Jooq: Improve performance of Record.into(Table) and related calls
Hi, and first of all thanks for a this great tool, we've been able to do almost everything we wanted so far on top of this clean abstraction that is jOOQ!
We are starting to run into performance issues as our DB fills up, and I tracked down part of it to what I believe is an inefficiency when converting "untyped" Records into "typed" MyTableRecords.
During my debugging, I found out that Record.into(Table) takes a small but non-negligible time, in my example debugging case ~200us. Unfortunately on a query returning 200 results this quickly adds up to ~40ms, a very large overhead for this simple query that itself takes ~10ms.
Profiling and looking at the code itself, it seems that most of the time is spent computing the mapping between the fields in the resulting Record and the target MyTableRecord:

From that observation, I think it should be possible to greatly reduce the overhead for queries returning relatively large result sets by only computing this mapping once and re-using it for all resulting records, h and I hoped this would be implemented in Result<Record>.into(Table), but unfortunately all this does is looping over all resutling record and calling Record.into(Table).
Obviously I know quite little of the jOOQ codebase so please lmk if I missed something obvious, or if there is a reason preventing to factorize the mapping computation to happen only once per query as opposed to once per record.
I'm planning to try and implement an alternative version of Result<>.into to try and do that as a PoC/workaround when I have the time, but obviously it would be lovely if the library itself supported it, and if I'm right a lot of other jOOQ users would benefit too!
Thanks,
-Arthur
Note:
I had posted a probably better written version of this as a comment on https://www.jooq.org/doc/latest/manual/sql-execution/performance-considerations/ a couple weeks ago, but it seems the discussion threads on the documentation pages have been entirely removed basically right after :(
So sorry if this issue is a bit less precise than it could be, I'm reconstructing my findings mostly from memory.
 alacoste
alacoste
All 38 comments
Thanks a lot for your report, and I'm sorry for the inconvenience about the removed comment on the manual. We hadn't removed only your comment, but all comments from the website, see https://github.com/jOOQ/jOOQ/issues/10962. I replied to your comment, and you should have received a notification message. You can still access it on disqus.com:
https://disqus.com/home/discussion/jooq/performance_considerations/#comment-5156026924
If you haven't received a notification, this just shows once more that disqus does not work well enough for us. I've lost way too many notifications myself, with messages having gone unanswered for months!
You're right, we should extract a mapper for the duration of the loop instead of looking it up on every record. We already do that for a variety of other mappings (e.g. into(Class)), but we're not doing that for into(Table) yet. This will be a pretty simple fix, I think. Will try to fix it right away.
 lukaseder
on 1 Dec 2020
lukaseder
on 1 Dec 2020
lukaseder
on 1 Dec 2020
lukaseder
on 1 Dec 2020
I'm not sure how to read your flame graph, but in a profiling session, it seems obvious that a lot of CPU cycles are wasted in wrapping the Table.fields() array in a temporary Row instance:
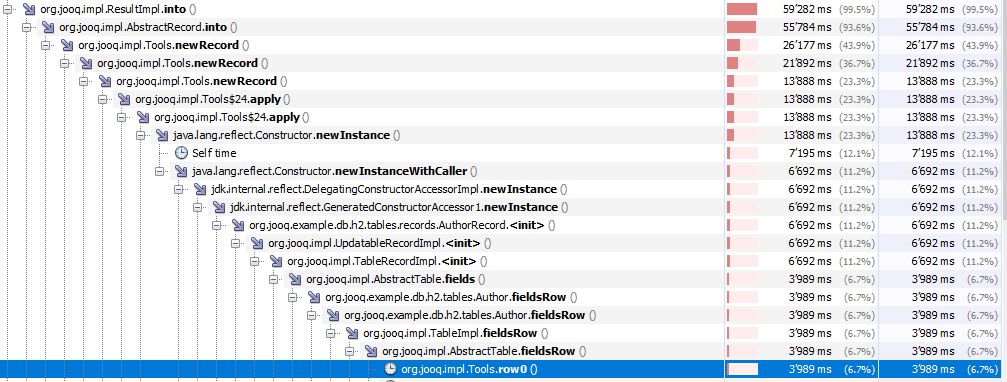
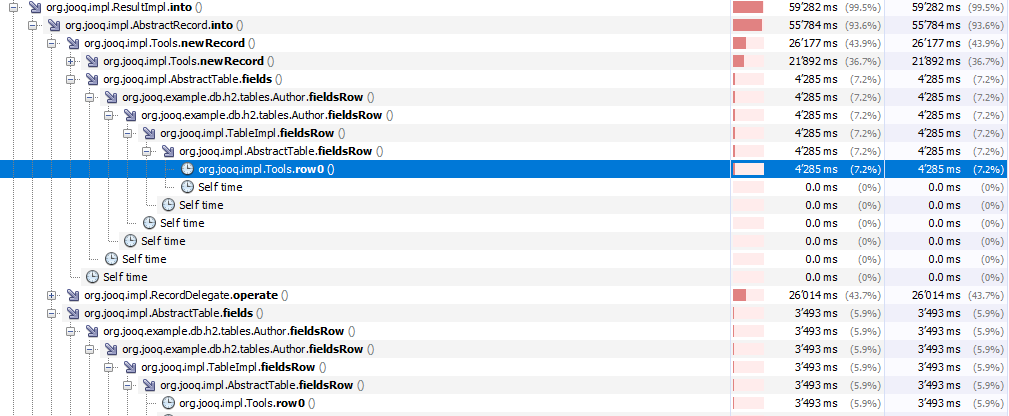
Another hot spot is looking up fields in the fields array with the O(N) lookup algorithm:

Both can obviously be improved.
lukaseder
on 1 Dec 2020
Well, caching the fieldsRow() lookup in the table seems to be a very low hanging fruit.
