Jupyterlab: Syntax highlighting for Stan
All 50 comments
Hi @rongmu! Our syntax highlighting is provided by the CodeMirror editor. This issue would be better suited there: https://github.com/codemirror/CodeMirror/issues
 blink1073
on 17 Oct 2018
blink1073
on 17 Oct 2018
@blink1073 Thank you! I will file an issue there!
 rongmu
on 17 Oct 2018
rongmu
on 17 Oct 2018
Unfortunately, the maintainer of CodeMirror says that they won't add any more language modes to the main distribution. The maintainer suggests that new language modes should be added as separate modules.
The issue in CodeMirror repo: https://github.com/codemirror/CodeMirror/issues/5623
Stan is really important for Bayesian data analysis, it has interfaces for Python, R, Matlab etc.; RStudio supports Stan syntax out-of-the-box.
It would be really great if JupyterLab supports Stan syntax.
rongmu
on 17 Oct 2018
Ah, understood. I marked it as help wanted since the core team is saturated with other tasks.
blink1073
on 18 Oct 2018
Yeah. So this raises again the need for a jupyter/syntax repo. Previous
considered entrants include graphviz and robotframework (the existing one
is long in the tooth), so maybe three is enough. Would this require a JEP,
or just someone with perms?
Ideally, this would initially consist of codemirror modes, packaged and
usable without lab, and labextensions that rely on them. We could also
incubate monaco and pygments modes there if it comes to it, though those
two communities are accepting new modes.
A related tool could be a "mimerenderer" for a JSON version of:
https://codemirror.net/demo/simplemode.html
Unfortunately it's not easy to encode regex flags in json, but perhaps even
that could be overcome with a bit of preprocessing. Anyhow, this could be a
way to make syntax more user serviceable.
On Wed, Oct 17, 2018, 21:21 Steven Silvester notifications@github.com
wrote:
Ah, understood. I marked it as help wanted since the core team is
saturated with other tasks.—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub
https://github.com/jupyterlab/jupyterlab/issues/5504#issuecomment-430842831,
or mute the thread
https://github.com/notifications/unsubscribe-auth/AACxRNUq4Th_kR0pqwmm29I22rN0dQFUks5ul9eOgaJpZM4Xj2QX
.
 bollwyvl
on 19 Oct 2018
bollwyvl
on 19 Oct 2018
Ah, this looks very promising as tool, by the creator of codemirror:
>
https://github.com/codemirror/grammar-mode
It's set up for building js files from it's bnf-like syntax, but could be
made into something dynamic.... We'd need more metadata, at any rate.
Practically, robust languages like Stan includes a bnf description, so this
could be a good match.
There's also this which supports many more features, but looks more
complicated and less maintained:
https://github.com/foo123/codemirror-grammar/blob/master/README.md
At any rate, it seems this is a possible low-barrier (e.g no ts/webpack)
entry point for language users to contribute to the lab ecosystem!
bollwyvl
on 20 Oct 2018
Re: the above: there's a big stack of examples in:
https://github.com/codemirror/google-modes
Not quite as spare as I was hoping to get everything, but probably still a
good way to go.
Oh, and i'd also like to point out the current work on codemirror 6:
There's a lot to love from a lab perspective: it's typescript-native,
tree-shakeable, dual-licenced gpl/mit, mobile-enabled and has accessibility
as a high-level goal, and still fast like v5.
While other efforts (e.g monaco) present many interesting opportunities, CM
will likely continue to be important to our work.
While the first CM6 demos are up, they're asking for donations! As a
community, we've gotten so much value from marijn and the CM community at
large, and I encourage those who have the means to pitch in: I intended to!
But anybody can star/fork the repo:
bollwyvl
on 20 Oct 2018
Is trying to submit a PR to Codemirror still the best way to add a language's syntax highlighting for support in Jupyterlab? As mentioned above, it appears that no new language modes will be considered for inclusion in CodeMirror. And it was suggested to distribute a new language's mode as a separate package/module. Then how would I distribute that to Jupyterlab users? Would I need to create a jupyterlab extension in order for users to get the syntax highlighting?
 kylebarron
on 9 Nov 2018
kylebarron
on 9 Nov 2018
For now the best way would be as a third party extension, perhaps with the mode itself in its own package to make it most useful to other codemirror consumers.
blink1073
on 12 Nov 2018
Yes, i think the best way to proceed is to write a codemirror mode in a JLab extension, as what I have done for sos.
 BoPeng
on 29 Nov 2018
BoPeng
on 29 Nov 2018
I figured out how to put the codemirror mode in its own NPM package, but I'm struggling to figure out the lab extension side.
@BoPeng I've been looking through your code, but it's quite complex since you're working with so many languages.
It feels like I should need a total of like 5 lines of code in the labextension...:
import * as CodeMirror from 'codemirror';
import 'codemirror-mode-stata';
if kernel name == 'stata' {
change mode to 'stata'
}
Any advice?
kylebarron
on 2 Dec 2018
You can create an extension using the jupyterlab extension cookiecutter following one of the examples and put your code in there. The code should have something like this to define the mode. Once the mode is loaded and listed as one of the JLab codemirror modes, you can associate .stan file type and the stan kernel with the mode.
BoPeng
on 3 Dec 2018
Ok, thanks, I'll look into it. For the record, I'm working to add Stata language support, not Stan. I piggybacked this issue because it seemed like a good place for a general discussion of how to add syntax highlighting to Jupyter lab for new modes.
kylebarron
on 3 Dec 2018
I see, you are the author of the Stata kernel, right? I have never used Stata but as the author of SoS, I am very interested in making Stata work with R and SAS in the same notebook. Do you know any known mechanism for Stata to import/export datasets in Python (DataFrame) or SAS?
BoPeng
on 3 Dec 2018
kylebarron
on 3 Dec 2018
Thanks. I have created a repo for Stata support for SoS and invited you as a collaborator in case I need your help on the use of the Stata kernel. :smile:
BoPeng
on 3 Dec 2018
@BoPeng Feel free to ping me with questions with regards to SoS, but I really don't have time to invest in another project right now.
You can create an extension using the jupyterlab extension cookiecutter following one of the examples and put your code in there.
I have a repo started from the JS cookiecutter. I don't want to deal with TS right now.
The code should have something like this to define the mode.
That's included in the mode's NPM package. I assume when I run import 'codemirror-mode-stata' it runs those lines.
Once the mode is loaded and listed as one of the JLab codemirror modes
The mode should be loaded from import 'codemirror-mode-stata', but how do you list it as one of the Jupyterlab codemirror modes? Is that this? That didn't work.
you can associate
.stanfile type
I do that: https://github.com/kylebarron/jupyterlab-stata-highlight/blob/49453d54e6c0efb4b8626bb513504e0be2b8b245/lib/plugin.js#L14-L21
and the stan kernel with the mode.
I did that as well: https://github.com/kylebarron/stata_kernel/blob/0e4dffaad88c5d802fff5fca0ffe6b38dc916bf8/stata_kernel/kernel.py#L30
kylebarron
on 3 Dec 2018
Is the codemirror mode not being loaded correctly?
kylebarron
on 3 Dec 2018
Thanks. The extension should be easy to write after I get a trial version of Stata installed. I invited you to the project just to make pinging you a bit easier.
