Keras-retinanet: Performance of batch_size > 1
Theoretically batch_size > 1 should be working, practically however performance appears to degrade. I've looked at the data generator and loss functions but everything appears to be fine.
I'm not sure where the degradation of performance comes from, perhaps a fresh set of eyes can help uncover the issue? My intuition expects the problem to be in the loss function, or a deeper issue in Keras / Tensorflow perhaps.
In extension, this also breaks multi GPU support since that requires batch_size > 1.
@awilliamson I think you ran some tests on this right? Do you still have them stored somewhere? Can you share them?
 hgaiser
hgaiser
All 24 comments
Now that https://github.com/fizyr/keras-retinanet/pull/339 is merged, we should re-evaluate if this is still broken. https://github.com/fizyr/keras-retinanet/pull/339 might affect these results. Is anyone interested in testing this? I wouldn't test it in combination with multi-gpu however, only single-gpu.
hgaiser
on 27 Mar 2018
Hi!
I can fire up training with batch size 16 today. Will post here if i see anything odd.
Thanks!
 sorinpanduru
on 27 Mar 2018
sorinpanduru
on 27 Mar 2018
Any update on this?
hgaiser
on 3 Apr 2018
Hi!
Sorry, I've been busy with other things.
I only started training yesterday with batch size 10 on my own dataset. Looks pretty ok so far, but still need to redo it with batch size 1 so we can compare.
sorinpanduru
on 3 Apr 2018
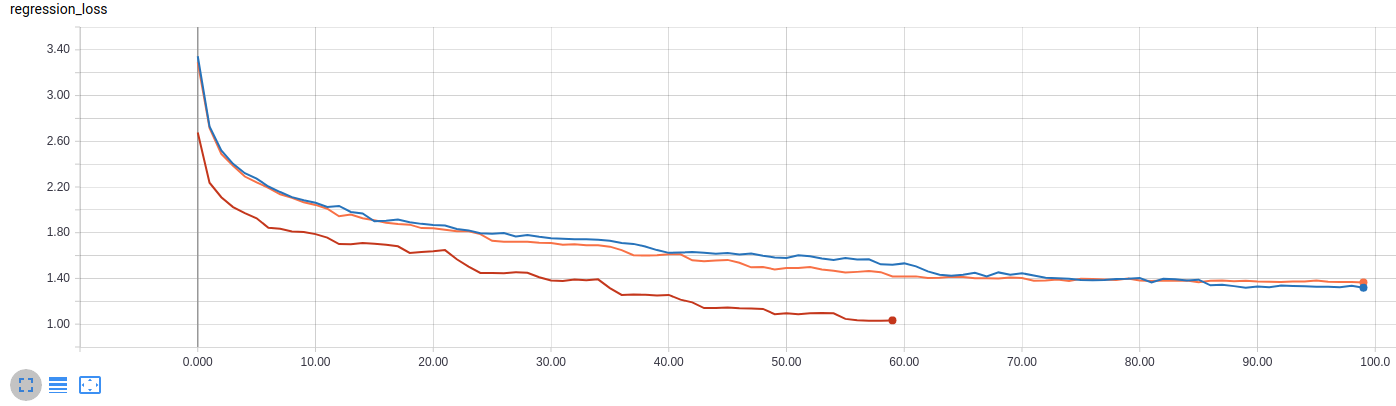
@hgaiser here're my training results of resnet50 on coco.
red: batch_size=2, steeps=5000, lr=1e-5
blue: batch_size=1, steeps=5000, lr=1e-5
Also, I'm training batch_size=4, lr=1e-4 with 2*1080ti(--no-evaluation,evaluation running on cpu is super slow).
I think It works.


 jjiunlin
on 3 Apr 2018
jjiunlin
on 3 Apr 2018
Ah awesome. @sorinpanduru let me know if you can confirm the same behaviour. If so, I'll close this issue.
hgaiser
on 3 Apr 2018
I think this is quite premature. All this shows is that using batch_size=2 has some stabilising effect on training vs batch_size=1.
