Influxdb: Higher Memory Usage in 1.5 with TSI indexes
I updated my current 1.4.2 installation to 1.5, ran the influx_inspect buildtsi script to convert to TSI indexes, and restarted influxdb. Memory usage immediately substantially higher causing major service disruption. Normal RAM usage is about 22 MB's, and with 1.5 and TSI, RAM usage maxed out at 30GB and started using about 18GB of swap. So more the double the memory usage for the same database on the same server.
I am running this database on a 30GB memory instance at Rackspace.
I restored the data back to the TSM indexes, still running under 1.5, and memory usage appears to be back to normal for the moment. So the issue seems more related to the TSI indexes, than with 1.5 specifically.
Here are some screenshots of the memory usage after the move to TSI indexes:
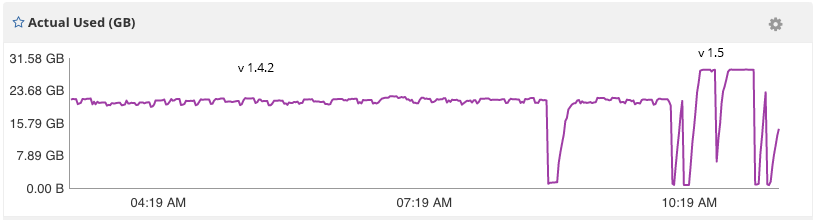
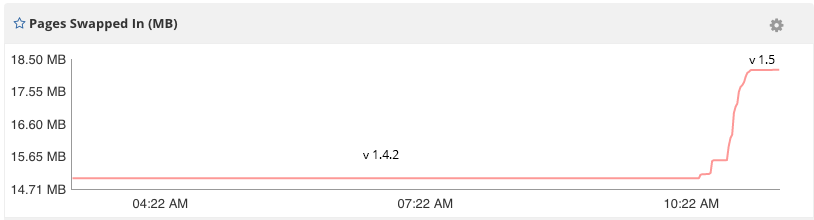
Also here are some pprofs using the TSI indexes:
Let me know if you need any more information.
 cnelissen
cnelissen
All 22 comments
It looks like you may have a lot of log files that aren't compacting. Are you seeing any tsi related errors in your log? Also, can you post the output of tree for your data directory?
 benbjohnson
on 9 Mar 2018
benbjohnson
on 9 Mar 2018
There weren't any tsi related errors in the logs. But one thing I did notice is that even after converting to TSI indexes and updating the configuration, when the shards were loading it was saying "engine=tsm1" still:
Mar 9 16:50:05 influxdb-1 influxd: ts=2018-03-09T16:50:05.315213Z lvl=info msg="Opened file" log_id=06jvXJ_W000 engine=tsm1 service=filestore path=/var/lib/influxdb/data/sunray/rp-1h/114200/000000033-000000005.tsm id=0 duration=1366.969ms
Here is the output of tree from the data directory.
cnelissen
on 9 Mar 2018
I'm seeing similar behavior after upgrading from 1.2.0 to 1.5.0 and building TSI indices:
- Higher memory usage.
- Long startup times as in #9534
- Logs reporting "engine=tsm1" despite TSI being enabled in the config file.
 dvdjaco
on 13 Mar 2018
dvdjaco
on 13 Mar 2018
@cnelissen @dvdjaco How many databases do you have on your instance? Also, are you using spinning disks or SSDs?
From the mem.pprof it looks like it's using 10GB of heap. TSI uses memory-mapped files to pull data into memory but the OS should handle paging data in and out automatically so it may seem like high memory usage but the OS will use as much RAM as is currently available. How are you measuring the swap file paging?
benbjohnson
on 13 Mar 2018
My setup is only a single database. Storage is SSD and is a dedicated block storage device just for Influx data, WAL is on a separate I/O device.
There was noticeable performance problems running under TSI, namely massive timeouts when writing data via the HTTP API every few seconds.
cnelissen
on 13 Mar 2018
In my case, 1.5.0 is OOMing on boot, whereas 1.4.2 works fine.
We have ~7k databases in this single influx instance, with about 14M series total. I know this is a bit unconventional, but this has worked out very well for us since the 0.8x days where we had major issues with using a single database.
I've tried converting all Influx DBs to TSI with influx_inspect buildtsi but I get the same OOM when booting 1.5.0 and the log does not mention anything about TSI files. How can I verify that the databases were converted?
- Here's the 1.5.0 boot log (OOM, before converting to TSI)
- Here's the 1.4.2 boot log (works fine)
I also have output I can share of:
treeon the influx data dir- series count by database
SHOW SHARDSoutput (from 1.4.2)SHOW STATSoutput (from 1.4.2)influx_inspect verifyof all databases (all showhealthy)
Server specs: AWS EC2 i3.16xlarge (64 ECU "cores" , 488RAM). Tested on both EBS SSD and local NVMe SSDs.
