Ksql: Improve performance with large Avro schemas
Is your feature request related to a problem? Please describe.
When a schema supplied for a stream is somewhat large (example), UDFs become quite slow. @harlev did some performance investigation and found that the majority of the time is spent serializing/deserializing workloads.
It seems like we might be doing some extraneous work here. He was able to benchmark the same logic using other systems and achieved much better performance.
Separately from this, we may want to consider allowing people to enable org.apache.avro.fastread to achieve even faster perf.
 MichaelDrogalis
MichaelDrogalis
All 5 comments
On the same workload Flink performed ~6x better.
After applying the AVRO flags Flink performed ~8x better.
We applied these flags to ksqlDB, but got no performance improvement.
For the record. The issue is not specific to UDFs.
With the schema linked above, you can see the performance issue (especially with a profiler), even when running
select count(*) from my_stream group by 1 emit changes;
 harlev
on 26 Aug 2020
harlev
on 26 Aug 2020
The tl;dr of the tl;dr is that turning on the Avro flags won't help ksql much at all; the portion that is spent inside Avro code during deserialization is (shockingly) somewhat negligible (~11%).
Thanks for reporting this @harlev! I took this as an excuse to do dig into the performance aspects of ksql, something I haven't really had the time to do but truly enjoy... the tl;dr is that the ksqlDB data model is far from optimized but nothing is fundamentally wrong with our execution model (i.e. Kafka Streams). Most of the overhead is in ksql code, and we can get a few quick wins with minor investment (see below). Getting it on par with vanilla Avro performance, however, will require a concerted effort. I'm guessing that this is what you're comparing against when you use Flink because you plug in your own data handing code into Flink - a more "fair" comparison would be coding up your pipeline with Kafka Streams (I suspect you'll get similar performance).
Here's a heat graph of a benchmarking run with a medium sized schema:

We spend a surprising amount of time (~23%) just converting field names to uppercase. To make sure the profiler wasn't lying, I noticed that it claimed about 15% of the time was spent converting to upper case specifically in this part of the code:
private static Map<String, Field> getCaseInsensitiveFieldMap(final Schema schema) {
final Map<String, Field> fieldsByName = new HashMap<>();
schema.fields().forEach(
field -> fieldsByName.put(field.name().toUpperCase(), field)
);
return fieldsByName;
}
They way we have it implemented, this actually happens _per input record_ even though the schema rarely changes. I hacked in a cache for this to see what effect it might have to prove that it actually makes a difference and for a relatively small schema, I got about 15% improvement in deserialization speed (so this was in line with what the flame graph was telling me):
Benchmark (schemaName) (serializationFormat) Mode Cnt Score Error Units
SerdeBenchmark.deserialize metrics Avro avgt 3 8.172 ± 4.015 us/op
SerdeBenchmark.cached_dese metrics Avro avgt 3 7.194 ± 2.506 us/op
This means that it indeed takes a ton of time constructing this map and changing fields to upper case. If we're smarter about the way we handle our schemas I think we can improve this dramatically. I also suspect that because this is done per field, the overhead that ksqlDB adds here will get proportionally worse as the schema gets larger. To test that, I ran the profiler on a benchmark with a smaller schema:
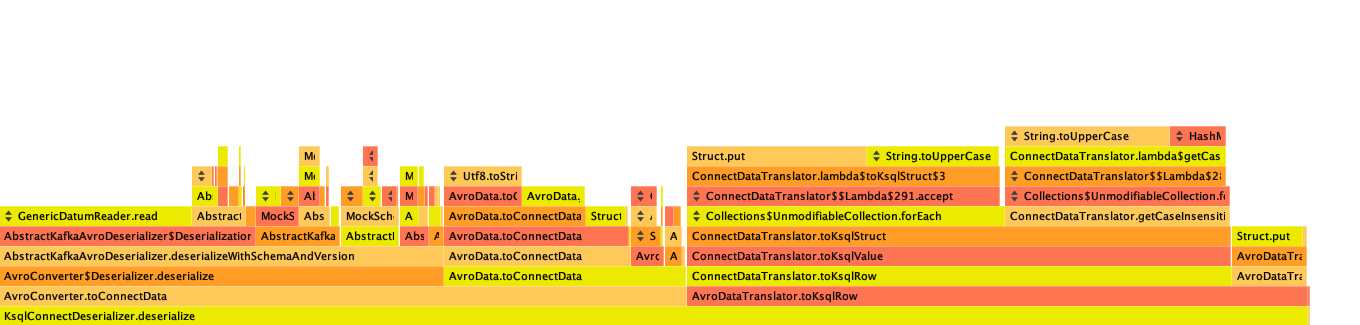
That seems to confirm my suspicion (you can immediately see that the AvroDataTranslator part of the heat graph is on takes up more for the larger schema as a percetnage - 49% vs 36% respectively).
There's another part of the code that uses this case-insensitive map as it was built to check if the Avro schema exists in the ksql generated schema (or the one taken from schema registry):
final String fieldNameUppercase = field.name().toUpperCase();
if (caseInsensitiveFieldMap.containsKey(fieldNameUppercase)) {
final Field connectField = caseInsensitiveFieldMap.get(fieldNameUppercase);
I changed this to first try to just get the name directly from the schema instead of getting it from the cache. This sped things up even further (about ~30% improvement from the original code).
Benchmark (schemaName) (serializationFormat) Mode Cnt Score Error Units
SerdeBenchmark.deserialize metrics Avro avgt 3 5.816 ± 2.392 us/op
After taking another flame graph of the performance after my optimizations, I noticed that at least now the GenericDatumReader#read method takes up more as a percentage of total time (phew - that's what I would expect!) but there's still a big chunk of time in AvroConverter and in AvroDataTranslator that are really just doing extra copies of the data:
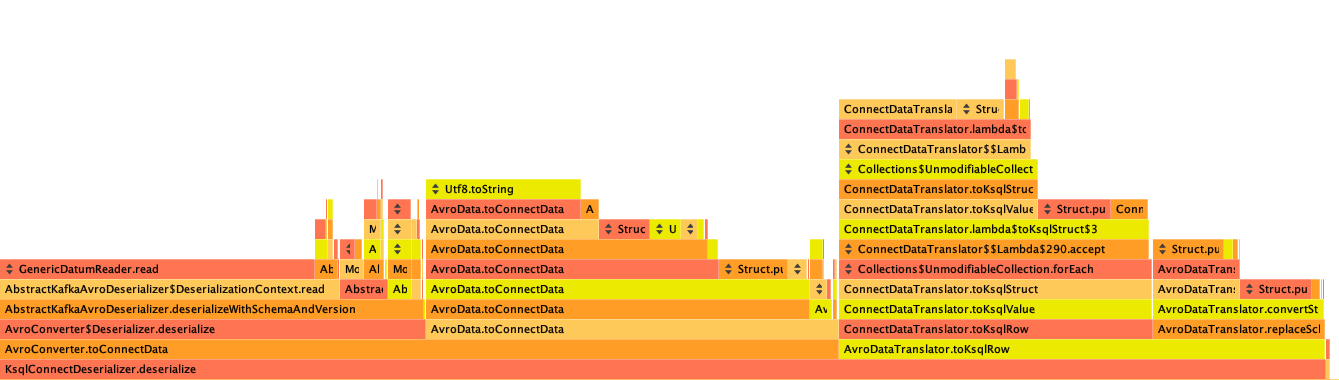
To hack away an optimization for those would be much harder, but I think the long-term strategy would be to move from an eager-copy into the connect data types to a model that just delegated to the underlying Avro data (or whatever the underlying type is) essentially implementing a zero-copy (ok, fine, a one-time-copy) interface.
I think the takeaway from this is that none of the performance issues with Avro (or other data types for that matter) stem from our execution model (Kafka Streams) - and that's the good news, because that's _much_ more difficult to change than our data model, where all of the problems happen. The bad news, is that we're not great with serialization overhead...
 agavra
on 11 Sep 2020
agavra
on 11 Sep 2020
Thanks for the awesome analysis @agavra ! I guess the good thing is that we have lots of opportunities for perf improvements :)
Should we file follow up issues to track the specific optimizations you prototyped? There are two high ROI itmes there which would be worth shipping sooner rather than later.
