Kedro: Load data from a download link online (if no API exists) using catalog.yml file
What are you trying to do?
In the current catalog.yml documentation, there seems to be no way to pull in a dataset from a download link if an API does not exist. Typically with a shell script I use 'wget name_of_url', but I can't seem to figure out how to incorporate these data sets into the kedro pipeline.
Is there currently a way to do this?
 kelandrin
kelandrin
All 8 comments
Do you have an example? I believe all the APIDataSet does is issue a GET request, so a "download link" should work, no?
 mzjp2
on 16 Oct 2020
mzjp2
on 16 Oct 2020
what would the entry in the yml file look like?
kelandrin
on 16 Oct 2020
I'm sorry, I am new to using Kedro and trying to get my footing / transfer how I used to do things to this new framework.
kelandrin
on 16 Oct 2020
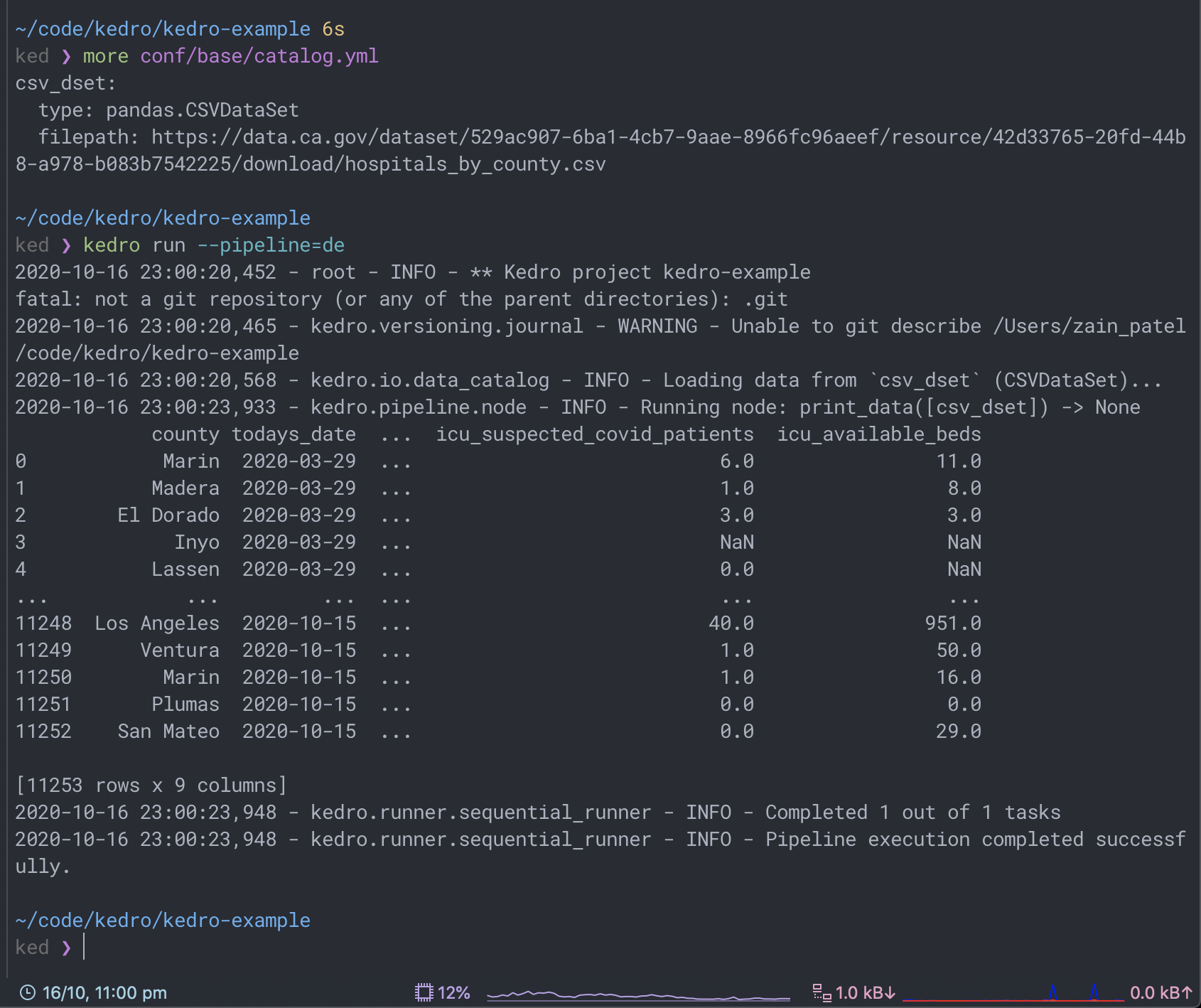
Ah, gotcha! Kedro actually uses fsspec under the hood, so you just use the "typical":
dset_name:
type: pandas.CSVDataSet
filepath: https://data.ca.gov/dataset/529ac907-6ba1-4cb7-9aae-8966fc96aeef/resource/42d33765-20fd-44b8-a978-b083b7542225/download/hospitals_by_county.csv
It deals with the https:// automatically - you can also use s3://, gcs://, adfs:// for S3/GCP/Azure storage as well, it handles it seamlessly.
mzjp2
on 17 Oct 2020
Oh, excellent! Thank you! And I wouldn't save the data to raw_01 in this case correct? Or is there a way to do that?
kelandrin
on 17 Oct 2020
Oh, excellent! Thank you! And I wouldn't save the data to raw_01 in this case correct? Or is there a way to do that?
You would define a new dataset in your catalog, something like:
output_dset:
type: pandas.CSVDataSet
filepath: data/02_intermediate/processed_hospitals_by_country.csv
and then in your node definition, it would look something like:
def create_pipeline(**kwargs):
return Pipeline(
[
node(
process_data,
input="csv_dset",
output="output_dset"
)
]
)
where process_data looks like:
def process_data(pandas_dataframe_from_csv):
return processed_pandas_dataframe_from_csv
and because the filepath doesn't start with a special token (like http(s), git, s3, etc...) it just saves it to your data/02_intermediate folder with the name processed_hospitals_by_country.csv.
You might want to have a quick look at one of the Kedro tutorials over here: https://kedro.readthedocs.io/en/stable/03_tutorial/01_spaceflights_tutorial.html :)
mzjp2
on 17 Oct 2020
Perfect, thank you very much!
kelandrin
on 17 Oct 2020
No worries, if you've got any further questions - feel free to post it over at https://stackoverflow.com/questions/tagged/kedro under the kedro tag for the best chance at getting answers :)
mzjp2
on 17 Oct 2020
Related issues
 jmrichardson
·
3Comments
jmrichardson
·
3Comments
 crypdick
·
3Comments
crypdick
·
3Comments
 tamsanh
·
3Comments
tamsanh
·
3Comments
 yetudada
·
4Comments
yetudada
·
4Comments
 applelok
·
3Comments
applelok
·
3Comments