Happy to provide any other information as well.
 dlanderson
on 15 Mar 2018
dlanderson
on 15 Mar 2018
Apologies for hijacking this issue. My particular problem was identified as another issue - https://github.com/influxdata/influxdb/issues/9592
dlanderson
on 16 Mar 2018
@cnelissen What operating system and version are you running?
benbjohnson
on 21 Mar 2018
OS Version: CentOS Linux release 7.4.1708 (Core)
cnelissen
on 21 Mar 2018
Thanks! We had some issues with madvise() in CentOS (https://github.com/influxdata/influxdb/issues/9534) and we have reverted the offending change: https://github.com/influxdata/influxdb/pull/9614
I think it's probably a related issue.
benbjohnson
on 21 Mar 2018
Same issue here with Influxdb 1.5.0 docker alpine image. 4 databases, 17GB on SSD disk. Container consumes 4.8GB of RAM at the moment.
It also takes couple of minutes for container to startup as it opens tsm files for some reason:
lvl=info msg="Opened file" log_id=01klXJ_W012 engine=tsm1 service=filestore path=/var/lib/influxdb/data/telegraf/default/128/000005024-000000003.tsm id=0 duration=2566.931ms
I followed TSM to TSI migration procedure with influx_inspect buildtsi and all that.
Using CoreOS 1632.3.0 with 4.14.19 kernel and Docker 1.12.6
 juris
on 29 Mar 2018
juris
on 29 Mar 2018
I'm seeing similar behavior after upgrading from 1.4.2 to 1.5.0 and building TSI indices:
Higher memory usage util oom
one database consume 20GB of RAM
 shilicqupt
on 8 Apr 2018
shilicqupt
on 8 Apr 2018
Same with us when upgrading from 1.4.3 to 1.5.1 using TSI. We previously had 32GB of RAM and it fit comfortably within that. After the upgrade, it frequently OOMs even with 64GB of RAM. Also seeing substantially longer start times. We ended up reverting to 1.4.3 for now.
We have a test instance that can exactly replicate one of our prod if there are any tests or data that would be useful.
 codylewandowski
on 9 Apr 2018
codylewandowski
on 9 Apr 2018
I see that a few here have both upgraded from 1.4.x to 1.5.x AND moved from in memory indices to tsi. According to my experience 1.5.x works fine/better than 1.5.x when comparing memory indices with memory indices. Could you please upgraded to 1.5.x without tsi to verify this @codylewandowski @shilicqupt @juris ?
 hpbieker
on 10 Apr 2018
hpbieker
on 10 Apr 2018
@hpbieker we hack code to change tsi partition DefaultMaxLogFileSize from 5MB to 512k, the memory usage keep smooth
shilicqupt
on 12 Apr 2018
@shilicqupt We have a change coming to make it adjustable via the configuration. Also the default is being lowered to 1MB: https://github.com/influxdata/influxdb/pull/9670
benbjohnson
on 12 Apr 2018
@benbjohnson Will this be backported to 1.5.x? If I have around 5000 shards, does this mean that it previously used 5 MB x 5000 = 25000 MB for this buffer?
If so, why do we have to keep this buffer around for cold shards?
hpbieker
on 12 Apr 2018
There is a backport coming in 1.5.2. TSI is actually sharded into 8 partitions so there's a 5MB x 5000 x 8 multiplier. The log files keep an in-memory representation of their data which doesn't match to the log file size.
5000 shards is a lot of shards though. Why do you have so many? Also, cold shard compaction is not in place yet but will likely be added in the future.
benbjohnson
on 12 Apr 2018
Hi again @benbjohnson ,
I have 33384 .tsl files, which means I have 4173 shards. They are in ~10 different databases. The reason for this many shards is that we have 10 year of data, each in 7 days shard. Currently it is not possible to merge shards/change shard duration for old shards, so I guess I cannot change it without reimporting all the data.
hpbieker
on 13 Apr 2018
Hi
Do you have some news? I upgraded to 1.5.2 from 1.4.x. Enabled tsi, tsm was transformed to tsi but now I also have problem with high memory usage (and OOM) and Influx still using tsm (according to log)
 nkondratyk
on 25 Apr 2018
nkondratyk
on 25 Apr 2018
@nkondratyk How many shards do you have on your system?
benbjohnson
on 2 May 2018
I'm closing this issue as it's a mix of several issues. Running with hundreds or thousands of shards is not recommended so we recommend reducing your shard count to help with memory usage. If you are still having issues in 1.5.2, please open a new issue with specific details. Thank you.
benbjohnson
on 8 May 2018
Related issues
 udf2457
·
3Comments
udf2457
·
3Comments
 airyland
·
3Comments
airyland
·
3Comments
 dtouzeau
·
3Comments
dtouzeau
·
3Comments
 shilpapadgaonkar
·
3Comments
shilpapadgaonkar
·
3Comments
 756445638
·
3Comments
756445638
·
3Comments
Most helpful comment
I'm seeing similar behavior after upgrading from 1.2.0 to 1.5.0 and building TSI indices: