Joss-reviews: [REVIEW]: GAMA: Genetic Automated Machine learning Assistant
Submitting author: @PGijsbers (Pieter Gijsbers)
Repository: https://github.com/PGijsbers/GAMA
Version: v0.1.0
Editor: @arokem
Reviewer: @jsgalan
Archive: 10.5281/zenodo.2545472
Status

Status badge code:
HTML: <a href="http://joss.theoj.org/papers/74cfa7e5796270cd2a96005370973c71"><img src="http://joss.theoj.org/papers/74cfa7e5796270cd2a96005370973c71/status.svg"></a>
Markdown: [](http://joss.theoj.org/papers/74cfa7e5796270cd2a96005370973c71)
Reviewers and authors:
Please avoid lengthy details of difficulties in the review thread. Instead, please create a new issue in the target repository and link to those issues (especially acceptance-blockers) in the review thread below. (For completists: if the target issue tracker is also on GitHub, linking the review thread in the issue or vice versa will create corresponding breadcrumb trails in the link target.)
Reviewer instructions & questions
@jsgalan, please carry out your review in this issue by updating the checklist below. If you cannot edit the checklist please:
- Make sure you're logged in to your GitHub account
- Be sure to accept the invite at this URL: https://github.com/openjournals/joss-reviews/invitations
The reviewer guidelines are available here: https://joss.theoj.org/about#reviewer_guidelines. Any questions/concerns please let @arokem know.
✨ Please try and complete your review in the next two weeks ✨
Review checklist for @jsgalan
Conflict of interest
- [x] As the reviewer I confirm that I have read the JOSS conflict of interest policy and that there are no conflicts of interest for me to review this work.
Code of Conduct
- [x] I confirm that I read and will adhere to the JOSS code of conduct.
General checks
- [x] Repository: Is the source code for this software available at the repository url?
- [x] License: Does the repository contain a plain-text LICENSE file with the contents of an OSI approved software license?
- [x] Version: Does the release version given match the GitHub release (v0.1.0)?
- [x] Authorship: Has the submitting author (@PGijsbers) made major contributions to the software? Does the full list of paper authors seem appropriate and complete?
Functionality
- [x] Installation: Does installation proceed as outlined in the documentation?
- [x] Functionality: Have the functional claims of the software been confirmed?
- [x] Performance: If there are any performance claims of the software, have they been confirmed? (If there are no claims, please check off this item.)
Documentation
- [x] A statement of need: Do the authors clearly state what problems the software is designed to solve and who the target audience is?
- [x] Installation instructions: Is there a clearly-stated list of dependencies? Ideally these should be handled with an automated package management solution.
- [x] Example usage: Do the authors include examples of how to use the software (ideally to solve real-world analysis problems).
- [x] Functionality documentation: Is the core functionality of the software documented to a satisfactory level (e.g., API method documentation)?
- [x] Automated tests: Are there automated tests or manual steps described so that the function of the software can be verified?
- [x] Community guidelines: Are there clear guidelines for third parties wishing to 1) Contribute to the software 2) Report issues or problems with the software 3) Seek support
Software paper
- [x] Authors: Does the
paper.mdfile include a list of authors with their affiliations? - [x] A statement of need: Do the authors clearly state what problems the software is designed to solve and who the target audience is?
- [x] References: Do all archival references that should have a DOI list one (e.g., papers, datasets, software)?
 whedon
whedon
All 48 comments
Hello human, I'm @whedon, a robot that can help you with some common editorial tasks. @jsgalan it looks like you're currently assigned as the reviewer for this paper :tada:.
:star: Important :star:
If you haven't already, you should seriously consider unsubscribing from GitHub notifications for this (https://github.com/openjournals/joss-reviews) repository. As a reviewer, you're probably currently watching this repository which means for GitHub's default behaviour you will receive notifications (emails) for all reviews 😿
To fix this do the following two things:
- Set yourself as 'Not watching' https://github.com/openjournals/joss-reviews:

- You may also like to change your default settings for this watching repositories in your GitHub profile here: https://github.com/settings/notifications

For a list of things I can do to help you, just type:
@whedon commands
Attempting PDF compilation. Reticulating splines etc...
Just making sure I did not miss anything, but there is not something _I_ should be doing right now, correct?
 PGijsbers
on 24 Dec 2018
PGijsbers
on 24 Dec 2018
Just making sure I did not miss anything, but there is not something I should be doing right now, correct?
Correct, we're waiting on @jsgalan to complete their review (by updating the checklist above).
 arfon
on 24 Dec 2018
arfon
on 24 Dec 2018
@jsgalan
I am sorry to bother and I know there have been holidays in-between, but given the indicated review period I felt compelled to ask. I was wondering if there is any estimate of when you plan to work on this? Or should we see if we can find a substitute?
edit: to be clear, there are no bad feelings here, just looking for an update.
PGijsbers
on 14 Jan 2019
Hi all, i proceeded with the first steps of the review (installation and upgrades here:
installation-gama.txt )
Everything is installed correctly, however I get the following errors,
For Example #1
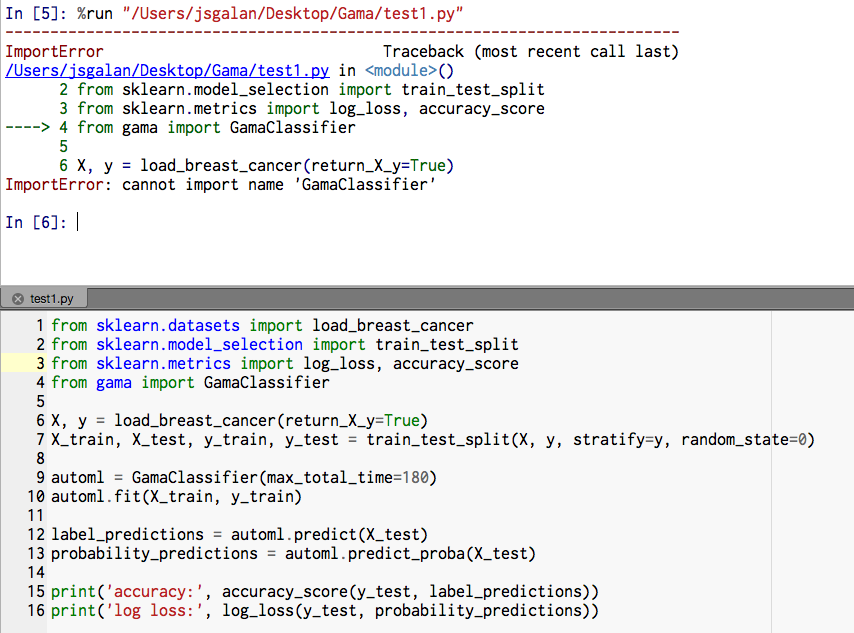
For Example #2
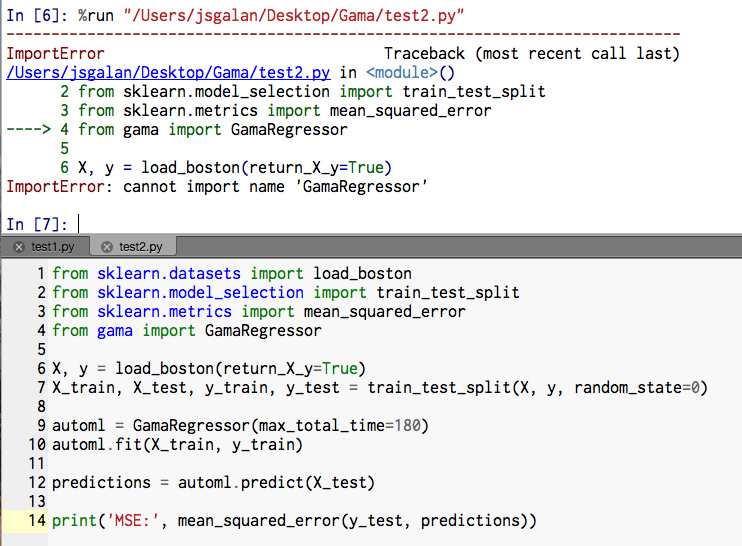
For Example #3

