Kong: Kong 2.1.0 messes up responses when there're unhealthy upstream targets
Summary
Kong 2.1.0 messes up responses when there're unhealthy upstream targets. By messing up responses I mean a client get a response of another client. When I stressed test kong 2.10 with 100 concurrent threads, then I added an unhealthy target to service's upstream. I started to observe my stress test script reporting it was receiving different response than it expected.
I also attach a gist contains materials for a quick reproduce and PoC.
Steps To Reproduce
- Start kong 2.1.0-alpine container
- Add a service with ring-loadbalancer
- Stress test the service
- Make an upstream's target unhealthy (add an invalid target or take a target down)
Additional Details & Logs
- Kong version 2.1.0 with default configuration
- Operating system docker 19.03.12-ce
 nhamlh
nhamlh
All 19 comments
@hbagdi could you take time to look this? We got this bug on production env after upgrade from 2.0.3 to 2.1.0 and then we need revert Kong back to 2.0.3.
So, if any organizations or individuals are using 2.1.0, 2.1.1 versions, they need to know this bug soon.
Thank you so much!
 ehdieunguyen
on 12 Aug 2020
ehdieunguyen
on 12 Aug 2020
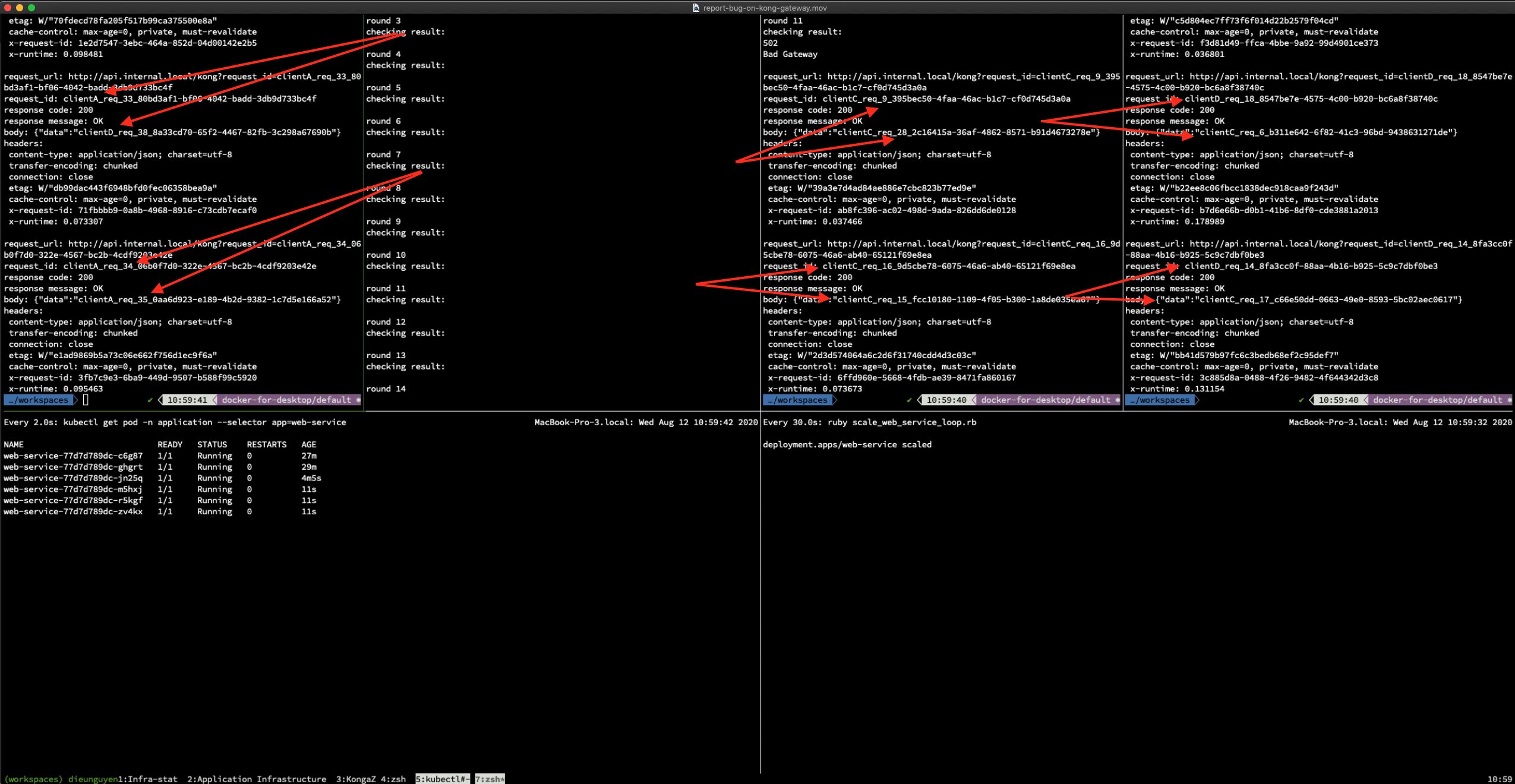
I also recorded a video when Kong 2.1.0 messes up responses.
