Junit5: Create IndicativeSentences Display Name Generator
Overview
As a follow-up from #1588 use the DisplayNameGenerator SPI to turn names of test classes and test methods using camel-case and/or underscores in their notation into human-readable display names that form complete sentences.
Example
From "fragments" using @DisplayName for each fragment, thus duplicating the same information as encoded in the associated method name...
...resulting in this picture...

...to "indicative sentences", merging contexts and auto-prettify display names based on the method names:

Related Issues
- #1595
Deliverables
- [ ] Create and implement
IndicativeSentencesGeneratorinorg.junit.jupiter.api.DisplayNameGenerator - [ ] Integrate this new pre-defined generator into
org.junit.jupiter.engine.descriptor.DisplayNameUtils - [ ] Extend
org.junit.jupiter.api.DisplayNameGenerationTeststo verify the implementation
 sormuras
sormuras
All 14 comments
Caveat: the IndicativeSentencesGenerator implemented here, might not be integrated into JUnit Jupiter. But perhaps into JUnit Pioneer or as an example into junit5-samples.
sormuras
on 23 Sep 2018
I would like to take a stab at this, if nobody is working on it. Once I am ready: should I open the PR against Pioneer or better here and after the review you will move it (if needed)?
Just one more quick nit question to make sure that we are on the same page: in the attached snippet and png there is a transition that I am not sure it is feasible to make (with new Stack() -> using its noarg constructor.)
@Test
@DisplayName("is instantiated with new Stack()")
A stack is instantiated using its noarg constructor.
I would go ahead and assume that the name should be A stack is instantiated with new Stack() instead;)
And the same thinking for A stack when new ... instead of A new stack ....
 olcbean
on 26 Sep 2018
olcbean
on 26 Sep 2018
Is this issue still relevant? It seems that the related PR was closed because you suggested to move it to JUnit Pioneer, but I see no such commit there... Is there something to do?
 juliette-derancourt
on 2 Aug 2019
juliette-derancourt
on 2 Aug 2019
@sormuras @olcbean is this still up-for-grabs? It seems to have gone pretty quiet - but I'm not sure from context if the discussion has moved elsewhere?
 RoryBlevins
on 2 Oct 2019
RoryBlevins
on 2 Oct 2019
Yes, it's still up for grabs, but it's also labeled for "team discussion".
The reason for the latter is that the team never came to a consensus on exactly how the feature should be implemented in terms of capitalization, combining display names, etc.
@olcbean raised some of those issues in https://github.com/junit-team/junit5/issues/1596#issuecomment-424836041.
So before anyone actually implements anything concrete, a detailed proposal should be made first.
Feel free to make such a proposal here.
 sbrannen
on 2 Oct 2019
sbrannen
on 2 Oct 2019
Hi!, I don't know if @sormuras still working on this issue, but i want to try to work on make a proposal and then implement it.
 Kazhuru
on 2 Dec 2019
Kazhuru
on 2 Dec 2019
@Kazhuru It's not assigned so feel free to go ahead!
 marcphilipp
on 2 Dec 2019
marcphilipp
on 2 Dec 2019
Sorry for the silence and the delay in answering, yesterday I was browsing the flow from the issue #162 and PR #1588 to here, and before I start coding it would be good to come up with a proper solution, I propose that the generation of names should be this way:
Using the same example of "StackTest" ->