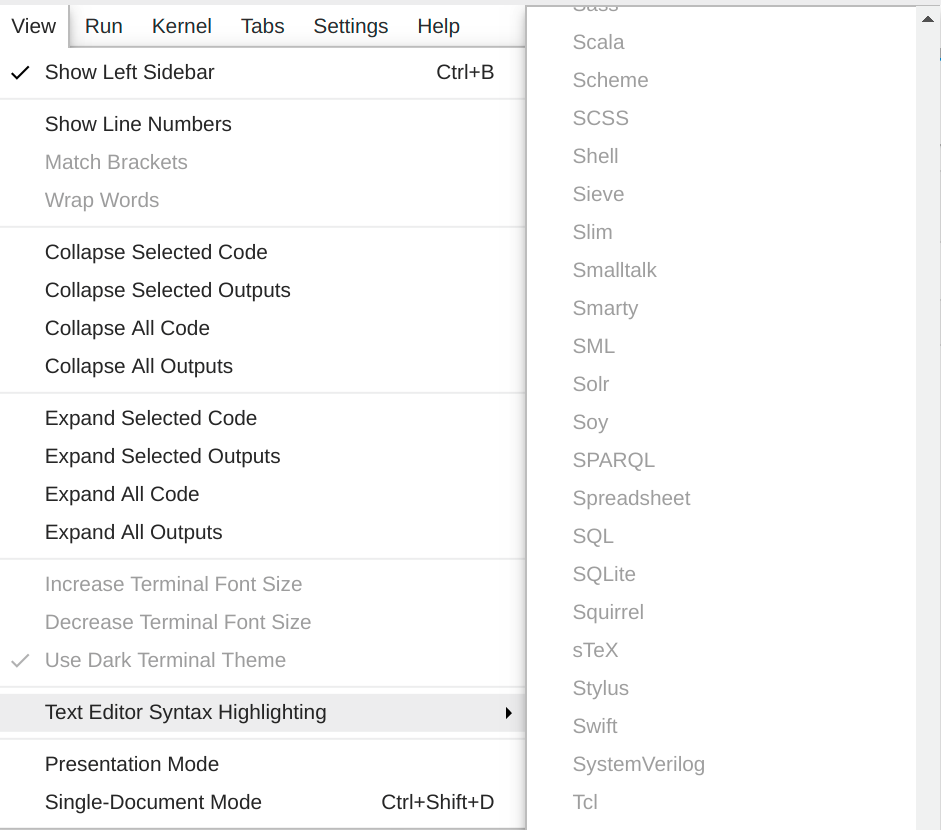
Your problem is most likely caused by the extension. You should check if the extension is correctly installed (jupyter labextension list), loaded (use a console.log line when package is loaded), and executed (set a break point in the browser). If all goes well, you should see the stata mode listed under View -> Text Editor Syntax Highlighting.
BoPeng
on 3 Dec 2018
It appears that I need to do something else in order for Jupyter to see the third-party mode:
kylebarron
on 3 Dec 2018
You also need to make sure that your extension depends on @jupyterlab/codemirror, not on codemirror because in my experience that will add your mode to your own instance of codemirror, not JupyterLab's codemirror. You might have to clean up jlab or your node_modules if that is already the case. I had a lot of confusion and trouble with the npm caches for this.
BoPeng
on 3 Dec 2018
Your problem is most likely caused by the extension. You should check if the extension is correctly installed (
jupyter labextension list), loaded (use aconsole.logline when package is loaded),
It is loaded:

and executed (set a break point in the browser).
Sorry, I don't know how to do this. I was able to set a breakpoint in the browser console, but then I don't know how that helps me check that it's executed correctly.
If all goes well, you should see the stata mode listed under
View -> Text Editor Syntax Highlighting.
I still don't see that.
You also need to make sure that your extension depends on
@jupyterlab/codemirror, not oncodemirrorbecause in my experience that will add your mode to your own instance of codemirror, not JupyterLab's codemirror. You might have to clean up jlab or yournode_modulesif that is already the case. I had a lot of confusion and trouble with the npm caches for this.
