Kafka-node: Too may "'ignoring message due to it being from an old group" error
Bug Report
I have a client setup using ConsumerGroupStream. It is getting too many errors with message starting with "'ignoring message due to it being from an old group".
But the consumer seems to be working fine, but this error is polluting my logs and alerts.
There is "Heartbeat error" happens quite frequently just before this error. Based on an issue already reported I understand that it is a debug log.
But the error which with starts "ignoring message due to being an old group - " is logged as "ERROR".
Based on the code it appears that this can happen every time the client rebalances.
Shouldn't it be logged as DEBUG if this error is expected?
https://github.com/SOHU-Co/kafka-node/blob/949c594bbe268f75fd8c56f55394f661007f6297/lib/kafkaClient.js#L1221
Environment
- Node version: 10.15.0
- Kafka-node version: 4.0.2
- Kafka version: 1.1
For specific cases also provide
- Number of Brokers: 1
- Number partitions for topic: 4
Include output with Debug turned on
timestamp=2019-02-25T21:15:46.824Z,message="... Heartbeat error:",errorCode=27,logger="kafka-node:ConsumerGroup",meta={"message":"Kafka Error Code: 27"},level="WARN"
timestamp=2019-02-25T21:15:46.824Z,message="tryToRecoverFrom heartbeat",errorCode=27,logger="kafka-node:ConsumerGroupRecovery",meta={"message":"Kafka Error Code: 27"},level="DEBUG"
timestamp=2019-02-25T21:15:46.824Z,message="RECOVERY from heartbeat: ... retrying in 1000 ms",errorCode=27,logger="kafka-node:ConsumerGroupRecovery",meta={"message":"Kafka Error Code: 27"},level="DEBUG"
timestamp=2019-02-25T21:15:46.838Z,logger="kafka-node:KafkaClient",level="ERROR",message="ignoring message due to it being from an old group - memberId: 6ef2fee1-0c44-4537-89e1-ce1bb439013b !=6ef2fee1-0c44-4537-89e1-ce1bb439013b - generationId: 55373!=55373"
timestamp=2019-02-25T21:15:46.838Z,logger="kafka-node:KafkaClient",level="ERROR",message="ignoring message due to it being from an old group - memberId: 6ef2fee1-0c44-4537-89e1-ce1bb439013b !=6ef2fee1-0c44-4537-89e1-ce1bb439013b - generationId: 55373!=55373"
Appreciate your help!
 snatesan
snatesan
All 16 comments
Looks like those messages were received while the consumer is rebalancing. Does your consumer do this often?
 hyperlink
on 26 Feb 2019
hyperlink
on 26 Feb 2019
Yes, my consumer does this quite often every 10s.
snatesan
on 28 Feb 2019
Yes, my consumer does this quite often every 10s.
That does not seem normal. Have you looked at the group describe periodically to see if the partition ownership is really changing that often?
hyperlink
on 1 Mar 2019
That does not seem normal. Have you looked at the group describe periodically to see if the partition ownership is really changing that often?
Yes, I checked at the group describe and the rebalancing happens quite often.
Got "Warning: Consumer group '
snatesan
on 6 Mar 2019
Are new ConsumerGroups instantiated based on requests ?
hyperlink
on 6 Mar 2019
I didn't fully understand the question.
new ConsumerGroup are not instantiated based on requests to the web server if that is what you meant. I am actually using ConsumerGroupStream and there is only one instance of it listening to multiple topics.
snatesan
on 6 Mar 2019
Hapenning here the same with ConsumerGroup
 davicente
on 2 Apr 2019
davicente
on 2 Apr 2019
We're experiencing a similar issue. Sometimes (quite often) after rebalancing (not after each rebalancing, but after some) there's no consumers left assigned for a partition. We consume from AWS Lambda, so consumers being recreated quite often - every 5m. The interesting thing is that this issue happens more often for partition#0, less often for the 1st one, and almost never for the 2nd. Can protocol: ['range'] be the cause of such uneven split of failures?
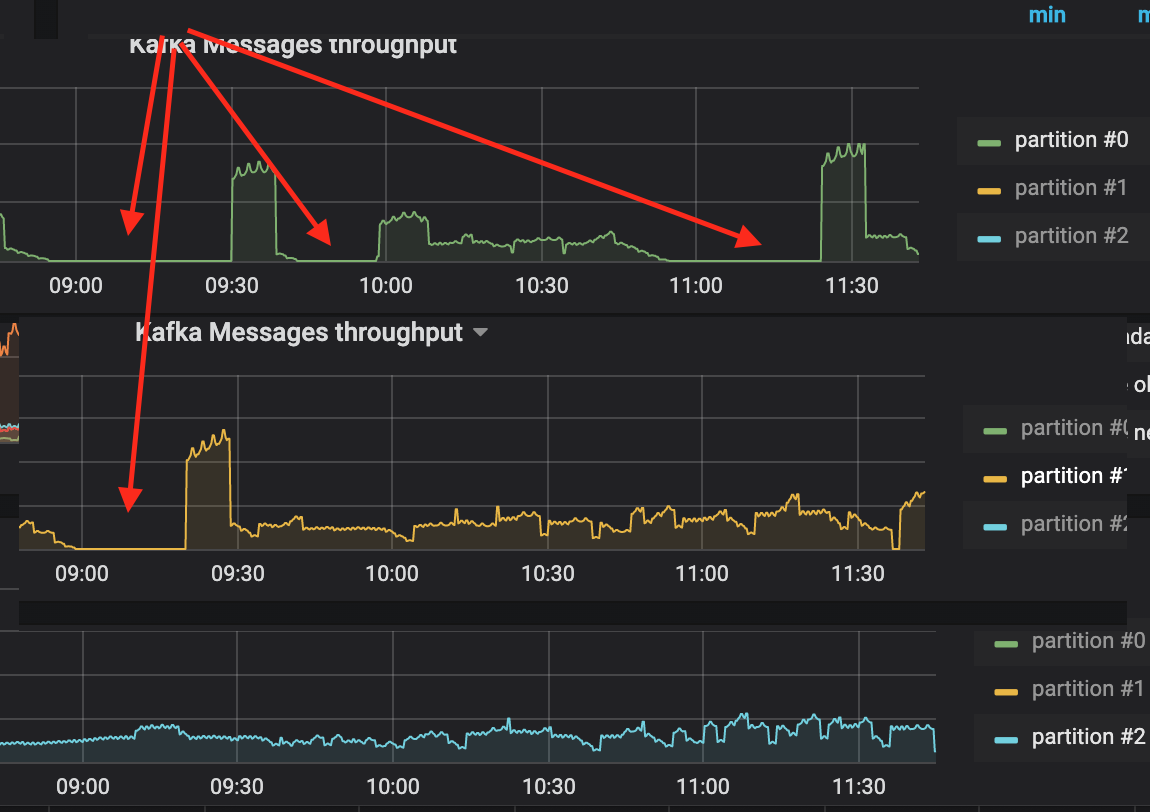
Also if there're any ideas why the issue happens after rebalancing I'm glad to investigate further or try other approaches. Any help is appreciated.
 wips
on 9 Apr 2019
wips
on 9 Apr 2019
The message is correct.
We don't want to emit messages in the middle of a rebalance as when rebalances occur, group partition assignment is changing, the generation ID is changing, and your consumer will not be allowed to even COMMIT that message back to the group.
If you receive a message on generationID 1, and rebalance occurs, and you had an inflight fetch request that came back with a message from gen1 and a rebalance is now in progress, if you try to commit that message to the group while the generation is now 2, it will be an error.
The member may not even be assigned that partition anymore!
You really need to solve this yourself and stop so many rebalances from occurring.
 aikar
on 11 Apr 2019
aikar
on 11 Apr 2019
Though I will agree this should be debug and not error.
aikar
on 11 Apr 2019
:+1: for debug
 darky
on 15 Apr 2019
darky
on 15 Apr 2019
For my understanding, this error is generated by the library while doing internal operations and there's no specific action being done by the end user (committing, producing etc.) that would specifically trigger it? Ie. it will just happen sometimes whenever a rebalance occurs?
 ajwootto
on 1 May 2019
ajwootto
on 1 May 2019
@aikar @hyperlink how to resolve this issue? is known issue? it's critical bug.....
 kgneng2
on 27 Jul 2020
kgneng2
on 27 Jul 2020
@kgneng2 just noticed the ping, sorry no idea, I gave up on this library and kafka.
However, the logical idea of this issue means you just need to build support into your app for it, that when you get this error, to drop your processing and abort processing the message.
aikar
on 9 Dec 2020
@aikar thanks for your comment. I also gave up on this library 🤪
kgneng2
on 10 Dec 2020
we encountered the same, remain unresolved with 2.5.1 kafka
I didn't fully understand the question.
new ConsumerGroup are not instantiated based on requests to the web server if that is what you meant. I am actually using ConsumerGroupStream and there is only one instance of it listening to multiple topics.
same setup here
 jun0tpyrc
on 25 Feb 2021
jun0tpyrc
on 25 Feb 2021
Related issues
 juhanishen
·
7Comments
juhanishen
·
7Comments
 sergeyjsg
·
4Comments
sergeyjsg
·
4Comments
 ashishnetworks
·
4Comments
ashishnetworks
·
4Comments
 Sonivaibhav26
·
5Comments
Sonivaibhav26
·
5Comments
 chetandev
·
5Comments
chetandev
·
5Comments
Most helpful comment
Though I will agree this should be debug and not error.