To this result:
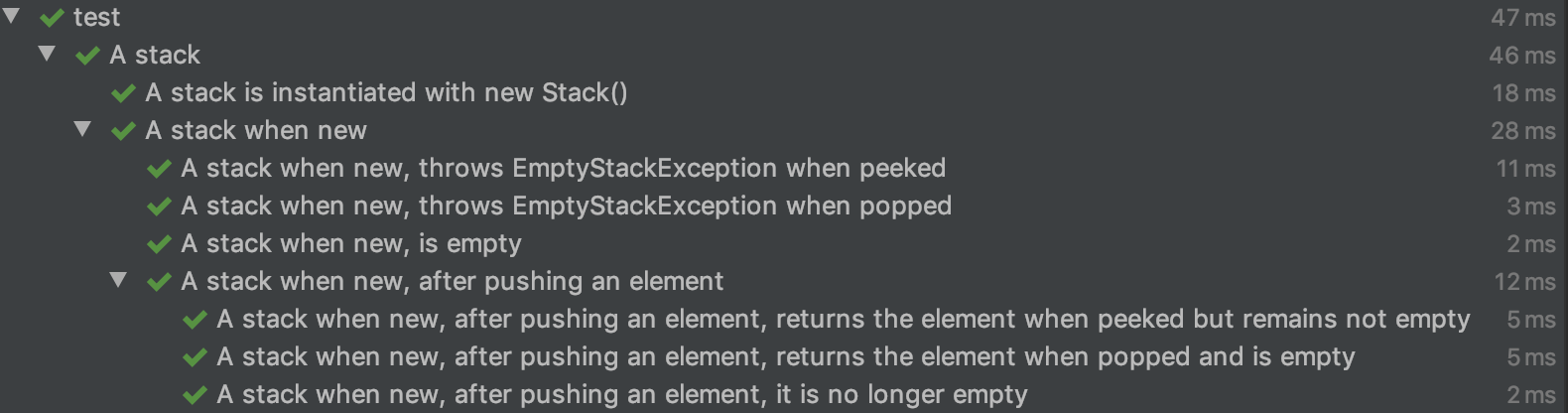
With the rules of:
- Not modifying the capitalization of the text with the exception that the first word of the sentence is in capital letters, in addition the spaces will be respected to maintain sense if it is a method/class/object with camelcase.
- Also when combining the parent text with a @Nested, the following children will be divided by a comma.
- I think the part about combining names is bit tricky, it would need to have a set of initialization words ("new, initialized, started, created") and know what item it is about, also this same logic could apply on another context like destroy.
Kazhuru
on 5 Dec 2019
The _rules_ are in fact the hardest part.
Not modifying the capitalization of the text with the exception that the first word of the sentence is in capital letters
I'm wondering if we even need to capitalize the first word.
Typically the entry point would be the top-level test class, and I doubt people would want to name it aStack or a_Stack. Rather, people will probably name it something like StackTests and annotate it with @DisplayName("A Stack").
in addition the spaces will be respected to maintain sense if it is a method/class/object with camelcase.
Are you planning on providing support for parsing camelcase?
That might turn out rather tricky. So, in light of that, maybe we should just stick to supporting underscore-separated terms and not mess with capitalization provided in the class or method name.
Also when combining the parent text with a @nested, the following children will be divided by a comma.
I guess that might be the best we can do here, since we're talking about supporting "sentences".
I think the part about combining names is bit tricky, it would need to have a set of initialization words ("new, initialized, started, created") and know what item it is about, also this same logic could apply on another context like destroy.
I don't think it's reasonable to expect the algorithm to know anything about initialization words or context. The algorithm has to be "dumb" in order to be generic and to support any spoken language in use.
sbrannen
on 5 Dec 2019
I believe that support for camelcase would be a problem when it comes to distinguish reserved names and when explaining something, so it would be for underscore if it exists or if not, the use of DisplayName("...") text value.
On the part of the capitalization of the first sentence letter, I only thought so because it would look more organized that the results have that slight pattern, in the example you gave me if someone writes: @DisplayName("a Stack is ...") it would be nice to be Uppercased to _"A Stack is ..."_.
And finally, I do agree that a dummy concatenation algorithm is better, because verifying the context would require a support of that for each language.
Kazhuru
on 5 Dec 2019
On the part of the capitalization of the first sentence letter, I only thought so because it would look more organized that the results have that slight pattern, in the example you gave me if someone writes: @DisplayName("a Stack is ...") it would be nice to be Uppercased to "A Stack is ...".
I don't think we need to capitalize either... In this case, if someone writes @DisplayName("a Stack is ...") then maybe they want it to be that way? Otherwise they would have put a capital letter themselves?
Also when combining the parent text with a @nested, the following children will be divided by a comma.
I'd also add a comma after the first name (e.g. A stack, when new, is empty). Or use em dashes (e.g. "A stack — when new — is empty"). Might be a bit too much though... 😁
If you have several @Nested classes, maybe the names could be separated by "and"? Like A stack, when new and after pushing an element, is no longer empty.
Just thoughts! :)
juliette-derancourt
on 5 Dec 2019
I don't think we need to capitalize either... In this case, if someone writes
@DisplayName("a Stack is ...")then maybe they want it to be that way? Otherwise they would have put a capital letter themselves?
Of course you are right to avoid an implementation that could restrict and modify the decisions of the names that someone wants to use, it was just an idea that could be.
I'd also add a comma after the first name (e.g.
A stack, when new, is empty). Or use em dashes (e.g. "A stack — when new — is empty"). Might be a bit too much though... 😁If you have several
@Nestedclasses, maybe the names could be separated by "and"? LikeA stack, when new and after pushing an element, is no longer empty.
I hadn't thought about that comma between the Class and the first DisplayName , it could be useful since there could be cases where without it that part of the sentence couldn't make sense, like:
@DisplayNameGeneration(DisplayNameGenerator.ReplaceUnderscores.class)
class testReporter {
@Test
void reports_Single_Value(TestReporter testReporter) {
testReporter.publishEntry("a status message");
}
@Test
void reports_Key_ValuePair(TestReporter testReporter) {
testReporter.publishEntry("a key", "a value");
}
}
should return:
testReporter, reports Single Value
testReporter, reports Key ValuePair
I'm not sure if all nested cases would read well with a "and" in between, i wouldn't much like to generalize
Kazhuru
on 5 Dec 2019
In fact, I'm thinking that the separator could be a decision variable like: "and", "-", "—", ">>", etc. If you want it, and if you don't define anything, use "," as default, for example.
Kazhuru
on 5 Dec 2019
Hi, after these days I was working on this and I opened a pull request #2124, about the issue we we're talking about just FYI.
Kazhuru
on 10 Dec 2019
Related issues
 aepfli
·
4Comments
aepfli
·
4Comments
 jayjupdhig
·
5Comments
jayjupdhig
·
5Comments
 mfulton26
·
3Comments
mfulton26
·
3Comments
 timandy
·
3Comments
timandy
·
3Comments
 ondrejlerch
·
4Comments
ondrejlerch
·
4Comments
Most helpful comment
Hi, after these days I was working on this and I opened a pull request #2124, about the issue we we're talking about just FYI.