9 Jan 2018
The following might be useful for @gcp. But I suspect he is already aware of it :)
Net2Net: Accelerating Learning via Knowledge Transfer
(Abstract) We introduce techniques for rapidly transferring the information stored in one neural net into another neural net. The main purpose is to accelerate the training of a significantly larger neural net . . .
ashinpan
on 10 Jan 2018
Is the 0.10.1 any better than 0.10?
It fixed a bug related to maximum number of threads.
 LetterRip
on 10 Jan 2018
LetterRip
on 10 Jan 2018
I have some doubt about how training is done as I read the AGZ paper closer: in the paper, it seems to me that they always use the search propability distribution π for training, which is proportional to the visit counts for the first 30 moves (temperature=1) and assigns 1 to the move with most visits, which is also the move actually played, and 0 to other moves (temperature=0). However, we have been using the visit counts for training all game long. @gcp commented https://github.com/gcp/leela-zero/issues/78#issuecomment-346347588 that training on the distribution should give a slightly stronger program than training on just the moves, and indeed in the AZ paper, they set temperature=1 all game long. However they use the same temperature setting in self-play and training, while we are taking a hybrid approach. I imagine this could be a potential source of problem, and I think it is at least worth trying to train networks following AGZ starting from the current best network and see whether this leads to faster improvement. For this one may need to re-generate the training data (https://github.com/gcp/leela-zero/issues/167).
I am not saying that we need to follow AGZ completely faithfully. I have several ideas deviating from the AG approach, for example (1) using the Q-value of the root node after a certain number of MCTS playouts (say 1600) in place of the final winner to train the network; (2) add in "the number of moves remaining" as an input feature and generate training data by doing MCTS from random positions with different densities and with the number of moves remaining gradually increasing from 1 to 722. I don't currently have the time and skill to test these ideas, but I would be glad to hear your comments. (By the way, Prof. Paul Purdom is having another offering of his graduate course on AG this semester here at IU, and he doesn't like using the final winner as feedback either. Edit: it turned out that he didn't study the loss function before.)
 alreadydone
on 10 Jan 2018
alreadydone
on 10 Jan 2018
@alreadydone Alphago Zero was a demonstration of one particular implementation that works. They never proved what they did works best, and they never shared any information they didn't publish with @gcp when he asked, even though that might have helped a lot in the beginning. We have to assume they also had multiple experiments that failed, but they never shared any information on that either. What we're doing here is a _mostly_ faithful reimplementation, which I though was a very good decision since starting a 256x20 run with untested code would have been a disaster, and even distributed we don't have even close to the computing resources of Google.
The general consensus of the project seems to be to gradually try out further deviations from AGZ simply to build up some knowledge on why their approach works, rather than just confirm it did. I can't think of any other way to be successful in the end.
jkiliani
on 10 Jan 2018
I have some doubt about how training is done as I read the AGZ paper closer: in the paper, it seems to me that they always use the search propability distribution π for training, which is proportional to the visit counts for the first 30 moves (temperature=1) and assigns 1 to the move with most visits, which is also the move actually played, and 0 to other moves (temperature=0)
You are confusing the actual move selection with the data used for the training. They use the temperature for the move selection.
For the training:
" The neural network (p, v) = fθi (s) is adjusted to minimise the error between the predicted value v and the self-play winner z, and to maximise the similarity of the neural network move probabilities p to the search probabilities π "
This obviously makes no sense if you set temperature = 0. And it would be silly, because if the search sees multiple good moves, you're forcing the network to forget about all but the first, which is catastrophic.
gcp
on 10 Jan 2018
using the Q-value of the root node after a certain number of MCTS playouts (say 1600) in place of the final winner to train the network;
It is very likely that this was tried and discarded (it is a common optimization for REINFORCE). People who tried it with supervised-style learning got clearly worse results.
gcp
on 10 Jan 2018
add in "the number of moves remaining" as an input feature
I'm pretty sure the network can calculate 722 - stones on the board.
And if you mean until the original game was stopped, then you would need to predict the future to fill in this input.
gcp
on 10 Jan 2018
@gcp are you tempted to adopt AlphaZero's approach of having randomness on all game and not just for the opening?
I think that rule was added to deal with games with a much lower branching factor, who might not deviate enough otherwise. It probably does not improve go.
On the other hand, yay for less magic constants.
gcp
on 10 Jan 2018
using the Q-value of the root node after a certain number of MCTS playouts
(say 1600) in place of the final winner to train the network;This is far worse. Many people have already tried it.
The policy network already gets the information from the immediate
tree-search so I can see why this would not get good results. You are
effectively doubling up this information.
I can see the idea of not waiting until the final game result though, to
get more immediate feedback. Taking the Q-value of the root node of a move
played a few moves after the one you are training on is the idea I had
thought of and am yet to test.
evanroberts85
on 10 Jan 2018
Do you want to change?
 xss801
on 10 Jan 2018
xss801
on 10 Jan 2018
You are confusing the actual move selection with the data used for the training. They use the temperature for the move selection.
"The MCTS search outputs probabilities π of playing each move. ... Once the search is complete, search probabilities π are returned, proportional to N^(1/τ), where N is the visit count of each move from the root state and τ is a parameter controlling temperature."
"the neural network's parameters are updated to make the move probabilities and value (p, v)=f_θ(s) more closely match the improved search probabilities and self-play winner (π, z)"
"The neural network parameters θ are updated to maximize the similarity of the policy vector p_t to the search probabilities π_t, and to minimize the error between the predicted winner v_t and the game winner z"
"a move is played by sampling the search probabilities π_t ... The data for each time-step t is stored as (s_t, π_t, z_t) ... new network parameters θi are trained from data (s, π, z) sampled uniformly among all time-steps of the last iteration(s) of self-play."
The above are all from the AGZ paper, and I cannot see any indication that they are using different temperatures for self-play and training. The search probabilities depend on the temperature, the moves are played according to the search probabilities, and the network is trained to approximate the search probabilities. In our case, what worries me is that although the network is trained to explore all moves according to the visit count, it only sees continuations from one of the moves. I can imagine this have some effect on learning forced moves, e.g. ladders, (self-)atari, and capturing races.
alreadydone
on 10 Jan 2018
I cannot see any indication that they are using different temperatures for self-play and training.
They're not, nobody is saying this. Again, the temperature to select the move is not necessarily the same as the output of the search probabilities.
"In each iteration, αθ∗ plays 25,000 games of self-play, using 1,600 simulations of MCTS to select
each move (this requires approximately 0.4s per search). For the first 30 moves of each game, the
temperature is set to τ = 1; this selects moves proportionally to their visit count in MCTS, and
ensures a diverse set of positions are encountered. For the remainder of the game, an infinitesimal
temperature is used, τ → 0."
"At the end of the search AlphaGo Zero selects a move a to play in the root position s0 , proportional to its exponentiated visit count, π(a|s0 ) = N (s0, a)1/τ / Pb N (s0 , b)1/τ , where τ is a temperature parameter that controls the level of exploration."
However, I'll give you that it's actually rather confusing:
"MCTS may be viewed as a self-play algorithm that, given neural network parameters θ and a root position s, computes a vector of search probabilities recommending moves to play, π = αθ (s), proportional to the exponentiated visit count for each move, πa ∝ N (s, a)1/τ , where τ is a temperature parameter."
The paragraph you quote is even less clear, but it's the explanation of a figure.
I guess you could also interpret that as saying that after move 30, they train the network to predict the best move only (which would be incredibly arbitrary, much more than only doing so for move selection). They rather consistently note π as having the temperature parameter applied to it.
gcp
on 10 Jan 2018
The next AZ paper:
"The search returns a vector π representing a probability distribution over moves, either proportionally or greedily with respect to the visit counts at the root state."
And they do say:
"Moves are selected in proportion to the root visit count" (i.e. without any qualification that it's the first 30 moves only)
At worst we accidentally used the improved method from the AZ paper. (I wondered about the "either" in the first paragraph, but they use greedy selection for evaluation games)
gcp
on 10 Jan 2018
@gcp what is the process for training on the next window when 8k-256k steps all fail? For the next 8k-256k steps network do you start over from previous best weights or do you continue on from the previous failed 256k step? Latter seems better to me but maybe it would overfit?
Also what about increasing the game window back to 500k games? Or maybe it would overfit because we have a smaller network than google?
 killerducky
on 10 Jan 2018
killerducky
on 10 Jan 2018
An idea for new run: since we are doing some sort of node merge as stated in #576 already, inputting the last 8 board positions aka the last 7 moves into the neural net is less useful. Inputting so many move history only serves the purpose of reading triple ko within 1 playout and it will miss special cases like triple ko stones cycle anyway. Meanwhile the computation is a lot more inflated for some ko corner cases and then we throw the benefit away.
On the other hand, if we input only the last 4 or even just 3 board positions, it will still pass the bare minimum requirement to read Chinese Superko in 1 playout, while the computation resource can be better spent for more blocks or more featuresfilters or more game throughput. Since we are not aiming for perfect play or super-human Go strength in the second run (yet) I guess, such a tradeoff for better reading for large group life and death / long ladders looks attractive to me.
EDIT: There is no clear proof that the so called "Chinese Superko" is used in Chinese go tournaments today. But since 8 is just a magic number set by AGZ, it can also subject to decrease like the featurefilter count or block count, and 3 is at least less magic as there is some historical context.
 billyswong
on 11 Jan 2018
billyswong
on 11 Jan 2018
while the computation resource can be better spent for more blocks or more "features" or more game throughput.
Increasing the number of input features barely increases the number of weights and computations of the network, because the number of intermediate filters in each layer is still 64.
Furthermore, if some information in the 8-step history is not interesting enough, the network will learn to spend its computations elsewhere anyway.
RavnaBergsndot
on 11 Jan 2018
Ouch, so they are called filters not features. I was talking of those 64vs128vs256 thing, and forgot the exact name.
billyswong
on 11 Jan 2018
@gcp If you want to get a snapshot of your 128x6 strength, load it in as a match but not against the best-network. That way it won't promote and replace anything if it does win. (Promotion depends on beating current best network.) I'm curious what result 128x6 vs ffc1e51b would have, for instance.
I will let this run until about 2/3 of the training window is from the same network without improvement
Is the training window still at 250K or back to 500K currently?
 roy7
on 11 Jan 2018
roy7
on 11 Jan 2018
Just two random thoughts:
- I think the current setup should be let run until it nearly completely stalls, to get as much info as possible (maybe then hack-switch to 6 blocks for a few weeks to see the difference it makes).
- In the longer run, why not 40 blocks? Even if it takes a few years, that's what people are interested in, a real AGZ in the public domain. For the same reason, I'd consider increasing the playouts during selfplay. Aim for maximum strength, not minimum time spent.
 tapsika
on 11 Jan 2018
tapsika
on 11 Jan 2018
For the next 8k-256k steps network do you start over from previous best weights or do you continue on from the previous failed 256k step? Latter seems better to me but maybe it would overfit?
I restart from the best to prevent overfitting. (I do not consider it likely we lack enough steps to see improvement - not with already having had to reduce the learning rate, and no clear progress in the training loss)
Also what about increasing the game window back to 500k games? Or maybe it would overfit because we have a smaller network than google?
It would be less likely to overfit, not more. But I don't see why it would help to include much weaker networks. Our training window is 1/2 that of Google but the network is 64 times smaller. It's likely that a smaller window would help more, but that just ends up equivalent to letting training games accumulate, so I don't really want to change it for now.
gcp
on 12 Jan 2018
Is the training window still at 250K or back to 500K currently?
It's 250K. I used 500K briefly to get the 128x6 started with all games post the major bugfixes.
gcp
on 12 Jan 2018
I think the current setup should be let run until it nearly completely stalls, to get as much info as possible (maybe then hack-switch to 6 blocks for a few weeks to see the difference it makes).
I agree we should try got get as much out of 5x64 as possible. 6x128 is already 5 times slower to compute (ok, not really on most GPU, but in theory), so it will have to overcome that handicap in "real" games.
A strong 5x64 is also very useful for people without a GPU, if someone wants to make a phone app, etc.
gcp
on 12 Jan 2018
In the longer run, why not 40 blocks? Even if it takes a few years, that's what people are interested in, a real AGZ in the public domain. For the same reason, I'd consider increasing the playouts during selfplay. Aim for maximum strength, not minimum time spent.
I think the intermediates are likely to be more useful in the near future, until we all get a few TPU in our desktop machines. Someone should test how many nodes per second a 1080 Ti can search with 256x40. It's not going to be much.
If our bootstrapping 6x128 on 5x64 data works, that's another reason to not leap too far.
I think the timescale of 40x256 is also such that it will take much longer to run than I personally am willing to commit to, and one would probably need to think a bit more about what to do with bad clients and so on. @roy7 intends to open source the server side this weekend, so I am hoping to become redundant soon.
gcp
on 12 Jan 2018
@gcp If you want to get a snapshot of your 128x6 strength, load it in as a match but not against the best-network. That way it won't promote and replace anything if it does win. (Promotion depends on beating current best network.)
Very clever, I will do exactly this for the supervised one and my current candidate.
gcp
on 12 Jan 2018
Those matches are added, they are a bit more down on the match table, but you can see them on the graph (will probably confuse a few onlookers).
gcp
on 12 Jan 2018
Those matches are added, they are a bit more down on the match table, but you can see them on the graph (will probably confuse a few onlookers).
Oh, i just found them based on the date. I never realized that list wasn't sorted on date, but on network training games + steps.
Dorus
on 12 Jan 2018
So basically a 6x128 already wins against a 5x64.
marcocalignano
on 12 Jan 2018
1e2b85cf611d5ede3f8d77ddc56a7bd79a7f1e51a647ddea428b92c00fdf2612 is the supervised one
5e1014c1d19b03ea7188310711b37bbf50421d777d0f6f5cd6d20986acb7c34c is 6x128 on 5x64 data
gcp
on 12 Jan 2018
1e wins convincingly
5e is getting crushed
LetterRip
on 12 Jan 2018
Looks like beating a 5 times bigger supervised network will be possible with 5x64 (and that's ignoring the speed difference).
But the odds for bootstrapping are a bit worse. From the training I see it has a comparable policy loss, but a much lower MSE loss, than the smaller network. Interesting that this by itself does not translate in strength.
gcp
on 12 Jan 2018
Remember the current 5x64 network is handpicked out of 2 dozen networks. If you try to bootstrap the 6x128 network like that, with different learning steps etc, one might get lucky and improve on 5x64. 20% win vs ffc1e51b is terrible of course, but the 5x64 2.13M+64k network from before had a similar score.
Dorus
on 12 Jan 2018
What does exactly "the supervised one" mean?
Marcin1960
on 12 Jan 2018
@gcp - perhaps rerun the test but with a lower resign threshold. It might be predicting that against itself it is in a lost position and resigning games it can win. Or better, download the games and complete them with a lower resign threshold.
LetterRip
on 12 Jan 2018
Slightly surprised at the poor performance of the 6x128 bootstrapped network, but as Dorus says the 5x64 networks has gone through the process of being successively handpicked. The 6x128 may need a round of self-play to discover its weaknesses.
The low MSE score is very promising.
evanroberts85
on 12 Jan 2018
@evanroberts85 Could we simulate the successive handpick for the 6x128 bootstrap?
billyswong
on 12 Jan 2018
I wasn't even talking about self play yet, just try a number of extra training steps on the currently available games might be enough. If you use the games from 46ff i would actually be surprised if this did not result in a stronger net.
However i also have the theory that a larger net, that will be able to run less playouts, will have it very difficult to improve on the current dataset. The problem is that a larger net can mostly improve because ti can learn to see things the current net can not (things future away or things that require more filters), but because the current games are from the current net that is blind to those weaknesses, the self play games do not contain much information about these weaknesses. A couple rounds of self play might improve this, but it might also be required to start all the way from scratch.
I'm still wonderinf if the messed up first 900k games are still leaking trough weaknesses in the current net, with failure to capture large groups, incorrect passes and self atari.
Dorus
on 12 Jan 2018
The better value output alone should be enough to see an improvement, but as gcp said, that does not seem to always translate. We are going to need a few more tests after extra training to see how much randomness there is in this translation.
evanroberts85
on 12 Jan 2018
I just set 6x128 supervised net 1e2b85cf against 6 dan HiraBot43 on KGS as LeelaZeroT
Marcin1960
on 12 Jan 2018
t might be predicting that against itself it is in a lost position
If it is better, why is it getting into lost positions in the first place? Seems pointless to try that.
gcp
on 12 Jan 2018
Could we simulate the successive handpick for the 6x128 bootstrap?
Yes, that's no problem.
gcp
on 12 Jan 2018
@gcp I'm not quite clear - is 5e101 trained only on the current window of 5x64 games (which are mostly generated by 46ff), or has it seen windows from the very beginning of the 5x64 run? Or some mix?
ssj-gz
on 12 Jan 2018
Just seen the 6x128 network was trained using 1m steps! Is this then using the full game window (since the major bug-fix). If this is the full window, is the plan to take this network and then train it on just the last 250k games?
evanroberts85
on 12 Jan 2018
I have already answered this in the beginning of this thread.
gcp
on 12 Jan 2018
@alreadydone FWIW I fired an email to DeepMind asking if they were willing to clarify this issue.
gcp
on 12 Jan 2018
@gcp I believe you said that the you would be gradually moving it up to the present day, reducing the window as you go along. Is this the final part of that process, in which case why 1m steps?
evanroberts85
on 12 Jan 2018
The number of steps is simply how long the training ran in total. There is no "best" network to restart from on a new set of training data, so it will just keep incrementing.
gcp
on 12 Jan 2018
Well that is only more confusing. While there is no "best network" you can save the network and restart training using that network to initialise but using the smaller window. This is what I had assumed you would do from what you said before, or simply change the window mid-training if that is possible. Do you mean you just used the one window for the whole for the total of training?
evanroberts85
on 12 Jan 2018
"No, I started with a huge window and have been narrowing it to 250k."
I guess you just narrowed it mid-training, ok I understand now. Does that also mean the training rate was also adjusted mid training?
evanroberts85
on 12 Jan 2018
Just looked over a sampling of the games it lost, and it is clearly getting out played. Also most of the games won by 5e1014c1 are when ffc1e51b would get laddered early in the game. Also looking at the games versus supervised network, about 1/3 of lost games were to an early ladder.
LetterRip
on 12 Jan 2018
you can save the network and restart training using that network to initialise but using the smaller window
This doesn't reset the training steps.
gcp
on 12 Jan 2018
This [saving then initialising from that saved network with new
parameters] doesn't reset the training steps.
Ok, that is different behaviour to the number of training steps reported
when you have initialised from a "best network" on the current 5x64 run,
hence my confusion.
>
evanroberts85
on 12 Jan 2018
The current training iteration will run with about 146k games from the best network. If this does not produce a new best, the learning rate will be lowered.
gcp
on 12 Jan 2018
@gcp Do you think that, after switching to the 6x128 network, if you keep training the 5x64 network with the games of the new one will keep improving?
marcocalignano
on 12 Jan 2018
Just FYI the current version 46ff4b is about 100 Elo stronger on the CGOS leaderboard than the previous version (the score isn't finalized but is going up and only has a few more games before it passes the threshold for a verified rating)
http://www.yss-aya.com/cgos/19x19/standings.html
http://www.yss-aya.com/cgos/19x19/cross/LZ-46ff4b-t1-p1600.html
LetterRip
on 12 Jan 2018
Tbh the huge jump by 46ff seems to be a reason for me to stay on this learning rate for slightly longer. Idk what is lost by decreasing it, but the last few networks show no sign of stagnation yet, so far it is a stable upwards line (mostly because 46ff scored almost 60% instead of 55%)
Dorus
on 12 Jan 2018
Is 1e2b85cf the same as best_v1? If not what's the difference?
 Azirine
on 12 Jan 2018
Azirine
on 12 Jan 2018
Is 1e2b85cf the same as best_v1? If not what's the difference?
Do a sha256sum on best_v1 and find out!
(It is)
gcp
on 12 Jan 2018
Do you think that, after switching to the 6x128 network, if you keep training the 5x64 network with the games of the new one will keep improving?
I don't know. I guess that might be possible.
gcp
on 12 Jan 2018
Tbh the huge jump by 46ff seems to be a reason for me to stay on this learning rate for slightly longer.
If the training window consists (near-)entirely of games from the last best network, and this does not produce an improvement, there is no point in continuing as is. Playing more games will change nothing.
Idk what is lost by decreasing it
The (large scale) rate of improvement slows down after an initial small jump.
gcp
on 12 Jan 2018
The Elo difference between the supervised and previous best network based on the match (+195) is quite a bit smaller than the Elo difference from CGOS leaderboard Bayes Elo (2663, 2316 = +343).
LetterRip
on 12 Jan 2018
its the same with 46ff, it has less than 70 elo over previous network and 100 elo in CGOS, previous elo differences have been inflated so this is even more noticeable, i guess match elo is deflated now, but we still dont have the bayers elo for 46ff so maybe its too early to say.
 Liserotte
on 12 Jan 2018
Liserotte
on 12 Jan 2018
Remember that both 46ff and the supervised network on CGOS only played the order of 100 games each, so that's quite a small sample size especially since it's against many different opponents.
 wnwen
on 12 Jan 2018
wnwen
on 12 Jan 2018
What are the current benchmarks for people on the winograd branch about 128x6 vs 64x5 seconds per move?
jkiliani
on 12 Jan 2018
from now, is it just generating the 128x6 networks?
 st90115
on 12 Jan 2018
st90115
on 12 Jan 2018
from now, is it just generating the 128x6 networks?
No, nothing has changed.
gcp
on 12 Jan 2018
We have just surpassed 2/3 of the window.
barrtgt
on 12 Jan 2018
If the 256k step network of the current (2.32M) training cycle somehow passes, we'll probably stay at 0.001. Otherwise, as @gcp announced earlier, the learning rate will be lowered starting with the next training cycle.
jkiliani
on 12 Jan 2018
@jkiliani Do you mean that the learning rate has not already lowered yet?
ashinpan
on 12 Jan 2018
No, that is what @gcp said in his last post. Also I think it's pretty clear from the strength fluctuation that learning rate is not changed yet.
jkiliani
on 12 Jan 2018
@Dorus
I never realized that list wasn't sorted on date, but on network training games + steps.
It's actually sorted on opponent network creation date first, then sorted by age of the network itself. This was requested of me when I started queuing the old networks for matches when the match system was new, so they'd all sort more properly.
roy7
on 12 Jan 2018
We could also try
1) more rollouts during training - even 200 more rollouts might give it enough additional information to train a stronger network
2) fewer rollouts during match tests - MCTS makes up for weaknesses in the NN evaluation function, perhaps it will be easier to see improvements with fewer rollouts.
3) Sample more from completed games or different parts of the game - this might help it address specific weaknesses that it might be having trouble learning.
LetterRip
on 13 Jan 2018
more rollouts during training - even 200 more rollouts might give it enough additional information to train a stronger network
Did you mean more playouts?
Just to be clear - "rollouts" refers to the random simulations to the end of the game from leaf nodes in UCT style MCTS. Those were removed in AGZ and so in LZ as well. There are no more random rollouts at all.
If you meant playouts, those are essentially deterministic node expansions in the UCT during matches and training.
Well, more COULD help. Or they might not. Deepmind actually reached a far better and faster result after using less playouts in AlphaZero for example.
What it would do for sure is slow it down considerably which, if it's not guaranteed to help, will just hurt the project.
These things need to be tested before implementation to at least have an idea of what you expect to work better.
grolich
on 13 Jan 2018
I did mean playouts - 200 more is 10% longer.
LetterRip
on 13 Jan 2018
@killerducky commented a while ago on the training procedure here, specifically about whether restarting from the previous best network at the start of every training cycle is actually better than continuing directly from the last window. Now that learning rate is lowered, maybe this could be reconsidered? The switch from 0.01 to 0.001 was at the same time https://github.com/gcp/leela-zero/commit/6b018413df0e0d11232eba44e5b6f0e423f62f7d improved the training speed a lot and allowed much more steps per training run, so we may not have seen any problems from backing up back then.
Maybe backing up to best-network only every third or forth training run would still serve the purpose of preventing overfitting, while allowing more training steps to accumulate if needed to break out of a local optimum.
jkiliani
on 13 Jan 2018
If you meant playouts, those are essentially deterministic node expansions in the UCT during matches and training.
Well, more COULD help. Or they might not. Deepmind actually reached a far better and faster result after using less playouts in AlphaZero for example.
Earlier I also voted for more playouts as this seems the easiest way for increasing search strength. I believe LZ currently squeezes less knowledge/gain out from each selfplay game, which are of lower quality than AGZ. But the actual problem may be in the search code.
Before investing a year of computation into the new run, it may worth to do some structured testing, such as running 100k-100k selfplay games from an earlier net (way before stall) with different number of sims, also probably with different search (exploration) tweaks, and see the gains in training. Some objective comparison to AGZ progress per game may also be in order.
tapsika
on 13 Jan 2018
@tapsica "Before investing a year of computation into the new run"
But is it possible to piggyback on some 5x64 stuff? Or isn't it?
The 6x128 unsupervised net runs as LeelaZeroT right now on KGS, and is around 1 kyu versus other bots. Can one start from there?
Marcin1960
on 13 Jan 2018
@gcp I believe the learning rate got dropped for the last 6 networks? No progress so far (although we probably need another 12-24h to be sure), but could you consider to increase the learning window back to say 500k before switching to a new strategy all together. The last 250k games are all created by the same net, and that might hurt the learning too.
Dorus
on 13 Jan 2018
@Dorus "The last 250k games are all created by the same net, and that might hurt the learning too."
Can other nets be used instead? The ones that were close?
Marcin1960
on 13 Jan 2018
But those other nets did not generate games. Also there is no reason to believe new games generated by other weaker nets will have better results than just using games from a previous net we already generated games with.
Beside, using games we already have anyway is something we can test very easily, generating new games first takes a lot of project resources.
Dorus
on 13 Jan 2018
@Dorus "there is no reason to believe new games generated by other weaker nets will have better results"
Those which were close. do not have to be weaker, Or not much. Can they provide some diversity?
Marcin1960
on 13 Jan 2018
Right now we are wasting resources since new games are the same strength as games in the maximum window. So we should probably make some change - such as more playouts, etc.
LetterRip
on 14 Jan 2018
I agree that the current stall is another opportunity to get an idea of the benefits of more playouts - like doubling or tripling for a few days. But even if this won't help now, it can still be more optimal for an unpeaked state, so further testing may still be necessary.
tapsika
on 14 Jan 2018
As you can see lowering the learning rate did not produce an improvement. There is a possibility that using 3200 playouts could still produce a tiny jump, but IMHO the odds are strongly against it as the problem seems simply that the network is at capacity, not that more playouts are needed to make deeper discoveries about Go (and note the AZ result with 800!).
At this point I think it's best to just terminate the 5x64 run (EDIT: OK I GUESS NOT!). More games are unlikely to help much, as we're close to 500k games on 2 networks very close to the optimal strength. Further experiments can be run on the existing dataset, we don't need to continue generating games from the same network for that.
I'll ask @roy7 to make the get-task endpoint 404, at which point the clients should stop and gradually back off, checking every now and then if there's something to do (we may have some test matches for you). Or you can just close them. There'll probably be some news in a week, or two.
Bootstrapping 6x128 was (very!) unsuccessful so far. From eyeballing the results (and experience with supervised learning), the value network on those is overfit. It's possible to control this, but training new networks is going to take a week or so in any case. Just forcing the clients to play games with any of those (which are pretty much known to be in a bad state) seems a waste of resources. I'd rather we do testing and see if we can produce a better network from the data we have. We can still start a new run from that instead of 0.
I'll use the break to make the (incompatible) changes that were intended (new weights format, add resigning statistics to training data), we can probably merge Winograd (~x2 speedup for 6x128) during that time, and I get some time to upload all the data so people can run experiments rather than make random theories.
Meanwhile, the server source was published:
https://github.com/gcp/leela-zero-server
gcp
on 14 Jan 2018
According to AGZ paper's learning rate schedule, the 0.0001 learning rate
should run with 600k+ steps, but I'm still seeing 8/16/32/64/128/256k steps
as before. What am I misreading?
On Sun, Jan 14, 2018 at 4:39 PM, Gian-Carlo Pascutto <
[email protected]> wrote:
As you can see lowering the learning rate did not produce an improvement.
There is a possibility that using 3200 playouts could still produce a tiny
jump, but IMHO the odds are strongly against it as the problem seems simply
that the network is at capacity, not that more playouts are needed to make
deeper discoveries about Go (and note the AZ result with 800!).At this point I think it's best to just terminate the 5x64 run. More games
are unlikely to help much, as we're close to 500k games on 2 networks very
close to the optimal strength. Further experiments can be run on the
existing dataset, we don't need to continue generating games from the same
network for that.I'll ask @roy7 https://github.com/roy7 to make the get-task endpoint
404, at which point the clients should stop and gradually back off,
checking every now and then if there's something to do (we may have some
test matches for you). Or you can just close them. There'll probably be
some news in a week, or two.Bootstrapping 6x128 was (very!) unsuccessful so far. From eyeballing the
results (and experience with supervised learning), the value network on
those is overfit. It's possible to control this, but training new networks
is going to take a week or so in any case. Just forcing the clients to play
games with any of those (which are pretty much known to be in a bad state)
seems a waste of resources. I'd rather we do testing and see if we can
produce a better network from the data we have. We can still start a new
run from that instead of 0.I'll use the break to make the (incompatible) changes that were intended
(new weights format, add resigning statistics to training data), we can
probably merge Winograd (~x2 speedup for 6x128) during that time, and I get
some time to upload all the data so people can run experiments rather than
make random theories.Meanwhile, the server source was published:
https://github.com/gcp/leela-zero-server—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub
https://github.com/gcp/leela-zero/issues/591#issuecomment-357496732, or mute
the thread
https://github.com/notifications/unsubscribe-auth/ABHWLr3172yU3-tFIaK4vH7oij6rpiriks5tKb0qgaJpZM4RVxWY
.
 bood
on 14 Jan 2018
bood
on 14 Jan 2018
Our steps reset on each best new network. Their numbers are total training steps, and that on another batch size and orders of magnitude bigger network. The numbers aren't comparable at all, and not useful.
gcp
on 14 Jan 2018
Maybe backing up to best-network only every third or forth training run would still serve the purpose of preventing overfitting, while allowing more training steps to accumulate if needed to break out of a local optimum.
I don't see any movement in the training one way or another (but weaker networks do come out), so I don't consider it worthwhile. (This would be different if loss gradually decreased, obviously)
You can try this if the entire dataset is uploaded.
gcp
on 14 Jan 2018
I suppose now that it's decided that 46ff4b94 is the best 5x64 for this run, would it be okay to keep clients involved / connected by running self play with various other networks? Potentially some of the recently failed 5x64 or 6x128 -- this is somewhat like the AZ approach without evaluation. (?)
People can choose to self terminate or participate in an experiment that doesn't require client changes.
Tradeoffs being people see the break as a time to leave and potentially not come back. Or running selfplay on failed networks is a waste of resources and not wanting to contribute any more. Or… ?
 Mardak
on 14 Jan 2018
Mardak
on 14 Jan 2018
I knew that as soon as I made that post this would happen. (0db82470 had an SPRT pass)
Y'all keep your clients running for now will ya?
gcp
on 14 Jan 2018
Looking at 0db82470 (currently 47 : 28), it seems that one strategy for dealing with stalls is to publicly call a halt to the run - this should immediately cause a new best network to be created.
Edit:
Too late XD
Edit2:
The ELO of this one can't be too far off from 1e2b, which is very interesting.
ssj-gz
on 14 Jan 2018
Potentially some of the recently failed 5x64 or 6x128 -- this is somewhat like the AZ approach without evaluation. (?)
This would be reasonable but it requires server side fiddling I guess.
