Feature Request
From the benchmark (performed by @SukkaW) we can see that cheerio can cause significant performance hit.
While cheerio is not necessary for the core functions of Hexo, it is currently utilized by several default plugins:
- [x]
meta_generator.js - [x]
external_link.js - [x]
toc.js - [x]
open_graph
We are hoping to re-implement them without depending on cheerio, if possible.
Related PRs:
- meta_generator:
https://github.com/hexojs/hexo/pull/3669~~https://github.com/hexojs/hexo/pull/3671~~ - open_graph:
https://github.com/hexojs/hexo/pull/3670~~https://github.com/hexojs/hexo/pull/3679~~https://github.com/hexojs/hexo/pull/3680~~ - external_link:
https://github.com/hexojs/hexo/pull/3685~~ - toc:
https://github.com/hexojs/hexo/pull/3850~~
Related issue:
 curbengh
curbengh
All 24 comments
Can this be part of the roadmap?
@NoahDragon
curbengh
on 18 Aug 2019
Cheerio use perse5 now and use htmlparser2 before.
There is a benchmark between NodeJS side dom parser: https://travis-ci.org/AndreasMadsen/htmlparser-benchmark
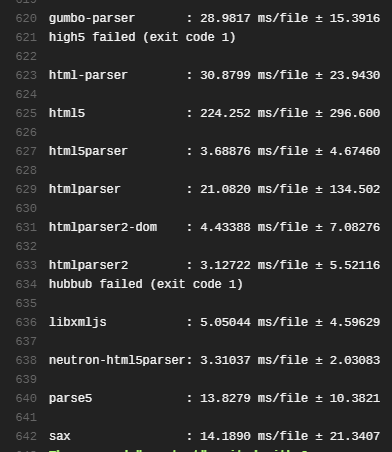
 SukkaW
on 18 Aug 2019
SukkaW
on 18 Aug 2019
That means [email protected] is slower than [email protected]. (Edit: not necessarily after benchmark)
After a glance through the htmlparser2, I wonder if we can use it directly, instead of via cheerio; not sure if that can bring perf benefit.
curbengh
on 18 Aug 2019
@curbengh Hexo is now using [email protected]
Maybe we should first test the performance of hexo using [email protected], to see is it actually slower.
Update
Here is the result:
Test A
latest hexo master branch, with meta_generator commented out.
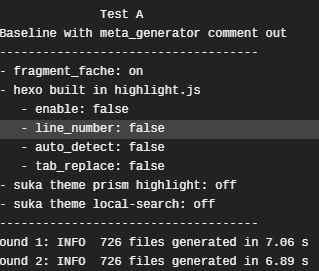
Test B
sukkaw/hexo#bump-cheerio-1.x using github:curbengh/cheerio#decode-test, with meta_generator commented out.

The [email protected] is even slightly faster than [email protected].
SukkaW
on 18 Aug 2019
Interesting, perhaps [email protected] includes some optimizations that somehow negate the latency of parse5. Judging from https://github.com/cheeriojs/dom-serializer/pull/85, [email protected] dropped decodeEntities and xmlMode options, maybe that's why it's faster.
This also means parse5 may not be that slow, so we can consider it in addition to htmlparser2.
curbengh
on 19 Aug 2019
The DOMParser package performs high-speed analysis according to web standards Draft.
However, it may be inconvenient because it is a pure parser.
 segayuu
on 19 Aug 2019
segayuu
on 19 Aug 2019
DOMParser looks promising, too bad it can't do any manipulation.
Just realized DOMParser can be utilized in open_graph since it just needs to parse.
and in unit tests.
Edit: Unit test is usually tiny (<5 posts), so the improvement might not be noticeable.
curbengh
on 19 Aug 2019
I just tried re-implementing toc using dom-parser. Somehow parentNode doesn't work, to replace $.parent().
const DomParser = require('dom-parser')
const source = `<span class="john">hey<h1>aaa</h1><h2>bbb</h2><h3>ccc</h3></span>`
const dom = new DomParser().parseFromString(source)
const heading = dom.getElementsByTagName('h1')
console.log(heading[0].parentNode)
// null
const cheerio = require('cheerio')
const $ = cheerio.load(source)
console.log($('h1').parent().attr('class'))
// john
cheerio is easy to use, and I think the problem of cheerio is it will become very slow when it need to load huge content (for small content cheerio will consume 11ms, for huge content cheerio might consume 65ms).
We might try to use regex to obtain small fragment, then let cheerio to load and manipulate that fragment.
SukkaW
on 19 Aug 2019
For the optimization for toc() helper, I start with conditional require cheerio and return before cheerio.load: sukkaw/hexo:lazy-cheerio-for-toc. But the performance dropped by 5%, so I stopped.
@curbengh do you work out the dom-parser problem?
SukkaW
on 22 Aug 2019
Nope, I'm still far off.
curbengh
on 23 Aug 2019
toc() helper needs parentNode, which makes nearly impossible using regex to replace cheerio.
SukkaW
on 23 Aug 2019
Regular expressions are specialized for searching from the left, and it is necessary to search from the right to find parents efficiently.
Is there any way other than using String#lastIndexOf() and RegExp#sticky flag?
segayuu
on 23 Aug 2019
html-dom-parser, which is a wrapper of htmlparser2, can turn a dom tree into json. And parent is supported in html-dom-parser.
@curbengh Have a look?
SukkaW
on 23 Aug 2019
Currently I have came up with this, a pieces of codes to flatten the html-dom-parser output.
const parser = require('html-dom-parser');
const output = parser('<p>Hello, <span>world!</span></p><span>123</span>');
console.log(output);
/*
[ { type: 'tag',
name: 'p',
attribs: {},
children: [ [Object], [Object] ],
next:
{ type: 'tag',
name: 'span',
attribs: {},
children: [Array],
next: null,
prev: [Circular],
parent: null },
prev: null,
parent: null },
{ type: 'tag',
name: 'span',
attribs: {},
children: [ [Object] ],
next: null,
prev:
{ type: 'tag',
name: 'p',
attribs: {},
children: [Array],
next: [Circular],
prev: null,
parent: null },
parent: null } ]
*/
let result= {};
Object.assign(result, parseOutput);
const flatten = (tag) => {
if (!tag.children.length) return tag;
for (let child of tag.children) {
if (child.children) {
flatten(child);
}
result[Object.keys(result).length] = child;
}
};
for (let tag of parseOutput) {
flatten(tag);
}
console.log(result);
/*
{ '0':
{ type: 'tag',
name: 'p',
attribs: {},
children: [ [Object], [Object] ],
next:
{ type: 'tag',
name: 'span',
attribs: {},
children: [Array],
next: null,
prev: [Circular],
parent: null },
prev: null,
parent: null },
'1':
{ type: 'tag',
name: 'span',
attribs: {},
children: [ [Object] ],
next: null,
prev:
{ type: 'tag',
name: 'p',
attribs: {},
children: [Array],
next: [Circular],
prev: null,
parent: null },
parent: null },
'2':
{ data: 'Hello, ',
type: 'text',
next:
{ type: 'tag',
name: 'span',
attribs: {},
children: [Array],
next: null,
prev: [Circular],
parent: [Object] },
prev: null,
parent:
{ type: 'tag',
name: 'p',
attribs: {},
children: [Array],
next: [Object],
prev: null,
parent: null } },
'3':
{ data: 'world!',
type: 'text',
next: null,
prev: null,
parent:
{ type: 'tag',
name: 'span',
attribs: {},
children: [Array],
next: null,
prev: [Object],
parent: [Object] } },
'4':
{ type: 'tag',
name: 'span',
attribs: {},
children: [ [Object] ],
next: null,
prev:
{ data: 'Hello, ',
type: 'text',
next: [Circular],
prev: null,
parent: [Object] },
parent:
{ type: 'tag',
name: 'p',
attribs: {},
children: [Array],
next: [Object],
prev: null,
parent: null } },
'5':
{ data: '123',
type: 'text',
next: null,
prev: null,
parent:
{ type: 'tag',
name: 'span',
attribs: {},
children: [Array],
next: null,
prev: [Object],
parent: null } } }
*/
I am indeed struggling with traversing levels of html-dom-parser output. I'll see how I can proceed. Feel free to work on toc.js, I may only do it this weekend. (edit: or next)
curbengh
on 28 Aug 2019
const parse5 = require("parse5");
const html = `
<!-- Based on example.org -->
<!doctype html>
<html>
<body>
<div id="container">
<h1>Example Domain</h1>
<p>This domain is established to be used for illustrative examples in documents. You may use this
domain in examples without prior coordination or asking for permission.</p>
<p id="text"><a href="http://www.iana.org/domains/example">More information...</a></p>
</div>
</body>
</html>
`;
const dom = parse5.parse(html);
console.log(dom);
will result in an Object of DOM Tree.