IMO the issue should not be closed until someone can train a network at a decently large batch_size (say ~8) that converges to the (around) same value as batch_size=1, and in fewer iterations.
 yhenon
on 3 Apr 2018
yhenon
on 3 Apr 2018
@yhenon I agree with you.
I get OOM issue when training with batch_size=4 on 2 gpus.

jjiunlin
on 3 Apr 2018
I did a training for my custom dataset with differents batch sizes. My dataset are made by small images, so I changed the default min-side-size and max-size-side calling the script in this way:
"python .\keras_retinanet\bin\train.py --backbone=mobilenet128_1.0 --ima
ge-min-side=200 --image-max-side=400 --epochs=100 --batch-size=8 csv data2train.txt classMap.txt
"
It was trained on a 1070ti, which with batch-size=1 took around 2gb of gpu memory and 80ms per iteration, with batch-size=8 took 2.7gb and 160ms per iteration
The training time was around 15hrs for each training, here is my results:
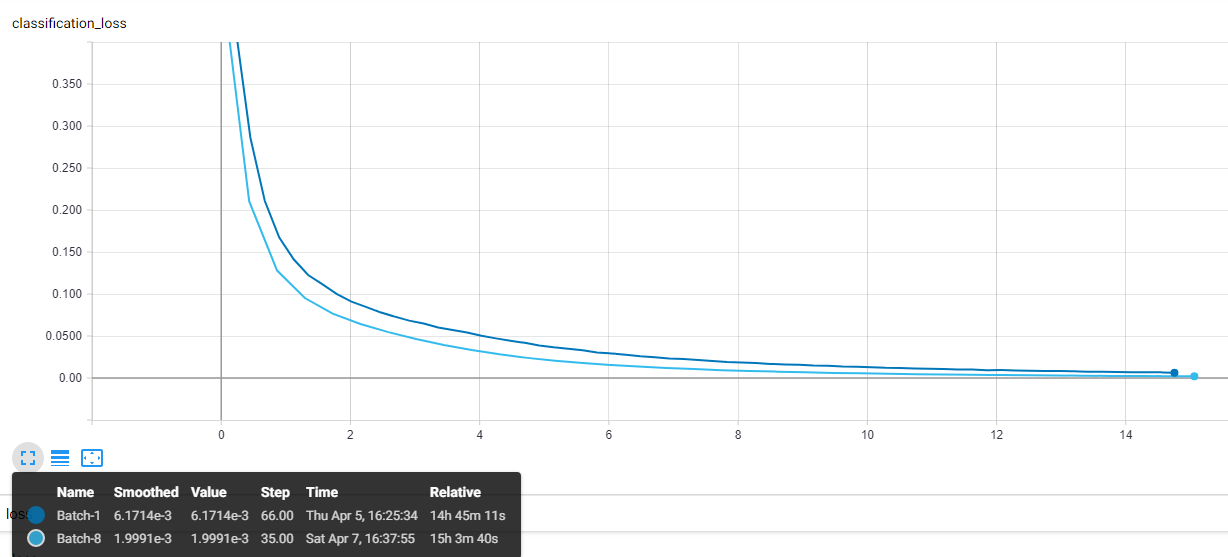

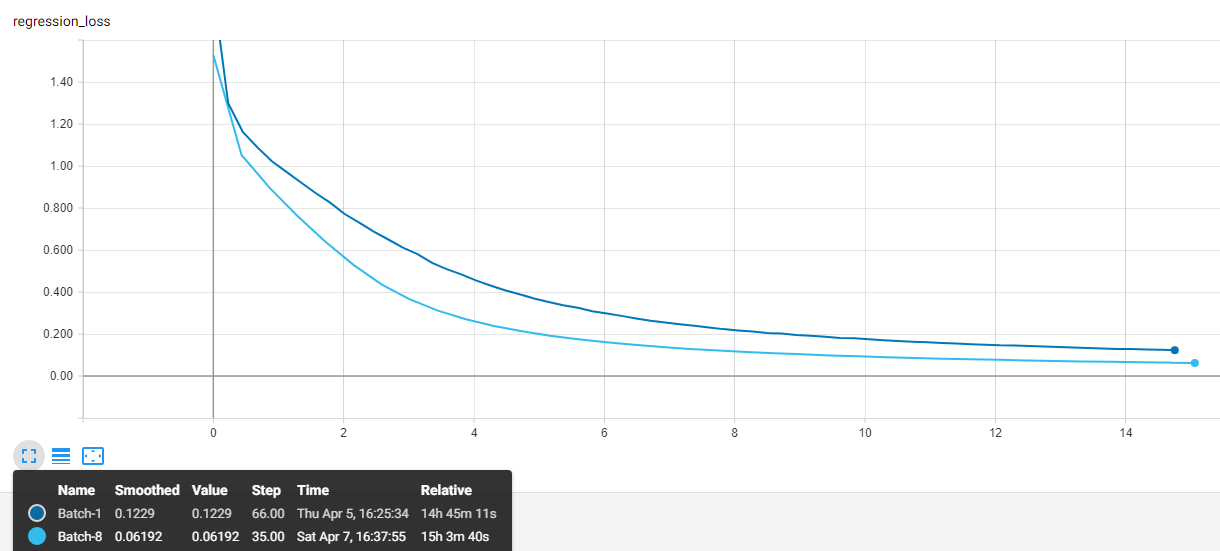
I also can train with large batch sizes if is needed.
I hope this can help.
 rodrigo2019
on 7 Apr 2018
rodrigo2019
on 7 Apr 2018
Thanks @rodrigo2019 , those seem to be nice results!
hgaiser
on 11 Apr 2018
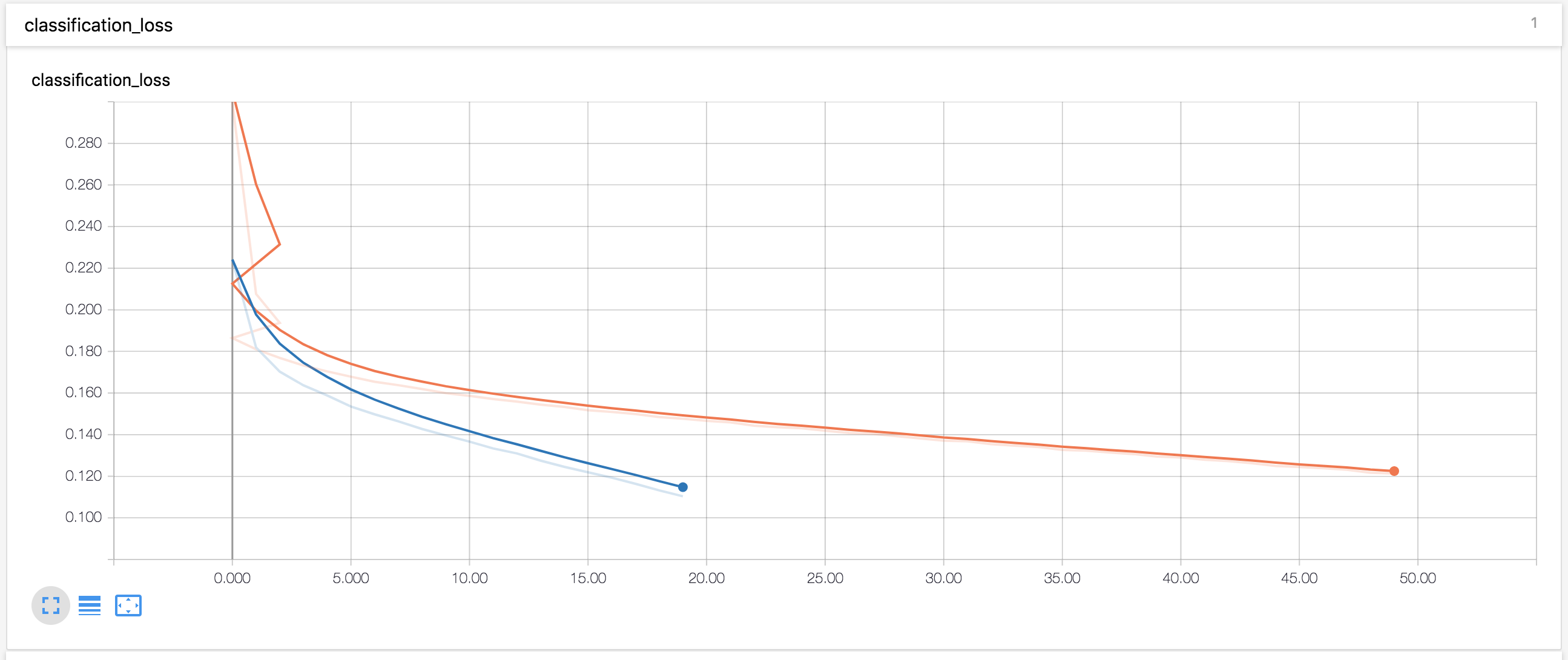


Blue = batch size 1
Orange = batch size 10