I consider the current 6x128 to be a be a dead loss. They're so much weaker it has to be possible to make better ones by adjusting the training (lowering the MSE weighting seems like a good bet).
gcp
on 14 Jan 2018
”I knew it that as soon as I made that post this would happen.
Y'all keep your clients running for now will ya?”
Hahaha, you need to make another post again when we are not making any progress for a few days next time. ;-)
 pcengine
on 14 Jan 2018
pcengine
on 14 Jan 2018
I agree it is best to stop self-play while we figure out how to improve
things for the next run.
On Sun, 14 Jan 2018 at 09:21, pcengine notifications@github.com wrote:
”I knew it that as soon as I made that post this would happen.
Y'all keep your clients running for now will ya?”Hahaha, you need to make another post again when we are not making any
progress for a few days next time. ;-)—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/gcp/leela-zero/issues/591#issuecomment-357498606, or mute
the thread
https://github.com/notifications/unsubscribe-auth/AgPB1n0V-S6Jx36vQbzGq39rwrmV6Quaks5tKccrgaJpZM4RVxWY
.
evanroberts85
on 14 Jan 2018
The current network only made 475 games so far. It's too early to call this run completed.
Dorus
on 14 Jan 2018
@gcp I could add an now option into autogtp (for the /next branch) so that if the server deliver a command wait with the json, each thread in autogtp would wait for x minutes and then check again. Would that help?
The only think is that I check the code and the autogtp in the master will exit with a wait command.
marcocalignano
on 14 Jan 2018
@gcp since we have bit of time now (we have anew best network) I added the wait command for autogtp and I will test it.
@roy7
the command look like this:
{
"cmd" : "wait",
"minutes" : "5",
}
If you could set up an URL where you loop 5 wait commands and 1 selfplay commands you would help me a lot in the test.
marcocalignano
on 14 Jan 2018
Why "each thread"? Would it be possible to set some global wait state and only have 1 thread responsible for checking again?
Dorus
on 14 Jan 2018
There is a possibility that using 3200 playouts could still produce a tiny jump, but IMHO the odds are strongly against it as the problem seems simply that the network is at capacity, not that more playouts are needed to make deeper discoveries about Go (and note the AZ result with 800!).
I still think experiments (4800) are better than assumptions, especially when they are free since the swarm does no other useful things. And I think there can be SIGNIFICANT differences between LZ and A(G)Z in the search code, so if the playout optimum happens to differ that is one more thing to look for.
EDIT: Another idea to experiment with would be to try 5x128 (I guess hacking this is possible to start with the old weights directly, with new weights at near-zero random) - another drop of information for the future.
tapsika
on 14 Jan 2018
What is the risk in freezing 5x64 and letting 6x128 to grow for couple weeks, using contributors GPUs?
If the problem with 5x64 is too small size, why not let bigger net take over, even if slower? As it is 5x64 growth is quite slow anyway.
Marcin1960
on 14 Jan 2018
I don't believe that 6x128 will be much different that 5x64. I'd rather believe that 10x128 will surpass the ama level.
 dzhurak
on 14 Jan 2018
dzhurak
on 14 Jan 2018
It is almost certain that 10 blocks would be significantly stronger. The point is, we should use the current opportunity to gain as much information as possible, to make the most effective use of computation resources during a longer run.
tapsika
on 14 Jan 2018
Am I the only one who would like to continue on 5x64 for quite some time asuming that we get a new best network every 250k-500k games ?
 CheckersGuy
on 14 Jan 2018
CheckersGuy
on 14 Jan 2018
I'd also continue with 5x64. We need to see the limit. It's not at it's max right now.
dzhurak
on 14 Jan 2018
Glad to see a new best network when I got up. BRII is down for maintenance at this moment though.
alreadydone
on 14 Jan 2018
If bootstrapping ends up working after all there's nothing wrong with 6x128. If we have to restart, I would definitely hope we go for 10x128, so the improvement in plateau isn't just marginal.
jkiliani
on 14 Jan 2018
@Dorus Each thread works independently from the other, so if one finishes and receive the wait command, the others may still have to finished their work, so they cannot be stopped. To synch them all with a sigle flag, the code have to be change a lot and more test have to be done. This is the easier and faster way to do the waiting. But maybe you have a good reason to make it global?
marcocalignano
on 14 Jan 2018
@marcocalignano Send get-task/1 and you'll get a wait 80% of the time.
While you are at it, get-task/client-major-version-# is the intended use of that if you want to update autogtp to send proper client version # to the server? Just the major version, it won't read periods/letters/etc.
The idea was we could add support for a feature in a newer client while not sending those commands to older clients, like if old clients were asking for get-task/9 and newer clients on /ext asking for get-task/10.
roy7
on 14 Jan 2018
@roy7 so actually now I should ask get-task/12 but get-task/1 is for the tests. Am I right?
marcocalignano
on 14 Jan 2018
Yeah. /0 for self play only, /1 for wait test.
roy7
on 14 Jan 2018
@roy7 so when I finish testing I will make a PR and the code will ask for /12.
marcocalignano
on 14 Jan 2018
I don't know how @gcp has trained 6x128 networks. But according to him, the training has failed to produce better networks.
Then, why don't we try the technique from a (2016) Google paper titled "Net2Net: Accelerating Learning via Knowledge Transfer" https://arxiv.org/abs/1511.05641?
If we follow that method, the way forward would be to embed the best available 5x64 network in a new 6x128 network, and train it on its own self-play games.
At the starting point, elo would be rather lower than the best network, but it would still be better than starting from complete random games.
ashinpan
on 14 Jan 2018
Then, why don't we try the technique
Great, where do we download your implementation?
gcp
on 14 Jan 2018
If you are wondering why the server is non-responsive right now: I'm running some maintenance and the server is choking a bit. It will clear up in the next few hours.
I don't think we'll accidentally miss a new best network during that time.
Edit: Done now.
gcp
on 14 Jan 2018
@gcp, "Great, where do we download your implementation?" You are the project leader, who makes all decisions. Not everyone else may have the computing resources or expertise that you have. But it does not mean that everything they say is rubbish. At least, you should be able to listen, and respond or ignore as necessary.
ashinpan
on 14 Jan 2018
But it does not mean that everything they say is rubbish.
I don't know if what you said is rubbish! We'd need to test it. You asked us why we don't try, and I want to try. That's why I'm asking for the implementation.
Edit: If you think I'm being an ass, see the paragraph about this kind of discussion in the first post of this topic.
gcp
on 14 Jan 2018
Here's a graph of the recent passing networks of win rates based on games chunked to each 100s of moves:
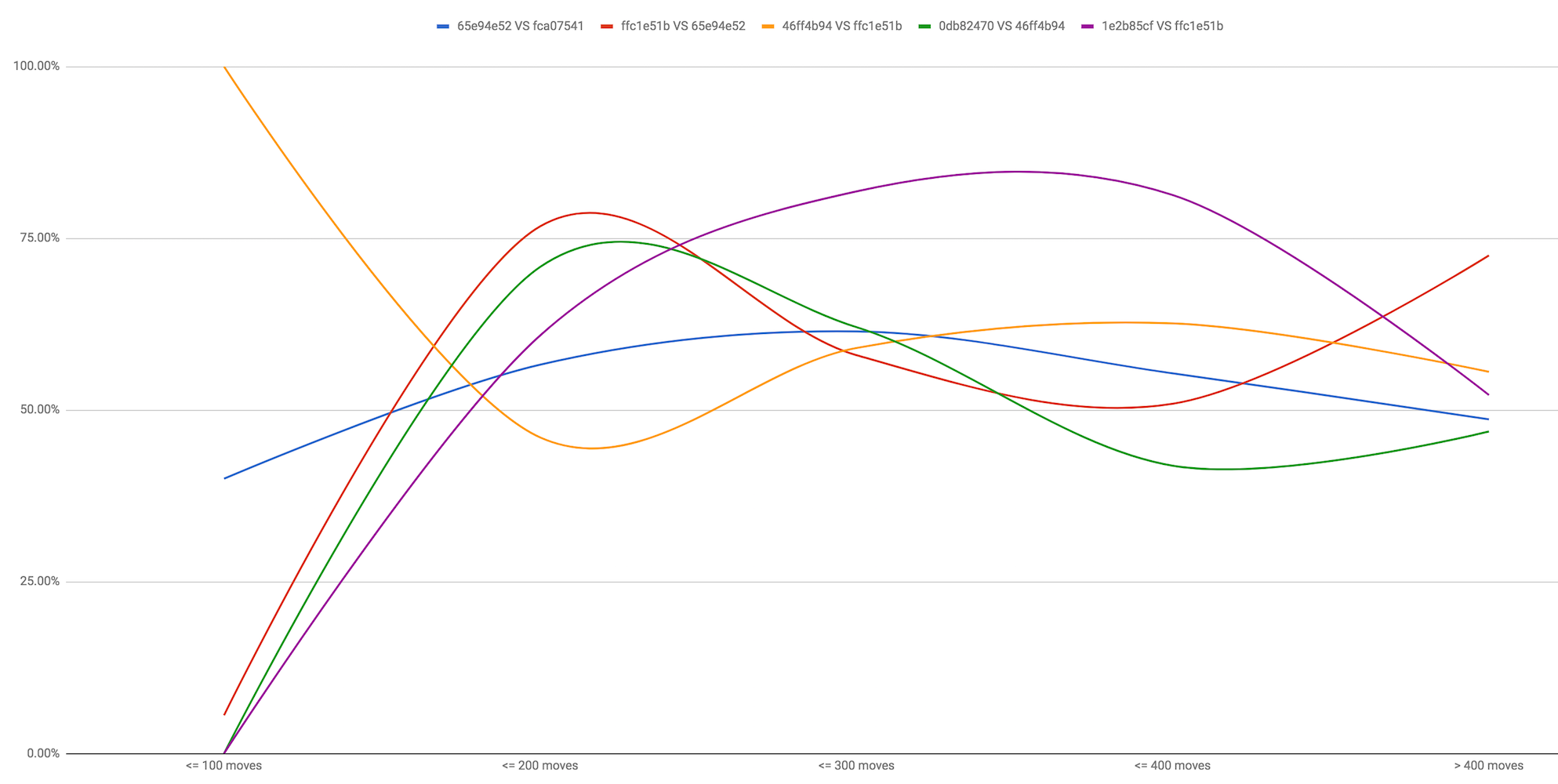
I suppose it mostly shows that 46ff4b94 is the only recent network to not fall early to ladders, although that same network is more likely to lose between 100-200 moves.
The human game trained network 1e2b85cf looks to be particularly strong between 200-400 moves. Also, most games (~55%) fall into the 200-300 moves group, so glancing at that value is a quick estimate of the overall winrate.
(I don't play go, so if someone has better ways to group together games based on the readily available data, I'm open to suggestions.)
Mardak
on 14 Jan 2018
Looking a bit more at the graph from https://github.com/gcp/leela-zero/issues/591#issuecomment-357535647
I wonder if switching networks mid-game is even beneficial. E.g., Play the first 100 moves with 46ff4b94 then the next 100 moves with ffc1e51b, then 0db82470, then back to 46ff4b94, and finish off with ffc1e51b.
I know it's nothing close to the A(G)Z approaches, but potentially that could generate better self play games? (Or generally: some approach that uses a hybrid combinations of networks (potentially of different network sizes too?))
Mardak
on 14 Jan 2018
@gcp "I don't know if what you said is rubbish! We'd need to test it. You asked us why we don't try, and I want to try. That's why I'm asking for the implementation."
It means that you would consider the idea only if you can get an implementation ready to be tested. I understand, you have got a lot on your plate. But someone else may find it interesting to try himself---for, the source is a paper from Google. Even if no one does, it cannot hurt the project by such brainstorming.
As for myself, that Google paper is above my head---both in computing resources and expertise.
ashinpan
on 14 Jan 2018
What use has brainstorming have if you choke as soon as we move to actually using your idea? All gcp said is he needs an implementation. That implementation could come from you or anyone else here. His answer also more or less implicate he'll consider using this idea if somebody actually shows up with an implementation.
Dorus
on 14 Jan 2018
@Dorus What you said is essentially not different from what I said.
ashinpan
on 14 Jan 2018
I found an implementation have a look at my last comment in #648
marcocalignano
on 14 Jan 2018
@marcocalignano Do you think it can be adapted to our use?
ashinpan
on 14 Jan 2018
They are talking about the same paper, but I need a bit of time to dig in both (paper and implementation)
marcocalignano
on 14 Jan 2018
@CheckersGuy You are not the only one, I also want to see how far it can go. What's more, I think if the 5*64 network come to a leap in elo graph because of the trainning parmeters tuned up, this will be conducive to larger network
Tsun-hung
on 15 Jan 2018
One thing which I'll take from this thread is that people don't mind having their clients kept busy even if it is for something with low probability of success. So I guess I will switch to 3200 playouts next time a stall looms.
gcp
on 15 Jan 2018
And I think there can be SIGNIFICANT differences between LZ and A(G)Z in the search code
There shouldn't be? The only known differences are:
UCT parameter might be optimized to a different value, but I observed very little difference in strength between 0.5 and 1.5 for example.
We use the parent node value for Q(s,a) initialization. It seems AGZ used a prior of 0.5 (which is very close to ours if the game is still undecided).
gcp
on 15 Jan 2018
One thing which I'll take from this thread is that people don't mind having their clients kept busy even if it is for something with low probability of success. So I guess I will switch to 3200 playouts next time a stall looms.
I'm sure that there are people who do mind. Personally I don't see the point in looking for a magic number that will allow 5x64 to climb a bit higher, and still most likely be inferior to the vast majority of MCTS based bots.
 Yakago
on 15 Jan 2018
Yakago
on 15 Jan 2018
Looks like 46656616 the 6x128 network trained with only 400k steps total did a bit better, but still not close to current 5x64 network.
evanroberts85
on 15 Jan 2018
If (a big if) training the 6x128 network ends up showing training with less steps gives a better final outcome; should we look to limit the max number of steps each training session runs for, refusing a potential short term gain for better long term network health?
evanroberts85
on 15 Jan 2018
Shouldn't the L2 regularization be scaled as a function of the network size? I run some quick checks with random networks and 20x256 has more than 10 times bigger regularization loss than 5x64 due to the larger size. Is the current value of 1e-4 because it's from the AGZ paper or does it work best for the smaller networks too?
step 10, policy=6.15937 mse=0.281394 reg=0.251964 total=7.53691 (0 pos/s)
5x128
step 10, policy=6.15762 mse=0.280463 reg=0.476988 total=7.75646 (0 pos/s)
5x256
step 10, policy=6.10667 mse=0.28311 reg=0.922638 total=8.16175 (0 pos/s)
20x256
step 10, policy=6.03798 mse=0.314675 reg=3.56568 total=10.8624 (0 pos/s)
 Ttl
on 15 Jan 2018
Ttl
on 15 Jan 2018
It's from the paper. Other values may work better. But note that "10 times bigger" may not mean so much. It's just a value whose gradient the optimizer pulls on, and it works out to decaying the (individual) weights with a certain fixed ratio (which is actually what Caffe calls the parameter). In the latter formula (which IIRC is equivalent), the network size will have disappeared from the equation. That's why values from 1e-3 to 1e-5 are typical for many different network setups.
gcp
on 15 Jan 2018
Since we're not actually enforcing the new version yet, are there any bugs in the prior fixed in 0.10 that might impact game quality or training? I was reminded of this by looking at a match game and seeing the leela command line arguments in the SGF. :) (A v10 feature, games viewed online without that are running 0.9.)
Edit: Correction, that is still a /next feature, didn't make it to v10.
roy7
on 15 Jan 2018
Can you pull up statistics on how many self play games are still from Leela Zero 0.9? (Match games are biassed since Leela Zero 0.10 also had a speed upgrade and clients for match games are selected on speed).
Or simpler, just start enforcing the new version. Nothing wrong with that right now, we have surplus of self play effort anyway now we're waiting for the next version and 5x64 to finalize.
Dorus
on 15 Jan 2018
Mostly OpenCL self-checks. I think we can't force the upgrade though? IIRC @marcocalignano said something about AutoGTP not parsing 0.10.1 correctly. So there would have to be a 0.11 release. I just merged Winograd, so maybe I'll make one with that soon?
gcp
on 15 Jan 2018
Didn't autogtp v8 use a different endpoint? In order to upgrade v11 you can use a new endpoint again so you can require a higher version on the current end point once that time come.
Or just release a version 1.0/v12 :P
Dorus
on 15 Jan 2018
https://github.com/gcp/leela-zero/blob/next/autogtp/Job.cpp#L35
I think the code will work with triple dot versions. It's just that it only enforces you be on a certain MAJOR.MINOR. It ignores stuff after the second dot.
killerducky
on 15 Jan 2018
@alreadydone Have you tried out the latest client? Is it working well on BR?
roy7
on 15 Jan 2018
I think the code will work with triple dot versions. It's just that it only enforces you be on a certain MAJOR.MINOR.
If that's true then we should enforce leelaz "0.10" and AutoGTP "11".
gcp
on 15 Jan 2018
Want me to make that change now and we'll see if things break? :)
roy7
on 15 Jan 2018
@gcp @marcocalignano I've not actually changed this myself before on the server, can you remind me, best-network-hash is what asks for the autogtp protocol version and get-task is what asks for the Leelaz client version, is that right?
Right now best-network-hash sends 8 and get-task sends 10.
roy7
on 15 Jan 2018
Originally best-network-hash sent the AutoGTP version, and each AutoGTP had the Leela version coded in.
With modern AutoGTP that does get-task they're both in the JSON IIRC?
gcp
on 15 Jan 2018
@gcp @roy7
- -autogtp v8 (old version not used anymore hopefully) download bestnet and check lellaz version internally
- -autogtp v 9 v 10 v 11 (new version) ask for json commands the server can set the min version of the client and the min version of leelaz with 2 numbers also 0.10 would work and both binary 0,10 and 0,10,1 will be acceppted.
- -autogtp v 12 (/next) will accept three number version (when merged)
marcocalignano
on 15 Jan 2018
Sorry, yes, it has:
"required_client_version":"10","leelaz_version":"0.9"
Right now. Got it. So I'd move that to 11 and 0.10 if we're ready.
Should the autogtp version being sent in best-network-hash be removed at this point? Do modern clients expect/need it there?
roy7
on 15 Jan 2018
My mistake, best-network-hash isn't even used any more. The hash is in the get-task JSON. Oops.
I'm going to update the required versions now.
Done.
roy7
on 15 Jan 2018
Of the last 107K games (# currently on server, about 1.5 days), 59660 were from a v10 client. People have had 7-8 days to upgrade though.
roy7
on 15 Jan 2018
@roy7 commented on 2018年1月15日 GMT-5下午3:17:
@alreadydone Have you tried out the latest client? Is it working well on BR?
I am using AutoGTP v10 and Winograd without tuner; I think I now need to upgrade to AutoGTP v11. Maybe I'll just check out the /next branch and compile...
alreadydone
on 15 Jan 2018
@alreadydone Ok cool. AutoGTP v11 is the official release along with Leela 0.10.0 (and 0.10.1). /next now has winograd merged in.
roy7
on 15 Jan 2018
d77eb4f9 VS 0db82470 | 205 : 205 (50.00%)
ae492135 VS 0db82470 | 218 : 205 (51.54%)
Just before we stop, we should probably let those go to 800 or 1000 games or so, so we know what actually was the best network.
gcp
on 15 Jan 2018
@gcp Done. Do you want to add a match between d77e and ae49 for good measure?
We could also choose to promote one of these in spite of being under 55% if you like.
roy7
on 15 Jan 2018
Could we currently afford to release and test networks at a faster schedule? Since the majority fail already with only 50 games, we should easily have the capability to test a network once an hour on average. There's a good chance we may find a passing network this way we'd have missed otherwise.
I assume the theory behind the current release schedule [8k, 16k, 32k, 64k, 96k, 128k, 192k, 256k, 384k, 512k] is that with higher step counts, the trained networks asymptotically approach the state of a network perfectly trained to the window. But is it actually proven that the winrate of networks sampled at advanced step counts stays similar? What if there is a chaotic element in the training process, and finding a winning network has more to do with being lucky enough to sample it at exactly the right time than anything else?
If that was the case, a linear release schedule like we had before Christmas would make more sense than the current exponential one.
jkiliani
on 15 Jan 2018
What if there is a chaotic element in the training process, and finding a winning network has more to do with being lucky enough to sample it at exactly the right time than anything else?
That be could be tested by going back to a prior network that promoted with 8k training steps, and run say 10 more network trainings from the prior best network for 8k steps each. See if they all are similar/better strength, or if there is a big swing in the win %.
I know NNs aren't an exact science and AlphaGo Zero also had ups and downs in their results graph, but it still feels weird to me how much variation there is in the win rates and that more data + tons of training steps can result in networks that can barely win a game. :)
roy7
on 15 Jan 2018
A couple of more hours and I'll be done generating training data from the TYGEM "9D vs 9D" dataset (1,516,031 games) from https://github.com/yenw/computer-go-dataset and I'll start traning a supervised 5x64 net like I planned to do in #628
 zediir
on 15 Jan 2018
zediir
on 15 Jan 2018
Great @zediir. :) If we do have any subtle training related bugs left in LZ there's probably no way to find them until someone eventually stumbles into it? Darn black box technologies...
roy7
on 15 Jan 2018
I know NNs aren't an exact science and AlphaGo Zero also had ups and downs in their results graph, but it still feels weird to me how much variation there is in the win rates and that more data + tons of training steps can result in networks that can barely win a game. :)
Nothing weird at all. There is a lot of randomness all over in training. Imagine the network has 64 filters, but 4 of those are absolutely vital to win games. If one of the 8000 training steps damages one of those 4 filters, it wont win much. As vital filters are very likely to be corrected, at 16k or 32k steps that filter might already have been repaired and winrate will jump up again.
As the network goes near capacity it is more likely to forget viral things while learning other things, as there are more "vital things". This is why I'm very interested in comparing a 5x64 vs 6x64 vs 5x128 vs 6x128 (is it really necessarily to double filters?*) and see what has a bigger effect on the network strength.
*) Would it be possible to extend the current network with say 12 random filters and train it again? That would give it a relatively low new upper bound, so training it shouldn't take long to reacha peak. And also that would increase difficulty similar to a 5->6 layer network increase, making comparison a bit easier.
Also, would it be possible to keep experiments like that short? Even if you just run them for 1-2 days, network strength progression has shown to be rather predictable. Even at 1.8M games on our current run it was fairly easy to see where we where going to end up. (Even if i had predicted/expected 100 more elo from the learning rate drop, it was easy to see it wasn't going to hit 7k elo.)
Dorus
on 15 Jan 2018
There is going to be some degree of variation between networks that have been trained the same amount of steps starting from the same network. Gradients are calculated from random game positions and depending on which positions the network saw the applied gradients will be different.
The amount of variance between the networks will depend at least on batch size, learning rate and size of the network. For example see Figure 8 in https://arxiv.org/pdf/1710.06451.pdf for comparison of test accuracy during training with different batch sizes. With larger batch size there is more averaging on each step and the variance is much lower. Lowering the learning rate will also decrease the variance since each gradient has smaller effect. You can actually see on the graph that since the learning rate decrease variance between networks is much smaller.
I guess the variance is also why most of our networks fail so quickly. The next network must be very lucky to beat the previous one which was already lucky to beat the one before it. The new network sees mostly the old data that the previous network was trained with so it doesn't help much that the training is started from the previous best.
I guess that's why Deepmind could remove the evaluation in AZ. They have larger batch size, less training steps, larger network, strict promotion schedule and if they don't rely on lucky networks the next trained network should be very likely to be stronger than the earlier one.
Ttl
on 16 Jan 2018
Wins / Losses | Games | SPRT
-- | -- | --
d77eb4f9 VS 0db82470 | 249 : 256 (49.31%) | fail
ae492135 VS 0db82470 |264 : 266 (49.81%) |
0db82470 is going to claim that prize lol. The first net is now SPRT fail. Would it be preferable to let it run to 1000 anyway to see if it can get back over 50%? SPRT fail only means it wont be likely to get over 55%.
Dorus
on 16 Jan 2018
I'd suggest we shall try 3200 PO plus steps with 8k interval, searching for a best 5 block network before we move to 6 block or something else. :)
 liverex
on 16 Jan 2018
liverex
on 16 Jan 2018
2018-01-16 08:57 | aed8d0d5 VS ae492135 | 1 : 32 (3.03%)
Bootstrapping is turning out to be much harder than anticipated. Unless there's some success in #648 soon I think we may end up going from scratch.
I mean we can try for 2 weeks to get an enlarged network or a bootstrap, or we can run 10x128 for 2 weeks, discover in passing if the AZ no-testing approach works for us, and maybe end up not far from the same point...
gcp
on 16 Jan 2018
Maybe not a bad idea to restart on 10x128 after all... with all the bug fixes, it should climb up the kyu ranks much faster than the first run. If we're taking some things from AZ, what about a different temperature setting than the first run? How about, say, τ=0.5 for the whole game? Move probabilities ~N^2 should prevent most big blunders seen by the tree search from being played, while allowing diversity between moves with similar visit counts. Or simply τ=1, since Alpha Zero seems to have learned very well in spite of (or maybe because) it played these blunders.
jkiliani
on 16 Jan 2018
Yeah, 10b seems to be more exciting to me. On the other hand, it would also
be good to know the limit difference of 5b and 6b. Do you have a rough
estimation on the limit difference @gcp?
On Tue, Jan 16, 2018 at 5:52 PM, jkiliani notifications@github.com wrote:
Maybe not a bad idea to restart on 10x128 after all... with all the bug
fixes, it should climb up the kyu ranks much faster than the first run. If
we're taking some things from AZ, what about a different temperature
setting than the first run? How about, say, τ=0.5 for the whole game? Move
probabilities ~N^2 should prevent most big blunders seen by the tree search
from being played, while allowing diversity between moves with similar
visit counts. Or simply τ=1, since Alpha Zero seems to have learned very
well in spite of (or maybe because) it played these blunders.—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub
https://github.com/gcp/leela-zero/issues/591#issuecomment-357908213, or mute
the thread
https://github.com/notifications/unsubscribe-auth/ABHWLo39NiIjYmXuXzF1tI-C7hjby7d5ks5tLHFIgaJpZM4RVxWY
.
bood
on 16 Jan 2018
Or simply τ=1, since Alpha Zero seems to have learned very well in spite of (or maybe because) it played these blunders.
I'd do τ=1 for the entire game, although as I pointed out in the leela-chess topic, for Go the current approach may work just fine. Remember that they had to find parameters which worked well for games with a much lower branching factor, and for getting chess and shogi to diverge "enough" the first 30 moves might not have been enough.
On the other hand, yay for getting rid of a magic parameter?
gcp
on 16 Jan 2018
Do you have a rough estimation on the limit difference @gcp?
Not really. It seems the supervised 6x128 is still (barely) stronger than our 5x64, so with supervised training you could get some insight.
I think there's an argument that "whole board reading" such as ladders does become easier for the network with >=10 residual blocks. Also it's a more logical progression: 5x64 => 10x128 => 20x256.
gcp
on 16 Jan 2018
How would you go about testing the "no-testing" approach? Simply adopt every new network without testing, or test and then adopt regardless of the result? What about the learning rate adjustments, how would you determine the right time without extensive testing?
jkiliani
on 16 Jan 2018
How would you go about testing the "no-testing" approach? Simply adopt every new network without testing, or test and then adopt regardless of the result?
Fetch all data, run the training for 1000 (batch-size-adjusted) iterations, upload a new network as best.
Testing would happen every 1 in x networks, where x will need some tweaking but something like x=5 or x=10 or so?
What about the learning rate adjustments, how would you determine the right time without extensive testing?
Same as we do now: drop by 1/10th if there's no improvement after a (mostly) full training window. (We can see improvement or not because of the above)
gcp
on 16 Jan 2018
Fetch all data, run the training for 1000 (batch-size-adjusted) iterations, upload a new network as best.
Sounds good, but may be problematic for some clients with poor internet bandwidth if new networks are uploaded very frequently (and of course, a 10x128 weight file is much larger than our current ones). You may want to give clients the option to update less frequently, if bandwidth and download times start being an issue.
jkiliani
on 16 Jan 2018
Taking into account high variance in networks strength how about to test +-4k network near networks with a good score? Like for example we have this network 8k 2d05baee with 46% win score and I wonder what would 4k and 12k networks score would be. This should not take any additional work since network is stored in checkpoints during training anyway.
dzhurak
on 16 Jan 2018
This should not take any additional work
It takes a ton of additional work since the training client would have to periodically go back and ask the server about the current status of all matches (which requires webpage scraping or a bunch of extra API calls server side), figure out which networks were close to the best network enough to warrant investigating (and you have to define the conditions exactly), find back the dumped checkpoints (which now need to be indexed per network instead of per step, and can't be cleaned up) and queue new matches.
gcp
on 16 Jan 2018
may be problematic for some clients with poor internet bandwidth if new networks are uploaded very frequently
Note that the clients will update at most after every game, which can take awhile if they're slow, and that it also takes a bit to dump out the training window (which I would try to speed up, but it won't be instant due to the size of the data).
gcp
on 16 Jan 2018
Another thought is to experiment ideas (AlphaZero approach etc) with smaller board size, e.g. 13x13 or 9x9
It takes time to do any experiments with current settings, but could take much less with smaller board size.
bood
on 16 Jan 2018
I really like the mentioned idea of using 2 or 3 networks since we notice some work better at opening or endgame. It makes sense that optimal weights are different in opening middlegame and endgame. And while you could double the number of nodes it would be faster to not run filters that aren't needed for that phase of the game and leave them room for learning things that are.
The main downside is it might miss a godlike move where an endgame idea works much earlier than normal.
 jjoshua2
on 16 Jan 2018
jjoshua2
on 16 Jan 2018
@bood Smaller board sizes bypass a lot of what makes 19x19 really complex though, and if you want to do smaller board sizes than 9x9, a single machine is enough to get a decent game generation rate (even on 9x9 I manage somewhat with only 4 gtx 1060);
Oh, careful with the winograd code though, I'm still unsure if it's due to an error in the way I've ported the code to support 9x9 (the way tiles work is a bit beyond me to be honest), but it changes the heatmaps a lot (I'm noticing up to 5% difference in prior probabilities, meaning a move that should have a prior probability of, say, 10% without winograd has a prior of 15% with winograd, while another will have lower prior probability, etc.). I'm running a match between leelaz-9-9 without winograd and leelaz-9-9-wn and the winograd version seems to come off a bit worse (43% winrate after 69 games currently, but I'll let it run for 400 games).
Anyway as far as experiments on smaller board sizes go, I think since those can be run on single machines, the "main" Leela Zero project should continue focusing on 19x19.
Alderi-Tokori
on 16 Jan 2018
@Alderi-Tokori https://github.com/glinscott/leela-chess/issues/10 may be of interest to you. It seems porting Winograd to different board sizes alters the way padding has to be done.
jkiliani
on 16 Jan 2018
Ah, thank you, yeah I am around 80% certain the problem is because I didn't change the tile/padding code, I'll look at this.
Alderi-Tokori
on 16 Jan 2018
What's the plan for http://zero.sjeng.org in case of a restart (i.e. the progress curve, links to best networks etc.)? Is there going to be an archive site for past runs, with zero.sjeng.org changed to link to the new run?
jkiliani
on 16 Jan 2018
@jkiliani From what I can see in the code and gcp's comment in the thread, seems like I do not have to touch the current padding / tile code : I still need (W + 1) * (W + 1) / 4 = 25 tiles for 9x9, and it has to be padded to 10x10 (so 1 line and one column of zeros, the same as with a 19x19 board). I don't know why I'm getting such big inaccuracies in heatmaps...
Anyway, I'll stop talking about this here, it's not really the right place. Either I'll figure it out or I'll just stay on the ol' version.
