Kubespray: TASK :etcd cluster health check is failed
i'm running kubespray on aws ec2 instances with RHEL8 and playbook failed at etcd cluster healthcheck task with below error
TASK [etcd : Configure | Check if etcd cluster is healthy] ******
Saturday 26 October 2019 05:22:30 +0000 (0:00:00.402) 0:07:20.395 *
fatal: [xxxxxx]: FAILED! => {"changed": false, "cmd": "/usr/local/bin/etcdctl --endpoints=https://xxx:2379,https://xxx:2379,https://xxx:2379 cluster-health | grep -q 'cluster is healthy'", "delta": "0:00:00.067419", "end": "2019-10-26 05:22:31.405436", "msg": "non-zero return code", "rc": 1, "start": "2019-10-26 05:22:31.338017", "stderr": "", "stderr_lines": [], "stdout": "", "stdout_lines": []}
when execute below command in one of the master 👍
/usr/local/bin/etcdctl --endpoints=https://xxxx:2379 cluster-health
cluster may be unhealthy: failed to list members
Error: client: etcd cluster is unavailable or misconfigured; error #0: remote error: tls: bad certificate
error #0: remote error: tls: bad certificate
kubespray 2.11
ansible :2.7.12
hosts.ini
master1 etcd_member_name=etcd1 ansible_python_interpreter=/usr/bin/python3
master2 etcd_member_name=etcd2 ansible_python_interpreter=/usr/bin/python3
master3 etcd_member_name=etcd3 ansible_python_interpreter=/usr/bin/python3
node1 ansible_python_interpreter=/usr/bin/python3
node2 ansible_python_interpreter=/usr/bin/python3
node3 ansible_python_interpreter=/usr/bin/python3
## configure a bastion host if your nodes are not directly reachable
bastion ansible_host=x.x.x.x ansible_user=some_user
[kube-master]
master1
master2
master3
[etcd]
master1
master2
master3
[kube-node]
node1
node2
node3
[k8s-cluster:children]
kube-node
kube-master
 muniprakash2b9
muniprakash2b9
All 30 comments
I'm facing the same situation. I am setting up a cluster on the bare metal:
TASK [etcd : Configure | Check if etcd cluster is healthy] ************************************
Wednesday 30 October 2019 15:25:46 +0300 (0:00:00.217) 0:06:34.376
FAILED - RETRYING: Configure | Check if etcd cluster is healthy (4 retries left).
FAILED - RETRYING: Configure | Check if etcd cluster is healthy (3 retries left).
FAILED - RETRYING: Configure | Check if etcd cluster is healthy (2 retries left).
FAILED - RETRYING: Configure | Check if etcd cluster is healthy (1 retries left).
fatal: [kub-master-1 -> 172.27.20.34]: FAILED! => {"attempts": 4, "changed": false, "cmd": "/usr/local/bin/etcdctl --no-sync --endpoints=https://172.27.20.34:2379 cluster-health | grep -q 'cluster is healthy'", "delta": "0:00:05.067341", "end": "2019-10-30 15:26:25.465501", "msg": "non-zero return code", "rc": 1, "start": "2019-10-30 15:26:20.398160", "stderr": "", "stderr_lines": [], "stdout": "", "stdout_lines": []}
Can this problem be solved?