The expectation is that request_id from the client needs to match with request_id in the server response. However, you can see they did not match.
Additional Details & Logs
- Docker Kubernetes
v 1.16.5on macOS 10.15.5 - Kong 2.1.0 deploy by Kong chart with Kong Ingress Controller
- One simple ruby web service
- Testing script Thanks @nguyenductoan for this!
ehdieunguyen
on 12 Aug 2020
i can not reproduce the error with Kong 2.0.5, so i guess this error appeared from 2.1.0
 nguyenductoan
on 12 Aug 2020
nguyenductoan
on 12 Aug 2020
Is this when leveraging upstreams exclusive or also single backend proxies? I wonder if the new upstream pool member logic to manage connections is playing a role here otherwise if on non LB proxies too. Hmm.
 jeremyjpj0916
on 12 Aug 2020
jeremyjpj0916
on 12 Aug 2020
@jeremyjpj0916 I faced this issue with LB proxy so I only reproduced it with LB.
nhamlh
on 12 Aug 2020
If I mark a target as unhealthy via the Admin API, it has no effect, i.e, it's still serving requests... is this expected? I'm running Kong 2.1.0 and set passive health checks with worker_consistency set to strict. I'm running Kong in hybrid mode.
Upstream:
{
"next": null,
"data": [
{
"client_certificate": null,
"created_at": 1597244441,
"id": "d04b4427-8cfc-4a38-9431-2b90d551be5d",
"tags": null,
"name": "UpstreamA",
"algorithm": "round-robin",
"hash_on_header": null,
"hash_fallback_header": null,
"host_header": null,
"hash_on_cookie": null,
"healthchecks": {
"threshold": 0,
"active": {
"unhealthy": {
"http_statuses": [
429,
404,
500,
501,
502,
503,
504,
505
],
"tcp_failures": 0,
"timeouts": 0,
"http_failures": 0,
"interval": 0
},
"type": "http",
"http_path": "\/",
"timeout": 1,
"healthy": {
"successes": 0,
"interval": 0,
"http_statuses": [
200,
302
]
},
"https_sni": null,
"https_verify_certificate": true,
"concurrency": 10
},
"passive": {
"unhealthy": {
"http_failures": 1,
"http_statuses": [
429,
500,
503
],
"tcp_failures": 1,
"timeouts": 1
},
"healthy": {
"http_statuses": [
200,
201,
202,
203,
204,
205,
206,
207,
208,
226,
300,
301,
302,
303,
304,
305,
306,
307,
308
],
"successes": 1
},
"type": "http"
}
},
"hash_on_cookie_path": "\/",
"hash_on": "none",
"hash_fallback": "none",
"slots": 10000
}
]
}
Targets:
{
"next": null,
"data": [
{
"created_at": 1597244451.786,
"id": "4ee4e4af-d138-46ec-ba06-e97d1b3a49d5",
"tags": null,
"weight": 100,
"target": "targetb.com:8010",
"upstream": {
"id": "d04b4427-8cfc-4a38-9431-2b90d551be5d"
}
},
{
"created_at": 1597244448.213,
"id": "943562b3-4339-46a7-b4d0-c53a104db04f",
"tags": null,
"weight": 100,
"target": "targeta.com:8009",
"upstream": {
"id": "d04b4427-8cfc-4a38-9431-2b90d551be5d"
}
}
]
}
Setting targeta.com:8009 as unhealthy via the Admin API does not work as the target keeps responding normally.