Before
Benchmark Mode Cnt Score Error Units
BenchmarkRecordMapper.intoTableCache thrpt 5 1458359.918 ± 9696.187 ops/s
BenchmarkRecordMapper.intoTableNoCache thrpt 5 1479192.078 ± 64283.812 ops/s
After
Benchmark Mode Cnt Score Error Units
BenchmarkRecordMapper.intoTableCache thrpt 5 1762523.256 ± 8437.748 ops/s
BenchmarkRecordMapper.intoTableNoCache thrpt 5 1780473.360 ± 8192.952 ops/s
Other mapping benchmarks seem unaffected by the change, neither positively nor negatively.
lukaseder
on 1 Dec 2020
With the cached Table.fieldsRow(), we can now attempt to avoid calling Tools.row0() in the AbstractRecord constructor:
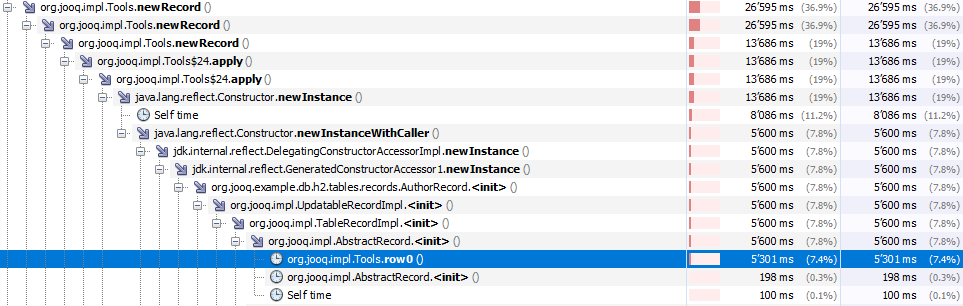
Further improvement can be seen:
Benchmark Mode Cnt Score Error Units
BenchmarkRecordMapper.intoTableCache thrpt 5 1918579.192 ± 17475.524 ops/s
BenchmarkRecordMapper.intoTableNoCache thrpt 5 1909308.100 ± 16318.026 ops/s
These were the low hanging fruit, which brought a 30% improvement, which isn't bad. Now the elephant in the room is the unnecessary, repeated call to Row.indexOf(field), which is an O(N) field look up to map between source and target fields, something that can definitely be cached for the duration of the loop within the Result, but it's not as simple as the other improvements:

lukaseder
on 1 Dec 2020
It's not worth looking at Result.into(Table) in isolation. There are many other looping mapping methods on Result that could profit from this, including e.g. Result.intoMap(Table), Result.intoMap(Table, Table), and many more. I'll need to think about this a bit more.
I'm planning to try and implement an alternative version of Result<>.into to try and do that as a PoC/workaround when I have the time, but obviously it would be lovely if the library itself supported it, and if I'm right a lot of other jOOQ users would benefit too!
Did you have anything specific in mind?
lukaseder
on 1 Dec 2020
Some improvements will be backported to 3.14.5 (#11060)
lukaseder
on 1 Dec 2020
I probably missed the notification, but had guessed you migrated away from that comment system. Github does have its many flaws but it does an OK job at reporting and discussing issues!
Thanks for your super-prompt action on this, and it seems I'd be more getting in your way than anything else, but please do let me know if I can do anything that would help!
alacoste
on 1 Dec 2020
It's not worth looking at
Result.into(Table)in isolation. There are many other looping mapping methods onResultthat could profit from this, including e.g.Result.intoMap(Table),Result.intoMap(Table, Table), and many more. I'll need to think about this a bit more.I'm planning to try and implement an alternative version of Result<>.into to try and do that as a PoC/workaround when I have the time, but obviously it would be lovely if the library itself supported it, and if I'm right a lot of other jOOQ users would benefit too!
Did you have anything specific in mind?
Well, nothing clear obviously since I don't know the inner working of jOOQ very well, but basically hoped to compute the "mapping" of the kind of records returned by the actual query to the kind of records I want once, then apply that mapping 200 times, as my investigation led me to believe constructing the mapping was the slower part, and moving the data around was fast.
alacoste
on 1 Dec 2020
Hmm, something that isn't being measured currently in our benchmarks is your usage of non-TableField fields in your projection, which leads to the less efficient TableFieldImpl::equals call. I wonder how that came to be... Would be interesting to see your jOOQ query. It doesn't happen when you use the table fields from the code generator, as that would produce short circuiting identity comparisons in Row.indexOf(Field)...
lukaseder
on 1 Dec 2020
as my investigation led me to believe constructing the mapping was the slower part, and moving the data around was fast.
Yes, the remaining bottleneck is the lookup of source column index -> target column index, which is done on each iteration.
lukaseder
on 1 Dec 2020
but please do let me know if I can do anything that would help!
If you could add the query leading to your flamegraph, that would be very useful
lukaseder
on 1 Dec 2020
Here is the SQL query in my debugging case. It lets us do a batch query for all messages in several conversations ("experiences", here 60 of them), with pagination (order by ... limit 6) of messages inside each conversation.
