Hi,
i tried to find information in the documentation but didn't find anything related to that. I also looked in the LSTM papers but wasn't able to find the information. So maybe it's missing documentation or I'm just to dumb.
I would like to know how e.g. 30 inputs are mapped to 10 lstm units.
There are several possibilities which I can imagine and could make sense. But non of them fit to the kernel weights when I plot them.
e.g.
10 LSTM units have 40 kernel weights (10 [units]*4 [gates]) - which is ok according to the LSTM paper from 1997.
but how are these now mapped to my 30 inputs? Are they applied in a sliding window approach where the windows has the size 10?
BR
 MarvinFollmann
MarvinFollmann
All 7 comments
I think you confuse "LSTM cell" with LSTM layer argument named "units".
In Keras, LSTM(units=N) means that every cell of LSTM layer have N neurons (at every moment the hidden state is vector with size N).
The number of LSTM cells is determined automatically (if you feed LSTM with input tensor with shape (150, 300) then 150 LSTM cells will be applied).
This is LSTM layer containing 3 LSTM Cells (not units):

Best LSTM tutorial I found so far:
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
Very detailed description of algorithm here:
http://deeplearning.net/tutorial/lstm.html
The original LSTM paper you can find here: http://deeplearning.cs.cmu.edu/pdfs/Hochreiter97_lstm.pdf
Keras LSTM implementation may also be helpful to understand how it works: https://github.com/fchollet/keras/blob/master/keras/layers/recurrent.py#L1122
 mahnerak
on 12 Aug 2017
mahnerak
on 12 Aug 2017
Thanks for your answer.
I looked into the original paper and I marked the parts of the LSTM Layer (in green), i marked one LSTM unit (in red) and a single LSTM cell (in purple).
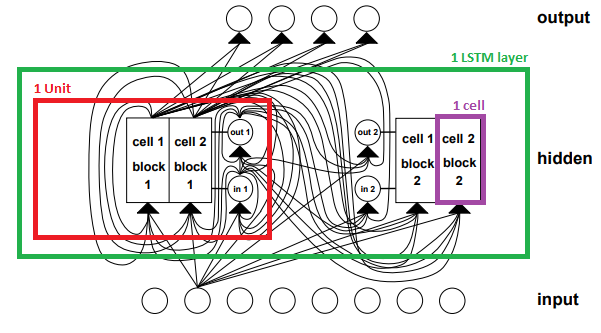
Source: Hochreiter 1997 - Page 9
But like the picture shows each input goes into all gates of each unit. So thats the point I don't get.
When I model a LSTM layer with 10 units, I get a recurrent weight matrix with 40 weights.
But the number of weights don't change when I change the number of inputs (in keras).
That means that there needs to be a way to apply a "random" number of inputs to a static LSTM layer.
I had a look at the implementation in keras. and in line 1145 they just take the first x inputs (number of units) as x_i. And before that, they do a time_distributed_dense in line 1074, maybe thats the "magic" how to apply a random number of inputs to a fixed number of weights.
I hope that this isn't a stupid question. Maybe I just miss something :-)
BR
MarvinFollmann
on 12 Aug 2017
Probably that figure is the reason of your confusion. LSTM is working like this. You have some function named step (which correspond to one LSTM Cell, takes vector x_t and two LSTM states h_t and c_t). When you have temporal data x_1, x_2, ..., x_T, the step function iterates (like reduce in functional programming) and gets the final result, like this:
h_0 = zeros
c_0 = zeros
h_1, c_1 = step(x_0, h_0, c_0)
h_2, c_2 = step(x_1, h_1, c_1)
...
h_T, c_T = step(x_(T-1), h_(T-1), c_(T-1))
LSTM_output = h_T
Weights are used only inside step function, thus their shape don't depend on input length (over time axis).
I strongly encourage you too look this article http://colah.github.io/posts/2015-08-Understanding-LSTMs/ to understand how LSTM works.
mahnerak
on 12 Aug 2017
This issue has been automatically marked as stale because it has not had recent activity. It will be closed after 30 days if no further activity occurs, but feel free to re-open a closed issue if needed.
![stale[bot] picture](https://avatars3.githubusercontent.com/in/1724?v=4&s=40) stale[bot]
on 10 Nov 2017
stale[bot]
on 10 Nov 2017
@mahnerak I want to have one clarification regarding the expansion of step function above. Does the step function execute recursively calling itself again and again pass old computed values of h_t-1 and c_t-1 to the next call to get h_t,c_t and so on
 shaifugpt
on 21 Nov 2017
shaifugpt
on 21 Nov 2017
@shaifugpt Right, every time it takes previous states h_t-1, c_t-1 (and also x_t-1) in order to compute new states h_t, c_t.
But actually it is not recursively calling itself. The backend functionK.rnn (same as theano.scan or tf.scan) makes it possible to apply the expression on sequences. (Low level-code is behind)
I don't know what's the main purpose of your question, so can't decide what to note in more detail.
mahnerak
on 21 Nov 2017
Thanks @mahnerak
I want to use all the previous hidden states for computing the values of the h_t instead of just h_t-1. For this I modified the step function in the LSTM to store the previous hidden state as: Here h_tm12 is defined to store all states.
var_exists = 'h_tm12' in locals() or 'h_tm12' in globals()
if(var_exists):
h_tm12=numpy.vstack((h_tm12,states[0]))
else:
h_tm12 = states[0]
But h_tm12 shows the same size as states[0]. I expected it to be timesteps x states [0]. I expect that the step function executes once for every timestep. But the size does does not seem to agree to that. This is why I wondered if or not it is running in a loop so that I can save all the previous states while training to use them
shaifugpt
on 21 Nov 2017
Related issues
 MarkVdBergh
·
3Comments
MarkVdBergh
·
3Comments
 amityaffliction
·
3Comments
amityaffliction
·
3Comments
 oweingrod
·
3Comments
oweingrod
·
3Comments
 LuCeHe
·
3Comments
LuCeHe
·
3Comments
 NancyZxll
·
3Comments
NancyZxll
·
3Comments
Most helpful comment
I think you confuse "LSTM cell" with LSTM layer argument named "units".
In Keras,
LSTM(units=N)means that every cell of LSTM layer haveNneurons (at every moment the hidden state is vector with size N).The number of LSTM cells is determined automatically (if you feed LSTM with input tensor with shape
(150, 300)then150LSTM cells will be applied).This is LSTM layer containing 3 LSTM Cells (not units):

Best LSTM tutorial I found so far:
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
Very detailed description of algorithm here:
http://deeplearning.net/tutorial/lstm.html
The original LSTM paper you can find here: http://deeplearning.cs.cmu.edu/pdfs/Hochreiter97_lstm.pdf
Keras LSTM implementation may also be helpful to understand how it works: https://github.com/fchollet/keras/blob/master/keras/layers/recurrent.py#L1122