 murillopaula
on 12 Aug 2020
murillopaula
on 12 Aug 2020
Also after I take my server down, I tried to take it back up and it seems like the round-robin LB is not actually re-proxying requests to it. Even if I mark it as healthy manually via the Admin API I’m not able to see requests being proxied to it.
murillopaula
on 12 Aug 2020
Can this also be related? https://github.com/Kong/kong/issues/6112
murillopaula
on 12 Aug 2020
Hey folks,
Thanks for the bug report. We are currently investigating.
 dndx
on 13 Aug 2020
dndx
on 13 Aug 2020
I tried to reproduce this problem using Go server and client
Send this request
GET http://localhost:8000/?param=user-1-param-2-01efj2wetyz3b9yf7f6g0jz1j0
Accept: application/json
Header: user-1-header-2-01efj2wetyz3b9yf7f6g0jz1j0
{"body":"user-1-body-2-01efj2wetyz3b9yf7f6g0jz1j0"}
Server should response with
Header: user-1-header-2-01efj2wetyz3b9yf7f6g0jz1j0
{
"body":"user-1-body-2-01efj2wetyz3b9yf7f6g0jz1j0",
"header":"user-1-header-2-01efj2wetyz3b9yf7f6g0jz1j0",
"param":"user-1-param-2-01efj2wetyz3b9yf7f6g0jz1j0",
}
With Kong 2.1.1, Kong did mess up the request to upstream:
2020/08/13 05:12:14 Unmarshal: invalid character 'G' looking for beginning of value
2020/08/13 05:12:14 body: GET /?param=user-1-param-1-01efk3qf8ta87gvew3g3p619
2020/08/13 05:12:14 header: map[Accept-Encoding:[gzip] Connection:[keep-alive] Content-Length:[51] Header:[user-1-header-1-01efk3qf8ta87gvew3g3p6190y] User-Agent:[Go-http-client/1.1] X-Forwarded-For:[172.17.0.1] X-Forwarded-Host:[10.0.0.3] X-Forwarded-Port:[80] X-Forwarded-Prefix:[/] X-Forwarded-Proto:[http] X-Real-Ip:[172.17.0.1]]
2020/08/13 05:12:14 url: /?param=user-1-param-1-01efk3qf8ta87gvew3g3p6190y
Broken body of the request that sent to upstream: GET /?param=user-1-param-1-01efk3qf8ta87gvew3g3p619
This problem doesn't exist in Kong 2.0.3.
However as the go server could handle this error and response to correct request, there is no mess up between client sessions.
