Keras: Sudden accuracy drop when training LSTM or GRU
Hi! My recurrent neural network (LSTM, resp. GRU) behaves in a way I cannot explain. The training starts and it trains well (the results look quite good) when suddenly accuracy drops (and loss rapidly increases) - both training and testing metrics. Sometimes the net just _goes crazy_ and returns random outputs and sometimes (as in the last of three given examples) it starts to return _same output to all the inputs_.

Do you have any explanation for this behavior? Any opinion is welcome. Please, see the task description and the figures below.
The task: From a word predict its word2vec vector
The input: We have an own word2vec model (normalized) and we feed the network with a word (letter by letter). We pad the words (see the example below).
Example: We have a word _football_ and we want to predict its word2vec vector which is 100 dimensions wide. Then the input is $football$$$$$$$$$$.
Three examples of the behavior:
Single layer LSTM
model = Sequential([
LSTM(1024, input_shape=encoder.shape, return_sequences=False),
Dense(w2v_size, activation="linear")
])
model.compile(optimizer='adam', loss="mse", metrics=["accuracy"])

Single layer GRU
model = Sequential([
GRU(1024, input_shape=encoder.shape, return_sequences=False),
Dense(w2v_size, activation="linear")
])
model.compile(optimizer='adam', loss="mse", metrics=["accuracy"])

Double layer LSTM
model = Sequential([
LSTM(512, input_shape=encoder.shape, return_sequences=True),
TimeDistributed(Dense(512, activation="sigmoid")),
LSTM(512, return_sequences=False),
Dense(256, activation="tanh"),
Dense(w2v_size, activation="linear")
])
model.compile(optimizer='adam', loss="mse", metrics=["accuracy"])

We have also _experienced this kind of behavior in another project before_ which used similar architecture but its objective and data were different. Thus the reason should not be hidden in the data or in the particular objective but rather in the architecture.
 marekmodry
marekmodry
All 19 comments
My only 2 cents is that in the original W2V paper they used a shallow FFNN so there must be something about the RNN structures. I would think exploding/vanishing gradient but you are seeing it with the LSTM so....
 gcgibson1989
on 9 Aug 2016
gcgibson1989
on 9 Aug 2016
I have already experienced the same behavior with non-word2vec data and the behavior was very similar. Any idea on how to extract gradients from Keras? ... in order to examine closer whether the gradient is exploding/vanishing/... ?
marekmodry
on 9 Aug 2016
I'm seeing something similar with a single layered LSTM classifier on acoustic data. After around 50 epochs, the loss suddenly started increasing and training and validation accuracy dropped badly.
modelV1 = Sequential()
modelV1.add(LSTM(60, return_sequences=False,
input_shape=(20, 3), activation='relu'))
modelV1.add(Dropout(0.2))
modelV1.add(Dense(7, activation='softmax'))
modelV1.compile(loss='categorical_crossentropy',
optimizer='Nadam',
metrics=['accuracy'])
modelV1.fit(F_train, V1_train, nb_epoch=100, validation_split=0.15)
Edit: I have two separate test sets and the really weird thing is the model evaluates similar to training/validation (i.e. badly) on one but seems to perform decently on the other.
 irfus
on 14 Sep 2016
irfus
on 14 Sep 2016
Oh I had the same problem. Very annoying. I trained a network with LSTM and also used (word2vec), and got a sudden drop as in below:
Epoch 37/500
6400/6400 [==============================] - 44s - loss: 1.6209 - acc: 0.4892 - val_loss: 1.7309 - val_acc: 0.4562
Epoch 38/500
6400/6400 [==============================] - 44s - loss: 1.6402 - acc: 0.4805 - val_loss: 1.6928 - val_acc: 0.4463
Epoch 39/500
6400/6400 [==============================] - 44s - loss: 1.6328 - acc: 0.4917 - val_loss: 1.6404 - val_acc: 0.5044
Epoch 40/500
6400/6400 [==============================] - 44s - loss: 2.2682 - acc: 0.3142 - val_loss: 2.7337 - val_acc: 0.1806
Epoch 41/500
6400/6400 [==============================] - 44s - loss: 2.7492 - acc: 0.1811 - val_loss: 2.6720 - val_acc: 0.1806
Epoch 42/500
6400/6400 [==============================] - 44s - loss: 2.6774 - acc: 0.1814 - val_loss: 2.6636 - val_acc: 0.1806
Epoch 43/500
6400/6400 [==============================] - 44s - loss: 2.6739 - acc: 0.1814 - val_loss: 2.6631 - val_acc: 0.1806
 ylmeng
on 3 Nov 2016
ylmeng
on 3 Nov 2016
I have the same problem in a normal CNN using TensorFlow backend in keras. The loss frops to about 10^-7. Anybody an idea why this happens?
 LetiP
on 4 Jan 2017
LetiP
on 4 Jan 2017
Has this problem any solution yet!? It quite frustrating to have the training go bananas all of a sudden.
I have run other CNN architectures on the same data with no problems but maybe it is some problem with sending in multiple references to the same data as I do? (I haven't tried inputting copies instead, training takes a day.)
Here is what I do: (I have only 2 classes but use categorical_crossentropy because I will have more later)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
....
history = model.fit([X_data_x,X_data_x,X_data_x, X_data_y,X_data_y,X_data_y], Y_data, validation_split=0.25, nb_epoch=epochs, batch_size=batch_size,callbacks=callbacks)
 pinkponk
on 21 Mar 2017
pinkponk
on 21 Mar 2017
It happens when somehow log returns NaN
 thisismohitgupta
on 13 Apr 2017
thisismohitgupta
on 13 Apr 2017
when I train model, using CNN with relu , acc and val_acc suddenly get zero.I'm clueless on what to do with this. It's bug?