Alderi-Tokori
on 16 Jan 2018
The Winograd code definitely generates larger errors, but I couldn't see any ill effects. It might depend on the exact network weights, whether you have points where the calculation ends up with larger cancellation errors, etc.
https://github.com/gcp/leela-zero/pull/523#issuecomment-357498736
gcp
on 16 Jan 2018
Yeah I was following the thread and I saw your results, but I'm always afraid of some hidden thing changing because the board is smaller and making it work worse for me. FWIW though, I restarted the match between leelaz-9-9 and leelaz-9-9-wn because I realized I had forgotten to add -t 1 to the command line arguments, and now leelaz-9-9-wn has a 68% winrate after 25 games so... shrug I guess I'll let it run for the 400 games and make my decision after that.
Alderi-Tokori
on 16 Jan 2018
I think there's an argument that "whole board reading" such as ladders does become easier for the network with >=10 residual blocks. Also it's a more logical progression: 5x64 => 10x128 => 20x256.
Original AG had 192 filters for 12/13 layers (not blocks). And their paper confirms my experience: unlike extra layers, extra filters are always an advantage. Even on 5 blocks 128 could make some difference (and may ease a later transition? anybody tried to go from 5 to 6 with the same number of filters, with any method?)
This may also partly explain the big difference between original AG strength and current peak (?) at 5 blocks - but is this hardly-dan level really the max 5 blocks could do? I have some doubts, so it would seem a pity to skip the experiment with triple playouts (logarithmic effect) before restart, as that could also offer some validation for the search code (and leave a better final gameset window for later experiments).
tapsika
on 16 Jan 2018
The one thing that will happen (or is already happening) is that ppl are losing intrest and we get less active clients. So maybe we shouldn't wait too long until moving to a different network.
CheckersGuy
on 16 Jan 2018
I expect we'll probably see a new release with Winograd soon, and maybe the restart with 10x128 will happen at the same time (assuming bootstrapping fails and no stronger 5x64 net appears soon). Even if we have to go through the beginning again, I'll certainly continue to support since I'm excited to see how far a 10 block network can go. Hopefully many others view it the same way.
jkiliani
on 16 Jan 2018
Ouch I so wish I have time to build a new computer with a new beefy display card. I wish to test the effect of reduced number of bit planes (from inputting [t0, t-7] to [t0, t-2]) on computation time and go playing strength. (No discrete display card at home :( )
billyswong
on 16 Jan 2018
I don't know if there's any easy way to tell from the interactive darkgo test script or the weights file, but DarkGo is a pure supervised NN that gets about 4d-5d on OGS. It also can't read out ladders but it's quite strong.
https://pjreddie.com/darknet/darkgo-go-in-darknet/
If anyone knows, I'm curious what network structure they use compared to LZ.
roy7
on 16 Jan 2018
If anyone knows, I'm curious what network structure they use compared to LZ.
https://github.com/pjreddie/darknet/blob/master/cfg/go.test.cfg
Seems like 12/13 layers (similar to original AG and just a little more than current LZ) but 256 filters.
tapsika
on 16 Jan 2018
Fetch all data, run the training for 1000 (batch-size-adjusted) iterations, upload a new network as best.
How often would you fetch all the data and run the training? i.e. how many games need to be played before you start training a new network?
 jw098
on 16 Jan 2018
jw098
on 16 Jan 2018
@tapsika Ahh thank you. Too easy.
roy7
on 16 Jan 2018
Original AG had 192 filters for 12/13 layers (not blocks). And their paper confirms my experience: unlike extra layers, extra filters are always an advantage.
Facebook did a similar design with 256 filters, and saw benefit up to 384 filters. But it is not a good idea to reason like this: those experiments were done without resnets, which make the behavior for more layers a lot better.
gcp
on 16 Jan 2018
This may also partly explain the big difference between original AG strength and current peak (?) at 5 blocks - but is this hardly-dan level really the max 5 blocks could do?
The current network is a single 5x64, original AG was 2x6x128 and with hand formed extra inputs and Monte Carlo playouts. That's several massive advantages. Just play leela-zero with 5x64 against regular Leela and you will see the same thing. Without all the extra advantages a bigger net is needed to compensate. It has to carry all the missing knowledge.
gcp
on 16 Jan 2018
I wish to test the effect of reduced number of bit planes (from inputting [t0, t-7] to [t0, t-2]) on computation time
It makes no difference since those are a totally negligible part of the total computation time. You don't even need to test this. 18x64 is small, much smaller than 10x64x64.
gcp
on 16 Jan 2018
How often would you fetch all the data and run the training? i.e. how many games need to be played before you start training a new network?
I don't care, I run as fast as I can. Maybe not worth bothering if it's less than some minimum, but I doubt that'll be the problem.
gcp
on 16 Jan 2018
The current network is a single 5x64, original AG was 2x6x128 and with hand formed extra inputs and Monte Carlo playouts. That's several massive advantages. Just play leela-zero with 5x64 against regular Leela and you will see the same thing. Without all the extra advantages a bigger net is needed to compensate.
There is no doubt that a deeper net is better (and I wouldn't expect the same strength). But currently LZ has roughly average depth with below-average filters (AG used 192, even if also tested with 128 and 256, am I wrong?), so it still seems possible that the current bottleneck has just as much to do with filters - or something else. A dual net may also need more filters than two separate nets individually. So in the end, even on 10x128 the filters may prove a bit lacking.
tapsika
on 16 Jan 2018
Filters can be traded for depth for any feature that does not need more than (filters) simultaneous inputs to compute, but depth has an advantage that it can compute higher level features.
So in the end, even on 10x128 the filters may prove a bit lacking.
And depth can be too, I don't understand what your argument is supposed to be. Lacking compared to what? What does "roughly average depth" mean? Right now it's only 5 blocks compared to 20-40. Comparing to the original AG Lee is deceptive because that had manually constructed high level inputs, and they were not using Resnets then, so they could not make it deeper without making it untrainable.
Remember that 128 -> 256 is a 3-4 times slowndown. But 5 -> 10 is only a 2 times slowdown.
Being slow makes the program weaker.
gcp
on 17 Jan 2018
Remember that 128 -> 256 is a 3-4 times slowndown. But 5 -> 10 is only a 2 times slowdown.
So how about 64*10?
Tsun-hung
on 17 Jan 2018
So how about 64*10?
What about it? It will be stronger than 5x64 and weaker than 10x128.
gcp
on 17 Jan 2018
What about it? It will be stronger than 5x64 and weaker than 10x128.
I wonder if 1064 are stronger than 6128, and which run faster? But it seems unnecessary to test since 5903f263 can beat the 5 blocks network,
Tsun-hung
on 17 Jan 2018
I wonder if 1064 are stronger than 6128, and which run faster?
I suspect 10x64 might be stronger, but I'm not sure, and not sure about the speed, especially with Winograd.
it seems unnecessary to test since 5903f263 can beat the 5 blocks network,
Well it seems we got an 6x128 that doesn't suck. But 5x64 should run a bit more, it's still making progress.
gcp
on 17 Jan 2018
@gcp we notice 6b network 5903f263 has beat the 5b network 35df1f93, does it mean 5b -> 6b success?
Could you please say some technology detail about how to train the 6b network from 5b self-play games.
 pangafu
on 17 Jan 2018
pangafu
on 17 Jan 2018
I did what I said above, i.e. I reduced the weighting on the MSE component in the loss calculation by 10. (The AGZ paper points out a similar trick for supervised learning)
I also used a slightly higher learning rate (which also prevents overfits a bit), and a 500k window (given that we had a bunch of networks of nearly the same strength when I made the dataset).
None of those are necessarily good for a new self-play run, I just looked at what seemed to be going wrong with supervised learning and tried to correct as much as possible.
gcp
on 17 Jan 2018
So the 6b network training start from a random network? @gcp
pangafu
on 17 Jan 2018
Yes, it's a random network trained on the 5x64 self-play data. Starting at around 850k games, which is the point where most serious bugs were fixed.
gcp
on 17 Jan 2018
Marvelous job!
pangafu
on 17 Jan 2018
Will there be a 6x128 run from scratch or immediately a 10x128 one (the geometric half-way point to 20x256 though the latter is of course much slower)?
 odeint
on 17 Jan 2018
odeint
on 17 Jan 2018
Given that we have something reasonable to bootstrap from, I don't think I'll be starting from scratch.
gcp
on 17 Jan 2018
If this was your first try with the new loss calculation and it ended up this good, I think there's a good chance of finding an even better bootstrap with a few tries. Are you training 6x128 on newer games with 5903f263 as a starting point?
By the way, if value head overfitting is such a serious obstacle to getting stronger nets, has it been tried to reduce MSE weighting in reinforcement learning as well?
jkiliani
on 17 Jan 2018
I wish to test the effect of reduced number of bit planes (from inputting [t0, t-7] to [t0, t-2]) on computation time
It makes no difference since those are a totally negligible part of the total computation time. You don't even need to test this. 18x64 is small, much smaller than 10x64x64.
Thanks for clarification. I always mistook that the 18 bit planes are still there after filters, not realizing they are melted into 64/128/256 filters for all subsequent network layers, not 18x64 etc.
billyswong
on 17 Jan 2018
I reduced the weighting on the MSE component in the loss calculation by 10.
By that, I assume you mean the mse component had a weight of 0.1? I didn't recall them mentionning this in the paper, so I skimmed through it and saw they used an even more extreme weighting of 0.01 for the mse component.
By the way, if value head overfitting is such a serious obstacle to getting stronger nets, has it been tried to reduce MSE weighting in reinforcement learning as well?
I don't think it has but that's something to consider, I don't see any reason why it would work for supervised and not for reinforcement, but I'm admittedly not an expert.
Alderi-Tokori
on 17 Jan 2018
c83e1b6e has a higher Elo that best_v1 (1e2b85). That is a fantastic achievement.
More frequent testing seems to be working to find every last big of strength from this 5x64 network, after it had looked to have stalled before.
The value head data overfitting before the policy head is very interesting. I had this idea a while back to test training alternating using a higher weighting for the policy output on high-playout games and a small training window, then a higher weighting for the value output on very-low-playout games with a large training window(millions of games played quickly). Just need to get a decent GPU.
evanroberts85
on 17 Jan 2018
6x128 net, 5903 / 848K playing on KGS now, as LeelaZeroT against 3 dan Hirabot33
Marcin1960
on 17 Jan 2018
c83e1b6e has a higher Elo that best_v1 (1e2b85). That is a fantastic achievement.
Can we test these 2 nets straight up? That would be interesting.
Dorus
on 17 Jan 2018
I don't think it has but that's something to consider, I don't see any reason why it would work for supervised and not for reinforcement, but I'm admittedly not an expert.
The problem with supervised learning is the small dataset (in terms of game outcomes, which is much smaller than the amount of "move selections"), and that isn't so much a problem for a reinforcement learning network, that sees much more games in total. In the AGZ case, there's a control on overfitting by test matches, and in the AZ case, the overfitting gets corrected quickly because it starts to lose and the data for those games goes into the next learning iteration (strictly speaking, the 2nd next).
There are also differences in the nature of the data (supervised learning games don't necessarily resign at the same point).
When bootstrapping a bigger network on the smaller network data, you get a kind of mix of these problems. You don't have a problem with the data amount, but it's unclear how long you should train on each window. If you train too long on a single window, it will just start remembering the outcome of those games.
gcp
on 17 Jan 2018
I see, I guess in my case it'd still make sense to test this then, since I always only use the games generated by the latest best player (which makes for small datasets).
Alderi-Tokori
on 17 Jan 2018
wish to test the effect of reduced number of bit planes (from inputting [t0, t-7] to [t0, t-2]) on computation time
It makes no difference since those are a totally negligible part of the total computation time. You don't even need to test this. 18x64 is small, much smaller than 10x64x64.
Thanks for clarification. I always mistook that the 18 bit planes are still there after filters, not realizing they are melted into 64/128/256 filters for all subsequent network layers, not 18x64 etc.
hmm I was under the same impression, thx for clarifying.
 ThorAvaTahr
on 17 Jan 2018
ThorAvaTahr
on 17 Jan 2018
I did what I said above, i.e. I reduced the weighting on the MSE component in the loss calculation by 10. (The AGZ paper points out a similar trick for supervised learning)
I suspect that this kind of networks would have a huge initial strength drop when we use them in our current selfplay-training iteration. It's easy to imagine a sudden change from 10:1 to 1:1 in the scale of gradients back-propagated from those two heads would disrupt the structure of the network, and it would take quite a while to stabilize.
Might as well use a model that's weaker but trained in the same way as our reinforcement learning, or just wait for more 5x64 data and train on them with the 1:1 setting. AGZ didn't scale the MSE component lower in their supervised learning from their self-play games in their 4-network comparison experiment, because they got more data than what they had with human games:
"Each network was trained on a fixed data-set containing the final 2 million games of self-
play data generated by a previous run of AlphaGo Zero, using stochastic gradient descent with
the annealing rate, momentum, and regularisation hyperparameters described for the supervised learning experiment; however, cross-entropy and mean-squared error components were weighted equally, since more data was available." (page 29-30)
RavnaBergsndot
on 18 Jan 2018
Filters can be traded for depth for any feature that does not need more than (filters) simultaneous inputs to compute, but depth has an advantage that it can compute higher level features.
This is nice in theory (and I as a human could set weights manually to postpone some processing to later layers), but were this actually tested in go (does gd find such optimums reasonably well)? As I mentioned I have always seen (on non-go data) extra conv filters / wider fc layers increase strength even where further layers do not any longer. OC, LZ is nowhere above optimum (which is likely above 40 blocks), this is just about bottlenecks.
Maybe it would worth to train a few 5x128 and 10x64 nets on the last 1M games or so, and compare their performance. With "roughly average" and "below average" I meant I'm unaware of anybody sucessfully using only around 64 filters, so these at least seem unknown waters. OTOH, on 10x128 this problem will mostly solve itself anyway.
tapsika
on 18 Jan 2018
Correct me if I'm wrong, as I'm not very knowledgeable on this. But somebody mentioned 5x128 is 4x as difficult as 5x64 and 10x64 is only twice as difficult. Wouldn't it make more sense to compare 5x128 to 20x64?
Dorus
on 18 Jan 2018
I think speed is (very) roughly proportional to the number of connections. One can compare both on this parity and on number of neurons, but the latter may say more about the extent the postponed feature extraction works in practice. In any case the results are biased (either twice as much neurons OR connections).
But in practice the huge variance on training/testing makes comparison even harder (would depend mostly on luck, even if you train a few nets each :) ). Another distorting factor is the quality of current selfplay games (it's possible that even a better net could not immediately realize its potential).
tapsika
on 18 Jan 2018
@roy7 I plan to deploy the latest /next branch on BRII since it has the ko bug fixed. Since the code may not have been exhaustively tested, would you prefer me modifying the source so that you can tell from the uploaded game data that they are generated by this version? If so, let me know what to do.
(BTW I will still be using get-task/0 since GPUs on BRII are still unable to run matches and CPUs are too slow.)
alreadydone
on 18 Jan 2018
@alreadydone I'm not sure who/where it is, but think there was a PR or commit to put a special version number in the SGF comments for people who compiled off /next and weren't using the official releases. Ah, it was a discussion in https://github.com/gcp/leela-zero/pull/426 with @killerducky but I'm unsure of the current status of that.
I think you're safe to just give /next a shot. If some sort of critical problem appears we'll know it was the data of all /next clients from 1/18/2018 forward.
If you track your game speeds or do any benchmarking, I'm curious how all of the recent speed improvements pay off for you. Such as winograd, etc. Is it possible you can do a --tune-all once and that be used by all of your instances? I'd hate for you to get stuck running 100+ tuners for each GPU instance. :)
roy7
on 18 Jan 2018
@roy7 Thanks for the reply. The speed went up from ~1900ms/move (previous benchmark) to 1630ms/move 1480ms/move with default tuning. I run all instances of autogtp from the same directory, and once tuning has been done once and the leelaz_opencl_tuning file created no more tuning will be attempted. I've done tuning both for 5x64 and both 6x128 so there shouldn't be a problem when we switch. Here are the results after trying 578 valid configurations with default tuning:
0;XgemmBatched;64;100;64;16; -DKWG=32 -DKWI=2 -DMDIMA=8 -DMDIMC=8 -DMWG=32 -DNDIMB=16 -DNDIMC=16 -DNWG=32 -DSA=1 -DSB=1 -DSTRM=0 -DSTRN=0 -DVWM=4 -DVWN=2;OpenCL: NVIDIA Corporation Tesla K20 @ 705MHz | 0.0353 ms (371.3 GFLOPS)
0;XgemmBatched;128;100;128;16; -DKWG=32 -DKWI=2 -DMDIMA=8 -DMDIMC=8 -DMWG=32 -DNDIMB=16 -DNDIMC=16 -DNWG=32 -DSA=1 -DSB=1 -DSTRM=0 -DSTRN=0 -DVWM=4 -DVWN=2;OpenCL: NVIDIA Corporation Tesla K20 @ 705MHz | 0.0945 ms (554.8 GFLOPS)
The two configurations are identical but when I tuned for 5x64 once more the configuration changed to
0;XgemmBatched;64;100;64;16; -DKWG=32 -DKWI=2 -DMDIMA=8 -DMDIMC=8 -DMWG=32 -DNDIMB=32 -DNDIMC=32 -DNWG=64 -DSA=1 -DSB=1 -DSTRM=0 -DSTRN=0 -DVWM=4 -DVWN=2;OpenCL: NVIDIA Corporation Tesla K20 @ 705MHz
However I didn't use --full-tuner so I'll do it now and update the results when done. (Edit: takes too much time, will do later.)
alreadydone
on 19 Jan 2018
So about 15% more Big Red for us to enjoy. :) I ran full tuning twice and got 1228.2 and 1235.6 GFLOPS as my results on a 1080Ti.
roy7
on 19 Jan 2018
@alreadydone I'm confused you said your GPUs are not working but then you posted tuning results showing a Telsa K20?
killerducky
on 19 Jan 2018
@killerducky The GPUs can't do matches because two leelaz instances can't access GPU at the same time; however self-play games are fine. The GPUs are currently in process exclusive mode; the latest update was that the staff got a mode switching script from ORNL and would see if that can work on BRII, but no timeline was given.
cuDNN (7.5, 7.0, 5.1) is available on BRII however I had trouble making the codes of NTT123 and sethtroisi work on BRII; if they work further speedup can be expected, but anyway the codes seem to be out of sync with gcp/leela-zero. TensorFlow (1.1.0) is also available but I guess training will be slow with the K20...
alreadydone
on 19 Jan 2018
@roy7 When I looked at console output stored on the disk it shows the speed ~1630ms/move, but when I tested under the same condition as before the speed turned out to be ~1480ms/move, even faster. I guess that the difference is possibly due to: (1) writing the console output of (100-200 instances of) autogtp to (the same) file; (2) high CPU usage (the GPU nodes each come with a 16-core CPU; 14 cores each run 1 instance of autogtp; 1 core runs the autogtp that runs leelaz on the GPU; the remaining core runs PCP.) Maybe I'll do some tests to pin down the cause.
alreadydone
on 19 Jan 2018
Since your compiling why don't you try commenting out a lot of the print
statements to hopefully fix it if its #1. Or maybe try putting a timestamp
of start in the filename so they won't all be exactly the same?
On Thu, Jan 18, 2018 at 9:23 PM, JY XU notifications@github.com wrote:
@roy7 https://github.com/roy7 Are 1228.2 and 1235.6 GFLOPS from a 5x64
network? What about a 6x128 one?When I looked at console output stored on the disk it shows the speed
~1630ms/move, but when I tested under the same condition as before the
speed turned out to be ~1480ms/move, even faster. I guess that the
difference is possibly due to: (1) writing the console output of (100-200
instances of) autogtp to (the same) file; (2) high CPU usage (the GPU nodes
come with a 16-core CPU; 14 cores each runs 1 instance of autogtp; 1 core
runs the autogtp that runs leelaz on the GPU; the remaining core runs PCP
https://kb.iu.edu/d/bdka.) Maybe I'll do some tests to pin down the
cause.—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
https://github.com/gcp/leela-zero/issues/591#issuecomment-358847259, or mute
the thread
https://github.com/notifications/unsubscribe-auth/AO6INBxeBP_ed3G7WZVxUU-SLzCrQl8Tks5tL_yfgaJpZM4RVxWY
.
jjoshua2
on 19 Jan 2018
@alreadydone can you remind me, are you able to have multiple CPUs submit work to the same GPU? Like autogtp -g 8 or similar?
killerducky
on 19 Jan 2018
I tried a game with no playout limit but 15 second moves, and LZ seemed to beat DarkGo well enough DarkGo resigned early. First 20 or so moves were on 1600 playouts by accident. https://online-go.com/game/11332742
I should perhaps run an additional "slow" LeelaZero bot on OGS like the KGS people do.
Trying a game vs Bifron now (a Leela instance I think). With more playouts, LZ mixes the opening up more. It did a 3-4 opening for 2nd move. (https://online-go.com/game/11333017)
roy7
on 19 Jan 2018
@roy7 Many people have already tried that. If no playout limit but 15 second moves, Leela zero with current best network has earned 6dan level. However, it still sometimes makes some silly mistakes, such as cannot read life and death of big groups. I have also asked some 6dan to 7dan friends to play 30 seconds leela, and they all believe it at least has 6 dan strength.
pcengine
on 19 Jan 2018
@roy7
According to some Chinese go players, LeelaZero playing 15 seconds has earned 4-dan level using fca0 network, 5-dan level using 46ff, and 6-dan level with current best.
pcengine
on 19 Jan 2018
Ah, great info. Thanks. :) I think I mostly did the 1600 playout approach to minimize the damage to RoyalLeela since they both share the same GPU.
roy7
on 19 Jan 2018
The 6 Dan is on fox go server. That is 3 - 4 Dan on KGS.
 fell111
on 19 Jan 2018
fell111
on 19 Jan 2018
@jjoshua2 I did the tests which show that the speed difference is actually due to (2) instead of (1).
@killerducky At this moment one GPU on BRII can be accessed by one process only. In addition to this problem I do have some trouble making autogtp -g 2 (or higher) work with aprun and mpiexec, so I am now running only one leelaz with each autogtp. details
By the way I find that the speed dropped from ~1480ms/move to ~2250ms/move using the latest /next branch. (The tuner output remained ~0.0350ms.) Is this possibly due to your fix?
@gcp IMHO to truly explore the limit of 5x64 the suggestion of Dorus is worth considering; I would start by adding one feature for ladder capture, one for ladder escape, and one for whether liberty is >1 following the AG paper, Extended Data Table 2. Our best network's performance in these aspects fluctuates; dealing with these seem to place to much burden on a small network, consuming too many weights, and making it hard for the network to learn other important things without forgetting these and dropping its winrate. Such weaknesses may be addressed by enlarging the network but small networks do have the merit of being fast as people mentioned.
BTW I do favor using new networks with winrate below 55% to generate self-play games (at least those above 50% and maybe also those not too much worse); they add variations to the data and may speed up the progress.
alreadydone
on 19 Jan 2018
By the way I find that the speed dropped from ~1480ms/move to ~2250ms/move using the latest /next branch. (The tuner output remained ~0.0350ms.) Is this possibly due to your fix?
It's due to the implementation of tree reuse. This means that the NNCache loses most of its effectiveness, but the program becomes vastly stronger at the same playout count.
With Winograd, tree-reuse and multi-GPU, it's time for a new release.
gcp
on 19 Jan 2018
@roy7 If you can spare the gpu time, a LZ slow on OGS would give a much more accurate rating than the unranked bots on KGS.
wnwen
on 19 Jan 2018
Are we going to start self-play games with 6 blocks network tomorrow?
Tsun-hung
on 19 Jan 2018
I have a question about the bootstrap procedure: When a 6x128 net is put up as best network (probably 5903f263 at this point), will the training use a mixed window for a while (i.e. partially 5x64, partially newer 6x128)? What would be the reinforcement learning rate after bootstrap, back to 0.001 or even 0.01?
jkiliani
on 19 Jan 2018
I would hope the switch to a new network is delayed till the new client is released and enforced on the server. Also if the new tree reused code makes Leela stronger, it might be interesting to see how to 5x64 network react to self play games with that new code, if the theory is correct that this result in higher quality games, it might also result in higher quality training data and eventually in higher quality networks.
That said, i also cannot wait for the new larger network to start making games. Once that network goes near top strength, it will be very interesting if we can train a 5x64 network on those self play games and see if it can top the current 5x64 network.
Dorus
on 19 Jan 2018
When a 6x128 net is put up as best network (probably 5903f263 at this point), will the training use a mixed window for a while (i.e. partially 5x64, partially newer 6x128)?
Yes. Training on a smaller window makes overfitting problems even worse.
What would be the reinforcement learning rate after bootstrap, back to 0.001 or even 0.01?
I think it should be reset. Not sure where though :-)
gcp
on 19 Jan 2018
Are we going to start self-play games with 6 blocks network tomorrow?
Looks likely. I think I can just copy it over and self-play and training should switch to it. I'm not sure about promotion though, whether the next one will need to beat that or beat c83e1b6e.
gcp
on 19 Jan 2018
You could just act like everything reset, only difference is that we initiate with a trained instead of random network (and the training window already contains games). Thus the network we use as current best switches to a 6x128 one, and the next current best should beat that 6x128 one.
It shouldn't be relevant if the first or second 6x128 one can beat the last 5x64 or any other arbitrary net.
Dorus
on 19 Jan 2018
I think it should be reset. Not sure where though :-)
How about an experiment? Run one training window with 0.01, with enough networks output (10-20) and see if we get passers. If not, try the next window with 0.001.
My guess would be 0.001 is probably better, since we should already be in the region where even 6x128 flattens off.
jkiliani
on 19 Jan 2018
@alreadydone I think the ladder related fluctuations come from the vision limit, and the nets assigning probabilities to unreadable ladders according to the statistics observed during training (which has random variance). So in the end a net appears "stronger" if the ladder working percentage during the eval match happen to be close to the percentages it last seen during training (which is random of course).
But AFAIS the majority of games are decided by other means not ladders. This may also be a sign of the net starting to understand the correct handling of ladders: avoiding unreadable ones. And a few extra layers (like on 6 blocks) will likely mitigate this problem.
tapsika
on 19 Jan 2018
Where to restart 6x128, if the size of 5x64 was a cause for flattening out?
I looked at the strength graph and I had an impression that the flattening started to appear soon after 1,300K. So I would take the best network before that and if the size was the reason 6x128, could catch up with today best net around 1,700, to keep moving up until next flattening.
What do you think?
Marcin1960
on 19 Jan 2018
What do you think?
We can't just pick a 5x64 network and make it bigger, see #648.
gcp
on 19 Jan 2018
So if i understand things right, we will switch self play and best net to 6x128 soon? Probably that is 0d7766a4 right? The plan to start from zero is frozen for now?
I remain interested to see if starting from zero again on a 6x128 net ends up with a stronger net than bootstrapping like we did now. Anyway to compare those two scenario's we need to run both anyway so makes sense to start with the most promising one.
So many possible experiments, so few we can actually run :-)
Dorus
on 19 Jan 2018
@gcp
I'm not sure about promotion though, whether the next one will need to beat that or beat c83e1b6e.
You can manual promote whenever needed by just over-writing best-network.gz with the network you want promoted.
roy7
on 19 Jan 2018
Here's a funny example "you may not resign".
roy7
on 19 Jan 2018
Here's a funny example "you may not resign".
is resignation deactivated for certain matches? or is it just that network?
Liserotte
on 20 Jan 2018
Good question. Some % can't resign in selfplay, but matches can always resign I thought. So I wonder why black didn't give up.
roy7
on 20 Jan 2018
Probably the seki. Black hopes White will accidentally suicide the seki.
BTW note this is proof White understands the seki, even if Black is hoping White doesn't understand it. ;-)
killerducky
on 20 Jan 2018
I've got RoyalZeroSlow playing on OGS for the weekend. Here was a complex game where L&D destroyed her in the end sadly.
roy7
on 20 Jan 2018
Very nice. It will be interesting to see if the larger net will become better at LD problems.
Dorus
on 20 Jan 2018
Just run a handi game with Leela 0.11. The 0d7766 net is quite weak and there will be much training needed. Regarding LD problems, I really like the 5748 net which sometimes even outsmarted Leela 0.11.
 Splee99
on 20 Jan 2018
Splee99
on 20 Jan 2018
Surprised by the sudden jump in performance by 6x128 networks just by
further training. Did you make any more tweaks to training @gcp?
Anyhow it looks like we are now on 6x128 for self-play which makes
following more exciting again.
On Sat, 20 Jan 2018 at 02:12 Splee99 notifications@github.com wrote:
Just run a handi game with Leela 0.11. The 0d7766 net is quite weak and
there will be much training needed. Regarding LD problems, I really like
the 5748 net which sometimes even outsmarted Leela 0.11.—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/gcp/leela-zero/issues/591#issuecomment-359137085, or mute
the thread
https://github.com/notifications/unsubscribe-auth/AgPB1rHRnqBDZlTQT_v9-cFHttz19O37ks5tMUtzgaJpZM4RVxWY
.
evanroberts85
on 20 Jan 2018
I noticed some 10b networks queuing to test at zero.sjeng.org/networks
What will we do if they pass? I think it's too early to switch to 10b at this moment.
 zjuwyz
on 20 Jan 2018
zjuwyz
on 20 Jan 2018
@zjuwyz I think it's likely that the 10 block networks are going to be tested against a network that's not best-network for now. That way, @gcp can measure their strength without risk of an unexpected promotion.
jkiliani
on 20 Jan 2018
I queued about 10 matches of 6x128 and 10x128 against "best-network". The good ones will automatically promote, and this has in fact happened for one of the 6x128.
That way, @gcp can measure their strength without risk of an unexpected promotion.
No, if they are clearly better than the best 6x128 they will promote.
gcp
on 20 Jan 2018
How do you queue a 10 block vs a 6 block network? Do they get unbalanced playouts? If not, the 10 block network will be using more resources right?
Dorus
on 20 Jan 2018
I think it's too early to switch to 10b at this moment.
10x128 is much closer to 6x128 than 5x64 is to 6x128. 10 blocks has various advantages in dealing with large groups, e.g. see #658. So it's a size with good potential. We'll see if any manages to promote.
gcp
on 20 Jan 2018
If not, the 10 block network will be using more resources right?
Yes, same as for 6x128 vs 5x64 where the difference is much larger even.
gcp
on 20 Jan 2018
Ah, so even if it promotes it actually still has less real elo because we have to compensate for computing time.
How much slower is 6x128 vs 5x64, and how much slower is 10x128 vs 5x64? I believe any doubling in computing time gave the previous network ~200 elo, so if we know those ratio's we can compensate the elo graph with that.
If i remember right 6x128 will be 4x slower and 10x128 66% slower, so around 400 elo and 130 elo if i need to make a ballpark estimate.
Dorus
on 20 Jan 2018
Why should we care for a computing time since we compare networks with the same amount of playouts?
If i remember right 6x128 will be 4x slower and 10x128 66% slower, so around 400 elo and 130 elo if i need to make a ballpark estimate.
The bigger network is faster?
dzhurak
on 20 Jan 2018
Why should we care for a computing time since we compare networks with the same amount of playouts?
I guess it matters to online bots that are timer based, not playout based. So a "best network" in fixed playouts may not be the best network (yet) in fixed time.
billyswong
on 20 Jan 2018
Why should we care for a computing time since we compare networks with the same amount of playouts?
Because a larger net will take longer to compute the same number of playouts.
The bigger network is faster?
No, i compared the 10x128 to the 6x128 one, so you should stack the 4x and 1.6x slowdown. 5x64 vs 10x128 is probably a 6.6x slowdown.
Dorus
on 20 Jan 2018
But the chart on leela page is based on 1600 playouts. We don't need to change it. Let's compare apples with apples.
dzhurak
on 20 Jan 2018
Update: 6x128 takes 3767 ms/move for me, 5x64 took 1517 ms/move, so this is a 2.5x slowdown only. That makes about 250 elo.
