Incubator-superset: Make aggregation not mandatory
I would like to visual only the raw data WITHOUT the need of apply any kind of aggreation, as the data from the table is already pre-computed aggreated metric values.
Superset version
0.26.3
Expected results
There shouldn't be aggregation enforced for a metric. There should be an option to display the raw metric WITHOUT any aggreation function
Actual results
User must select one of six aggreation available in order to visualize data.
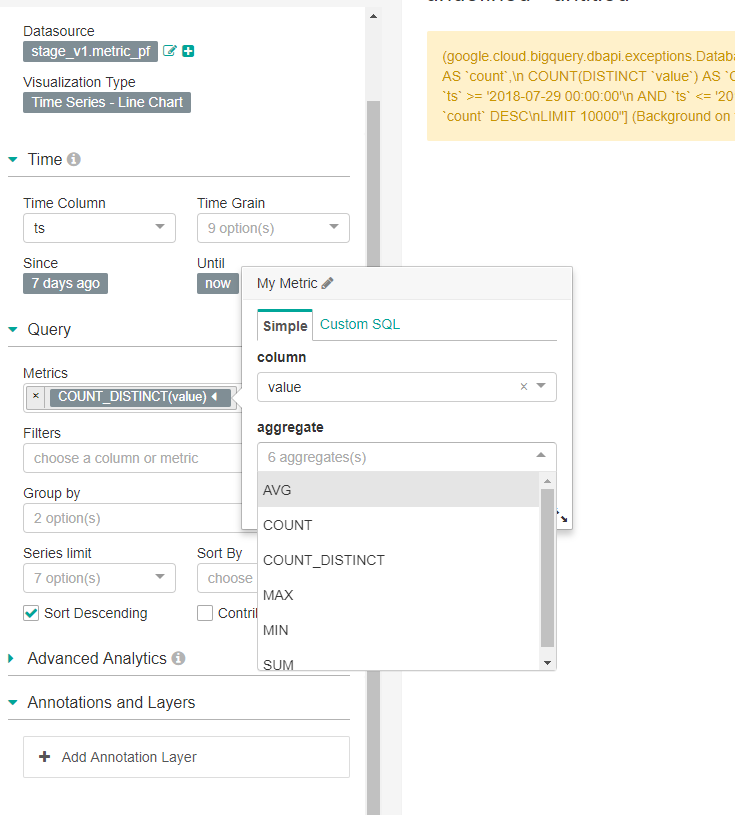
Steps to reproduce
- Go to Charts
- Create a new Timeseries Line Chart
- Under Query section
- Configure metric
 bobbui
bobbui
All 9 comments
I too would like this change. It would also be nice to change the legend for your metric under "Custom SQL" to rename it. Instead of AVG(metric) you could do AVG(metric) AS [my_legend_name]
 davidhassan
on 6 Aug 2018
davidhassan
on 6 Aug 2018
This is more complex than it may seem. The assumption that a metric is an aggregate function runs deep in Superset. The clear and easy workaround is to use a dummy aggregation function. min, max, sum should all provide the same answer in cases where dimension combinations are unique in the source data. The downside is a bit more work on the database side. Note that in some cases that can hurt quite a bit. For example for geospatial data visualizations where hundreds of thousands of data points can be surfaced, grouping by lat&long is expensive and often unnecessary.
The committers have had lengthy conversations about this, and the key may be something around the MetricsControl allowing users to specify not to aggregate. It may have to be coupled with validation/assertions on resulting dataframes making sure that dimension combinations are not duplicated in some cases, as that may cause problems with some of the visualizations.
I don't see this work getting prioritized anytime soon though as the work would be complex and there are clear easy workarounds.
 mistercrunch
on 6 Aug 2018
mistercrunch
on 6 Aug 2018
@mistercrunch I have been using AVG or SUM as my dummy aggregations. However now in the legend it shows something like AVG(metric) as my metric name. Which is a little misleading.
Any chance to to change this in the "Custom SQL" section or elsewhere.
