Keras: Documentation Gap: GRU recurrent weights and layer connection
Hi,
I searched for explanations about how the layers of LSTMs/GRUs are connected to each other, and how or if the layer's cells are connected to each other. Another question is how the first layer is connected to the input.
I found some older issues in the repo about that. I will list and comment them later.
First I want to show you my test model with 3 GRU cells with 30 inputs, and 1 Dense layer with 30 outputs which I used to figure out how many weights the model gets and how they are used:
model.add(GRU(3,
return_sequences=False,
input_shape=(30, 1),
name="GRU_1",
use_bias=True))
model.add(Dense(30,
activation=ACTIVATION,
name="OUTPUT_LAYER"))
When I use get_weights to get the weights of a layer I get some matrixes.
the first one is the kernel, the second one the recurrent, the third one the bias.
This is the plot I made:

source code of keras GRU:
736: self.kernel = self.add_weight(shape=(self.input_dim, self.units * 3).... ...)
741: self.recurrent_kernel = self.add_weight(shape=(self.units, self.units * 3).... ...)
749: self.bias = self.add_weight(shape=(self.units * 3,),.... ...)
that explains the 3 weight matrices and the number of weights in it.
So the kernel weights are the input weights, 33 makes sense here. One input for each gate of each cell, right?
But why do they do unit * unit * 3 weights for the recurrent layer? The 3 is the number of gates. Because I used GRU, there is a 3. If I would use LSTM, then we get *4 (1 more gate)
In issue 4149 the people said that the cells aren't connected to each other on the same layer. But when I plot the weights of my first layer (the GRU layer) It looks like they are connected to each other. What else should be the reason for 3(33) weights for the recurrent layer? When only one cell is recurrent to ifself it would be 33 weights.
In 4149 it's also stated that the layers are fully connected, which seams to be correct.
I made some more plots for different GRU unit counts, and saw that the weights are independent to the input/output shape (because i always use 1 feature dim)
Thats correct, the source says: self.input_dim = input_shape[2].
In issue 2673 they said that the first layer is not fully connected to the input. I think, that this is corrent,..
But how are my 30 inputs mapped to this 9 input weights? With 3 inputs it would make sense to have 3 or 9 weights (for each gate input)... but with 30 inputs?
In the original paper they show on page 9, that ALL inputs are connected to ALL gates. I think that this is also done in keras.
Are the inputs then applied like:
- 1: input[0:3]
- 2: input[1:4]
- 3: ...
- n: input[n-3:,n] ?
BR
 MarvinFollmann
MarvinFollmann
All 2 comments
This issue has been automatically marked as stale because it has not had recent activity. It will be closed after 30 days if no further activity occurs, but feel free to re-open a closed issue if needed.
![stale[bot] picture](https://avatars3.githubusercontent.com/in/1724?v=4&s=40) stale[bot]
on 4 Nov 2017
stale[bot]
on 4 Nov 2017
Surprisingly little web-info on this topic; my findings:
Kernel weights = [input_dim] x [num_gates * layer_dim]
Recurrent weights = [layer_dim] x [num_gates * layer_dim]
Bias weights = ________[1] x [num_gates * layer_dim]
num_gates = 3 for GRU, = 4 for LSTM. layer_dim = # of hidden units
Keras GRU gates: UPDATE (z), RESET (r), NEW (h)-- IMG1
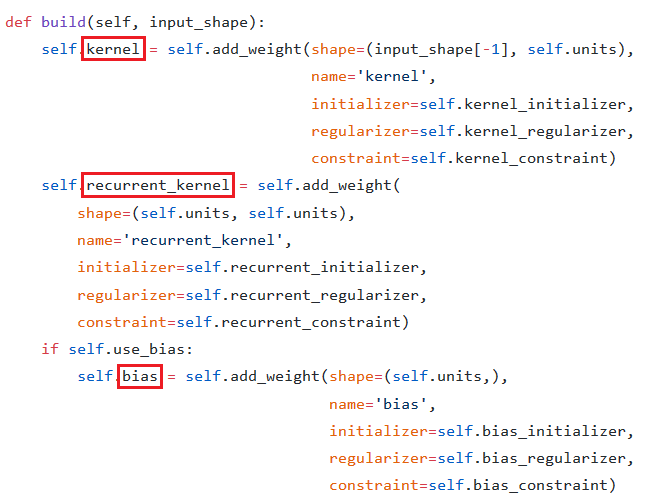
It's often of interest to know _which gate_ the weights correspond to; in your example, layer_dim=3, and you see 3*3=9 columns for each weight matrix; which three belong to, say, the update gate? Digging further into the source code -- IMG2 -- the weights appear to be aligned with order of declaration:
[UPDATE -- hidden_00] [UPDATE -- hidden_01] [UPDATE -- hidden_02] | [RESET -- hidden_00] ...
[UPDATE -- hidden_10] [UPDATE -- hidden_11] [UPDATE -- hidden_12] | [RESET -- hidden_01] ...
[UPDATE -- hidden_20] [UPDATE -- hidden_21] [UPDATE -- hidden_22] | [RESET -- hidden_02] ...
I'm not familiar with TensorFlow's graph build syntax, but Keras' model.layers[].get_weights() orders weights exactly in order of source code declaration; can be verified further by printing individual weights and comparing against a heatmap plot.
Fine inquiry.
IMG1

IMG2
 OverLordGoldDragon
on 5 May 2019
OverLordGoldDragon
on 5 May 2019
Related issues
 anjishnu
·
3Comments
anjishnu
·
3Comments
 rantsandruse
·
3Comments
rantsandruse
·
3Comments
 snakeztc
·
3Comments
snakeztc
·
3Comments
 oweingrod
·
3Comments
oweingrod
·
3Comments
 MarkVdBergh
·
3Comments
MarkVdBergh
·
3Comments
Most helpful comment
Surprisingly little web-info on this topic; my findings:
Kernel weights =
[input_dim] x [num_gates * layer_dim]Recurrent weights =
[layer_dim] x [num_gates * layer_dim]Bias weights =
________[1] x [num_gates * layer_dim]num_gates= 3 for GRU, = 4 for LSTM.layer_dim= # of hidden unitsKeras GRU gates: UPDATE (z), RESET (r), NEW (h)--
IMG1It's often of interest to know _which gate_ the weights correspond to; in your example,
layer_dim=3, and you see3*3=9columns for each weight matrix; which three belong to, say, the update gate? Digging further into the source code --IMG2-- the weights appear to be aligned with order of declaration:I'm not familiar with TensorFlow's graph build syntax, but Keras'
model.layers[].get_weights()orders weights exactly in order of source code declaration; can be verified further by printing individual weights and comparing against a heatmap plot.Fine inquiry.
IMG1

IMG2