It does use @jupyterlab/codemirror: https://github.com/kylebarron/jupyterlab-stata-highlight/blob/49453d54e6c0efb4b8626bb513504e0be2b8b245/package.json#L20
kylebarron
on 3 Dec 2018
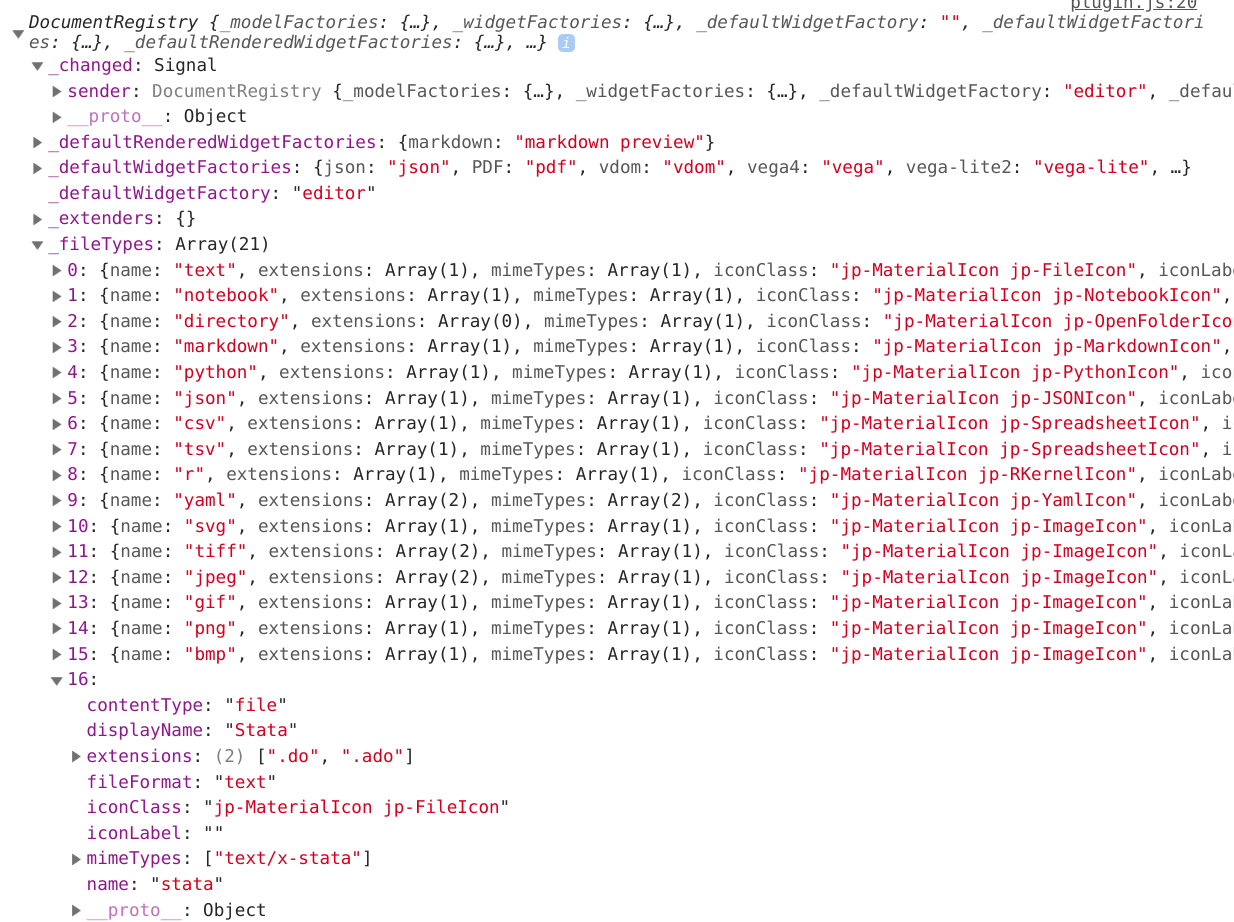
It appears it's loaded to the document registry in the console:
kylebarron
on 3 Dec 2018
Well, I do not know if this line does its work as good as this line and this. I am not proficient in JS to identify the problem by checking your code so I would suggest that you copy/paste code from your npm package, make it work and then split.
To debug, open inspector, source, open file and find your source file, this should work at least for chrome.