 hongguangguo
on 15 May 2017
hongguangguo
on 15 May 2017
Switched from theano to Tensorflow today and saw this kind of thing happen for the first time ever.
Training went down to the expected best loss (~0.3), accuracy of ~91%, for the task at hand and then proceeded to suddenly go up to 15+ with an accuracy of less than 2%. It then stayed there, did not bounce back. Something must be numerically instable? This is on a wide residual network, no RNNs involved.
My learning rate at this point was 0.00005 using Adam.
Maybe this is what happened at least to me, and maybe some others in this thread: https://stackoverflow.com/a/42420014/5709630
However it does seem... odd that I've trained this setup dozens of times using theano and never saw this happen and now, during the very first run with tensorflow it happens. Maybe something in the theano backend handles this better?
Or it uses float64 in the place that matters, the reason I am trying tensorflow is because I could not get theano to stop doing that.
 ColaColin
on 7 Jun 2017
ColaColin
on 7 Jun 2017
This issue has been automatically marked as stale because it has not had recent activity. It will be closed after 30 days if no further activity occurs, but feel free to re-open a closed issue if needed.
![stale[bot] picture](https://avatars3.githubusercontent.com/in/1724?v=4&s=40) stale[bot]
on 5 Sep 2017
stale[bot]
on 5 Sep 2017
maybe because the relu,
The ReLU units can irreversibly die during training since they can get knocked off the data manifold. For example, you may find that as much as 40% of your network can be “dead” (i.e., neurons that never activate across the entire training dataset) if the learning rate is set too high. With a proper setting of the learning rate this is less frequently an issue.
read more about it in here : http://lamda.nju.edu.cn/weixs/project/CNNTricks/CNNTricks.html
 wildanputra
on 17 Oct 2017
wildanputra
on 17 Oct 2017
@wildanputra I don't believe that the dead relus would cause the network to drop the accuracy so suddenly. Moreover, in our initial case, there were no relus.
marekmodry
on 19 Oct 2017
I am using Keras framework and this happened to me only when I use SGD or nadam optimizer. It only works if I use adam optimizer. My model is 3 layers of LSTMs each with 100 cells.
 MohammedSalman
on 26 Jan 2018
MohammedSalman
on 26 Jan 2018
In my case, reducing the initial learning rate and adding decay helped.
 vmarkovtsev
on 4 Mar 2018
vmarkovtsev
on 4 Mar 2018
This happened to me as well in two different RNN-based NLP tasks.
One is using LSTM to predict topic of document, another one is a bidirectional GRU-language model to predict next word.
GRU activation tanh
LSTM activation tanh
Optimizer adam with configurations lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0
Loss categorical_cross_entropy and KL_divergence
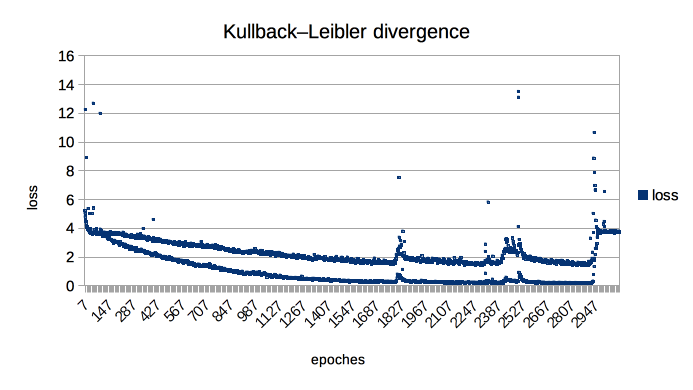
any clue on this?
 newbiesitl
on 10 Mar 2018
newbiesitl
on 10 Mar 2018
Same here. NLP task with bidirectional LSTMs, using rmsprop and categorical_crossentropy. ReLU units throughout. Will try with tanh activations, but I've seen those are slow.
 free-variation
on 12 Mar 2018
free-variation
on 12 Mar 2018
I also faced this issue multiple times and it seems to me this is linked to vanishing gradient/dead neuron issue.
What helped (although it didn't solve the issue in all cases) was this:
- replace ReLU with SeLU
- check the input distribution and rescale it if it is too centered around 0 (you may want to add several standard deviations and/or multiply by a factor 2 or 3)
 GregVial
on 25 Apr 2018
GregVial
on 25 Apr 2018
Using tanh fixed the issue for me, without significant loss of performance.
free-variation
on 26 Apr 2018
For me, reducing the learning rate of ADAM from lr=0.001 to lr=0.0005 fixed it, using a single layer LSTM (ELU) for a classification problem.
 Dawei84
on 28 Jun 2019
Dawei84
on 28 Jun 2019
Related issues
 Imorton-zd
·
3Comments
Imorton-zd
·
3Comments
 oweingrod
·
3Comments
oweingrod
·
3Comments
 amityaffliction
·
3Comments
amityaffliction
·
3Comments
 NancyZxll
·
3Comments
NancyZxll
·
3Comments
 zygmuntz
·
3Comments
zygmuntz
·
3Comments