Html: Make custom attribute rules consistent with custom element name rules
Related WICG discussion: https://discourse.wicg.io/t/relaxing-restrictions-on-custom-attribute-names/1444
Currently, custom attributes need to start with data-. For frameworks with a lot of attributes (Angular, Vue etc), this introduces a serious problem: Either they prefix all attributes with data- and become prone to collisions with other libraries (I've even had two of my own libraries collide!), or they make them extremely verbose (data-ng-*), or they make them non-standard (ng-*, v-*), which is their chosen solution. I'm about to release a library with a lot of attributes and I went for the latter as well. The former two pose serious practical problems, the latter is just conformance.
However, it doesn't have to be this way. Custom elements allow any element name with a hyphen in it, we could do the same for attributes. The cowpaths have been paved: Several very popular libraries follow this practice already. This is not true for proposals like #2250, which introduce a completely new naming scheme.
The main issue with this is all the existing attributes in SVG that come from CSS properties which use hyphens. However, there are several solutions to deal with this:
- Exclude these prefixes, or just these names. The SVG working group is dying and these attributes must be manually added to the spec, there's no clause that says all CSS props must automatically be available as attributes.
Only allow prefixes of 1 or 2 letters. This gives us 26*26 + 25 = 701 more prefixes already, and does not clash with any CSS property that is available as an SVG attribute (
z-indexis the only CSS property that matches this, and it's not an SVG attribute). It also legalizes Angular & Vue's practices.The more commonplace invalid HTML becomes, the less authors care about authoring valid HTML. Validation becomes pointless in their eyes if they see tons of perfectly good use cases being invalid. Also, if both attributes with and without hyphens are equally invalid, nothing forces developers to stick to any naming scheme. So, I think it would be great if we found a solution for this. And it's a proposal that requires zero effort from implementers, since these attributes already work just fine!
 LeaVerou
LeaVerou
All 78 comments
I’d be fine with this as long as the pre-hyphen part could be empty, so attributes could have names like -foo, -bar, etc.
Otherwise this does not add much over the existing data- prefix (e. g. da- instead of data-) and is probably too problematic compared with the _absolutely_ issue-free and future-proof underscore/hyphen-prefixed custom attributes.
To be fair, better than nothing anyway though.
 Marat-Tanalin
on 17 Jan 2017
Marat-Tanalin
on 17 Jan 2017
I'm supportive of this, but only if we also add an API equivalent to what we added for custom elements. It should be possible for folks to easily observe when such attributes are added, removed, and change in value.
 annevk
on 18 Jan 2017
annevk
on 18 Jan 2017
I’d be fine with this as long as the pre-hyphen part could be empty, so attributes could have names like
-foo,-bar, etc.
Starting with a dash is not XML-compatible. Currently the spec requires data-* attribute names to be XML-compatible, and custom element names as well.
 zcorpan
on 18 Jan 2017
zcorpan
on 18 Jan 2017
Otherwise this does not add much over the existing data- prefix (e. g. da- instead of data-) and is probably too problematic compared with the absolutely issue-free and future-proof underscore/hyphen-prefixed custom attributes.
Clearly, you have not considered collisions between libraries and think everything can have the same prefix and the only problem is how to make the prefix less verbose. I don't blame you, I thought they were an edge case in the past as well, but they absolutely are not. With your proposal, libraries would end up doing things like _ng-*, or (most likely) simply not care and continue using ng-* like they've done for years.
LeaVerou
on 18 Jan 2017
I'm supportive of this, but only if we also add an API equivalent to what we added for custom elements. It should be possible for folks to easily observe when such attributes are added, removed, and change in value.
That would be awesome. So basically, syntactic sugar for MutationObserver?
LeaVerou
on 18 Jan 2017
The problem with MutationObserver for this use case is that you don't know where the attribute is going to be added. So if you want a global custom attribute, you'd have to observe the entire tree and even then you'd miss certain things, such as shadow trees.
annevk
on 18 Jan 2017
@LeaVerou
With your proposal, libraries would end up doing things like
_ng-*, or (most likely) simply not care and continue usingng-*like they've done for years.
_ was invalid at the moment of making decisions as for design of those libraries, that’s most likely why libraries’ authors have decided just to drop the (only valid at that moment) data- prefix and not to use a generic prefix that would be formally invalid anyway.
As a side note, it’d probably be wrong to assume that the fact that it’s hard for someone who is already a smoker _(existing libraries in terms of custom attributes)_ to leave off smoking is a reason not to try to prevent others _(new products and libraries)_ from starting smoking _(provide a valid short unobtrusive generic prefix)_.
Marat-Tanalin
on 18 Jan 2017
The problem with MutationObserver for this use case is that you don't know where the attribute is going to be added. So if you want a global custom attribute, you'd have to observe the entire tree and even then you'd miss certain things, such as shadow trees.
True, and what you're proposing would solve a HUGE problem and I would cry tears of joy once it gets implemented! I'm just a bit concerned that it requires considerably more implementor effort, so adding it could stall. Whereas just permitting such attribute names at first would let us use them and it's a super easy addition to the spec since it requires no implementation effort.
LeaVerou
on 18 Jan 2017
Fair, I think there is interest to go in this direction once custom elements has shipped. This idea was briefly discussed at the last W3C TPAC. I think the main thing we lack is someone freeing up the time to write the standard. @domenic thoughts?
annevk
on 19 Jan 2017
I think the fact custom elements kind of encourage people to add a random attribute is a serious issue already so coming up with a some convention for author-defined attribute is a win even if we couldn't add an API for custom attributes yet.
Having said that, we think custom attribute is a much better alternative to is attribute.
 rniwa
on 19 Jan 2017
rniwa
on 19 Jan 2017
Pages in httparchive with attributes that start with _ or non-standard attributes containing -:
SELECT * FROM (
SELECT page, url, REGEXP_EXTRACT(LOWER(body), r'(<[a-z][a-z0-9-]*\s+(?:(?:data-|aria-|http-|accept-)?[a-z]+(?:\s*=\s*(?:"[^"]*"|\'[^\']*\'|[^>\s/"\']+\s+)|\s+))*(?:_[a-z]|(?:[b-ce-gj-z]|d[b-z0-9]|a[a-bd-qs-z0-9]|h[a-su-z0-9]|da[a-su-z0-9]|ar[a-hj-z0-9]|ac[a-bd-z0-9]|ht[a-su-z0-9])[a-z0-9]*-)[^>\s]*\s*=[^>]*>)') AS match
FROM [httparchive:har.2017_01_01_chrome_requests_bodies]
)
WHERE page = url
AND match != "null"
AND NOT REGEXP_MATCH(match, r'["\']\s*\+') # exclude JS string concats
AND NOT REGEXP_MATCH(match, r'<(altglyph|animate|circle|clippath|color-profile|cursor|defs|desc|ellipse|feblend|fecolor|fediffuse|fedisplacement|fedistant|feflood|fefunc|fegauss|feimage|femerge|femorph|feoffset|fepoint|fespec|fespot|fetile|feturb|filter|font|foreign|g\s|glyph|hkern|image|line|marker|mask|metadata|missing|mpath|path|pattern|polygon|polyline|radial|rect|set\s|stop|svg|switch|symbol|text\s|textpath|tref|tspan|use\s|view\s|vkern)') # exclude SVG elements
4068 results: https://gist.github.com/zcorpan/b54592e415a2f79f2ef7f79c0c37b2ed
Of those:
- 26 have
_moz_* - 531 have an attribute starting with
_(excluding moz prefix). - 22 have
x-webkit-*orx-ms-*(the HTML spec for a while recommended vendor extensions to be prefixed withx-vendor-). - 57 start with
x-(excluding webkit/ms prefixes). - 2015 have a prefix of 1 or 2 letters and a dash (excluding
x-). - 1418 have 3+ letters before the dash.
Other things to note:
- SVG
font-facehadx-heightandv-alphabetic(etc) attributes. But this element is dead. - The HTML attributes with dash are
aria-*,data-*,accept-charset,http-equiv. - I found an instance of typo of
aria-- it would be good if conformance checkers could continue to catch this mistake:
<button area-invalid="true" aria-required="true" aria-controls="checkincontainer" aria-label="checkin" id="checkinbutton" class="checkinbutton">
zcorpan
on 19 Jan 2017
For comparison, equivalent query for data-* gives 59,755 results. So data-* is about 15 times more common than non-standard custom attributes (excluding _moz_, x-webkit-, x-ms-).
zcorpan
on 19 Jan 2017
So @LeaVerou's proposal is used by ~0.4% of pages in httparchive; @Marat-Tanalin's proposal is used by ~0.1%. data-* is used by ~12.1%. (The data set is 494,956 pages.)
Since the point here is to adopt what people like or use anyway, if we are to do this, it seems most reasonable to me to allow both. But we should disallow _moz_, x-webkit- and x-ms- and 3+ letter prefix followed by dash (to avoid clashes in SVG, and to make it possible to tell if an attribute is a "custom attribute" or not, and to catch typos in aria- or data-), as well as anything not XML-compatible. But no need to restrict the prefix to [a-z], I believe (data-* and custom element names allow other XML-compatible characters).
zcorpan
on 19 Jan 2017
I still feel there's a strong advantage to sticking to a single sanctioned convention (data-) for custom data attributes, at least until we have a processing model for the "custom attributes".
If people want to go against that convention, that's their choice, but we shouldn't give them a free pass; they're making a conscious choice to trade conformance and ecosystem compatibility for convenience.
 domenic
on 19 Jan 2017
domenic
on 19 Jan 2017
@domenic Sorry, but that’s just a purely theoretical statement totally detached from reality.
As a practicing web developer, I’m quite happy with what we already have currently feature-wise: getAttribute() / setAttribute() / removeAttribute() in JS and [attribute] in selectors.
The only issue here is the artificial validity limitation that could and should be easily removed on spec level. Having (or not) a processing model for custom attributes does _not_ affect the ability to use such attributes right now (to be clear: I’m specifically about _-prefixed attributes that are 100% future-proof).
Marat-Tanalin
on 19 Jan 2017
Thanks for the data @zcorpan!! Very enlightening. I find it surprising that Angular and Vue would only be used by 0.4% of websites. Perhaps a lot of these attributes are added dynamically? Also, I'm not surprised that data- has such as high percentage: Small libraries that only add 1 or 2 attributes can easily use data- and be less worried about either collisions or verbosity. It only takes 1 such library for a page to qualify as having a data- attribute.
It's also an interesting idea to allow both proposals. I don't see any problem with that, flexibility is good!
@domenic Several people have commented about the problems with data-. Developers of popular libraries with many attributes are not using data-. Even those that supported both their own prefix- and a data-prefix- version of each attribute are dropping the latter because nobody is using it, probably because data-prefix- is a verbose abomination. And you resist legalizing anything other than data- because of some theoretical purity argument about "a single sanctioned convention"? What happened to the priority of constituencies? Doesn't author convenience come several levels before theoretical purity?!
LeaVerou
on 19 Jan 2017
Several people have commented about the problems with data-. Developers of popular libraries with many attributes are not using data-. Even those that supported both their own prefix- and a data-prefix- version of each attribute are dropping the latter because nobody is using it, probably because data-prefix- is a verbose abomination.
This argument (and I would appreciate if you avoided phrases like "abomination" in reasoned discussion) is based on anecdotes, whereas @zcorpan shows soundly with data that it does not hold in the real world. A small minority of developers using custom attributes are unhappy with data; 15x more are happy with data than are unhappy. They can be vocal, as you are, but saying that this is a widespread problem is just not supported.
And you resist legalizing anything other than data- because of some theoretical purity argument about "a single sanctioned convention"? What happened to the priority of constituencies? Doesn't author convenience come several levels before theoretical purity?!
Sorry, but that’s just a purely theoretical statement totally detached from reality.
I don't think it's helpful or accurate to characterize the argument as one of theoretical purity, or start invoking the priority of constituencies before any such violation is apparent. This is about the practical impact of fracturing the ecosystem into multiple conventions for custom data. That has real impact on tooling, libraries, authors reading other authors' source code, API consistency and predictability (why do some data properties get a dataset API, and others don't?) and much more.
Again, I repeat that there is nothing stopping you from making a conscious choice between conformance and brevity. If you value brevity so much as to start calling data- attributes an abomination, I presume you value it more than conformant documents. That's fine! You can make that choice! As you yourself have noted, there's nothing stopping you. But it doesn't mean the spec should stop trying to keep the ecosystem coherent to the best of its abilities.
domenic
on 19 Jan 2017
@domenic
15x more are happy with data than are unhappy.
The obvious reason of prevalence of data--prefixed attributes over other prefixes is that data- is the _only formally valid_ option for now. This has _nothing to do_ with whether people are actually _happy_ with it.
Good web developers just usually prefer to keep their documents valid, and not just because that makes them “feel good”, but also to be able to use validators to easier see _real_ errors not intermixed with fictious pseudoerrors related to artificial spec-level limitations not matching reality.
why do some data properties get a dataset API, and others don't?
Because not all custom attributes are data attributes. data- attributes are for data, custom-prefixed attributes are for custom needs whatever those are.
Marat-Tanalin
on 19 Jan 2017
@zcorpan wrote:
So @LeaVerou's proposal is used by ~0.4% of pages in httparchive; @Marat-Tanalin's proposal is used by ~0.1%. data-* is used by ~12.1%. (The data set is 494,956 pages.)
does that mean that some other form of prefix is used by the other 87%?
 stevefaulkner
on 19 Jan 2017
stevefaulkner
on 19 Jan 2017
The obvious reason of prevalence of data--prefixed attributes over other prefixes is that data- is the only formally valid option for now. This has nothing to do with whether people are actually happy with it.
That's an interesting speculation. Fortunately, it's also one we can answer, or at least upper-bound, with data. That is, what percentage of those ~12.1% of pages are conformant? In other words, what percentage of people using data-* attributes are also people who care about conformance, and thus might have chosen data- over x- because of conformance concerns?
Similarly, what percentage of the ~0.5% using nonstandard prefixes are conformant-except-for-bad-prefixes? This number is especially interesting, because it indicates people who are interested in conformance but just aren't willing to change their prefixes. Certainly you and Lea might fall in that sub-bucket of the ~0.5%. (Although maybe not?) But how many of that ~0.5% are you representing?
Another point worth making is the analogy to a previous push to use <i> for icons. The reasoning was exactly the same: lots of people are doing it, because it's shorter than the recommendation in the spec (<span> with fallback text). We even did a HTTP archive search, and found that many more developers would "benefit" from allowing this than the fraction-of-~0.5% being discussed here. But allowing <i> for icons has many practical downsides---the same ones I listed before for allowing non-data- prefixes for custom data attributes. For that reason, we didn't do it.
does that mean that some other form of prefix is used by the other 87%?
I assume it means they are not using any prefixed attributes (data- or otherwise) at all.
domenic
on 19 Jan 2017
Let me also repeat that I do support exploring the concept of custom attributes, with a processing model similar to custom elements. That gives serious benefits beyond just brevity, that IMO outweigh the practical disadvantages. It's the simple conformance change with no processing model that I am not in support of.
domenic
on 19 Jan 2017
Again, I repeat that there is nothing stopping you from making a conscious choice between conformance and brevity. If you value brevity so much as to start calling data- attributes an abomination, I presume you value it more than conformant documents. That's fine! You can make that choice! As you yourself have noted, there's nothing stopping you. But it doesn't mean the spec should stop trying to keep the ecosystem coherent to the best of its abilities.
@Marat-Tanalin
Authors don't typically invent their own attributes, and when they do, data- is fine. Most custom attributes are used because a library/framework will utilize them. Therefore, the person using the attribute is not the same person that decided on its naming. It's not about my choice, it's about making the right choice for the users of my library. I don't want to impose verbosity on them and litter their markup with lengthy prefixes, and I don't want to impose nonconformance on them. Library devs should not be forced into this dilemma.
Re: fracturing the ecosystem, how does that not apply to custom element names?
whereas @zcorpan shows soundly with data that it does not hold in the real world
While I definitely commend the effort to get real data, I would take that percentage with a grain of salt:
- We're basically parsing HTML with regexes here
- None of this accounts for dynamically added attributes.
- It counts occurrence of each naming scheme per page, whereas I suspect that when ng- or v- attributes are used, A LOT of them are used.
- As I mentioned above, smaller libraries can use
data-just fine. When you only have one or two attributes, the verbosity doesn't matter much and the collisions are more rare. It only takes 1 such library for a page to count in @zcorpan's data. - As @Marat-Tanalin mentioned,
data-is the only conformant option right now, don't you think that affects usage? - These stats go against common knowledge: Angular and Vue are very popular, it seems weird that they'd be collectively used by only 0.4% of websites.
Fortunately, it's also one we can answer with data. That is, what percentage of those ~12.1% of pages are conformant? In other words, what percentage of people using data-* attributes are also people who care about conformance, and thus might have chosen data- over x- because of conformance concerns?
You're assuming here that everybody who cares about conformance is actually conformant. A parallel about religions and sins comes to mind. :) Many authors care about conformance, but don't actually validate, so they make mistakes that are never caught. However, conformance still influences their decision making.
LeaVerou
on 19 Jan 2017
Let me also repeat that I do support exploring the concept of custom attributes, with a processing model similar to custom elements. That gives serious benefits beyond just brevity, that IMO outweigh the practical disadvantages. It's the simple conformance change with no processing model that I am not in support of.
Nobody is against that. As I said above, that would be incredible! It would make my life so much easier. What I was suggesting is making the conformance change first, since it's easy, and adding the (harder to design) API as a later step, once it gets implementor interest and a spec editor willing to do it.
LeaVerou
on 19 Jan 2017
@domenic
I would appreciate if you avoided further trolling.
FYI, unlike what you’ve probably naively assumed, I _am_ aware the pubdate attribute is _currently_ not in the HTML spec, so using the formally invalid attribute is _not_ accidental. I use the attribute _intentionally_ since it _was_ previously specced and _perfectly valid_, but then has been removed on a purely theoretical basis by someone who unfortunately has a sort of overformal logical approach (but who is still able to be respectful and deserves to be respected) somewhat similar to yours, and recommended to use the bolted-on verbose pseudosemantic surrogate called Microdata instead. (Btw, the same person also tried to remove the TIME element in favor of a new cool universal element called… DATA, but fortunately failed thanks to massive web-developers’ objections.) Violating the current version of the HTML spec by continuing to use the pubdate attribute solely on my _own_ site is a sort of my _conscious and consistent objection_ to that (wrong in my opinion) decision. Moreover, according to my experience, at least Google search engine _does_ support the attribute _regardless_ of that it has been removed from the spec, so its use still makes sense in practice.
Marat-Tanalin
on 19 Jan 2017
Another point worth making is the analogy to a previous push to use
<i>for icons.
Any analogy suffers from inaccuracies, is not a proof or an argument of any kind, and is often actually just irrelevant offtopic noise.
Marat-Tanalin
on 19 Jan 2017
Let's please remain focused on the technical issues.