BoPeng
on 3 Dec 2018
DocumentRegistry is populated correctly does not mean the mode has been correctly inserted into codemirror.
BoPeng
on 3 Dec 2018
You're right. The part that's not working is the import 'codemirror-mode-stata';. When I paste the contents of codemirror-mode-stata into plugin.js, it works correctly.
kylebarron
on 3 Dec 2018
Great. Now you only need to figure out how to organize your npm package to work with your JLab extension. Frankly I do not know how to do this so I have the same code in both sos-notebook (for classic jupyter) and jupyterlab-sos (for JupyterLab). 😭
BoPeng
on 3 Dec 2018
Well I gave up and copy-pasted the codemirror mode definition into the jupyterlab extension. In any case, it's functional, so thanks a lot and hopefully someone can use my example to help with Stan syntax highlighting.
kylebarron
on 3 Dec 2018
That is unfortunate because I was hoping that you could find some way to do it. :smile:
@blink1073 Do you have any idea on how to use a npm defined codemirror mode in a JupyterLab extension? More specifically, @kylebarron used
import 'codemirror-mode-stata';
in his extension for Stata but it did not work, so he had to copy/paste the content of the mode definition into the extension.
BoPeng
on 3 Dec 2018
I tested setting @jupyterlab/codemirror as the peerDependency in the NPM package's package.json, but that didn't work either.
I found that having these lines were essential: https://github.com/kylebarron/jupyterlab-stata-highlight/blob/86e6990a75f0305daf1a5d93992a4361f1b551b5/lib/stata.js#L496-L504, but that including those lines at the end of the file in the NPM package raised an error, like "can't push on an undefined object". Maybe Jupyterlab is using a different version of Codemirror?
kylebarron
on 3 Dec 2018
@kylebarron, those lines require codemirror/mode/meta. Does it work if you import the mode from codemirror-mode-stata, require codemirror/mode/meta in your plugin, and then define the metadata?
blink1073
on 3 Dec 2018
I was never able to get it to work, even playing around with import codemirror/mode/meta
kylebarron
on 10 Dec 2018
So far, this sounds awful. Is there another issue here dedicated to adding syntax highlighting for languages not currently in codemirror, or are the valiant efforts described here (which it seems like haven't worked yet) where we're at? FYI, I got here looking for Stan language support like @rongmu.
 rgerkin
on 23 Dec 2018
rgerkin
on 23 Dec 2018
I kinda co-opted this issue to be a general discussion of adding syntax highlighting for languages not in codemirror.
It's working for me, but only with code duplication, where I include the codemirror language definition inside the Jupyterlab extension package itself.
kylebarron
on 23 Dec 2018
I know we are pretty far off the original stan issue, but here is a rough cut at something suggested:
https://github.com/deathbeds/jupyterlab-simple-syntax
The basic idea is a mime "renderer" that dynamically makes a CM mode from simplemode json. It's not ready for primetime, but _could_ be adapted to be useful for a kernel to make something interesting happen without touching typescript. I haven't written a simple mode for Stan, though, so no closer to a solution for this issue. :crying_cat_face:
However, in stumbling around, I did find this chain:
- https://github.com/jrnold/atom-language-stan/blob/master/grammars/language-stan.json
- ... a json definition of a stan grammar which can be loaded into ...
- https://github.com/patrick-steele-idem/codemirror-atom-modes
- ... a bridge from tm/subl/vscode to cm
This is probably _far_ more useful than inventing some new format, and probably worth investigating further, as we would inherit a decade or so worth of syntax highlighting knowledge. That being said, I really like simplemode, as it supports nice things like embedded other modes just by knowing their names. So there might be a place for both, potentially in the same (eventually in core) extension.
bollwyvl
on 26 Dec 2018
I hadn't seen codemirror-atom-modes, and it's a couple years old, so it would need to be tested, but if it worked, that would be a really great solution!
