Keras: Model with stateful sub-model results in error on prediction
[X] Check that you are up-to-date with the master branch of Keras. You can update with:
pip install git+git://github.com/keras-team/keras.git --upgrade --no-deps[X] If running on TensorFlow, check that you are up-to-date with the latest version. The installation instructions can be found here.
I've tested this on Tensorflow 1.1 and 1.4
- [X] Provide a link to a GitHub Gist of a Python script that can reproduce your issue (or just copy the script here if it is short).
Here is the Gist showing the issue.
The Gist shows that (using the functional API):
A) predicting and training a Keras model based on a combination of non-stateful sub-models works,
B) predicting and training a Keras model using stateful processing, using a stateful RNN embedded in the training model (no stateful sub-model), works,
C) training of a Keras model using a stateful sub-model works, BUT predicting does NOT work!
It results in exception:
You must feed a value for placeholder tensor 'encoded-previous-response-context-input' with dtype float and shape [128,256]
[[Node: encoded-previous-response-context-input = Placeholder[dtype=DT_FLOAT, shape=[128,256], _device="/job:localhost/replica:0/task:0/cpu:0"]()]]
C) is the desired implementation for me since it allows me to reuse the sub-models for efficient inference.
This error occurs for any type of RNN, and both on CPU and GPU. Also the changing the way I concatenate features in the script doesn't change the outcome.
Is this a Keras bug, or am I missing something?
A bit more background
I’m developing a stateful sequence to sequence model for conversation modelling (chatbot). The conversation ‘context model’ (or conversation ‘context processor’) is the sub-model that should capture the conversation context over multiple chat turns, hence it is stateful.
I want to use separate encoder, context and decoder sub-models, to create the final training model, because that helps me in the inference phase after training.
However calling predict or predict_on_batch on the training model results in error when using a stateful context model as sub-model, see above. When the context model is not stateful there is no issue.
When the context processing is directly embedded in the training model, without the use of a sub-model, there is also no issue.
I personally think this is a bug in Keras but would like to hear your insights.
Thank you!
-- Freddy Snijder
 visionscaper
visionscaper
All 14 comments
To provide some more insight, I created this graph using (also see the Gist for the definition of train_model_stateful) :
from keras.utils import plot_model
plot_model(train_model_stateful, to_file='train_model_stateful.png')
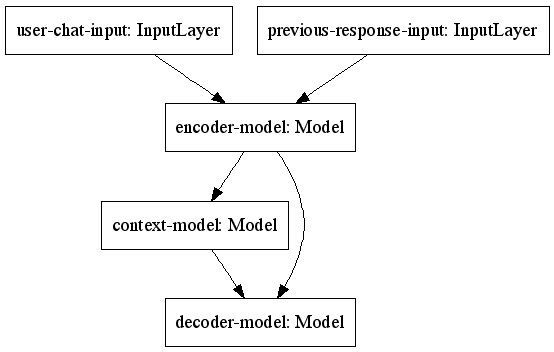
Anyone know why train_on_batch always works, and predict_on_batch only works when:
- the
context-modelis non-stateful, or, - when we don't use a sub-model for the context modelling but directly embed the context processing?
The graph for the model with context processing directly embedded (so not using a sub-model), looks like this:
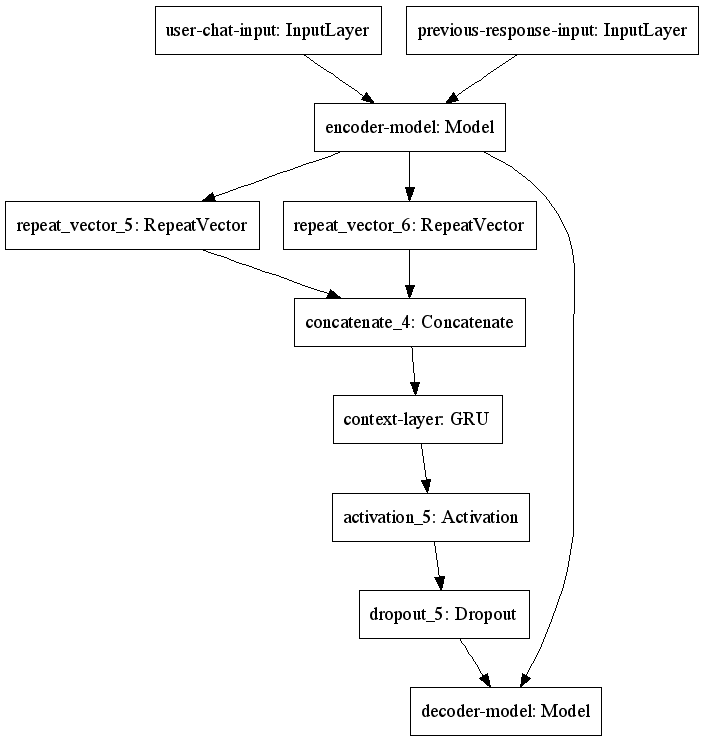
visionscaper
on 17 Jan 2018
i trained stacked autoencoder in greedy layerwise , which the encoder was non-stateful.
