Kedro: Allow catalog in Python format in addition to YAML
Description
I would suggest allowing declaring catalog datasets as a Python code in addition to YAML.
Context
I personally like to use YAML, but it seems that forcing YAML format as catalog is becoming an obstacle for many Python users to start to use Kedro.
Here are some examples new Kedro users suffered from YAML :
- https://github.com/quantumblacklabs/kedro/issues/386
- https://github.com/quantumblacklabs/kedro/issues/387
- https://github.com/quantumblacklabs/kedro/issues/392
It is true that many Python users hesitate to learn YAML or Kedro's Templated Config.
Possible Implementation
In addition to catalog.yml, accept catalog.py like this:
# written in conf/base/catalog.py
from kedro.extras.datasets.pandas import CSVDataSet
catalog_dict = dict(
foo_dataset = CSVDataSet(filepath="data/foo.csv"),
bar_dataset = CSVDataSet(filepath="data/bar.csv"),
)
Possible Alternatives
Provide a built-in hook to add catalog Python dict like this:
from typing import Dict
from kedro.io import AbstractDataSet, DataCatalog
from kedro.framework.hooks import hook_impl
class AddCatalogDictHook:
""" Hook to add data sets.
"""
def __init__(
self, catalog_dict: Dict[str, AbstractDataSet],
):
"""
Args:
catalog_dict: catalog_dict to add.
"""
assert isinstance(catalog_dict, dict), "{} is not a dict.".format(catalog_dict)
self._catalog_dict = catalog_dict
@hook_impl
def after_catalog_created(self, catalog: DataCatalog) -> None:
catalog.add_feed_dict(self._catalog_dict)
My Kedro template using this hook is available at: https://github.com/Minyus/kedro_template
 Minyus
Minyus
All 16 comments
Hi @Minyus! Thanks for raising this.
I believe we already have some sort of support for this, documented here: https://kedro.readthedocs.io/en/stable/04_user_guide/04_data_catalog.html#using-the-data-catalog-with-the-code-api in the "Data Catalog with the Code API". Have you had a look through that and how does it differ from what you propose? Does it fit the need?
In terms of the after_catalog_created hook, @limdauto or @921kiyo can lend some more voices here. Our initial set of hooks were conservative because it's easier to provide new hooks than to remove ones.
 mzjp2
on 1 Jun 2020
mzjp2
on 1 Jun 2020
Hi @mzjp2
I believe most of Kedro users want to use KedroContext, but the document (https://kedro.readthedocs.io/en/stable/04_user_guide/04_data_catalog.html#using-the-data-catalog-with-the-code-api) does not use KedroContext.
It might be useful for unit testing though.
Minyus
on 1 Jun 2020
@mzjp2 The after_catalog_created hook does allow one to modify the catalog just fine.
@Minyus You should be able to create the pipelines in a separate class, and attach it to the context using hooks.
Ex:
class MyNewDataSets:
@staticmethod
@hook_impl
def after_catalog_created(*args, catalog=None, **kwargs):
for name, ds in dict(foo_dataset = CSVDataSet(filepath="data/foo.csv"), bar_dataset = CSVDataSet(filepath="data/bar.csv"),):
catalog.add(name, ds)
class ProjectContext(KedroContext):
hooks = (MyNewDataSets,)
....
 tamsanh
on 2 Jun 2020
tamsanh
on 2 Jun 2020
Ah, I forgot we actually had a after_catalog_created hook 🤦♂️ and thought the proposal here was asking for us to add it, my bad
I think this can potentially be something we document in the Code API section of the docs 🤔
mzjp2
on 2 Jun 2020
I'm sorry that my explanation was not clear.
This feature request is for potential Kedro users rather than me.
I'm fine with YAML and Kedro hooks, but YAML and Kedro hooks could be obstacles for new Kedro users.
I'm suggesting we modify the KedroContext so that new Kedro users can choose not to learn about YAML or Kedro hooks and get benefits from Kedro with less learning effort in the beginning.
The objective of this feature request is to expand Kedro community.
Minyus
on 2 Jun 2020
Ah, @Minyus , I misread your post. I understand, now. What you’re suggesting is that using a python file to generate catalogs should be allowed as an alternative _default_ option, so that inexperienced YAML users may choose to use that instead.
tamsanh
on 2 Jun 2020
Hi @tamsanh , yes, your explanation sounds more concise than mine.
It is better to be friendly to both novice and expert users.
(That's why I recommend your YouTube videos in my package here .)
Minyus
on 3 Jun 2020
Hey @Minyus, I was thinking about your notes regarding new users, and totally agree.
For a bit of fun, I made a project that you may like. It's along the same vein as your work, but is focused more on beginners.
Rather than specifying catalog entries with python code, this plugin specifies plugins via the nodes themselves. What do you think? Would it help some of the users you have in mind? ☺️ https://github.com/tamsanh/kedro-wings
tamsanh
on 3 Jun 2020
Hi @tamsanh, thanks for sharing your kedro-wings.
Here are pros and cons I found.
Pros:
- For major file extensions such as "csv", users do not need to specify the DataSet class.