SELECT "tmp_table"."target_id",
"message"."id",
"message"."uuid",
"message"."created_at",
"message"."event_time",
"message"."text_content",
"message"."experience_id",
"message"."type",
"message"."starred",
"message"."doctor_id",
"message"."visible_to_patient",
"message"."file_upload_id",
"message"."retry_counter",
"message"."reply_message_id",
"message"."is_reply",
"message"."sender_type",
"message"."is_automatic",
"message"."has_deleted_content"
FROM (VALUES (1),
(2),
(3),
(4),
(5),
(6),
(7),
(8),
(9),
(10),
(11),
(12),
(13),
(14),
(15),
(16),
(17),
(18),
(19),
(20),
(21),
(22),
(23),
(24),
(25),
(26),
(27),
(28),
(29),
(30),
(31),
(32),
(33),
(34),
(35),
(36),
(37),
(38),
(39),
(40),
(41),
(42),
(43),
(44),
(45),
(46),
(48),
(47),
(49),
(50),
(51),
(52),
(53),
(54),
(55),
(56),
(57),
(58),
(59),
(60)) AS "tmp_table" ("target_id"),
LATERAL (SELECT "public"."message"."id",
"public"."message"."uuid",
"public"."message"."created_at",
"public"."message"."event_time",
"public"."message"."text_content",
"public"."message"."experience_id",
"public"."message"."type",
"public"."message"."starred",
"public"."message"."doctor_id",
"public"."message"."visible_to_patient",
"public"."message"."file_upload_id",
"public"."message"."retry_counter",
"public"."message"."reply_message_id",
"public"."message"."is_reply",
"public"."message"."sender_type",
"public"."message"."is_automatic",
"public"."message"."has_deleted_content"
FROM "public"."message"
WHERE "public"."message"."experience_id" = "tmp_table"."target_id"
ORDER BY "public"."message"."event_time" DESC, "public"."message"."created_at" DESC
LIMIT 6) AS "message";
This query returns 168 records here:
2020-12-01 15:56:32.487 [DefaultDispatcher-worker-4 @coroutine#31] DEBUG ace.db.jooq.utils.JooqLoggerListener - Fetched row(s) : 168
Then we manually group the resulting rows by conversation (target_id) and convert them into MessageRecords, which is the slow step.
I can try to inspect the jOOQ Query object right before executing it too if that would help.
alacoste
on 1 Dec 2020
In case that helps, here is the generate jOOQ class for the message table:
/**
* This class is generated by jOOQ.
*/
@SuppressWarnings({ "all", "unchecked", "rawtypes" })
public class Message extends TableImpl<MessageRecord> {
private static final long serialVersionUID = 1L;
/**
* The reference instance of <code>public.message</code>
*/
public static final Message MESSAGE = new Message();
/**
* The class holding records for this type
*/
@Override
public Class<MessageRecord> getRecordType() {
return MessageRecord.class;
}
/**
* The column <code>public.message.id</code>.
*/
public final TableField<MessageRecord, Integer> ID = createField(DSL.name("id"), SQLDataType.INTEGER.nullable(false).identity(true), this, "");
/**
* The column <code>public.message.uuid</code>.
*/
public final TableField<MessageRecord, java.util.UUID> UUID = createField(DSL.name("uuid"), SQLDataType.UUID.nullable(false).defaultValue(DSL.field("uuid_generate_v4()", SQLDataType.UUID)), this, "");
/**
* The column <code>public.message.created_at</code>.
*/
public final TableField<MessageRecord, OffsetDateTime> CREATED_AT = createField(DSL.name("created_at"), SQLDataType.TIMESTAMPWITHTIMEZONE(6).nullable(false).defaultValue(DSL.field("now()", SQLDataType.TIMESTAMPWITHTIMEZONE)), this, "");
/**
* The column <code>public.message.event_time</code>.
*/
public final TableField<MessageRecord, OffsetDateTime> EVENT_TIME = createField(DSL.name("event_time"), SQLDataType.TIMESTAMPWITHTIMEZONE(6).nullable(false).defaultValue(DSL.field("now()", SQLDataType.TIMESTAMPWITHTIMEZONE)), this, "");
/**
* The column <code>public.message.text_content</code>.
*/
public final TableField<MessageRecord, String> TEXT_CONTENT = createField(DSL.name("text_content"), SQLDataType.CLOB.defaultValue(DSL.field("''::text", SQLDataType.CLOB)), this, "");
/**
* The column <code>public.message.experience_id</code>.
*/
public final TableField<MessageRecord, Integer> EXPERIENCE_ID = createField(DSL.name("experience_id"), SQLDataType.INTEGER.nullable(false), this, "");
/**
* The column <code>public.message.type</code>.
*/
public final TableField<MessageRecord, MessageType> TYPE = createField(DSL.name("type"), SQLDataType.VARCHAR.nullable(false).defaultValue(DSL.field("'TEXT'::message_type", SQLDataType.VARCHAR)).asEnumDataType(ace.db.enums.MessageType.class), this, "");
/**
* The column <code>public.message.starred</code>.
*/
public final TableField<MessageRecord, Boolean> STARRED = createField(DSL.name("starred"), SQLDataType.BOOLEAN.nullable(false).defaultValue(DSL.field("false", SQLDataType.BOOLEAN)), this, "");
/**
* The column <code>public.message.doctor_id</code>.
*/
public final TableField<MessageRecord, Integer> DOCTOR_ID = createField(DSL.name("doctor_id"), SQLDataType.INTEGER, this, "");
/**
* The column <code>public.message.visible_to_patient</code>.
*/
public final TableField<MessageRecord, Boolean> VISIBLE_TO_PATIENT = createField(DSL.name("visible_to_patient"), SQLDataType.BOOLEAN.nullable(false).defaultValue(DSL.field("true", SQLDataType.BOOLEAN)), this, "");
/**
* The column <code>public.message.file_upload_id</code>.
*/
public final TableField<MessageRecord, Integer> FILE_UPLOAD_ID = createField(DSL.name("file_upload_id"), SQLDataType.INTEGER, this, "");
/**
* The column <code>public.message.retry_counter</code>.
*/
public final TableField<MessageRecord, Integer> RETRY_COUNTER = createField(DSL.name("retry_counter"), SQLDataType.INTEGER.nullable(false).defaultValue(DSL.field("0", SQLDataType.INTEGER)), this, "");
/**
* The column <code>public.message.reply_message_id</code>.