this is the code :
timesteps = x_train.shape[1]
input_dim = 1
inputs = Input(batch_shape=(1,timesteps, input_dim))
encoded = LSTM(num_units1)(inputs)
decoded = RepeatVector(timesteps)(encoded)
decoded = LSTM(input_dim,return_sequences = True)(decoded)
sequence_autoencoder = Model(inputs, decoded)
encoder = Model(inputs,encoded)
in the fine-tuning phase, i loaded these non-stateful encoders and it worked fine.
But, when i make these encoders STATEFUL and trained them again in greedy layerwise, the fine-tuning phase gave me error.
that is the error message:
InvalidArgumentError (see above for traceback): You must feed a value for placeholder tensor 'input_1_2' with dtype float and shape [1,1,13] [[Node: input_1_2 = Placeholderdtype=DT_FLOAT, shape=[1,1,13], _device="/job:localhost/replica:0/task:0/device:CPU:0"]]
This is my fine-tuning phase code:
# load three lstm layers
layer1 = load_model('encoder1.h5')
layer2 = load_model('encoder2.h5')
layer3 = load_model('encoder3.h5')
# rename layer2 and layer3
layer2.name = 'model_3'
layer3.name = 'model_4'
# built forecasting model
timesteps = x_train.shape[1]
input_dim = x_train.shape[2]
inputs = Input(batch_shape=(1,timesteps, input_dim))
lstm_1 = layer1(inputs)
reshape = Reshape((1,19))(lstm_1)
lstm_2 = layer2(reshape)
reshape = Reshape((1,13))(lstm_2)
lstm_3 = layer3(reshape)
outputs = Dense(1)(lstm_3)
model = Model(inputs,outputs)
model.compile(loss='mean_squared_error', optimizer='Adam')
for i in range(num_epochs):
print("Epoch ",i,":")
model.fit(x_train, y_train, epochs=1, batch_size=1, verbose=1,shuffle=False)
model.reset_states()
# evaluate model with validation data
mse = model.evaluate(x_valid,y_valid,batch_size=1)
rmse = sqrt(mse)
print("RMSE = ",rmse)
 DeepWolf90
on 5 Feb 2018
DeepWolf90
on 5 Feb 2018
@DeepWolf90 Do you get this error at 'model.evaluate()' or at 'model.fit()'?
visionscaper
on 5 Feb 2018
@visionscaper I get it at model.evaluate(), model.fit() works fine
DeepWolf90
on 5 Feb 2018
@DeepWolf90 That is exactly the issue that I have here. There is a work around that I use that might also work for you. Will need some more time to write this down, so I will come back later today/this week. Cliffhanger ;-)
visionscaper
on 5 Feb 2018
@visionscaper I tried a solution that proposed in keras issues also, which you add K.set_learning_phase() methode, but not working. I can't wait to hear from you.
DeepWolf90
on 5 Feb 2018
@DeepWolf90 To give a very brief answer:
a. Be sure to name all the layers in your models uniquely
b. Instead of using your loaded models directly, embed the layers that your loaded models consists of, directly in your new model.
c. per layer of the new model :
1. find the layer with the same name in the loaded models
2. transfer the weights from the loaded model to your new model (with get_weights() and set_weights())
Because embedding the layers of the models you load directly in the new model works with stateful layers (embedding stateful models does not work), with this trick you can load the weights of your original models that you have separately trained in the past.