Since parse5 doesn't provide methods like getElementById, we still need to flatten the Object and traverse through it.
SukkaW
on 15 Oct 2019
const flatten = (obj) => {
const array = Array.isArray(obj) ? obj : [obj];
return array.reduce((acc, value) => {
acc.push(value);
if (value.children) {
acc = acc.concat(flatten(value.children));
}
return acc;
}, []);
};
There is a sample code snipppet about how to flatten an array or Object in ES6 way.
SukkaW
on 19 Oct 2019
It seems that cheerio used in toc() helper just can not be dropped.
parentNode of dom-parser is broken, parse5 has no parent support, and it is very hard to implement a textContent when using html-dom-parser.
And it seems that the [email protected] is about 4% faster than [email protected] when used with Hexo according to the benchmark (https://github.com/hexojs/hexo/issues/3677#issuecomment-522318120). For me I will just giveup and use the latest version of cheerio.
SukkaW
on 19 Oct 2019
Just a note that the current published version of [email protected] (an rc) still suffer from this bug. The fix is yet to be published.
Anyhow, I still determined to have toc without cheerio. We can check out how others implement it.
Edit: Just checked out eleventy-plugin-toc & eleventy-plugin-nesting-toc, they also depend on cheerio...
Perhaps can investigate how other langs implement it.
curbengh
on 27 Oct 2019
@curbengh
It will be very simple for toc() helper to support a regular post since most markdown renderer for hexo will insert id for every heading (both of hexo-renderer-marked and hexo-renderer-markdown-it enable it by default). Then we can just write some regex to extract the heading tags and their id attribute.
The real chanllenge is the posts/pages which are not written in markdown, heading tags might not have id attribute, thus toc() helper has to look up for their parent element.
SukkaW
on 27 Oct 2019
@curbengh https://github.com/derhuerst/flickr-photo-url/pull/10
I have found a PR about some project relpace cheerio with htmlparser2. I might carry out some expriment then.
SukkaW
on 9 Nov 2019
@curbengh
Although for Hexo itself, the behavior of toc() helper won't be changed. But dropping cheerio will break theme that load cheerio from hexo's node_modules. We should mention it in 4.2.0's release notes to warn the theme maintainers & users.
SukkaW
on 14 Dec 2019
Hexo has completely replace cheerio with native JavaScript after #3850 is merged, so the issue can be closed now.
cheerio will remain in devDependencies since it is quite useful when making a unit test.
SukkaW
on 20 Dec 2019
Related issues
 mengLLLL
·
3Comments
mengLLLL
·
3Comments
 demurgos
·
3Comments
demurgos
·
3Comments
 yunTerry
·
3Comments
yunTerry
·
3Comments
 netcan
·
3Comments
netcan
·
3Comments
 jasoncheng911
·
3Comments
jasoncheng911
·
3Comments
Most helpful comment
Hexo has completely replace cheerio with native JavaScript after #3850 is merged, so the issue can be closed now.
cheerio will remain in devDependencies since it is quite useful when making a unit test.