 volkmydj
on 30 Oct 2019
volkmydj
on 30 Oct 2019
i skipped the cluster health check task and proceed with cluster deployment and it created cluster but some communication issues are there
when hit below in master :
/usr/local/bin/etcdctl --endpoints=https://xxxx:2379 cluster-health
Error: client: etcd cluster is unavailable or misconfigured; error #0: client: endpoint https://xxxx:2379 exceeded header timeout
muniprakash2b9
on 31 Oct 2019
Etcd health checks are performed using host access IPs:
- name: Configure | Check if etcd cluster is healthy
shell: "{{ bin_dir }}/etcdctl --endpoints={{ etcd_access_addresses }} cluster-health | grep -q 'cluster is healthy'"
These are not the same as service bind address (ip vs. access_ip):
hosts:
node1:
ansible_host: 172.17.66.31
ip: 10.10.10.31
access_ip: 172.17.66.31
ansible_user: root
There might be an incosistency between health check endpoint and address configuration for etcd:
# /etc/etcd.env
ETCD_ADVERTISE_CLIENT_URLS=https://172.17.66.32:2379
ETCD_INITIAL_ADVERTISE_PEER_URLS=https://172.17.66.32:2380
ETCD_LISTEN_CLIENT_URLS=https://10.10.10.32:2379,https://127.0.0.1:2379
ETCD_LISTEN_PEER_URLS=https://10.10.10.32:2380
ETCD_INITIAL_CLUSTER=etcd1=https://172.17.66.31:2380,etcd2=https://172.17.66.32:2380,etcd3=https://172.17.66.33:2380
 bzurkowski
on 4 Nov 2019
bzurkowski
on 4 Nov 2019
Works fine after removing the access_ip variable:
hosts:
node1:
ansible_host: 172.17.66.31
ip: 10.10.10.31
ansible_user: root
Works fine after removing the
access_ipvariable:hosts: node1: ansible_host: 172.17.66.31 ip: 10.10.10.31 ansible_user: root
你zz
Works fine after removing the
access_ipvariable:hosts: node1: ansible_host: 172.17.66.31 ip: 10.10.10.31 ansible_user: root
Where is this file
 liujian163
on 6 Nov 2019
liujian163
on 6 Nov 2019
It's Ansible inventory for Kubespray:
https://github.com/kubernetes-sigs/kubespray/blob/master/inventory/sample/inventory.ini
Generated using inventory builder Python utility:
https://github.com/kubernetes-sigs/kubespray#usage
bzurkowski
on 6 Nov 2019
Same problem here with the following error
"changed": false, "cmd": "/usr/local/bin/etcdctl --endpoints=https://10.8.26.92:2379,https://10.8.26.89:2379,https://10.8.26.87:2379 cluster-health | grep -q 'cluster is health
y'", "delta": "0:00:00.022949", "end": "2019-11-07 23:48:31.604721", "msg": "non-zero return code", "rc": 1, "start": "2019-11-07 23:48:31.581772", "stderr": "Error: client: etcd cluster is unavailable o
r misconfigured; error #0: dial tcp 10.8.26.92:2379: connect: connection refused\n; error #1: dial tcp 10.8.26.89:2379: connect: connection refused\n; error #2: dial tcp 10.8.26.87:2379: connect: connecti
on refused\n\nerror #0: dial tcp 10.8.26.92:2379: connect: connection refused\nerror #1: dial tcp 10.8.26.89:2379: connect: connection refused\nerror #2: dial tcp 10.8.26.87:2379: connect: connection refu
sed", "stderr_lines": ["Error: client: etcd cluster is unavailable or misconfigured; error #0: dial tcp 10.8.26.92:2379: connect: connection refused", "; error #1: dial tcp 10.8.26.89:2379: connect: conn
ection refused", "; error #2: dial tcp 10.8.26.87:2379: connect: connection refused", "", "error #0: dial tcp 10.8.26.92:2379: connect: connection refused", "error #1: dial tcp 10.8.26.89:2379: connect: c
onnection refused", "error #2: dial tcp 10.8.26.87:2379: connect: connection refused"], "stdout": "", "stdout_lines": []}
OS : Ubuntu 18.04
ansible version : 2.7
Any ideas ?
 jrabary
on 8 Nov 2019
jrabary
on 8 Nov 2019
Finally, I figured out the solution for my case. The time on my nodes was not synchronised and the generated certificats were not valide on some nodes during the installation.
jrabary
on 8 Nov 2019
Finally, I figured out the solution for my case. The time on my nodes was not synchronised and the generated certificats were not valide on some nodes during the installation.
Hi @jrabary,
Can you tell me how you fix it. Is it need to sync with NTP server or not...? Or just fix timezone?
 tanrobotix
on 20 Nov 2019
tanrobotix
on 20 Nov 2019
I noticed a feature. If you run the playbook from any node of the future cluster, then everything goes without errors.