- Users can avoid repeating to specify the same directory using optional "root" args.
Cons:
- Auto-completion by Python IDE (PyCharm, VSCode, etc.) for DataSet classes cannot be used.
- To use a custom DataSet class, users need to find the correct "type" string (e.g. "src.datasets.my_dataset.MyDataSet") which could be troublesome for some new users.
While kedro-wings seems to be an interesting option and helpful for some Kedro users, catalog with Python code seems to be a straightforward option for majority of new Kedro users.
Minyus
on 3 Jun 2020
Hey, thanks for looking @Minyus. I appreciate that feedback, and I see what you mean: auto-completion by the IDEs is so useful, and being able to do auto complete for custom datasets is doubly so.
If that's the case, how about this API change?
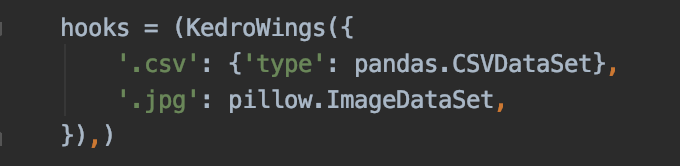
Instead of just copying the config dictionary, it can also supports passing in the dataset class. That would cover both the valid concerns regarding auto-completion, and the config would also be supported if the class is placed under type.
tamsanh
on 4 Jun 2020
Hi @tamsanh , thanks for your suggestion.
In your example, the auto-completion seems to be limited to the DataSet class names.
Auto-completion can be used for arguments of DataSet classes if users can code like this:
hooks = (
KedroWings(
{
"foo_dataset": pandas.CSVDataSet(
filepath="data/foo.csv",
load_args=dict(float_precision="high"),
save_args=dict(float_format="%.16e"),
),
"bar_dataset": api.APIDataSet(
url="https://raw.githubusercontent.com/quantumblacklabs/kedro/develop/static/img/kedro_banner.png",
method="GET",
timeout=1,
),
}
),
)
@tamsanh KedroWings is really cool! I tested it out combined with steel-toes and they work really well together
 WaylonWalker
on 4 Jun 2020
WaylonWalker
on 4 Jun 2020
Thanks everyone for this very interesting discussion. I think in the future, we are going to transition towards a composition-based API for KedroContext, in which you can supply your own catalog, runner, pipeline, etc. in a much more declarative way. In such a world, using a YAML-backed catalog should be straightforward.
In the mean time, I agree using Hooks either in a DIY fashion or through @tamsanh's fantastic kedro-wings is a very sensible approach. I'm going to close this issue but please feel free to re-open if necessary.
 limdauto
on 8 Jul 2020
limdauto
on 8 Jul 2020
@mzjp2 I used the Data Catalog with Code API instructions to make a catalog.py, but now I'm trying to figure out how to add it to the main Kedro catalog. Following @tamsanh tutorial on adding Datasets Programmatically to a Kedro Catalog, I see how I can add entries to the main catalog by overloading _get_catalog()-- but how do I merge the catalog.py catalog with the main Kedro catalog?
EDIT: instead of trying to merge two DataCatalog(), I created a hook as per https://github.com/quantumblacklabs/kedro/issues/397#issuecomment-637213280. Now, I'm getting DataSetAlreadyExistsError thrown because somehow the hook is being run multiple times.
 crypdick
on 19 Aug 2020
crypdick
on 19 Aug 2020
Hi @crypdick , just to clarify, are you using _only_ hooks now, or a combination of both? Ideally only hooks or only _get_catalog() method should suffice. The hooks should only be called once, unless you have multiple hook implementations that are adding the same datasets at some point.
On the off chance that adding same dataset names more than once is intentional, you could pass replace=True to your catalog.add() calls.
 lorenabalan
on 19 Aug 2020
lorenabalan
on 19 Aug 2020
@lorenabalan When I run just the hook:
class CodeAPIDataSetHook:
@staticmethod
@hook_impl
def after_catalog_created(catalog: DataCatalog) -> None:
print("running hook")
for name, ds in my_catalog_dict.items():
catalog.add(name, ds)
class ProjectContext(KedroContext):
...
hooks = (
KedroWings(),
KedroGreat(),
CodeAPIDataSetHook(),
)
def _get_pipelines(self):
return create_pipelines()
The hook appears to run multiple times:

For now, I've fixed the issue by checking the catalog before I add:
def after_catalog_created(catalog: DataCatalog) -> None:
already_loaded_datasets = set(catalog.list())
for name, ds in my_catalog_dict.items():
if name not in already_loaded_datasets:
catalog.add(name, ds)
Related issues
 kaemo
·
3Comments
kaemo
·
3Comments
 yetudada
·
3Comments
crypdick
·
3Comments
yetudada
·
3Comments
crypdick
·
3Comments
 torazem
·
3Comments
WaylonWalker
·
3Comments
torazem
·
3Comments
WaylonWalker
·
3Comments
Most helpful comment
Hi @tamsanh , yes, your explanation sounds more concise than mine.
It is better to be friendly to both novice and expert users.
(That's why I recommend your YouTube videos in my package here .)