kylebarron
on 26 Dec 2018
Well, it does appear the textmate route works out rather well:

bollwyvl
on 26 Dec 2018
so it would need to be tested
I wouldn't call it Old and Busted: however, the dependency on
https://github.com/bcoe/onigurumajs
...for the much better regexen it requires is a bit creaky, as it bundles in pretty heavy (no stats handy, sorry). There do appear to be wasm-based attempts at porting it.
bollwyvl
on 26 Dec 2018
Well I'm excited to hear your progress. My Atom syntax highlighting (for Stata) is a lot better than the simple codemirror mode I put together, so I'd love to use that too.
kylebarron
on 26 Dec 2018
Binder is updated: ![]()
I added an example of getting stata thing, dumping it to JSON: there's definitely some wrongness:

which is handled just fine by the same code loaded from CSON into atom. So not really sure where this puts us. We'd probably need to get a look at getting https://github.com/NeekSandhu/onigasm into the mix (used by theia).
bollwyvl
on 27 Dec 2018
@bollwyvl - thanks for pursuing this. Those results look really nice!
I also just stumbled across https://github.com/neeksandhu/codemirror-textmate
 jasongrout
on 29 Dec 2018
jasongrout
on 29 Dec 2018
I implemented pygments syntax-highlighting for SoS because jupyter uses it for static HTML output, then I went a long way to implement a codemirror mode for editing SoS code in Jupyter, still I found that I need to implement a text-mate version for the notebook to be displayed in github (https://github.com/vatlab/sos-notebook/issues/141), and I really did not have the energy for it. A quick glance at the codemirror-textmate project shows that it goes from textmate to codemirror, not the other way around, so I am still stuck. 😭
BoPeng
on 29 Dec 2018
not the other way around
A textmate grammar is a regexp-based grammar, right? In general, a codemirror mode involves arbitrary code. I think it's probably impossible to convert an arbitrary codemirror mode to a textmate grammar.
jasongrout
on 29 Dec 2018
it's probably impossible to convert an arbitrary codemirror mode to a textmate grammar.
Yes, that is exactly the problem. The SoS codemirror mode is quite involved as it uses other codemirror modes to highlight code in other languages, for example, use the R mode to highlight the R_code in a R block.
R:
R_code
I do not think textmate can do this kind of thing and it is one of the reasons why I have not done it.
BoPeng
on 29 Dec 2018
Textmate can. In Atom, you'd just do include: 'source.r', to include all the R rules. That's what the markdown grammar does to include all the syntax highlighting of embedded code blocks.
See here for the Textmate specification: https://macromates.com/manual/en/language_grammars
kylebarron
on 29 Dec 2018
@kylebarron That is indeed good to know. Can it also overlay modes as codemirror does? By overlay I mean highlighting the same code by two modes, for example highlighting by R and also by another mode that identifies and highlights expressions in python f-string in the following example. The tricky part is that the second mode in this example is triggered by the expand=True option so I thought that a regular expression based solution will not cut it.

But even without overlay the use of multiple modes might be good enough. I will have a look at the spec you sent when I get a chance.
BoPeng
on 29 Dec 2018
There's an order of regex rules. You can set it to first try all the R rules and apply more rules if something isn't caught, or vice versa.
kylebarron
on 29 Dec 2018
Well, I could certainly see multiple schema-based modes working together.
Perhaps a cm simple mode that is just a wrapper for other modes, some stock
cm, some from textmate grammars.
Another thing I've been wondering about... Writing regexen in JSON is
really a special place in hell. It would be interesting to have something
like...
https://github.com/VerbalExpressions/JSVerbalExpressions
...represented as validateable JSON. I've recently been working with some
really dynamic syntaxes, and it would be great to be able to support live
hacking what you see when you start making changes in a less arcane format.
bollwyvl
on 30 Dec 2018
indeed, codemirror-textmate and onigasm FTW. That fixed up the Stata syntax highlighting. Same binder as above:

Without reaching _way down_ into the guts of Lab's webpack (One Does Not Simply Add A Loader :ok_hand: ), in order to get the onigasm.wasm into the browser I had to add a serverextension that, _gasp_, monkeypatches mimetype on the python side so that tornado will serve the correct mime type. And They Call It a MIME!