*/
public final TableField<MessageRecord, Integer> REPLY_MESSAGE_ID = createField(DSL.name("reply_message_id"), SQLDataType.INTEGER, this, "");
/**
* The column <code>public.message.is_reply</code>.
*/
public final TableField<MessageRecord, Boolean> IS_REPLY = createField(DSL.name("is_reply"), SQLDataType.BOOLEAN.nullable(false).defaultValue(DSL.field("false", SQLDataType.BOOLEAN)), this, "");
/**
* The column <code>public.message.sender_type</code>.
*/
public final TableField<MessageRecord, MessageSenderType> SENDER_TYPE = createField(DSL.name("sender_type"), SQLDataType.VARCHAR.nullable(false).asEnumDataType(ace.db.enums.MessageSenderType.class), this, "");
/**
* The column <code>public.message.is_automatic</code>.
*/
public final TableField<MessageRecord, Boolean> IS_AUTOMATIC = createField(DSL.name("is_automatic"), SQLDataType.BOOLEAN.nullable(false), this, "");
/**
* The column <code>public.message.has_deleted_content</code>.
*/
public final TableField<MessageRecord, Boolean> HAS_DELETED_CONTENT = createField(DSL.name("has_deleted_content"), SQLDataType.BOOLEAN.nullable(false), this, "");
private Message(Name alias, Table<MessageRecord> aliased) {
this(alias, aliased, null);
}
private Message(Name alias, Table<MessageRecord> aliased, Field<?>[] parameters) {
super(alias, null, aliased, parameters, DSL.comment(""), TableOptions.table());
}
/**
* Create an aliased <code>public.message</code> table reference
*/
public Message(String alias) {
this(DSL.name(alias), MESSAGE);
}
/**
* Create an aliased <code>public.message</code> table reference
*/
public Message(Name alias) {
this(alias, MESSAGE);
}
/**
* Create a <code>public.message</code> table reference
*/
public Message() {
this(DSL.name("message"), null);
}
public <O extends Record> Message(Table<O> child, ForeignKey<O, MessageRecord> key) {
super(child, key, MESSAGE);
}
@Override
public Schema getSchema() {
return Public.PUBLIC;
}
@Override
public List<Index> getIndexes() {
return Arrays.<Index>asList(Indexes.CALL_UUID_BEA0B6C2, Indexes.MESSAGE_EXPERIENCE_ID_B8960612, Indexes.MESSAGE_UUID_BE1056C2);
}
@Override
public Identity<MessageRecord, Integer> getIdentity() {
return (Identity<MessageRecord, Integer>) super.getIdentity();
}
@Override
public UniqueKey<MessageRecord> getPrimaryKey() {
return Keys.MESSAGE_PKEY;
}
@Override
public List<UniqueKey<MessageRecord>> getKeys() {
return Arrays.<UniqueKey<MessageRecord>>asList(Keys.MESSAGE_PKEY, Keys.MESSAGE_UUID_KEY);
}
@Override
public List<ForeignKey<MessageRecord, ?>> getReferences() {
return Arrays.<ForeignKey<MessageRecord, ?>>asList(Keys.MESSAGE__MESSAGE_EXPERIENCE_ID_B8960612_FK_EXPERIENCE_ID, Keys.MESSAGE__MESSAGE_DOCTOR_ID_FKEY, Keys.MESSAGE__MESSAGE_FILE_UPLOAD_ID_FKEY, Keys.MESSAGE__MESSAGE_REPLY_MESSAGE_ID_FKEY);
}
public Experience experience() {
return new Experience(this, Keys.MESSAGE__MESSAGE_EXPERIENCE_ID_B8960612_FK_EXPERIENCE_ID);
}
public Doctor doctor() {
return new Doctor(this, Keys.MESSAGE__MESSAGE_DOCTOR_ID_FKEY);
}
public FileUpload fileUpload() {
return new FileUpload(this, Keys.MESSAGE__MESSAGE_FILE_UPLOAD_ID_FKEY);
}
public Message message() {
return new Message(this, Keys.MESSAGE__MESSAGE_REPLY_MESSAGE_ID_FKEY);
}
@Override
public List<Check<MessageRecord>> getChecks() {
return Arrays.<Check<MessageRecord>>asList(
Internal.createCheck(this, DSL.name("if_type_audio_then_file_upload_not_null"), "(((type <> 'AUDIO'::message_type) OR (file_upload_id IS NOT NULL)))", true)
, Internal.createCheck(this, DSL.name("if_type_file_then_file_upload_not_null"), "(((type <> 'FILE'::message_type) OR (file_upload_id IS NOT NULL)))", true)
, Internal.createCheck(this, DSL.name("if_type_image_then_file_upload_not_null"), "(((type <> 'IMAGE'::message_type) OR (file_upload_id IS NOT NULL)))", true)
, Internal.createCheck(this, DSL.name("if_type_text_then_text_content_not_null"), "(((type <> 'TEXT'::message_type) OR (text_content IS NOT NULL)))", true)
, Internal.createCheck(this, DSL.name("if_type_video_then_file_upload_not_null"), "(((type <> 'VIDEO'::message_type) OR (file_upload_id IS NOT NULL)))", true)
, Internal.createCheck(this, DSL.name("patient_message_is_not_automatically_generated"), "(((sender_type <> 'PATIENT'::message_sender_type) OR (is_automatic = false)))", true)
, Internal.createCheck(this, DSL.name("reply_message_id_different_from_id"), "((reply_message_id <> id))", true)
, Internal.createCheck(this, DSL.name("reply_message_id_null_if_is_not_reply"), "(((is_reply = true) OR (reply_message_id IS NULL)))", true)
, Internal.createCheck(this, DSL.name("system_message_is_always_automatically_generated"), "(((sender_type <> 'SYSTEM'::message_sender_type) OR (is_automatic = true)))", true)
, Internal.createCheck(this, DSL.name("system_message_is_not_doctor_message"), "(((sender_type <> 'DOCTOR'::message_sender_type) <> (doctor_id IS NOT NULL)))", true)
);
}
@Override
public Message as(String alias) {
return new Message(DSL.name(alias), this);
}
@Override
public Message as(Name alias) {
return new Message(alias, this);
}
/**
* Rename this table
*/
@Override
public Message rename(String name) {
return new Message(DSL.name(name), null);
}
/**
* Rename this table
*/
@Override
public Message rename(Name name) {
return new Message(name, null);
}
// -------------------------------------------------------------------------
// Row17 type methods
// -------------------------------------------------------------------------
@Override
public Row17<Integer, java.util.UUID, OffsetDateTime, OffsetDateTime, String, Integer, MessageType, Boolean, Integer, Boolean, Integer, Integer, Integer, Boolean, MessageSenderType, Boolean, Boolean> fieldsRow() {
return (Row17) super.fieldsRow();
}
}
Interesting, thanks for sharing. How did you construct it (with jOOQ API)?
lukaseder
on 1 Dec 2020
The code is factorized to be shared between various foreign keys, but it looks like:
(Sorry it has a bunch of mostly irrelevant things I guess, but I don't want to prune too much of what I think is irrelevant since I'm not sure exactly what you are looking for. Tried to explain everything)
private suspend fun getReferencingEntitiesForIdsPaginated(
components: IComponents,
dsl: DSLContext,
targetIds: Set<U>,
page: ReferenceFromAdditionalInput.Page
): List<R2> { // Here R2 is our MessageRecord
// Create a "fake" table of values containing the target IDs.
val targetRows = targetIds.map { row(it) }
val tmpTable = values(*targetRows.toTypedArray()).`as`("tmp_table", "target_id")
@Suppress("UNCHECKED_CAST")
val targetTmpField = tmpTable.field("target_id") as Field<U>
// Query the reference table, paginating independently for each entry in our fake table.
return dsl
.select()
.from(
tmpTable,
lateral(
select(*referenceCompanion.table.fields()) // This selects all the fields of Message
.distinctOn(*distinctOnFields) // This should have no impact here
.fromJoin() // See below, but basically joins against
.where(referenceField.eq(targetTmpField)) // Joining against the tmp_table
.and(condition) // Custom condition passed from the top, probably noCondition() / not impactful here.
.paginate(page) // Just does a .and(someTimeField > someTimeThreshold).orderBy(someTimeField, otherSortingFields).limit()
).`as`(referenceCompanion.table) // This will be the message table here.
)
.fetchAllSuspendingInto(components, referenceCompanion.table) // Out utility, eventually wraps fetch()
}
private fun <R : Record> SelectFromStep<R>.fromJoin(): SelectJoinStep<R> =
from(referenceCompanion.table.withLeftJoin())
private fun Table<R2>.withLeftJoin(): Table<*> = additionalTable?.let { table ->
additionalTableJoinCondition?.let { leftJoin(table).on(it) } ?: leftJoin(table).onKey()
} ?: this
OK, I'll try to chase the fact that your query uses fully qualified column names (e.g. "public"."message"."id"), but with the derived table, the columns are no longer fully qualified (e.g. "message"."id").
Given:
Table<?> t= table(select(T_BOOK.AUTHOR_ID).from(T_BOOK)).as(T_BOOK, T_BOOK.AUTHOR_ID);
Field<Integer> f = t.field(T_BOOK.AUTHOR_ID);
...Both of these calls ultimately wind up in the costly AbstractQueryPart::equals implementation:
T_BOOK.AUTHOR_ID.equals(f);
f.equals(T_BOOK.AUTHOR_ID);
Which calls DSLContext::renderInlined etc.
lukaseder
on 2 Dec 2020
As a workaround, you could try to turn off schema qualification in your code generator using:
<outputSchemaToDefault>true</outputSchemaToDefault>
That way, you should profit from a short circuiting call in AbstractNamed::equals. Can you confirm that on your side?
lukaseder
on 2 Dec 2020
OK, I can confirm with a benchmark that this problem is really about comparing schema.table.column field references with table.column field references. All the other comparisons are much faster:
Benchmark Mode Cnt Score Error Units
BenchmarkRecordAccess.testAccessFirstColumnByExactFieldRef thrpt 7 224178590.681 ± 2702249.987 ops/s
BenchmarkRecordAccess.testAccessFirstColumnByIndex thrpt 7 345303597.422 ± 1158450.635 ops/s
BenchmarkRecordAccess.testAccessFirstColumnByName thrpt 7 27200172.142 ± 140554.392 ops/s
BenchmarkRecordAccess.testAccessFirstColumnBySimilarFieldRef thrpt 7 15619860.109 ± 73329.193 ops/s
BenchmarkRecordAccess.testAccessFirstColumnBySimilarFieldRefWithTableQualification thrpt 7 187093.789 ± 1884.166 ops/s
Where:
testAccessFirstColumnByExactFieldRefprofits from identity comparisonstestAccessFirstColumnByIndexprofits from index access (obviously the fastest)testAccessFirstColumnByNamecompares unqualified names (OK)testAccessFirstColumnBySimilarFieldRefcompares qualified names with unqualified names (OK)testAccessFirstColumnBySimilarFieldRefWithTableQualificationcompares fully qualified names with partially qualified names (terrible)
JMH benchmark logic:
@Fork(value = 1, jvmArgsAppend = "-Dorg.jooq.no-logo=true")
@Warmup(iterations = 3, time = 3)
@Measurement(iterations = 7, time = 3)
@State(Scope.Benchmark)
public class BenchmarkRecordAccess {
@State(Scope.Benchmark)
public static class BenchmarkState {
DSLContext ctx;
Record record;
Field<Integer> id;
Field<Integer> bookId;
int idIndex;
Field<LocalDateTime> recTimestamp;
Field<LocalDateTime> bookRecTimestamp;
int recTimestampIndex;
@Setup(Level.Trial)
public void setup() {
ctx = DSL.using(SQLDialect.H2);
record = ctx.newRecord(BOOK);
id = field(BOOK.ID.getUnqualifiedName(), BOOK.ID.getDataType());
bookId = field(BOOK.getUnqualifiedName().append(BOOK.ID.getUnqualifiedName()), BOOK.ID.getDataType());
idIndex = BOOK.fieldsRow().indexOf(BOOK.ID);
recTimestamp = field(BOOK.REC_TIMESTAMP.getUnqualifiedName(), BOOK.REC_TIMESTAMP.getDataType());
bookRecTimestamp = field(BOOK.getUnqualifiedName().append(BOOK.REC_TIMESTAMP.getUnqualifiedName()), BOOK.REC_TIMESTAMP.getDataType());
