Keras-retinanet: Few important questions regarding training and transfer-learning/fine-tuning
Hello,
I would so appreciate if you consider these questions.
1) In the README you mentioned about training, it is training from scratch or training using a pre-trained imagenet weights?
if you train with initial imagenet weights, is it 50 or 101?
Should we download them from somewhere?
is it possible to train with 101?
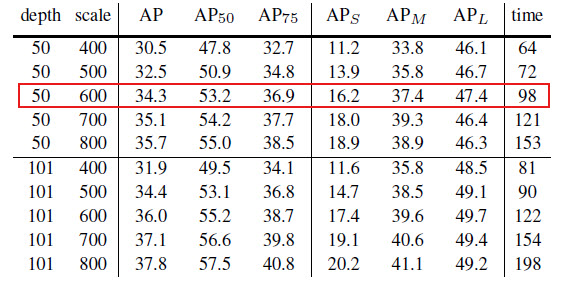
2) You have trained your model on the COCO and put some conclusions and you referred to the paper value. Do you mean this?
By this you have got a better results than paper?
3) I have a small dataset of one class (one object and background). Should I train with initial imagenet weights (50 or 101) or use your pre-trained coco weights and fine-tune it?
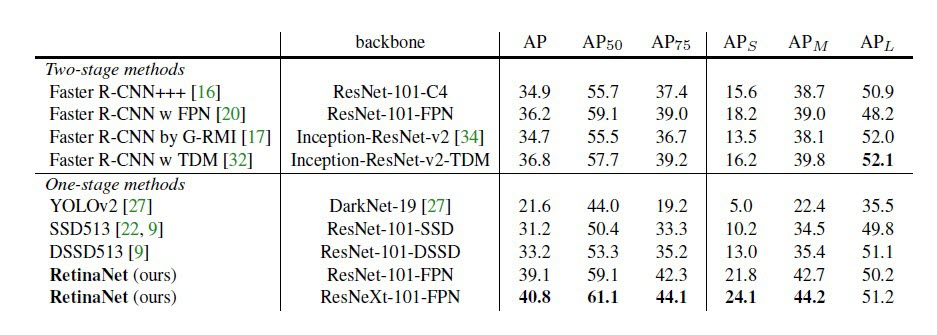
4) it seems the best results of the peper is with Resnet-101, why not train with it instead of ResNet-50?
 VanitarNordic
VanitarNordic
All 11 comments
In the README you mentioned about training, it is training from scratch or training using a pre-trained imagenet weights?
if you train with initial imagenet weights, is it 50 or 101?
Should we download them from somewhere?
is it possible to train with 101?
By default, imagenet weights will be (downloaded) and used. This is also what we used to train on COCO. Yes it is possible to use resnet101, you'll need to pass a --backbone resnet101 argument to train.py.
You have trained your model on the COCO and put some conclusions and you referred to the paper value. Do you mean this?
By this you have got a better results than paper?
Yeah, that's what it was referring to. However we recently (few days ago) switched to an image size of 800px instead of 600px as before. The comparison to 0.343 was when we were using 600px, it should be (and I just adjusted it) 0.357 now. So unfortunately we get slightly lesser results compared to the paper. Any tips on why this is, I'm all ears :)
I have a small dataset of one class (one object and background). Should I train with initial imagenet weights (50 or 101) or use your pre-trained coco weights and fine-tune it?
I would go for using the pre-trained COCO weights always.
it seems the best results of the peper is with Resnet-101, why not train with it instead of ResNet-50?
Using ResNeXt101 actually, but yeah. The goal of this repository is not to get the best possible results, but to match the implementation described in their paper. Training on ResNet50 is then easier and faster.
 hgaiser
on 6 Mar 2018
hgaiser
on 6 Mar 2018
Thank you very much for your reply.
I would go for using the pre-trained COCO weights always.
1) May I ask you how I should use this pre-trained weight with a custom class and possibly with different number of classes? Besides the coco pre-trained weights link in the README is broken, after you updated it to the v2.0.1.
Any tips on why this is, I'm all ears :)
I don't know how much it differs, but sometime it is because of different augmentation methods.
2) regarding the CSV, should I write a code to make this CSV file from the annotations or you have provided a script for that in the repo?
VanitarNordic
on 6 Mar 2018
May I ask you how I should use this pre-trained weight with a custom class and possibly with different number of classes? Besides the coco pre-trained weights link in the README is broken, after you updated it to the v2.0.1.