Dorus
on 20 Jan 2018
On what time setting? Because starting from enough time the difference will be ~0 elo.
dzhurak
on 20 Jan 2018
How do the gflops on the self tuner correlate to time spent on moves? I went from 870 gflops on the quick self-tuner to 1300+ gflops when using the full tuner mode. If that should be seen as a decrease in time per move, then wouldn't it make sense to force the full-tuner since it doesn't need to be run that often?
What kind of differences are other people getting between the quick self tuner and leelaz --tune-only --full-tuner ?
EDIT: I switched back to quick tuner to test what the difference in time per move is, and now the quick tuner is giving me 1161. I've gotten 930 on Windows, 870 on Linux several times, now 1161, full tuner giving over 1300. The tuning results seem to be all over the place at least for me when re-running? Same card, same CPU, no other load on computer.
 MaxMaki
on 20 Jan 2018
MaxMaki
on 20 Jan 2018
Why did e574f59d just queue against ed002cf3, when there's still a good chance 7fde81e8 may pass?
jkiliani
on 20 Jan 2018
It happened, 7fde81e8 now passed and promoted but e574f59d is going against the prev-best.
The only good news i guess is that it only scored 25% so far so it's not likely to promote.
Dorus
on 20 Jan 2018
For me at least the gflops seem to be somewhat correlate with time spent per move.
I'm seeing a 10% decrease in time when using full tuner instead of quick tuner, IF the quick tuner happens to give me a good result.
So at least basically for me, the use of full tuner on a GTX 1060 on Ubuntu is a rather big performance gain.
MaxMaki
on 20 Jan 2018
No, if they are clearly better than the best 6x128 they will promote.
If any of the 10x128 nets do promote, can we seriously consider either running -v 1600 instead of -p 1600 self-play games, or -p 1000? I'm mentioning this now since if there is ever a time to consider trading some strength for speed, it's after a successful bootstrap, when the currently used network size still has a lot of improvement potential. When the learning curve flattens again, higher strength self-play will become more important again than it is now.
jkiliani
on 20 Jan 2018
I notice my prior tunings for 5x64 gave me 1235 GFLOPS but my fresh --full-tune on a 6x128 network is giving me 2500 GFLOPS. Would that mean anything, like better GPU usage from the larger network or things along those lines? Or are the GFLOPS speeds not directly comparable between network sizes?
roy7
on 20 Jan 2018
I noticed that the bootstrapped net tends to resign very late, with the end result that our game rate has now dropped by much more than the factor 2.5 from the ms/move increase. Looks like the bootstrapped net has a much stronger policy than c83e1b6e, but a weaker value net, so it ends up playing on when recent 5x64 nets would have resigned long ago. I think the easiest fix for this would be to quickly produce a lot of games with the new networks, a bit less strength shouldn't matter much since it now needs to straighten out its value net first. Maybe a change to -v 1600 or even -v 1000 temporarily would help?
jkiliani
on 20 Jan 2018
I'd need to double check that full support for --visits is on server and autogtp already.
roy7
on 20 Jan 2018
Surprised by the sudden jump in performance by 6x128 networks just by further training. Did you make any more tweaks to training @gcp?
5903f2 was already stronger than the 5x64 networks that had the same training data (it's a green dot above the blue line on the graph), I just synchronized the training machine with the latest data.
gcp
on 20 Jan 2018
Same card, same CPU, no other load on computer.
Almost all modern cards have built-in overclocking and variable clocks that are temperature controlled. It's very hard to get a stable reading.
gcp
on 20 Jan 2018
If any of the 10x128 nets do promote, can we seriously consider either running -v 1600 instead of -p 1600 self-play games, or -p 1000?
I thought the tests with -v versus -p were inconclusive?
gcp
on 20 Jan 2018
Would that mean anything, like better GPU usage from the larger network or things along those lines? Or are the GFLOPS speeds not directly comparable between network sizes?
Larger networks (in terms of filters, not layers!) can make much more efficient use of the GPU. There's much more to compute at the same time. That's why I said earlier that although going 64 -> 128 is in theory a 4x speed drop, we won't get quite the same penalty in practice.
The GFLOPS are comparable between the sizes. They calculate how much actual GFLOPS we can get out of the GPU for the matrices that we need to evaluate. As you can see, it's a pretty far cry from what you'll find on the marketing materials, though it does get closer for very large networks.
gcp
on 20 Jan 2018
Anyhow it looks like we are now on 6x128 for self-play which makes following more exciting again.
Well yes, but:
a) The rate of self-play games will drop a lot.
b) The overall curve will be flatter because the network is bigger, you can't expect to see the same slope of line as when it was 1500 Elo. (Also happened to AGZ)
On the other hand, roughly each ~250-300 Elo we can gain now is maybe a stone improvement...for a player that is somewhere between 3d and 5d or so.
gcp
on 20 Jan 2018
Is there some optimal # of filters for modern GPUs? Should we be considering like 5x256 or 6x256?
roy7
on 20 Jan 2018
I do not think we can know exactly what to expect from 6x128, that is why
it is exciting. First two networks trained on the new 6x128 data have
failed badly. Are you using the lowest learning rate that the 5x64 network
was using, or did you put it up a bit like you said you might?
On Sat, 20 Jan 2018 at 19:31 Jonathan Roy notifications@github.com wrote:
Is there some optimal # of filters for modern GPUs? Should we be
considering like 5x256 or 6x256?—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/gcp/leela-zero/issues/591#issuecomment-359196177, or mute
the thread
https://github.com/notifications/unsubscribe-auth/AgPB1nDDfiKGAQTXHOxZtpRz8W8F11Bcks5tMj74gaJpZM4RVxWY
.
evanroberts85
on 20 Jan 2018
I thought the tests with -v versus -p were inconclusive?
This is not about strength... I made the observation that the bootstrapped net tends to resign very late, and that for this reason it's probably better to create more games for the moment, at the cost of reduced strength. Correct me if I'm wrong, but I remember that right at the start of the project, our reasoning was that until networks can count to an acceptable degree, more data was more important than slightly better data. If the bootstrapping procedure has produced a net with stronger policy but weaker counting ability (and the late resignations suggest that to me), then would reducing playouts not make sense at the moment?
jkiliani
on 20 Jan 2018
Are you using the lowest learning rate that the 5x64 network was using, or did you put it up a bit like you said you might?
I raised it again to the initial value. But I don't think that has got anything to do with its failure right now actually.
gcp
on 20 Jan 2018
Should we be considering like 5x256 or 6x256?
For regular Leela the penalty of going 192->256 was not worth it (but she does not have Winograd). So I think 128 is a good step for now. More layers are very important, I stated several times above why.
gcp
on 20 Jan 2018
I remember that right at the start of the project, our reasoning was that until networks can count to an acceptable degree, more data was more important than slightly better data.
This was before they had any policy to speak of (the initial networks had near uniform priors).
If we incorporate your suggestion now, you would fix the value net faster, at the cost of weakening the policy network. It's not clear that tradeoff is good.
gcp
on 20 Jan 2018
Looks like the bootstrapped net has a much stronger policy than c83e1b6e, but a weaker value net
The problem 7fde81e8's "children" have right now is that it remembers the outcome of all the training games in the current window, as it was trained on them, it has a lot of capacity the previous net didn't have, and there's very few new games.
The value network is totally over-fit:
step 24000, policy=2.64083 mse=0.114482 reg=0.0746186 total=3.17338 (2226.95 pos/s)
step 24000, training accuracy=48.6914%, mse=0.158908
Which is of course fatal:
2018-01-20 20:05 | fab6aa84 VS 7fde81e8 | 0 : 46 (0.00%) | 46 / 400 | fail
2018-01-20 19:34 | 4a987470 VS 7fde81e8 | 0 : 42 (0.00%) | 42 / 400 | fail
I assume this will fix itself when the new data starts weighting more in the training window.
Edit: In case it's not clear why 7fde81e8 itself isn't overfit: it had a lowered MSE weighting. Running the training now with the same data simply undoes that fix. It will need to see enough new data to escape from that problem.
gcp
on 20 Jan 2018
If we incorporate your suggestion now, you would fix the value net faster, at the cost of weakening the policy network. It's not clear that tradeoff is good.
Agree in principle, which is why I originally suggested switching to -v while keeping the number constant. Using -v has a higher impact in late game, while it should affect the policy network during early and midgame less. But it's your call of course...
jkiliani
on 20 Jan 2018
why I originally suggested switching to -v
Let me repeat: "I thought the tests with -v versus -p were inconclusive?"
If it's not conclusive that -v x plays stronger at the same total CPU usage than -p y, I don't see why we should use it. I think that question should be investigated and answered first.
gcp
on 20 Jan 2018
Given that training windows between sessions will overlap a lot, is there then an argument for potentially limiting training with one session to leave enough fresh data for the next, to avoid overfitting?
evanroberts85
on 20 Jan 2018
is there then an argument for potentially limiting training with one session to leave enough fresh data for the next, to avoid overfitting?
What does "session" mean here? Why would you not use all data in a session? What's the point of gathering the data if you are not going to use it?
The procedure is gated on the trained net performing well, we checkpoint at intervals in the training, and we reset if it does not beat the best network at any point. So the failures you are seeing is exactly this control against overfitting at work. The next training iteration will not have any training from the previous one in it. It only does that if it worked.
(The other control against overfitting is to just let the overfit network play games and take in the massive failures as training data too, i.e. the AZ procedure. Doing that now looks like it could put us back an undetermined amount of Elo, as a score of 0 : 46 doesn't even allow calculating it!)
gcp
on 20 Jan 2018
I guess it might be worth pretending that the data from c83e1 and before just doesn't exist for the training window. I'll give that a try.
gcp
on 20 Jan 2018
What's the point of gathering the data if you are not going to use it?
It will get fully used, just in the following sessions. Overtrained data is
potentially worse than no data, but if you leave the data out you end up
with just the data from the very latest best network, not providing much
variety. So you hold some data back for a future session. Results have
shown that on average 256k steps is hardly an improvement on any of the
8-64k step networks anyway, so is the short term gain worth it if it
results in having to wait much longer for the next best?
While the validation protects from using overtrained data, fastest progress
would mean having to wait the least time possible before the next network,
not waiting for a fresh 250k window.
And by session I mean each time you start training with a new window and
from the latest initialised network.
On Sat, 20 Jan 2018 at 20:06 Gian-Carlo Pascutto notifications@github.com
wrote:
is there then an argument for potentially limiting training with one
session to leave enough fresh data for the next, to avoid overfitting?What does "session" mean here? Why would you not use all data in a
session? What's the point of gathering the data if you are not going to use
it?The procedure is gated on the trained net performing well, we checkpoint
at intervals in the training, and we reset if it does not beat the best
network at any point. So the failures you are seeing is exactly this
control against overfitting at work.(The other control against overfitting is to just let the overfit network
play games and take in the massive failures as training data too, i.e. the
AZ procedure. Doing that now looks like it could put us back an
undetermined amount of Elo, as a score of 0 : 46 doesn't even allow
calculating it!)—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/gcp/leela-zero/issues/591#issuecomment-359198473, or mute
the thread
https://github.com/notifications/unsubscribe-auth/AgPB1u98ICQXm6-WC8qUnhV1Baida5gHks5tMkddgaJpZM4RVxWY
.
evanroberts85
on 20 Jan 2018
If you are currently using a really small window, would that not mean that the number of sampled positions per game for the same training step count is much higher? If so, there would be a high chance that 8k steps might be already too much, and additional training steps would just make things worse.
Until the number of 6x128 training games is higher, you might consider testing after 1k or 2k steps already and see if this changes things.
jkiliani
on 20 Jan 2018
About the value being overfit. The way I read code in parse.py, there are 65536 positions read at a time and those are shuffled. There are multiple workers, and each selects a random chunk. But from that random chunk they read every position in order. Does this mean those 65536 positions will contain complete games? If a game averages 200 moves that means there are only 327 unique games in each of those windows. I think this is too far from uniform random sampling over the 250K window that the AGZ paper calls for.
Maybe the chunks themselves are shuffled when they are created from the database? Or maybe this doesn't matter since the mini-batch is 256?
If it does matter either the dataset.shuffle(65536) could be increased, or the workers could select just a few random positions from each chunk and then pick a new random chunk?
killerducky
on 20 Jan 2018
Chunks are batches of games downloaded from the server in order. Unless @gcp is doing something sneaky, I think you are correct. If you are reading all moves from a chunk then you are reading complete games.
roy7
on 20 Jan 2018
In terms of fighting over fitting, with the bigger network, should we maybe go back to 500K games window? So the value network has a lot more information to think about.
roy7
on 20 Jan 2018
@killerducky Very good analysis.
The way i read the AGZ paper, they take the last 500k games and select 2048 moves completely at random for every single training step (mini-batch). Every time 25k new games are generated they move the window by 25k games. They do 700,000 training steps, and move the window 196 times, so on average 3500 training steps of 2048 moves per window.
Each mini-batch of data is sampled uniformly at random from all positions from the most recent 500,000 games of self-play
[AGZ paper]
They also evaluate a network every 1000 training steps, so 700 times in total over the 700,000 mini-batches.
Because it takes 20 window moves before a game is moved out of the window, a single game is present in 20*3500=70,000 training steps. A game is only selected once every 244 mini-batches (500k games / 2048 positions) so on average 70,000/244=287 moves are selected per game.
287 moves/game is close to an average full game (with proper resignation), but because of randomness and birthday paradox, many moves will be selected multiple times, while others are never used.
Still, with this technique, it might be much less likely the network starts to "remember the games", because it is only trained on 2048 completely random moves from completely random games in the 500k game window.
By the way, the 25k window move seems a bit arbitrary, and probably used just to be able to synchronize the training pipeline with the self play pipeline, it is also the point where they swap the new current best in self play.
For us it makes more sense to swap out right away. Possibly it could even make sense to download a new window every time we send a network to the evaluator also. I know we also go trough many more training steps (at least 8k, then incremental up to 500k every 12 hours). I cannot find in the paper if they switch back to the current best for training when they move the window, but for us that also make more sense as we do so many more training steps, so i guess it is another guard against over fitting.
Dorus
on 21 Jan 2018
If it does matter either the dataset.shuffle(65536) could be increased
I already use 1 << 18 on the training machine, FWIW.
gcp
on 21 Jan 2018
Any plan to test if lowering the learning rate is beneficial? If it is still at the initial value, I am definitely sure that it is too high.
isty2e
on 21 Jan 2018
Or maybe this doesn't matter since the mini-batch is 256?
It's 512. The repeats per training batch are low enough that I haven't see much difference from fiddling with the shuffle buffer, but obviously it makes sense to put it as high as RAM allows.
gcp
on 21 Jan 2018
Any plan to test if lowering the learning rate is beneficial? If it is still at the initial value, I am definitely sure that it is too high.
I agree. The next batch will be with the lowered rate, and with an extra upload at 4k steps.
gcp
on 21 Jan 2018
What sort of learning schedule was used for bootstrapping? Was is a high initial learning rate that was gradually lowered, along with moving the window to the more recent games?
About the window, are you currently training only on the bootstrapped networks' games, with the ones from c83e removed? Would it make sense to include those 5x64 games that were not included in the bootstrap training data?
jkiliani
on 21 Jan 2018
Was is a high initial learning rate that was gradually lowered, along with moving the window to the more recent games?
I shrunk the window first, then lowered the learning rate later.
About the window, are you currently training only on the bootstrapped networks' games, with the ones from c83e removed?
I did a run of both, actually. Only newer games did better, though it's hard to say for sure that 1:49 is an improvement over 0:50.
Would it make sense to include those 5x64 games that were not included in the bootstrap training data?
Maybe but it's not all that much.
gcp
on 21 Jan 2018
By "lowered rate" for the next batch, do you mean to the lowest rate or the middle one (a reduction by 10 or 100)?
I am curious on what the results would be if you lowered it drastically and kept the number of training steps limited to the current numbers, presumably you would get a load of trained networks within a small deviation from 50%. The average win-rate would certainly go up (doing nothing in training would achieve that!), but the amount of 55% plus networks that pass the SPRT might go down.
evanroberts85
on 21 Jan 2018
With no training at all, a network should be like 50% against itself right? Does a learning rate of 0 make no changes?
Just as a sanity check you might train a network for 1000 steps with 0 learning rate and see if you still have the same network. If not, is it still 50/50? If not, is there a bug?
And/or try some insanely small learning rate like .00001. Same thing. Do we stay 50/50?
If we do normal training for just 1 step, how much weaker do we get? It should be close to still 50/50 if we only did one step of training... no?
Just some silly "this can't be broken" confirmation tests.
roy7
on 21 Jan 2018
@gcp Is the training stuff in github up to date and in sync with how your training system actually operates? Perhaps I could dedicate a bit of time to experiment with training this week some more myself. Could do some of the things maybe you don't want to mess with, like pull a random example out of a random chunk each time. A lot more file IO for my ssd, but speed of training doesn't seem like our issue if we are testing nets with 256K+ steps already anyway. Maybe "more random" examples would show something useful at 4k or 8k steps, I don't know...
roy7
on 22 Jan 2018
@gcp Is the training stuff in github up to date and in sync with how your training system actually operates?
It's the exact same code, but the parameters are changed as described in this thread.
gcp
on 22 Jan 2018
is it possible to include those training parameters on the matching page as
well? I've seen many people asked many times about this @roy7 @gcp
On Mon, Jan 22, 2018 at 5:21 PM, Gian-Carlo Pascutto <
[email protected]> wrote:
@gcp https://github.com/gcp Is the training stuff in github up to date
and in sync with how your training system actually operates?It's the exact same code, but the parameters are changed as described in
this thread.—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/gcp/leela-zero/issues/591#issuecomment-359366311, or mute
the thread
https://github.com/notifications/unsubscribe-auth/ABHWLn-dj-Nve1M3m2QatnB9q3oPWuSjks5tNFMzgaJpZM4RVxWY
.
bood
on 22 Jan 2018
Not sure that makes much sense. What would you put for 7fde81e8? The information is also not that useful really.
gcp
on 22 Jan 2018
I guess what I mean is, so I don't risk missing what your latest changes are or how/where you made those changes in the code, could you do a commit to the training tools to match them to your current "normal" (not testing) state? Then if I'm going to do some training of my own and only change one thing (say how we pull random examples, or a super low learning rate, or whatever), at least I'm starting from the exact place you are.
roy7
on 22 Jan 2018
Again, there are no changes in the code except changing the parameters as described above. If you don't read the thread you will get it wrong regardless of what I commit because I am trying different things - there's no precedent for bootstrapping!
gcp
on 22 Jan 2018
I pushed an update:
https://github.com/gcp/leela-zero/commit/b8130095d84713e10fb15dc0dbd17e2e411311a0
Right now I'm pushing networks both with a full 250k window and a "only new networks" window, and 0.005 and 0.0005 learning rates. Those are my best guesses at something that hopefully works.
gcp
on 22 Jan 2018
Uhm, why not 0.00005 too? It may be too low since the network is larger and pretty new, but the real effect of that will be made clear by tests.
isty2e
on 22 Jan 2018
Ah ok. I guess I was gun shy to try training again, back the last time I did it, there was some setting that was different in github than your training machine. :) I don't recall the specifics any more.
What I'm mostly interested in is, once the Net2Net stuff is confirmed working as expected, is seeing if one of those networks expanded from 5x64 can beat 5x64 more easily than trying to self-train off of the bootstrap 6x128.
roy7
on 22 Jan 2018
Uhm, why not 0.00005 too?
Not worth trying at this point. Google used that when the learning had totally flat-lined, and when we used it for 5x64 we didn't even get a jump up (we did get the greatly reduced learning speed).
I really don't get this obsession with low learning rates FWIW. You use those to squeeze the very very last bit out of a network. If we're at that point for 6x128 already, it's a failure.
gcp
on 22 Jan 2018
Google used that when the learning had totally flat-lined
I did not think there was any evidence for that, am I missing something?
Also it seems like you consider lowering the learning rate as something like the last resort, but my claim is that there is always an optimal learning rate, and when the number of training steps is fixed this is especially easier to find out. If lowering the rate leads to a lower loss for 128k steps for example, then it should be adopted, and if we do not know what would happen exactly, why not test it? Also Deepmind changed the training rate in powers of 10, but we can tune it in a finer basis, like halving. At any rate, essentially my claim is not that we should lower the learning rate, but that it is always beneficial to test lower training rates to find out which is the optimal one.
isty2e
on 22 Jan 2018
@isty2e When you say "lower loss for 128K steps for example", do you mean lower policy loss, lower MSE, or lower W/L rate in match testing vs prior network?
roy7
on 22 Jan 2018
Right, if lowering the learning rate only leads to...a better overfit, it's not useful. If it leads to an improvement ("a jump") but then slows down the rest of the run by a factor 10...eh...
The number of total training steps we are going to run is not known in advance. Just the one for this batch of training data.
Typically, you use the largest learning rate that won't cause divergence, run for as long as loss drops, and only then lower the learning rate. But "as long as loss drops" is tricky with the training window still filling.
gcp
on 22 Jan 2018
@roy7 A lower total loss, since that is a quantity easy to monitor during training, which also does not require much computational cost.
@gcp Theoretically, each cycle is just a supervised learning step. We just train the network to fit the policy to match one from the ANN+MCTS and values to fit the game results. While we sometimes encounter better performing network during the course of training, in principle lowering the loss is not supposed to be bad. Thus for a given training set, I suppose there is no tricky part. We just need to run tests on a regular basis. And I cannot agree to "slows down the rest of the run by a factor 10" for following reasons:
- The loss does not decrease linearly with respect to the training steps.
- The network can move smoother in the weights-loss manifold when the learning rate is lower.
- Oscillating networks (i.e., networks with higher loss due to a high ) can slow down or stall the run.
- The factor of 10 is somewhat arbitrary here. As I said, we can always take a less value than 10.
- As the network becomes stronger, it is more likely to lose rating under an increment of weights, since in the weights space rating is likely to be convex.
- If a slower convergence is a concern, one can always adopt a higher learning rate for first 1k or 4k steps. Of course, the number of such steps and the corresponding learning rate should be determined by tests, which do not have to be too costly or strict.
The learning rate is the arguably the most important hyperparameter once the ANN architecture, optimization method and batch size are fixed. Thus I really wish it to be determined in a systematic way, based on experiments.
isty2e
on 22 Jan 2018
If a slower convergence is a concern, one can always adopt a higher learning rate for first 1k or 4k steps. Of course, the number of such steps and the corresponding learning rate should be determined by tests, which do not have to be too costly or strict.
I have wondered about this myself a few times... would it not combine "the best of both worlds" to use a higher learning rate at the beginning of each training set, and then gradually lower it with additional steps?
jkiliani
on 22 Jan 2018
8k steps at the moment already produces drastic change and hardly takes any
time to train, so even if convergence was 10 times slower it would still be
more than fast enough, so I see no point in having a higher training rate
just for the first few thousand steps.
On Mon, 22 Jan 2018 at 19:23, jkiliani notifications@github.com wrote:
If a slower convergence is a concern, one can always adopt a higher
learning rate for first 1k or 4k steps. Of course, the number of such steps
and the corresponding learning rate should be determined by tests, which do
not have to be too costly or strict.I have wondered about this myself a few times... would it not combine "the
best of both worlds" to use a higher learning rate at the beginning of each
training set, and then gradually lower it with additional steps?—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/gcp/leela-zero/issues/591#issuecomment-359535581, or mute
the thread
https://github.com/notifications/unsubscribe-auth/AgPB1sZn4CF_Eg8viryGntCvNHgr8uEEks5tNOAxgaJpZM4RVxWY
.
evanroberts85
on 22 Jan 2018
Watching failed nets on the graph, I have a good feeling. They seem to gradually go up, or am I wrong?
Marcin1960
on 22 Jan 2018
I see a lot of advice/opinions on training (myself included!). Are there more people willing to take the time to actually try some of these? gcp is doing an outstanding job but he's just one person.
This is a large project, and it requires a lot of resources. GPU resources is the obvious one and I'm glad to see the dedication people have running their autogtp clients 24x7. But I believe the bottleneck is still software development time, not GPU time.
Everything about this project is open and available for anyone with the time and skills to help with the software development.
killerducky
on 22 Jan 2018
39% win rate was a ray of sunshine after all these 0/1 wins.
roy7
on 22 Jan 2018
Maybe there's just too much conflict between the old 5x64 and new 6x128 training data and once the 6x128 training data starts to fill the window, we'll see some good progress.
roy7
on 22 Jan 2018
@killerducky "But I believe the bottleneck is still software development time, not GPU time.
Everything about this project is open and available for anyone with the time and skills to help with the software development."
I will try to spread the word in the IT places
Marcin1960
on 22 Jan 2018
@killerducky For the discussion I am involved, here are the reasons:
- He is already testing 5e-3 and 5e-4, so adding another learning rate is not a dreadfully costly task.
- If a nearly optimal learning rate should be found with regular experiments, it is better to be done (preferably automatically) on the server side. It is both inefficient and not systematic to do this waiting for someone to find out.
- Some experiments are extremely costly for a single person to perform. For example, to come up with counter-examples against gcp's claim that "lowering the learning rate ... slows down the rest of the run by a factor 10", one needs to run everything including self-plays for at least a few cycles. This is practically impossible, and I believe discussion is more suitable than experiments here.
- The fundamental disagreement on some issues can only be resolved by discussion.
isty2e
on 22 Jan 2018
I don't mean to discourage discussion, only to encourage more people to do code changes and tests.
It's true that it is costly for a single person to setup the training flow. But once that flow is setup, then it will also be almost as cheap for that person to do regular experiments as for gcp. So if we can get three people to pay the initial setup cost, then those three people can start doing additional experiments with small additional cost.
You pointed out a few examples that would be cheap for gcp to try. But any change, no matter how small, would probably take a few hours for him to do. And there are so many people in here suggesting so many "just change this one thing" (again, myself included!).
As an example, look at what happened for #696. Someone suggested a change. I thought it looked promising and since I am setup to run ringmaster tests etc. I decided to run more tests on it. Even though the change is 1 line of code, it still took me almost an hour to setup the test, collect the results, and post them, so it is not free! It took much more time for me to do more analysis on alternatives etc. Once statistically relevant results were shown, gcp immediately started a more comprehensive tuning process.
If I had the training flow setup, I could just as easily pick the ideas in this thread I thought were promising and test them quickly. I hope to get it setup later but I'm busy with other things now.
killerducky
on 22 Jan 2018
The fundamental disagreement on some issues can only be resolved by discussion.
Data. Data is the only thing that can resolve any disagreement.
Dorus
on 22 Jan 2018
@killerducky I do agree that people coming up with suggestions are also strongly encouraged to test them. I have no problem training a network or two, or running matches between different networks or settings, though it will take some time. However, when it comes to self-plays, it is just not feasible. As I said, to argue against gcp's aforementioned claim, I expect at least 100k self-play games to be played with networks trained by myself (and to be fair, gcp also doesn't have the concrete supporting data).
@Dorus Well, there are always interpretation and hypotheses involved. Not always.
isty2e
on 22 Jan 2018
You can also send networks that you train to roy or gcp and I'm sure they'd be happy to test it with distributed testing.
wnwen
on 22 Jan 2018
@WhiteHalmos That will surely work for most of the cases, but not for this one unfortunately. To verify or disprove the statement that "lowering the learning rate ... slows down the rest of the run by a factor 10", a completely different run, if not two, is required. One should train networks with a lower learning rate, and again generate self-play games with the network on his own, then train again... Moreover, this should be done for at least a few generations if not more to determine if the run is actually slowing down (by a factor of 10) or not.
isty2e
on 22 Jan 2018
@isty2e ok how about this: Train a network with your preferred learning rate etc, run a match of ~400 games to prove it is better than the current. That should take about 1-2 days. Give it to gcp. Assuming he takes it, we would quickly generate many self-plays on that network. Assuming the learning rate is key, the current method will fail to produce better networks and we will get our 100k self-play games on your method.
killerducky
on 22 Jan 2018
@isty2e And if I may do a bit of advertising as well: Make a quick test for your trained nets at lower playouts first. If they flunk at 50 playouts, you don't have to bother testing 1600 playouts. I think I have tested the concept enough to say this much, but it's up to you if you want to try it.
jkiliani
on 22 Jan 2018
@killerducky First let me summarize what is the deal here.
- I do not necessarily claim that a low learning rate is better. What I claim is that an optimal learning rate exists and this should be found regularly and systematically, since it is such an important hyperparameter.
- Suppose a lower learning rate eventually led to a better performing network. My and gcp's interpretation will be different. I take it as the result of finding a more desirable learning rate, while gcp would think that is the last resort, squeezing out of the network.
- Assume another situation: After lowering the learning rate, suppose the rating growth has slowed down after a few cycles. I will consider it is due to either a too high learning rate or the network capacity issue, so I will suggest to quickly test if a lower learning rate is any beneficial, while gcp will wait for the process to almost completely stall out.
- These different points of view comes from a difference in interpretation and thoughts.
Given those, I am not sure if the suggested experiment would help. Even if a lower learning rate led to a better network, there will be still a fundamental difference in how to interpret it. I think the important thing here is to discuss and fill up the gap between our thoughts.
@jkiliani I have been tracking the issue and the results indeed seem useful for fast screening. Unfortunately the bottleneck is self-play step, if I am to do some experiments concrete enough to prove or disprove the aforementioned statement.
isty2e
on 23 Jan 2018
I see that a lot of 6x128 network fail the SPRT test. Wouldn't be better to let them train a bit more? Since now there are much more weights to adjust during training 128K or 256K may not be sufficient to get to a good network.
marcocalignano
on 23 Jan 2018
(Correct me if I am wrong) Fixed learning rate + varied training steps = varied learning rate + fixed training steps, in terms of training/learning effectiveness. So if we think learning rate was too high before, there should be no way for training steps to be not enough.
billyswong
on 23 Jan 2018
You can't replace 100 steps at lr=0.01 by 1 step at lr=1.0.
gcp
on 23 Jan 2018
I see that a lot of 6x128 network fail the SPRT test. Wouldn't be better to let them train a bit more? Since now there are much more weights to adjust during training 128K or 256K may not be sufficient to get to a good network.
I can try that but it will take a bit (obviously). There's no clear pattern of scores going up with more training though.
gcp
on 23 Jan 2018
Maybe there's just too much conflict between the old 5x64 and new 6x128 training data and once the 6x128 training data starts to fill the window, we'll see some good progress.
I hope so. Current results aren't very encouraging.
If this bootstrap turns out to be a failure, we should consider adjusting the server to always take new networks and try the AZ (rather than AGZ) style where tests are only used for the graph, not for promotion.
gcp
on 23 Jan 2018
FWIW I'll try to get all the training data up overnight. I have been a bit busy merging pull requests as a lot of good stuff keeps coming in.
gcp
on 23 Jan 2018
@gcp, @roy7 I'd like to do an experiment: Can we do one training run (probably 128k steps) and sample it really often, like every 2k steps, uniformly? Since this would obviously be a lot of testing, I'd like to screen these networks at low playouts first and then repeat at higher playout number for those who do well.
This is not just about finding a new net, I would also be interested to investigate things like the correlation of the win rates of nets sampled at step counts close together, for different playout counts if possible. I assume the reasoning between sampling at exponential step counts is to sample at similar steps in training accuracy or loss functions? I would like the possibility to confirm that we're not missing good nets by doing that...
Since I don't have a computer capable of running training, I'd need an archive of nets for this from one of you, I can only work with the data.
jkiliani
on 23 Jan 2018
It's fairly easy to do that but it's going to generate quite a bit of spam on the match table and graph.
gcp
on 23 Jan 2018
I can also just generate those networks and not queue them, but point you to where they are in the /networks dir.
gcp
on 23 Jan 2018
That would be great, thanks... the file name would indicate the step counts as usual, correct?
jkiliani
on 23 Jan 2018
Yeah. Give me a day or so, I'll run this on the backup machine.
gcp
on 23 Jan 2018
Is there a qualitative difference between the training sets 3.04M, 3.05M, 3.07M and 3.09M? (apart from the number of new self-play games obviously) For example, did some of these training sets include only 6x128 games, while others included 5x64 games?