recTimestampIndex = BOOK.fieldsRow().indexOf(BOOK.REC_TIMESTAMP);
}
}
public static void main(String[] args) throws Exception {
BenchmarkState state = new BenchmarkState();
state.setup();
new BenchmarkRecordAccess().testAccessFirstColumnBySimilarFieldRefWithTableQualification(state);
}
@Benchmark
public Object testAccessFirstColumnByIndex(BenchmarkState state) {
return state.record.get(state.idIndex);
}
@Benchmark
public Object testAccessFirstColumnByName(BenchmarkState state) {
return state.record.get("ID");
}
@Benchmark
public Object testAccessFirstColumnByExactFieldRef(BenchmarkState state) {
return state.record.get(BOOK.ID);
}
@Benchmark
public Object testAccessFirstColumnBySimilarFieldRef(BenchmarkState state) {
return state.record.get(state.id);
}
@Benchmark
public Object testAccessFirstColumnBySimilarFieldRefWithTableQualification(BenchmarkState state) {
return state.record.get(state.bookId);
}
// @Benchmark
public Object testAccessLastColumnByIndex(BenchmarkState state) {
return state.record.get(state.recTimestampIndex);
}
// @Benchmark
public Object testAccessLastColumnByName(BenchmarkState state) {
return state.record.get("REC_TIMESTAMP");
}
// @Benchmark
public Object testAccessLastColumnByExactFieldRef(BenchmarkState state) {
return state.record.get(BOOK.REC_TIMESTAMP);
}
// @Benchmark
public Object testAccessLastColumnBySimilarFieldRef(BenchmarkState state) {
return state.record.get(state.recTimestamp);
}
//@Benchmark
public Object testAccessLastColumnBySimilarFieldRefWithTableQualification(BenchmarkState state) {
return state.record.get(state.bookRecTimestamp);
}
}
While the O(N) lookups in indexOf() calls could probably be improved as well (this is much more delicate), clearly, the call to renderInlined() should be prevented.
lukaseder
on 2 Dec 2020
A significant part of these AbstractQueryPart::renderInlined calls are done because we don't override CatalogImpl::equals: https://github.com/jOOQ/jOOQ/issues/11078
lukaseder
on 2 Dec 2020
For the record, that improvement had this impact:
Benchmark Mode Cnt Score Error Units
BenchmarkRecordAccess.testAccessFirstColumnBySimilarFieldRefWithTableQualification thrpt 7 187093.789 ± 1884.166
BenchmarkRecordAccess.testAccessFirstColumnBySimilarFieldRefWithTableQualification thrpt 7 6637299.749 ± 21159.432 ops/s
Could still be better, but is already very significant. I'll look into this more tomorrow, I think your call ist yet different, because TableAlias is involved.
lukaseder
on 2 Dec 2020
Regarding #11064 that was closed in lieu of this ticket: the fixes on this ticket only apply to TableRecords and their underlying Tables, but also ad-hoc records (e.g. RecordImpl1, RecordImpl2...) could use some form of caching for their fieldsRow().
I'm also unsure why AbstractRecord itself uses both fieldsRow().indexOf(...) and fields.indexOf(...), depending on method. The former entails quite a lot of logic for non-TableRecord classes.
 arlampin
on 3 Dec 2020
arlampin
on 3 Dec 2020
Regarding #11064 that was closed in lieu of this ticket: the fixes on this ticket only apply to TableRecords and their underlying Tables, but also ad-hoc records (e.g. RecordImpl1, RecordImpl2...) could use some form of caching for their
fieldsRow().
Thanks for the pointer. Perhaps #11064 is a different (though related) issue after all. I'll check again.
I'm also unsure why
AbstractRecorditself uses bothfieldsRow().indexOf(...)andfields.indexOf(...), depending on method. The former entails quite a lot of logic for non-TableRecord classes.
There's probably no good reason...
lukaseder
on 3 Dec 2020
I'm also unsure why
AbstractRecorditself uses bothfieldsRow().indexOf(...)andfields.indexOf(...), depending on method. The former entails quite a lot of logic for non-TableRecord classes.There's probably no good reason...
This seems to be a historic issue. At some point, the fields reference may not have been accessible from where that logic was implemented at the time (perhaps a subtype). I don't see a good reason why we should call fieldsRow() from within AbstractRecord. We already don't in most cases.
lukaseder
on 3 Dec 2020
Running our benchmarks again on RecordImpl2 instead of TableRecordImpl with the status quo:
Benchmark Mode Cnt Score Error Units
BenchmarkRecordAccess.testAccessFirstColumnByExactFieldRef thrpt 7 100145925.332 ± 2222725.225 ops/s
BenchmarkRecordAccess.testAccessFirstColumnByIndex thrpt 7 293331310.856 ± 2734585.993 ops/s
BenchmarkRecordAccess.testAccessFirstColumnByName thrpt 7 66610065.295 ± 996860.124 ops/s
BenchmarkRecordAccess.testAccessFirstColumnBySimilarFieldRef thrpt 7 37247839.685 ± 203619.159 ops/s
BenchmarkRecordAccess.testAccessFirstColumnBySimilarFieldRefWithTableQualification thrpt 7 29359648.926 ± 208193.317 ops/s
Avoiding all unnecessary fieldsRow() calls in a variety of methods, including field(Field<T>), field(String), field(Name), get(Field), etc. etc.
