@StevenBlack only noticed today how big the repo is when I pull updates with SourceTree, any reason it's so large?
 mitchellkrogza
mitchellkrogza
All 55 comments
I've thought about this. A lot.
The reason it's so large, of course, is the nature of git: it preserves the full history of every artefact. Since this repo produces several megabyte-sized host files every few days, this is where we end-up.
I don't care about the history of all these hosts files.
So some questions for the group:
1) How can we keep the hosts files in the repo but not track their history, and
2) How can we truncate the history of this repo?
I've looked at this several times, and I've found no great answers.
 StevenBlack
on 31 Mar 2017
StevenBlack
on 31 Mar 2017
Think any of this might help? http://stevelorek.com/how-to-shrink-a-git-repository.html
mitchellkrogza
on 31 Mar 2017
@mitchellkrogza yes, I saw that. We have the opposite problem: large files that we want to keep in the repo. We just don't ever want to revert to prior versions. Which isn't how git is fundamentally wired.
I need to keep the freshest hosts files in the repo, just not track their history. Or, say, not track their history for very long.
Truncating the repo is problematic because that would lose contributor history on the Python scripts, which I do not want to lose.
It's complicated 😄 – I hope we can find a way to make it work. The increasing clone size is unreasonable and unsustainable.
StevenBlack
on 31 Mar 2017
Maybe this might help ?
 funilrys
on 31 Mar 2017
funilrys
on 31 Mar 2017
@funilrys yeah, I think that's the ticket!
Maybe my requirement to preserve the contributors is ultimately unwise. Perhaps I could acknowledge past contributors in the readme, then aggressively cull old objects.
StevenBlack
on 31 Mar 2017
I don't care about the history of all these hosts files.
A little history is useful, especially for new false-positives or unexpected omissions.
But history going back too far is likely not needed, and has the problem being discussed in this issue.
 Gitoffthelawn
on 1 Apr 2017
Gitoffthelawn
on 1 Apr 2017
Just make a shallow clone git clone --depth 1 https://github.com/StevenBlack/hosts.git or change the depth for as much as you would like.
 bsides
on 7 Apr 2017
bsides
on 7 Apr 2017
This would indeed be the soft option.
Maybe all we need to do is document this, at the top of the readme.
StevenBlack
on 7 Apr 2017
@StevenBlack I agree.
When I open a project in Github I usually go to the issues to see how is the project developing and this topic was the first one I opened, before actually cloning. Thankfully. I would be so mad to have 400mb+ hanging in my HDD.
bsides
on 7 Apr 2017
@bsides that's why I raised it, I work on OSX so all my GIT projects are in my Documents folder and linked with iCloud so that whatever is on my desktop syncs to my macbook. Mornings when there was new commits on this repo I would bring my local copy up to speed and then my network would slow down dramatically not only from the Pull request but the subsequent upload that iCloud then does syncing all my doc folders. Us poor South Africa stuck with ADSL at 5Mbs when uploads take place it just about kills the network download speed until it finishes. That's when I actually went to check the folder size and saw why it was causing me such headaches. Hope it gets culled down soon 👍
mitchellkrogza
on 7 Apr 2017
Anyone using the SourceTree App?
How does one set git clone --depth 5 https://github.com/StevenBlack/hosts.git in Sourcetree?
mitchellkrogza
on 17 Apr 2017
FYI, Sourcetree for Windows has a clone depth setting under advanced settings when adding a repo to SourceTree but Sourcetree for OSX does not have this. Have logged issues with Sourcetree developers.
mitchellkrogza
on 25 Apr 2017
Maybe once a year or month delete all the "hosts" files and their history using something like the BFG Repo-Cleaner? You would only need to backup the unique StevenBlack hosts file, or any other "hosts" unique to this repo, and the rest can just be regenerated/re-downloaded as usual as if totally fresh to the repo. Obviously there should be a backup of everything anyway before any repo cleaning, but those would be the real irreplaceable ones you'd have to snag out of the backup. This would retain the history for the actual project files and just dump the problematic history for the large files that are routinely regenerated.
There's also the possibility of deleting all the "hosts" as above with the repo cleaner once and just transition to having the hosts files stored separately by a free third-party web host and not part of the repo, a ZIP of all of them with some easily extractable file structure and also a direct URL for each file so you have options of how it can be fetched. Essentially it would be separating the working project from the data itself, both the source data being acted on and the resultant data being generated. Basically it's the same thing game developers do when they're working with licensed content (i.e. artistic content used for textures, sound content used for sound effects or music, dialog content used for NPC speech, etc.) but an open game engine. They develop the engine, but keep the game content itself separate and in a state that it can be easily reintroduced by just extracting some files back into it or what have you. Once you have your local repo reassembled, you then put .gitignore to work and make sure git ignores those data files and just syncs everything else.
The latter is a basic use case for .gitignore. If you want files to be part of git, then they are part of git and everything that comes with it. If you don't want certain files to get caught up with all the git history, you're basically saying you don't want them to be part of git and there's no shame in separating them out and distributing them via a different protocol. This project is basically aggregating multiple files that already have entire git repos dedicated just for each one of them, so trying to then again aggregate them together into another repo can be seen as a bit redundant anyway.
Either way, I do think documenting contributors/contributions would be a good idea anyway just to give the project more options down the road. You could just export a quick git shortlog and format it however is best for the kind of credits you want.
 ScriptTiger
on 4 Aug 2017
ScriptTiger
on 4 Aug 2017
Some really solid ideas here, @ScriptTiger. Thank you for this valuable input.
I think I like the first idea best.
StevenBlack
on 4 Aug 2017
https://rtyley.github.io/bfg-repo-cleaner/
Using the repo cleaner on particular files would be the least invasive method of cleaning as you know exactly what you're getting rid of. However, if there's still problems after that, you can then try playing with getting rid of different types of blobs as well, like those bigger than a certain size.
ScriptTiger
on 5 Aug 2017
@ScriptTiger I have a question.
The BFG docs say...
At this point, you're ready for everyone to ditch their old copies of the repo and do fresh clones of the nice, new pristine data. It's best to delete all old clones, as they'll have dirty history that you don't want to risk pushing back into your newly cleaned repo.
This repo currently has 634 forks, and according to Github stats that I can see, 219 unique cloners in the past two weeks alone.
What are the potential risks?
StevenBlack
on 5 Aug 2017
PRs will still do compares and let you know what you're getting into before you merge. If it's trying to push more than you want it to, just ask the person to delete their repo, re-fork, and paste a backup of their changed files back in and submit the PR again. If they are using the GitHub website, deleting a repo, re-forking, uploading their changes, and sending a PR could take less than 5 minutes. If they are also wiping a local repo and cloning their new fork locally, if the clean was successful that shouldn't take too long either. If they made so many changes and don't know which files to upload or how to sync it, they can backup their old local repo, clone their new fork, and then just dump their entire backup, minus the .git directory, on top of the new clone so they have the new .git with their old files that they wanted to PR. Worst case scenario is you hit the merge and confirm buttons in haste and and up pulling more than you bargained for.
To be honest just looking at those numbers can be greatly misleading. The number that is actually affected by this is the contributors (currently only 34), not those that just clone or fork. People clone and fork for different reasons, wanting the latest build, thinking they might do something with it later, thinking they look cool having it in their repo list, whatever. But at the end of the day there has still only been 34 people that made the leap to PR and merged their data with yours. For those that don't wish to contribute, they can keep their old histories to themselves and your files and scripts will keep on working either way. If you update your repo and they want to pull the changes, they can do the compare and pull from yours like usual on top of theirs and that doesn't affect yours at all.
Another option, if you want to keep these files on Git but want to make their history more manageable, is setting up another repo for the problem files and just changing the links in this repo to point to the raw files in the other repo, which shouldn't be too much of a leap. Then contributions and feedback specific to those files can be contained in that repo while the Python script kiddies can get a bit more peace in this one. And then regularly cleaning out those isolated files would pose no risk at all to the Python scripts. Separating work flows between those with issues with or additions to domain lists (which I am sure is the bulk of the "issues") and those that are contributing to the core functionality of how those files are aggregated and generated (which is probably the bulk of the PRs) may also be seen as an advantage, similar to those that separate different work flows into different Slack channels for operations, development, etc. It would basically separate the consumers of the hosts files from the developers.
Now while all this at least makes sense to me, I'm just a satcom guy, which is really just playing with expensive radios. If we could get some further thumbs up or confirmation on this, that would be much appreciated. I don't want to end up being "that guy" that gets all the glares if things go "tits up," as the British say.
ScriptTiger
on 5 Aug 2017
Thanks @ScriptTiger, definitely going to do this.
StevenBlack
on 5 Aug 2017
@ScriptTiger incidentally, from The Guardian: Fast & simple Git history rewrites with The BFG is a great article.
StevenBlack
on 6 Aug 2017
Yeah, I've read it. I would have linked it the first time, but since I am new to this community I don't want people to think I am just spamming.
ScriptTiger
on 6 Aug 2017
Thinking about this again, we didn't really mention it, but the history for all the .zip files and READMEs that get regenerated each time should probably be nuked, as well. Just making sure we get a complete checklist down.
ScriptTiger
on 9 Aug 2017
Just as an update to this, I was far too curious to wait any longer. I have been dabbling with BFG with my tiny repos for a while, but playing with yours is far too good to pass up. So I ran this myself and reduced the repo to the uncompressed numbers below. Keep in mind the original repo is 550 MB.
This is what I did on my Windows machine:
java -jar C:\blah\blah\bfg-1.12.15.jar -D files/types C:\blah\blah\hosts
cd C:\blah\blah\hosts
git reflog expire --expire=now --all && git gc --prune=now --aggressive
The resultant packages are below for your perusal, they also include the full reports from BFG:
Only deleted history of binary .zip blobs:
java -jar C:\blah\blah\bfg-1.12.15.jar -D *.zip C:\blah\blah\hosts
Reduced to 67 MB
Deleted .zips plus hosts and readme files:
java -jar C:\blah\blah\bfg-1.12.15.jar -D {*.zip,readme.md,hosts} C:\blah\blah\hosts
Reduced to 34 MB
If you check the histories, everything is the same except the files with deleted history all start with the last commit as the first. If we just nuke the .zip history alone it should be fine, since I know you want to keep as much history as possible. Since binary packages can't be diffed, they are kept in whole blobs every overwrite and can't be diff patched like text files.
So after going through the above steps, the only thing that's missing is the last force push:
git push -f origin master
ScriptTiger
on 9 Aug 2017
Thanks @ScriptTiger, this is really awesome.
I'll likely wait for the weekend to perform this.
StevenBlack
on 10 Aug 2017
No worries, I just thought I'd vomit as much info about it as possible before you make the leap to rewriting history, as I know it's massively a taboo subject in certain circles.
ScriptTiger
on 10 Aug 2017
Thanks @ScriptTiger I tried this on a new repo I started and brought it down from 1.7 Gb to 585 mb. It is a big repo to begin with but this really helped fixing the massive size and I now no longer do any tagging or releases on the repo concerned as it just grows the repo in size way too fast.
mitchellkrogza
on 13 Aug 2017
The biggest thing to consider is binary packages or anything that can't be diffed and ends up getting blobbed, which is basically just putting a duplicate in history similar to a shadow copy. Git was designed to enhance the history capabilities of text files through diffing and patching so it doesn't have to duplicate and only stores the changes from commit to commit. Files that aren't text just get duplicated whole and are always the biggest burden in history.
ScriptTiger
on 13 Aug 2017
I also cloned this repo, stripped the .zip history, and re-upped it as one of my own repos. I can't fork it to give you compares across forks as children repos don't have full rights to change history, but at least it gives you something to explore the edited history visually through the GitHub website.
ScriptTiger
on 13 Aug 2017
@StevenBlack I think this is quite possibly the ultimate guide to fixing this. I used this on my one repo and got it down from 870mb to 276mb. https://rtyley.github.io/bfg-repo-cleaner/#usage
I then did the same with your repo.
Size before:

Size After:

I did the following to your repo to test how much I could cull it down.
cd home/myusername
mkdir GIT
cd GIT
git clone --mirror https://github.com/StevenBlack/hosts.git
java -jar bfg.jar --strip-blobs-bigger-than 1M hosts.git/
cd hosts.git
git reflog expire --expire=now --all && git gc --prune=now --aggressive
cd ..
java -jar bfg.jar --strip-biggest-blobs 10000 --protect-blobs-from master hosts.git/
cd hosts.git
git reflog expire --expire=now --all && git gc --prune=now --aggressive
git push
Suggest you make a real live copy of StevenBlack/hosts repo and call it StevenBlack/hosts2 then copy the existing repo into number 2 and test this out before doing it on this live repo.
Hope this helps.
mitchellkrogza
on 14 Aug 2017
I went a step further and deleted my fork of your repo, then re-forked it and did the test above on my own fork at https://github.com/mitchellkrogza/hosts after pushing back I cloned my local fork to my local computer and this is the size.
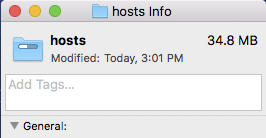
And all the commit history is still there, looks ok to me but you'll have to test this yourself.
So these were my steps:
cd home/myusername
mkdir GIT
cd GIT
git clone --mirror git clone --mirror https://github.com/mitchellkrogza/hosts.git
java -jar bfg.jar --strip-blobs-bigger-than 1M hosts.git/
cd hosts.git
git reflog expire --expire=now --all && git gc --prune=now --aggressive
cd ..
java -jar bfg.jar --strip-biggest-blobs 10000 --protect-blobs-from master hosts.git/
cd hosts.git
git reflog expire --expire=now --all && git gc --prune=now --aggressive
git push
Can you upload a zip of your BFG report directory for that, as well? I'm just worried stripping out history based on blob size might be a bit arbitrary and not as specific as particular files or file types. And the difference between being 67 M versus 34 M isn't really that big of a deal, especially in light of its current size. It might be something to consider further down the road if the repo gets unmanageable once again even after routine cleaning, but just personally I wouldn't be quick to do that unless it was needed. After being faced with all the options we could all collectively get together, Steven is set on retaining as much history as possible for the contributors' sakes while still making it manageable.
ScriptTiger
on 14 Aug 2017
@ScriptTiger here it is, look forward to your analysis of it 👍
bfg-report.zip
mitchellkrogza
on 14 Aug 2017
Just looking at it quickly, you have definitely stumbled upon some extra blobs we can lose, like there are some image files floating around in there, as well, apparently. But python scripts, json files, and a bunch of readmes are also mentioned quite a bit. When I get some time later and do some more testing I'll try and make a more complete list of file types to lose, unless you beat me to it. Nice work though, it's definitely digging deeper than I had thought of before. Ultimately Steven knows the repo best and what history should stay and go, so making a list with some examples of files that maybe he's forgotten of over the years would probably be a good idea, as well.
In my opinion, however, as fascinated as you and I are over such details, I think it may be best to address the actual issue of this topic first, being that the repo is unacceptably large, not just larger than it needs to be. I don't want to make the ultimate problem take a back seat while we go down another rabbit hole and make the others suffer. Through the independent testing we have both done, by getting rid of the zip files alone it reduces it to 67 M, and anything beyond that only squeezes out another 30 M, which really isn't that big of a deal compared to the almost 500 M the zip history lost. We should definitely open a new issue for this that can be worked on separately to do the more granular cleaning later.
ScriptTiger
on 14 Aug 2017
@ScriptTiger I'm thinking of getting rid of .zip files altogether.
The history of this is in Issue #188, where the whole .zip file thing appears to be a bum steer.
Or, does Hostman really require a .zip file?
StevenBlack
on 14 Aug 2017
Cleaning out history beyond that point can just be done with the standard git filter-branch, using the BFG reports as a guide. The performance improvements won't be noticeable once the repo is reduced to that size anyway. And the more granular details are always better with the git filter-branch, even the BFG documentation says so.
If Hostman does require zips, I honestly have never used it and wouldn't even begin to know, but making a 7za script would take less than a minute to write and it could download the raw and just package it after download. Now that's for Windows, of course on Linux everything is easier because such commands come standard. And let's be honest, worrying about how to make it easier for someone to make a zip and put a file in it really is the least of our concerns in the grander scheme of things I would think. I think our IT brains might just be making things run wild at this point, not EVERYTHING is a bug if it's not automatic.
In the off chance it has to do with requiring a remote file to be a .zip, I'll just host the packages myself in a separate repo as I already have a daily routine to check for updates, download all the hosts, and convert the file formats and adding an extra line or two to also package them in another repo really would not take much effort. And then I'll just routinely clear out all the history in that entire repo, which is even easier and faster than tweaking BFG settings and can be done with the standard git command set. I'll post those commands here in case @mitchellkrogza wants to play with it.
git checkout --orphan temp-branch
git add -A
git commit
git branch -D master
git branch -m master
git gc --aggressive --prune=all
git push -f origin master
This basically commits the files themselves to a new branch, deletes the master, renames the new branch to master, cleans house, and pushes the fresh and squeaky clean repo up as if it were a newborn.
ScriptTiger
on 14 Aug 2017
By the way, I totally missed how you made a perfect segue for me to shamelessly plug my AutoUpdate:
https://github.com/ScriptTiger/Unified-Hosts-AutoUpdate
It basically makes Hostman irrelevant for Windows users, or at least its broader use case.
ScriptTiger
on 14 Aug 2017
@ScriptTiger I'm happy to entertain a PR that extends readme_template.md to mention Unified-Hosts-AutoUpdate.
StevenBlack
on 15 Aug 2017
For sure. I was waiting to get some more feedback first before I started pushing for it to be "official," but it is getting quite a lot of traffic. In IT no news is good news I guess. I don't know if you've seen my DualServer repo, but if you check it out and find things to be in order, I could also throw it a mention at the bottom of the readme, as well, with the other interesting applications. It's actually been getting more traffic from Google than GitHub because I guess nobody else provides blacklists for DualServer, but I wouldn't mind fellow GitHubbers checking it out, as well.
ScriptTiger
on 15 Aug 2017
By the way, do you have any links for the Hostsman that people here are using? I have tried searching around and have found several different independent Python repos hosted by different people. All the articles I found on it just lead to a dead website, the same one that comes up when you just google it. Did this lose support a long time ago and only people that have been using it for a couples years are still using it? Do we know if people here are even using the same flavor of it, made by the same people, etc.? It's also possible I am just completely off and it's something so obvious I just can't see it, because it seems like a lot of people here know what it is and I wouldn't mind at least reading through the documentation or scripts or whatever it is just to check it out firsthand rather than just reading articles and issue posts here about it.
ScriptTiger
on 15 Aug 2017
@ScriptTiger it's literally the first :) http://www.abelhadigital.com/hostsman
 Jezza-x3
on 15 Aug 2017
Jezza-x3
on 15 Aug 2017
Hmm... I might just be having some technical difficulties on my end to access it then.
ScriptTiger
on 15 Aug 2017
@ScriptTiger
http://www.softpedia.com/get/Network-Tools/Misc-Networking-Tools/HostsMan.shtml
http://www.softpedia.com/get/Network-Tools/Misc-Networking-Tools/HostsMan-Portable.shtml
Those are mirrored from the site.
Jezza-x3
on 15 Aug 2017
Yeah, I found plenty of downloads for it on all the usual sites, cnet, softpedia, etc., but I was trying to check out the official stuff. I can access it now though, thanks. I had some security measures on my end preventing it from opening.
ScriptTiger
on 15 Aug 2017
What features about this product make it irreplaceable for the current users? I see you can pull from multiple sources, do most users here use other hosts lists besides those from this repo?
ScriptTiger
on 15 Aug 2017
Just something for consideration. I just added three lines to my existing daily script to put this repo together. I tried to mimic as much as possible the existing structure. I am assuming the .zip files here are packaged with gzip, so I also do the same as well as retain all the naming and directory structure to ensure compatibility with whatever software is currently in use. As I have said before, a different protocol all together would be ideal, such as HTTP/FTP, but this is at least a good demo for current users to try pointing their software towards.
ScriptTiger
on 18 Aug 2017
@ScriptTiger .zip files are going away very soon...
StevenBlack
on 18 Aug 2017
Lol, as they should. In the meantime this thread will just continue to get longer because I have a festering itch to address open issues and drop new ideas as I get them. I apologize for my OCD, I admit to having a problem and admit to not seeking help for it.
ScriptTiger
on 18 Aug 2017
@ScriptTiger just keep being you. No complaints here 😄
StevenBlack
on 18 Aug 2017
Oh, as an added benefit, the .zip files I host are all CRLF! I forgot to mention that, so we can actually just direct all traffic there for people that want it. I think the number of people wanting it in CRLF are more broadly just trying to use it rather than send PRs to this repo. So it's a two birds with one stone kind of deal I guess.
ScriptTiger
on 18 Aug 2017
So I guess in both regards it's basically the all-around legacy support repo. Would it be too much to amend to the readme once more and add a note for this on there? It would knock out a large chunk of our current issues, CRLF and Hostsman, at the same time.
ScriptTiger
on 18 Aug 2017
I am assuming the .zip files here are packaged with gzip
You must be meaning the file is created by GZip, not a ZIP file using GZip algo. In any case, neither is possible: ZIP doesn't support GZip as the algo (and doesn't create ZIP-compatible files although both use Deflate), but does Deflate, Deflate64, BZip2, LZMA, WavPack, and PPMD, as listed in https://stackoverflow.com/a/10220082. Of those 7-Zip doesn't support WavPack at all as said in http://www.7-zip.org/faq.html.
 rautamiekka
on 18 Aug 2017
rautamiekka
on 18 Aug 2017
As I said in an earlier post, I was going to use 7za, and actually had the script written for it, but then second-guessed myself based on the limited knowledge of Linux I have. I'll swap it back though, thanks!
ScriptTiger
on 18 Aug 2017
^ I've created aliases for different commands and they're publicly listed in https://github.com/rautamiekka/public_scripts/blob/master/global_shell_aliases, 7z being one of them with multiple forms. They'll get you going quickly.
rautamiekka
on 18 Aug 2017
All right, everything has been repacked and ready for Hostsman/CRLF lovers.
ScriptTiger
on 19 Aug 2017
In the readme it states the following:
The Non GitHub mirror is the link to use for some hosts file managers like Hostsman for Windows that don't work with Github download links.
The non-GitHub mirrored links are raw and not archived. If this has been working the whole time, why do we need archived packages at all? I thought that issue was with Hostsman that it had to be an archive?
ScriptTiger
on 20 Aug 2017
I'm closing this issue. Because it goes on, and on, and on....
I know what needs to be done.
StevenBlack
on 20 Aug 2017
Related issues
 bigdargon
·
3Comments
bigdargon
·
3Comments
 beerisgood
·
3Comments
beerisgood
·
3Comments
 Laicure
·
3Comments
Laicure
·
3Comments
 node1634
·
3Comments
node1634
·
3Comments
 The-Compiler
·
3Comments
The-Compiler
·
3Comments
Most helpful comment
Just as an update to this, I was far too curious to wait any longer. I have been dabbling with BFG with my tiny repos for a while, but playing with yours is far too good to pass up. So I ran this myself and reduced the repo to the uncompressed numbers below. Keep in mind the original repo is 550 MB.
This is what I did on my Windows machine:
java -jar C:\blah\blah\bfg-1.12.15.jar -D files/types C:\blah\blah\hosts
cd C:\blah\blah\hosts
git reflog expire --expire=now --all && git gc --prune=now --aggressive
The resultant packages are below for your perusal, they also include the full reports from BFG:
Only deleted history of binary .zip blobs:
java -jar C:\blah\blah\bfg-1.12.15.jar -D *.zip C:\blah\blah\hosts
Reduced to 67 MB
Deleted .zips plus hosts and readme files:
java -jar C:\blah\blah\bfg-1.12.15.jar -D {*.zip,readme.md,hosts} C:\blah\blah\hosts
Reduced to 34 MB
If you check the histories, everything is the same except the files with deleted history all start with the last commit as the first. If we just nuke the .zip history alone it should be fine, since I know you want to keep as much history as possible. Since binary packages can't be diffed, they are kept in whole blobs every overwrite and can't be diff patched like text files.
So after going through the above steps, the only thing that's missing is the last force push:
git push -f origin master