Training isn't finished on batch size 1 but it seems it's diverging quite a lot from the batch 10 session.
I'll get back here after a few more epochs.
Thanks!
sorinpanduru
on 11 Apr 2018
What am I looking at? I assume the x-axis is the epoch? Why does it seem to go back in time? Why is the orange line further than the blue line, did you start batch_size 1 later than batch size 10? Is this COCO?
hgaiser
on 11 Apr 2018
Yes, x-axis is epoch. As i said, batch 1 is not finished training. only at step 18 as of now, while i trained 50 epochs with batch 10.
Also, It's my own dataset.
The "back in time" artifact seen for batch 10 is only because i restarted training once without removing the tensorboard log files. that part can be safely ignored :)
sorinpanduru
on 11 Apr 2018
Ah I see. Strange how your results conflict with those of @rodrigo2019 and @jjiunlin . Silly question, but you're sure you're using the latest version of keras-retinanet?
hgaiser
on 11 Apr 2018
Yep, it's the latest version... I'll just wait for few more epochs. It might converge at some point
sorinpanduru
on 11 Apr 2018
That's strange.
5000 steps per epoch for all batch_size = 1,2,4. Not original steps = 10000.
lr = 1e-4, batch_size=4 get mAP=0.312 at epoch 58

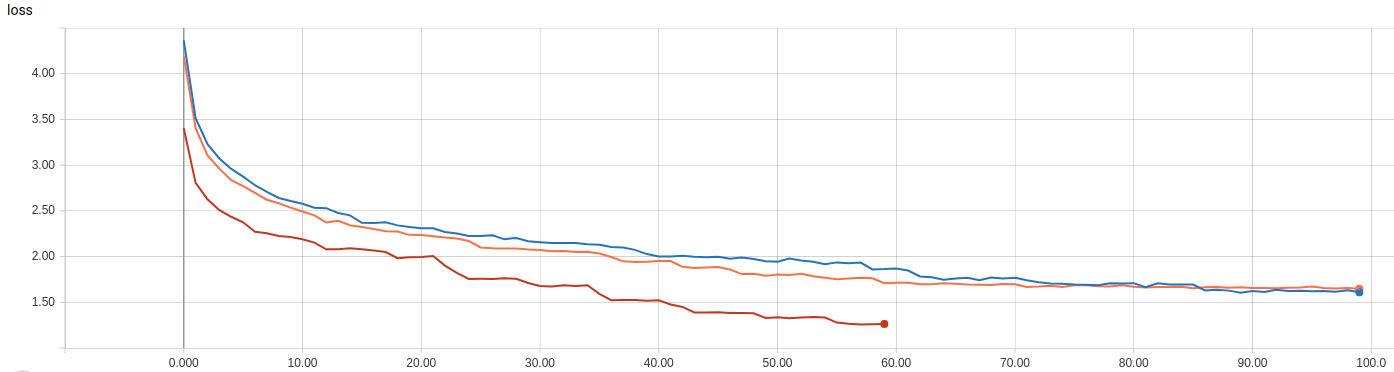


jjiunlin
on 11 Apr 2018