Benchmark Mode Cnt Score Error Units
BenchmarkRecordAccess.testAccessFirstColumnByExactFieldRef thrpt 7 253221896.822 ± 3448397.287 ops/s
BenchmarkRecordAccess.testAccessFirstColumnByIndex thrpt 7 345160454.129 ± 9363897.936 ops/s
BenchmarkRecordAccess.testAccessFirstColumnByName thrpt 7 90051853.569 ± 1653515.111 ops/s
BenchmarkRecordAccess.testAccessFirstColumnBySimilarFieldRef thrpt 7 51433125.711 ± 199903.347 ops/s
BenchmarkRecordAccess.testAccessFirstColumnBySimilarFieldRefWithTableQualification thrpt 7 31716992.033 ± 840790.008 ops/s
Clearly, this was quite wrong so far. But as you said correctly, the fieldsRow() call shouldn't matter but be cached. The various RecordImpl[N] constructors are calling the wrong super constructor. In fact, it should be possible to create a RowImpl[N] instance only once per query, and then pass it around from the CursorImpl instead of the current Field<?>[]. That way, the entire Result can share the same instance of fieldsRow().
lukaseder
on 3 Dec 2020
A minor, related improvement would be if AbstractKey had a reference of an AbstractRow instead of TableField[], see: https://github.com/jOOQ/jOOQ/issues/7451
lukaseder
on 3 Dec 2020
A lot of improvements have been committed to 3.15 and 3.14 branches.
If any of you, @alacoste and @arlampin are interested in verifying if this fixes your issues, early feedback would be very useful prior to releasing. You can build the jOOQ Open Source Edition from github, or access snapshots builds from here, if you're licensed:
https://www.jooq.org/download/versions
- 3.15.0-SNAPSHOT will be published by tomorrow
- 3.14.5-SNAPSHOT has been built just now
I think this issue here is still not fixed, as I haven't benchmarked any TableAlias comparisons from derived tables yet, but the RecordImpl[N] issues from https://github.com/jOOQ/jOOQ/issues/11064 should hopefully be gone.
lukaseder
on 3 Dec 2020
Will give it a try this afternoon!
alacoste
on 4 Dec 2020
OK, I am running 100 times the same block of code linked earlier and exhibiting the performance issue, measuring on each run the time taken by Result<Record>.into(Table) for the problematic query.
On that metric I can't see any major difference between jooq v3.14.4 and my locally built v3.15.0-SNAPSHOT. There is quite a bit of variance, but both take ~50ms on average.
Here is the profiling results on 3.15.0-SNAPSHOT: server_[run]_2020-12-04-200049.jfr.zip
Screenshot of the interesting part:
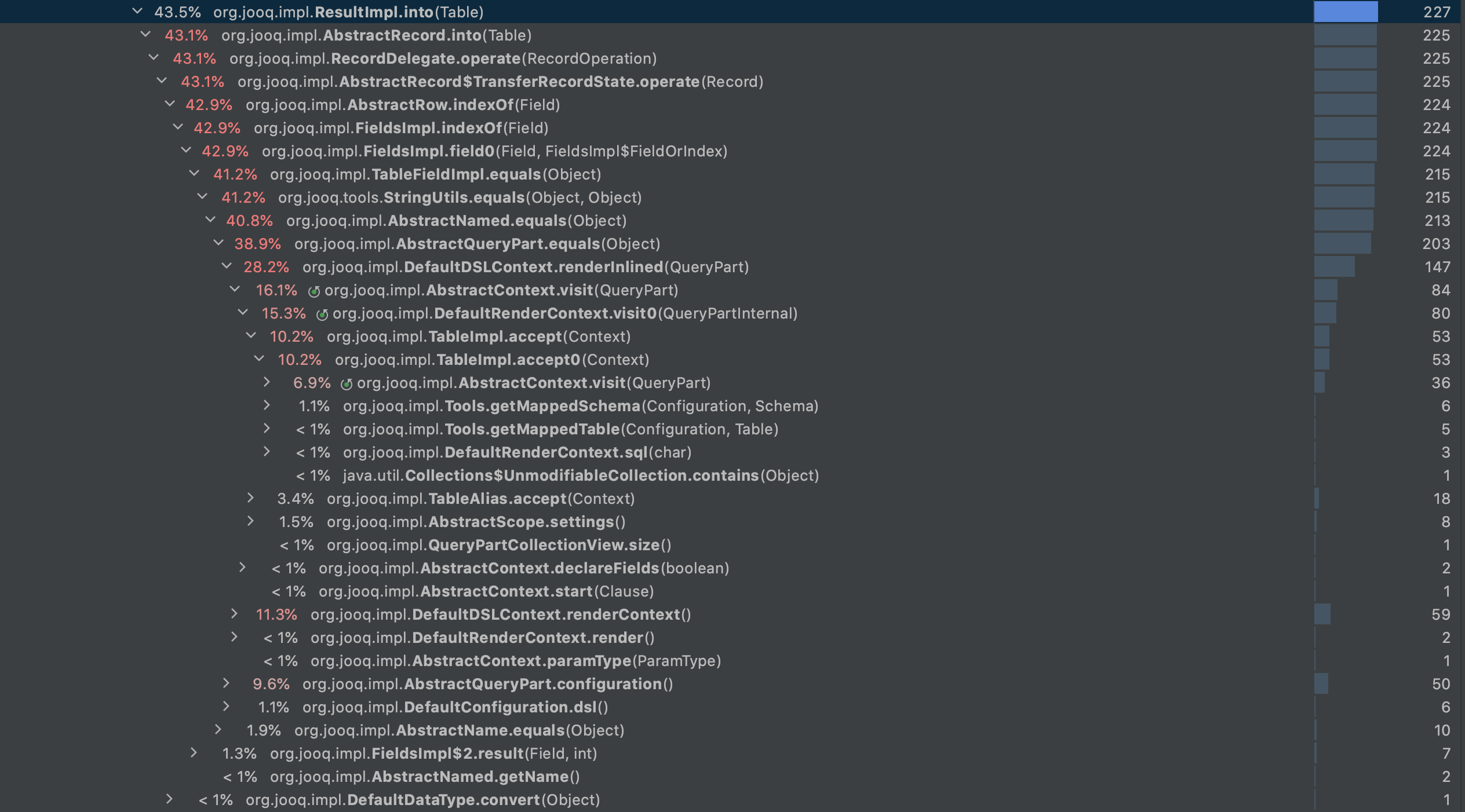
alacoste
on 4 Dec 2020
Thanks for the feedback, @alacoste. I'll be looking into this further. There are a few other, related issues I'm benchmarking, currently, including #11099 and also #8762. It seems the caching of fieldsRow is not effective for aliased tables, which are created afresh all the time, not shared like the generated tables. This also impacts performance of the implicit join algorithm (see #8762)
lukaseder
on 11 Dec 2020
Looking into the JFR file now with VisualVM.
As mentioned elsewhere, we should absolutely try to avoid calling AbstractQueryPart::equals, and by consequence, DefaultDSLContext::renderInlined. That's a big task. When throwing an exception from AbstractQueryPart::equals, there are 84 integration tests failing, showing how often we're transitively calling this equals method.
A lower hanging fruit might be to use a cached version of AbstractQueryPart::configuration, instead of creating a new one all the time, just for equals (!):
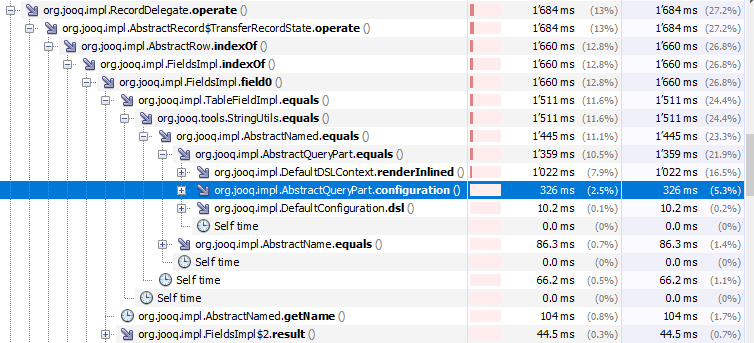
We already have a global instance in Tools.CTX, introduced with #6025 in jOOQ 3.10. We could re-use this instance
lukaseder
on 14 Dec 2020
Will fix this in a separate issue: https://github.com/jOOQ/jOOQ/issues/11125.
lukaseder
on 14 Dec 2020
Thanks again @lukaseder, please do lmk if I can be of assistance!
alacoste
on 14 Dec 2020
Well, if you have time, an self-contained MCVE (we have a template here: https://github.com/jOOQ/jOOQ-mcve) for the reproducer here would be very useful: https://github.com/jOOQ/jOOQ/issues/11058#issuecomment-736700013
Otherwise, I'll be able to look into generally improvable things, but maybe not the exact thing you're running into...
lukaseder
on 14 Dec 2020
For the record, I'll investigate all the locations where we call AbstractQueryPart::equals from our integration tests in a separate issue: https://github.com/jOOQ/jOOQ/issues/11126. Chances are, this will also cover your case, "by accident".
lukaseder
on 14 Dec 2020
Without a full MCVE, you could put a breakpoint in AbstractQueryPart::equals, and report all the types of this and that that you encounter on your side to https://github.com/jOOQ/jOOQ/issues/11126
lukaseder
on 14 Dec 2020
Hi @lukaseder and sorry for the long radio silence over the holiday break!
I just checked again since you already merged a couple of fixes but our use-case still exhibits the performance problem, so I finally got around to creating a MCVE :)
Here it is: https://github.com/nabla/jOOQ-mcve
I'm running it against a local postgres DB, and the setup is the following:
- A table EXPERIENCE, of which I create 10 rows
- A table MESSAGE with an EXPERIENCE_ID column, of which I create 20 rows per experience (100 total).
- The other columns of message are approximately what we have in our real use-case, just because I think without them the .into() slowness might not be as apparent since there would be less columns to "match".
- Repeat 5 times the perf measurement:
- Perform our query using "lateral" to fetch messages for the experiences (which normally serves to paginate on messages inside each experience, here pagination is removed as it was not necessary to reproduce the issue)
- Perform
Result.into(MESSAGE), measuring the time taken.
On my machine it takes ~100ms to perform Result.into(MESSAGE) for the 100 rows of the result set.
As always let me know if I can be of any additional help :)
And thanks again for the attention you are dedicating to this issue!
alacoste
on 14 Jan 2021
Related issues
 krzysztof-osiecki
·
6Comments
krzysztof-osiecki
·
6Comments
 dustContributor
·
5Comments
dustContributor
·
5Comments
 nkoterba
·
7Comments
lukaseder
·
4Comments
nkoterba
·
7Comments
lukaseder
·
4Comments
 eduramiba
·
5Comments
eduramiba
·
5Comments