Insightface: Cannot reproduce the results in IJB
Dear insightface:
I have tried python2/python3 and mxnet-cu80/mxnet-cu90. But I cannot reproduce the results in https://github.com/deepinsight/insightface/blob/master/Evaluation/IJB/IJBC_Evaluation_MS1MV2.ipynb.
After running through the notebook, my ROC curve is somewhat strange:


If I directly use the downloaded results file (*.npy), rather than the file generated by myself, the ROC curve is normal.

I also investigate the features at images level, the cluster pattern can be observed, which means that the extracted features of the starting 128 images are correct.

When reproducing,
I modify similarity_score = np.sum(feat1 * feat2, -1) to similarity_score = np.sum(feat1 * feat2, -1).flatten(). For python2, I do not change anything else; for python3, I modifies
img_input_feats = img_feats[:,0:img_feats.shape[1]/2] to img_input_feats = img_feats[:,0:img_feats.shape[1]//2].
Could you help me find out the problem?
Thanks a lot!
 luzai
luzai
All 8 comments
I try to reimplement the procedure of evaluation.
In test_ijbc2, the ROC curve is strange; And in test_ijbc3 the ROC curve is normal.
And the same in pytorch version, test_ijbc2, test_ijbc3.
But I do not tell the difference between two version.
luzai
on 11 Dec 2018
Could you please help to try this?
score[s] = similarity_score
-->
score[s] = similarity_score.flatten()
Actually, I never got the wrong curves by the code ......
 jiankangdeng
on 13 Dec 2018
jiankangdeng
on 13 Dec 2018
It seems the there are some problems with np.loadtxt. As shown in image, the label p11 is correct while t1 is not.
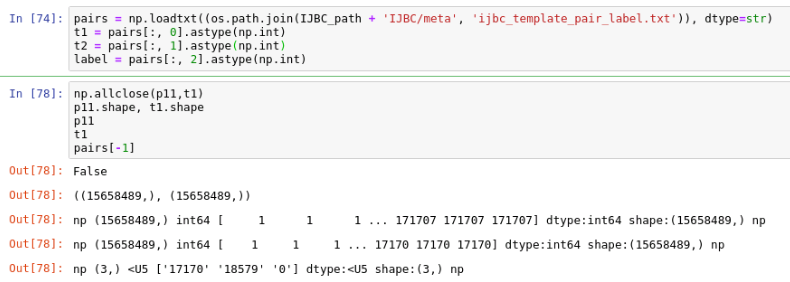
Could you tell me the version of numpy you use? (I am using 1.14.3) .
luzai
on 15 Dec 2018
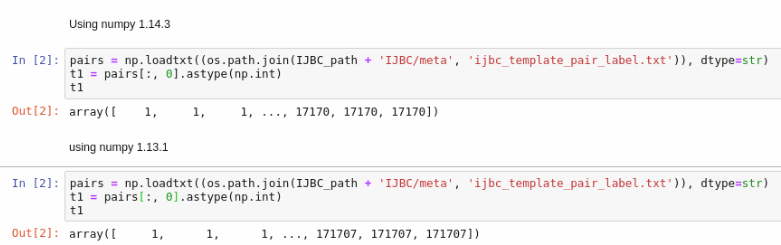
It is numpy-1.13.1 on my server and it works well after score[s] = similarity_score.flatten()
 nttstar
on 15 Dec 2018
nttstar
on 15 Dec 2018
It works with numpy-1.13.1 or pd.read_csv. I think it is related to the version of numpy.
Thanks a lot for your helps and efforts to running the code!
luzai
on 15 Dec 2018
@luzai Thanks for your feedback!
nttstar
on 15 Dec 2018
I have the same error ,but the different numpy version ,the out is the same
,finally, I found the reason , because dtype=str ,save error , I modify int , the out t1 t2 is correct.
pairs = np.loadtxt(path, dtype=int)
def read_template_pair_list(path):
pairs = np.loadtxt(path, dtype=int)
t1 = pairs[:,0].astype(np.int)
t2 = pairs[:,1].astype(np.int)
 shiyuanyin
on 26 Jun 2019
shiyuanyin
on 26 Jun 2019
i also can not reproduce the result, details: here
even change numpy version...
 Light--
on 13 Sep 2020
Light--
on 13 Sep 2020
Related issues
 nmzszxsl01
·
4Comments
nmzszxsl01
·
4Comments
 PavitFaaiz
·
4Comments
PavitFaaiz
·
4Comments
 zhenglaizhang
·
3Comments
zhenglaizhang
·
3Comments
 shenriver
·
5Comments
shenriver
·
5Comments
 mdv3101
·
5Comments
mdv3101
·
5Comments
Most helpful comment
I have the same error ,but the different numpy version ,the out is the same
,finally, I found the reason , because dtype=str ,save error , I modify int , the out t1 t2 is correct.
pairs = np.loadtxt(path, dtype=int)
def read_template_pair_list(path):
pairs = np.loadtxt(path, dtype=int)
t1 = pairs[:,0].astype(np.int)
t2 = pairs[:,1].astype(np.int)