Any clues?
Best
 jsgalan
on 14 Jan 2019
jsgalan
on 14 Jan 2019
That's odd, I can not recreate the issue locally (tried a clean install on a ubuntu docker image). It looks like you installed it to a 'gama' virtual environment, are you also running the scripts from that environment?
PGijsbers
on 15 Jan 2019
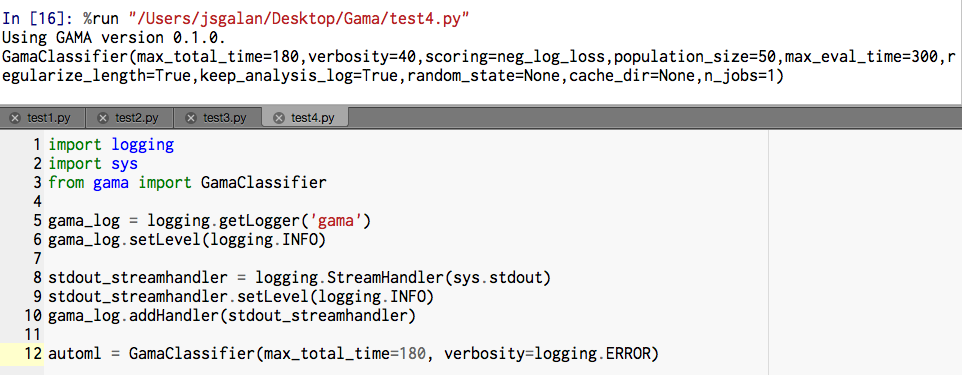
Hi, i restarted the computer and everything worked fine :)
Here are my results for the tests provided in the documentation:

Had a few warnings for run-test2.txt and run-test5.txt
And the rest looked fine also for
run-test3.txt and example 4
jsgalan
on 15 Jan 2019
I have a few suggestions to be made to the authors:
1- add a few examples (not just the minimal example, but all five examples) to the Github repository. Also please check that the examples is wrongly edited, missing the last part of the statement

2- Provide a more detailed examples and explanations of the following sections: Using ARFF files, Logging, Log Visualization and GAMA Search Space Configuration.
3- The authors could add in the manuscript a few lines describing in detai
l logging and log visualization aspects, which can be interesting for a user/reader.
4- Documentation should be complete, in the comparison with other AutoML tools a paragraph is missing.

jsgalan
on 15 Jan 2019
Good to hear it works now! Thank you for the feedback, I will ping you here when I am done resolving the issues. I expect to be able to finish them all by tomorrow.
PGijsbers
on 15 Jan 2019
Hi @jsgalan!
I processed your feedback best I could, but I still have some questions:
- What more detailed explanation are you missing for the log visualization?
- We mentioned the log visualization and type of questions you can currently answer with it in our paper submission. What in particular were you missing or expected to be changed?
I changed log levels of some statements so that anything of at least logging.INFO level will not end with a stream of warning statements. The reported crashes in the statements were harmless to the optimization process, but I concede that it is not a nice user experience :)
For all other aspects, I updated the docs.
Thanks again for your time.
PGijsbers
on 16 Jan 2019
Hi all,
Sorry for being so vague on my descriptions. I will reformulate:
1- add a few examples (not just the minimal example, but all five examples) to the Github repository.
1.1-Also please check that the examples is wrongly edited, missing the last part of the statement <-- this was done! [check!]
2- What more detailed explanation are you missing for the log visualization? <- can this link or this information be found somewhere on the initial Github webpage
3- We mentioned the log visualization and type of questions you can currently answer with it in our paper submission. What in particular were you missing or expected to be changed?
The article currently reads:
In addition to its general use AutoML functionality, GAMA aims to serve AutoML researches as well. During the optimization process, GAMA keeps an extensive log of
progress made. Using this log, insight can be obtained on the behaviour of the population of pipelines. It can answer questions such as which mutation operator is most
effective, how fitness changes over time, and how much time each algorithm takes
I think is important to include in those lines regarding the aspects such as:
a) the figures/plots it produces. (a.e Fitness over number of evaluations vs No. evaluations, Pipeline length over number of evaluations vs No. evaluations and more importantly how Fitness over number of evaluations by main learner vs No. evaluations )
b) all the methods/models that can be learned (a.e NB, Decision Tree,Boosting, Random Forest, KNN, SVC, LogReg). This is not stated clearly in the documentation.
Sorry for being stubborn but I think this should be main focus of the article and be very well described in the Github website, showing all the full capabilities of the software and all the models that can be tested using the implementation.
After revising I think some extra homework...
4- There were .csv files generated that are not well described anywhere