 Hixie
on 19 Jan 2017
Hixie
on 19 Jan 2017
@Marat-Tanalin
Because not all custom attributes are data attributes. data- attributes are for data, custom-prefixed attributes are for custom needs whatever those are.
I think this is incorrect (as I also said in https://github.com/whatwg/html/issues/2250#issuecomment-271479610). There is no difference in intended use at all -- why would there be? Possibly we should tweak the spec text to clarify that it is not "wrong" to use data-foo as a "boolean" attribute, etc. I can work on a PR for that. What other usages for "custom attributes" are there that you think are not "data"?
zcorpan
on 19 Jan 2017
@zcorpan Is the disabled attribute a data attribute?
(Fwiw, it is clear to me that boolean data- attributes are valid per spec.)
Marat-Tanalin
on 19 Jan 2017
FWIW, the moment data-* shipped is the moment pretty much every old fashioned _MVC_ library added data-bind to any node, knockout to name one, others following, causing the same name clashing problem data- was supposed to solve for HTML attributes, but in developers-land (TL;DR the problem just moved somewhere else)
Being also impossible to polyfill, in terms of el.dataset.name and similar Proxy kind of sorcery, most advantages initially thought for developers got lost in "_trans(pi)lation_", since it was still a el.get/setAttribute('data-whatever') matter, which is probably in the Top Ten things I really don't want to waste time anymore typing in my life ... but that's another story, sorry ...
That being said, there's a lot of legacy in the wild trusting data-attributes and aria-roles are also untouchable from a "_don't break the Web_" point of view, so I agree with @domenic there's no way we can just throw away data- and aria- like that, and we honestly shouldn't.
However, since the begninning of the time, Custom Elements had reserved names such:
color-profile
font-face
font-face-src
font-face-uri
font-face-format
font-face-name
missing-glyph
Proposing a new attribute standard that define forbidden prefixes for attributes doesn't seem that different, as long as the provided data is realiable and there are really no huge conflicts with what's already used out there. For instance, I know some major player use prefixes that are not mentioned in here, only because their prefixes are behind the scene, and not public. Having browser breaking randomly prefixes that don't show up on the Open Web is not probably "_good enough_".
Good news is: these kind of changes don't happen over night, so if there is a will to promote custom attributes, providing a list of untouchable prefixes so that other can have time to eventually update their code-base, that'd be ace.
Not A Substitute for Native Extends
I am not sure whi @rniwa mentioned it, but this proposal has nothing to do with the is="custom-el" one.
Attributes are per element, unless you want every website to add a MutationObserver to the document.documentElement so that every custom attribute would be intercepted and its node somehow manifested, including Shadow DOM concerns already mentioned, there's no way this is going to solve anything at all regarding the ability to define Custom Elements that extends natives: you would still need to declare a prototype that should react when that kind of node only had a custom attribute changed.
Possible Custom Element Seppuku
One thing to be concerned about, is the dual binding at that point a custom prefixed attribute is going to be readable, and writable, through the element.
In current Custom Element specifications, if I have ['my-attr'] as list of observable attributes, I expect that whoever use setAttribute on it would trigger an attributeChangdCallback.
If I have something reflected per instance that as soon as accessed would eventually trigger a possible callback, we'll be in infinite loop/recursion land for a basic attribute set, something that at least el.dataset.attrName = "value" wouldn't cause.
As summary, I hope this proposal/idea will be implemented, considering all the possible side-effects it might bring to the table (and not because the proposal is bad, simply because we have legacy around the WWW :-( )
 WebReflection
on 20 Jan 2017
WebReflection
on 20 Jan 2017
@Marat-Tanalin it's not a custom attribute, so I don't understand the relevance to what I said. I did not say that standard boolean attributes are "data". I said that data-* attributes are not just for "data", but for any custom use, like you want to use _foo attributes for. So again, what do you want to use _foo for that you do not consider "data"?
zcorpan
on 20 Jan 2017
@LeaVerou
These stats go against common knowledge: Angular and Vue are very popular, it seems weird that they'd be collectively used by only 0.4% of websites.
SELECT page, COUNT(url) AS num
FROM [httparchive:har.2017_01_01_chrome_requests] WHERE
REGEXP_MATCH(JSON_EXTRACT(payload, '$.request.url'), '/(angular|vue).+js')
AND JSON_EXTRACT(payload, '$.response.content.mimeType') CONTAINS 'javascript'
GROUP BY page
ORDER BY num DESC
5841 pages, so ~1.2%. Per https://trends.builtwith.com/javascript/Angular-JS it should be something like 1.4% in top 1m sites using Angular, so this seems in the right ballpark.
zcorpan
on 20 Jan 2017
@zcorpan Simon, thank you for your substantive comments and questions.
it's not a custom attribute, so I don't understand the relevance to what I said.
My point is that _all_ custom attributes are data attributes to the same extent as _all_ standard attributes are data attributes. The latter are obviously not, so the former are not too.
what do you want to use
_foofor that you do not consider "data"?
Given that _-prefixed attributes are currently formally invalid and I care about validity, I add them only via JS for now, so they are not discoverable by validator. This primarily includes adding attributes to the root HTML element dynamically based on feature detection for the purpose of applying different styles depending on what features are available. Using classes for the HTML element for this purpose is undesirable since such classes could conflict with other elements’ classes given that it’s a good CSS practice, in stylesheets, not to prepend class selector with a specific-element selector when styles are for a generic DIV container (e. g. just .foo should be used instead of DIV.foo, while the HTML element could have the foo class too, so styles could be unintentionally applied to the HTML element too). To prevent collisions, a prefix should be added to the class name (so that HTML-element’s class is named _foo instead foo), but then there is no point in using a class (<html class="_foo">), and it’s easier just to add a same-name prefixed attribute (<html _foo>). Compared with data- attributes, _ is shorter and makes selectors in CSS easier to read and use ([_foo] instead of [data-foo]) regardless of whether the attributes are added dynamically (and not hard-coded statically) on HTML level.
Also, using attributes in terms of feature detection allows to have more than just two boolean states (available/unavailable) that, in case of a class, would need to have a bunch of different similar classes, while an attribute, unlike a class, has not just a name, but also a value (this specific benefit applies to data- attributes too, but they are just too long as we already know).
Another purpose I _would_ use _-prefixed attributes for once they are legitimized is e. g. navigation menus where design needs to apply styles to previous element of a specific element (e. g. corresponding to current section of the site). Given that there is still no way to select the previous sibling (unlike next sibling), it’s solved by marking the corresponding previous element _explicitly_ on HTML level either with a class or with an attribute. With a class, to prevent collisions with global classes, it would make sense to use a local class prefixed with e. g. _, but if I’m forced to use a prefix anyway, it’d be unreasonable to use a class if a same-name attribute could be used instead:
<li class="_prev"> → <li _prev>
As a bonus, compared with classes, attributes allow more possibilities in terms of selectors, e. g. it’s possible to select elements by a _part_ of an attribute. And compared with the one-character _ prefix, the data- prefix is too long and obtrusive as already said by me and others.
Marat-Tanalin
on 20 Jan 2017
My point is that _all_ custom attributes are data attributes to the same extent as _all_ standard attributes are data attributes. The latter are obviously not, so the former are not too.
OK, so it seems we agree on this.
Thanks for the examples. I'll try to tweak the spec text and add new examples in the spec for data-* attributes.
zcorpan
on 23 Jan 2017
If both proposals are being looked at perhaps it would be worth adding a note discouraging use of underscore prefix in libraries but to reserve it for individual sites and page level javascript. If this is done at the level of SHOULD/SHOULD NOT it won't affect conformance but will hopefully encourage good practice (and avoid the worst scenario where the first library using underscore to get popular will end up owning it).
This actually then has a nice benefit of making it easy to see attributes that are part of a library vs ones aimed at more local use.
 chaoaretasty
on 23 Jan 2017
chaoaretasty
on 23 Jan 2017
That sounds reasonable; the spec already has this text for data-* and JS libraries:
JavaScript libraries may use the custom data attributes, as they are considered to be part of the page on which they are used. Authors of libraries that are reused by many authors are encouraged to include their name in the attribute names, to reduce the risk of clashes. Where it makes sense, library authors are also encouraged to make the exact name used in the attribute names customizable, so that libraries whose authors unknowingly picked the same name can be used on the same page, and so that multiple versions of a particular library can be used on the same page even when those versions are not mutually compatible.
For example, a library called "DoQuery" could use attribute names like data-doquery-range, and a library called "jJo" could use attributes names like data-jjo-range. The jJo library could also provide an API to set which prefix to use (e.g. J.setDataPrefix('j2'), making the attributes have names like data-j2-range).
https://html.spec.whatwg.org/multipage/dom.html#embedding-custom-non-visible-data-with-the-data-*-attributes
zcorpan
on 23 Jan 2017
Don't want to weigh in on the discussion, but from a practical Web developer's point of view, we have a disagreement with our colleagues at the office related to your subject. We are creating our own custom Angular components (e.g. <my-dropdown>) and we are wondering how to name the custom attributes for these. One colleague is putting data- all over them, because he's concerned about the validation issues, and I suggested that this is pointless, since strict, old-fashioned validators will complain about the custom elements anyway, so what's the point of prefixing the attributes with data-?
I would appreciate some advice on this.
Thanks :)
 digeomel
on 8 Feb 2017
digeomel
on 8 Feb 2017
You could use https://checker.html5.org/ which supports custom elements.
The reason arbitrary attributes are not allowed on custom elements is that standard global attributes apply to custom elements as well, and they are not a frozen set; we want to keep the possibility to add new attributes to the standard without conflicting with existing web content that had already started using that name for something else. So data- for custom elements is correct.
zcorpan
on 8 Feb 2017
Sorry, my above comment is wrong for autonomous custom elements, they allow any attribute per the HTML standard (and the checker allows them as well). See https://html.spec.whatwg.org/#autonomous-custom-element . The possible conflict with any new global attributes is still there, but is also there for the embed element...
zcorpan
on 8 Feb 2017
Based on the current discussions the recommendations would be:
_attribute- if this is custom just for your specific siteng-attribute- namespaced under the prefix angular usesdata-attribute- this is still finedata-my-attribute- existingdataprefix but also good practice of including a namespace for your attributesmy-attribute- if you're developing this as a library to be used in other places,myshould be a prefix common to your library to minimise collisions and must be 1 or 2 charactersng-my-attribute- it's an angular component so namespacing underngmakes sense, the extramyhelps namespace yours together to further prevent collisions with other angular attributes.
chaoaretasty
on 8 Feb 2017
data-my-attribute- existing data prefix but also good practice of including a namespace for your attributes
This one looks redundant.
Also, it would probably make sense to generally _recommend_ to use the _ prefix for _any_ (incl. library-specific) nonstandard attributes, and additionally use a library-specific prefix for libraries. So if a New Cool Framework has appeared and it needs HTML attributes, its prefix would be e. g. _ncf-. Two-characters prefix space would be _exhausted_ very quickly, while with _, we would have an _unlimited_ number of possible framework-specific prefixes.
Marat-Tanalin
on 8 Feb 2017
Any news on this?
There is no good reason why tags can be custom but attributes not.
 nuxodin
on 28 Apr 2017
nuxodin
on 28 Apr 2017
Fwiw, I’ve already started using _-prefixed custom attributes instead of data- attributes and local classes.
_Update:_ I mean using now in _static HTML_ — besides adding dynamically via JS that I did long ago before public proposal.
Marat-Tanalin
on 28 Apr 2017
Fwiw, I’ve already started using _-prefixed custom attributes instead of data- attributes and local classes.
I've been using mv- attributes in a library I'm about to release since before I started this post, doing my part in paving the cowpaths even more :)
LeaVerou
on 28 Apr 2017
I’d be fine with this as long as the pre-hyphen part could be empty, so attributes could have names like -foo, -bar, etc.
I'd rather support your proposal, as it is generic and not biased (towards angular or whatever).
I also have the personal preference of the dash over the underscore (the latter just looks uglier to me).
But please remember that many X(HT)ML parsers follow the XML syntax that mandates that XML names may start with a letter, an underscore, or a colon (!) only.
Should this change be implemented as is, that might break a lot of things.
_(In an era when one has to fight for people to close tags like<img />, <br /> properly, it does matter to me.)_
On the other hand, attributes starting with a colon shall work with XML based stuff, and according to my test they also work in Firefox properly, however there may be quirks with other user agents / DOM implementations.
 strongholdmedia
on 30 Apr 2017
strongholdmedia
on 30 Apr 2017
Dumb question: does XML compatibility matter at all? HTML5 is not XML already.
Also I'd add that today we can have data-* and aria-* attributes only because nobody squatted on those before. If people start using random attributes we'll reach a point where you can't introduce attributes with "nice" prefixes because they'd conflict with existing sites.
I'd love -myattr, I'd be ok with _myattr, but I see the suggestion to open any dashed attribute as shortsighted.
What I really liked was the good ol' real namespaces of XML, where you'd define your namespace:* at the top and avoid any conflicts.
 fregante
on 25 May 2017
fregante
on 25 May 2017
Re XML compatibility, see https://github.com/whatwg/html/pull/1356#issuecomment-224088877 and earlier comments.
In this case, attribute names are important to preserve and be able to work with without having to go through infoset coersion. So in my opinion the general rule to be XML compatible should apply.
zcorpan
on 30 May 2017
Can someone set it in stone?
nuxodin
on 4 Jul 2017
So far none of the arguments here have sufficed to convince the editors or address their objections in a satisfactory way, so no. See https://github.com/whatwg/html/issues/2271#issuecomment-273839370 for my latest thinking, at least. In fact it maybe time to close the issue without action.
domenic
on 4 Jul 2017
Probably the best option is just to use the feature since it just works in all browsers regardless of what the spec says.
Marat-Tanalin
on 4 Jul 2017
Sure, why not
- Willingly risk things breaking in the future
- Cause headaches for spec authors who will have to work around stubborn library authors' decisions?
fregante
on 4 Jul 2017
No risk at least with the underscore prefix. Standard attributes will never start with underscore.
If the spec authors would be forced to standardize the feature they otherwise wouldn’t, that’d be a nice intended outcome.
Marat-Tanalin
on 4 Jul 2017
See #2271 (comment) for my latest thinking, at least. In fact it maybe time to close the issue without action.
I can't help but wonder if a similar analysis was done for custom element names. Did you find that nonstandard elements with hyphens were so widespread already that you had to standardize them? I’m guessing not. In fact, I'd wager that the number of invalid attribute names in the wild is much bigger than the number of invalid element names in the wild, even now. You just saw the need for a reasonable naming scheme that is not unreasonably verbose. Given that element names are only used once per element, and attributes multiple times, the need is greater here. This is a rather long discussion, where many people have expressed opinions, especially if you count the silent votes. It's disrespectful to all these people to close this with "no action" just because the feature we're proposing is not sufficiently in use already (even though the absolute numbers are in the thousands, unlike most proposed features!). That's a level of scrutiny that I have not seen applied to any other proposed feature in the Web platform.
LeaVerou
on 5 Jul 2017
The analogy with custom elements is a good one, especially from a cost vs. benefit perspective. Custom elements bring whole new capabilities to the platform, allowing you to hook into the parser and react to element lifecycles in a way that was impossible before. That's worth the downside, in our eyes.
On the contrary, the benefit of the change proposed here is that some people will be able to get both shorter custom attribute names and still have their pages validate. That's not worth the downsides that have been enumerated, especially given that people can do either of those things alone as long as they don't want to do them together.
Finally this lets me reiterate the point I've made several times now. Which is that if we had a true custom attributes feature, exposing low-level platform capabilities in the same way custom elements did, then it would be a worthwhile. In the absence of that, it's not.
domenic
on 5 Jul 2017
Finally this lets me reiterate the point I've made several times now. Which is that if we had a true custom attributes feature, exposing low-level platform capabilities in the same way custom elements did, then it would be a worthwhile. In the absence of that, it's not.
Then let's do that! That's what we really need, only making them valid is a compromise, as it seems easier to implement.
LeaVerou
on 5 Jul 2017
I think html-syntax should not be influenced by DOM APIs
The advantages I see:
- Same rules as custom-elements
- Shorter (yes, there can be a lot of custom-attributes)
- Standardizise what is allready in use and can not be overturned
- Armed for a future API like "document.registerAttribute('my-title')"
nuxodin
on 5 Jul 2017
FWIW re: Custom Attributes similar to Custom Elements, there's a custom-attributes library which follows the Custom Elements API very closely (almost identical), to allow a mixin style of functionality. Might be a good spot to test the waters / API.
As @annevk mentioned, it was discussed (briefly) at 2016 TPAC - see this tweet, and personally would love to see it discussed in more depth at this years 2017 TPAC. I feel Custom Attributes could solve a lot of of problems as well as this one, namely in the Custom Elements domain e.g. inheritance debate
 bedeoverend
on 31 Jul 2017
bedeoverend
on 31 Jul 2017
I was at TPAC 2016, shame I missed this discussion. I will be at TPAC 2017 too, I'll make sure not to miss it again :)
Custom elements and custom attributes are inextricably linked. If custom elements are going to act like normal HTML elements, their functionality could require annotating existing HTML elements too. For example, let's assume <datalist> did not exist and had to be implemented with a custom element (e.g. <foo-datalist>). We would need a custom attribute on <input> to go with it (foo-list). It seems odd to spec the element part but not the attribute part.
LeaVerou
on 31 Jul 2017
Coming back to my practical Web developer's point of view, has anybody noticed what's going on with attributes in Angular (2+)? They have all sorts of (I would assume non-standard) symbols, stars, parentheses, brackets, square brackets, parentheses in square brackets... 😝
I guess the Angular team has not been reading this discussion or they just couldn't care less about W3C standards because... Google?
digeomel
on 31 Jul 2017
@digeomel interesting, thanks for pointing that out (see https://angular.io/guide/template-syntax for examples). If https://github.com/whatwg/dom/pull/449 is successful, maybe we should allow such attribute names (despite the XML incompatibility).
zcorpan
on 16 Aug 2017
I guess the Angular team has not been reading this discussion or they just couldn't care less about W3C standards because... Google?
Seems like that, yep. Like the "don't be evil" times are way over.
(Too bad "vue" followed suit though.)
strongholdmedia
on 16 Aug 2017
Please stop the attacks against Google. They're not welcome here as per https://whatwg.org/code-of-conduct.
annevk
on 17 Aug 2017
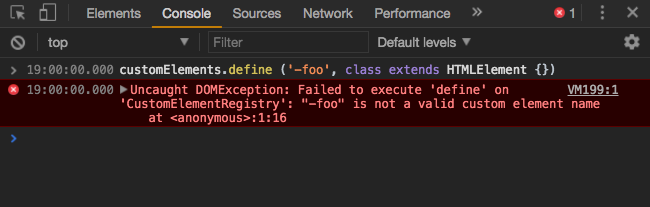
@LeaVerou @bedeoverend @Marat-Tanalin @rniwa @annevk @chaoaretasty @strongholdmedia please note that custom elements cannot have an empty prefix section i.e. -foo. Just a heads up as have recently had this discussion ad nauseam. Just wanted to be clear as this is the only naming caveat when comparing _custom elements name conventions/restrictions_ to _custom attributes being named similar to custom elements_
Just thought i'd mention as @bfred-it stated he'd love the -foo syntax. For Custom Element definitions that wouldn't validate the PotentialCustomElementsName production restrictions
which enforces [a-z] (PCENChar)* '-' (PCENChar)*
 snuggs
on 10 Sep 2017
snuggs
on 10 Sep 2017
Thanks for the follow up.