I hope this helps for now.
visionscaper
on 5 Feb 2018
@visionscaper , thank you for your help.
please, would you verify my code after i changed it.
# load three lstm layers
layer1 = load_model('encoder1_stateful.h5')
layer2 = load_model('encoder2_stateful.h5')
layer3 = load_model('encoder3_stateful.h5')
layer2.name = 'model_3'
layer3.name = 'model_4'
# get LSTM layers from trained encoders
l1 = layer1.get_layer('lstm_1')
l2 = layer2.get_layer('lstm_1')
l3 = layer3.get_layer('lstm_1')
# get weights from LSTM layers
weights_l1 = l1.get_weights()
weights_l2 = l2.get_weights()
weights_l3 = l3.get_weights()
# built forecasting model
timesteps = x_train.shape[1]
input_dim = x_train.shape[2]
inputs = Input(batch_shape=(1,timesteps, input_dim))
lstm_1 = LSTM(19,name='lstm_19')(inputs)
reshape = Reshape((1,19))(lstm_1)
lstm_2 = LSTM(13,name='lstm_13')(reshape)
reshape = Reshape((1,13))(lstm_2)
lstm_3 = LSTM(24,name='lstm_24')(reshape)
outputs = Dense(1)(lstm_3)
model = Model(inputs,outputs)
#set weights of previously trained LSTMs to new model
z1 = model.get_layer('lstm_19')
z1.set_weights(weights_l1)
z2 = model.get_layer('lstm_13')
z2.set_weights(weights_l2)
z3 = model.get_layer('lstm_24')
z3.set_weights(weights_l3)
model.compile(loss='mean_squared_error', optimizer='Adam')
num_epochs = 3
for i in range(num_epochs):
print("Epoch ",i,":")
model.fit(x_train, y_train, epochs=1, batch_size=1, verbose=1,shuffle=False)
model.reset_states()
mse = model.evaluate(x_valid,y_valid,batch_size=1)
rmse = sqrt(mse)
print(rmse)
@DeepWolf90 I think this captures the idea of the workaround, but you did not make your lstm_1 to lstm_3 stateful; models layer1 to layer3 are stateful, correct?
As a side note, what I find a bit odd is why you have three models with just one LSTM layer, did you really train and save these models separately? It was not possible to train and save one model with 3 LSTM layers stacked?
Edit: Ah, I think I see what you are doing, you are training your encoder layer-wise, hence the layers trained and saved as separate models.
visionscaper
on 5 Feb 2018
@visionscaper Yes, i'm training three encoders layer-wise with one stateful LSTM and saved them, then loading and stacking them in fine-tuning phase.
DeepWolf90
on 6 Feb 2018
@DeepWolf90 ok, cool, in that case don't forget to make the corresponding layers in your forecasting model stateful as well.
visionscaper
on 6 Feb 2018
@visionscaper Oh!!! thank you man, i don't know how i forget to do that.
DeepWolf90
on 6 Feb 2018
@DeepWolf90 No problem :)
visionscaper
on 6 Feb 2018
@keras-team @fchollet I think this is a real bug related to the functional API somehow.
TLDR; for a model A with a stateful sub-model (the model is constructed with a set of other models), training works but predicting not. When you would directly embed the layers of the stateful sub-model in model A there is no issue.
visionscaper
on 6 Feb 2018
Related issues
 harishkrishnav
·
3Comments
harishkrishnav
·
3Comments
 oweingrod
·
3Comments
oweingrod
·
3Comments
 yil8
·
3Comments
yil8
·
3Comments
 amityaffliction
·
3Comments
amityaffliction
·
3Comments
 NancyZxll
·
3Comments
NancyZxll
·
3Comments
Most helpful comment
@DeepWolf90 To give a very brief answer:
a. Be sure to name all the layers in your models uniquely
b. Instead of using your loaded models directly, embed the layers that your loaded models consists of, directly in your new model.
c. per layer of the new model :
1. find the layer with the same name in the loaded models
2. transfer the weights from the loaded model to your new model (with
get_weights()andset_weights())Because embedding the layers of the models you load directly in the new model works with stateful layers (embedding stateful models does not work), with this trick you can load the weights of your original models that you have separately trained in the past.
I hope this helps for now.