4.1- There were folders empty folders created with the same name of the .csv files.
4.2- Can the user specify the folder/csv files names instead of automatically assigning the date of the experimental run?
Hope this helps.
jsgalan
on 16 Jan 2019
add a few examples (not just the minimal example, but all five examples) to the Github repository.
Could you elaborate what you mean specifically? I made three of them into separate scripts in the example folder and linked them from the README.md. What other examples are you referring to? Setting log output and adding an event hook?
can this link or this information be found somewhere on the initial Github webpage
It is referred to in the documentation but I will add it to the README.md, good call.
4, 4.1
I turned it off for examples now, as I don't think examples should produce extra files. I will add documentation regarding the files should you wish to produce them.
Can the user specify the folder/csv files names instead of automatically assigning the date of the experimental run?
Yes, using the 'cache_dir' hyperparameter when initializing a GamaClassifier or GamaRegressor object. I will make sure it also shows up in the regular documentation (not just API docs).
I'll make the changes tomorrow.
PGijsbers
on 16 Jan 2019
Sorry for being stubborn [...]
Also, no worries :) it's your job 👍 I appreciate the effort you put in
PGijsbers
on 16 Jan 2019
@whedon generate pdf
PGijsbers
on 17 Jan 2019
Attempting PDF compilation. Reticulating splines etc...
@whedon generate pdf
PGijsbers
on 17 Jan 2019
Attempting PDF compilation. Reticulating splines etc...
@whedon generate pdf
Sorry for the spam. It seems that Whedon did not take the last version last time? Missing a line-break.
PGijsbers
on 17 Jan 2019
Attempting PDF compilation. Reticulating splines etc...
Hi @jsgalan,
add a few examples (not just the minimal example, but all five examples) to the Github repository.
No news since last comment.
What more detailed explanation are you missing for the log visualization? <- can this link or this information be found somewhere on the initial Github webpage
Added link and example image to the README.md.
I think is important to include in those lines regarding the aspects such as:
a) the figures/plots it produces [..]
b) all the methods/models that can be learned [..]
I added a plot example to the paper and also explicitly named some algorithms as well as emphasize using scikit-learn algorithms (see the latest article proof).
Furthermore I also explicitly wrote out and linked some of the algorithms used in the documentation.
However, I think including all the different plots produced and algorithms used is not a great idea for three reasons:
- There are many different plots and algorithms, taking up a lot of space while I think the current selection gives a good impression.
- Precise plots and algorithms are not what defines the package. You are free to extract more information from logs and/or add your own algorithms or remove used ones.
- Algorithms and visualization are susceptible to change. Other machine learning packages might be incorporated and/or better visualizations might be developed.
I find the adjustments I made are a reasonable balance between providing too little information and all information. Please let me know if you disagree.
- There were .csv files generated that are not well described anywhere
4.1 There were folders empty folders created with the same name of the .csv files.
4.2- Can the user specify the folder/csv files names instead of automatically assigning the date of the experimental run?
They now have their section in the documentation.
After reconsideration, the .csv is no longer be generated as gama.log supersedes it (and is thus not documented).
PGijsbers
on 17 Jan 2019
Hi all @arfon @PGijsbers
I just revised and all the changes suggested were made in documents and pdf, respectively. I am happy to say that from my part all the requirements were fulfilled.
However, I think including all the different plots produced and algorithms used is not a great idea for three reasons:
There are many different plots and algorithms, taking up a lot of space while I think the current selection gives a good impression.
Precise plots and algorithms are not what defines the package. You are free to extract more information from logs and/or add your own algorithms or remove used ones.
Algorithms and visualization are susceptible to change. Other machine learning packages might be incorporated and/or better visualizations might be developed
Answering to this comment, after my initial thoughts and replies, I imagined that the package can be (and will be extended) to include different types of tests or can be put into a greater pipeline using various packages, so i concur with your reasoning.