Of course, XML standard specifically prohibits "Name" (as per a subset of NMTOKEN) to start with anything non-alpha.
But it allows "Name" to start with underscore, no matter it be an element name or attribute name.
This is consistent with that part of the PotentialCustomElementsName specification too.
(As a side note, I personally think the "blacklisting the already-used names" exclusion method is kind of horrible and prone to future collisions. But then again, maybe it is better to have collisions than a beautiful garden nobody visits.)
strongholdmedia
on 10 Sep 2017
I know I'm a little late but it would be great to not have to do the data-. Every developer I know thinks it's very annoying lol.
 tsteuwer
on 9 Oct 2017
tsteuwer
on 9 Oct 2017
I found @strongholdmedia's suggestion of using a colon for denoting custom attributes to be a good solution, but seems like using colon would be invalid in HTML5 parsed as XML? (https://www.w3.org/TR/html5-diff/#syntax and https://www.w3.org/TR/html5/the-xhtml-syntax.html#the-xhtml-syntax). Which leaves us with @Marat-Tanalin's _ style attributes.
I came here from @LeaVerou's mavo website and initially felt that it made sense to drop data- attributes. (I used them extensively in angular 1.4, but then angular itself moved away from it towards a very puzzling syntax). But after reading all the comments here, and in the linked issues above, I feel conflicted. As a developer, adopting the mv- style 2-letter attributes feels like an arbitrary restriction, even though it does save me time from typing out data- every time. The _ syntax feels ok but looks ugly in a sea of hyphens.
Attributes have a name and a value. Attribute names must consist of one or more characters other than the space characters, U+0000 NULL, U+0022 QUOTATION MARK ("), U+0027 APOSTROPHE ('), ">" (U+003E), "/" (U+002F), and "=" (U+003D) characters, the control characters, and any characters that are not defined by Unicode. In the HTML syntax, attribute names, even those for foreign elements, may be written with any mix of lower- and uppercase letters that are an ASCII case-insensitive match for the attribute's name.
Then, you could also have -my-* style attributes, correct? I don't think there's any possible clash with SVG or other standard HTML attributes here? I'd serve the same as _-based proposition above, but would be more in-line with what is already there.
But, as a committee which has to decide on the spec to "set in stone" the validity of the attributes, and these solutions feel like only an iterative improvement over the existence of data- attributes, and probably might just work to fragment the developers' usage even more.
I still feel there's a strong advantage to sticking to a single sanctioned convention (data-) for custom data attributes, at least until we have a processing model for the "custom attributes".
I don't know what this means, and couldn't find a link describing the 'processing model', but it sounds promising.
 kumarharsh
on 13 Nov 2017
kumarharsh
on 13 Nov 2017
I found @strongholdmedia's suggestion of using a colon for denoting custom attributes to be a good solution, but seems like using colon would be invalid in HTML5 parsed as XML?
I am unsure if I was suggesting anything like it, IIRC, it is rather the XML spec itself that allows such namings/NMTOKENs.
seems like using colon would be invalid in HTML5 parsed as XML?
From what I read,
A node with a local name containing a ":" (U+003A).
it comes to my understanding that this is due to these being forbidden for they are used to reference other namespaces. So your suspicion seems correct.
I'd serve the same as _-based proposition above, but would be more in-line with what is already there.
Please note that standardising "what is already there", as opposed to premature optimization, is in reality the root of all evil.
Of course, there may be tried and true solutions and methods for different things, but just that something is widespread does not mean it is any good (just that, at a specific time, it was better than anything else widely known).
As for standardization, IMHO constructing a spec having a fixed - and lengthy - list of exceptions to it (on different bases mostly aggregating around things like "they was there first") pretty much nukes the purpose to begin with.
strongholdmedia
on 13 Nov 2017
Another use case: Web Components that degrade gracefully.
For example, take a look at this carousel component
It’s used like this:
<skeleton-carousel dots nav loop>
<iron-image placeholder="https://source.unsplash.com/category/nature/10x10"
data-src="https://source.unsplash.com/category/nature/500x300"
sizing="cover"
preload
fade
></iron-image>
<iron-image placeholder="https://source.unsplash.com/category/food/10x10"
data-src="https://source.unsplash.com/category/food/500x300"
sizing="cover"
preload
fade
></iron-image>
<iron-image placeholder="https://source.unsplash.com/category/buildings/10x10"
data-src="https://source.unsplash.com/category/buildings/500x300"
sizing="cover"
preload
fade
></iron-image>
</skeleton-carousel>
Wouldn't it be great if its content was proper <img> tags, so that something reasonable is visible in older browsers?
But if you do that, then the attributes would have to be data- prefixed with no indication of which attributes belong to the component and which ones don't.
LeaVerou
on 6 Dec 2017
@LeaVerou
Wouldn't it be great if its content was proper
tags, so that something reasonable is visible in older browsers?
But if you do that, then the attributes would have to be data- prefixed with no indication of which attributes belong to the component and which ones don't.
What am I missing? If you customised the img element, e.g.
<img is="iron-image" src="some.img" alt="what?"...>
You would use normal attributes where they existed, no? Isn't it only an issue where you are making up something completely new anyway?
 chaals
on 25 Apr 2018
chaals
on 25 Apr 2018
@chaals: I think the issue is that the current custom elements spec says:
Customized built-in elements follow the normal requirements for attributes, based on the elements they extend. To add custom attribute-based behavior, use data-* attributes.
So if you write a component as <img is="iron-image", then all attributes defined by the iron-image component need to be data- prefixed. But data-* attributes are also used by whatever other scripts (unrelated to the iron-image component) might be interacting with the page that contains an <img is="iron-image" element. Hence, @LeaVerou's observation that:
no indication of which [data-*] attributes belong to the component and which ones don't
 effulgentsia
on 26 Apr 2018
effulgentsia
on 26 Apr 2018
@chaals They are not customizing the <img> element because they don't want data- prefixed attributes (and I don't blame them). They use custom elements just so they can use shorter attribute names, so there is no fallback.
LeaVerou
on 29 Apr 2018
But if you do that, then the attributes would have to be data- prefixed with no indication of which attributes belong to the component and which ones don't.
Following your logic, those attributes that display "something reasonable" in "older" browsers -or affect the appearance - do belong to the "component", while the others don't.
In my opinion, one should not use the markup layer for state and unpredictable side effects at all, for that is violation of the single responsibility principle. But this is exactly what Angular or Vue does.
I believe that people should not at all use something like your skeleton-carousel in the markup as well. For these types of things, there is - was and will be - XML/XSLT always, should anybody find the need.
After all, what could the benefits be of "knowing" what "attributes" do, according to the designer's own logic, belong to the component, if one could not reasonably deduce what attributes will actually affect the rendering in any conformant and well-specified client?
Does anyone really want to reduce the concept of well-formedness to having an even number of quotation marks or inequality marks?
I think, after following this discourse for a while, that perhaps the idea of a specific layer, just like XML/XSLT but maybe distinct, being promoted towards those people who are obsessed with this component-oriented thing that is, in my opinion, somewhat distinct and distant from the concept of DOM and what it was conceived for, that also conveys the abandon hope all ye who enter here type of note in and of itself for others; and that HTML be left to those who actually prefer documentation over convention of people with random mindsets that they may, at times, consider counter-intuitive or even marginal, is possibly better for both worlds.
strongholdmedia
on 30 Apr 2018
I don't see a it being likely people will use data- attributes for custom elements, I don't think I've ever even seen an example of custom elements that uses them (even the HTML spec does not), there's no encouragement from any existing solutions and no push from custom element authors to use data--prefixed attributes.
I think non-conforming names is web reality already anyway, a decent number of sites are already using these non-conforming attributes (and even ones without hyphens). Regardless of whether the WHATWG agrees to change the spec new global attributes will still need to be checked for web compatibility.
 Jamesernator
on 31 May 2019
Jamesernator
on 31 May 2019
> I think non-conforming names is web reality already anyway, a decent number of sites are already using these non-conforming attributes (and even ones _without_ hyphens). Regardless of whether the WHATWG agrees to change the spec new global attributes will still need to be checked for web compatibility.
Please stop the attacks against Google. They're not welcome here as per https://whatwg.org/code-of-conduct.
Still, it may be important to find out that no matter how much effort you put into standardization, there were, are, and probably will be people that won't give a darn about these.
Of course, it wouldn't be a problem, were it not for such people having inexplicable influence.
Surely enough, it could be asked what this comment adds to the "mix" - if there is anything left to it.
But some of us do remember that we've seen this before (at IE5.5, to single out one) and it didn't turn out that well.
strongholdmedia
on 1 Jun 2019
Please don't add off-topic comments. This issue is about custom attributes.
To move this issue forward, a good step would be to ask implementers if there's interest in an API for observing changes to custom attributes as annevk suggested.
zcorpan
on 3 Jun 2019
Since the css function attr() will be usable with all attributes, it might be a good time to think about a specification for custom attributes.
https://www.w3.org/TR/css3-values/#attr-notation
nuxodin
on 12 Jun 2020
Since the css function attr() will be usable with all attributes
attr() may be limited to a subset of prefixed attributes, see https://github.com/w3c/csswg-drafts/issues/5136.
 Malvoz
on 21 Oct 2020
Malvoz
on 21 Oct 2020
I'm currently in the process of writing a framework built on Web Components (custom elements), and I'm having a very hard time figuring out how to handle the name-spacing of attributes. The way I see it, there are 3 different agents who may want to define attributes on custom elements:
- The consumer of the custom element. The intent may be to mark the element for querySelector() purposes or for CSS.
- The author of the custom element. The intent may be to provide an interface with the consumer for receiving initial state or reflecting the element's state.
- The user-agent (browser), which will inevitably define new _global_ attributes in the future, for arbitrary purposes.
The first group of people (consumers of the element) can simply use data-* attributes, which are reserved by the spec for this purpose.
The third group of people (browsers) tend to define attributes that are single lowercased words, but I'm not confident that I can rely on that assumption.
The second group of people (authors of custom elements) seemingly have no good solution. They can't use data-* attributes because those are reserved for the consumers of the element. And without some guarantees about the naming of future global attributes, they have no way of protecting themselves against future name collisions.
As a software engineer, the obvious solution to me is namespaces. If we can't use colon (:) namespaces due to XML compatibility, then hyphen (-) namespaces seem perfectly fine. Each independent agent can define their own namespace to work in. The data- namespace is for the website author. The "empty" namespace (no hyphen) is for browsers. And every other namespace (except aria-, I guess) is for everybody in-between.
 JoshuaWise
on 14 Dec 2020
JoshuaWise
on 14 Dec 2020
As a software engineer, the obvious solution to me is namespaces. If we can't use colon (
:) namespaces due to XML compatibility, then hyphen (-) namespaces seem perfectly fine. Each independent agent can define their own namespace to work in. Thedata-namespace is for the website author. The "empty" namespace (no hyphen) is for browsers. And every other namespace (exceptaria-, I guess) is for everybody in-between.
You, sir, as your name suggests, are indeed very wise.
I also insisted that something similar be made / kept, but ran into the _some actors_ doing what-when-ever they _deem feasible_ attitude that turned out persistent, and thus gave up.
strongholdmedia
on 14 Dec 2020
Related issues
 tkent-google
·
3Comments
tkent-google
·
3Comments
 benjamingr
·
3Comments
benjamingr
·
3Comments
 tontonsb
·
3Comments
tontonsb
·
3Comments
 lespacedunmatin
·
3Comments
lespacedunmatin
·
3Comments
 iane87
·
3Comments
iane87
·
3Comments
Most helpful comment
@domenic
The obvious reason of prevalence of
data--prefixed attributes over other prefixes is thatdata-is the _only formally valid_ option for now. This has _nothing to do_ with whether people are actually _happy_ with it.Good web developers just usually prefer to keep their documents valid, and not just because that makes them “feel good”, but also to be able to use validators to easier see _real_ errors not intermixed with fictious pseudoerrors related to artificial spec-level limitations not matching reality.
Because not all custom attributes are data attributes.
data-attributes are for data, custom-prefixed attributes are for custom needs whatever those are.