It's just curious that the best training set after bootstrapping so far was 3.05M with one 40% score and several in the 15-20% range, while 3.09M is disappointing so far, even with (in theory) better data available...
jkiliani
on 23 Jan 2018
I think the problem is that though the current 6/128 network has the strength stronger than the strongest 5/64 network, its inner organization is very different because it's trained with a different loss function (policy loss + 0.1 * value loss instead of policy loss + value loss).
Is there even any proof that the current 6/128 network is better than a random network when it's being trained on new data with the loss function changed back to policy loss + value loss from policy loss + 0.1 * value loss?
RavnaBergsndot
on 23 Jan 2018
Is there even any proof that the current 6/128 network is better than a random network when it's being trained on new data with the loss function changed back to policy loss + value loss from policy loss + 0.1 * value loss?
Aside from being about 6800 Elo stronger, you mean?
gcp
on 23 Jan 2018
For example, did some of these training sets include only 6x128 games, while others included 5x64 games?
Yes, but if you are looking for any patterns, they aren't there. The configuration that had a good result at 39% (IIRC used all games) failed as badly as the others in the next run.
gcp
on 23 Jan 2018
Aside from being about 6800 Elo stronger, you mean?
I don't think it would be 6800 Elo stronger than a random network after both are trained on new data.
My point is that in our 5/64 training pipeline, the loss function is always kept the same, so new data won't disrupt the network as severely as the 6/128 one, which was initially trained with a different loss function.
Even in the net2net paper, in which they keep the loss function the same, the student networks don't improve immediately when it's made, in contrast, they all have huge initial dips on the prediction accuracy. Our case is worse than theirs, so without sufficient new data and training steps, the dip should be expected.
RavnaBergsndot
on 23 Jan 2018
@gcp Some of us are starting to play around with it, but if 6x128 keeps struggling for a bit might you want to try generating a 6x128 from net2net off the prior 5x64 and see if you can train one of those into a winner?
roy7
on 23 Jan 2018
@gcp So... What is going to happen to the learning rate? I think I have listed my arguments in a reasonable fashion, and I would like to ask for your opinion, since you are usually the one who makes decisions.
isty2e
on 23 Jan 2018
If this bootstrap turns out to be a failure, we should consider adjusting the server to always take new networks and try the AZ (rather than AGZ) style where tests are only used for the graph, not for promotion.
Mentioning Alpha Zero, is the big change just the "no-testing"-approach? The use of temperature = 1 for the whole game also sounds like a major change to me, which lowers playing strength a lot, but not the quality of the policy training data. But would it lower the value head training data a lot, because of all the induced blunders?
In either case, both the no-testing change and the t=1 change, along with lowering playouts to 800, suggests to me that diversity and quantity of training data may be more important than quality (i.e. playing strength).
jkiliani
on 23 Jan 2018
But would it lower the value head training data a lot, because of all the induced blunders?
I really wonder if this is true. I just realize this but... AGZ is known to play slightly better in endgame than AGM. AGM would insist on 0.5 point wins, but AGZ would usually go for slightly better margins.
With the more random move picking, that makes sense. On a 0.5 point game AGM would give 100% win near the end, AGZ would score worse on 0.5 point games compared to 1.5 point games, because blunders are more likely to lose on a 0.5 point game.
Also even with high temperature, doesn't the MTCS still allow to make bad moves (a lot less) likely? With that the network would be forced to get strong enough to eliminate blunders all together instead of making them less likely.
As for the AZ method: I predict switching to it would result in weaker net on the short term, but as long as training parameters are right, it should eventually improve. We can still make the latest "new style net" play against the current best and see how long it takes to get stronger (if at all).
Dorus
on 23 Jan 2018
Performance still seems to fall of a cliff at the beginning of training, with little chance to recover. d28b5261 trained with just 4k steps won only 4.1% of its games. Surely learning rate is still too high, has anyone yet tried setting it much lower?
evanroberts85
on 23 Jan 2018
I have a setup to try training things with the data from 46ff. I could change learning rate in tfprocess.py from 0.05 to something much lower? The file does have this comment:
# You need to change the learning rate here if you are training
# from a self-play training set, for example start with 0.005 instead.
So maybe even using the default 0.05 is too high? I could try 0.0005 and stop after 8k steps and see if the new net is similar to the old net or unable to win a game.
roy7
on 23 Jan 2018
Earlier there was talk about the shuffle buffer and correlation of positions in mini-batch. I did some simulations of the correlation.
With the values @gcp gave earlier (buffer size 2^18 and batch size 512) I simulated that on average in one mini-batch 237 positions are such that they are the only positions from their game in the current mini-batch. Rest of the positions are such that there is more than one position from the same game. On average 181 positions are such that there are two positions from the same game in the mini-batch. Full distribution below:
[237.717, 180.716, 70.398, 18.792, 3.895, 0.384, 0.007, 0.0, 0.0, 0.0]
With the default buffer size of 65536 the distribution is much worse and majority of the positions have at least one more other position that come from the same game:
[25.806, 73.99, 109.884, 110.62, 86.505, 54.648, 28.931, 14.36, 5.553, 1.22]
If the shuffling was perfect then with 300k game window we would expect that practically all positions would be from different games. Is the correlation of positions in mini-batch significant? I have no idea.
Method:
First I sampled 50 self-play games on the zero.sjeng.org to find out the distribution of the game lengths. Currently average game length is around 387 moves, by the way. Then I wrote some Python code to simulate the shuffling using the sampled game length distribution. You can find it here: https://gist.github.com/Ttl/ccb59df1af07ec274ccd5ad4ed12435e
Ttl
on 23 Jan 2018
What's the proper way to have training use less GPU ram that won't break things like batch sizes, learning rates, and so forth? It'll use almost all of the memory currently which is fine if I wasn't running ranked bots trying to play Go. ;)
roy7
on 23 Jan 2018
I could try 0.0005 and stop after 8k steps and see if the new net is similar to the old net or unable to win a game.
Definitely worth a go.
evanroberts85
on 23 Jan 2018
I trained a supervised 20x256 network from the 1.5M Tygem games and played it against 5x64 net (574810) with both having 2 seconds to play. 20x256 net did around 500 playouts per move and 5x64 did around 4400 playouts per move. The 20x256 net won. It almost didn't because it could not see that the big black group in the middle was dead. Neither of the networks saw that so at some point 574810 predicted 100% win. As soon as white killed the center group the win percentage of black went from 100% to 0% and black resigned.
Net was trained with learning rate 0.05 for 72000 steps (did not think to change learning rate after changing steps size until this point) and 0.01 from that point to 424000 steps with batch size of 64.
Net: https://drive.google.com/open?id=1gTV5XpmXzgopqPLTUjJSPAVwiT-GhM5s
zediir
on 23 Jan 2018
@zediir Can you try it against our new winner d9a5ed48 instead of the 5x64? :)
wnwen
on 23 Jan 2018
Meantime out of nowhere the new best has come. Which passes 7000 by the way! Huurray!!!
dzhurak
on 23 Jan 2018
or someone did have some fun with adjusting the learning rate :P
CheckersGuy
on 23 Jan 2018
I have followed this entire long thread since the start, but I'm having trouble putting together the full story of the change to six blocks. Some changes which were made are non-obvious or even entirely absent from this thread and commit history.
Here is the rough breakdown of so far:
1) Five-block run declared over.
2) Six-block networks trained, and two are promoted same day (7fde81e8 wins overall).
3) Long and unprecedented period with 20+ networks generated, each failing with lower than <5% winrate.
4) Sudden change of winrate, 20+ networks now generated with higher than >5% winrate, consistently.
5) Now d9a5ed48 is promoted with 67% winrate, and new sister f0d5f0ab has roughly 50% winrate vs. d9a5ed48 as well.
This brings up several unanswered questions that I've only been able to fill in bits and pieces of the answers to:
- A) What changed between five- and six-block network creation?
- B) Why did so many six-block networks have <5% winrate against 7fde81e8?
- C) What changed suddenly to allow >5% winrate against 7fde81e8?
- D) Why do new winner d9a5ed48 and new sister f0d5f0ab appear on the same day?
 FFLaguna
on 24 Jan 2018
FFLaguna
on 24 Jan 2018
Here are some of the bits and pieces I can fill in to the questions above, hopefully others can help to build a fuller accounting of what happened. This might be important for figured out what did and did not work, as well as what factors we should consider in the future.
- A) What changed between five- and six-block network creation?
Winograd optimizations and hash revisit/reuse were both implemented. Five blocks moved to six blocks.
128 and 256 filters tested, settled on 128 filters.
Window size may have been changed. What from, what to? Were there any unusual window sizes used for the two initial six-block winners from back on Jan. 20th? (7fde81e8 and ed002cf3)
Learning rate was also "reset". Was it really? What to? What other changes were made to learning rate along the way?
- B) Why did so many six-block networks fail with <5% winrate against 7fde81e8?
I don't know.
- C) What changed suddenly to allow >5% winrate against 7fde81e8?
I don't know. Learning rate and game window changes? Other issues?
- D) Why do new winner d9a5ed48 and new sister f0d5f0ab appear on the same day?
I don't know. Learning rate and window changes again? Interesting to note these two new networks happen to come after ~237k selfplay games from the six-block network.
FFLaguna
on 24 Jan 2018
I'm speculating, but I believe since the 6x128 we have running loose is a supervised trained one with different understanding of things, the prior network game data and net network game data would result in conflicting policies in how to play the game. Once the # of new network only data got big enough (or training window reduced to ignore prior network game data), the network can learn from only its own games which will make sense to it.
Net2Net wasn't ready when we first dove into the 6x128 waters. I do still want to know how well a 6x128 Net2Net would have done starting from the 5x64 data though. It might have avoided these growing pains since they start from identical understanding of the game (same policies/weights/etc).
roy7
on 24 Jan 2018
Roy7, do you know if the parse.py/tftraining.py somehow support taking just a (net2net) network and continuing on that with a dataset?
I know i can continue training by specifying the model from where the training was interrupted, but what if its a completely new net like a net2net one?
MaxMaki
on 24 Jan 2018
@MaxMaki Yes indeed, that's why people worked on it. :) You do the Net2Net conversion like:
python net2net.py 1 64 46ff
Where 46ff is your old network file and you want to add 1 layer and 64 filters (or whatever). Then you convert the net network file into a model the trainer can use:
python net_to_model.py 46ff_net2net
And then resume training with that as your model.
./parse.py train_46ff4b94 leelaz-model-0
roy7
on 24 Jan 2018
It is hard to believe that the prior 5x64 network data hindered the
learning of the new 6x128 network. If anything the extra variety in play
should be a benefit.
A sudden leap just because of an extra 10k or so training games is hard to
understand without other training parameters having also been changed, lets
see what GCP has to say.
On Tue, 23 Jan 2018 at 23:30 Jonathan Roy notifications@github.com wrote:
I'm speculating, but I believe since the 6x128 we have running loose is a
supervised trained one with different understanding of things, the prior
network game data and net network game data would result in conflicting
policies in how to play the game. Once the # of new network only data got
big enough (or training window reduced to ignore prior network game data),
the network can learn from only its own games which will make sense to it.Net2Net wasn't ready when we first dove into the 6x128 waters. I do still
want to know how well a 6x128 Net2Net would have done starting from the
5x64 data though. It might have avoided these growing pains since they
start from identical understanding of the game (same policies/weights/etc).—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/gcp/leela-zero/issues/591#issuecomment-359966035, or mute
the thread
https://github.com/notifications/unsubscribe-auth/AgPB1lJfj6TvEZOGJCeR53L3PyNWZLKCks5tNmmygaJpZM4RVxWY
.
evanroberts85
on 24 Jan 2018
@evanroberts85 But remember we aren't trying to learn just a value network or a move prediction like from pro grames. We're trying to learn our own MCTS results. And those results change if the network weights change. So then we have conflicting examples of what to do in many situations, and the new network has to try and learn to predict the MCTS results from two separate networks.
Maybe I'm blowing it out of proportion, I don't know.
roy7
on 24 Jan 2018
Thanks roy7! The net_to_model was what i was missing :)
I've been toying around with training new larger nets from the match games and other small experiments.
MaxMaki
on 24 Jan 2018
To use it you need to clone https://github.com/Ttl/leela-zero and change to net2net branch, or import his net2net branch into your local git setup.
roy7
on 24 Jan 2018
Thanks, already have it cloned and already tried it as well. Seems to work!
MaxMaki
on 24 Jan 2018
@evanroberts85 Even during the slow growth phase of 5x64, I've frequently seen that some training sets were much more successful than others. I have no good explanation why, could it be that parsing sometimes batches the sampled positions in a way that helps the learning process, and often not?
jkiliani
on 24 Jan 2018
You know, if you just look at all eval matches from the last few days, and ignore any parameter tweaking that has been done during training, you can still see that:
2.9-3.0m game networks had around 6200 elo +/-100
3.05m game networks had around 6500 elo +/- 200
3.09m game networks have around 6700 elo +/-300
The curerent (2) nets are just outliers on the current training set, but that we get 2 strong nets in this training set is no surpise at all. In fact, the next 20k games should give another similar increase if we draw this line forward/upwards :)
Dorus
on 24 Jan 2018
I'll triple down and suggest when incremental networks happen, the new data is similar to old data, and training can refine towards another incremental network. When a breakthrough understanding happens, new data is going to be different from old data in some board states, causing training confusion until the old data flows out of the window.
By the same token, I suspect any improvements we make to LZ (MCTS tree search, etc) that change the shape of the dump_training tree search results target, will cause a similar "confused by conflicting data" delay until the pre-change examples leave the window.
Because if old network says "Search 99% A" and new network says "Search 99% B", it'll try to learn "Search A and B 50/50" which may result in a weaker move than either. As old network data leaves, Search B will move higher towards 99%.
roy7
on 24 Jan 2018
@Dorus - but you can not ignore parameter tweaking, GCP lowered training rate a couple of days ago which saw a marginal improvement but still the newly trained networks were a long way from passing, other than not there has been no real pattern just the standard noise - until now.
evanroberts85
on 24 Jan 2018
I wonder if there's a way to quantify this stuff. Take a set of 10K board positions, fetch a heat map from each network, compare the heatmaps and record the MSE? The more similar the heatmaps, the more similar the networks think.
roy7
on 24 Jan 2018
@evanroberts85 If we get another 150 elo increase in the next 20k games, i'm going to claim we can ignore parameter tweaking :)
Roys explanation makes a lot of sense and explains why we started off at -500 elo on the first few new networks. Probably the current high speed gain will drop off when all old games have turned out of the window. On the other hand, we now generate higher quality data, so if we get 2 more networks that jump 150 elo, that might give us enough quality increase to make the next full window gain more too.
Dorus
on 24 Jan 2018
@gcp
Right now I'm pushing networks both with a full 250k window and a "only new networks" window, and 0.005 and 0.0005 learning rates. Those are my best guesses at something that hopefully works.
We await with excitement which combination actually won. ;) If I had to bet, I'd say "only new networks" window.
roy7
on 24 Jan 2018
@MaxMaki For your testing you might want to bring in https://github.com/gcp/leela-zero/commit/b8130095d84713e10fb15dc0dbd17e2e411311a0 changes. Those aren't in the net2net branch from @ttl.
roy7
on 24 Jan 2018
Should we have any concern that v10 and v11 provide different MCTS results because of the tree-reuse code and other changes in v11? Should we sometime soon require upgrade to v11?
roy7
on 24 Jan 2018
I agree, maybe not a big problem but keep the same setting for all self-play games is always the right thing to do. I think we should force an update ASAP.
I also remember someone said that AGZ does not use tree reuse in self-play? but I cannot find the information in the papers. Can any one confirm? This could speedup the self-play too.
bood
on 24 Jan 2018
I don't know why it wasn't entering my mind that if conflicting data to learn is an issue, then even using "only latest network" is misleading right now since v10 and v11 are mixed.
Some simple tests tonight using network 46ff4b94 and train_46ff4b94 data only.
net2net 6x128 is even with original 5x64 network in a -p 50 face off.
Default settings (before @gcp's training changes) and quick -p 50 validation, the net2net 6x128 version lost 17-0 to original network after 8k steps.
Bringing in only https://github.com/gcp/leela-zero/commit/b8130095d84713e10fb15dc0dbd17e2e411311a0 to the net2net branch, fresh try after 8k steps, 27-1 sprt fail at -p 50
May as well go big or go home. Dropped learning rate from .05 to .00005. 8k steps. As you'd expect the policy, mse, and req numbers barely move during training although accuracy was higher at 45%. -p 50 validation shows:
The first net is better than the second
46ff v leelaz-m ( 151 games)
wins black white
46ff 94 62.25% 51 61.45% 43 63.24%
leelaz-m 57 37.75% 32 38.55% 25 36.76%
83 54.97% 68 45.03%
Which at least isn't heading towards 0% as fast as higher learning rates. ;)
Same as above continued more steps, 16000 total. At 61-61 I'm stopping it. So, hey, that's progress? We're back to even! (Maybe not statistically significant, but good enough for me. I was curious if more training would push us further towards 0 like the higher learning rates do.)
On to 24000 steps. New network wins this time!
The first net is worse than the second
46ff v leelaz-m ( 135 games)
wins black white
46ff 56 41.48% 28 41.18% 28 41.79%
leelaz-m 79 58.52% 40 58.82% 39 58.21%
68 50.37% 67 49.63%
I should test this at -p 1600 overnight but I need to get my OGS bots online. Still I can't resist... 8K more steps! 32000 total steps. 1st net led first like 300 games, then 2nd net surges from behind. Still though, very similar. Would need -p 1600 test to see if it really has any meaning.
The first net is worse than the second
46ff v leelaz-m ( 344 games)
wins black white
46ff 166 48.26% 84 48.28% 82 48.24%
leelaz-m 178 51.74% 90 51.72% 88 51.76%
174 50.58% 170 49.42%
After all this I just realized... I'm using /next client. So v11 tree-use and other changes apply, but I'm using networks trained from v10. So the MCTS suggestions coming from the NN won't actually match what the MCTS decides/wants to do during play. Maybe this doesn't matter, maybe it has an effect. I don't know. For best/proper play should the NN policies suggested match the actual MCTS operation in the search? :)
roy7
on 24 Jan 2018
Perhaps my question is naive, but still bothers me:
6a99f1ec VS d9a5ed48 | 23 : 48 (32.39%) | 71 / 400 | fail
f0d5f0ab VS d9a5ed48 | 216 : 193 (52.81%) | 409 / 400 |
d9a5ed48 VS 7fde81e8 | 276 : 166 (62.44%) | 442 / 400 | PASS
7262155a VS 7fde81e8 | 8 : 40 (16.67%) | 48 / 400 | fail
Before and after win rates are low.
My question, what would happen if after such peaking appeared,
extra tests were inserted, for example in addition
around the best d9a5ed48(16K) additional 12, 14, 18, 20 were run? Would a better net net be
hidden there?
Marcin1960
on 24 Jan 2018
In either case, both the no-testing change and the t=1 change, along with lowering playouts to 800, suggests to me that diversity and quantity of training data may be more important than quality (i.e. playing strength).
I think there's some indications, but note that they had to find suitable parameters for 3 games at once.
For example, t=1 for the entire game instead of the first 30 moves may have a much bigger impact for games with a small branching factor. Same for playouts.
gcp
on 24 Jan 2018
@gcp So... What is going to happen to the learning rate? I think I have listed my arguments in a reasonable fashion, and I would like to ask for your opinion, since you are usually the one who makes decisions.
Nothing until it stalls. I've explained why I think lowering before it is required is a serious mistake, and from the following I think you understand why experimenting with it just doesn't work:
"Even if a lower learning rate led to a better network, there will be still a fundamental difference in how to interpret it."
i.e. you would say it's because it's a "better" learning rate, and I would lament the fact that we've thrown away all hope of a serious improvement in order to get a singular minimal gain.
Experience from SL says that you use the largest learning rate that does not diverge until learning stalls, and then drop. I see no convincing argument to do this differently, and no indication the original AGZ run was done differently.
Yes, if you have the resources to do a full hyperparameter search for the entire experiment, you can search for the ideal rate and schedule. This is not possible here.
gcp
on 24 Jan 2018
Is the correlation of positions in mini-batch significant? I have no idea.
Note that the 8-fold symmetries play a factor here too.
gcp
on 24 Jan 2018
I've explained why I think lowering before it is required is a serious mistake
And I think I presented some counterarguments against it...?
experimenting with it just doesn't work
If we talk about the loss, then it should work. By comparing the loss values for a few learning rates, we can both detect an oscillation (due to a high learning rate) and a slow convergence (due to a low learning rate), leading us to a better learning rate. Also I think my argument that such an important hyperparameter should be determined by experiments still holds.
isty2e
on 24 Jan 2018
A) What changed between five- and six-block network creation?
Winograd optimizations and hash revisit/reuse were both implemented. Five blocks moved to six
blocks. 128 and 256 filters tested, settled on 128 filters.
The changes you mention have not much effect on the learning (tree reuse might improve the quality of data bit, but probably not fundamentally). Some 10x128 trained from the 5x64 data were tested but they weren't good.
Window size may have been changed. What from, what to?
As explained in the thread, the window was always 250k, but I tried excluding the networks that
7fde81e8 was trained from. (Which means the window starts "empty").
Learning rate was also "reset". Was it really? What to? What other changes were made to learning rate along the way?
Described in thread. The starting value is 0.005 and the next one is 0.0005. Both were tried.
As to what makes some networks good and others not, nobody knows either.
gcp
on 24 Jan 2018
By comparing the loss values for a few learning rates, we can both detect an oscillation (due to a high learning rate) and a slow convergence (due to a low learning rate), leading us to a better learning rate.
If you have a window of 250k games from a certain set of networks, and you add 10k new ones from a new network, what do you expect to happen with the loss?
(The learning rate has no bearing on this question. It is not an SL setup with a fixed training set!)
gcp
on 24 Jan 2018
A sudden leap just because of an extra 10k or so training games is hard to
understand without other training parameters having also been changed, lets
see what GCP has to say.
It's hard to understand, but exactly the same thing has happened before?
gcp
on 24 Jan 2018
If you have a window of 250k games from a certain set of networks, and you add 10k new ones from a new network, what do you expect to happen with the loss?
What I am suggesting here is to train with exactly the same training set. I am not suggesting to do this for every training window, but rather once a week or so. If the time consumption is a concern, it may be terminated at 64k steps.
isty2e
on 24 Jan 2018
We await with excitement which combination actually won. ;) If I had to bet, I'd say "only new networks" window.
Full window, 0.0005. That also gave the 38% one earlier.
gcp
on 24 Jan 2018
So v11 tree-use and other changes apply, but I'm using networks trained from v10. So the MCTS suggestions coming from the NN won't actually match what the MCTS decides/wants to do during play. Maybe this doesn't matter, maybe it has an effect.
I don't think this matters at all. The tree search is more efficient, it's not making different conclusions.
gcp
on 24 Jan 2018
It's hard to understand, but exactly the same thing has happened before?
I mean it's literally what happened with the first post of this thread.
gcp
on 24 Jan 2018
Performance still seems to fall of a cliff at the beginning of training, with little chance to recover. d28b5261 trained with just 4k steps won only 4.1% of its games. Surely learning rate is still too high, has anyone yet tried setting it much lower?
2018-01-23 22:10 | d9a5ed48 (16k steps) VS 7fde81e8 | 278 : 167 (62.47%) | 445 / 400 | PASS
2018-01-23 21:41 | 7262155a (8k steps) VS 7fde81e8 | 9 : 40 (18.37%) | 49 / 400 | fail
I think the learning rate is too high because it was 18% after 8k steps.
(If you can't tell I'm being sarcastic here, you haven't been paying attention)
gcp
on 24 Jan 2018
Current plan:
- Continue 6x128 until it stalls for ~200k ish games.
- Drop the learning rate and see what happens.
- If this has also stalled, try the AZ always-promote technique.
- Use net2net to go to 10x128.
- If AZ worked, use it, else maybe try it now (?)
Version 0.12:
- Needs a fix for timing problems with tree reuse.
- Tuning for FPU reduction is running, seems like a >150 Elo gain.
gcp
on 24 Jan 2018
@gcp Not sure if you have read my last comment, but would it be helpful if I write up the exact experiment protocol here, if you care?
isty2e
on 24 Jan 2018
Before we go to 10x128, shall we test a bit on 5x64 to 6x128 to show how it performs compared to the current approach?
bood
on 24 Jan 2018
Tuning for FPU reduction is running, seems like a >150 Elo gain.
Did you consider the possibility of investing these >150 Elo into lowering playouts?
jkiliani
on 24 Jan 2018
I think the learning rate is too high because it was 18% after 8k steps.
(If you can't tell I'm being sarcastic here, you haven't been paying attention)
There is a big difference in drop off in performance between 4% after 4k
steps and 18% after 8k steps. Most networks that have gone on to perform
well have stayed above 5% for the whole run I recall, 18% in fact is quite
reasonable at the 8k stage. Of course there are going to be exceptions to any trend, but
if you are going to be sarcastic it helps if the point stands up.
In any case we all know that performance within a session and between
sessions fluctuates, but as a general rule only so much. Of course we can
always wait longer hoping for one of the bigger random highs, but why
bother when we can move the whole average up and only require a smaller
high? Even networks that stalls after 200k fresh games could still improve
without changing anything, by just waiting for that freak training session
where everything goes well. But even you have your limits.
Also, the previous trends were complicated by the fact it seems you were
running sessions at both 0.0005 and 0.005 which was not 100% clear. It
would seem the 0.0005 performed significantly better overall which would
should be an indicator that it is worth reducing further to see if you can
get still more improvement. Instead you resist for some strange belief that
this will cause long term harm, except for someone usually so keen on
empericalism you offer no solid data to back this up, and provide no solid
theory either.
On Wed, 24 Jan 2018 at 09:35 Bood Qian notifications@github.com wrote:
Before we go to 10x128, shall we test a bit on 5x64 to 6x128 to show how
it performs compared to the current approach?—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/gcp/leela-zero/issues/591#issuecomment-360073143, or mute
the thread
https://github.com/notifications/unsubscribe-auth/AgPB1m0q0tnb0M667maOhz4DTgFInJe9ks5tNvlZgaJpZM4RVxWY
.
evanroberts85
on 24 Jan 2018
@gcp Not sure if you have read my last comment, but would it be helpful if I write up the exact experiment protocol here, if you care?
I think I understand what you want. Someone asked earlier to take snapshots at 1k intervals (or smaller). I will probably use the same setup to do your run (i.e. single training data dump). Just run it twice with the second run having a reduced learning rate, right?
It will take a bit because obviously my fastest machine is doing the real training.
gcp
on 24 Jan 2018
@gcp Yes, but you do not need to actually take the snapshot for every 1k step for the experiment. Only the loss record is important here for the experiment, and I think actual matches are enough for current snapshots (8k, 16k, ... 128k). In addition, reducing the learning rate by 10 times seems too crude for me, I would like it to be halved, and repeated until it reaches near the optimum.
And also I just saw your previous comment being updated, and here are my opinions for that:
i.e. you would say it's because it's a "better" learning rate, and I would lament the fact that we've thrown away all hope of a serious improvement in order to get a singular minimal gain.
I should strongly disagree, I already explained why.
Experience from SL says that you use the largest learning rate that does not diverge until learning stalls, and then drop. I see no convincing argument to do this differently, and no indication the original AGZ run was done differently.
This is not the case, since:
- A fundamental common knowledge in the ML is that a higher learning rate is desirable in the early stage, and when loss is reduced, the learning rate should be lowered to prevent oscillation. In general, thus, gradually decreasing the learning rate is in general better. What you said is essentially a crude approximation to this.
- Unlike the SL case, the training set is constantly and gradually changing, little by little.
- We do not start from a randomly initialized network. Rather, we start from a fairly good ("fairly good" here approximately depends on the how strong it is) initial guess, close to the optimized one, and this implies that it can be considered as being in the mid-late stage of a training procedure starting from a random network.
isty2e
on 24 Jan 2018
Yes, but you do not need to actually take the snapshot for every 1k step for the experiment. Only the loss record is important here for the experiment
For your experiment yes, but if you haven't noticed you are not the only one asking me to run experiments for them.
In general, thus, gradually decreasing the learning rate is in general better.
Yes, but this requires knowing the schedule ahead of time, so it's not applicable here.
Unlike the SL case, the training set is constantly and gradually changing, little by little.
Ok, I buy this. But it does not necessarily support either case.
this implies that it can be considered in the mid-late stage of a training procedure starting from a random network.
Which is why I immediately tested 0.0005. If 0.00005 did not benefit 5x64 (thus indicating it stalled because it was at capacity, and not because of a too high learning rate), and 6x128 cannot reasonably be at capacity already, it seems more reasonable to go to 0.0005.
gcp
on 24 Jan 2018
@isty2e I asked for the frequent step count run because I have some doubts that the loss record correlates all that well to actual testing performance. Do you know of any evidence to support it does?
Edit, @gcp: Do you regularly keep training accuracy and loss records for your training runs?
jkiliani
on 24 Jan 2018
Before we go to 10x128, shall we test a bit on 5x64 to 6x128 to show how it performs compared to the current approach?
I'm not sure what you're asking exactly. I don't plan to step up to 10x128 until 6x128 stalls.
gcp
on 24 Jan 2018
For your experiment yes, but if you haven't noticed you are not the only one asking me to run experiments for them.
I was talking about the second run with the reduced learning rate.
Yes, but this requires knowing the schedule ahead of time, so it's not applicable here.
Sure, but I mentioned that to show the "wait-until-stall" strategy is suboptimal (the definition of "stalling" can be also arbitrary, by the way). In addition, if the suggested experiment goes well, we can adopt a higher learning rate for first few steps like 4k. I know it is not transferrable to all the training set, but it is better than nothing.
Ok, I buy this. But it does not necessarily support either case.
It connects to my third point: The implication of the gradual change in the training set is that your network is expected to have already a fairly low loss value.
Which is why I immediately tested 0.0005. If 0.00005 did not benefit 5x64 (thus indicating it stalled because it was at capacity, and not because of a too high learning rate), and 6x128 cannot reasonably be at capacity already, it seems more reasonable to go to 0.0005.
But why not a lower one, too? Again I stress that I do not claim that the learning rate should be lowered immediately, but I am claiming that it should be tested.
isty2e
on 24 Jan 2018
I'm not sure what you're asking exactly. I don't plan to step up to 10x128 until 6x128 stalls.
I'm saying we never tried n2n approach before, so we don't know how well it works compared to current approach (the SL approach). I suggest we try that a bit on a small network first (e.g. generate a new 6x128 network from c83 and train a bit) to see how it performs compared to the SL approach now. Or you're already confident it will outperform SL approach a lot?
bood
on 24 Jan 2018
@jkiliani If the loss is 0 (of course it is not), it is expected to beat the previous-gen one unless there are some conflicts in the training set. The training procedure can be understood as moving the NN in the parameters space toward the target generated by the ANN-MCTS. In reality, the rating surface in the NN parameters space is not necessarily expected to be simple, and during the training, the training algorithm sometimes wanders around, and can eventually encounter an unexpected region with at higher rating. This is one of the reasons why less trained network sometimes performs better. But in general, we do not want the network to be oscillating due to a high learning rate, since the network will poke around all the points around the minimum, but not actually reaching there. Of course, during this one can eventually happen to find a better performing far from the our target, but it is more based on luck and not exactly the thing we want.
isty2e
on 24 Jan 2018
except for someone usually so keen on empericalism you offer no solid data to back this up
Oh, ho ho!
It's not like there's any actual data by the people claiming otherwise. See the original post in this topic: if were was good evidence they were right, changes would have been made already. But no, everybody has an opinion and nobody wants to do a test or offer data themselves. So yeah, now you're finding that you're butting your head against the wall and it's no fun!