If you start from the host ansible, then only changing the variable in etcd.yml helps
etcd_peer_client_auth: false
But this is not safe, so I consider the problem relevant.
 SaymonPhoenix
on 21 Nov 2019
SaymonPhoenix
on 21 Nov 2019
I ran into the same problem with time inconsistencies between servers. I installed chrony as an ntp server to sync the times and haven't had this problem since.
 danielcaldwell
on 27 Dec 2019
danielcaldwell
on 27 Dec 2019
My setup was on Baremetal, 2 Node cluster.
My Etcd was setting up in Master Node, which gave me the issue of cluster unavailable or misconfigured.
Now changed Etcd on Minion Node, fixed my problem.
 kushalarya
on 15 Jan 2020
kushalarya
on 15 Jan 2020
Etcd health checks are performed using host access IPs:
- name: Configure | Check if etcd cluster is healthy shell: "{{ bin_dir }}/etcdctl --endpoints={{ etcd_access_addresses }} cluster-health | grep -q 'cluster is healthy'"These are not the same as service bind address (
ipvs.access_ip):hosts: node1: ansible_host: 172.17.66.31 ip: 10.10.10.31 access_ip: 172.17.66.31 ansible_user: rootThere might be an incosistency between health check endpoint and address configuration for etcd:
# /etc/etcd.env ETCD_ADVERTISE_CLIENT_URLS=https://172.17.66.32:2379 ETCD_INITIAL_ADVERTISE_PEER_URLS=https://172.17.66.32:2380 ETCD_LISTEN_CLIENT_URLS=https://10.10.10.32:2379,https://127.0.0.1:2379 ETCD_LISTEN_PEER_URLS=https://10.10.10.32:2380 ETCD_INITIAL_CLUSTER=etcd1=https://172.17.66.31:2380,etcd2=https://172.17.66.32:2380,etcd3=https://172.17.66.33:2380
@bzurkowski
Let's say you remove access_ip and it works but in my inventory all three IP (ansible_host, ip, access_ip) are same. i did generate inventory using below
cp -r inventory/sample inventory/mycluster
declare -a IPS=(10.10.1.3 10.10.1.4 10.10.1.5)
CONFIG_FILE=inventory/mycluster/hosts.yml python3 contrib/inventory_builder/inventory.py ${IPS[@]}
all:
hosts:
node1:
ansible_host: 10.20.10.10
ip: 10.20.10.10
access_ip: 10.20.10.10
node2:
ansible_host: 10.20.10.11
ip: 10.20.10.11
access_ip: 10.20.10.11
How was your inventory have different IP address for ansible_host vs ip?
 hk1313
on 5 Feb 2020
hk1313
on 5 Feb 2020
Well, given:
hosts:
node1:
ansible_host: 172.17.66.31
ip: 10.10.10.31
access_ip: 172.17.66.31
ansible_user: root
172.17.66.31is the external address of the node - the address used for operations via SSH or to execute Ansible playbooks (i.e. provision the K8S cluster).10.10.10.31is the internal address of the node - this is the address from an internal network dedicated to network communication within the K8S cluster.
bzurkowski
on 5 Feb 2020
Also had this issue with some VMs and installing chrony for ntp fixed the issue. Is there a place in the requirements that mentions that host clock times need to be in sync or very close to in sync?
 davidcorbin
on 17 Feb 2020
davidcorbin
on 17 Feb 2020
I encountered this same error message.
the root cause in my case was that the time was not synchronized with chrony service and firewalld.
the readme on kubespray recommend to disable firewalld service or properly configure the firewall rules.
I configured the proper NTP server and tried to install on the same machine after i deleted the cert and key files. and stop and disabled firewalld service.
But it failed.
So I started from scratch on the new installed centos machine and i configured ntp at the first.