Also, do we have a ticket already about perhaps moving away from the connect data types and the performance overhead that that entails? If so, then it would be worth linking those tickets: the perf hit is perhaps yet another reason to prioritize that investment.
 apurvam
on 11 Sep 2020
apurvam
on 11 Sep 2020
@apurvam I added the following tickets to track this work: #6189 #6190 and #6191 detailing what I had in mind with the optimizations outlined above
agavra
on 12 Sep 2020
It's also worth noting that Avro is really not good at handling small object. Here's an example performance comparison of different serialization formats for small objects (objects with about 10 fields being serialized - i.e. most ksqlDB usecases): 
 big-andy-coates
on 16 Sep 2020
big-andy-coates
on 16 Sep 2020
Related issues
 sofianinho
·
4Comments
sofianinho
·
4Comments
 OferLahav
·
4Comments
OferLahav
·
4Comments
 Harshith2396
·
4Comments
Harshith2396
·
4Comments
 rmoff
·
4Comments
rmoff
·
4Comments
rmoff
·
4Comments
rmoff
·
4Comments
Most helpful comment
The tl;dr of the tl;dr is that turning on the Avro flags won't help ksql much at all; the portion that is spent inside Avro code during deserialization is (shockingly) somewhat negligible (~11%).
Thanks for reporting this @harlev! I took this as an excuse to do dig into the performance aspects of ksql, something I haven't really had the time to do but truly enjoy... the tl;dr is that the ksqlDB data model is far from optimized but nothing is fundamentally wrong with our execution model (i.e. Kafka Streams). Most of the overhead is in ksql code, and we can get a few quick wins with minor investment (see below). Getting it on par with vanilla Avro performance, however, will require a concerted effort. I'm guessing that this is what you're comparing against when you use Flink because you plug in your own data handing code into Flink - a more "fair" comparison would be coding up your pipeline with Kafka Streams (I suspect you'll get similar performance).
Here's a heat graph of a benchmarking run with a medium sized schema:
We spend a surprising amount of time (~23%) just converting field names to uppercase. To make sure the profiler wasn't lying, I noticed that it claimed about 15% of the time was spent converting to upper case specifically in this part of the code:
They way we have it implemented, this actually happens _per input record_ even though the schema rarely changes. I hacked in a cache for this to see what effect it might have to prove that it actually makes a difference and for a relatively small schema, I got about 15% improvement in deserialization speed (so this was in line with what the flame graph was telling me):
This means that it indeed takes a ton of time constructing this map and changing fields to upper case. If we're smarter about the way we handle our schemas I think we can improve this dramatically. I also suspect that because this is done per field, the overhead that ksqlDB adds here will get proportionally worse as the schema gets larger. To test that, I ran the profiler on a benchmark with a smaller schema:
That seems to confirm my suspicion (you can immediately see that the
AvroDataTranslatorpart of the heat graph is on takes up more for the larger schema as a percetnage - 49% vs 36% respectively).There's another part of the code that uses this case-insensitive map as it was built to check if the Avro schema exists in the ksql generated schema (or the one taken from schema registry):
I changed this to first try to just get the name directly from the schema instead of getting it from the cache. This sped things up even further (about ~30% improvement from the original code).
After taking another flame graph of the performance after my optimizations, I noticed that at least now the
GenericDatumReader#readmethod takes up more as a percentage of total time (phew - that's what I would expect!) but there's still a big chunk of time inAvroConverterand inAvroDataTranslatorthat are really just doing extra copies of the data:To hack away an optimization for those would be much harder, but I think the long-term strategy would be to move from an eager-copy into the connect data types to a model that just delegated to the underlying Avro data (or whatever the underlying type is) essentially implementing a zero-copy (ok, fine, a one-time-copy) interface.
I think the takeaway from this is that none of the performance issues with Avro (or other data types for that matter) stem from our execution model (Kafka Streams) - and that's the good news, because that's _much_ more difficult to change than our data model, where all of the problems happen. The bad news, is that we're not great with serialization overhead...