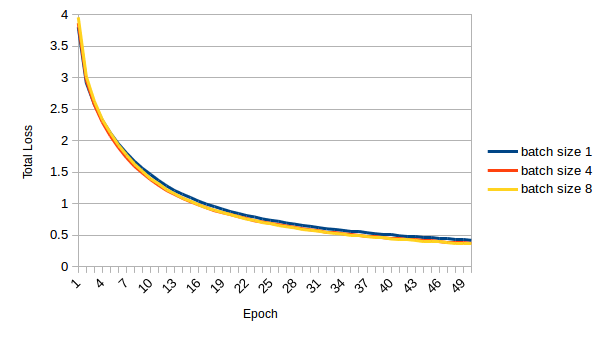
Ran a test on pascal VOC, training on trainval07, testing on test07. Learning rate was set to batch_size * 1e-5, each epoch was num_images//batch_size. Test was run for 50 epochs at batch size 1, 4 & 8.
Results show batching works just fine, that is the batched version converges slightly faster, likely due to increased stability of the gradient update.

yhenon
on 17 Apr 2018
Ah that's good news! I was hoping for more of an improvement w.r.t. bs1, but at least it's working.
hgaiser
on 17 Apr 2018
The improvement is mostly in runtime:
batch_size | time per epoch (s)
-- | --
8 | 680
4 | 792
1 | 1246
yhenon
on 17 Apr 2018
How can the time per epoch be smaller for bs8 than for bs1? Did you scale the number of steps with the batch size? Or did you keep the static 10k steps?
Other than that, does this conclude that batch_size > 1 is working?
hgaiser
on 20 Apr 2018
Did you scale the number of steps with the batch size?
Indeed I did. I ensured that the same number of images were trained on, to have a fair comparison.
Other than that, does this conclude that batch_size > 1 is working?
Yeah I believe so, and I suggest we close this.
If someone has issues with batch_size>1, they can reopen this issue.
yhenon
on 20 Apr 2018
@yhenon I agree with you.
I get OOM issue when training with batch_size=4 on 2 gpus.