Something like AVG(metric) AS [my_legend_name]
Ex: AVG(price) AS [Price (CAD$)]. Legend will now show "Price CAD$" instead of AVG(price).
davidhassan
on 6 Aug 2018
@mistercrunch thank you for your information, I also believe that should be discussed already but couldn't find the issue on GitHub.
Let's consider this a place to discuss and gather people' thoughts.
@davidhassan i have the same problem as well
bobbui
on 6 Aug 2018
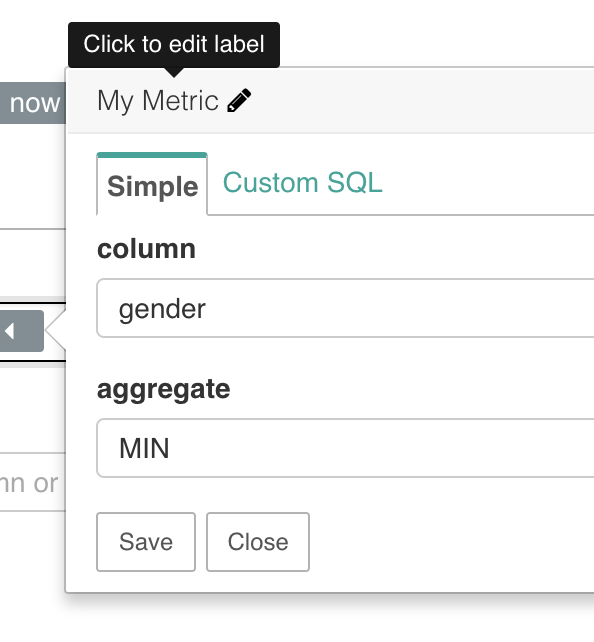
You should be able to click and edit the label of the metric, and that should show up in the legend.
mistercrunch
on 6 Aug 2018
@mistercrunch greatest feature ever! Thank you for pointing this out.
davidhassan
on 14 Aug 2018
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions. For admin, please label this issue .pinned to prevent stale bot from closing the issue.
![stale[bot] picture](https://avatars3.githubusercontent.com/in/1724?v=4&s=40) stale[bot]
on 10 Apr 2019
stale[bot]
on 10 Apr 2019
I'd like to voice my support in having aggregations be optional. Like @thangbn, I have a lot of data that's already processed and aggregated, and would love to just be able to plot that.
Dummy aggregations are mostly fine but sometimes difficult. I understand that this might be difficult to disentangle from the assumptions made in the Superset backend, but I thought I'd contribute this show of support anyway. Thanks !
 QCaudron
on 1 May 2019
QCaudron
on 1 May 2019
The work-around doesn't work for pre-calculated percentages. In the pivot table does some kind of operation on them instead of just displaying the data that was pre-calculated - resulting in values like 770m for a percent . 😱
 WizardOfArc
on 29 May 2019
WizardOfArc
on 29 May 2019
Related issues
 XiaodiKong
·
3Comments
XiaodiKong
·
3Comments
 amien90
·
3Comments
amien90
·
3Comments
 lenguyenthedat
·
3Comments
lenguyenthedat
·
3Comments
 john-bodley
·
3Comments
john-bodley
·
3Comments
 deity-bram
·
3Comments
deity-bram
·
3Comments
Most helpful comment
This is more complex than it may seem. The assumption that a metric is an aggregate function runs deep in Superset. The clear and easy workaround is to use a dummy aggregation function. min, max, sum should all provide the same answer in cases where dimension combinations are unique in the source data. The downside is a bit more work on the database side. Note that in some cases that can hurt quite a bit. For example for geospatial data visualizations where hundreds of thousands of data points can be surfaced, grouping by lat&long is expensive and often unnecessary.
The committers have had lengthy conversations about this, and the key may be something around the
MetricsControlallowing users to specify not to aggregate. It may have to be coupled with validation/assertions on resulting dataframes making sure that dimension combinations are not duplicated in some cases, as that may cause problems with some of the visualizations.I don't see this work getting prioritized anytime soon though as the work would be complex and there are clear easy workarounds.