And tried to run "ansible-playbook".
now it works.
 cisco-simonyang
on 27 Feb 2020
cisco-simonyang
on 27 Feb 2020
This is frustrating as hell. Same issue on CentOS 7. Going to try to revert everything and install chrony first and add NTP server of each etcd and try to install k8s with ansible-playbook again :(
 Novitoll
on 7 Mar 2020
Novitoll
on 7 Mar 2020
On CentOS 7, installing chrony on masters and adding NTP servers to each other via chronyc, seems, resolved the issue. Firewalld is running as well.
Novitoll
on 11 Mar 2020
Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/lifecycle stale
 fejta-bot
on 9 Jun 2020
fejta-bot
on 9 Jun 2020
Stale issues rot after 30d of inactivity.
Mark the issue as fresh with /remove-lifecycle rotten.
Rotten issues close after an additional 30d of inactivity.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/lifecycle rotten
fejta-bot
on 9 Jul 2020
Rotten issues close after 30d of inactivity.
Reopen the issue with /reopen.
Mark the issue as fresh with /remove-lifecycle rotten.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/close
fejta-bot
on 8 Aug 2020
@fejta-bot: Closing this issue.
In response to this:
Rotten issues close after 30d of inactivity.
Reopen the issue with/reopen.
Mark the issue as fresh with/remove-lifecycle rotten.Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/close
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
 k8s-ci-robot
on 8 Aug 2020
k8s-ci-robot
on 8 Aug 2020
I still have the issue
null_resource.kubespray_create (local-exec): fatal: [k8s-kubespray-lab-master-0]: FAILED! => {"attempts": 4, "changed": false, "cmd": "/usr/local/bin/etcdctl --no-sync --endpoints=https://192.168.0.131:2379,https://192.168.0.132:2379,https://192.168.0.133:2379 cluster-health | grep -q 'cluster is healthy'", "delta": "0:00:03.060691", "end": "2020-08-11 21:19:14.811849", "msg": "non-zero return code", "rc": 1, "start": "2020-08-11 21:19:11.751158", "stderr": "", "stderr_lines": [], "stdout": "", "stdout_lines": []}
Ansible version
ansible 2.7.8
config file = None
configured module search path = ['/home/itsm3int/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']
ansible python module location = /usr/local/lib/python3.6/site-packages/ansible
executable location = /usr/local/bin/ansible
python version = 3.6.8 (default, Apr 2 2020, 13:34:55) [GCC 4.8.5 20150623 (Red Hat 4.8.5-39)]
I have read all the treads but I still get the error ..
Can you please help?
Thank you
 marco69
on 11 Aug 2020
marco69
on 11 Aug 2020
I forgot OS is CentOS 7.7 3 masters and 2 workers all on Centos7.7
marco69
on 11 Aug 2020
I also have this issue using ubuntu.
 cunningr
on 22 Aug 2020
cunningr
on 22 Aug 2020
Hey there,
I am having a similar issue with etcd check on my deployment. Using Ubuntu 18.04 and deploying Kubernetes 1.17.3.
TASK [etcd : Configure | Ensure etcd is running] *************************************************************
changed: [node1]
changed: [node2]
changed: [node3]
Monday 14 September 2020 10:00:46 +0200 (0:00:00.672) 0:04:38.288
Monday 14 September 2020 10:00:46 +0200 (0:00:00.131) 0:04:38.419 *
FAILED - RETRYING: Configure | Wait for etcd cluster to be healthy (4 retries left).
FAILED - RETRYING: Configure | Wait for etcd cluster to be healthy (3 retries left).
FAILED - RETRYING: Configure | Wait for etcd cluster to be healthy (2 retries left).
FAILED - RETRYING: Configure | Wait for etcd cluster to be healthy (1 retries left).