ps. using the same configuration I just got the same error, presumably because the loss optimization is running on gpu0, it cannot handle the data from all batches and GPUs... not sure how to fix this though.
hgaiser
on 23 Apr 2018
Found this issue just now after looking for something related to my problem. I tried training for BS > 1 but as soon as I start the training, Keras indicates ETA for 1 epoch at ~18 hours and I can see that it takes multiple seconds for an iteration of 1 image. When I set it to BS=1, the ETA goes immediately down to ~30 minutes and I can see that 7-10 iterations (i.e. images) are being processed per second.
Another thing I see is that when I have BS > 1, then the classification and regression losses are a lot higher (like 5x bigger) compared to BS=1 at a given iteration.
 mdfwn
on 27 Apr 2018
mdfwn
on 27 Apr 2018
Is there news about how to solve the performance?
 dabasmoti
on 3 Feb 2019
dabasmoti
on 3 Feb 2019
Related issues
 penguinmenac3
·
5Comments
penguinmenac3
·
5Comments
 KHBillel
·
3Comments
KHBillel
·
3Comments
 xyiaaoo
·
5Comments
xyiaaoo
·
5Comments
 KwanjaiKJ
·
3Comments
KwanjaiKJ
·
3Comments
 ktobah
·
3Comments
ktobah
·
3Comments
Most helpful comment
Hi!
I can fire up training with batch size 16 today. Will post here if i see anything odd.
Thanks!