Here are the test code https://gist.github.com/thanhnl/3c762eb51e79cc4d8a1be691873e6b9a
 thanhnl
on 13 Aug 2020
thanhnl
on 13 Aug 2020
After change the request to this form GET http://localhost:8000/user-1-param-2-01efj2wetyz3b9yf7f6g0jz1j0 , the problem come clearly in Kong 2.1.1
## mismatch header:
request : user-1-header-0-01efkwt9wsbpxnc03dcdfx7td3
response: map[Content-Length:[117] Content-Type:[application/json] Date:[Thu, 13 Aug 2020 12:30:41 GMT] Header:[user-3-header-9-01efkwt9kh2jrnt5q8v9n4xmp1] Via:[kong/2.1.1] X-Kong-Proxy-Latency:[3] X-Kong-Upstream-Latency:[194]]
request: {user-1-body-0-01efkwt9wsbpxnc03dcdfx7td3 user-1-param-0-01efkwt9wsbpxnc03dcdfx7td3 user-1-header-0-01efkwt9wsbpxnc03dcdfx7td3}
body : {"body":"","param":"user-3-param-9-01efkwt9kh2jrnt5q8v9n4xmp1","header":"user-3-header-9-01efkwt9kh2jrnt5q8v9n4xmp1"}
## mismatch param:
request : user-1-param-0-01efkwt9wsbpxnc03dcdfx7td3
response: user-3-param-9-01efkwt9kh2jrnt5q8v9n4xmp1
request: {user-1-body-0-01efkwt9wsbpxnc03dcdfx7td3 user-1-param-0-01efkwt9wsbpxnc03dcdfx7td3 user-1-header-0-01efkwt9wsbpxnc03dcdfx7td3}
header : map[Content-Length:[117] Content-Type:[application/json] Date:[Thu, 13 Aug 2020 12:30:41 GMT] Header:[user-3-header-9-01efkwt9kh2jrnt5q8v9n4xmp1] Via:[kong/2.1.1] X-Kong-Proxy-Latency:[3] X-Kong-Upstream-Latency:[194]]
body : {"body":"","param":"user-3-param-9-01efkwt9kh2jrnt5q8v9n4xmp1","header":"user-3-header-9-01efkwt9kh2jrnt5q8v9n4xmp1"}
Test code https://gist.github.com/thanhnl/03033ab9911d168d97955e8f9f532270
thanhnl
on 13 Aug 2020
Hello everyone,
Thanks again for the detailed bug report and the reproduction steps. We can confirm the bug indeed occurs in Kong version >= 2.1.0.
This bug could be mitigated temporarily by disabling upstream keepalive pools. It can be achieved by either:
- In
kong.conf, setupstream_keepalive_pool_size=0, or - Setting the environment
KONG_UPSTREAM_KEEPALIVE_POOL_SIZE=0when starting Kong with the CLI.
Then restart/reload the Kong instance.
Please know that we are taking this bug very seriously. A new release containing the fix will be out as soon as possible. Please stay tuned.
dndx
on 13 Aug 2020
After a more comprehensive test as follow:
Clients send a bunch of request to a service behind kong with a request param, a header, and a body with the same value. Upstream service does an integrity check to these value, it'll output a debug log if the check fails. Upstream service then construct a json object of those values and return to clients. Clients also perform an integrity check with the response.
It looks like we're facing two different bugs:
- When clients send requests without body while there're unhealthy upstream targets. Clients start to get response of others.
Each request contains a tuple of param and header with the same value. The integrity check of server all passes.
- When clients send requests body while there're unhealthy upstream targets. Clients get back its own request, but the response body is a mess. The integrity check of server fails. More specifically, kong messed up the request body before sending it to upstream servers.
I updated the gist to quickly reproduce the cases.
nhamlh
on 13 Aug 2020
Oh thank @dndx. Please also consider the second case in my previous comment.
nhamlh
on 13 Aug 2020
@dndx I just want to ask again to confirm if the bug occurs in kong = 2.1.0 as you said kong > 2.1.0
nhamlh
on 13 Aug 2020
@nhamlh Yes, it occurs in Kong >= 2.1.0. Sorry for the confusion, I have updated the comment.
dndx
on 13 Aug 2020
@nhamlh If you are able, could you please give a try of https://github.com/Kong/kong/pull/6224? It should have fixed this issue according to my local tests.
dndx
on 13 Aug 2020
Hello everyone,
Thanks for your patience! We have released Kong 2.1.2 patch version which should fix this issue. Please give it a try.
Changelogs for 2.1.2: https://github.com/Kong/kong/blob/master/CHANGELOG.md#212
dndx
on 14 Aug 2020
Thank @dndx! I've just tested again with kong 2.1.2 and it looks like the bug is gone. I'm closing this issue now.
nhamlh
on 14 Aug 2020
Related issues
 vikaskmr1008
·
3Comments
vikaskmr1008
·
3Comments
 ghost
·
3Comments
ghost
·
3Comments
 lavoiedn
·
3Comments
lavoiedn
·
3Comments
 hbagdi
·
3Comments
hbagdi
·
3Comments
 carnei-ro
·
3Comments
carnei-ro
·
3Comments
Most helpful comment
Thank @dndx! I've just tested again with kong 2.1.2 and it looks like the bug is gone. I'm closing this issue now.