The wasm itself is a "reasonable" 0.5mb, and is loaded/cached/parsed lazily, so doesn't _currently_ entail a startup hit... but could if it was wired up for real. Not sure how deeply I can hack the loading stuff.
This is actually A Good Thing, as no doubt this mime-type based syntax highlighting is not the end-all-be-all approach, and syntaxes will want to be installed and served statically. In fact, codemirror-textmate does not really permit re-loading syntax anyway. Also, we're gonna need more wasm, and Never Want To WebPack It.
Another thing: we really, really can't support CSON. I don't want to talk about it.
bollwyvl
on 31 Dec 2018
Most recent push on the demo adds a full serverextension (api, schemas for: tmlanguage.json, simplemode, and a rudimentary manifest) and a full labextension (manager, also nothing configurable yet). It also includes stan (!), stata (and therefore sql) as examples.
Note that the binder example notebooks are now kinda busted, because you can only register a tmlanguage once... and they'll already be registered! Still good for getting the example files, i guess! Probably still worth having the renderer.
This is pretty much working at this point: it allows purely static, validateable files, served/modifiable at runtime (maybe with some cache busting) from an nbextension-style search path, to provide new syntax highlighting for the two schema (well, almost) and could be extended for other JSON-native (or presumably other) formats.
here's the workflow
- user would
labextension installandserverextension install(or the package manager would do the equivalent) - on lab launch, the (new) full labextension
- monkeypatches
Mode.ensure - requests the known modes
- monkeypatches
- the serverextension manager looks through all the mode sources from
jupyter_path('syntax')({$PREFIX/share/jupyter,$HOME/.local/.jupyter/$THE_LIB}/syntax)
- validates all the manifests and languages
- returns a unified map (closer to user wins)
- labextension pushes them onto
modeInfoand makesIFileTypes - when a user requests some highlighting and the mode is
ensured, the labextension first checks its modes
- if it finds it
- if it's a tmlanguage
- if it's the first time it's needed onigasm, it loads that
- if it needs dependent scopes, and hasn't loaded them before, it loads those
- finally loads the actual scope, and registers it as a mode (if it hasn't before)
- if it's a simple mode... i haven't extracted that yet!
- if it doesn't find anything, the usual path is taken (probably resulting in an uncatcheable webpack
requireerror)
The workflow for adding new modes:
- if you are a kernel author, you'd probably package your modes into
$PREFIX/share/jupyter/syntax/my-langand pray
- if we keep the renderer, that might still be an option, rather than files, but see limitations on updating modes...
- if you just want to highlight some files, you'd PR the set of files needed into this repo, or have your own package that populated $PREFIX
- tests (not yet written) would verify that your mode conforms to the schema, or if schema changes you need (they aren't perfect yet) would break other modes (kernel authors and/or other packagers could reuse the tests)
- better still, we could use an approach like the codemirror google modes above which also include tests which actually check whether the dom ends up with the correct tokens for a given file
- a cookiecutter or equivalent (not yet written) could potentially generate a new mode and manifest with two pieces of information: the URL of an atom
language-*repo and the mimetype(s) you want to register.
The only upstream change required: in @jupyterlab/codemirror/lib/mode, adding a Mode.registerEnsurer would remove the need for the monkeypatch, and still let modes be lazily loaded.
bollwyvl
on 2 Jan 2019
Related issues
 cceyda
·
49Comments
cceyda
·
49Comments
 dclong
·
61Comments
blink1073
·
92Comments
dclong
·
61Comments
blink1073
·
92Comments
 ellisonbg
·
64Comments
jasongrout
·
69Comments
ellisonbg
·
64Comments
jasongrout
·
69Comments
Most helpful comment
Well, it does appear the textmate route works out rather well:
