Insightface: How long did you take to train resnet100?
1 NVIDIA TITAN Xp, MS-1M_v2, batch_size : 64
How long does it take to train a resnet100 model with environment and configuration?
 Gabit07
Gabit07
All 30 comments
Hi Gabit,
Could you tell what are the steps if you want to load your own dataset (saying images captured/collected by ourselves).
If I'm not mistaken we have to:
- Create pairs.txt - like in example pairs_label.txt
- Get rec, idx files by running face2rec2.py
- Get .bin file by running build_eval_pack.py
- Start training by loading all above files to recognition/data and configuring train.py?
I think I'm doing something wrong.
P.S. I'm from KZ :)
 Talgin
on 10 Jun 2019
Talgin
on 10 Jun 2019
Hi Gabit,
Could you tell what are the steps if you want to load your own dataset (saying images captured/collected by ourselves).
If I'm not mistaken we have to:
- Create pairs.txt - like in example pairs_label.txt
- Get rec, idx files by running dir2rec.py
- Get .bin file by running build_eval_pack.py
- Start training by loading all above files to recognition/data and configuring train.py?
I think I'm doing something wrong.P.S. I'm from KZ :)
oh, I haven't train/test my data yet
I am not sure
Gabit07
on 11 Jun 2019
I have been training the model from a week, the verification accuracy for lfw is 0.997, cfp_fp is 0.977, agedb_30 is 0.980. Can the training be stopped now?
Batch size is 64 , training with two GTX1080
 rags25
on 11 Jun 2019
rags25
on 11 Jun 2019
@rags25 could you do the training with the 1 Million dataset too and report the accuracy for that large scale dataset? Thanks.
 Neltherion
on 11 Jun 2019
Neltherion
on 11 Jun 2019
I have been training the model from a week, the verification accuracy for lfw is 0.997, cfp_fp is 0.977, agedb_30 is 0.980. Can the training be stopped now?
Batch size is 64 , training with two GTX1080
I am also still training... I have been training for about a week...
Current status:
lr-batch-epoch: 0.00010000000000000003 24219 10
testing verification..
(12000, 512)
infer time 57.03464599999996
[lfw][934000]XNorm: 22.157355
[lfw][934000]Accuracy-Flip: 0.99617+-0.00358
testing verification..
(14000, 512)
infer time 66.03499499999997
[cfp_fp][934000]XNorm: 20.991168
[cfp_fp][934000]Accuracy-Flip: 0.96614+-0.01024
testing verification..
(12000, 512)
infer time 56.94079799999998
[agedb_30][934000]XNorm: 22.677737
[agedb_30][934000]Accuracy-Flip: 0.97267+-0.00764
[934000]Accuracy-Highest: 0.97500
INFO:root:Epoch[10] Batch [24200-24220] Speed: 6.39 samples/sec acc=0.551562 lossvalue=3.826245
INFO:root:Epoch[10] Batch [24220-24240] Speed: 121.53 samples/sec acc=0.534375 lossvalue=4.250386
Gabit07
on 12 Jun 2019
@Gabit07 I am on Epoch 25
INFO:root:Epoch[25] Batch [7760-7780]\tSpeed: 17.23 samples/sec\tacc=0.716797\tlossvalue=2.181622
and my verification results are
write(1, "[lfw][1162000]XNorm: 21.849603", 30) = 30
write(1, "[lfw][1162000]Accuracy-Flip: 0.99750+-0.00291", 45) = 45
...
write(1, "[cfp_fp][1162000]XNorm: 21.793458", 33) = 33
write(1, "[cfp_fp][1162000]Accuracy-Flip: 0.97686+-0.00928", 48) = 48
...
write(1, "[agedb_30][1162000]XNorm: 22.366503", 35) = 35
write(1, "[agedb_30][1162000]Accuracy-Flip: 0.98067+-0.00597", 50) = 50
write(1, "[1162000]Accuracy-Highest: 0.98183", 34) = 34
When do you plan on stopping the training.
rags25
on 12 Jun 2019
@Gabit07 I am on Epoch 25
INFO:root:Epoch[25] Batch [7760-7780]\tSpeed: 17.23 samples/sec\tacc=0.716797\tlossvalue=2.181622
and my verification results are
write(1, "[lfw][1162000]XNorm: 21.849603", 30) = 30
write(1, "[lfw][1162000]Accuracy-Flip: 0.99750+-0.00291", 45) = 45
...
write(1, "[cfp_fp][1162000]XNorm: 21.793458", 33) = 33
write(1, "[cfp_fp][1162000]Accuracy-Flip: 0.97686+-0.00928", 48) = 48
...
write(1, "[agedb_30][1162000]XNorm: 22.366503", 35) = 35
write(1, "[agedb_30][1162000]Accuracy-Flip: 0.98067+-0.00597", 50) = 50
write(1, "[1162000]Accuracy-Highest: 0.98183", 34) = 34When do you plan on stopping the training.
Well, I don't have any plan to stop it
I am on Epoch 10 now
Gabit07
on 12 Jun 2019
@Gabit07 how's your training coming along? How would I re-train the existing weights with a dataset of my own?
rags25
on 17 Jun 2019
Hi,
We started to train our custom dataset today (we wanted to test the system, so we only have 10 classes with 658 images), and we are on 3000th epoch now (from morning) using 1080 Ti.
So we have for now:
(1198, 512)
infer time 8.454853
[kazakh_11][66000]XNorm: 6.886962
[kazakh_11][66000]Accuracy-Flip: 0.50085+-0.00254
[66000]Accuracy-Highest: 0.54599
I don't know, maybe we've setup something wrong, but the accuracy seems to be low?! Or do you think something will change at the end of the training?
Talgin
on 18 Jun 2019
@Talgin I can't really say now. I am setting up a similar custom dataset, for re-training the model. What are the steps did you follow to create the dataset ?
Will put it up here once I get few hundred epochs run
Edit: Sorry read it as 300 instead of 3000. Maybe change the batch size or decrease the learning rate?
rags25
on 18 Jun 2019
@Talgin I can't really say now. I am setting up a similar custom dataset, for re-training the model. What are the steps did you follow to create the dataset ?
Will put it up here once I get few hundred epochs runEdit: Sorry read it as 300 instead of 3000. Maybe change the batch size or decrease the learning rate?
Hi @rags25,
- Yes, you were right, we changed the learning rate after we got "ValueError: Input contains Nan..." around 7000th epoch.
- Obviously, and according to #163 we can stop training after some time having the same verification accuracy.
- About the steps in creating dataset... actually, we do not have large dataset of which we can speak now, but we used our existing photos (from internet, of local people), cropped faces and aligned them to 112,112 size, then we created .rec, .idx files using scripts in /src/data, after that we created validation .bin file using the script in the same folder (but you have to make pairs.txt before, using formatting like in LFW dataset's pairs.txt file => http://vis-www.cs.umass.edu/lfw/pairs.txt). I think that's all about it. I don't know whether we have good results now, but verification accuracy with only our dataset shows 0.95. We tested small part of the dataset as I mentioned above, maybe the result will be better with bigger one.
Talgin
on 20 Jun 2019
@Talgin Yeah even I stopped the training after 2 weeks. I trained on MS1M dataset. Now preparing data for fine tuning the model on custom data. Will see how the training goes.
That's a good start with the verification accuracy. You can fine tune it better I am hoping
Edit: @Talgin Why did you use dir2rec.py instead of face2rec2.py. Is there any particular reason? The author in the README page mentions to use face2rec2.py
rags25
on 20 Jun 2019
Hi @rags25,
Sorry, it was mistake, yes, we used face2rec2.py. Thank you! I've edited the above :)
Talgin
on 3 Jul 2019
@Talgin Why did your training take 2 weeks?
 capilano
on 10 Jul 2019
capilano
on 10 Jul 2019
Hi @capilano,
I think you wanted to answer @rags2? :) We trained maximum 25-30 hours until we got stable verification accuracy.
Talgin
on 10 Jul 2019
@Talgin Oh, I am sorry. It was meant for him.
Yes, I was able to get stable accuracy(99.45 on LFW) in about 7 hours, but I used mobilenetv2(with some modifications) architecture. So, I was surprised by the 2 weeks training time for resnet 100 even with a slow GPU. So,25-30 hrs seems reasonable
capilano
on 11 Jul 2019
@capilano I was going on vacation and let the training go on for approx 2 weeks. I did achieve accuracy of 99.89 on LFW. So didnt harm me too much in that scenario
rags25
on 11 Jul 2019
@rags25 How many epochs did you let it run for? 99.89 on LFW is pretty awesome. The max I get is close to 99.65 but I have model size and speed constraints and that's about the max I can squeeze out of architectures similar to mobilenetV2, so I am considering adding Squeeze and excite blocks or getting rid of depthwise convolutions completely.
capilano
on 11 Jul 2019
@rags25 Also, What is your accuracy on datasets other than LFW (since LFW is already saturated)? Thanks.
Neltherion
on 12 Jul 2019
@capilano I ran it (or rather it ran for) 29 epochs. Sounds cool do update if the results are better.
@Neltherion
[lfw]Accuracy-Flip: 0.99880+-0.00250
[cfp_fp]Accuracy-Flip: 0.97786+-0.00724
[agedb_30]Accuracy-Flip: 0.98117+-0.00699
rags25
on 12 Jul 2019
@rags25 Thanks for the update. Is it possible for you to test it on the MegaFace dataset? To the best of my knowledge, the MegaFace test set is the hardest test set for Face Recognition Benchmarks.
Neltherion
on 12 Jul 2019
@Neltherion Thanks for the info Will do it in the coming weeks. Right now have other deadlines to meet and will update later on.
rags25
on 12 Jul 2019
@rags25 Thanks, I'll be waiting. And can I ask how many GPUs you used for training? it seems the more GPUs you have at your disposal the better the final training accuracy gets (it somehow seems related to the wider global minimums gained by larger training batch sizes theory).
Neltherion
on 12 Jul 2019
Hi @rags25, @capilano, @Neltherion, @Gabit07,
We trained our network more than a week and reached 50 epochs, but we have a problem with acc it is not changing since 7th epoch and is around 0.29-32:
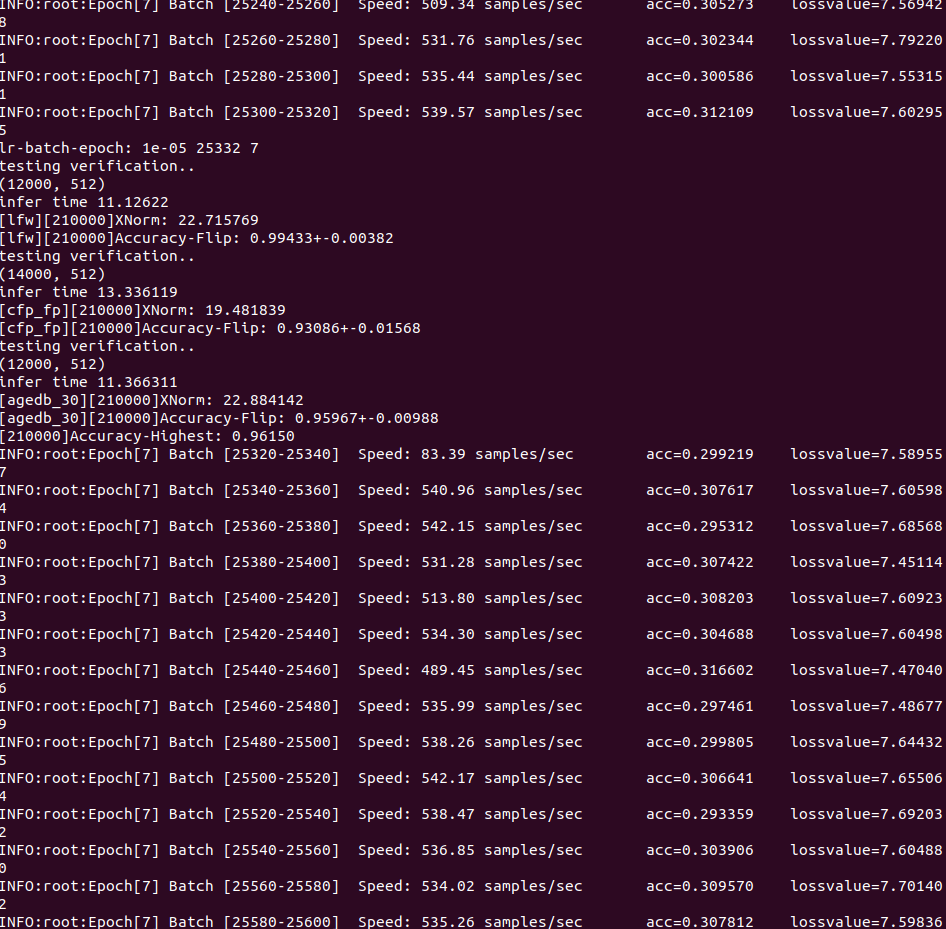
Our config:
default network
default.network = 'r100'
default.pretrained = ''
default.pretrained_epoch = 1
default dataset
default.dataset = 'faces_glint'
default.loss = 'arcface'
default.frequent = 20
default.verbose = 2000
default.kvstore = 'device'
default.end_epoch = 10000
default.lr = 0.001
default.wd = 0.0005
default.mom = 0.9
default.per_batch_size = 64
default.ckpt = 3
default.lr_steps = '100000,160000,220000'
default.models_root = './models/glint'
We have 4 Tesla P100 running.
Did you have the same problem and should we wait more epochs for acc to rise?
Thank you!
Talgin
on 6 Aug 2019
@Talgin Is this accuracy on the classifier? I think I got around 0.5(on cos loss) and I think the author of one of the papers also had similar accuracy if I remember correctly, on the cleaned MS-1m dataset with about 5.5M images and 85K ids. If I had to guess your epochs are not the issue, probably check if the loss and batch norm updates are correctly aggregated over the 4 GPU's. at each train step. Also, I think it does not matter(the acc values)
capilano
on 6 Aug 2019
@Talgin I agree with @capilano the accuracy values don't really matter. Calculate the F1 and the betaF1 scores on your dataset. I would suggest even to compute the confusion matrix and check for those values as they would be more bankable and these accuracy values. Hope this helps you ! :)
rags25
on 6 Aug 2019
Thank you @capilano and @rags25!
We stopped training yesterday (50 epochs). Maximum values in verification were:
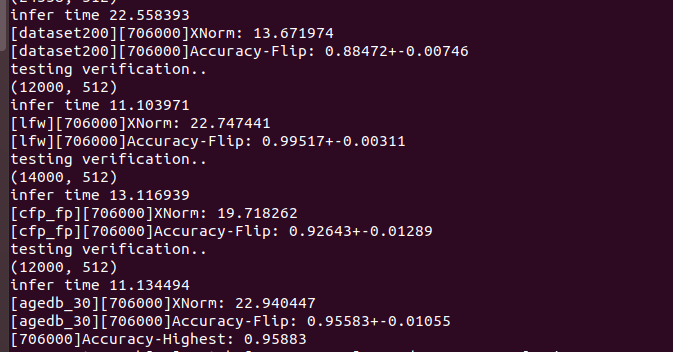
I'll try F1 tests and confusion matrix, and will post the results here :)
Thank you again! ;)
Talgin
on 7 Aug 2019
@Talgin how did the results turn out?
rags25
on 12 Aug 2019
@Talgin how did the results turn out?
Hi, @rags25
Sorry for the late reply, I had vacation. Tests show that the model we trained performed not so well... it seems that the acc values matter :) Maybe @capilano was right in saying that batch norm updates were not aggregated correctly between GPUs. I run training only on 1 GPU 2 days ago, hope this will help (because I do not know how to aggregate batch norm updates between multiple GPU's :)).
Have you tried to train glint or ms1m here?
Thank you!
Regards,
Talgin
on 5 Sep 2019
@Talgin @capilano @Neltherion Did anyone of you get the batch inference working?Issue #423 ?If so can anyone help me out?
rags25
on 22 Oct 2019
Related issues
 AnhVPB
·
4Comments
AnhVPB
·
4Comments
 PavitFaaiz
·
4Comments
PavitFaaiz
·
4Comments
 zhenglaizhang
·
3Comments
zhenglaizhang
·
3Comments
 wqq19930507
·
3Comments
wqq19930507
·
3Comments
 Edwardmark
·
4Comments
Edwardmark
·
4Comments