TASK [etcd : Configure | Wait for etcd cluster to be healthy] *********************************************************
fatal: [node1]: FAILED! => {"attempts": 4, "changed": false, "cmd": "set -o pipefail && /usr/local/bin/etcdctl endpoint --cluster status && /usr/local/bin/etcdctl endpoint --cluster health 2>&1 | grep -q -v 'Error: unhealthy cluster'", "delta": "0:00:05.079184", "end": "2020-09-14 10:01:29.559722", "msg": "non-zero return code", "rc": 1, "start": "2020-09-14 10:01:24.480538", "stderr": "{\"level\":\"warn\",\"ts\":\"2020-09-14T10:01:29.530+0200\",\"caller\":\"clientv3/retry_interceptor.go:62\",\"msg\":\"retrying of unary invoker failed\",\"target\":\"passthrough:///https://10.225.114.123:2379\",\"attempt\":0,\"error\":\"rpc error: code = DeadlineExceeded desc = latest balancer error: connection error: desc = \\"transport: Error while dialing dial tcp 10.225.114.123:2379: connect: connection refused\\"\"}\nFailed to get the status of endpoint https://10.225.114.123:2379 (context deadline exceeded)", "stderr_lines": ["{\"level\":\"warn\",\"ts\":\"2020-09-14T10:01:29.530+0200\",\"caller\":\"clientv3/retry_interceptor.go:62\",\"msg\":\"retrying of unary invoker failed\",\"target\":\"passthrough:///https://10.225.114.123:2379\",\"attempt\":0,\"error\":\"rpc error: code = DeadlineExceeded desc = latest balancer error: connection error: desc = \\"transport: Error while dialing dial tcp 10.225.114.123:2379: connect: connection refused\\"\"}", "Failed to get the status of endpoint https://10.225.114.123:2379 (context deadline exceeded)"], "stdout": "https://10.225.114.122:2379, 24606d18987b95e3, 3.4.13, 20 kB, false, false, 3, 20, 20, \nhttps://10.225.114.121:2379, f20b126fa80517fb, 3.4.13, 37 kB, true, false, 3, 20, 20, ", "stdout_lines": ["https://10.225.114.122:2379, 24606d18987b95e3, 3.4.13, 20 kB, false, false, 3, 20, 20, ", "https://10.225.114.121:2379, f20b126fa80517fb, 3.4.13, 37 kB, true, false, 3, 20, 20, "]}
NO MORE HOSTS LEFT ************************************************************************
PLAY RECAP **************************************************************************
localhost : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
node1 : ok=435 changed=13 unreachable=0 failed=1 skipped=471 rescued=0 ignored=0
node2 : ok=410 changed=13 unreachable=0 failed=0 skipped=412 rescued=0 ignored=0
node3 : ok=320 changed=14 unreachable=0 failed=0 skipped=347 rescued=0 ignored=0
node4 : ok=278 changed=9 unreachable=0 failed=0 skipped=316 rescued=0 ignored=0
 kimormiston
on 14 Sep 2020
kimormiston
on 14 Sep 2020
After using the reset.yml I have tried again to no avail and still get this error. I have applied most if not all of the recommended fixes out side of hashing out the etcd check as I don't want to have errors down the line.
From the troubleshooting I have done I have two thoughts around this issue
- Potentially a user security issue
- Certificates issue created by Kubespray in the process that is extrapolated by the user issue above...
Any help with this issue would be greatly appreciated.
kimormiston
on 14 Sep 2020
I noticed a feature. If you run the playbook from any node of the future cluster, then everything goes without errors.
👍
 koksario
on 15 Sep 2020
koksario
on 15 Sep 2020
I am having a same issue with etcd check on my deployment.