Let me show you how this works:
This is a completely bullshit suggestion that can't be right:
https://github.com/gcp/leela-zero/issues/696#issue-290194275
As I point out here:
https://github.com/gcp/leela-zero/issues/696#issuecomment-359191303
Oh look, somebody provides data:
https://github.com/gcp/leela-zero/issues/696#issuecomment-359230381
Guess who's "bullshit suggestion" is getting merged:
https://github.com/gcp/leela-zero/issues/696#issuecomment-359356729
and provide no solid theory either.
Isn't that the entire discussion we're having.
At least @isty2e has a reasonable suggestion to test their hypothesis. I think that's more productive to progress than whatever you're doing.
gcp
on 24 Jan 2018
I'm saying we never tried n2n approach before, so we don't know how well it works compared to current approach (the SL approach). I suggest we try that a bit on a small network first (e.g. generate a new 6x128 network from c83 and train a bit) to see how it performs compared to the SL approach now. Or you're already confident it will outperform SL approach a lot?
I was hoping to avoid having to train a good SL network again, because it was rather tricky to get something good in the end.
But yes, this is actually a good suggestion. I can do net2net on c83e1b6e and use that instead of the best-network for a training pass.
gcp
on 24 Jan 2018
Edit, @gcp: Do you regularly keep training accuracy and loss records for your training runs?
gcp
on 24 Jan 2018
Lowering learning rate without being stalled is wrong I guess. We just started to train 6x128 and it grows fast enough to consider it stalled. Why should we low the LR then? Just because it is not smooth enough? But we should remember that even a small change in value net weights can lead to a big changes in playing strength. It's not a continuous function since the result is binary. Someone can actually make a test. Just take the best network and add tiny noise to one layer. I am sure the result will be disastrous.
dzhurak
on 24 Jan 2018
@dzhurak The idea here is not that we should lower it blindly; I am claiming that we should test it, as I have stated multiple times. We do not know if lowering the learning rate is beneficial or not, so why not test it? Also your argument about the infinitesimal change is flawed. Though the pass/fail result is binary, the rating of networks can be considered continuous and hopefully smooth. In addition, the argument is not favorable toward a high learning rate .
isty2e
on 24 Jan 2018
As stated before we cannot properly test the effect of lowering LR. To do that we need to init the parallel run with about 1m games for which we do not have resources.
rating of networks can be considered continuous and hopefully smooth.
I guess this is the main reason of all the fuzz. Many believes this statement is true but it is not. The playing strength is not smooth at all which we actually can observe during the whole run.
dzhurak
on 24 Jan 2018
It's not like there's any actual data by the people claiming otherwise.
But as has been stated before, it is not easy to prove that a small learning rate has no long term negatives, as that more or less requires having already completed the project. In the absence of evidence either way, Occam's Razor suggests we should believe that there is neither a positive or negative long term affect (on top of the short term ones). It would need sound reasoning to convince otherwise, which you have not provided. Given this, why the patronising remarks on the need for data?
Of course it has yet to be proven that lowering the learning rate even produces a short term boost. For sure it would be better if I could come up with this data myself, but this probably requires me to get a NVIDIA graphics card which will not happen for a while. So I left to only encourage others to try this, sorry if you take such exception to me doing so.
evanroberts85
on 24 Jan 2018
Edit, @gcp: Do you regularly keep training accuracy and loss records for your training runs?
What software can read these .beast training log files, do I need Python+Tensorflow for that or are there other ways? Anyone know what the guys at https://github.com/glinscott/leela-chess/issues/20 are using for these plots?
jkiliani
on 24 Jan 2018
They are TensorFlow Summary files, so yes, you need TensorFlow, which contains TensorBoard which visualizes them.
gcp
on 24 Jan 2018
Occam's Razor suggests we should believe that there is neither a positive or negative long term affect (on top of the short term ones)
You can test the behavior with supervised learning and you'll see that lowering the learning rate too early is extremely harmful in terms of slowing down the total training time and getting stuck at a lower optimum.
Thus, applying the exact same "Occam's Razor" reasoning, I don't expect this to behave differently, and lowering the learning rate too early is extremely dangerous and potentially harmful.
gcp
on 24 Jan 2018
Ok, well that is a useful observation I had not read before. I guess then learning can get stuck at a local optimum much more easily that I had thought. Lowering the rate steadily rather than by orders of magnitude may help prevent this?
evanroberts85
on 24 Jan 2018
How would lowering the learning rate within a training set work out? I.e., apply 0.0005 until the TF summary shows no more progress in accuracy and loss, then apply more training steps at a lower rate? Would that not avoid the local optimum and slowdown effects?
jkiliani
on 24 Jan 2018
As stated before we cannot properly test the effect of lowering LR. To do that we need to init the parallel run with about 1m games for which we do not have resources.
I am fearing a bit you may be right here.
I started looking at @isty2e's proposal, and it would look like this I think:
Todo:
- Write out (fixed) 250k games training window
- Do learning pass with 0.0005 and record loss data (TF Summary?)
- Do learning pass with 0.00005 and record loss data (TF Summary?)
We're expect the 0.0005 will fluctuate and the 0.00005 (or maybe an intermediate value) will end up at a lower loss.
If the loss of 0.0005 isn't meaningfully different from 0.00005 I think we conclude the issue is the diversity and amount of data?
If the loss of 0.00005 is smaller, are we sure that it is actually better in the long run, i.e. are we at risk of finding a value that just optimizes the overfit on the current training window (rather than all network history + current window)?
I don't see a good way to answer the last question without repeating the experiment multiple times. Even testing the strength wouldn't really work, because there's so much variance there.
gcp
on 24 Jan 2018
How would lowering the learning rate within a training set work out? I.e., apply 0.0005 until the TF summary shows no more progress in accuracy and loss, then apply more training steps at a lower rate? Would that not avoid the local optimum and slowdown effects?
It's the same thing. The whole underlying problem is that you're trying to make the network map out generally applicable ideas. If you allow too fine adjustments, at some point the network is learning the specific examples rather than the general ideas = overfitting.
That's why regularization is used too. Want to lower the loss? Just remove the regularizer...
gcp
on 24 Jan 2018
I don't see a good way to answer the last question without repeating the experiment multiple times.
Huu, what about dumping a window of >250k similar strength games (quite possible now) and making the code have a proper test/validation split?
If there is overfit, this should be possible to see in the validation, right?
The current TF code doesn't do a proper split of the dataset, as is remarked in the code. (It's not useful for the training procedure itself, but it might be useful to answer this question?)
gcp
on 24 Jan 2018
It's the same thing. The whole underlying problem is that you're trying to make the network map out generally applicable ideas. If you allow too fine adjustments, at some point the network is learning the specific examples rather than the general ideas.
Can it actually do that, with our current window size and the number of board positions augmented by symmetries? The training data seems so much larger to my understanding than the number of weights, but maybe I'm overlooking something here.
Maybe increasing the window would counteract the overfitting issue as well?
jkiliani
on 24 Jan 2018
The training data seems so much larger to my understanding than the number of weights, but maybe I'm overlooking something here.
There are only ~250k game results in the window. (That's why MSE overfit is always a more serious problem than policy overfit)
Maybe increasing the window would counteract the overfitting issue as well?
Yes, but then there's lower-strength networks in the window again, which works a bit against progressing.
gcp
on 24 Jan 2018
A proper validation split would be very useful. How many games are needed for validation, I would have thought just a small percentage of the 250k?
If the percentage is small is it possible to split off a percent of all games going forward for validation use?
evanroberts85
on 24 Jan 2018
Has anyone ever tried fitting the value output not to the game result, but to some sort of weighted average of game result and MCTS value output?
jkiliani
on 24 Jan 2018
@dzhurak I already suggested an experiment to tune the learning rate at moderate cost. Also though the rating might be varying fast with respect to parameters, there is no reason to assume any discontinuity in it.
@gcp That seems good enough, though I would prefer 5e-4 and 2e-4 for example, rather than 5e-4 and 5e-5. Also it is important to compare the loss at given training steps, not the converged value, of course.
If there is any issue with overfitting, I suppose it is more related to the nature of the training set, for which case we can increase the training window size. However, considering that a 500k window worked well for AGZ, I do not think that is a serious problem for the current NN size. In fact, we did not test if there is really an overfitting issue: You might want to test it by training with a smaller subset of the training set, then by comparing validation/test loss with respect to training step.
isty2e
on 24 Jan 2018
Has anyone ever tried fitting the value output not to the game result, but to some sort of weighted average of game result and MCTS value output?
Yes, this makes the program far weaker. It's a very logical idea but it does not work. (Which is why DeepMind didn't use it either, presumably).
gcp
on 24 Jan 2018
@jkiliani Though the idea is logically appealing, I suppose it is vulnerable to self-bias issues.
isty2e
on 24 Jan 2018
You might want to test it by training with a smaller subset of the training set, then by comparing validation/test loss with respect to training step.
Yeah, I think we have to improve the TensorFlow code to do this properly if we want to have any useful outcome from the experiment.
gcp
on 24 Jan 2018
Yes, this makes the program far weaker. It's a very logical idea but it does not work. (Which is why DeepMind didn't use it either, presumably).
That's a pity... something just doesn't sit right with me in always training the value output toward the winner, even in cases when that was only determined by some endgame blunder. But if the state-of-the-art says there's no better way...
jkiliani
on 24 Jan 2018
So do I understand correctly that the problem with value overfitting prevents a large majority of the policy training data from ever being used?
jkiliani
on 24 Jan 2018
So do I understand correctly that the problem with value overfitting prevents a large majority of the policy training data from ever being used?
No?
The problem is that every game has say 300-400 different inputs for learning a move policy, but only 1 input for learning who won the game.
So it's much easier for the network to remember the latter, but not so easy to remember the former.
gcp
on 24 Jan 2018
It is for that reason that I thought of alternating between training between a large window mainly with the value output, and a smaller window for training with mainly the policy output. Not really expecting that to work though and best tried with a separate project.
evanroberts85
on 24 Jan 2018
@evanroberts85 I am almost sure that the approach does not work. The value and policy heads share the same residual blocks, so it is very likely to end up with all the parameters going nowhere.
isty2e
on 24 Jan 2018
@isty2e If you trained for a long time just using the value output data, then yes the policy output would suffer and vice versa. But you would not train with the value output exclusively, just with a higher weighting, and frequently alternating. The advantage is a larger data set for training the value output, while keeping the small window of highest quality games for training the policy output.
evanroberts85
on 24 Jan 2018
I set up net2net.py with 574810017c29d9c4d5231a20c256fc3b0e971c3418441ae4a1be4c2ba99bd959 as the base.
The next run of networks won't be based on d9a5ed48 but on this instead.
gcp
on 24 Jan 2018
@gcp It may (and probably) have to undergo more training, I suppose. What about testing it to 256k or 512k steps?
isty2e
on 24 Jan 2018
That'd take quite a while (6x128 is half the speed of 5x64)...d9a5ed48 was best after 16k steps, so not sure why?
We expect it to behave like an improved c83e1b6e but perhaps respond a bit better to new training data?
gcp
on 24 Jan 2018
I am not sure how long the weight redistribution will take, since the identity layer will obviously become a non-identity layer after training. Everything will depend on the result, of course.
isty2e
on 24 Jan 2018
@isty2e I though there isn't an identity layer for this case, since it's not just a block addition, but also an expansion in channels?
jkiliani
on 24 Jan 2018
@jkiliani You can think of it like adding channels first and then appending an identity block, I suppose. At any rate, the initial weights should be quite different from converged ones.
isty2e
on 24 Jan 2018
The next run of networks won't be based on d9a5ed48 but on this instead.
By doing this, do you mean we will use this new generated 5748 to generate a set of self-plays and train from these self-plays to get a better network? I would assume 5748 is a better quality network/start point compared to ed00/7fde which are trained by SL, is it correct?
bood
on 24 Jan 2018
By doing this, do you mean we will use this new generated 5748 to generate a set of self-plays and train from these self-plays to get a better network?
No, this "fat" 5748 will be trained with the current data window, and get chance to prove itself in the matches.
If it should win, we'll end up continuing from it.
I would assume 5748 is a better quality network/start point compared to ed00/7fde which are trained by SL, is it correct?
That's what we're trying to find out.
gcp
on 24 Jan 2018
Understood. Noob question: so even the training set is not generated from 5748, we can still use this training set to train 5748? I'm no expert of NN, just to make my head clear.
bood
on 24 Jan 2018
Understood. Noob question: so even the training set is not generated from 5748, we can still use this training set to train 5748? I'm no expert of NN, just to make my head clear.
Yes. Note that this happened with the SL networks, and most networks are trained with a window that includes a few past ones.
gcp
on 24 Jan 2018
I can't read all posts . is possible to write what happened from 5x64 to 6x128 in the readme ? like how to generate 6x128 networks,etc.
st90115
on 24 Jan 2018
I see your point, I think it's a good start since the resource cost is low.
But it may not be a fair comparison. Say if 5748 is indeed better than 7fde then it's now training from self-plays from 7fde (i.e. from a lower quality network), to be totally fair it should be trained from itself I guess. But this cost several days of self-plays too, so still, let's do the quick approach first. Just my two cents, correct me if anything I said is wrong.
bood
on 24 Jan 2018
No, you are right. It just seems worth doing the experiment.
gcp
on 24 Jan 2018
7fde is at least better than 5748, so it's higher quality actually.
wnwen
on 24 Jan 2018
Quality here does not mean strength. Say c83/5748 is quite good at ladder thus plays little ladder, SL trained 7fde would probably know less ladder than c83/5748. I'm not sure whether there is evidence, but 7fde's value network may be not good as c83/5748? @gcp could explain better.
bood
on 24 Jan 2018
Ah, I see, quality as in quality of the network rather than pure playing strength. Strangely 5748 is doing better than even d9a5 on CGOS, at least right now, we'll see when Bayes comes in: http://www.yss-aya.com/cgos/19x19/standings.html
wnwen
on 24 Jan 2018
I learnt that every session of networks are trained based on the current best network rather than a complete random network. And this brings me some concern about the n2n experiment we are doing now, but again, just based on my intuition, so correct me if anything is incorrect:
When self-plays and base network are similar (best or previous best), trainings can probably bring some controllable randomness and improve the network.
But if self-plays and base network diffs quite a bit, the learning could be totally lost? Of course argument can be made that 7fde is SL trained from c83 so it may still similar, but on the other side it is SL trained after all.
bood
on 24 Jan 2018
Are the current network being tested initialized with net2net? They aren't doing too well, which is kind of expected since number of training steps is so low.
Even though net2net expanded networks have identical output they don't seem to behave like continuing the training from the previous network. During the first few training steps the loss quickly worsens before starting to improve again. You can see this effect also in graphs in net2net paper as they don't start from the same point as the original network.
I also did some testing with 20x128 network that was expanded from 10x128 network that was expanded from 6x128 supervised network. Training data was pro and high dan amateur games.
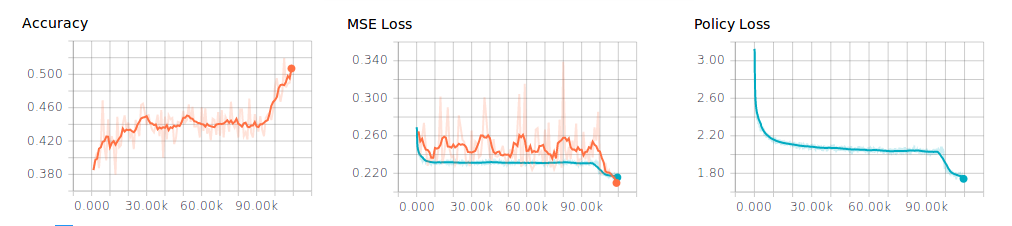
After 1000 steps the move prediction accuracy was 39% when the 10x128 network had 55% prediction accuracy. However after learning rate decrease the accuracy climbs quickly and the convergence seems much faster than with random initialization. It's probably best to treat it is as if it was random initialization especially when change in filters/blocks is big.
Ttl
on 24 Jan 2018
Are the current network being tested initialized with net2net? They aren't doing too well, which is kind of expected since number of training steps is so low.
Yes. They will run to 128k steps.
It's probably best to treat it is as if it was random initialization especially when change in filters/blocks is big.
So basically do the SL procedure as before, but start from net2net instead of random weights?
gcp
on 24 Jan 2018
So basically do the SL procedure as before, but start from net2net instead of random weights?
The training set should remain untouched, but the network should undergo more training steps after/for bootstrapping. That is basically what I was saying. I appreciate @Ttl for a concrete example.
Edit: If you are willing to, you might want to start with a relatively high training rate, and then decrease it if it looks like oscillating, while monitoring the loss. For the example above, I probably have considered lowering the learning rate at 50k steps or so.
isty2e
on 24 Jan 2018
I set up net2net.py with 574810017c29d9c4d5231a20c256fc3b0e971c3418441ae4a1be4c2ba99bd959 as the base.
The next run of networks won't be based on d9a5ed48 but on this instead.
@gcp Very cool. I was hoping you'd take the time to try this. Since net2net wasn't ready when you did the supervised networks, I wasn't sure if you'd go back to see what would have happened or not. My hope is the net2net 6x128 will retain all of the past learning from the 5x64 network and behave more naturally. (The supervised network on large playouts likes to open with 4,4 then 3,3 in same corner, which 5x64 didn't do.)
roy7
on 24 Jan 2018
Edit: If you are willing to, you might want to start with a relatively high training rate, and then decrease it if it looks like stalling, while monitoring the loss. For the example above, I probably have considered lowering the learning rate at 50k steps or so.
Not feasible in the automated training pipeline. If someone can spare a machine and let the training run for a long time on the net2net thing that's fine, but I can't.
(Ok, if there's a clear upward trend to 128k that might change things)
gcp
on 24 Jan 2018
@gcp Just confirming, 57481001 is a 6x128 net2net conversion from c83e1b6e? (The last 5x64 self-trained network if I recall right.)
roy7
on 24 Jan 2018
If the hyperparameters were optimal, what kind of behaviour would we expect?
That every new network is at least as good as the current best?
Yakago
on 24 Jan 2018
@roy7 57481001 is the last 5x64 to be better than c83e1, though only by 53% so it wasn't promoted, but it's definitely better. It is our "best" 5x64 network.
wnwen
on 24 Jan 2018
The supervised network on large playouts likes to open with 4,4 then 3,3 in same corner, which 5x64 didn't do
Is not this kind of behaviour expected though? The 5x65 network also tried
some unusual enclosures at some points in its history before quickly
rejecting them. If the search tree can not find a good response to these
moves why would it not try it?
On Wed, 24 Jan 2018 at 16:10 Gian-Carlo Pascutto notifications@github.com
wrote:
Edit: If you are willing to, you might want to start with a relatively
high training rate, and then decrease it if it looks like stalling, while
monitoring the loss. For the example above, I probably have considered
lowering the learning rate at 50k steps or so.Not feasible in the automated training pipeline. If someone can spare a
machine and let the training run for a long time on the net2net thing
that's fine, but I can't.—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/gcp/leela-zero/issues/591#issuecomment-360185004, or mute
the thread
https://github.com/notifications/unsubscribe-auth/AgPB1kUt1efFsdStkNrw6h4A45pgSfRTks5tN1YAgaJpZM4RVxWY
.
evanroberts85
on 24 Jan 2018
@gcp I am capable of giving it a try, but I suppose it will take several days, which is not that desirable here. @roy7 has already done some experiments: You can refer to this commnent. Setting the learning rate at least as low as it was and waiting for many steps will probably a lead to a better result. Alternatively, you can set the learning rate high for, say, first 1k steps.
@Yakago Unless there is no conflict in the training data, but there can be some conflicts in it. For example, the same move can be successful for a network, but it is possible that it turns out to be bad and is punished by the next network. In that case, probably not.
isty2e
on 24 Jan 2018
I'm a bit concerned about the rate games are generated currently... is there anything that could be done to generate more outreach, or find sponsors? At the moment there isn't any company or institutional support to the project with computing clusters apart from that coordinated by @alreadydone. Are there more institutions who might be able and willing to contribute GPU time? Go federations, more university AI research departments, open software foundations (Mozilla?)
We had an outreach issue a long time ago, and I didn't want to open a new one at this time, but with the recent increase of the network size and plans to increase further we'll need to either find speedups somewhere or find more contributors...
jkiliani
on 25 Jan 2018
@roy7 thought n2n looks bad for now due to discussion above, does it make sense to compare a relative good trained network against the original 57481001 to see if there is any improve? e.g. ed5f92be seems to be a good candidate
bood
on 25 Jan 2018
I tried to download train_7fde81e8.zip several times for training with a net2net-generated one as an initial guess, but the connection is occasionally closed and wget -c does not help anything. What I tried to do is to decrease the learning rate over time so it can be converged...
isty2e
on 25 Jan 2018
@jkiliani " is there anything that could be done to generate more outreach"
IMHO the easiest way is to post short encouraging info in the well targeted places (like newsgroups, FB groups etc) where people interested in AI and programming gather.
Marcin1960
on 25 Jan 2018
My opinion is that people tend to be attracted if we make some progress. The better we do, the more people gathered. I am pretty certain that we can do better than the current rate of progress.
isty2e
on 25 Jan 2018
My opinion is that people tend to be attracted if we make some progress. The better we do, the more people gathered. I am pretty certain that we can do better than the current rate of progress.
Starting from zero again is a good way to make fast progress.
(Not entirely being serious here)
gcp
on 25 Jan 2018
I am pretty certain that we can do better than the current rate of progress.
Feel free to implement proper validation splits in the training code, would be really useful to have now.
gcp
on 25 Jan 2018
Feel free to implement proper validation splits in the training code, would be really useful to have now.
My tool of the choice has been Torch so far, and I am not a big fan of TensorFlow (feels like too low-level for me). Especially when it comes to multi-GPU, TF hasn't provided any pleasant experience to me. Anyway I will give it a try... maybe after reading docs a bit.
isty2e
on 25 Jan 2018
But one of my concerns regarding the validation/test set is that we want to figure out if there is any overfitting with the current window size and how much it is. If we split the current training set into subsets and do k-fold CV or whatever, the training set size will inevitably decrease and the effect of overfitting (if any) will be increased for sure. Theoretically we have to generate even more self-play games for this purpose, but will it be a suitable plan for this project?
isty2e
on 25 Jan 2018
Would it be a big change to implement unique file names for the weight files similar to the tooltip on the webpage? I.e., instead of "leelaz-model-16000.txt" for 7a3f2766 make it something like "leelaz-3.131M-16000.txt". Currently, when I download a weight file from the match log, I have to be very careful not to switch it up with one from a different training set that would have the same name...
jkiliani
on 25 Jan 2018
I don't understand what you mean. The idea is to investigate the optimal learning rate. We need a, say, 90/10 split. We take the last 275k games, 250k train, 25k test. We run the training procedure at, say, 128k iterations for various learning rates and look what gives the best performance on the test set.
This seems to be the most sensible way to find the optimal learning rate for our uses. Using a validation set gives a good control to prevent picking a too low rate that overfits. It's not perfect (we can't detect whether the rate is too low/overfitting on a longer term level) but I surely don't know anything better than waiting until progress halts for an entire window (what we do now).
gcp
on 25 Jan 2018
Would it be a big change to implement unique file names for the weight files similar to the tooltip on the webpage?
No, I'll change it.
gcp
on 25 Jan 2018
I thought you were talking about another test intended to detect solely overfitting, which was also mentioned during discussion, I believe. Personally I do not think the 6x128 network would suffer from overfitting issues with 250k windows, since AGZ did not (or things were fine even with overfitting) with even 40x256. Anyway I usually just use train_test_split() in scikit-learn for that purpose.
isty2e
on 25 Jan 2018
Personally I do not think the 6x128 network would suffer from overfitting issues with 250k windows
It totally overfits on MSE. That's why the SL has to lower the weighting there (and given that this technique is given in the AGZ paper, they obviously had the same problem).
This is one of the main reasons why lowering the learning rate is dangerous...
gcp
on 25 Jan 2018
It totally overfits on MSE.
Is there any experimentally supporting data for this? I remember you mentioned this from time to time, but I do not quite remember what were the data behind this. If that is really the case, I think the loss contributions can be reweighted by experiments for a better performance (i.e. another hyperparameter optimization), though it will be quite costly.
Anyway I was trying to play with the tf.data.Dataset without importing scikit-learn, but I could not find any simple and elegant solution. One can apply shard() function to the Dataset object to split it into many and then concatenate, but this is certainly not exactly the thing someone would want...
isty2e
on 25 Jan 2018
Is there a experimentally supporting data to this?
Most recent example was that training the SL 6x128 on the window of games mostly consisting of its previous training data quickly dropped the MSE to about ~0.110 levels, whereas it's normally about 0.14-0.15. And one could observe that all these networks with incredibly good loss were not, in fact, any good.
You won't be able to train a decent SL net without protecting against this, so just trying that will convince you quickly.
Both the AlphaGo Lee and AlphaGo Zero paper explicitly address it.
Every loss record in the TensorFlow data I upload will show that although policy loss quickly converges, MSE loss tends to keep lowering. And the lowering isn't making the resulting networks stronger, on the contrary, so it's pure overfit.
The underlying reason is that every game has 400 policy training points, but only 1 game outcome. This has been pointed out several times in this thread, I think. The network has about 2M weights if I'm not mistaken, so remembering the result of 250k games is trivial for it. Remembering 100M moves (which also have more possible values:1..362 instead of 0..1) is much harder.
gcp
on 25 Jan 2018
That makes sense, which is even clearer after reading this from the AG paper:
The problem is that successive positions are strongly correlated, differing by just one stone, but the regression target is shared for the entire game.
Then the use of a test set totally makes sense and is essential. But then one thing that comes into my mind is the weight parameters for the policy and value losses, doesn't it make sense to lower the weight for the value loss part? I am not suggesting to change this for now, since the value head will learn significantly slower and probably it is problematic for more playouts (like several tens of thousands or more), but it is peculiar a bit.
isty2e
on 25 Jan 2018
doesn't it make sense to lower the weight for the value loss part?
That's what they did for supervised learning.
It's not required for self-play, because the total dataset is much larger (3M games for us now, 27M games or what was it for them?). However, you obviously have to be careful that the network does not overtrain on the single window you are training it on. Thus, the need to tune this (AlphaGo), do resets to best (us), and being careful about things that easily lead to overfitting, such as a too low learning rate.
The training procedure tries to ensure the network forms general rules (rather than remembering things) from ALL the games it saw, not just the current training window.
gcp
on 25 Jan 2018
My opinion is that people tend to be attracted if we make some progress. The better we do, the more people gathered. I am pretty certain that we can do better than the current rate of progress.
The best way to make more progress is to gather more people. We're currently progressing around 100k new games, with 1k games/hour that takes 4 days. If we get 10x more people on the project, we would progress every 10 hour.
(Not entirely being serious here)
I'd still like to see that happen, but not before we fixed all outstanding bugs that affect speed or elo (significant) and not before we switched to a (much) larger net and not before we tried other promising and possibly faster techniques like the AZ one.
Dorus
on 25 Jan 2018
Yeah, but the effect of a generation will decay over time, so the effective training set size should be much smaller. Anyhow, apparently the networks are not trained to full convergence for example in AZ: Translating it into training every 25k steps, it is 7k steps per generation with a minibatch size of 512.
By the way, it seems like it is able to filter a tf.data.Dataset object with a filter() function. Probably a RNG with a fixed seed as the predicate will do for the splitting.
isty2e
on 25 Jan 2018
I'm having some slight doubts the AZ technique is actually faster. If you compare progress curves between AZ and AGZ20, you'll notice that AGZ20 need a lot less games to achieve similar strength levels. It's easily possible that some of the differences between AGZ and AZ are beneficial in our case, but if all of them were, why would their progress be actually slower?
jkiliani
on 25 Jan 2018
Note for example that AZ games were only 800 playouts, which would affect the strength gain per game, likely?
gcp
on 25 Jan 2018
@jkiliani I have never thought that AZ is faster since its publication. Considering the playouts is halved in AZ, it requires a pretty much similar computational cost for the self-play part to reach the same rating. So I think it has a more or less similar bottleneck for the self-play, but for them the AZ approach might be useful because of the less training?
isty2e
on 25 Jan 2018
I wonder if the main impact of more playouts is actually really in the more accurate policy training target, or rather in the more accurate game results because of fewer blunders. If the latter has a large influence, temperature=1 could be considerably slower since the game results are much more affected by blunders.
jkiliani
on 25 Jan 2018
@jkiliani I would not say I am perfectly sure and there is speculation involved in the following, but my understanding is that the (i+1)th-gen policy is essentially an improved version of ith-gen policy, guided by ith-gen value. Then the effect of this improved policy will be reflected in the (i+2)th-gen value net, so I suppose the effect of to the value net will be somewhat delayed, in a sense. In that regard, a larger number of playouts contribute more to the policy.
isty2e
on 25 Jan 2018
Looks good:
ed4b48e3.139M+16.0k VS d9a5ed48 | 40 : 20 (66.67%) | 60 / 400
Marcin1960
on 25 Jan 2018
Why do these networks come out of nowhere every time :P It's like every other network loses so badly and then there comes the hero :P
CheckersGuy
on 25 Jan 2018
I sometimes feel like we're using genetic algorithms and not neural networks, searching for the next right mutation. ;)
roy7
on 25 Jan 2018
I think a genetic algorithm would have orders of magnitude lower chance of success in such a complex problem as go than these deep learning methods. :)
wnwen
on 25 Jan 2018
I sometimes feel like we're using genetic algorithms and not neural networks, searching for the next right mutation. ;)
Actually we do. The games we generate are rather random. The moves we pick for training are rather random. The network converging is also in a rather random direction, but generally in the right one. We also selected the 'fittest' network with evaluation.
In many ways we're much like genetic algorithm algorithm :)
Dorus
on 25 Jan 2018
Are these successful using the net2net weights now, or just using the standard network generation scheme @gcp has been using since the beginning of the six-block run?
FFLaguna
on 25 Jan 2018
Lately these mutations seem to come in pairs :)
The genetic algorithm reference made me think about the possibility of maintaining a population of "best networks" and generating games with round robin tournaments instead of just having the best net play against itself. That would give stylistic variance to training games. Just a thought.
 Serjpinski
on 26 Jan 2018
Serjpinski
on 26 Jan 2018
Two in a row? 68%? What sorcery is this!
roy7
on 26 Jan 2018
I wonder if @gcp's work on the training code today did something to make the trained models qualitatively better than before... of course it could be a coincidence that the first training set with the new code was spectacularly successful, but we'll see soon.
jkiliani
on 26 Jan 2018
I have to admit, results from this current training session seem to
vindicate the decision to keep training the same. Big jump in strength!
On Fri, 26 Jan 2018 at 00:11 jkiliani notifications@github.com wrote:
I wonder if @gcp https://github.com/gcp's work on the training code
today did something to make the trained models qualitatively better than
before... of course it could be a coincidence that the first training set
with the new code was spectacularly successful, but we'll see soon.—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/gcp/leela-zero/issues/591#issuecomment-360643544, or mute
the thread
https://github.com/notifications/unsubscribe-auth/AgPB1tSRdDUspgwhWFGdoVoYoCDkVMhLks5tORg2gaJpZM4RVxWY
.
evanroberts85
on 26 Jan 2018
Three in a row? MADNESS!
roy7
on 26 Jan 2018
And the third net in a row is leading again, seriously? I'm starting to think either the rotation bug fixed today, or the change with the shuffle buffer must have seriously improved training...
jkiliani
on 26 Jan 2018
It`s 1:40 am here and the only reason I am still awake is this third network.... Srsly... Keeping me from my deserved sleep :P
CheckersGuy
on 26 Jan 2018
We're seeing LZ catch up to Leela in just one night ;-) OK maybe not quite, but I think tomorrow is a new day as far as standings on cgos are concerned...
jkiliani
on 26 Jan 2018
Three in a row?! Holy cow. "Two at a time" has been happening more than chance. Now a third in a single go, wow. Looking forward to seeing how Network #4 does after this one...
FFLaguna
on 26 Jan 2018
Does anyone have an idea how AlphaZero would do on the cgos-ratinglist ? Obviously ranked first but what would be the difference to 2.?
CheckersGuy
on 26 Jan 2018
@CheckersGuy It'd have to lose games to have any sort of anchor. If all it did was win vs every other bot, we'd have no true idea.
roy7
on 26 Jan 2018
It's almost certainly due to #747.
In our earlier analysis about shuffle buffer size we only looked at the games within a batch, but the problem was actually that subsequent batches were all pulled from a too small pool of games.
https://github.com/gcp/leela-zero/pull/747#issuecomment-360694274
I basically overestimated how effective the shuffle buffer is, or rather, underestimated the required size by several orders of magnitude. That's also why changing it didn't show any improvements, it just went from too small to too small.
To make things worse, the supervised dumper was written before I was very aware of shuffle buffers, so it avoided this particular problem (Caffe doesn't have them): https://github.com/gcp/leela-zero/commit/a7743e8d7be765bacff479391c0b00cafcc97157#diff-99dd8e5316f0cc632c97bf16f12a8dfbR150 and got good results, hiding the problem with the trainer.
gcp
on 26 Jan 2018
Since the 3.139M 16k, 32k, and 64k, networks were all such a large success, but the 128k not, would you consider uploading for example the 72k and 80k for testing as well? (In case they exist and it's easy for you to do so. Or just a download link).
MaxMaki
on 26 Jan 2018
But 64275c74 and 9971929d are trained from the current best, so they can already be considered 64+8 and 64+16 k steps. 9971929d scored 36.2%, this is similar to the 34.5% 0f54f73a had against the current best.
Dorus
on 26 Jan 2018
But if i've understood correctly they are using different training data? More games (edit: well, not more, but a different game/training window), and also randomly in a different order?
MaxMaki
on 26 Jan 2018
Every next training step uses new training data. Actually it didn't, and fixing that gave the current increase in strength.
Dorus
on 26 Jan 2018
Ok, maybe i've misunderstood. This is how i understand it: 6427 and 9971 are labeled 3.146M and the three in a row that got promoted were labeled 3.139M. So the 6427 and 9971 are with more new games and less old ones (basically less games from the huge c83e dataset), and therefor the results will be different, so you can't really compare them to the training window of 3.139M. That's why 9971 is not the same thing as 3.139M windows 64k + 16k, and why i was asking if it would be possible to test the 72k and 80k training steps networks from the 3.139M training window.
MaxMaki
on 26 Jan 2018
Ok, it's now getting scary..
dzhurak
on 26 Jan 2018
Every next training step uses new training data. Actually it didn't, and fixing that gave the current increase in strength.
They always used new training data, that wasn't the problem.
It was something like this: for many consecutive steps, the network was mostly learning how to predict the outcome or moves from only a few games. So it found a good "solution" to these few games, and then had to slowly throw it away because it did not work for other games. That means that converge didn't happen or was extremely slow (with lower learning rates).
Instead, the positions that the network has to predict now in every step are all from different games, so it has to find a solution that works for all of them. In other words, it's now more forced to come up with general Go rules, instead of memorizing specifics about a few games.
gcp
on 26 Jan 2018
Ok, it's now getting scary..
It's a bit sad it's now clear our 5x64 was nowhere near what that size is capable of. (But I don't want to get hung up over it. 5x64 was never really the goal - bit too small to get optimal use out of GPUs)
gcp
on 26 Jan 2018
i was asking if it would be possible to test the 72k and 80k training steps networks from the 3.139M training window.
I don't keep them around. The person you are replying to was right that the next network +8k or +16k is really almost exactly the same. After all the training window is 250k, and there's not much new games added between iterations.
gcp
on 26 Jan 2018
Ok! Thanks for the info!
MaxMaki
on 26 Jan 2018
It's a bit sad it's now clear our 5x64 was nowhere near what that size is capable of.
There's nothing preventing you from trying another 5x64 training set from either a window before the bootstrap, or a current window, to find out at some point... and it also looks like the supervised network 1e2b85cf0 is nowhere near the skill ceiling for a supervised net this size.
But in either case this may have more implications about bootstrapping, by either net-to-net or from a random network. It may well be that this would both work much better than our experience now suggests.
jkiliani
on 26 Jan 2018
@MaxMaki But we use a training window of 250k games. The training window did move 7k games from 3.139M to 3.146M but that means 243k games are still the same. Those 7k games that have been dropped off are also the games in the current window that have already been used the most in previous windows and where generated by the oldest net, so are the least likely to add to the quality of the dataset.
@gcp I probably explained that a bit clumsy, but the way i understood it is it reused the same set of games too many times, you did use new moves for each step, but the moves picked didn't have enough variation.
It's a bit sad it's now clear our 5x64 was nowhere near what that size is capable of.
Once this run, and possibly the next one is over, we can try to retrain the best 5x64 from 1) the then best games or 2) restart self play on it and see how much future we can push it. All the change to self play speed, training techniques, MCTS logic and whatever else we have in the repo in a few months could result in a better 5x64 than we have now.
Dorus
on 26 Jan 2018
Interesting that if 6x128 would be enough to reach the pro level but DeepMind used 40x256 to beat top pro. They really backed themself up a lot)
Too bad they didn't show the chart of how different sized networks performed. And I am sure they did many test runs before that 20x256 and 40x256.
dzhurak
on 26 Jan 2018
it also looks like the supervised network 1e2b85cf0 is nowhere near the skill ceiling for a supervised net this size.
Note that the issue of #747 did not affect supervised training from SGF files. (But yes, it's almost certainly possible to make better ones. I only ran it for a few days as an example and test data).
But in either case this may have more implications about bootstrapping, by either net-to-net or from a random network. It may well be that this would both work much better than our experience now suggests.
That is true. The issue did affect the bootstrap.
gcp
on 26 Jan 2018
It's almost certainly due to #747
In our earlier analysis about shuffle buffer size we only looked at the games within a batch, but the problem was actually that subsequent batches were all pulled from a too small pool of games.
Very interesting, could you give an example of what the validation results
were showing with the shuffle buffer size at the old value?
On Fri, 26 Jan 2018 at 09:01 dzhurak notifications@github.com wrote:
Interesting that if 6x128 would be enough to reach the pro level but
DeepMind used 40x256 to beat top pro. They really backed themself up a lot)—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/gcp/leela-zero/issues/591#issuecomment-360722175, or mute
the thread
https://github.com/notifications/unsubscribe-auth/AgPB1rkoWOLcHGfgyIUuU8NiIq3fbNz4ks5tOZR4gaJpZM4RVxWY
.
evanroberts85
on 26 Jan 2018
Very interesting, could you give an example of what the validation results were showing with the shuffle buffer size at the old value
1) The shuffle buffer is mostly irrelevant here, see explanations above.
2) The fix for this issue is in the exact same changes to make validation work.
3) Because of (2) this would involve a lot of specific work with no benefit.
gcp
on 26 Jan 2018
Ah ok, I will read the new comments more thoroughly, just woke up.
On Fri, 26 Jan 2018 at 09:08 Gian-Carlo Pascutto notifications@github.com
wrote:
Very interesting, could you give an example of what the validation results
were showing with the shuffle buffer size at the old value
- The shuffle buffer is irrelevant here, see explanations above.
- The fix for this issue is in the exact same changes to make
validation work.- Because of (2) this would involve a lot of specific work with no
benefit.—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/gcp/leela-zero/issues/591#issuecomment-360724203, or mute
the thread
https://github.com/notifications/unsubscribe-auth/AgPB1sfp88CUAhh0FJTUtIbcNjiL2_vjks5tOZYhgaJpZM4RVxWY
.
evanroberts85
on 26 Jan 2018
Interesting that if 6x128 would be enough to reach the pro level
It probably is enough to reach 1p with fast hardware. Or very close.
And I am sure they did a test run before that 20x256 and 40x256.
Yeah test runs are pretty good for weeding out important bugs aren't they? 😁
gcp
on 26 Jan 2018
Do I understand correctly that even with the changes in #747 there still remains a fair bit of similarity between the games from one mini-batch to the next, so there is potential to improve training further?
Would still be nice to have the validation data as it may help discover other problems, but understand it is a fair bit of work and from the looks of your code already it was beyond my knowledge/coding skills.
evanroberts85
on 26 Jan 2018
The whole idea of that pull was to get good validation info, but the underlying problem of quickly sampling randomly from a 230G dataset remains. I am testing what we can get away with for 6x128 (bigger networks are less of problem, because the GPU is the limit then).
gcp
on 26 Jan 2018
If each new mini-batch was before getting 7 new games, then eventually it would end up with a good mix of games even if is started of with just a limited selection (due to inefficient shuffling). Though between batches there still would have been quite a bit of overlap.
I mention that only because it would partly explain why training results did not just get worse and worse with even more training, but after the initial few steps results between trained networks on average performed about the same.
evanroberts85
on 26 Jan 2018
Now playing using 5773 / 6x128 net:
LeelaZeroT on KGS against 6 dan HiraBot41
Marcin1960
on 26 Jan 2018
@gcp My earlier request for a training run sampled at very many steps seems somewhat redundant now, since with the new training code the strength of networks doesn't appear so chaotic anymore, but more or less deterministic. I'm putting https://github.com/gcp/leela-zero/issues/667 on the back burner for now, since the validation split may well fulfil this purpose more efficiently.
jkiliani
on 26 Jan 2018
Speaking of ladders, new network killed a couple.
But I wonder if it can -avoid- them as well...
roy7
on 26 Jan 2018
In fact I tested it on the first one, move 72. Heatmap is high for white to fall into the ladder trap, but a couple tests at 1600 playouts it avoided doing so. This specific one looks like it played the ladder out deeply based on the heatmap.
G17 -> 577 (V: 44.78%) (N: 9.76%) PV: G17 L12 G14 G12 B12 C11 B11 C10 K18 G2 M4
G16 -> 270 (V: 44.49%) (N: 5.80%) PV: G16 L12 G13 G11 J12 J11 F11 F10 E11 G12
L12 -> 250 (V: 41.73%) (N: 24.97%) PV: L12 K12 L11 L10 K11 J11 K10 K9 J10 H10 J9 J8 H9 G9 H8 H7 G8 F8 G7 G6 F7 E7 F6 F5 E6 D6 E5 E4 E8 D5 B12 B11 C11
This was using network 5773f44c as white instead of the network that lost the games.
roy7
on 26 Jan 2018
Really looking forward to the 10x128 network to check whether it can "see" ladders directly without search.
odeint
on 26 Jan 2018
@roy7 try playing out the ladder with new net and post the raw net_evals. I'm interested to see how early the net_eval realizes it's bad. I think it's not too bad for the N% to be high, we just want the winrate to drop ASAP. This basically means "hey let's read if escape works". If the winrate can say within 1 or 2 moves "nope it doesn't work" then everything is ok.
killerducky
on 26 Jan 2018
It's a bit sad it's now clear our 5x64 was nowhere near what that size is capable of. (But I don't want to get hung up over it. 5x64 was never really the goal - bit too small to get optimal use out of GPUs)
If 5b can be used on mobile, it may be still interesting to get it improved. Actually, with c83's self-play and improved training program, we should be able to test and see if we can get a much better 5x64 network with little resources (just some matches). Not sure it's worthy though. But I'll be interested to see a mobile version myself, I can help a bit on this too (I have some Android experience).
bood
on 26 Jan 2018
I wonder what will be stronger on mobile, a 6x128 network with 1 (or 100, or 1000) playouts, or a 5x64 network with 4 (or 400 or 4000) playouts. We would first need to find out how much slower a larger net is on mobile (and how viable it is to run a larger net on a low end device), and then see if more playouts on the smaller net make up for the higher base elo on the larger one.
The 23mb in size for the larger net seems acceptable for mobile.
Dorus
on 26 Jan 2018
Since it appears that the stagnation was due to this bug and not a too high learning rate, would it make sense to raise the learning rate to what it was before? Or at least to reevaluate what it should be?
 NightTusk
on 26 Jan 2018
NightTusk
on 26 Jan 2018
@NightTusk I suppose that can be tested by training three networks with different learning rates: current one, twice the current, and half the current.
isty2e
on 26 Jan 2018
In other ladder related humiliating news... ;) https://online-go.com/game/11432399
roy7
on 26 Jan 2018
@gcp Can I assume the new networks are from your bootstrap and the net2net didn't work out? Are you still trying out both to see if the net2net can catch up?
roy7
on 27 Jan 2018
Fixing a bug in the training data shuffle brought an enormous sudden boost in strength.
Along the same vein, are there any practical limitations preventing us from doubling the amount of data used to train each network? Since we are bottlenecked at selfplay game generation anyway, can we afford to spend extra time crunching a larger training dataset each time?
FFLaguna
on 27 Jan 2018
Having more data only helps if it's better. In this case the extra is even
older and worse networks. Really we rather would use only the best network
but then we wouldn't have enough data and would overfit. So we should be
close to a happy medium. We are using half the size alpha go did so we
should learn faster and not have overfitting issues since our net is still
smaller.
On Jan 26, 2018 8:00 PM, "FFLaguna" notifications@github.com wrote:
Fixing a bug in the training data shuffle brought an enormous sudden boost
in strength.Along the same vein, are there any practical limitations preventing us
from doubling the amount of data used to train each network? Since we are
bottlenecked at selfplay game generation anyway, can we afford to spend
extra time crunching a larger training dataset each time?—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/gcp/leela-zero/issues/591#issuecomment-360945754, or mute
the thread
https://github.com/notifications/unsubscribe-auth/AO6INNrvbIZzwSqV6aZfV41Sy06jeFqAks5tOnUfgaJpZM4RVxWY
.
jjoshua2
on 27 Jan 2018
Having more data only helps if it's better. In this case the extra is even
older and worse networks.
- We just experienced a sudden strength increase by fixing a shuffle bug that resulted in overfitting. That is the strongest evidence so far in favor of increasing training window.
- We are bottlenecked not by network generation speed, but rather by selfplay game generation rate.
- None of our data from the last month is "bad" data. They are all valid and strong games.
- Doubling the training window would only reach back downwards a small amount of extra ELO.
Considering all this, is now a good time to consider increasing training window to a larger value, such as from 250k to 500k?
FFLaguna
on 27 Jan 2018
RAM is an issue there. 250k isn't qualitatively that different from 500k.
wnwen
on 27 Jan 2018
We just experienced a sudden strength increase by fixing a shuffle bug that resulted in overfitting. That is the strongest evidence so far in favor of increasing training window.
We are bottlenecked not by network generation speed, but rather by selfplay game generation rate.
Actually we appear to have regressed in strength. CGOS Elo for all of the recent networks are 50-150 Elo below recent networks. So we likely had one weak network that was able to exploit a specific weakness in our strongest network, but was otherwise much weaker, and then the other networks are simply regaining the lost Elo.
LetterRip
on 27 Jan 2018
I'm not sure where you base that on, recent networks did not have many games on cgos yet and so not yet have Bayesian elo. Thus those ratings are very unreliable (+/-100 elo easily).
Dorus
on 27 Jan 2018
There was a big jump up lately. I guess a few more days are needed to accumulate new self-play games, before move up resumes? Am I right?
I was thinking about 55% requirement. I think it is very correct. Why? Even if all networks were identical, a few percent or so of them would pass 55% because of random, Brownian like movements. Am I right?
Marcin1960
on 27 Jan 2018
RAM is an issue there. 250k isn't qualitatively that different from 500k.
RAM isn't an issue afaik, the data is used in batches for specifically this reason.
FFLaguna
on 27 Jan 2018
LeelaZeroT / 714a9e64 net playing against 6 dan HiraBot44 on KGS
Marcin1960
on 28 Jan 2018
We may have found another net :P
CheckersGuy
on 28 Jan 2018
How do we know that the best networks are not playing "Rock, Paper, Scissors" with each other? Is the elo rating we're using enough to ensure that a new best network can statistically win all previous networks? Right now, we are only playing against the current best, not best -1 or best -2, etc.
 jonlave
on 28 Jan 2018
jonlave
on 28 Jan 2018
@jonlave Now and then someone has tried networks against older ones because of that concern. Also there's someone who runs every network on CGOS up to 100 games to get Bayes ratings. Not all networks we see are stronger are stronger on CGOS, but the general movement over time is rising.
roy7
on 28 Jan 2018
@jonlave I have some concerns myself about this, and the evident inflation of the self-play elo compared to Bayesian Elo on http://www.yss-aya.com/cgos/19x19/standings.html seems to also support this argument. However, from a training perspective it may well be better to simply accept some degree of rank inflation, so a network that can exploit the current network's weaknesses effectively is promoted even if it has some weaknesses itself.
jkiliani
on 28 Jan 2018
Exploiting weaknesses in self-play is not the same as RPS. Self-play Elo is inflated presumably because of exploiting weaknesses. But there is little evidence of a cycle where we make no progress as in an RPS situation. For that to happen the network has to learn to exploit one weakness while forgetting how to exploit another. I don't see much evidence of this is happening.
The closest is some anecdotal observations about some nets learning ladders and other nets forgetting them. But overall CGOS rating is going up steadily.
killerducky
on 28 Jan 2018
@killerducky Yes, that's what I was alluding to, but figured RPS would more succinctly describe the issue of concern. If CGOS/KGS ratings continue to climb, then that is probably good enough. If rankings stall, though, with new best nets, then it's worth revisiting.
jonlave
on 29 Jan 2018
Has it yet been considered to use a binary data format such as NetCDF (https://en.wikipedia.org/wiki/NetCDF) for weight files or training data? This would considerably reduce file sizes: For a weight file, if all weights were saved as single precision floats, the file size would be comparable to the current compressed size, with compression we'd probably have around half the size. Read and write access also tends to be much faster. I can see the motivation for ASCII in easy file accessibility, but with a formatted binary there are also standard tools like e.g. Panoply (https://www.giss.nasa.gov/tools/panoply/) for convenient access. While the size of training data will stay constant in the future, weight file size will likely become increasingly an issue with larger networks, which seems like a good reason to look for an efficient format.
jkiliani
on 6 Feb 2018
Are there any networks pass by 8k steps recently? Or if 8k passes always comes a stronger 16k-128k? If in that case, maybe we can skip 8k steps for saving computing resources? Furthermore, if in one cycle 128k vs old-net is 60% 16k vs old-net is 55%. If 16k passes firstly than 128k would usually have no change to vs the old-net than can not be the new-net. Are there any benefit to pass the net with less tanning steps? ( prevent over-fitting?) Or maybe let the cycle to be from 128k to 8k is better? I have no experience on this but just curious.
 2ji3150
on 6 Feb 2018
2ji3150
on 6 Feb 2018
I can see the motivation for ASCII in easy file accessibility
Exactly. There are no plans to change this whatsoever.
gcp
on 6 Feb 2018
ASCII + compression should be equal or possibly even smaller than binary data. So at least for saving on disk it would be preferred to go that route. Finding a more efficient compression algorithm is certainly easier than changing the whole data format.
In mem you could save out by using the right data types instead of ascii/string data, but last time @gcp told me that require diving into the TensorFlow code as TensorFlow expect a certain ascii-compressed format. It's totally something that would be interesting for anyone to look at, but for me it has been a bit low on my priority list ;P
Re 8k step networks: The current one isn't bad, we had another promising one in the last 100, and we even had promotions on them in the past. I remember somebody did a analyse on them, and more steps generally did result in better results, but since all our networks are like +/- 40%, even the 8k step can be the lucky one, so no need to skip it. On average a match only cost us 100 games, or about 4 minutes of self play effort. We run less than 10% eval games compared to our total.
Dorus
on 6 Feb 2018
I ran a few compression tests on one of the bigger networks:
http://zero.sjeng.org/networks/2671f15a7280d4b39d57f5b7acc2222b7c742543ba709e7754b8bece0b2276b5.gz
gzip file: 2671f15a7280d4b39d57f5b7acc2222b7c742543ba709e7754b8bece0b2276b5.gz 15507 KB
umcompressed content: leelaz-model-496000.txt 41485 KB
7zip LZMA: leelaz-model-496000.LZMA.7z 13473 KB
7zip BZip2: leelaz-model-496000.BZip2.7z 13540 KB
7zip PPMd: leelaz-model-496000.PPMd.7z 13017 KB
7zip xz (LZMA): leelaz-model-496000.txt.xz 13475 KB
7zip brotli : leelaz-model-496000.brotli.L11.7z 13678 KB
zip (PPMd): leelaz-model-496000.PPMd.L9.2MB.3word.zip 12541 KB
lz4, lz5, lizard, zstd weren't better either.
So changing to Prediction by Partial Matching (PPMd) as the compression method (instead of deflate or LZMA) could gain about 20% smaller files while keeping the content in ASCII. It would require bundling yet another helper executable with the releases though (gzip.exe can't unpack those I believe) - probably not worth it.
Bandwidth is relatively cheap and clients only need a few networks a day in any case (if they run matches, otherwise more like one a day). Debugging stuff and getting complaints when something doesn't work is 'expensive' (if not literally).
Edit: For fun, I tried Zpaq ( https://github.com/zpaq/zpaq ), a project going for high compression on several benchmarks at the price of speed (as far as I understand).
leelaz-model-496000.L4.zpaq 12357 KB
It shaves off another sliver but is quite a bit slower than the others at this compression level. On the default faster level it actually produces a bigger file (18 MB).
odeint
on 6 Feb 2018
Current plan:
Continue 6x128 until it stalls for ~200k ish games.
Drop the learning rate and see what happens.
If this has also stalled, try the AZ always-promote technique.
Use net2net to go to 10x128.
If AZ worked, use it, else maybe try it now (?)
How much of this is still current now? In the meantime we had the shuffling fix, FPU reduction, and the appearance of Minigo who are doing their own experiments in the direction of AlphaZero after all.
Are we still lowering the learning rate and trying the AZ technique? Or just expanding the net when progress stalls? I'm a bit dubious about the learning rate reduction, since this would make sense mostly if the aim was to maximise strength of the 6x128 net instead of steady progress. The difficulties with the last bootstrap may have been less if there hadn't been a learning rate reduction leading up to the strongest 5x64 nets, and a reset after the bootstrap.
jkiliani
on 8 Feb 2018
"If this has also stalled, try the AZ always-promote technique."
I read that if a new network is very weak, it might mean that it unlearned something.
Perhaps the eventual "AZ always-promote technique" should be modified, by exclusion of the weak networks like below 20%? (I picked 20% by looking at the frequency 20% plus and below occurrence)
BTW, why not to try "always-promote 20%plus" for a week or two to observe? It could be very instructive !!!
Marcin1960
on 8 Feb 2018
@Marcin1960 but the AZ promote technique include not playing match games, but to promote many networks (like once every 4-6 hours), blind. If you play no match games, how do you know if a network is below 20%?
Also, the entire point of AZ is to allow it to forget one thing in order to more easily learn something else. If the forgotten thing was important, the theory is it will relearn it quickly as the defect will show up in self play games right away.
My personal prediction with the AZ approach would be an initial drop in elo, but after that it would stabilise and be able to gain more elo quicker than the current approach. Only once a AZ run is near completion, it would make sense to match the last few nets against each other to see what the strongest one is.
Dorus
on 8 Feb 2018
What i dont understand is, why would the quality of network would go up ? Why would the elo progression wouldnt be completly random ? I mean if you promote network of random strengh, why could they not become weaker and weaker if you have a bad luck streak ? The new worse and worse network would indeed play worse and worse quality match, so dropping a lot of ELO on a bad streak luck seems plausible, or maybe i don't understand how it works with AZ approach.
 herazul
on 8 Feb 2018
herazul
on 8 Feb 2018
The tree search still strictly improves play. This is the magic sauce of all the Zero schemes. With the tree search, whenever you have a network playing at a certain level, it allows you to convert that into stronger play. Training new networks on the stronger play improves them on average. That's why it's not a random walk, the next generation is trained to reproduce the result of the old network plus tree search.
Edit: It probably helps if you do enough tree search that the Elo boost by search is bigger than the Elo fluctuations of the raw networks. I.e. if the networks jitter by 60 Elo, but you do enough playouts that after tree search you are 200 Elo stronger than the raw network, you never really get bad training data. It's always better than any of the current raw networks.
odeint
on 8 Feb 2018
@herazul because training is guided by MCTS results. Or at least that is the theory. AZ is also prove this technique works.
There are many things you can ask yourself about the AZ approach, questions that bug me are: Did they first find optimal training parameters? Would it also work from a pre-trained network like we have? Is the optimal strength higher or lower? Is the strength progression faster or slower? (The AZ paper suggest it's faster but it's unclear if it is stronger). Could you get better results if you start from scratch with AZ and then switch to AGZ?
Tons of questions, some we can answer once we switch over to the AZ technique, others might be filtered from reading the AZ or other papers close enough. Anyway the bottom line for now is that it would be very interesting (and potential very promising) experiment.
Dorus
on 8 Feb 2018
I can't grasp the concept behind what make MCTS work like that. Let's say the new networks during training are on a bad luck streak and have poor elo : It seems really weird that with MCTS the training will eventually get better even if there is a poor streak that lead to worse quality training games. It means that the training will eventually lead to better networks from worse quality game.
But yeah i know i would need to know more to understand what's going on because that clearly works for AZ but i dont understand a lot in deepmind papers. But your questions are indeed very good questions too.
herazul
on 8 Feb 2018
"the AZ promote technique include not playing match games, but to promote many networks (like once every 4-6 hours), blind. If you play no match games, how do you know if a network is below 20%?"
Perhaps by using a short match, let us say 10 games. If the result is less than 3, dump it, if 3 or more promote it. I know it is crude, but might be sufficient. Or even if it is less than 2.
Marcin1960
on 8 Feb 2018
@Marcin1960 Why? Do you have any empiric data a hybrid approach like that is better?
Dorus
on 8 Feb 2018
Nope, just I am curious what would happen if a limited almost-always-promote technique were used.
Marcin1960
on 8 Feb 2018
I think minigo promotes networks with AZ approaches.
@amj Would you please share some information about it? Does it works well?
fell111
on 9 Feb 2018
@herazul I try to explain: MCTS with infinite amount of time would in theory solve the game and play perfectly. The neural network makes MCTS much more efficient by trying the best moves in a better order and evaluate positions to find variation with high rate of winning. So in a self play game MCTS with 1600 simulations will generate a distribution of visits at root which is much stronger than what the policy output would suggest for that position. The next version of the network will train on positions where the saved distribution is better than the policy output of the old network.
So why are self played games generated with 1600 simulations only? Because training the new networks wants as many positions as possible, because it has to be able genaralize to new positions. If LZ would generatet self play games with 160000 simulations, there would not be enough data to train on and the next network would overfit and play worse despite the games being "stronger".
 odinAuthor
on 9 Feb 2018
odinAuthor
on 9 Feb 2018
@gcp Have you thought about it 10 blocks x 192 filters , alphagozero is 20 blocks x 256 filters .
 zxd0226
on 9 Feb 2018
zxd0226
on 9 Feb 2018
More generally, how efficient are the Winograd convolutions with 192 filters? Is there a big drop in efficiency, that would make shifting from 128 to 256 directly the better choice?
jkiliani
on 9 Feb 2018
@gcp @jkiliani Judging from the current output,compared to 10x256,10 x192 perhaps a better choice. filters small concern will limit the potential for blocks to play .Ersonal worry!
zxd0226
on 9 Feb 2018
I wasn't aware of any near-term plans to go beyond 128 filters... next network size is 10x128. And why would anyone choose 10x256? For a network with that many channels, that would be rather severely lacking in residual blocks.
If 192 filters turn out not to be a computational disaster, it may be worthwhile to try something with 15 to 20 residual blocks at 192 filters after 10x128 stalls. But all of that is speculative for now, since we're not even at 10 blocks yet.
jkiliani
on 9 Feb 2018
will we go to 10x128 in a few days?
st90115
on 9 Feb 2018
Please don't. 6x128 has a lot of room to improve.
dzhurak
on 9 Feb 2018
Please read a few posts back.
Continue 6x128 until it stalls for ~200k ish games.
Drop the learning rate and see what happens.
If this has also stalled, try the AZ always-promote technique.
Use net2net to go to 10x128.
If AZ worked, use it, else maybe try it now (?)
We're still at the first step of that list, last longest net took around 100k games, we still need to go to 200k and then drop learning rate.
Dorus
on 9 Feb 2018
@Dorus I was hoping for some input from @gcp if there's any changes to that plan, since it was from a while ago. About the learning rate drop: I'm not sure we'd be doing ourselves a favour there, since the following bootstrap will then have to beat a highly optimised 6x128 net instead of a decently optimised one, same with the reinforcement learning after the bootstrap (where learning rate would be raised again). Unless the goal is to optimise playing strength at 6x128 in particular, it would both save time and likely also avoid difficulties to simply bootstrap (or net-to-net) from 6x128 after it stalls at the current learning rate.
jkiliani
on 9 Feb 2018
Haven't changed the plan. I think 6x128 will probably need a learning rate reduction soon, but I don't know how long it will last after that.
Optimizing the strength of the intermediate nets is part of the goal. (They may be more relevant for getting optimal strength on limited hardware than a 256x20)
I realize that beating the optimized 6x128 after bootstrapping or net-to-net won't be easy, but it's not a hard requirement. It's just that if 10x128 is many hundreds of Elo worse, we know that we can probably do better.
gcp
on 9 Feb 2018
What's the intention regarding a (enforced?) release with FPU reduction as in the current /next? Since there is data indicating the balance of strength between nets may change considerably, this should probably happen before learning rate is lowered. I would not be surprised if FPU reduction extended 6x128 by a fair margin, and we may even be seeing the effects of training data generated by /next clients instead of /master already.
jkiliani
on 9 Feb 2018
I'm evaluating both pulls out there. I'm somewhat inclined towards the second one that got rid of the magic constants, which seems to have more stable behavior for weak nets.
There are other reasons to want to enforce all new clients (tree reuse, change playouts -> visits) but I did not want to do that because 0.11 has known bugs with timecontrols, tuning causing drivers to crash, etc. I think with 0.12 most of these have been fixed.
Edit: See also #803.
gcp
on 9 Feb 2018
@fell111 The 'always-promote' method for minigo has been... mixed. It's obviously quicker to just promote the newest network, but the downside is you're kind of flying blind in a lot of ways.
I did it without promoting because we were using root-parallelisation to have each selfplay-worker play a batch of 8 games at one time. This meant it would take ~hours to play a batch of games. Correctly implementing the 'orchestration' to pause all the selfplay-workers and have them wait for the results of an evaluation match was going to take too long, and it was just me working on it at the time, so i just said 'eh, let's see what happens'. Then the AZ paper came out and i felt clever :)
Unfortunately, having these evaluation matches is pretty important! I had no idea if the network was stalling, regressing, overfitting, etc., all of which could've been answered by evaluation matches. I had assumed that by following the paper closely, it wouldn't matter, but that didn't turn out to be the case. For instance, our first major attempt seemed to strongly overfit after ~230ish generations, and it was hard to figure out what was happening. Our only objective measurement came from CGOS, which was a badly lagging indicator.
Another way to think of it is that it seems like DM started with lots and lots of monitoring/evaluation, and as they refined the method, they were able to take away lots of these dials as they were more and more certain about their setup/config/hparams.
If i were to do it again with infinite resources, i'd do the evaluation games as the holdout data, without using it as a gating function for promotion. It doesn't seem like the important part of doing evaluation matches is to ensure the network is monotonically increasing in strength. It seems like they are important to ensure that everything else -- hyperparams, implementation, etc. etc. -- is correct. (The AZ result suggests to me that it might be important to have the network be able to take steps backwards to get out of local minima, but this is just a hypothesis). Already on our 9x9 run, we've seen that having some better monitoring has made it easier to see e.g. when to cut the learning rate -- all stuff @gcp has been on top of from the beginning :)
Hope that helps.