Happy to revise and test this novel tool that will be beneficial for the ML community.
Best
jsgalan
on 17 Jan 2019
Thanks again for all your effort @jsgalan!
PGijsbers
on 17 Jan 2019
I just noticed @arokem was not pinged, but he is the editor, I figure he needs to be pinged too/instead. So.. there :)
PGijsbers
on 18 Jan 2019
Great work everyone! Thanks for the review @jsgalan!
@PGijsbers : your paper is ready to be processed for acceptance.
Could you please create an archive of the current state of your software (e.g., by creating a tag/version of the software and uploading that to zenodo).
Once you have a DOI for the software, please post it here, so we can add the archive to the paper.
 arokem
on 20 Jan 2019
arokem
on 20 Jan 2019
Done. Zenodo directs me here but it doesn't show. I assume it will just take a few minutes?
PGijsbers
on 21 Jan 2019
Seems like it is all fixed @arokem
PGijsbers
on 21 Jan 2019
@whedon set 10.5281/zenodo.2545472 as archive
PGijsbers
on 24 Jan 2019
I'm sorry @PGijsbers, I'm afraid I can't do that. That's something only editors are allowed to do.
whedon
on 24 Jan 2019
Actually not sure what is preferred here:
- specifically this version: 10.5281/zenodo.2545472
- link to latest: 10.5281/zenodo.2545471
PGijsbers
on 24 Jan 2019
I think that this one is fine: 10.5281/zenodo.2545472
This is the version you generated after incorporating all of the reviewer comments?
Could you please edit the metadata of the Zenodo page (title and authors), so that it matches the paper?
Thanks!
arokem
on 27 Jan 2019
Done!
PGijsbers
on 28 Jan 2019
@whedon set 10.5281/zenodo.2545472 as archive
arokem
on 30 Jan 2019
OK. 10.5281/zenodo.2545472 is the archive.
whedon
on 30 Jan 2019
Congratulations! Your paper is now ready to be accepted.
Stand by for EIC or an Associate EIC to drop by and finalize this.
arokem
on 30 Jan 2019
Thanks for editing @arokem
Thanks for reviewing @jsgalan
And thanks for submitting @PGijsbers
 danielskatz
on 30 Jan 2019
danielskatz
on 30 Jan 2019
@whedon accept
danielskatz
on 30 Jan 2019
Attempting dry run of processing paper acceptance...
```Reference check summary:
OK DOIs
MISSING DOIs
- https://doi.org/10.3389/fninf.2014.00014 may be missing for title: Scikit-learn: Machine Learning in Python
INVALID DOIs
- None
```
whedon
on 30 Jan 2019
Check final proof :point_right: https://github.com/openjournals/joss-papers/pull/460
If the paper PDF and Crossref deposit XML look good in https://github.com/openjournals/joss-papers/pull/460, then you can now move forward with accepting the submission by compiling again with the flag deposit=true e.g.
@whedon accept deposit=true
whedon
on 30 Jan 2019
@whedon accept deposit=true
danielskatz
on 30 Jan 2019
Doing it live! Attempting automated processing of paper acceptance...
🚨🚨🚨 THIS IS NOT A DRILL, YOU HAVE JUST ACCEPTED A PAPER INTO JOSS! 🚨🚨🚨
Here's what you must now do:
- Check final PDF and Crossref metadata that was deposited :point_right: https://github.com/openjournals/joss-papers/pull/461
- Wait a couple of minutes to verify that the paper DOI resolves https://doi.org/10.21105/joss.01132
- If everything looks good, then close this review issue.
Party like you just published a paper! 🎉🌈🦄💃👻🤘
Any issues? notify your editorial technical team...
whedon
on 30 Jan 2019
:tada::tada::tada: Congratulations on your paper acceptance! :tada::tada::tada:
If you would like to include a link to your paper from your README use the following code snippets:
Markdown:
[](https://doi.org/10.21105/joss.01132)
HTML:
<a style="border-width:0" href="https://doi.org/10.21105/joss.01132">
<img src="http://joss.theoj.org/papers/10.21105/joss.01132/status.svg" alt="DOI badge" >
</a>
reStructuredText:
.. image:: http://joss.theoj.org/papers/10.21105/joss.01132/status.svg
:target: https://doi.org/10.21105/joss.01132
This is how it will look in your documentation:

We need your help!
Journal of Open Source Software is a community-run journal and relies upon volunteer effort. If you'd like to support us please consider doing either one (or both) of the the following:
- Volunteering to review for us sometime in the future. You can add your name to the reviewer list here: http://joss.theoj.org/reviewer-signup.html
- Making a small donation to support our running costs here: https://www.flipcause.com/secure/cause_pdetails/Mjk3Nzk=
whedon
on 30 Jan 2019
Related issues
whedon
·
12Comments
whedon
·
12Comments
whedon
·
11Comments
whedon
·
8Comments
whedon
·
12Comments
Most helpful comment
Thanks for editing @arokem
Thanks for reviewing @jsgalan
And thanks for submitting @PGijsbers