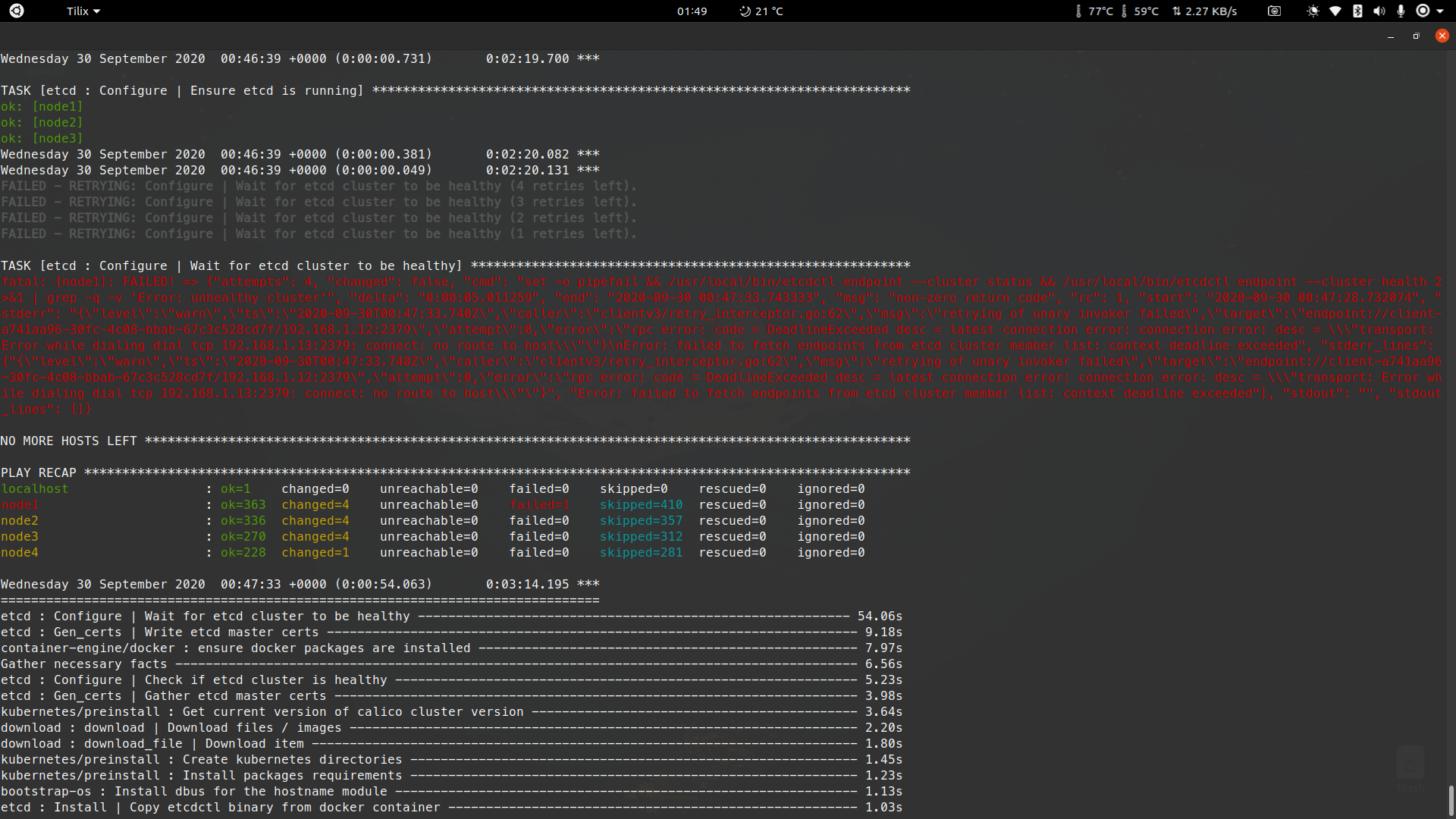
Any help
 GSalah
on 30 Sep 2020
GSalah
on 30 Sep 2020
I am having a same issue with etcd check on my deployment.
Any help
have same issuee. resolved by set timezone
 itsecforu
on 12 Oct 2020
itsecforu
on 12 Oct 2020
Related issues
 dylanzr
·
3Comments
dylanzr
·
3Comments
 dlifanov
·
3Comments
dlifanov
·
3Comments
 supabibz
·
3Comments
supabibz
·
3Comments
 jonathan-kosgei
·
4Comments
jonathan-kosgei
·
4Comments
 sermilrod
·
4Comments
sermilrod
·
4Comments
Most helpful comment
I ran into the same problem with time inconsistencies between servers. I installed chrony as an ntp server to sync the times and haven't had this problem since.