(FWIW, i'm very interested in the net2net stuff. With my current (very finite) resources, i'm also still looking at e.g. 2 months or more to train a 20x256).
 amj
on 18 Feb 2018
amj
on 18 Feb 2018
Since this is our catch all topic: I had a new idea for a fresh run, something we might want to do in the future consider how distorted our initial run was, and how much better our search algorithm is now and will become.
Start fresh with a 10x256 net (or whatever the size is we want to aim by then).
Start with -v 100 and time-management on. This will generate the initial required batch of games very quickly, without needing a smaller network.
Double visits to 200, 400, 800, 1600 every two days or so.
Finally go to 2200 visits and turn off time-management once our progress starts to knack off.
After that we can do what we do now, drop learning rate when we stop improving at 75% window size or so.
I would be especially interested in a fresh run if our 10 block net end up not learning about ladders and large dragons, the topics the current net has trouble with too. Obvious a 10 block net should be big enough to learn about these things, so if it doesn't, something wend wrong in the earlier (our current) training.
Dorus
on 19 Feb 2018
@Dorus Do you know of any indications that the current run is in any way hampered by the bootstrap? In retrospect, I would consider the bootstrap very successful, it just had a few problems at the very beginning. Why not simply continue expanding the network as it becomes necessary? It worked just fine so far...
About large dragons and ladders: I expect the 10 block network will become considerably better at both than present nets, but probably not perfect yet. What's wrong with just expanding to 256x20 when 128x10 stalls? (which will be a long time from now anyway)
jkiliani
on 19 Feb 2018
@jkiliani No not really, the current weaknesses in the 6 block network (poor performance on large groups), is totally possible a normal weakness on 6 block networks. Ladder problems can also be the result of poor FPU tuning and other search parameters.
I'm not advocating a switch to a fresh run right now, just addings ideas on how to proceed if we want to do a fresh run.
As i wrote above, a fresh run is probably only interesting if we fail to bootstrap a 10 block network. (And finding out so much is probably going to take a few months after switching to 10 blocks at least).
Dorus
on 19 Feb 2018
@Dorus Judging from current 6-block net sometimes fail to read life&death of size-10/size-11-group (at least that's what I feel in reading matches in KGS, also see #708 ), I don't think 10 blocks is a safe number for large dragon reading. If we are going to fresh restart, 11 or 12 is a safer number.
billyswong
on 19 Feb 2018
I don't think there is such a thing as a completely safe network size regarding large dragons. Even AGZ probably still scored large group kills against itself occasionally, in the much lower playout self-play games that Deepmind never released ;-)
Larger networks will of course make it much more difficult to outread Leela Zero, but it will still happen sometimes. Regarding ladders, I'm wondering if it is actually possible to train a network that completely understands ladders in this way, because if there was, ladders would stop appearing in the self-play games, migrate out of the training window after a while, and new networks would start forgetting. Maybe the answer is to just accept some degree of ladder weakness at 1600 playouts, as long as competition games at much higher playouts numbers get it right?
jkiliani
on 19 Feb 2018
Complete safety is of course impossible. Being able to handle some key cases like the illustration C & D in #708 will be good enough, i.e. it can count eyes for long group spanning from line 1 to line 19, so that it won't need to assume big dragons never die, and be able to react such as when a line 1 move threaten a group's life, start considering all useful moves including those in line 19.
Or in other words, a final-product network should be sized to be able to recognize the life/death of all groups that a beginner human player can learn to recognize, even if those groups span the whole board.
billyswong
on 19 Feb 2018
As the 6 block network seems to be approaching its limits, the plan set by @gcp calls for a learning rate reduction, followed by trying out the always-promote technique of Alpha Zero. Always-promote seems to have two potential advantages, diversity in self-play data and faster feedback, and one disadvantage, weaker self-play games with the possibility of regression. So what is the aim of the experiment? Is it to find out
- whether the technique can overcome stalls (local minima) better than promote with 55% winrate, and consequently improve the skill ceiling of a particular network size, or
- whether it leads to faster improvement with a net that still has plenty of room to grow
By trying the technique with a six-block net that has reached its limits already, we effectively only try out the first hypothesis. Even if doesn't produce an improvement then, it may still be worth it to try again after extending to 10 blocks. Any thoughts?
jkiliani
on 22 Feb 2018
I love experiments. So I have a (naive perhaps) question.
Is it possible to backup present state, experiment with always-promote technique for a week or two, and if it fails to return to the starting point from the backup?
Marcin1960
on 22 Feb 2018
It's too early to lower learning rate. The best networks still comes on 64+ steps.
dzhurak
on 22 Feb 2018
@dzurak I'm well aware of this, the criteria for lowering the rate have been discussed before. But for a change like Always-promote, it's probably best to clarify the purpose and details of such an experiment before actually starting it.
jkiliani
on 22 Feb 2018
whether it leads to faster improvement with a net that still has plenty of room to grow
I think that question can only be answered by running 2 "identical" experiments, to which, IMHO, our setup is not very suitable. Not only in terms of reproducibility - I think many people also don't like the "going back to 0 idea". Personally, I'd be really curious how fast a, say, 192x10 gets to our current level with all the fixes we did, and always-promote...
PS. As for bootstrap versus net2net, maybe one downside of net2net is that bootstrapping would allow features/filters to be constructed that are more suitable to the current network size, as compared to net2net?
I will try to get the training data up to date and see if we can fix the issue with resuming the downloads, as we may have to consider training a 128x10 soon-ish? I expect a reduction of learning rate to carry us futher, but if it does not, we should avoid 'getting stuck'.
gcp
on 22 Feb 2018
In net2net paper they found that random initialization and net2net converge to about same end result but net2net is quicker. Also net2net with larger learning rate ended up being better in the end than net2net trained with small learning rate although it had better loss at the start.
In my experiments and judging from the paper results it doesn't seem like using net2net initialization and trying to continue with low learning rate works too well. I think it's better to treat it as if it was random initialization. I would expect that with the same learning rate schedule net2net would give the same strength output as random initialization but quicker.
I'll try training a bigger network with net2net as soon as the training data is updated.
Ttl
on 22 Feb 2018
So the three methods I've heard so far for switching to a larger network are:
- Initialise randomly, self-train from there, i.e. totally from scratch
- Pros: Cleanest, probably highest ultimate strength
- Cons: Takes a long time, old progress is lost
- Initialise randomly, then supervised training on the self-play games of the smaller network. There could be different ways of doing this, for example only using the last games of the strongest smaller networks, or moving a window through the history of games to make the process closer to a self-learning run. Start actual self-training once the supervised bigger net is reasonably close to the old best playing strength (this criterion is not a hard one, but you want to make sure the training schedule for the "supervised Zero" net was ok).
- Pros: Doesn't lose much strength. Relatively clean, ultimate strength should be similar to a fresh start.
- Cons: The supervised learning process is kind of arbitrary with lots of knobs that can be tweaked. Our first run is not quite clean with some bugs and changes to the search, so maybe we do not want every new large network to go through a replay of this "troubled childhood".
- Initialise using net2net, self-train from there
- Pros: Actual continuity between nets (preserve not just strength but representations)
- Cons: Those representations are probably not optimal for the new size, maybe one gets stuck in a local optimum and cannot reach the full strength possible with the new size
I think all methods would start the self-training with a largish learning rate again.
odeint
on 22 Feb 2018
If an Alpha Zero experiment is in the planning, what would be the implementation details? For example,
- Do we keep the current meaning of "Best Network" to still mean "best we found so far", or do we change it to mean "Active Network"?
- If we keep "Best Network", do we continue to test new each net against best, to track how the change affects the distribution of network strength?
- What about the training pipeline? Train one dataset to a single predetermined endpoint, e.g. 32k steps (~2 hours), and parse new data afterward? Or continue training to multiple sampled nets? Backing up each training run to "Best network" should no longer apply I presume?
- How about the website stats? Are we tracking the number of games from each network? This will produce a very long list very soon...
This list may not be exhaustive, but it's what occurred to me offhand. I'm mentioning this since it may take a few decisions to find an implementation that works correctly, provides continuity to the current pipeline, and can be reverted without too much problems if it turns out not to produce good results.
About the three methods of network change @odeint mentioned: I favour 2 or 3, agreed on the learning rate. However, for a "largish learning rate", an initial strength drop may have to be accepted.
jkiliani
on 22 Feb 2018
If we keep "Best Network", do we continue to test new each net against best, to track how the change affects the distribution of network strength?
Doesn't really matter. I wouldn't test every network, just every 1/8th or 1/16th or so. The training machine will potentially spit out even more of them than it does now, after all...
Train one dataset to a single predetermined endpoint, e.g. 32k steps (~2 hours), and parse new data afterward?
Yes. Because we don't reset the training, we don't need to do a lot of steps.
How about the website stats? Are we tracking the number of games from each network? This will produce a very long list very soon...
Easy fix for @roy7 if we end up doing that.
gcp
on 22 Feb 2018
Re: AGZ approach.
If we push a new net every few hours, i think it would be nice if autogtp cleaned up old nets, as these files are rather large (when you add 4-12 of them every day). Not to mention bandwidth cost, are those kept acceptable?
For the elo graph: It would be preferable to not only match a network against the previous best, but against the last 3 or 5 previous best. If we play 10 games against the last 5 nets, and 10 games against the each of the next 10 nets, that would make 100 games per net and give more accurate elo.
Dorus
on 22 Feb 2018
- Initialise randomly, self-train from there, i.e. totally from scratch
- Pros: Cleanest, probably highest ultimate strength
- Cons: Takes a long time, old progress is lost
It's pure speculation that training from scratch will probably reach highest ultimate strength. Of course that's what Deepmind did, but is there any hard data to support this? I think it's far more likely that the ultimate strength depends only on the network architecture, as long as local minima are avoided by using appropriate learning rates, as @Ttl mentioned.
jkiliani
on 22 Feb 2018
It's a pure hypothesis that training from scratch will probably reach highest ultimate strength.
It is not proven but it is plausible, at least that it is for sure not worse than the others, but can be better. The question ties in with repeatability: If you do several Zero runs with the same settings, just different random seeds, will the networks end up at the same strength (and will they get there on a similar trajectory, i.e. learn things in the same order and roughly at the same time)? Or are there bifurcations in the road, and once you've taken a wrong turn, there's no way back? If the procedure always yields the same end result, even when the states in-between were different, then it is also likely that any bias from the bootstrap procedure will be overcome. If even different Zero runs give quite different results, it's hard to say anything about it because you'd need a large number _runs_ to be able to tell, so _billions of games_ overall.
odeint
on 22 Feb 2018
I've noticed something intriguing. I've adopted FPU reduction since 2 weeks ago for my 9x9 experiment, and since then, all my nets have easily passed the SPRT validation matches. But today I've run a set of matches between the current best and a lot of the previous nets (starting from the previous one, then the one before that, etc.).
It beat every network "created" with FPU reduction easily (keep in mind I'm always using only the games generated by the latest net when training, so there's no mix of data generated in different ways in my set up), but when I tested it against the last "vanilla" network, it could only score a 67% winrate, despite being 2200 Elo stronger according to the graph. Then, against the net before that one, it could only win 60% of the time. I'm currently running another match against the one even before that to see if when the winrate goes up again, but it seems generating games with FPU reduction might have inflated enormously the Elo, giving a false sense of progression.
Alderi-Tokori
on 22 Feb 2018
Yes, supervised learning and then selfplay reached a lower skill ceiling than random initialization. See AG and AGZ paper.
However AG was training on human games, so it is unknown is training on a smaller net self play games is going to harm a larger net. So far we've only done experiments with different network architectures, we've not yet tried the same architecture but with different initialisations.
Starting a new run or two with 6x128 with net2net and random initialisation is going to take at least 10-20 days each.
Also i have some doubt on our ability to make a clean run, we keep tweaking MCTS and other stuff, and with the new deepmind paper about the new MCTSnets method we might want to try too.
I think it would be best to just storm on and go for whatever method our guts tell us to use (my money is on net2net to be honest)
Dorus
on 22 Feb 2018
@gcp It might be interesting to run a match between the current best leelaz net and the last "vanilla" leelaz net, in order to see if we can observe the same thing on 19x19 as I've observed on 9x9 (big discrepancy between Elo difference and actual winrate), though since leelaz uses a sliding window, it might mitigate the problem.
Alderi-Tokori
on 22 Feb 2018
@Alderi-Tokori See cgos?
Dorus
on 22 Feb 2018
@Dorus What should I be looking for?
Alderi-Tokori
on 22 Feb 2018
@Dorus
Yes, supervised learning and then selfplay reached a lower skill ceiling than random initialization. See AG and AGZ paper.
If this is based on the comparison between AlphaGo Master and AlphaGo Zero, the argument is totally meaningless. For example, AGM has different handcrafted features and rollouts are used for it. Moreover, the number of self-plays or whatsoever is totally unknown for AGM.
isty2e
on 22 Feb 2018
@odeint If my memory did not serve me wrongfully, DM people said the result was reproducible for several runs. With the Dirichlet noise added, I suspect that any initialization (including supervised ones) can reach the optimum unless some parameters are really badly assigned.
isty2e
on 22 Feb 2018
@Dorus
Yes, supervised learning and then selfplay reached a lower skill ceiling than random initialization. See AG and AGZ paper.
Where does it say that?
killerducky
on 22 Feb 2018
@Dorus I presume you refer to Fig. 3 in the AGZ paper. Unfortunately, your interpretation is wrong: They compare the performance of their self-play reinforcement pipeline to a network trained by SL from human professional games, on an axis of training time. It's really comparing apples with oranges. Nowhere (afaik) do Deepmind ever compare the reinforcement learning performance of a net initialised from SL to the RL performance of a randomly initialised net.
If you mean any other place in the Deepmind papers, let me know.
jkiliani
on 22 Feb 2018
@odeint I accept your argument about repeatability, but I still doubt the assertion that random initialisation RL result is surely not worse.
I think there are two possibilities: One, initialisation matters. Then, different RL pipelines will end up with different endpoints in strength, no matter if their starting point is (different) random points, supervised learning or net-to-net. But the endpoint of a RL pipeline started from SL could then also be (randomly) higher.
Option two (which I think is most likely correct): Initialisation only matters for the how long the training takes, but not for the plateau performance. A supervised start should simply save time but have the same result.
We don't have enough information at this point to decide which is correct, but I think the assertion that a random start likely has a higher plateau is a stretch.
jkiliani
on 22 Feb 2018
@jkiliani I am talking about AGZ defeating AG with (at least this was implied) less training games and processing power. AG started off with training on human games and then self play. AGZ is not bootstrapped but instead started from random play.
Dorus
on 22 Feb 2018
Correct but you're missing several crucial pieces of information here that are also in the paper: The network architecture was changed, from separate convolutional networks to a dual residual one. They even measure how much strength this gains (1200 Elo). So using the performance of AGZ against AG Lee as an argument for learning from scratch is deeply flawed. There is nothing in this paper that compares reinforcement learning pipelines that differ only in their starting point, which would be the only kind of data relevant to this question.
jkiliani
on 22 Feb 2018
@jkiliani
Nowhere (afaik) do Deepmind ever compare the reinforcement learning performance of a net initialised from SL to the RL performance of a randomly initialised net.
Not sure that's true. AG-Master is the same architecture as AGZ, with different features, started by SL. The graphs showing the relative Elo between AGM & AGZ are (presumably) where @Dorus ' statement comes from.
amj
on 22 Feb 2018
@amj He did not mention this, but about AG Master: We do not know for sure what the exact architecture is, only that it's residual dual like Zero. However, it's quite likely 20 residual blocks, like the first Zero run. AGM is actually stronger than AGZ 20 blocks, presumably due to the additional features more than human knowledge, only AGZ 40 blocks is strong enough to beat Master. But without knowing the exact configuration of Alphago Master, we cannot deduce anything about why AGZ 40 blocks is stronger. I think it's "Stack more layers".
jkiliani
on 22 Feb 2018
My guess is that AGM has 40 blocks, but regardless of that, the comparison cannot be made in a sensible way since the number of self-play games nor training steps is unknown.
isty2e
on 22 Feb 2018
@isty2e Could be but I doubt it. I think the only reason they made the 40 block run is that they wanted Zero to beat Master for a better selling point in the article, and to get that result they had to increase blocks. Note that in the Alpha Zero paper, they shift the reference point back to the easier to beat AGZ 20 blocks.
jkiliani
on 22 Feb 2018
AlphaGo Master is the program that defeated top human players by 60–0 in January, 2017. It was previously unpublished but uses the same neural network architecture, reinforcement learning algorithm, and MCTS algorithm as described in this paper. However, it uses the same handcrafted features and rollouts as AlphaGo Lee 12 and training was initialised by supervised learning from human data.
AlphaGo Master differences compared to AGZ:
- Number of blocks not specified. (Use this to support whatever argument you want to make. ;-) )
- Training effort (time/resources) not specified.
- Bootstrapped using SL from human data.
- Handcrafted features.
- Rollouts + Net eval instead of Net eval only.
killerducky
on 22 Feb 2018
About the results @Alderi-Tokori reported: Apparently we're seeing a degree of rock-paper-scissors here, for whatever reason. To an extent that also appears to happen at 19x19, or we wouldn't have as much rating inflation in the progress curve. At some point, we might look at increasing the training window to the 500k games used by Deepmind: If much of the strength progression within the window isn't actually real, the benefit of using more games and more diverse training data may well be a net gain.
Maybe linked to "Always-promote", we could also try some adversarial learning concepts like using training data from a pool of different nets matched against each other instead of only the same net playing both sides. This should at least improve ladder handling, since currently ladders happen much more in matches than in self-play, for the simple reason that they are only played out when both players think they work for them.
jkiliani
on 23 Feb 2018
https://www.facebook.com/GOking2007/videos/1364474096921048/
at -20:15 David states Master uses 40 layers. So 20 blocks.
barrtgt
on 23 Feb 2018
The same video on YouTube, for future reference: https://youtu.be/G3p4JmCedW8?t=37m45s
alreadydone
on 23 Feb 2018
The last time we had back to back networks take 100k+ training games, it was net 0db82470, in the middle of our last big stall. If we're thinking of upgrading to 10 blocks, it's probably better to do it sooner rather than later to be more efficient with our computing resources.
jonlave
on 23 Feb 2018
The plan calls for first a reduction in learning rate at a prolonged stall, and then trying out AlphaZero's technique of promoting networks without testing.
@gcp Are we lowering the learning rate sometime tomorrow morning? (Assuming of course that no new best appears tonight... from experience, that usually happens when people start planning for consequences from a stall ^ ^)
jkiliani
on 23 Feb 2018
I guess we get a learning rate reduction tomorrow, after that we need some extra time to see if that has any effect on playing strenght. So i guess we wont go to 10x128 for at least another week.
If you ask me we could also skip the learning rate reduction, and just go straight for 10x128. However that's not the plan we've been following pretty steady since @gcp shared it.
Dorus
on 24 Feb 2018
My choice would also be the switch to 10x128 now but it's @gcp's call. In any case, he will need quite a bit of preparation time to bootstrap such a net (unless we're trying net-to-net now?)
The plan actually calls for first learning rate reduction, then trying Always-promote, and only after both of these steps upgrade to 10 blocks.
But now that we're talking about it, I'm sure we'll summon a passing network :)
jkiliani
on 24 Feb 2018
We now have a training window more than 2/3 full with no promotion. Is the learning rate being reduced now?
jkiliani
on 24 Feb 2018
And just after you said that, three challenger networks in a row win a majority of their games. Was the learning rate indeed reduced or is it that tempting fate apparently also works in the positive sense?
 TFiFiE
on 24 Feb 2018
TFiFiE
on 24 Feb 2018
@jkiliani commented on Feb 23, 2018, 7:56 PM GMT-3:
The plan calls for first a reduction in learning rate at a prolonged stall, and then trying out AlphaZero's technique of promoting networks without testing.
@gcp Are we lowering the learning rate sometime tomorrow morning? (Assuming of course that no new best appears tonight... from experience, that usually happens when people start planning for consequences from a stall ^ ^)
And now we got two near back to back promotions, just because you had to to say it :)
 LRGB
on 24 Feb 2018
LRGB
on 24 Feb 2018
Hmm maybe @gcp did actually change the learning rate... the 48k net is late, so at the least something was changed with the training machine...
jkiliani
on 24 Feb 2018
As you correctly anticipated and inferred, I cut learning rate to 0.00015 (which is "halfway" a 10x reduction) after we had 170k games without promotion. I also increased max steps to 256k and rejiggled the steps that will get matched a bit (but I made a mistake so the uploads this weekend stopped at 128k, now fixed).
I've started training 128x10's by using net2net to generate a network and then training it on the last 500k games.
gcp
on 26 Feb 2018
If this is the final learning rate we're using for 6 blocks, how are we going to do Always-Promote? Same learning rate as now, but autogtp gets tasked to play with the latest net in the list instead of best-network?
For those nets which get tested, are we continuing to test against best-network, like before?
jkiliani
on 26 Feb 2018
I can do another reduction to 0.00005 because this was only a halfway one. I can't really increase the max steps a lot so this seemed smoother.
Same learning rate as now, but autogtp gets tasked to play with the latest net in the list instead of best-network?
The latest net will always be marked as best-network.
For those nets which get tested, are we continuing to test against best-network, like before?
That's probably best, as we need something that also has a rating. This will require some coding from @roy7 though.
gcp
on 26 Feb 2018
FWIW I'm not sure whether I said I would do always promote with 128x6 or 128x10. Given that the current setup works, my current thinking is I'd wait till the final network at 128x10.
We can consider switching from 1600 playouts to 2400 visits now (or was it 2200?), as all clients are on 0.12+v14.
I think something happened just now when a91721af got promoted, as it's at 48% now. Complete blow out early on?
gcp
on 26 Feb 2018
So we are changing the actual meaning of best-network? Are you sure? How about introducing something like active-network, which is used for self-play, and keep best-network the reference for testing? For the 55% threshold promotion it would be identical...
Well if we're not doing this at 6 blocks, this question can wait actually.
jkiliani
on 26 Feb 2018
I'm not sure it's needed. I'm thinking in terms of the original autogtp client that checked best-network on the server, but with current AutoGTP they get a JSON packet telling them explicitly what to do, so as long as the server knows to send the latest network...
From the training side I would just like to set a flag when uploading that tells the server "use this from now on for self-play". Pinging @roy7
gcp
on 26 Feb 2018
@gcp Why not try "hybrid" weights at the end of 6 block. I now run a hybrid weight on CGOS, test parameter is :
LZ-HY-W23-PO1600: -g -p 1600 --noponder -t 1 -q -d -r 1 -w
LZ-HY-W23-NOLIMIT: -g --noponder -t 4 -q -d -r 1 -w
The weight file is bellow:
f66-081-9ac-8ee-4d5-5e4_1-0.5-0.5-0.5-0.5-0.5.zip
In my test, it stronger than the original weight, so we can wait the CGOS result.
pangafu
on 26 Feb 2018
I think something happened just now when a91721af got promoted, as it's at 48% now. Complete blow out early on?
Yes, see the match history.
11-1 win (sprt pass) before going on a lose streak to end at 44.90% :(
We've discussed this before, the scenario just never happened till now. a9 has a better winrate the first 200 moves and thus has a bias on short matches. We start 40-50 matches right away, so the half of them that is relatively short arrives early and gives a biassed win %. So far we've had a bunch of 10-1 nets that eventualy failed, this is the first 11-1 net that did so. I guess it just got lucky.
The only way to prevent situations like this (and also 92dd0397 that promoted at 220-180 and then ended at 230 : 191 (54.63%)) would be to only accept a pass when all 400 games are send out and all ongoing games have returned. This would slow down promotions by 30 minutes to 2 hours, but not too hard to program on the server.
Another workaround would be a minimal number of like 40 games before we accept a SPRT pass.
Dorus
on 26 Feb 2018
@Dorus This did happen before, with af4f49f1. A minimum number of games in addition to SPRT pass would be a good fix in my opinion.
jkiliani
on 26 Feb 2018
Yes, this is the second time we've had an under 50% promotion, both times causing minor comotions :)
I like the minimum number of games ideia.
By the way, has any thought be given to adopting an intermediary step between the promotion criteria we are using now and always promote? Say a 50% treshhold (or lower)? While the always promote method clearly works (as does the one we are using now), I wonder if there isn't a sweet spot that balances network diversity vs quality and gives optimal results? After doing this for a while we could move to alway promote and compare?
LRGB
on 26 Feb 2018
I suspect that always promote helps new, temporarily crippling discoveries to be retained by the next stronger networks. So open doors to creativity. Of course on the condition that windows is large enough for the older stronger nets to be present.
Marcin1960
on 26 Feb 2018
Do not forget that we use random noise in training games. It gives enough of creativity. I don't expect always promote approach will be any faster than current one. Also we have an example of MiniGo guys who used always promote technic and their results were not any better than ours.
P.S. Current methodology works great so as for me there is no need to change it. But I am biased to get the strongest bot not to discover the best algorithm.
dzhurak
on 26 Feb 2018
There is another logical option - if promoted net fails, promote previous best net back. (unless another 3rd net got promoted meanwhile, then I would pass)
Marcin1960
on 26 Feb 2018
This is my favorite option. It gets new nets running soonest and is closer
to the alpha zero model. Some variety of games with strong early moves
can't hurt that much if it's only a few thousand games.
I was wondering about a possible but for people that don't have internet on
weekends it keeps on playing with the last net. Do those get added to the
front of the training window or with the net they came from once they are
finally submitted? I'm wondering if some games in the 250k window can be
from older nets from odd clients.
On Feb 26, 2018 10:59 AM, "Marcin1960" notifications@github.com wrote:
There is another logical option - if promoted net fails, promote previous
best net back. (unless another 3rd net got promoted meanwhile, then I would
pass)—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/gcp/leela-zero/issues/591#issuecomment-368550830, or mute
the thread
https://github.com/notifications/unsubscribe-auth/AO6INBOaFX_oL2ciRv9Lbnf4Qt9gHxc-ks5tYtTngaJpZM4RVxWY
.
jjoshua2
on 26 Feb 2018
As you correctly anticipated and inferred, I cut learning rate to 0.00015 (which is "halfway" a 10x reduction) after we had 170k games without promotion. I also increased max steps to 256k and rejiggled the steps that will get matched a bit (but I made a mistake so the uploads this weekend stopped at 128k, now fixed).
Still don't see the 256k steps network.
2ji3150
on 26 Feb 2018
@gcp So I clearly understand, you want a toggle on the submit-network endpoint you can flag that says "promote this as the new best network immediately"? I'm not sure how we'd change the graphing setup to deal with a best network that has no match history. Maybe another parameter to manually set an ELO score that would override the current way we calculate them all?
Is this towards an eventual new "always promote" system or something we'll use for 10x128? If it's for always promote, what's our thoughts on how we'll generate ELO figures in that case? Still schedule matches like usual?
In an always promote world, if we still want to run match games, we could set the endpoint to auto promote after upload and auto add a match between the new upload and the prior best network at the same time. (Edit: In this case, there would be no more promotion as the result of matches, simply results for ELO graphing.)
roy7
on 26 Feb 2018
I would propose you just replace best-net every x hours, but for the elo graph you schedule a match every y hours, where y is a bit larger than x. Like you get a new net every 4 hours, but you schedule a match every 24 hours.
A future bonus would be to run a more tournament like setting where you play match games vs a bunch of previous nets. Instead of 400 games every 24 hours, you could play 10 games against each of the last 6 nets, resulting in 60 match games per new network, and also around 6*60=360 per day. Each net would then play 120 match games, 60 against the nets before and 60 against the net after. However we would need to borrow some code somewhere to calculate elo from that data :)
Idk how hard BayesElo is to calculate, but i believe the cgos code is available.
Dorus
on 26 Feb 2018
@pangafu what weights are w24, and what GPU are you using? Wondering about how many playouts your unlimited bot on CGOS gets. It's doing remarkably well, almost as good as the 20 block 1600 playouts.
jjoshua2
on 28 Feb 2018
@jjoshua2 Might be better to compare the 1600 playout versions since more playouts make it a lot stronger.
wnwen
on 28 Feb 2018
They are interesting too. The HW24 1600 is just barely ahead of HW23 1600, and they are both ahead of all the other lz bots, besides the 20 blocks. Even ahead of the lzladder-666 which had 3200 playouts and ladder knowledge.
jjoshua2
on 28 Feb 2018

I think in the first line, the first txt is W24 and the second is W23.
(If you don't know what these mean, see https://github.com/gcp/leela-zero/issues/814 and pangafu/Hybrid_LeelaZero.)
alreadydone
on 28 Feb 2018
Wowers a hybrid of 9 nets? I thought the 6 of hybrid 23 was a lot. Once you
get that high there's lots of combinations to test. I'm surprised limiting
it to the 3 strongest isn't better since nets are still progressing.
On Feb 28, 2018 2:03 PM, "Junyan Xu" notifications@github.com wrote:
[image: 478fdf6ffc4af5de]
https://user-images.githubusercontent.com/3064145/36807091-e3e82454-1cb9-11e8-96b7-842609dbfbb0.png
I think in the first line, the first txt is W24 and the second is W23.—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/gcp/leela-zero/issues/591#issuecomment-369346779, or mute
the thread
https://github.com/notifications/unsubscribe-auth/AO6INBUnGx7XXHait5B5ttRLSq8DsRsJks5tZaMdgaJpZM4RVxWY
.
jjoshua2
on 28 Feb 2018
@jjoshua2 Please see #954 , My test machine is 1070 8G
pangafu
on 1 Mar 2018
@alreadydone yes, the first is W24, and the second is W23 in first line.
pangafu
on 1 Mar 2018
@jjoshua2 in my test, the strongest hybrid weight is often not made by the strongest parent, the mix of 40%+ win rate weights often get the strongest one.
pangafu
on 1 Mar 2018
@gcp If hybrid weights are stronger due to noises being averaged out, it's probably a good idea to increase the batch size (we are using 512 due to GPU memory limit while AGZ and AZ are using 2048 and 4096 respectively). I suggested in another thread that we could use openai/gradient-checkpointing (see also Medium post) to reduce memory usage with slight increase in training time. A graph shows that peak memory usage is reduced by a half for a 6-block ResNet with batch size 1280, so since we can fit batch size 512 into GPU memory before we should now be able to fit batch size 1024 now.
alreadydone
on 1 Mar 2018
@gcp I think we're ready for the final learning rate reduction of 6x128: Considering the regression with a91721af, there has been no significant progress since 92dd0397, that's already more than 2/3 of a window. Are there any 10 block nets to start testing (probably against other than best net) yet?
jkiliani
on 2 Mar 2018
Since the bootstrap is a full blown success on the first try, can we simply do the switch to 10 blocks now? The new net looks great!
jkiliani
on 2 Mar 2018
Very impressive!
dzhurak
on 2 Mar 2018
have we switched to the new net size yet
 AscendChina
on 2 Apr 2018
AscendChina
on 2 Apr 2018
@hydrogenpi For information on training progress and the current network size, have a look at this page:
http://zero.sjeng.org/
You can hover over the network names in the Test Matches table and it will show you the network size.
The recent matches are with networks of size 128x10.
 qrss
on 3 Apr 2018
qrss
on 3 Apr 2018
Related issues
 l1t1
·
3Comments
l1t1
·
3Comments
 elensar92
·
3Comments
elensar92
·
3Comments
 syys96
·
4Comments
l1t1
·
4Comments
syys96
·
4Comments
l1t1
·
4Comments
 jslechasseur
·
4Comments
jslechasseur
·
4Comments
Most helpful comment
It's due to the implementation of tree reuse. This means that the NNCache loses most of its effectiveness, but the program becomes vastly stronger at the same playout count.
With Winograd, tree-reuse and multi-GPU, it's time for a new release.