Right, updated again :)
I don't know how much it differs, but sometime it is because of different augmentation methods.
According to their paper they use only horizontal flips, which we do too.
regarding the CSV, should I write a code to make this CSV file from the annotations or you have provided in the repo?
We don't have any conversion tools, then again we don't know which annotation format you (in general, the user) are using, so we can't.
hgaiser
on 6 Mar 2018
Thank you.
1) May I ask you how I should use this pre-trained weight (your provided coco pre-trained weights) with a custom dataset and possibly with different number of classes (one or two for instance)?
2) may I ask you which line represents your mAP results on the COCO using ResNet-50?
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.345
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.533
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.368
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.189
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.380
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.465
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.301
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.482
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.529
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.364
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.565
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.666
May I ask you how I should use this pre-trained weight (your provided coco pre-trained weights) with a custom dataset and possibly with different number of classes (one or two for instance)?
You can pass it to the training script like: python keras_retinanet/bin/train.py --weights /path/to/coco/weights.h5 csv /path/to/annotations.csv /path/to/classes.csv.
may I ask you which line represents your mAP results on the COCO using ResNet-50?
The first line is what I generally look at.
hgaiser
on 6 Mar 2018
You can pass it to the training script like ...
No need to edit the code or model somewhere like the last conv layer or something like that to make the weight compatible with different number of classes?
It's really good that you make it easy lie this. Congratulations. Good Job.
According to their paper they use only horizontal flips, which we do too.
As you know better this is definitely not enough. All object detection models have bunch of augmentation processes like flip, saturation, hue, jitters, scale. otherwise the training set would be easy to encounter for the model. I don't know why they wrote like this. Your results is only 1% or something lower.
VanitarNordic
on 6 Mar 2018
No need to edit the code or model somewhere like the last conv layer or something like that to make the weight compatible with different number of classes?
It's really good that you make it easy lie this. Congratulations. Good Job.
Keras used to crash when there was an inconsistency with architecture and the weights to load, but https://github.com/keras-team/keras/pull/8514 fixed that. You should now see a warning saying some layers could not be loaded, but that's okay.
As you know better this is definitely not enough. All object detection models have bunch of augmentation processes like flip, saturation, hue, jitters, scale. otherwise the training set would be easy to encounter for the model. I don't know why they wrote like this. Your results is only 1% or something lower.
We do support other methods for augmentation ( https://github.com/fizyr/keras-retinanet/blob/master/keras_retinanet/utils/transform.py#L255-L264 ).
hgaiser
on 6 Mar 2018
Your results on the Titan x Pascal GPU is around 13FPs for the ResNet-50. it seems the RetinaNet can not be suitable for Real-time tasks, isn't?
VanitarNordic
on 6 Mar 2018
Your results on the Titan x Pascal GPU is around 13FPs for the ResNet-50. it seems the RetinaNet can not be suitable for Real-time tasks, isn't?
If by real-time you mean 30fps, then no. At least not using ResNet50. You might have more luck trying MobileNet then, I don't have much experience with that backbone but it should be much faster.
hgaiser
on 6 Mar 2018
I take it this issue is resolved then, closing.
hgaiser
on 7 Mar 2018
Yes, Thank you very much.
VanitarNordic
on 7 Mar 2018
Related issues
 aaronBioBot
·
5Comments
aaronBioBot
·
5Comments
 remcova
·
4Comments
remcova
·
4Comments
 Lakshya-Kejriwal
·
5Comments
Lakshya-Kejriwal
·
5Comments
 ztf-ucas
·
3Comments
ztf-ucas
·
3Comments
 ktobah
·
3Comments
ktobah
·
3Comments
Most helpful comment
By default, imagenet weights will be (downloaded) and used. This is also what we used to train on COCO. Yes it is possible to use resnet101, you'll need to pass a
--backbone resnet101argument totrain.py.Yeah, that's what it was referring to. However we recently (few days ago) switched to an image size of 800px instead of 600px as before. The comparison to 0.343 was when we were using 600px, it should be (and I just adjusted it) 0.357 now. So unfortunately we get slightly lesser results compared to the paper. Any tips on why this is, I'm all ears :)
I would go for using the pre-trained COCO weights always.
Using ResNeXt101 actually, but yeah. The goal of this repository is not to get the best possible results, but to match the implementation described in their paper. Training on ResNet50 is then easier and faster.